
Table of Contents
- Integrating Local LLM Frameworks: A Deep Dive into LM Studio and AnythingLLM
- Introduction to Local Large Language Models (LLMs)
- Exploring LM Studio and AnythingLLM: Interact with Your Documents Like Never Before
- Next Steps in Local LLM Integration
- Getting Started with LM Studio
- Setting Up LM Studio
- Seamless Integration and Advanced Compatibility with Hugging Face Models in LM Studio
- Enhancing Model Compatibility and Performance with LM Studio
- Unlocking Full Potential with LM Studio’s AI Chat Interface
- Exploring LM Studio OpenAI-Like Local Inference Server
- Insightful Logging and Monitoring from the LM Studio Server
- LM Studio Command-Line Interface: Maximizing Efficiency
- Exploring AnythingLLM: Enhance Your Local AI Ecosystem
- Effortless Installation Guide for AnythingLLM
- Choosing Your AnythingLLM Setup: Docker vs Desktop Versions
- Leveraging AI Agents in AnythingLLM
- Seamless Integration with Local and Cloud-Based LLM Providers
- Strategic Advantages of AnythingLLM Over Other AI Frameworks
- Comprehensive Integration Capabilities of AnythingLLM
- Visual Integration Guide for AnythingLLM: Connecting with Top LLM Providers
- Integrating Local and Cloud Embedders with Vector Databases in AnythingLLM
- Optimizing Data Retrieval: Configuring Embedding Preferences in AnythingLLM
- Maximizing Efficiency with Vector Database Options in AnythingLLM
- Connecting AnythingLLM with Various File Systems for Enhanced RAG Capabilities
- LM Studio and Ollama as Local Inference Servers for AnythingLLM
- Comprehensive Integration Summary: LM Studio and Ollama in the AnythingLLM Ecosystem
Integrating Local LLM Frameworks: A Deep Dive into LM Studio and AnythingLLM
In this tutorial, you will explore two prominent frameworks, LM Studio and AnythingLLM, and learn how to integrate them for enhanced local foundational model capabilities. We will delve into their features, demonstrate how to chat with your documents using AnythingLLM, explore the capabilities of LM Studio with CPU offloading and other features, and show how to use LM Studio and Ollama as backend servers for AnythingLLM.

This will showcase their combined power in creating a robust local AI ecosystem. Let’s dive in!
This lesson is the 3rd of a 4-part series on Local LLMs:
- Harnessing Power at the Edge: An Introduction to Local Large Language Models
- Inside Look: Exploring Ollama for On-Device AI
- Integrating Local LLM Frameworks: A Deep Dive into LM Studio and AnythingLLM (this tutorial)
- Lesson 4
To learn how to integrate and explore LM Studio and AnythingLLM for enhanced local foundational model capabilities, just keep reading.
Introduction to Local Large Language Models (LLMs)
In our journey exploring the potential of local large language models (LLMs), we’ve delved into a wide array of frameworks and tools that empower users to harness AI capabilities on their own devices. Our first post, Harnessing Power at the Edge: An Introduction to Local Large Language Models, provided a comprehensive overview of LLMs. We examined what LLMs are, discussed the distinctions between local and cloud-based models, and explored various model formats (e.g., PyTorch, SafeTensor, GGML, and GGUF).
Additionally, we covered different quantization techniques essential for optimizing model performance on local hardware. A significant portion of that post was dedicated to evaluating numerous local LLM frameworks, from Ollama to ChatRTX by NVIDIA, Oobabooga TextGen WebUI, AnythingLLM, LM Studio, Continue.dev, and more. This laid the groundwork for understanding the diverse landscape of local LLMs and their potential applications.
In our second post, Inside Look: Exploring Ollama for On-Device AI, we took a deep dive into Ollama, a standout framework in the local LLM space. We guided you through the installation process, highlighting Ollama’s intuitive model registry and its ability to integrate models from Hugging Face seamlessly. We demonstrated how to utilize Ollama via the command-line interface (CLI) and its Python API, showcasing its versatility. Moreover, we explored Ollama’s integration with LangChain. We provided insights on deploying Ollama with WebUI using Docker to create a web-based chat UI, underscoring its flexibility and robustness for various AI-driven applications.
Exploring LM Studio and AnythingLLM: Interact with Your Documents Like Never Before
Today’s tutorial will focus on two other prominent frameworks: LM Studio and AnythingLLM. We will delve into their features and demonstrate how to chat with your documents using AnythingLLM. Additionally, we will explore LM Studio’s capabilities, including CPU offloading and other features, and show how to use LM Studio and Ollama as backend servers for AnythingLLM. This integration will showcase their combined power in creating a robust local AI ecosystem.
The first framework we will explore is LM Studio, known for its comprehensive set of features designed to maximize the efficiency and performance of local LLMs. We’ll look at its installation process, which is straightforward and user-friendly, requiring just a simple installation file. Once installed, LM Studio provides a suite of tools that enhance the capabilities of your local models (e.g., CPU offloading), which allows for better resource management and improved model performance. We’ll also discuss how LM Studio supports various model formats and integrates seamlessly with other AI tools and frameworks.
Next, we’ll dive into AnythingLLM, a versatile framework that offers a wide range of functionalities, including the ability to chat with your documents. This feature allows you to interact with your data more intuitively and efficiently, leveraging the power of LLMs to retrieve and generate information seamlessly. We’ll cover the setup process for AnythingLLM, highlighting its user-friendly interface and robust feature set. Additionally, we’ll explore how AnythingLLM can be configured to work with different backend servers, including LM Studio and Ollama.
Next Steps in Local LLM Integration
To get started, we’ll first introduce you to LM Studio, discussing its unique features and how it enhances local AI capabilities. Following that, we’ll explore AnythingLLM, highlighting its strengths and how it facilitates seamless interaction with your documents. Finally, we’ll demonstrate the integration process, showing you how to leverage the strengths of both LM Studio and Ollama as backend servers for AnythingLLM.
By the end of this tutorial, you’ll have a comprehensive understanding of how to utilize these frameworks to create a powerful local AI ecosystem. Whether you’re looking to enhance your document interaction capabilities or optimize your model performance with advanced features, this guide will provide you with the insights and tools you need. Let’s dive in and unlock the full potential of local LLM frameworks together!
Getting Started with LM Studio
LM Studio is a cutting-edge framework designed to streamline and enhance the deployment of large language models on local machines. Although it is not entirely open source, it offers most of its features freely, making it accessible for extensive testing and use. LM Studio stands out for its user-friendly interface and a suite of powerful features that cater to both novice users and AI experts. It boasts compatibility across various platforms (e.g., Apple, Windows, and Linux). However, on Linux, it is currently in a beta state.
I’ve dedicated a lot of time and effort to writing the blog post and creating an extensive video for our paid subscribers. Given this investment, I hope it’s understandable that captions and figure numbers might be omitted for free users. However, I will make sure to include sources for any material borrowed from other places.
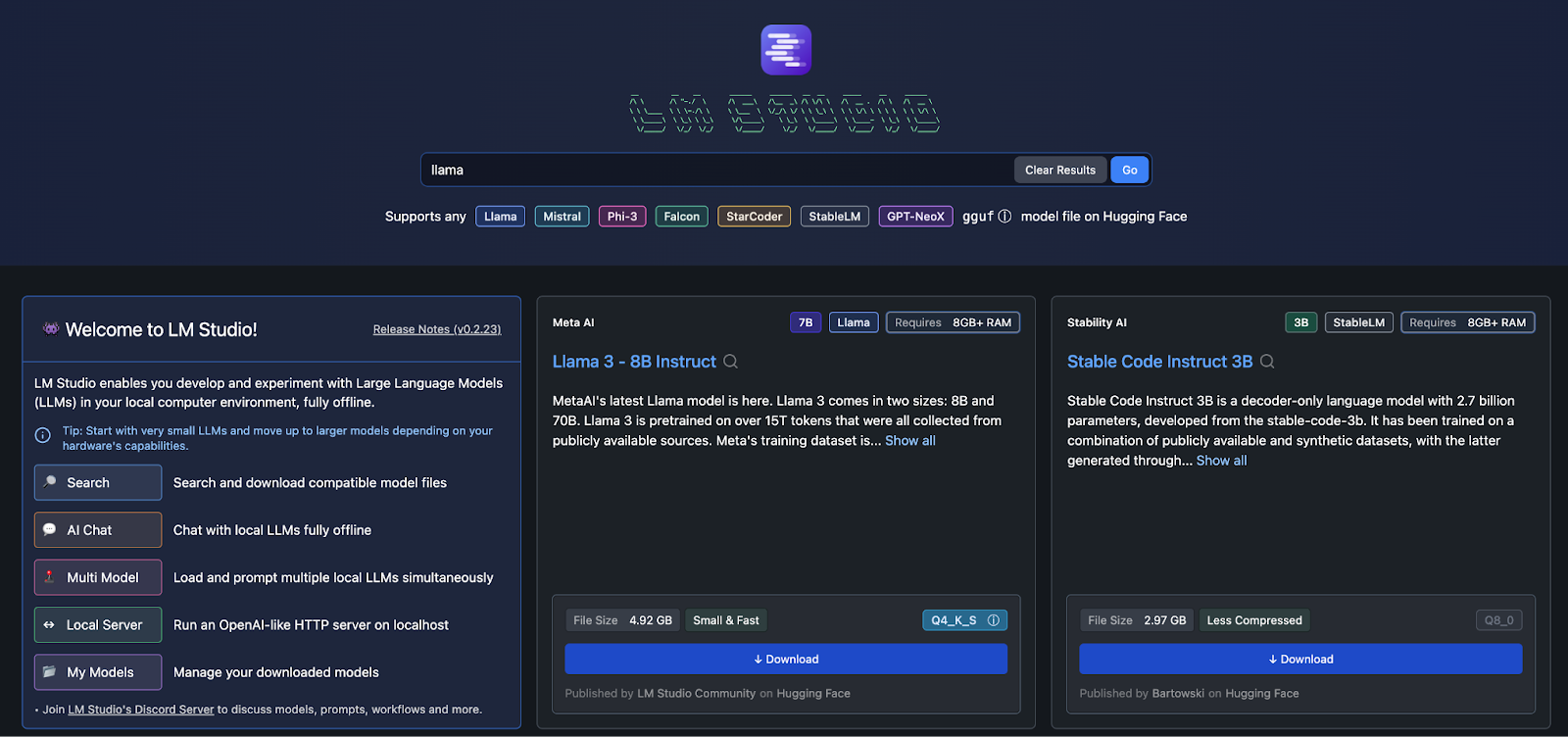
Setting Up LM Studio
Setting up LM Studio is a breeze. The installation process is straightforward, much like what we observed in our previous lesson with Ollama. Installing LM Studio is also quite simple: you just need to click the installation button on the website, which will provide you with the appropriate installation file for your operating system (.dmg for Mac or an equivalent for Windows and Linux). Notably, LM Studio supports all Apple silicon chips, including M1, M2, and the latest M3, ensuring optimized performance on the latest hardware. Once installed, LM Studio will be ready to use with all its features accessible from the main interface. Once installed, LM Studio will be ready to use with all its features accessible from the main interface.
One of the standout features of LM Studio, compared to Ollama, is its all-in-one application design. While Ollama typically installs as a background tool and requires a separate web UI or CLI terminal for interaction, LM Studio differentiates itself by offering a comprehensive tool with all features integrated into a single, user-friendly application. This includes a built-in chat interface, which provides a seamless user experience without the need for additional setups like third-party Docker builds or separate web UIs. This makes LM Studio an attractive choice for users looking for a streamlined and efficient AI framework.
Seamless Integration and Advanced Compatibility with Hugging Face Models in LM Studio
LM Studio supports a plethora of large language models available on Hugging Face. It allows you to pull or download these models directly from the Hugging Face model repository within the LM Studio application itself. It supports GGUF quantized model formats, ranging from Q8 quantization to Q1, which can be easily selected and downloaded with just a few clicks.
One of the unique features offered by LM Studio is its advanced model exploration and selection process. When searching for a specific model (e.g., Llama 3 or Mistral), LM Studio provides options to sort the results by the most liked, most downloaded, or most recent models. Additionally, it allows filtering based on compatibility, ensuring that users can find models that are suitable for their specific hardware setup.
A key advantage of LM Studio is its ability to assess your system’s RAM and GPU capabilities to suggest compatible models. For instance, on a Mac with an integrated Metal GPU supporting unified memory, LM Studio can estimate the total available RAM and determine if a model can be fully or partially run on your system. This feature is particularly useful for optimizing performance and avoiding compatibility issues.
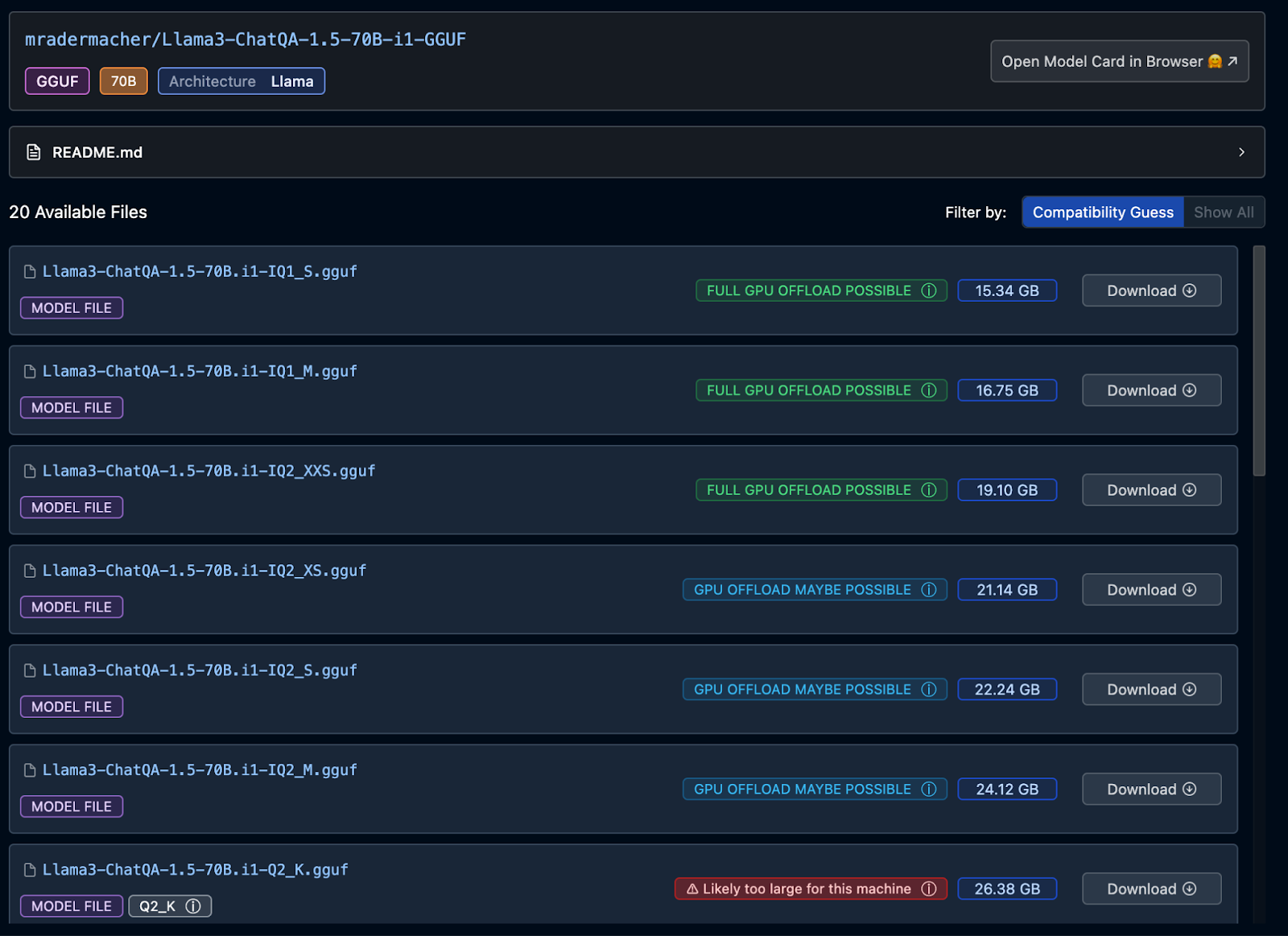
LM Studio provides clear indicators for model compatibility, especially when considering specific hardware setups like a Mac with an M3 Pro chip and 36 GB of RAM. This Mac has a unified memory architecture, where both the CPU and GPU share the same RAM. Based on this setup, LM Studio uses the following indicators:
- Full GPU Offload Possible: Displayed with a green sign, indicating that the model can entirely fit into your GPU memory, significantly speeding up inference.
- Partial GPU Offload Possible: Indicated with a blue sign, meaning the model might fit partially in your GPU memory. For example, a model requiring 22 GB of RAM may use a significant portion of your available memory but still be manageable.
- Likely Too Large for This Machine: Shown with a red sign, indicating that the model is likely too large for your system’s capabilities, such as a Llama3 70 billion Q2 quantized model requiring 26 GB of RAM.
As shown in the image below, we have selected the Llama3-ChatQA-1.5-70B model in the GGUF format, uploaded by mradermacher on Hugging Face. This model offers a total of 20 available files, each representing different quantization formats ranging from Q1 to Q5.
The LM Studio interface clearly displays these files with indicators that signify their compatibility with your system’s GPU capabilities. In this specific case, as we examine the different quantization levels of the Llama3-ChatQA-1.5-70B model:
- The lower precision models (e.g.,
Q1_S,Q1_M, andQ2_XXS) can be fully offloaded to the GPU, making them highly efficient for inference. - As we move toward higher precision models like
Q2_XS,Q2_S, and beyond toQ3,Q4, andQ5, the likelihood of fitting these models entirely into the GPU memory decreases, resulting in either partial offload or the model being too large for the machine.
Enhancing Model Compatibility and Performance with LM Studio
LM Studio’s detailed compatibility indicators and support for various GGUF quantized model formats from Hugging Face provide users with a clear understanding of which models can be efficiently run on their hardware. This feature ensures that users are aware of their system’s limitations and can make informed decisions, optimizing their AI workflows by selecting models that best fit their system’s capabilities. This comprehensive compatibility check is not easily available on many other platforms, making LM Studio a standout choice for managing and running large language models.
LM Studio’s support for all GGUF quantized model formats from Hugging Face, combined with its user-friendly interface and advanced features, makes it an excellent tool for anyone looking to optimize their AI workflows on local hardware.
Unlocking Full Potential with LM Studio’s AI Chat Interface
Once we are done exploring how seamlessly LM Studio integrates and downloads models for you on your machine, let’s move on to the AI Chat Interface. After downloading a model in the GGUF format, such as the Meta Llama 3 Instruct model from Hugging Face, you can easily load and interact with it.
To start, navigate to the AI Chat section in LM Studio. This section is designed similarly to ChatGPT, where you have options like “New Chat” and access to your previous chats on the left sidebar. Select an existing chat or start a new one.
At the top of the chat interface, you will see an option to select a model to load. Choose the Meta Llama 3 Instruct model from QuantFactory you downloaded earlier. The interface will begin loading the model, displaying real-time updates on RAM usage and CPU utilization. For example, the Meta Llama 3 Instruct GGUF model, which is an 8-bit quantized model, requires approximately 8.54 GB of RAM.
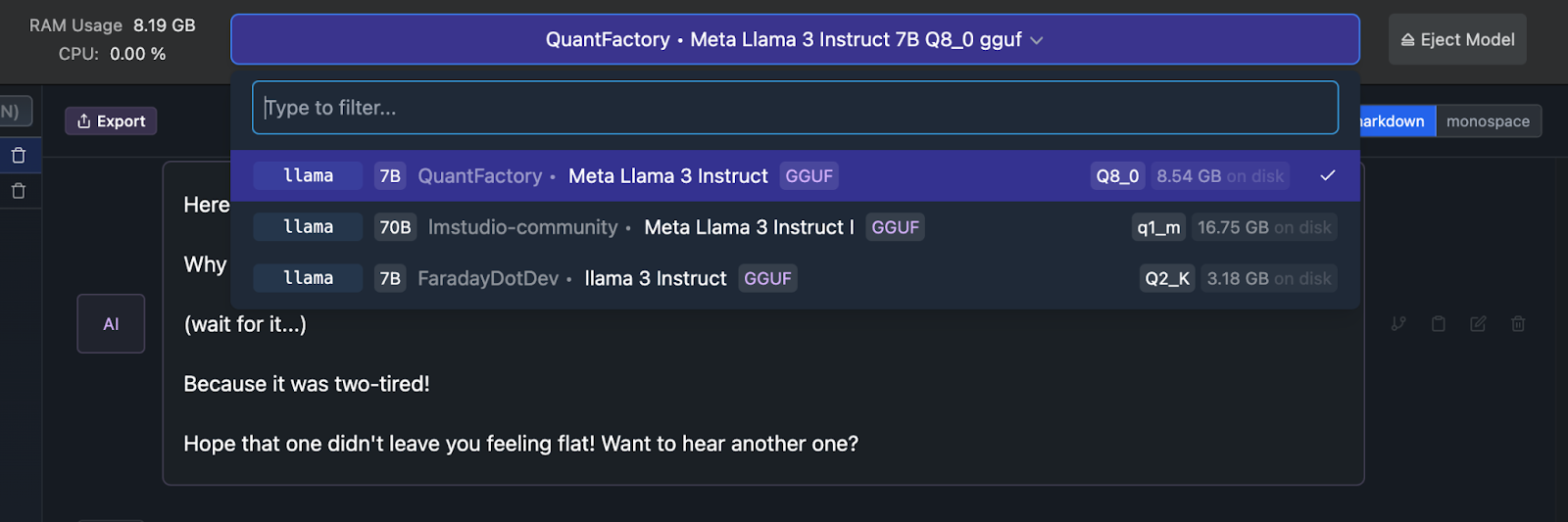
As the model loads, you will notice the RAM usage gradually increasing until it reaches the necessary amount. This process might take some time, indicating that the model is being loaded into memory. Once the loading is complete, the model will be ready for interaction.
You can now start chatting with the model. For instance, you might type, “Tell me a joke,” and the model will respond, “Why don’t scientists trust atoms? Because they make up everything. Hope that made you smile, do you want to hear another one?”
Initially, you might experience some latency, which suggests that the model is not fully utilizing the GPU. This is because, in GPU offload or GPU acceleration mode, the n_gpu_layers is set to 4, meaning it does not use the full GPU capability or the capacity of Apple’s Metal GPU. But we will go into this detail in just a bit.
As shown in the provided screenshot, the GPU utilization is only at 30%, which indicates that the GPU is not being fully leveraged. This limited GPU usage results in slower inference times and noticeable latency during interactions. We will go into more detail about optimizing GPU usage in just a bit.
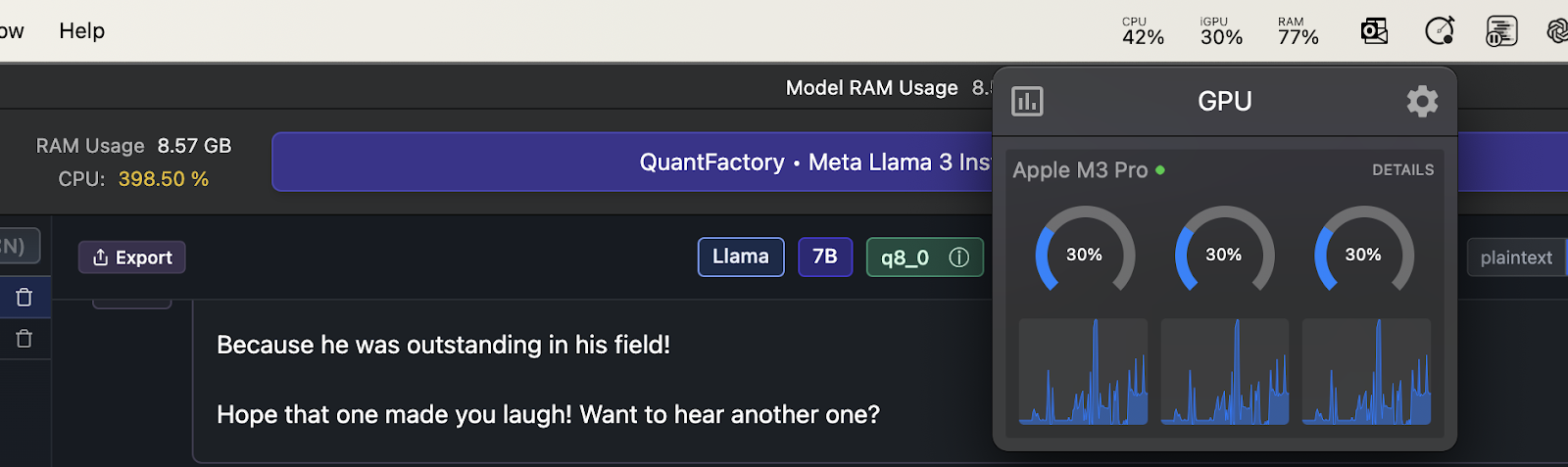
This interactive feature showcases the practical application of large language models within LM Studio. It allows you to engage in conversations and explore the capabilities of various models in a user-friendly environment.
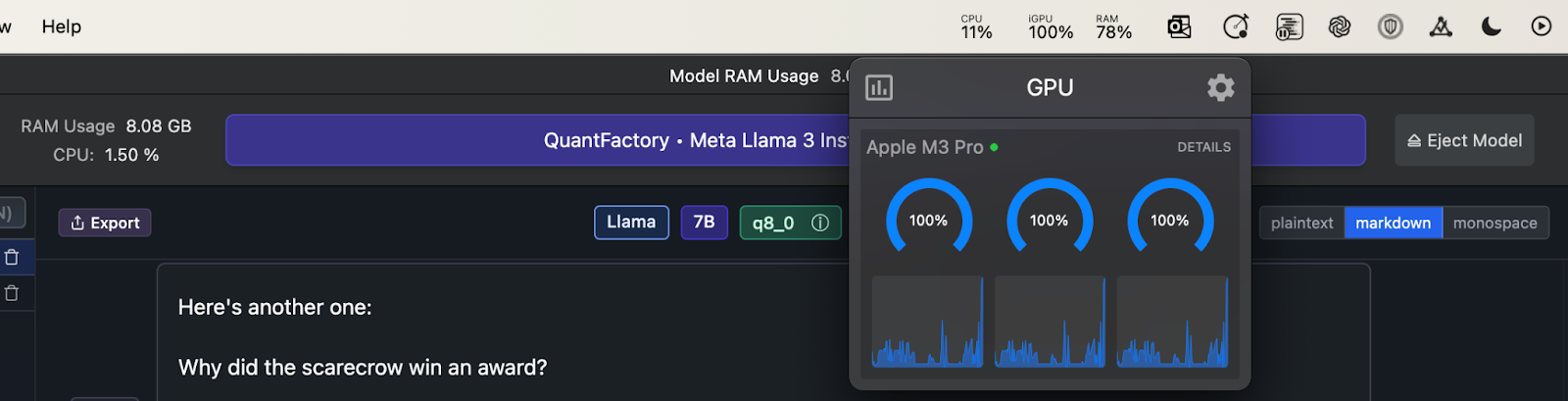
Now, let’s look at the scenario where the GPU offloading is set to max. In this case, the GPU utilization reaches 100%, significantly improving the inference speed. This can be seen in the following screenshot:
Several parameters are displayed below the user message chat box, providing insights into the performance:
- Time to First Token: This indicates the time taken to generate the first token of the response. With maximum GPU utilization, it is approximately
6.05seconds. - Gen t: This represents the generation time per token, which is around
2.98seconds. - Speed: The generation speed is approximately
14.18tokens per second. - Stop Reason: This specifies why the generation stopped, such as reaching the end of the sentence (
eosFound). - GPU Layers: Indicates the number of layers being processed by the GPU, which is
33in this case. - CPU Threads: The number of CPU threads in use, which is
4. - mlock: Whether memory locking is enabled (
true). - Token Count: The number of tokens processed, which is
4862out of2048.
Here, a token is roughly 3/4th of a word.
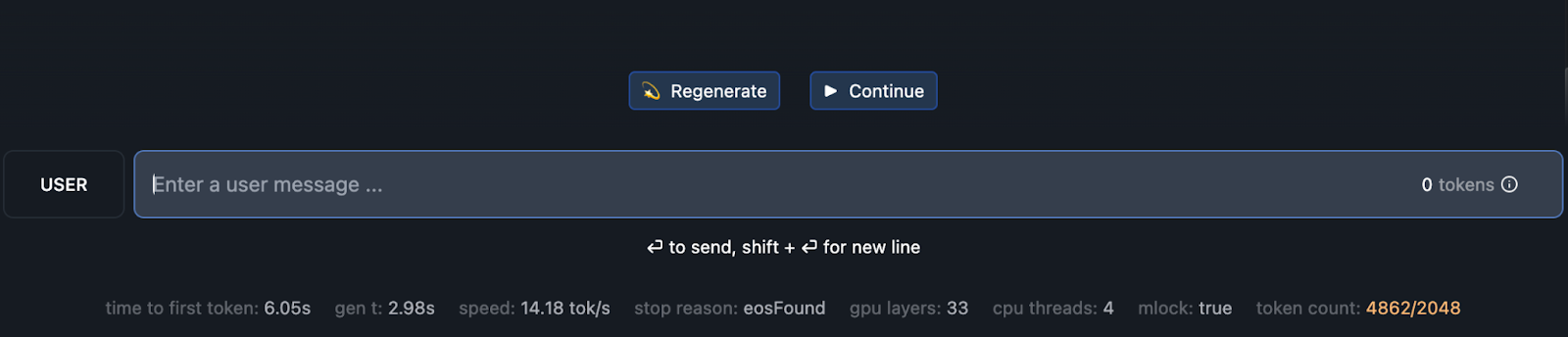
This detailed information helps users understand the performance metrics and optimize their model interactions. These parameters are available regardless of GPU offloading settings, providing valuable insights into model performance.
When GPU offloading is limited, as shown in the following snapshot, where only 4 layers are offloaded to the GPU, the time to the first token is significantly higher at 27.27 seconds. Similarly, the generation time per token and the speed of token generation are 3.91 seconds and 12.60 tokens per second, respectively.

This illustrates the advantage of having a GPU: even if you don’t have enough GPU VRAM or RAM available, you can offload some percentage of the compute to your GPU while utilizing the CPU for the rest. This hybrid approach can still achieve good inference times and improve overall performance.
Exploring LM Studio OpenAI-Like Local Inference Server
In this section, we explore a fascinating feature of LM Studio: the ability to start a local HTTP server that mimics select OpenAI API endpoints. This server can handle chat completions, generate embeddings, and perform other related tasks, providing a robust environment for local AI inference.
The snapshot below shows how the local inference server screen looks in the LM Studio application:
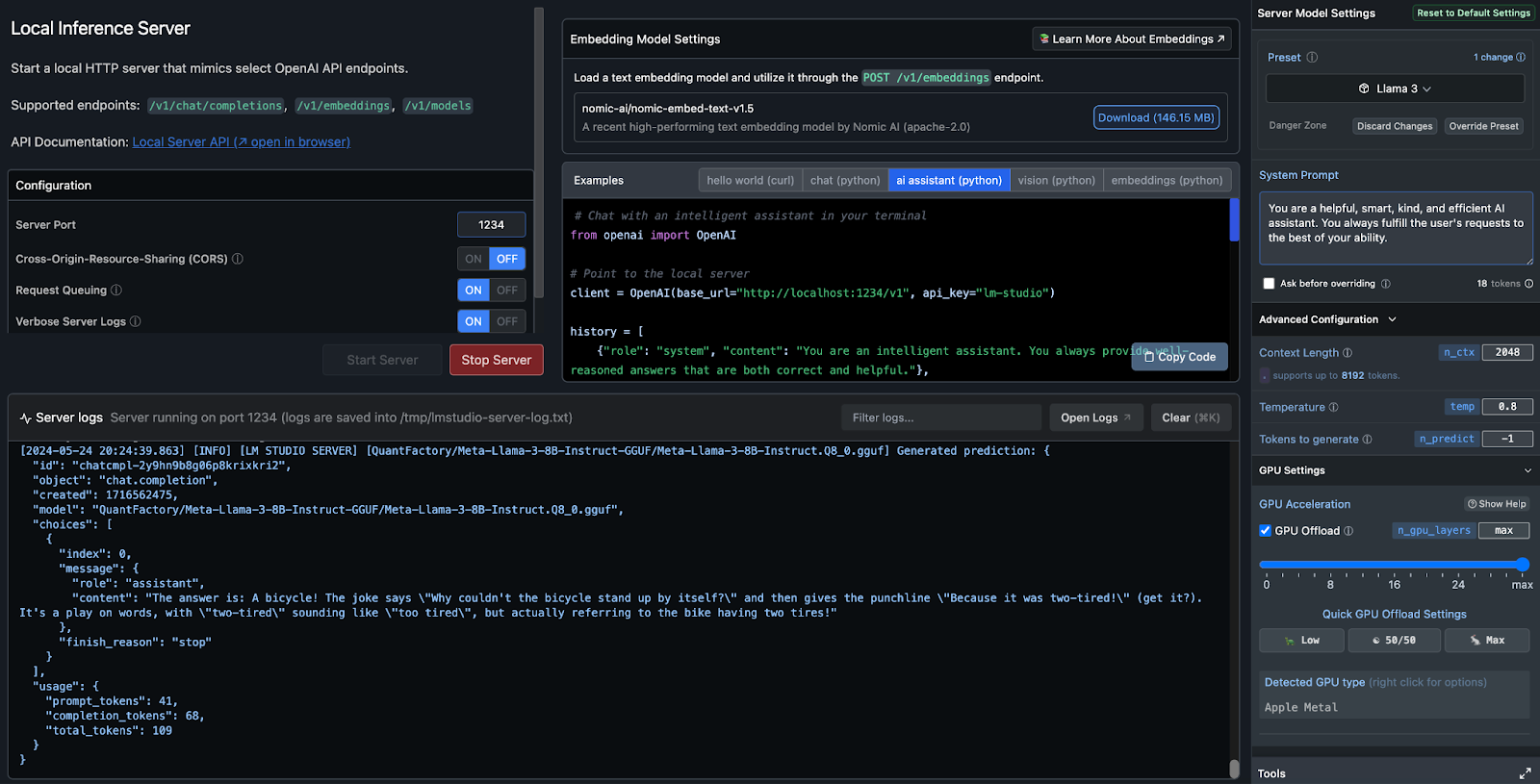
This interface allows you to configure the server, view logs, and manage various settings, making it a powerful tool for developers to utilize local AI capabilities seamlessly. Let’s look at how we can leverage LM Studio’s local inference server using the OpenAI API in Python.
OpenAI API is pip installable and can be installed easily using pip.
pip install openai==0.28.0
This Python script demonstrates how to use the OpenAI API with a local LM Studio server to create an interactive chat application. Here’s a step-by-step explanation:
1. Import OpenAI Library:
import openai
This imports the OpenAI Python library, which provides functions to interact with OpenAI’s API.
2. Configure OpenAI API:
openai.api_base = "http://localhost:1234/v1" openai.api_key = "lm-studio"
These lines configure the OpenAI API to use the local LM Studio server by setting the API base URL and API key.
3. Initialize Conversation History:
history = [
{"role": "system", "content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."},
{"role": "user", "content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."},
]
This initializes the conversation history with a system message and a user message.
4. Define the Response Function:
def get_response(history):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=history,
temperature=0.7
)
return response.choices[0].message.content.strip()
The get_response function takes the conversation history as input and calls the ChatCompletion.create method to get a response from the model. The function returns the generated response after stripping any leading or trailing whitespace.
5. Main Interaction Loop:
if __name__ == "__main__":
while True:
user_input = input("> ")
if user_input.lower() == "exit":
break
history.append({"role": "user", "content": user_input})
new_message = get_response(history)
history.append({"role": "assistant", "content": new_message})
print(new_message)
This loop continuously prompts the user for input, appends it to the conversation history, gets a response from the model, appends the response to the history, and prints the response. The loop breaks if the user types "exit".
This script demonstrates how to build a simple interactive chat application using the OpenAI API with a local server, showcasing the capabilities of the LM Studio setup.
Once we run the llm-inference-server.py script, it starts and waits for user input. As shown below, the interaction begins with the user saying “hello,” and the assistant responds with a greeting, introducing itself as a conversational AI. The conversation continues naturally, with the assistant maintaining context. For example, when the user asks for a joke and then follows up with a question about the joke, the assistant correctly references the previous joke.
Aditya-macbook$ python3 llm-inference-server.py > hello Nice to meet you! I'm a conversational AI designed to assist with tasks, answer questions, and provide helpful information. How can I help you today? > tell me a joke Why couldn't the bicycle stand up by itself? Because it was two-tired! > what couldn't stand by itself? The answer is: A bicycle! The joke says "Why couldn't the bicycle stand up by itself?" and then gives the punchline "Because it was two-tired!" (get it?). It's a play on words, with "two-tired" sounding like "too tired", but actually referring to the bike having two tires! >
This interaction showcases the assistant’s ability to maintain context, respond appropriately to various prompts, and provide coherent and helpful responses. The script efficiently handles the user’s inputs, generating meaningful conversations by leveraging the LM Studio’s local server capabilities.
Insightful Logging and Monitoring from the LM Studio Server
Below you can see the logs that are the server logs from the LM Studio application when we are having a conversation with the Llama 3 7 billion model using the OpenAI API. Below are the logs that are generated. These logs provide a detailed view of the processing steps for ChatGPT. Here is a breakdown:
- Request Received: The LM Studio server receives a POST request to the
/v1/chat/completionsendpoint with a body containing the model, messages, and temperature settings. - Context Handling: The server notes the context overflow policy and processes the last message in the sequence, maintaining a rolling window of the conversation history. For example, the latest message is identified, and the total number of messages is noted.
- Token Generation: The server accumulates tokens sequentially, showing the step-by-step formation of the response from the language model. Each log entry indicates the incremental build-up of the response with new tokens being added (e.g., “The answer is: A bicycle!”).
- Response Construction: The complete response, including the assistant’s message content, is generated. The log captures the total number of tokens used to generate this response.
- Final Output: The server logs the final generated prediction, detailing the content of the response, the number of prompt and completion tokens used, and the total token count.
[2024-05-24 20:24:35.039] [INFO] [LM STUDIO SERVER] Processing queued request...
[2024-05-24 20:24:35.041] [INFO] Received POST request to /v1/chat/completions with body: {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "system",
"content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."
},
{
"role": "user",
"content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."
},
{
"role": "user",
"content": "hello"
},
{
"role": "assistant",
"content": "Nice to meet you! I'm a conversational AI designed to assist with tasks, answer questions, and provide helpful information. How can I help you today?"
},
{
"role": "user",
"content": "tell me a joke"
},
{
"role": "assistant",
"content": "Why couldn't the bicycle stand up by itself?\n\nBecause it was two-tired!"
},
{
"role": "user",
"content": "what couldn't stand by itself?"
}
],
"temperature": 0.7
}
[2024-05-24 20:24:35.041] [INFO] [LM STUDIO SERVER] Context Overflow Policy is: Rolling Window
[2024-05-24 20:24:35.044] [INFO] [LM STUDIO SERVER] Last message: { role: 'user', content: 'what couldn't stand by itself?' } (total messages = 7)
[2024-05-24 20:24:35.463] [INFO] [LM STUDIO SERVER] Accumulating tokens ... (stream = false)
[2024-05-24 20:24:35.464] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 1 tokens: The
[2024-05-24 20:24:35.528] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 2 tokens: The answer
[2024-05-24 20:24:35.592] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 3 tokens: The answer is
[2024-05-24 20:24:35.659] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 4 tokens: The answer is:
[2024-05-24 20:24:35.726] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 5 tokens: The answer is: A
[2024-05-24 20:24:35.790] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 6 tokens: The answer is: A bicycle
[2024-05-24 20:24:35.854] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 7 tokens: The answer is: A bicycle!
[2024-05-24 20:24:35.918] [INFO] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 8 tokens: The answer is: A bicycle! The
......
......
[QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Accumulated 68 tokens: The answer is: A bicycle! The joke says "Why couldn't the bicycle stand up by itself?" and then gives the punchline "Because it was two-tired!" (get it?). It's a play on words, with "two-tired" sounding like "too tired", but actually referring to the bike having two tires!
[2024-05-24 20:24:39.863] [INFO] [LM STUDIO SERVER] [QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf] Generated prediction: {
"id": "chatcmpl-2y9hn9b8g06p8krixkri2",
"object": "chat.completion",
"created": 1716562475,
"model": "QuantFactory/Meta-Llama-3-8B-Instruct-GGUF/Meta-Llama-3-8B-Instruct.Q8_0.gguf",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The answer is: A bicycle! The joke says \"Why couldn't the bicycle stand up by itself?\" and then gives the punchline \"Because it was two-tired!\" (get it?). It's a play on words, with \"two-tired\" sounding like \"too tired\", but actually referring to the bike having two tires!"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 41,
"completion_tokens": 68,
"total_tokens": 109
}
}
This logging mechanism ensures transparency in how the model processes and generates responses, aiding in troubleshooting and optimizing performance. For more information on the LM Local Inference Server, you can visit here.
LM Studio Command-Line Interface: Maximizing Efficiency
As we saw in our previous lesson on Ollama, which is primarily a CLI Local LLM framework, LM Studio has recently introduced its own CLI. Although LM Studio is still in the test phase, the CLI provides a streamlined way to manage the local server, load and unload models, and perform various operations directly from the terminal.
LM Studio CLI is designed to leverage the local inference server concept. Instead of launching the full LM Studio application, you can use the CLI to start the server, which runs LM Studio in a minimized mode.
Here’s how the CLI can be utilized:
lms status # Prints the status of LMStudio lms server # Commands for managing the local server lms ls # List all downloaded models lms load <model> # Load a model lms unload <model> # Unload a model
For more information, you can visit the LM Studio CLI GitHub page and the LM Studio Local Server documentation.
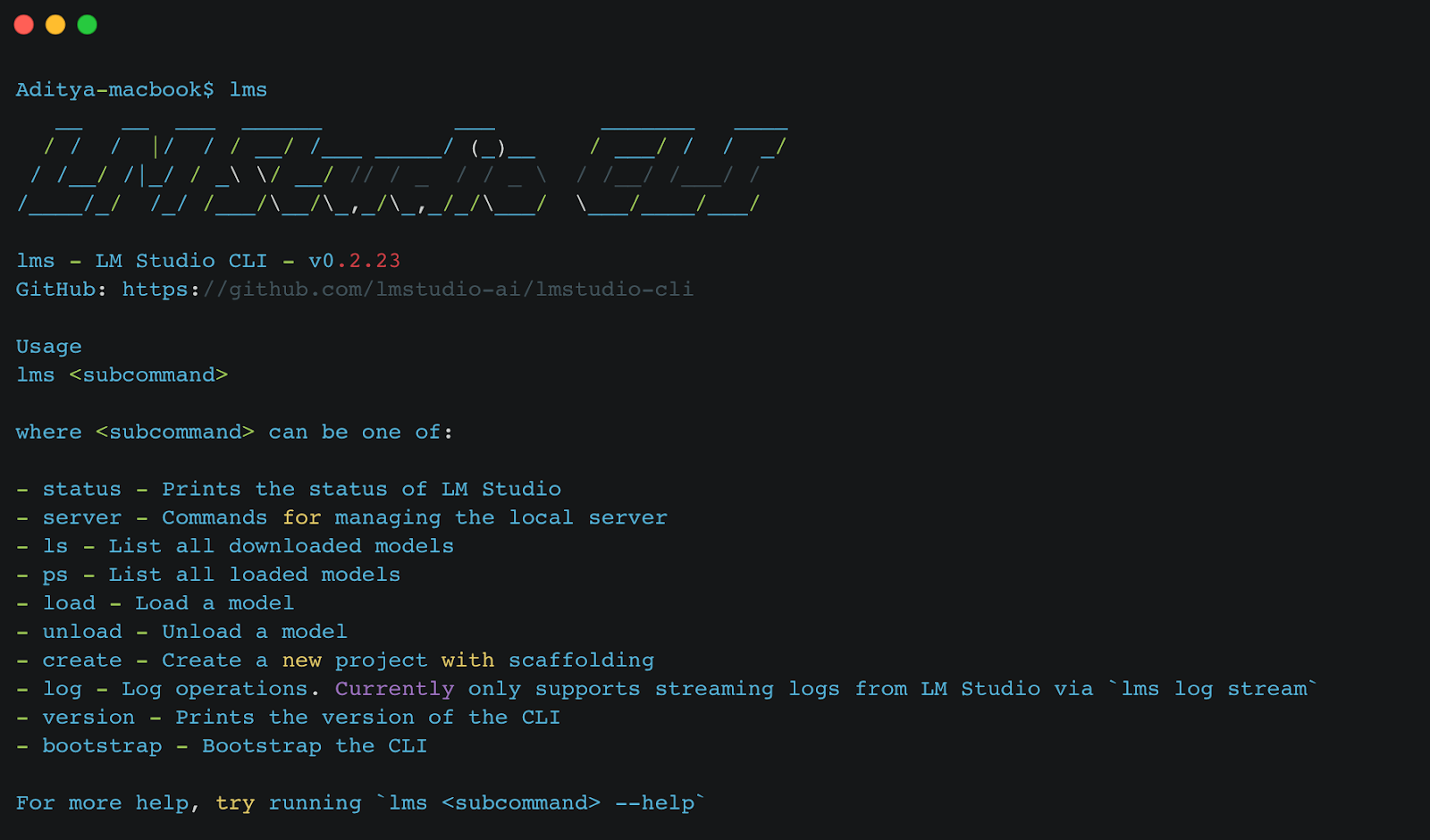
This new CLI tool ensures efficient and quick operations, enhancing the flexibility and usability of LM Studio.
Navigating the Limitations of LM Studio: What You Need to Know
While LM Studio offers numerous advantages, there are some limitations to be aware of:
- Model Format Restriction: LM Studio exclusively supports models in the GGUF format, quantized at different levels. This means other model formats are not supported. Users must ensure their models are in the GGUF format to be compatible with LM Studio.
- Dependency on Hugging Face: LM Studio only supports models from the Hugging Face model hub. Users cannot directly integrate custom models or fine-tuned models that are not uploaded to Hugging Face. To use a custom model, it must first be uploaded in the GGUF format on Hugging Face, from where it can then be pulled into LM Studio.
- Lack of Multi-Modal Support: Currently, LM Studio does not support multi-modal functionalities, such as the ability to upload and process images within the chat interface. This restricts users from running Vision Language Models (VLMs) like LLaVA, which can handle image inputs along with text prompts. In contrast, Ollama’s WebUI supports such multi-modal interactions, allowing users to upload images and ask related questions, which is a feature that could be beneficial if incorporated into LM Studio in the future.
These limitations highlight areas where LM Studio could expand its functionalities to provide a more comprehensive toolset for users working with advanced AI models.
Exploring AnythingLLM: Enhance Your Local AI Ecosystem
In our previous sections, we have explored LM Studio’s capabilities, including its seamless integration with large language models and user-friendly AI chat interface. Now, let’s turn our attention to another powerful framework in the local AI ecosystem: AnythingLLM.
AnythingLLM is an open-source AI tool developed by Mintplex Labs. AnythingLLM is designed to turn any collection of data into a trained chatbot that you can query and chat with. It operates on a BYOK (bring-your-own-keys) model, meaning there are no subscription fees or charges beyond the services you choose to use with it. This makes AnythingLLM a cost-effective solution for integrating powerful AI products into your workflows.
AnythingLLM simplifies the integration of various AI services, such as OpenAI, GPT-4, and vector databases (e.g., LangChain, Pinecone, and ChromaDB) into a cohesive package that enhances productivity exponentially. One of its key strengths is the ability to run entirely on your local machine with minimal overhead, requiring no GPU.
It also supports cloud and on-premises installations, providing flexibility based on your specific needs. Moreover, AnythingLLM supports Retrieval-Augmented Generation (RAG), allowing you to chat with your documents and retrieve relevant information seamlessly.
Getting started with AnythingLLM is straightforward. Data is organized into “Workspaces”, which are collections of files, documents, images, PDFs, and other materials that can be transformed into formats understandable by large language models. You can add or remove files from these Workspaces at any time, allowing for dynamic and flexible data management.
AnythingLLM offers two modes of interaction with your data:
- Query Mode: In this mode, your chats will return data or inferences found within the documents in your Workspace. Adding more documents to the Workspace makes the system smarter and more informative.
- Conversational Mode: This mode allows both your documents and your ongoing chat history to contribute to the LLM’s knowledge base simultaneously. It is particularly useful for appending real-time information, corrections, and addressing misunderstandings the LLM might have.
You can toggle between these modes in the middle of a conversation, offering a versatile approach to managing and interacting with your data.
In this section, we will explore the key features of AnythingLLM, its installation process, and how to effectively integrate it with backend servers like LM Studio and Ollama. By the end of this section, you will have a comprehensive understanding of how to utilize AnythingLLM to create a powerful and efficient local AI ecosystem.
Let’s dive into the world of AnythingLLM and uncover its potential to revolutionize your AI workflows.
Effortless Installation Guide for AnythingLLM
So far, we have explored local LLM frameworks like Ollama and LM Studio, both of which offer very user-friendly installation processes with one-click installation. Similarly, AnythingLLM follows the same approach, providing a one-click installable application with a full suite of tools as a single package that runs on your desktop or edge device.
The installation process for AnythingLLM is designed to be straightforward and hassle-free. As shown in the image provided, AnythingLLM offers installation files for various operating systems, ensuring broad compatibility:
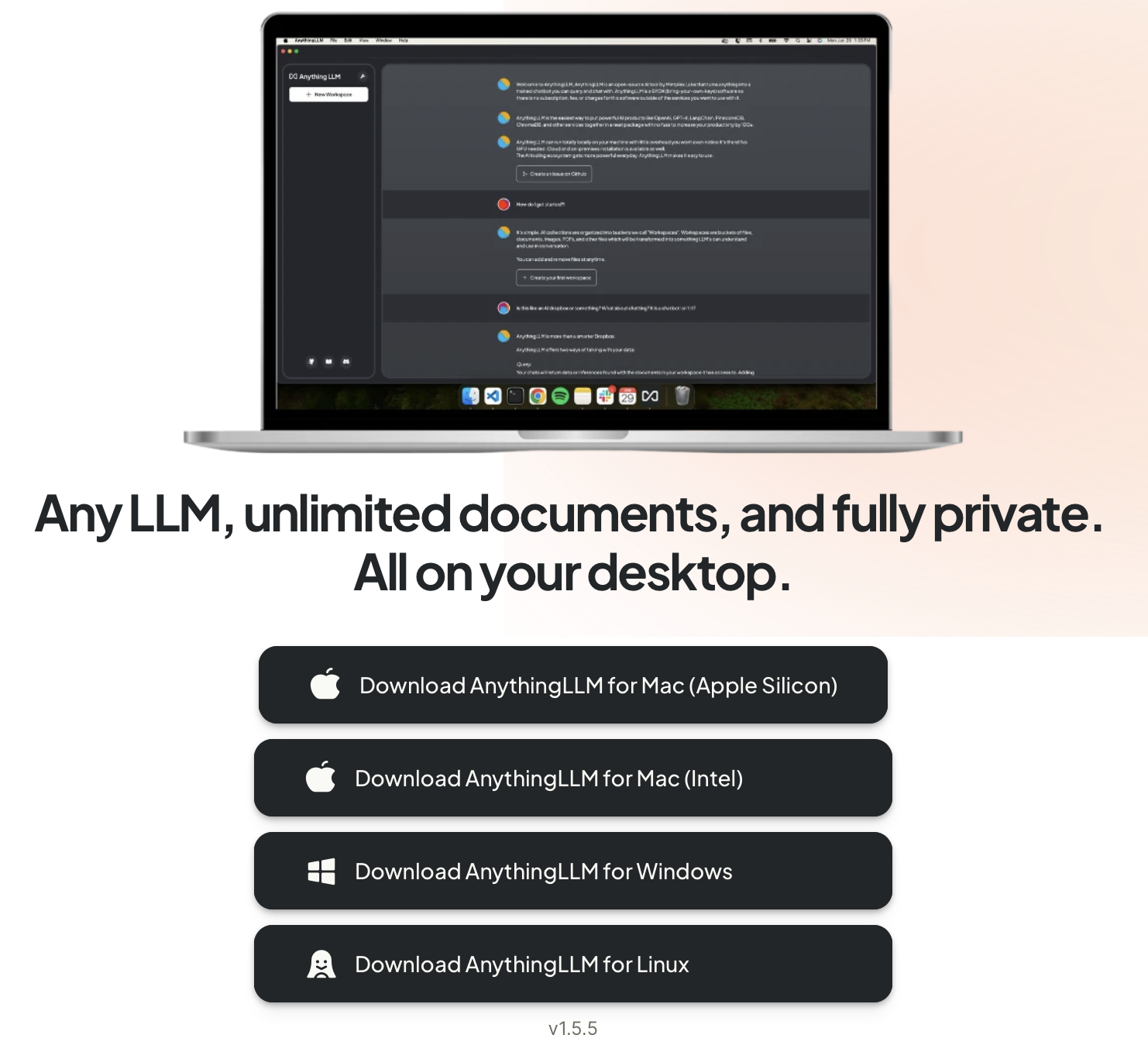
- Download AnythingLLM for Mac (Apple Silicon): This option is optimized for the latest Apple Silicon Macs, ensuring maximum performance on these devices.
- Download AnythingLLM for Mac (Intel): Although Intel Macs have been discontinued, AnythingLLM provides an installation option for users with older Intel-based Macs, making it accessible to a wider range of Mac users.
- Download AnythingLLM for Windows: This option caters to Windows users, providing a seamless installation experience on the most widely used desktop operating system.
- Download AnythingLLM for Linux: For those using Linux, AnythingLLM offers a compatible installation package, ensuring that users of this open-source platform can also benefit from its capabilities.
With this broad compatibility, AnythingLLM ensures that users can install and run the application on their preferred operating system, whether it’s macOS, Windows, or Linux. The installation process is simple: just click on the appropriate download button and follow the prompts to install the application on your device.
Once installed, AnythingLLM provides a fully integrated suite of tools that can transform your local machine into a powerful AI platform. The ability to run locally with minimal overhead, without the need for a GPU, makes it an attractive option for users looking to enhance their productivity with advanced AI capabilities.
Additionally, AnythingLLM supports Docker-based installation, providing flexibility for different usage scenarios.
Choosing Your AnythingLLM Setup: Docker vs Desktop Versions
AnythingLLM offers two main ways to use the application, each with distinct differences in functionality. Both options are open source:
Choose AnythingLLM Desktop if…
- You prefer a one-click installable app to use local LLMs, RAG, and Agents on your device.
- You do not require multi-user support.
- All data needs to remain solely on your device.
- You do not need to publish anything on the public internet, such as a chat widget for a website.
Choose AnythingLLM Docker if…
- You need an easy setup but prefer a server-based service to use local LLMs, RAG, and Agents.
- You want to run an AnythingLLM instance accessible to multiple users simultaneously.
- You want to share information with other users on your instance.
- You require admin and rule-based access for managing workspaces and documents.
- You plan to publish chat widgets to the public internet.
- You want to access AnythingLLM through a web browser.
For a more in-depth feature comparison between the desktop and Docker-based installations, refer to this installation overview guide.
In summary, AnythingLLM’s installation process is designed to be as accessible and user-friendly as possible. Users can quickly set up and start using the application on their devices, regardless of the operating system they use. This ease of installation, combined with its powerful features, makes AnythingLLM a standout choice for integrating AI into your local workflows.
Leveraging AI Agents in AnythingLLM
In this section, we will explore agents and how they enhance the functionality of AnythingLLM. Agents are specialized entities that can interact with various tools and services, acting as intermediaries between the user and the underlying AI models. They enable large language models (LLMs) to perform a wide range of tasks by accessing external resources, executing commands, and managing workflows.
Agents in AnythingLLM represent a unique and powerful feature that sets it apart from other local LLM frameworks we have explored. This capability allows AnythingLLM to access tools, integrate with external APIs, and perform complex operations autonomously. By leveraging agents, users can enhance the capabilities of their LLMs, making them more versatile and efficient.
Agents have access to a variety of tools that significantly extend their functionality. Here are some of the key tools available to agents in AnythingLLM:
- RAG Search: Enables agents to perform retrieval-augmented generation (RAG), allowing them to fetch relevant information from large datasets and provide more accurate responses.
- Web Browsing: Agents can browse the web to gather information or interact with web-based services.
- Web Scraping: Allows agents to extract data from websites, making it useful for data collection and analysis.
- Save Files: Agents can save data to files, enabling persistent storage of information.
- List Documents: Agents can list documents within a workspace, facilitating easy access to available resources.
- Summarize Documents: This tool allows agents to generate summaries of documents, making it easier to digest large amounts of information quickly.
- Chart Generation: Agents can create visual representations of data, helping to illustrate insights and trends.
- SQL Agent: Allows agents to interact with SQL databases, perform queries, and manage data directly.
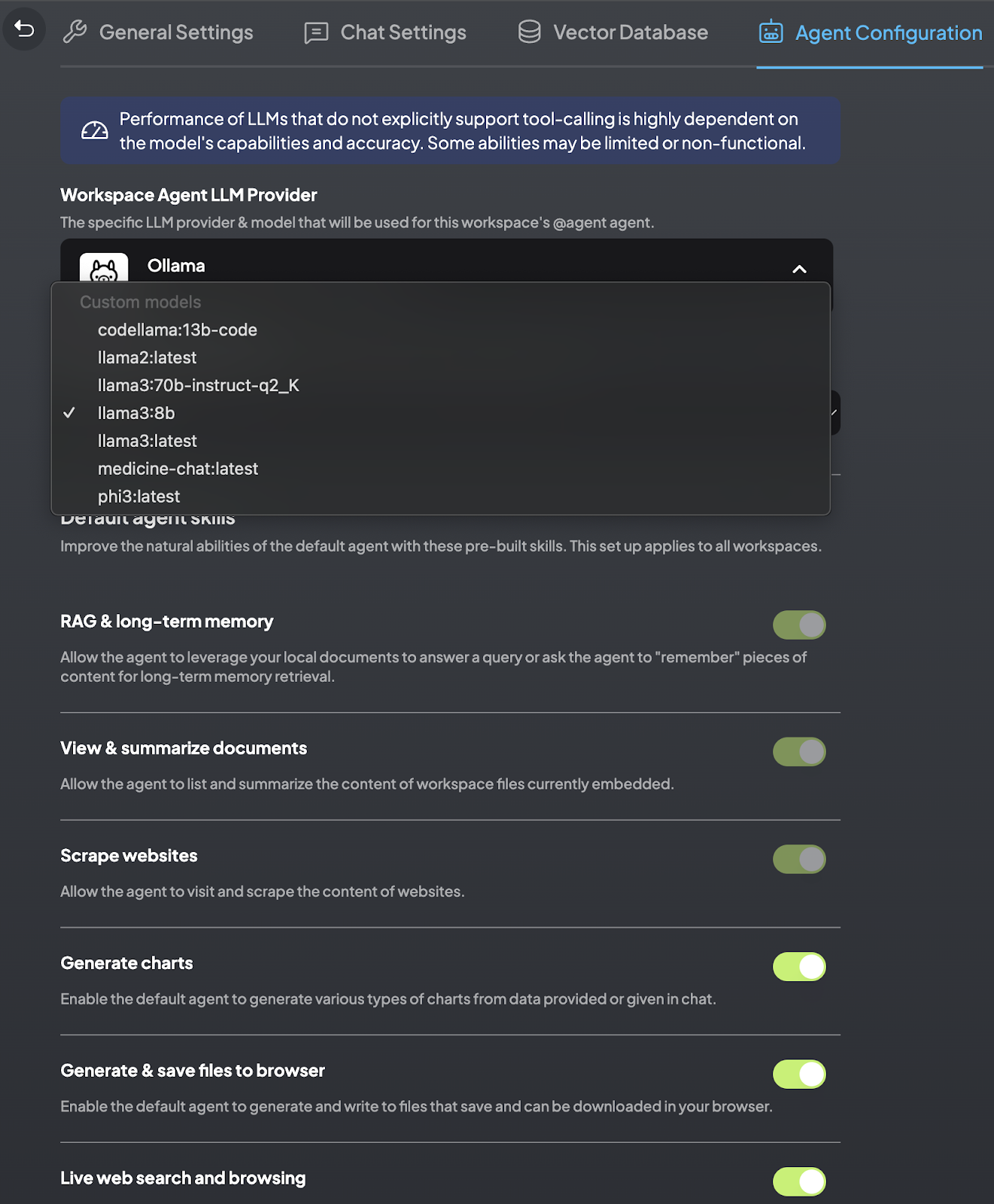
These tools make agents in AnythingLLM highly adaptable and capable of handling a wide range of tasks. The integration of agents within AnythingLLM allows the models to:
- Access External Tools: Agents can connect to various tools and services, enabling the LLM to perform tasks such as data retrieval, processing, and integration with third-party applications.
- Execute Commands: Agents can execute commands on behalf of the user, automating repetitive tasks and streamlining workflows.
- Manage Workflows: Agents can orchestrate complex workflows by coordinating multiple tasks and resources, ensuring seamless and efficient operations.
Additionally, agents in AnythingLLM are designed to be easy to use. To invoke an agent, simply use the @agent command in your chat. Once invoked, agents operate within the workspace they were called from and can access the shared tools available across workspaces.
Here are some examples of how to use agents in AnythingLLM:
- Example 1: Summarize sales volume data from a database.
@agent can you plot y=mx+b where m=10 and b=0?
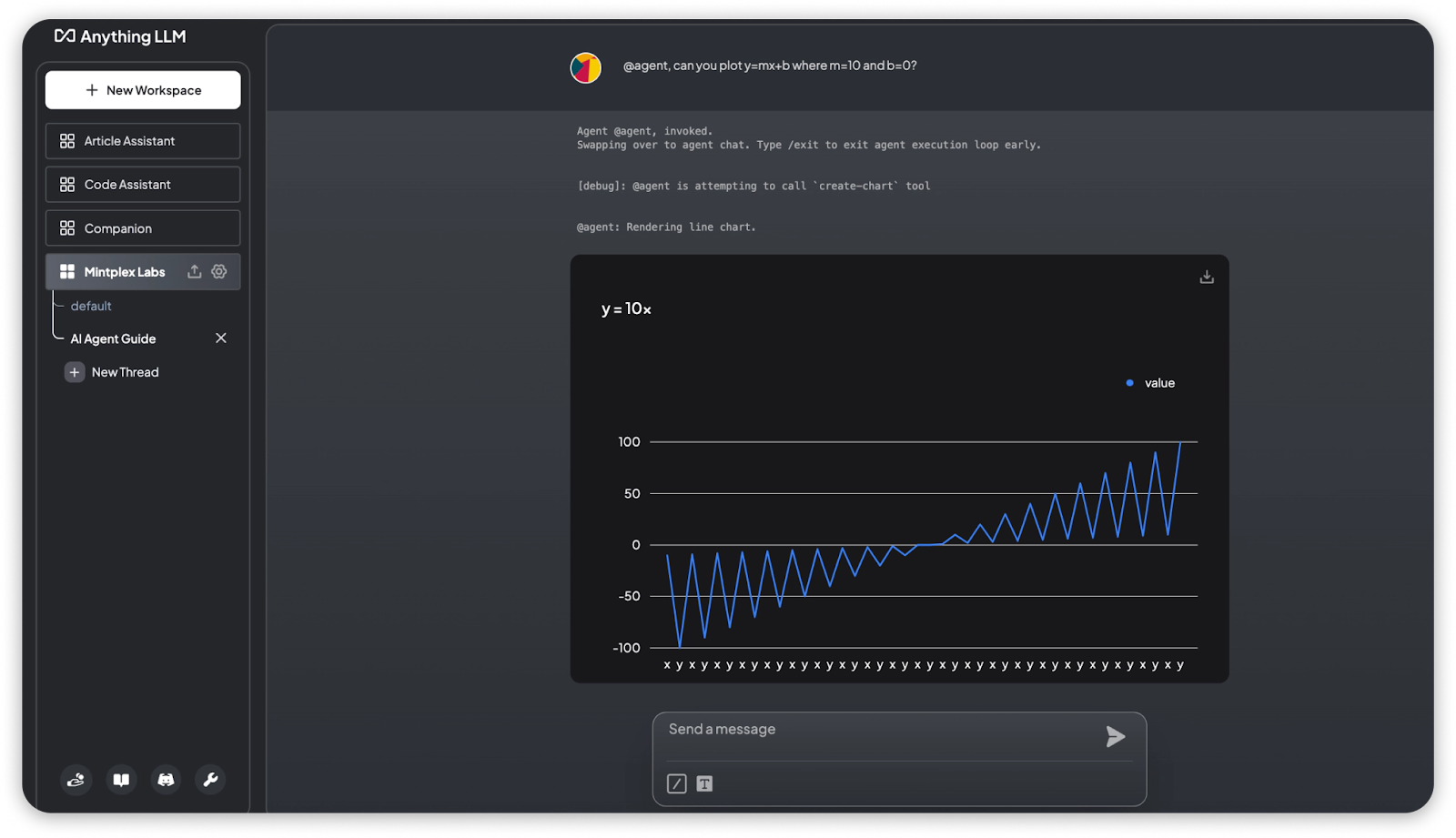
- Example 2: Summarize Documents tool allows the agent to give you a summary of a document.
@agent can you summarize the content on https://docs.useanything.com/features/chat-logs
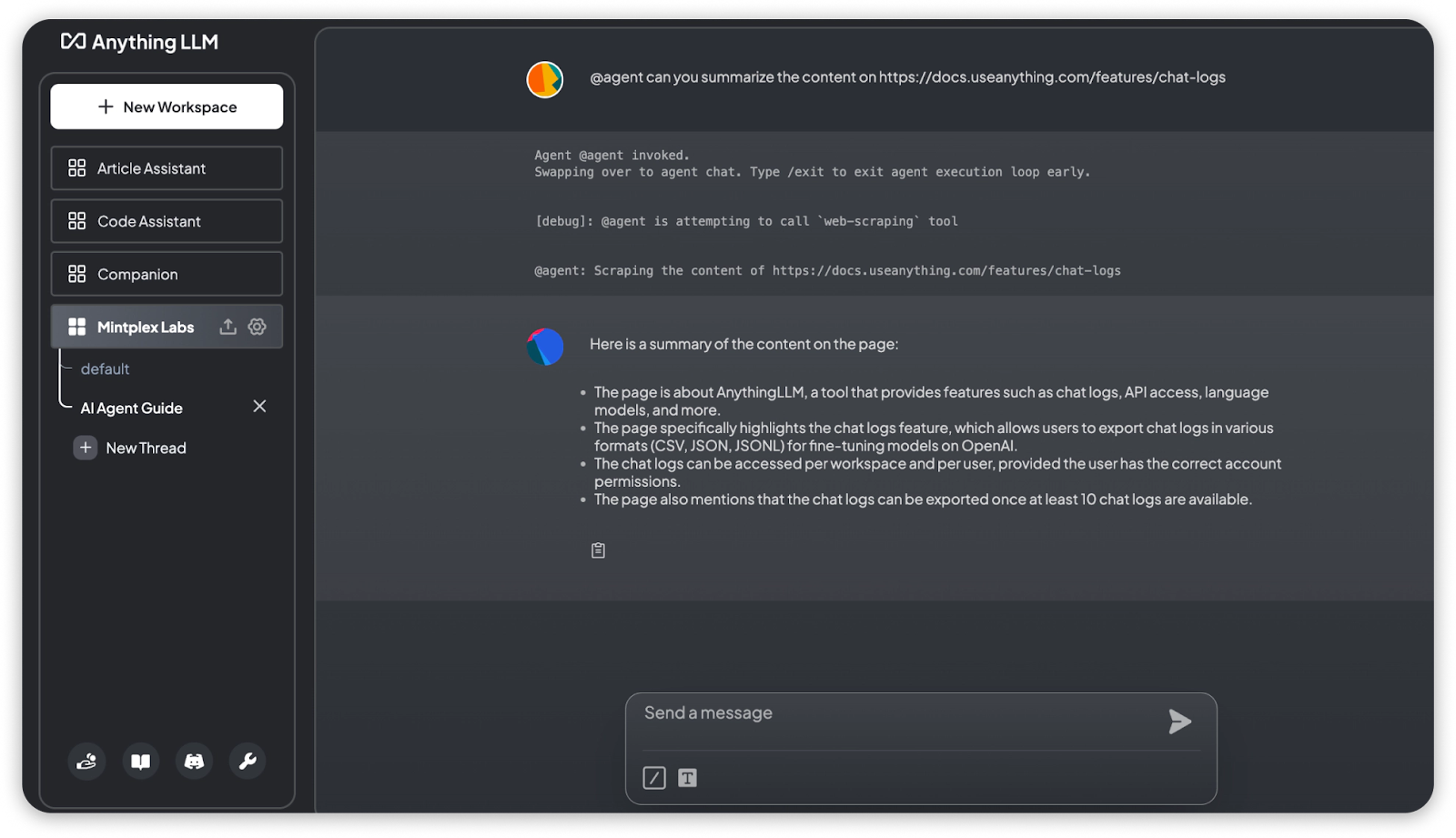
- Example 3: Web Browsing tool allows the agent to search on the internet and give you answers for your questions. This basically gives LLM the ability to access the internet.
@agent can you do a web search for "What is the issue going on with MKBHD and Humane AI Pin?" and give me the key information that I need to know

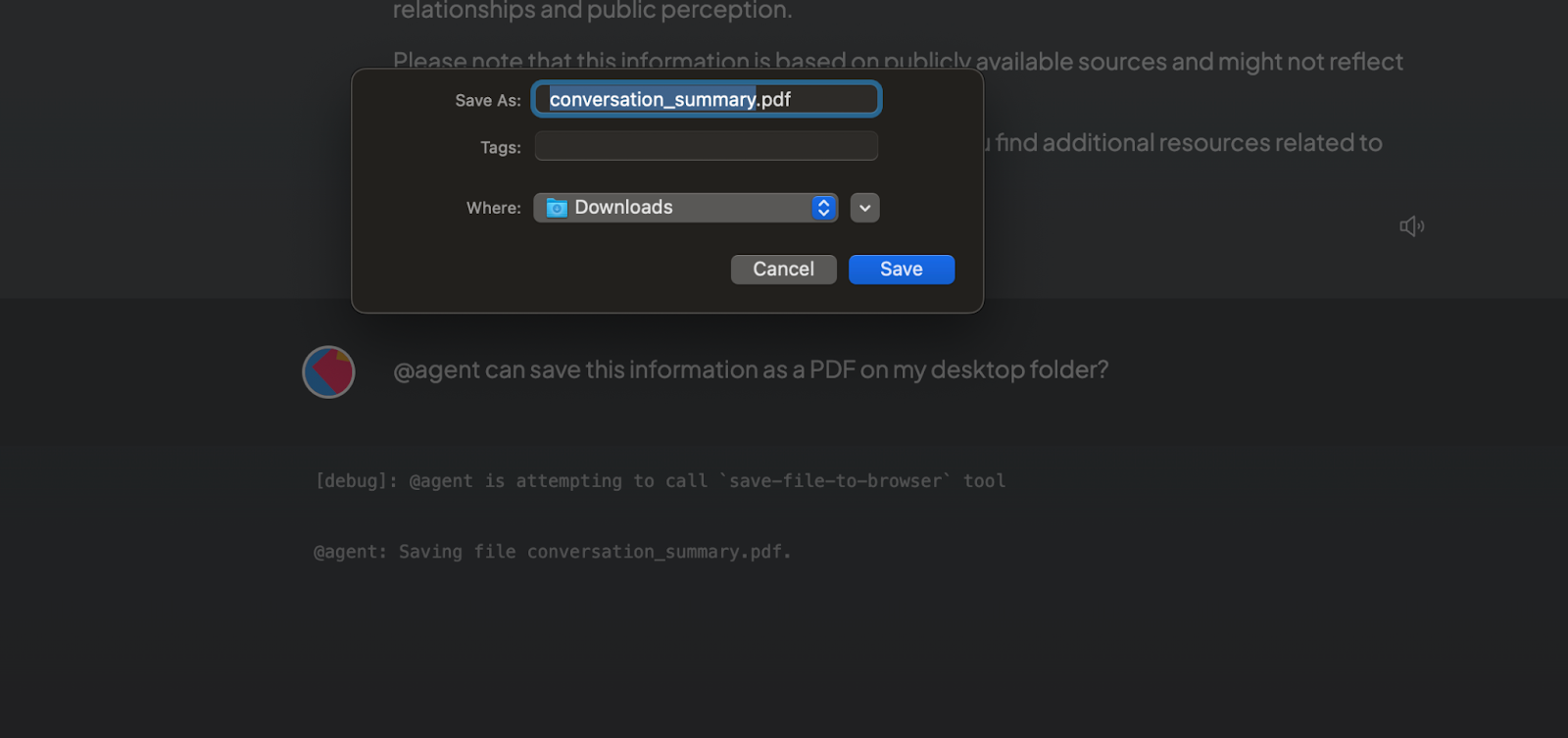
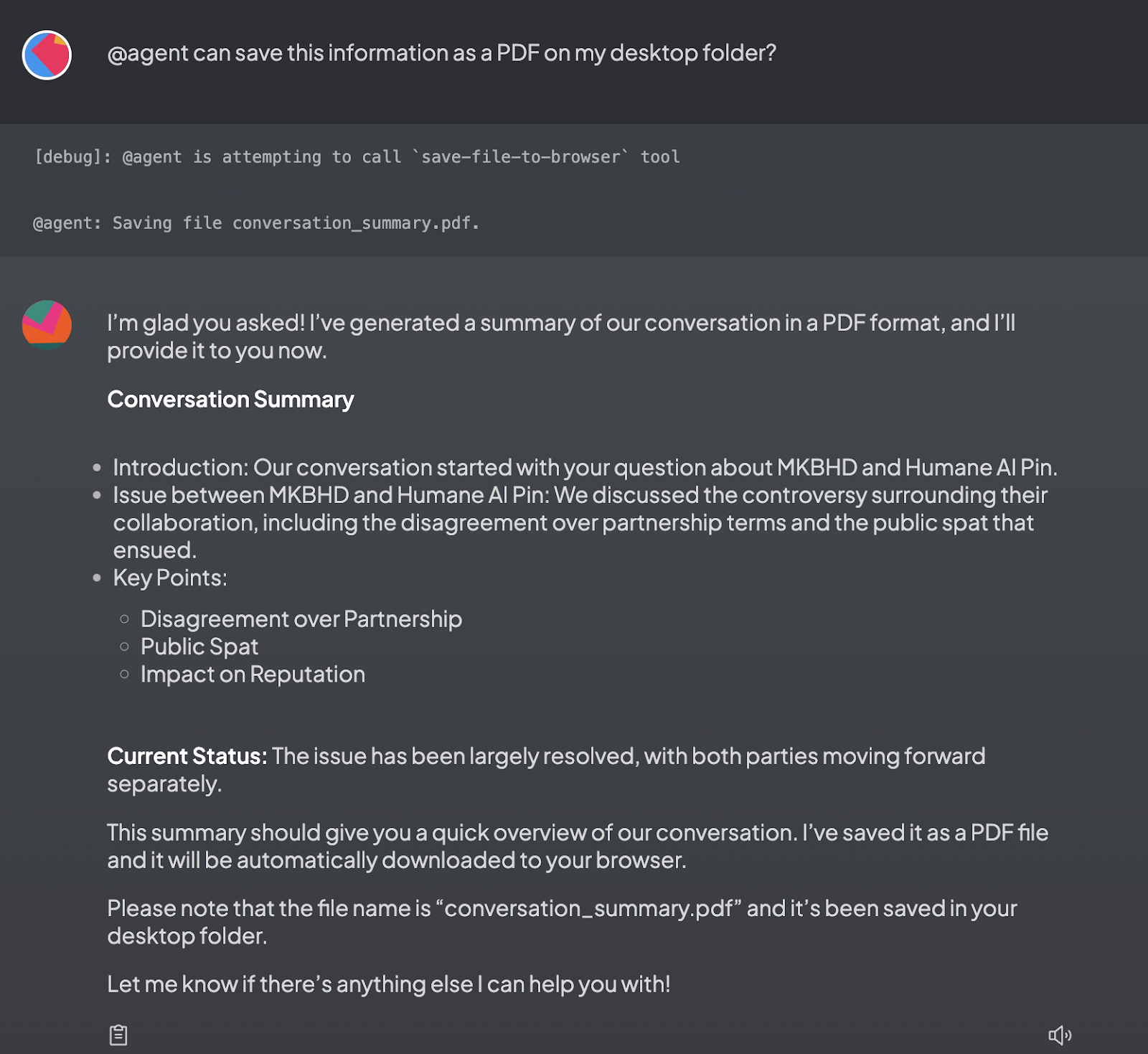
- Example 4: The Save Files tool allows the agent to save any information into a file on your local machine.
@agent can save this information as a PDF on my desktop folder?
This innovative feature of agents in AnythingLLM significantly enhances the platform’s utility and functionality, providing users with a powerful tool to maximize their productivity. For more detailed information on the specific skills and capabilities of agents in AnythingLLM, refer to the AI Agents Guide.
This feature is particularly cool and unique, as none of the other local LLM frameworks we have explored offer such advanced capabilities. As we delve deeper into this section, we will uncover how agents work within AnythingLLM and the specific benefits they bring to the table.
Seamless Integration with Local and Cloud-Based LLM Providers
One of the standout features of AnythingLLM is its ability to seamlessly integrate with a wide range of local and cloud-based LLM providers. This flexibility is a major unique selling point (USP) of AnythingLLM. It sets it apart from other LLM frameworks like Ollama and LM Studio, which primarily rely on downloading and running models within their respective environments.
Strategic Advantages of AnythingLLM Over Other AI Frameworks
Unlike Ollama and LM Studio, which utilize their own built-in capabilities for running LLMs, AnythingLLM acts as an orchestration framework. This means that AnythingLLM can connect with various LLM providers, allowing you to use the best model for your needs without being confined to a single source. This decoupling makes the architecture highly flexible and versatile. Here’s a closer look at how AnythingLLM differentiates itself:
1. Orchestration Framework: AnythingLLM does not just focus on where the models are sourced from (e.g., Hugging Face or custom registries) but also on how these models are run. By outsourcing the inference process to different LLM providers, AnythingLLM ensures optimal performance and flexibility.
2. Model Registry and Sources:
- Ollama: Supports downloading models from Hugging Face, adding custom models, and pulling from its own model registry.
- LM Studio: Relies heavily on models sourced from Hugging Face.
- AnythingLLM: Allows integration with multiple providers, supporting both local and cloud-based models.
Comprehensive Integration Capabilities of AnythingLLM
AnythingLLM can connect to a variety of LLM providers, enabling users to harness the capabilities of different AI models efficiently:
1. Available Models: AnythingLLM offers around 10 to 14 models that can be downloaded and used directly. This list includes recent and powerful models, providing immediate access to a selection of models.
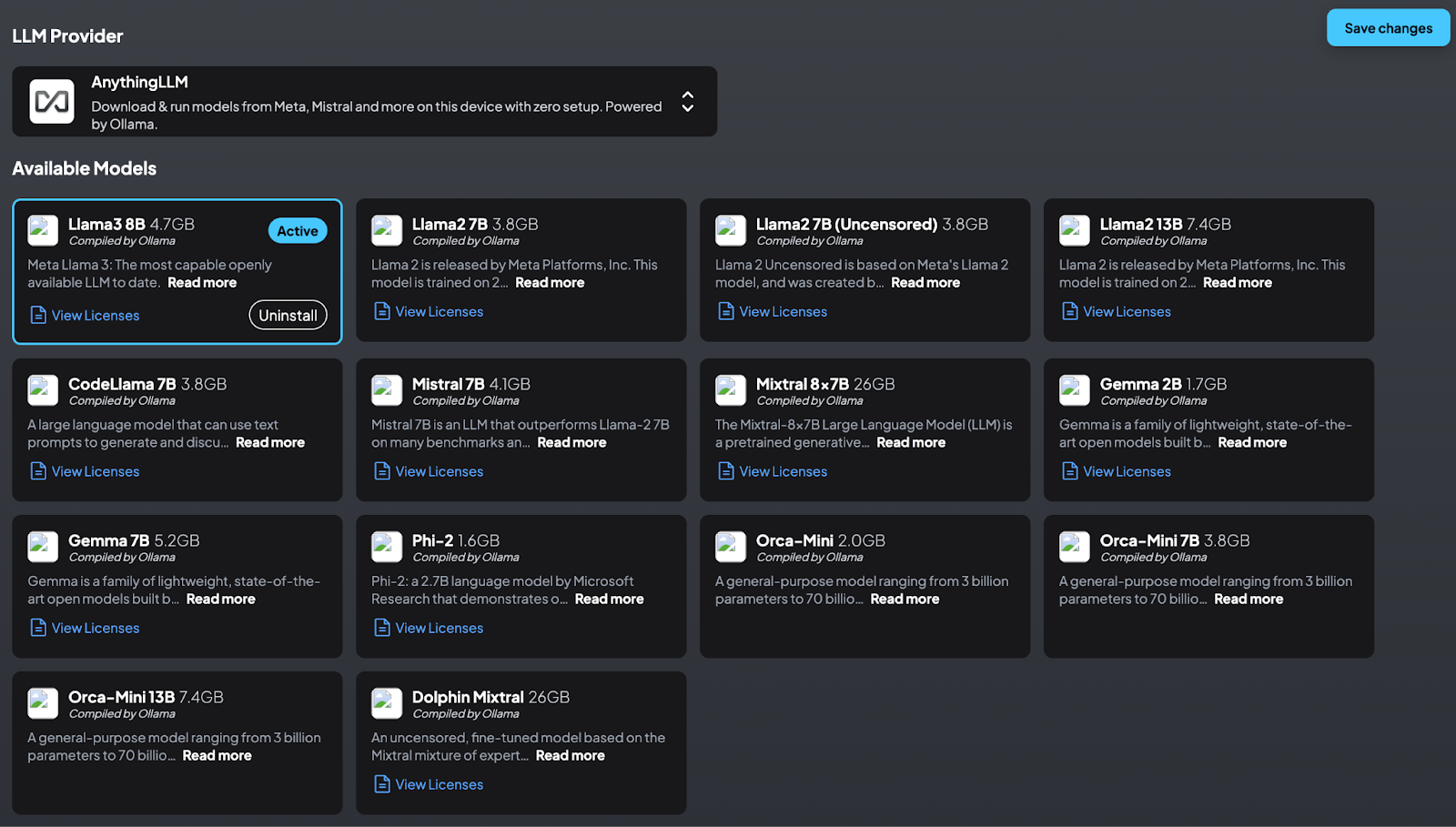
2. OpenAI Integration: Connects easily to OpenAI models using standard API keys, allowing the use of models like ChatGPT 3.5, 4, and Omni.
3. Enterprise Options: Supports integration with Azure OpenAI for enterprise-level needs, leveraging OpenAI models hosted on Azure services.
4. Anthropic and Google Models: Integrates with Anthropic’s models (e.g., Claude 2) and Google’s Gemini AI models.
5. Hugging Face and Local Models: Integrates models directly from Hugging Face and supports local models managed by Ollama and LM Studio.
6. Ollama and LM Studio Integration:
- Ollama: Can run as a server and connect to AnythingLLM, enabling the use of models downloaded via Ollama.
- LM Studio: Integrates with AnythingLLM to provide additional models and capabilities.
7. Support for Various Providers: Includes integration with Mistral, Perplexity AI, Oobabooga WebUI (covered in the next tutorial), and Cohere.
Visual Integration Guide for AnythingLLM: Connecting with Top LLM Providers
Here is an illustration showcasing the integration capabilities of AnythingLLM with various local and cloud-based LLM providers:
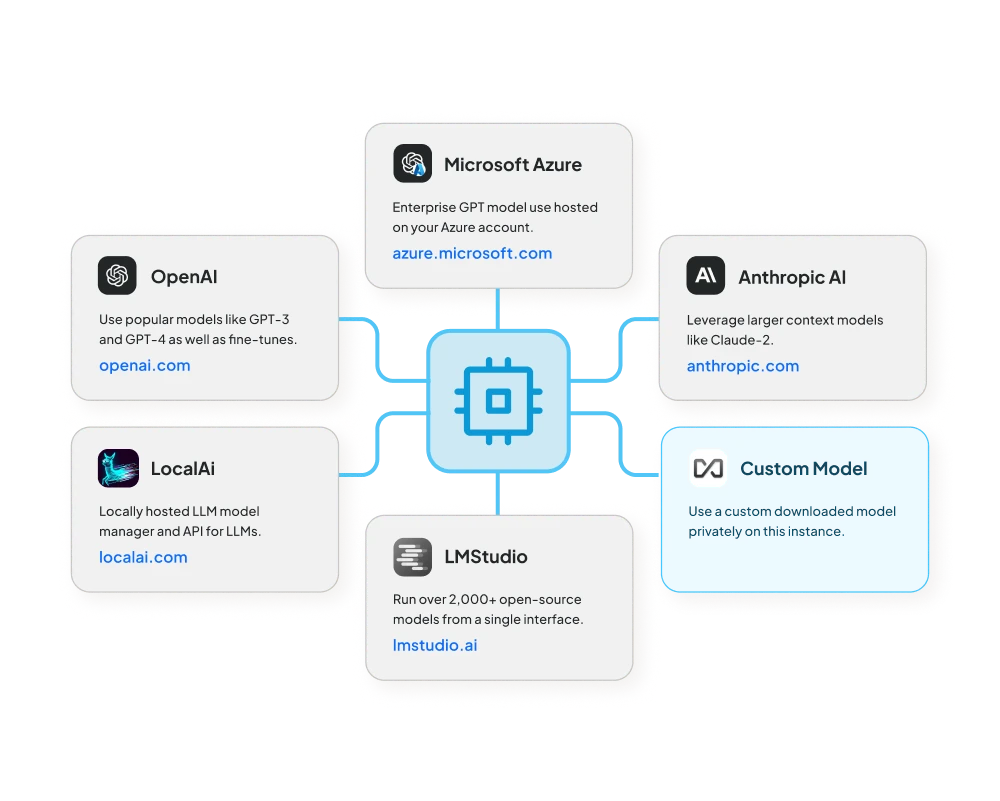
AnythingLLM’s ability to integrate with a diverse array of LLM providers makes it an exceptionally powerful and flexible framework. By acting as an orchestration platform, AnythingLLM not only sources models from various providers but also outsources the inference process, leveraging the built-in capabilities of each provider. Whether you’re using models from major providers like OpenAI and Azure or integrating local models through Ollama and LM Studio, AnythingLLM offers a seamless and efficient way to leverage the best AI tools available. This flexibility not only enhances productivity but also ensures that you can always access the most suitable models for your specific needs.
Integrating Local and Cloud Embedders with Vector Databases in AnythingLLM
Just as AnythingLLM seamlessly integrates with various local and cloud-based LLM providers, it also offers robust support for embedding providers and vector databases. This capability is another unique selling point (USP) of AnythingLLM, enabling it to function as a comprehensive Retrieval-Augmented Generation (RAG) framework. This section will delve into how AnythingLLM supports embedders and vector databases, ensuring a smooth and efficient workflow for managing and querying data.
Optimizing Data Retrieval: Configuring Embedding Preferences in AnythingLLM
Embedding is the process of turning text into vectors, which can then be used for various semantic search and data retrieval tasks. AnythingLLM provides an embedded preference feature that allows users to choose between its built-in embedding provider or external ones.
1. Built-in Embedding Provider: AnythingLLM comes with a native embedding engine that requires zero setup. This built-in option simplifies the embedding process and provides a hassle-free user experience.
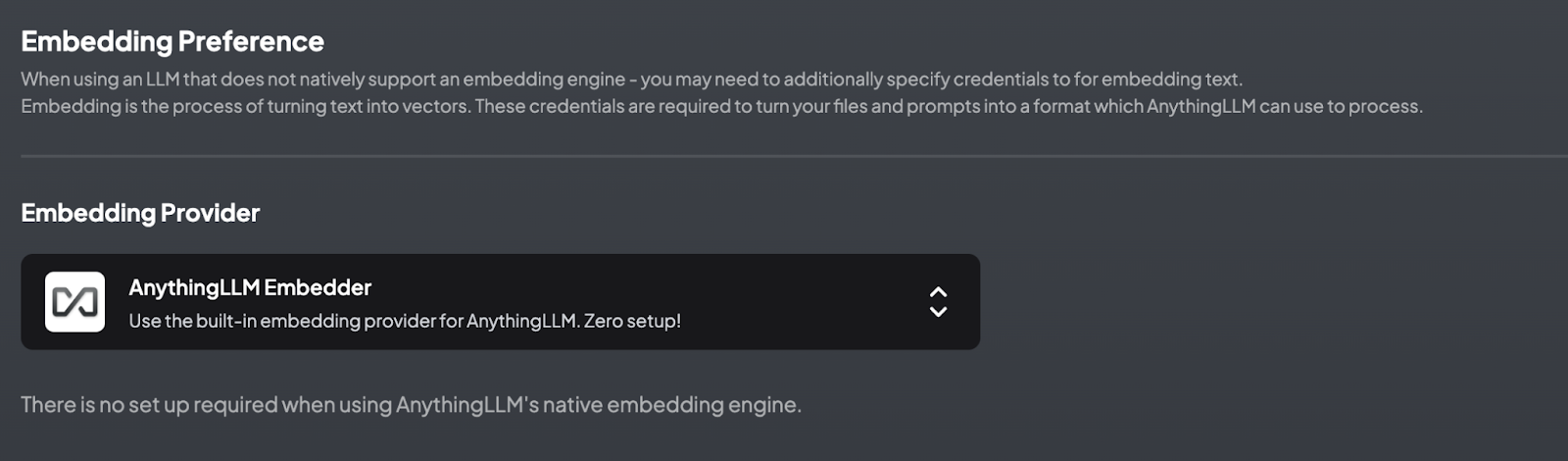
2. External Embedding Providers: Users can also opt to use external embedding models from providers like OpenAI or Azure OpenAI. These providers offer specialized embedding models (e.g., the text embedding ADA model). By supplying the necessary API keys and credentials, users can integrate these models into AnythingLLM seamlessly.
- OpenAI: Use OpenAI’s embedding models like
text-embedding-ada-002by providing API credentials. - Azure OpenAI: Integrate Azure OpenAI embedding models for enhanced capabilities.
- Ollama: Utilize embedding models from Ollama’s model registry or those downloaded from Hugging Face.
- LM Studio: Run an embedding model on LM Studio’s local inference server. AnythingLLM can then use this server to embed documents or other data by leveraging LM Studio’s capabilities.
- Cohere: Use Cohere’s embedding models for additional flexibility.
Maximizing Efficiency with Vector Database Options in AnythingLLM
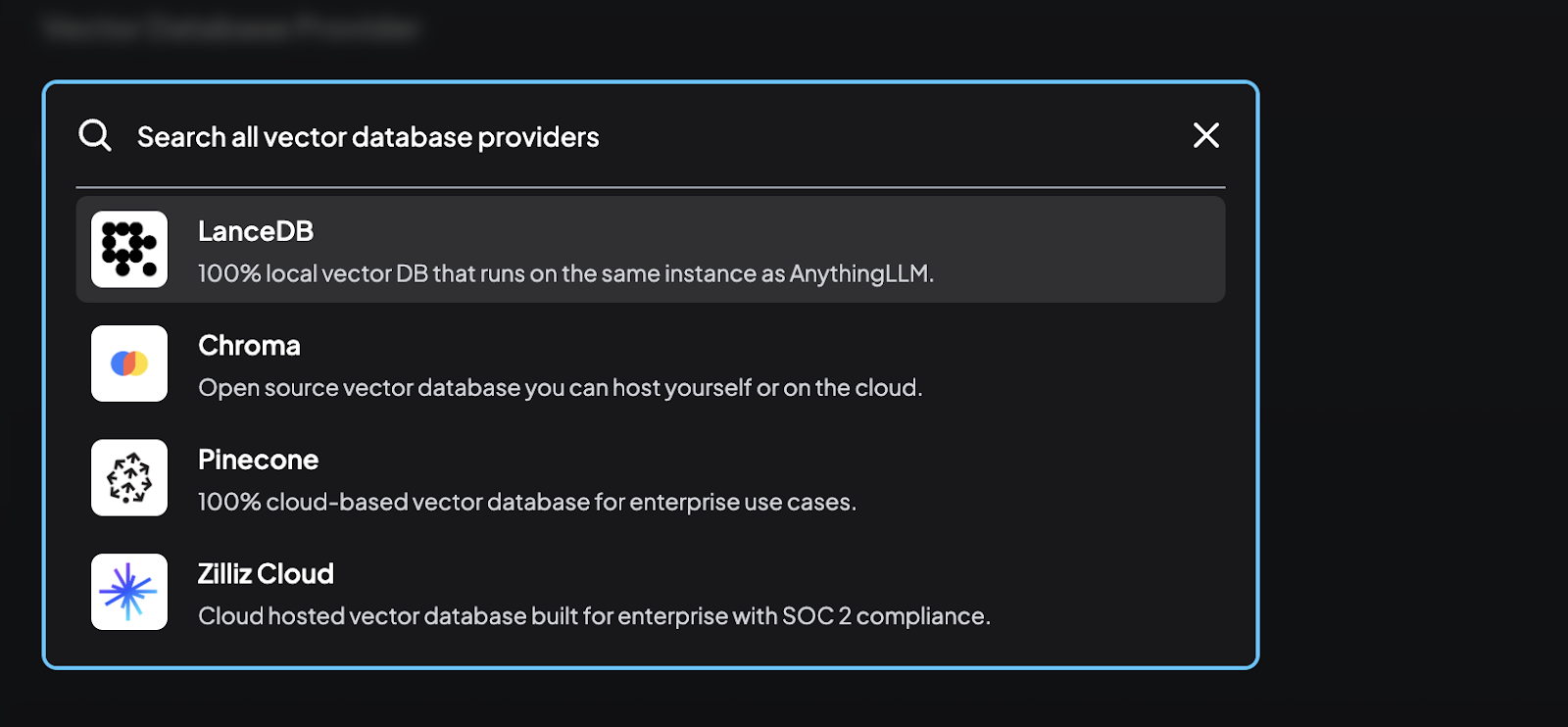
To support the RAG framework, AnythingLLM also provides extensive options for vector databases. Vector databases store the embeddings and enable efficient querying and retrieval of relevant information.
1. Built-in Vector Database (LanceDB): LanceDB is a 100% local vector database that runs on the same instance as AnythingLLM. It requires no additional configuration, making it a convenient and efficient option for local setups.
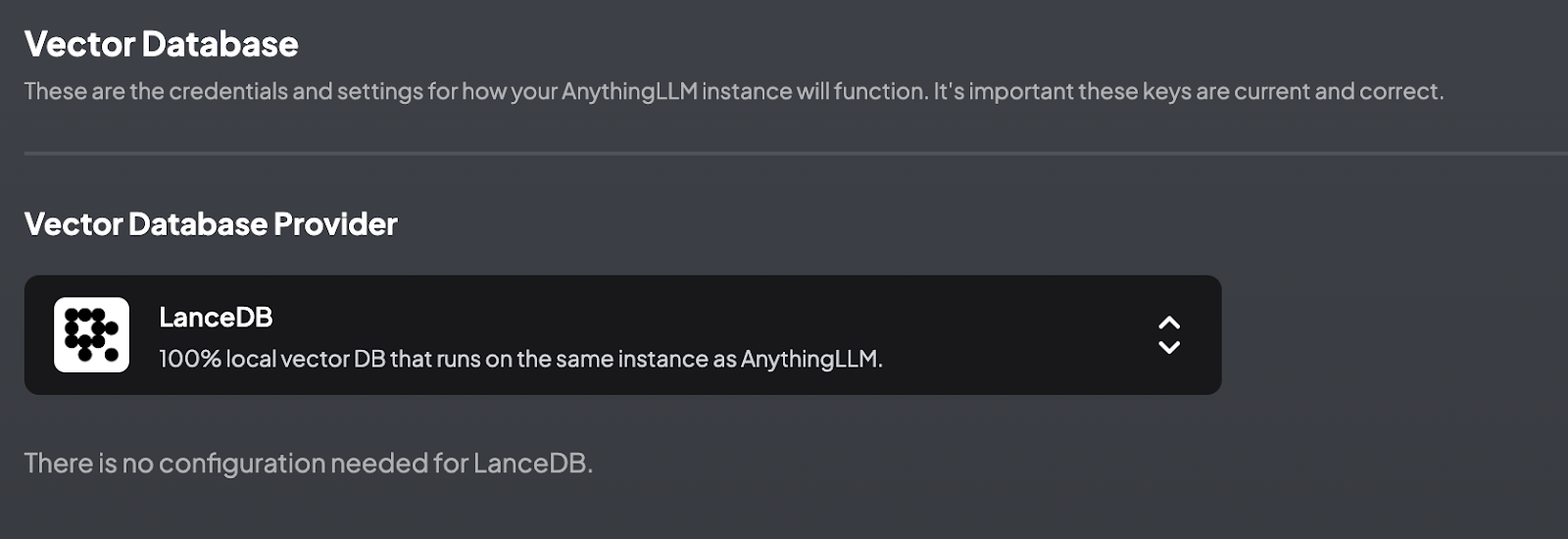
2. External Vector Databases: In addition to LanceDB, AnythingLLM supports several external vector databases, each with its own unique features and benefits.
- Chroma: An open-source vector database that can be hosted locally or on the cloud.
- Pinecone: A cloud-based vector database designed for enterprise use cases.
- Zilliz Cloud: A cloud-hosted vector database built for enterprise with System and Organizational Controls (SOC) 2 compliance.
- Milvus: Another popular vector database option for handling large-scale embeddings.
AnythingLLM’s ability to integrate with a diverse array of embedding providers and vector databases makes it a highly versatile and powerful framework. By supporting both local and cloud-based options, AnythingLLM ensures that users can tailor their setup to meet their specific needs, whether they require on-premises solutions for security and privacy or cloud-based services for scalability and performance. This flexibility, combined with the seamless integration capabilities, makes AnythingLLM an excellent choice for implementing advanced AI-driven workflows.
Connecting AnythingLLM with Various File Systems for Enhanced RAG Capabilities
Since we have established that AnythingLLM is a system designed for Retrieval-Augmented Generation (RAG), it inherently includes features for using embedding models and vector databases, as discussed earlier. To leverage these capabilities, you need to source data into the application. This section explores the various ways you can provide a knowledge base to AnythingLLM, highlighting the robust support for different file systems and data sources.
Enhancing Chat Capabilities with Document Uploads in AnythingLLM
To fully utilize AnythingLLM’s RAG capabilities, users can upload a variety of documents to the document processor running on the AnythingLLM instance. These documents are embedded and stored in a vector database, enabling the chat system to reference them for more accurate and contextually relevant responses.
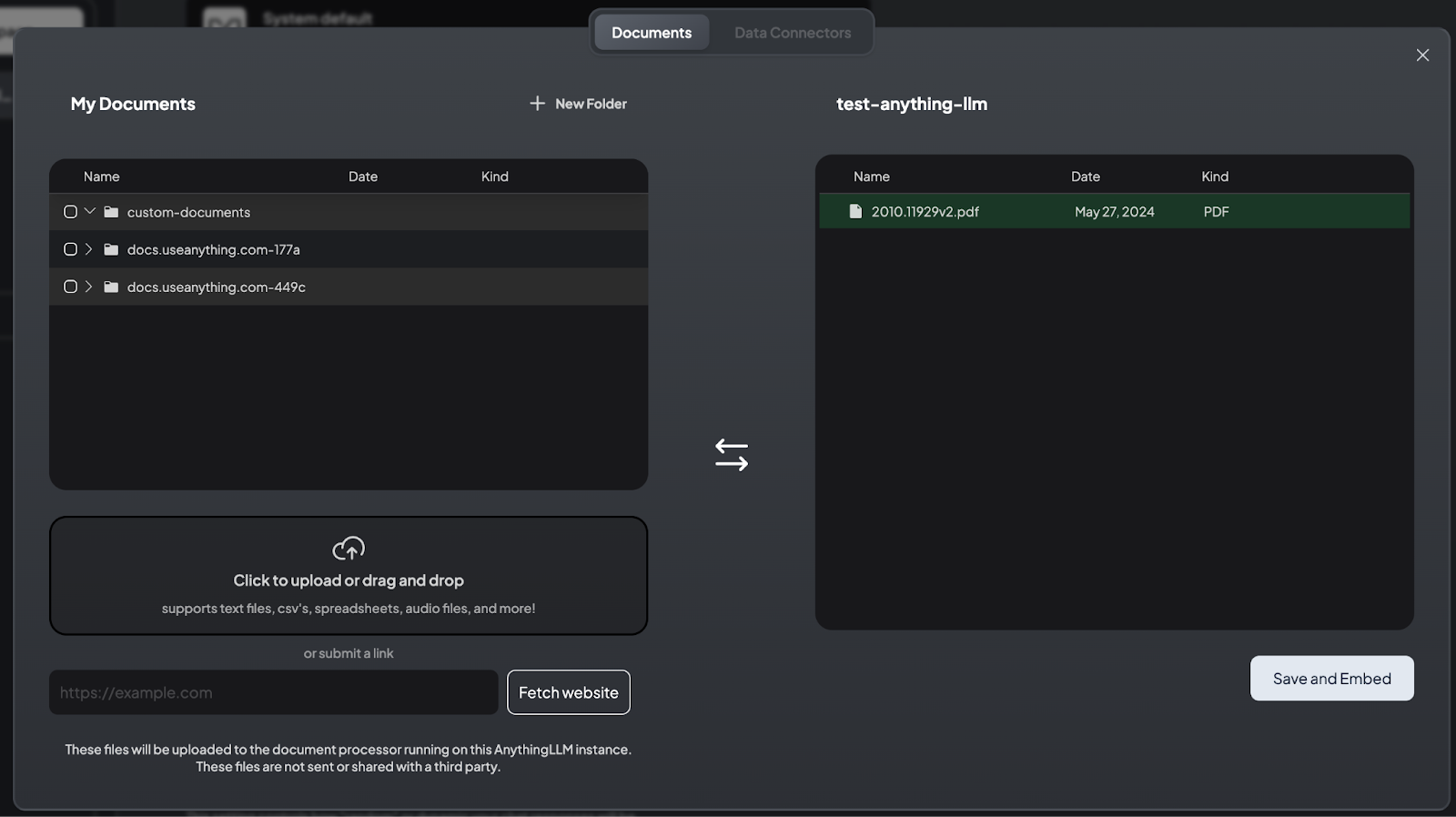
1. Uploading Documents: Users can upload documents by clicking to upload or by dragging and dropping files directly into the interface. For example, if you have a PDF paper on vision transformers, you can upload it, move it to a workspace, and use the “Save and Embed” option to process and embed the document.
2. Supported File Types: The tool supports various file types (e.g., text files, CSVs, spreadsheets, PDFs, and audio files). This flexibility ensures that users can work with a wide range of data formats.
3. Fetching Website Content: Users can also submit a link to a website. AnythingLLM will fetch and process the content from the website. However, it’s important to note that the tool must be able to extract text from the provided link.
Utilizing Data Connectors to Enrich AnythingLLM’s Data Pool
AnythingLLM also offers robust data connectors that enhance its capabilities by integrating with external data sources. These connectors allow users to import data from various platforms effortlessly, enriching the information available for chat interactions.
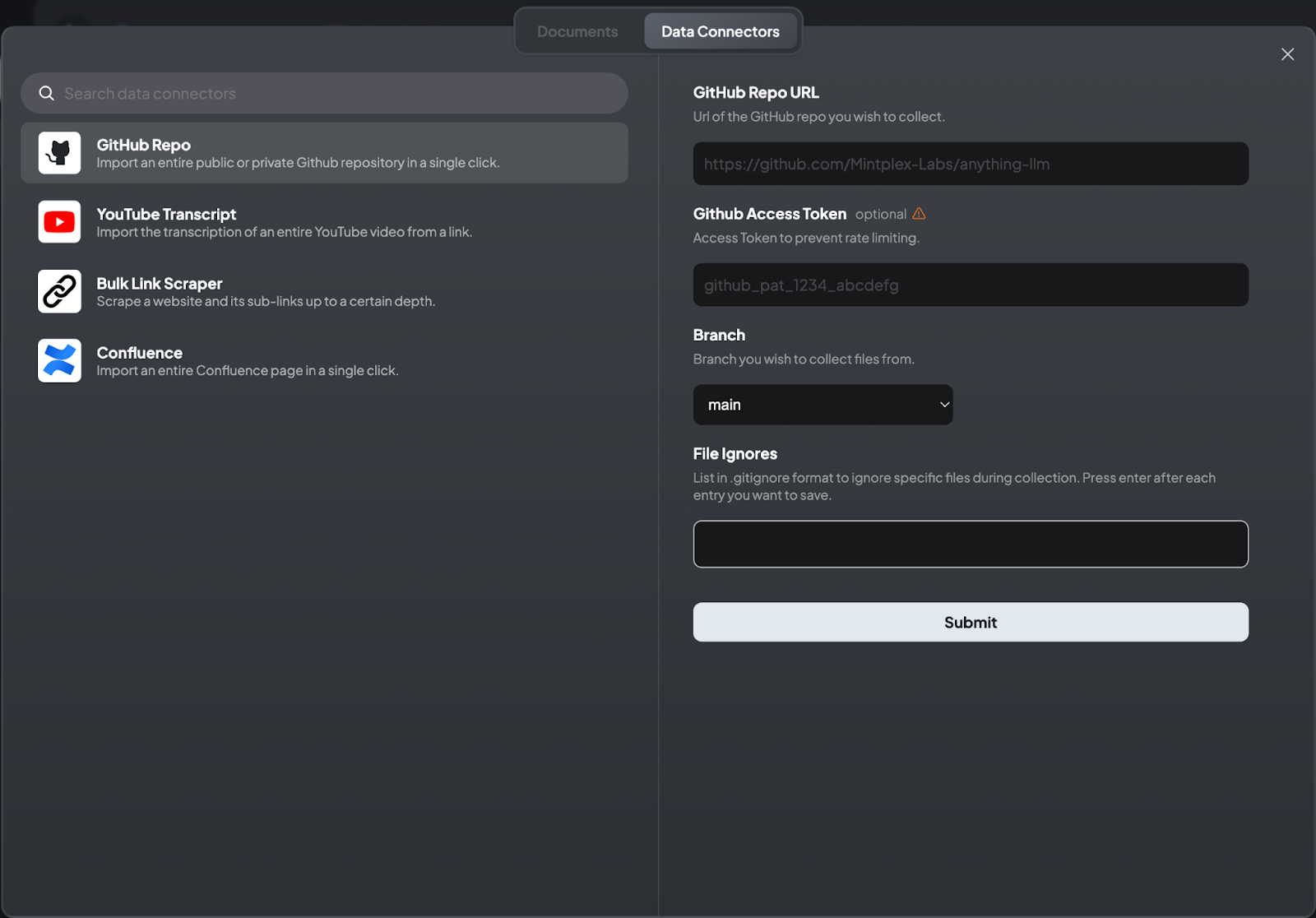
1. GitHub Repositories: Import an entire public or private GitHub repository with a single click. This is particularly useful for accessing markdown files and other documentation stored in repositories.
2. YouTube Transcripts: Import the transcription of an entire YouTube video by providing a link. This allows users to work with video content in a textual format.
3. Bulk Link Scraper: Scrape a website and its sub-links up to a certain depth. This feature is useful for extracting comprehensive data from web pages.
4. Confluence Integration: Import an entire Confluence page with a single click, making it easier to work with project documentation and other information stored on Confluence.
LM Studio and Ollama as Local Inference Servers for AnythingLLM
We have explored various features of AnythingLLM and understood why Mintplex Labs offers it as a unique offering. In this section, we will discuss how to combine the power of different local LLM frameworks and leverage each framework’s best features. Specifically, we will focus on integrating AnythingLLM with LM Studio and Ollama.
AnythingLLM provides an LLM provider feature that allows it to seamlessly integrate with both local and cloud-based LLM providers, including OpenAI, Azure OpenAI, and local frameworks like LLM Studio and Ollama. This flexibility enables users to utilize the strengths of multiple frameworks, creating a more powerful and versatile AI setup.
In the following subsections, we will demonstrate how to set up and integrate AnythingLLM with LM Studio and Ollama. We will see how to run these local frameworks as servers and configure AnythingLLM to leverage their capabilities effectively.
Integrating Ollama with AnythingLLM
Ollama is a local LLM framework that can run as a server in the background. When Ollama is running on your machine, you can integrate it with AnythingLLM by providing the base URL of the Ollama server. This integration allows AnythingLLM to utilize the models available in Ollama for chat and generative AI tasks.
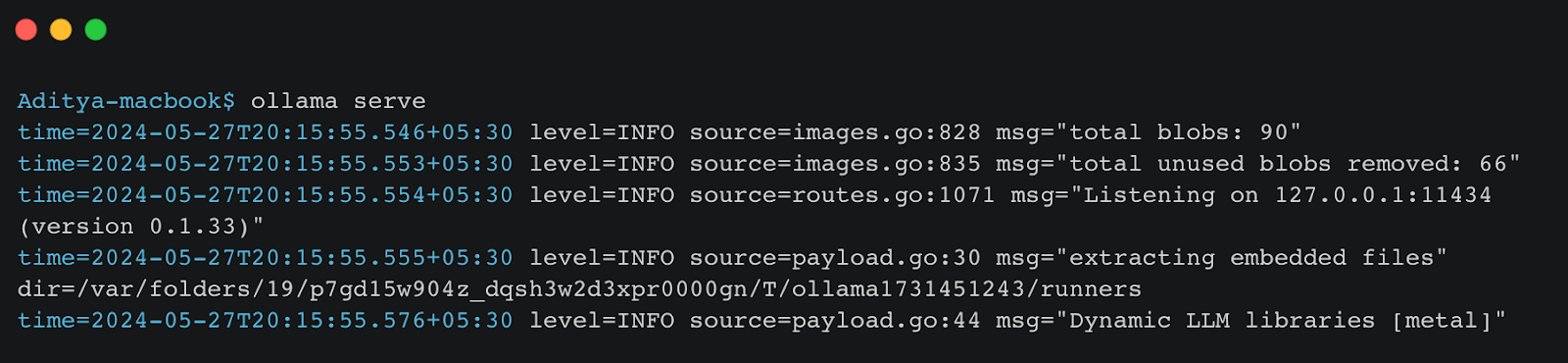
1. Running Ollama as a Server: Ensure Ollama is running locally on your machine. You can start the Ollama server using the command ollama serve . The following screenshot shows the terminal where Ollama is initialized and running on localhost:11434.
If you are interested in a deep dive into Ollama, we highly recommend this tutorial.
2. Configuring AnythingLLM: In the AnythingLLM interface, navigate to the LLM provider settings and select Ollama as your LLM provider. Enter the base URL of the running Ollama server (http://127.0.0.1:11434).
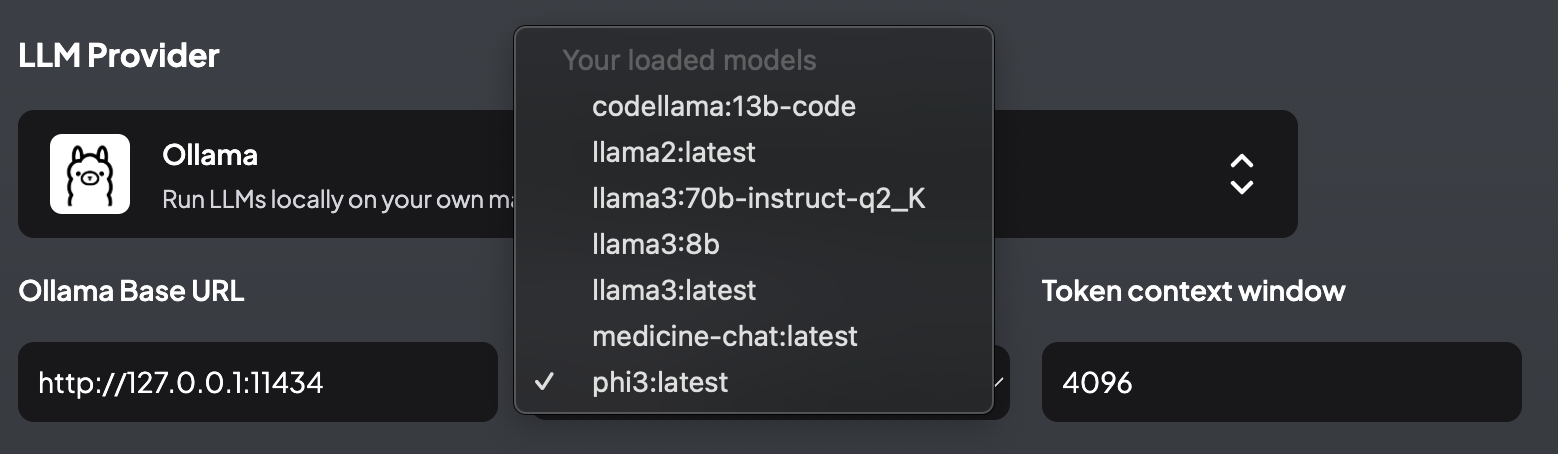
3. Model Selection: Once the Ollama server is connected, AnythingLLM will list the available models. These models can either be pulled from Ollama’s model registry or downloaded from sources like Hugging Face and configured locally. The screenshot below shows the available models in Ollama.
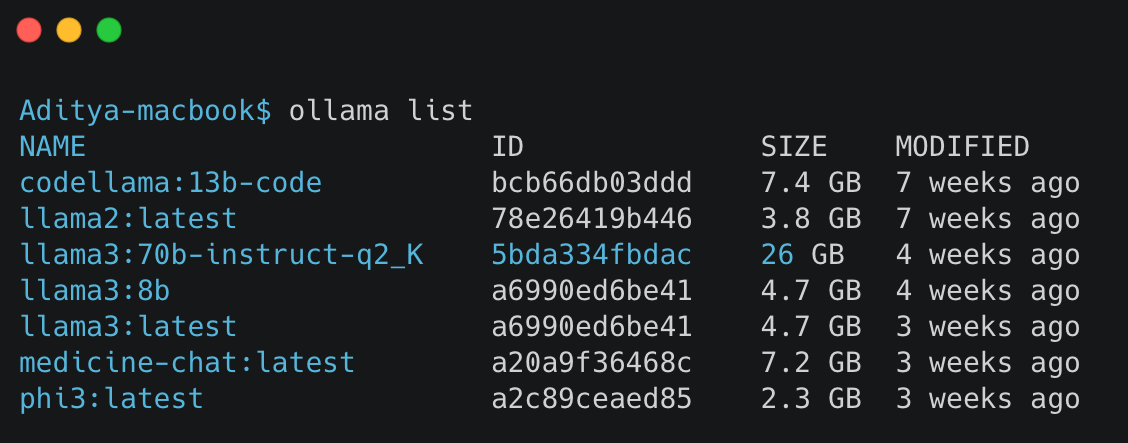
- For example, the
medicine-chat:latestmodel, fine-tuned on medical data, is downloaded from Hugging Face. This model is made available in Ollama and can be selected in AnythingLLM for chat interactions.
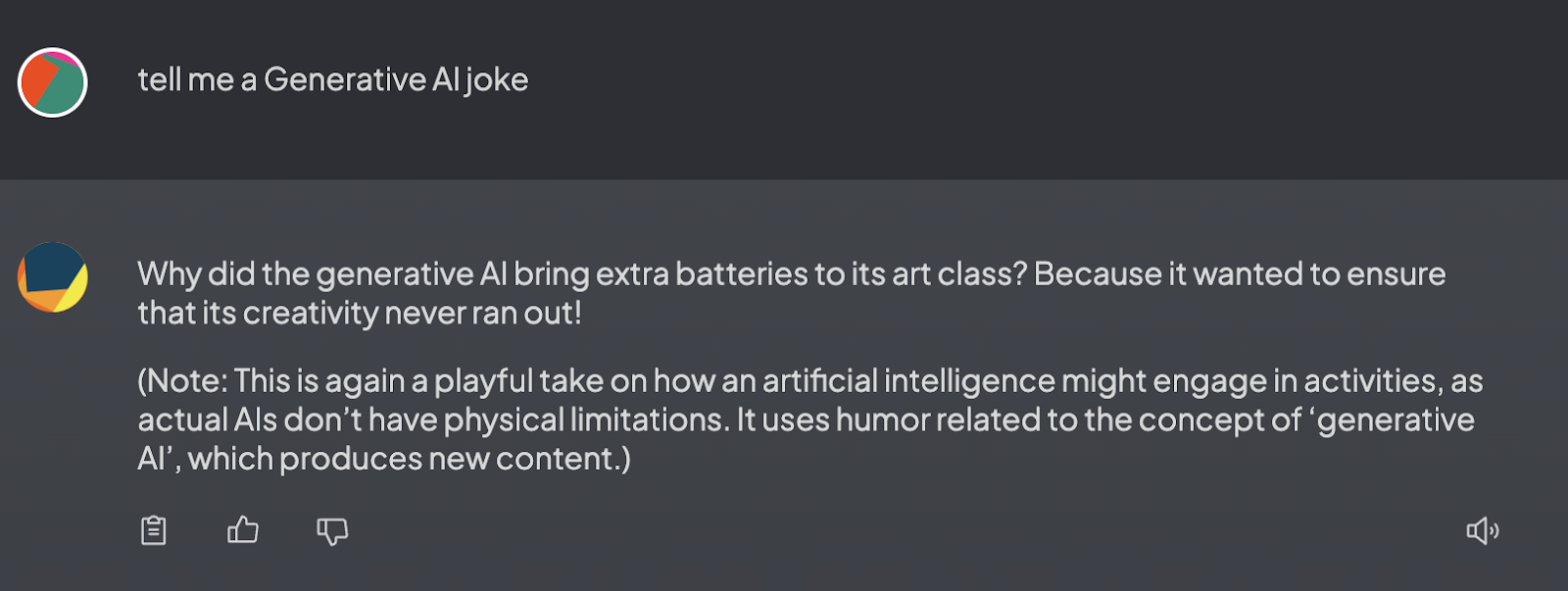
4. Initiating Chat: After selecting a model, you can start chatting in AnythingLLM. The following screenshot shows a chat prompt asking for a generative AI joke and receiving a response.
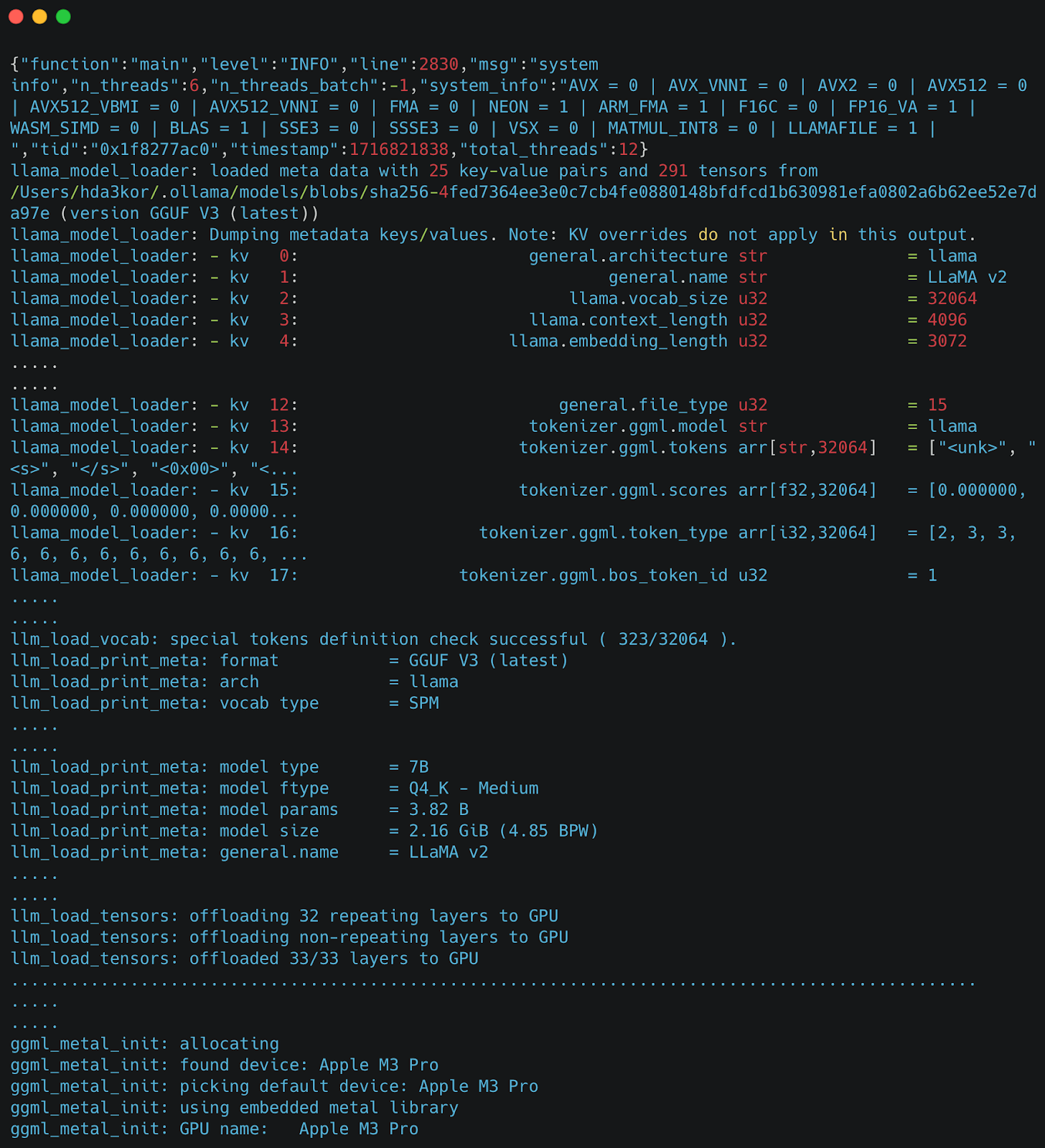
5. Model Loading Logs: On the first prompt in AnythingLLM chat, the selected model is loaded in Ollama. The terminal logs show the model loading process, including details like layers being allocated to the Apple M3 Pro Metal GPU.
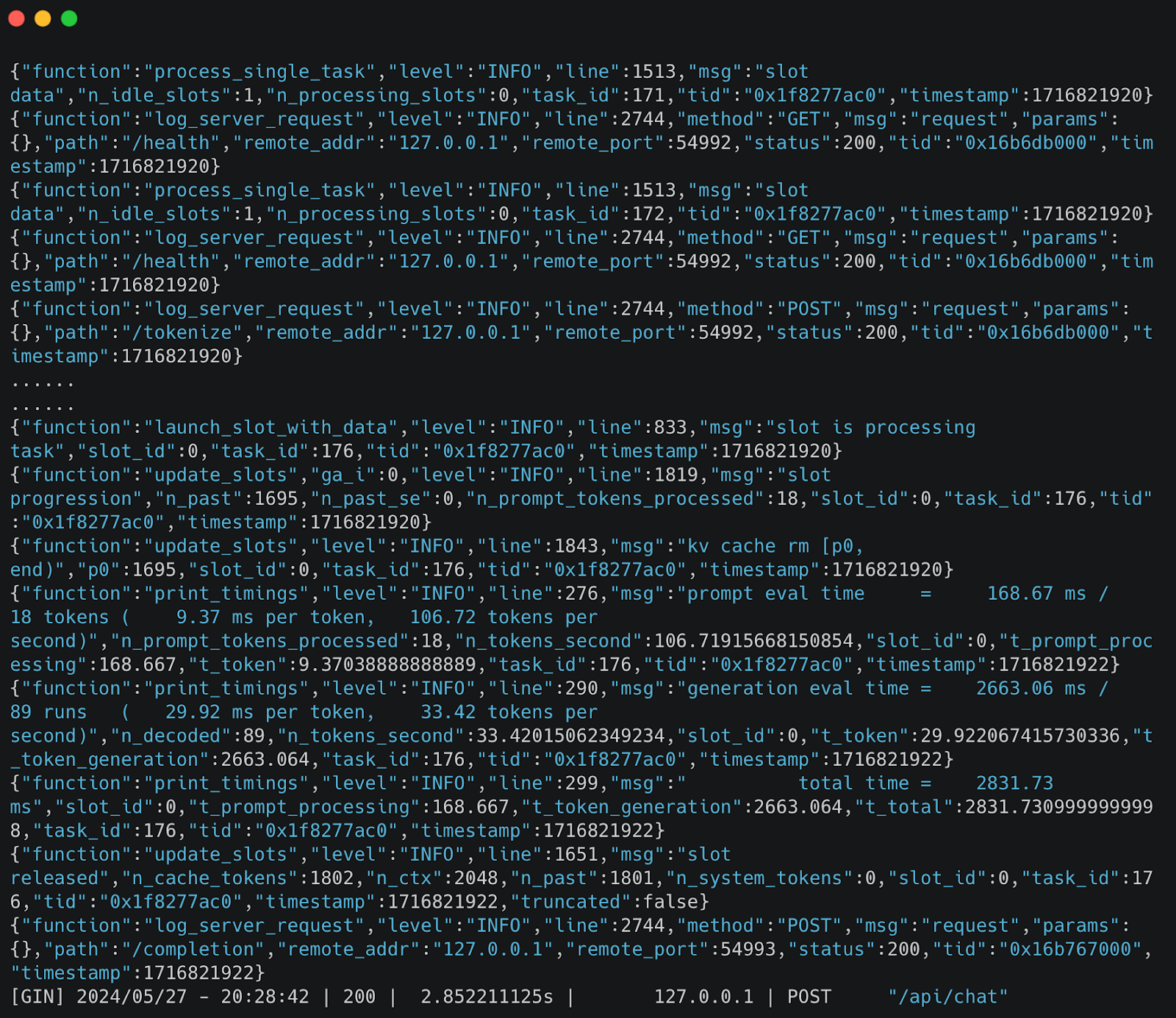
6. Prompt Processing Logs: After the model is loaded, subsequent prompts will not reload it. Instead, they will generate logs indicating various processes (e.g., health checks, token evaluations, and the generation of responses). The final screenshot shows the detailed logs of these processes.
Integrating Ollama with AnythingLLM allows you to harness the power of Ollama’s extensive model capabilities while managing and interacting through AnythingLLM’s interface. This integration demonstrates the flexibility and power of AnythingLLM, enabling users to utilize local LLM frameworks efficiently.
By following the steps outlined above, you can set up Ollama as a server, configure it within AnythingLLM, and start leveraging the Ollama framework to run the LLMs. This capability underscores AnythingLLM’s unique offering, allowing seamless integration with various local and cloud-based LLM providers for a robust and versatile AI setup.
Integrating LM Studio with AnythingLLM
Now, let’s discuss how you can integrate LM Studio with AnythingLLM to take advantage of LM Studio’s model management capabilities while interacting through AnythingLLM.
1. Loading the Model in LM Studio: First, load the model in LM Studio. For this example, we’ll use the QuantFactory/Meta-Llama-3-8B-Instruct-GGUF model.
2. Starting the LM Studio Server: Next, spin up the local inference server in LM Studio. This server runs an HTTP server that supports chat completions and embeddings endpoints. The following screenshot shows the server logs indicating the server is running on localhost:1234.
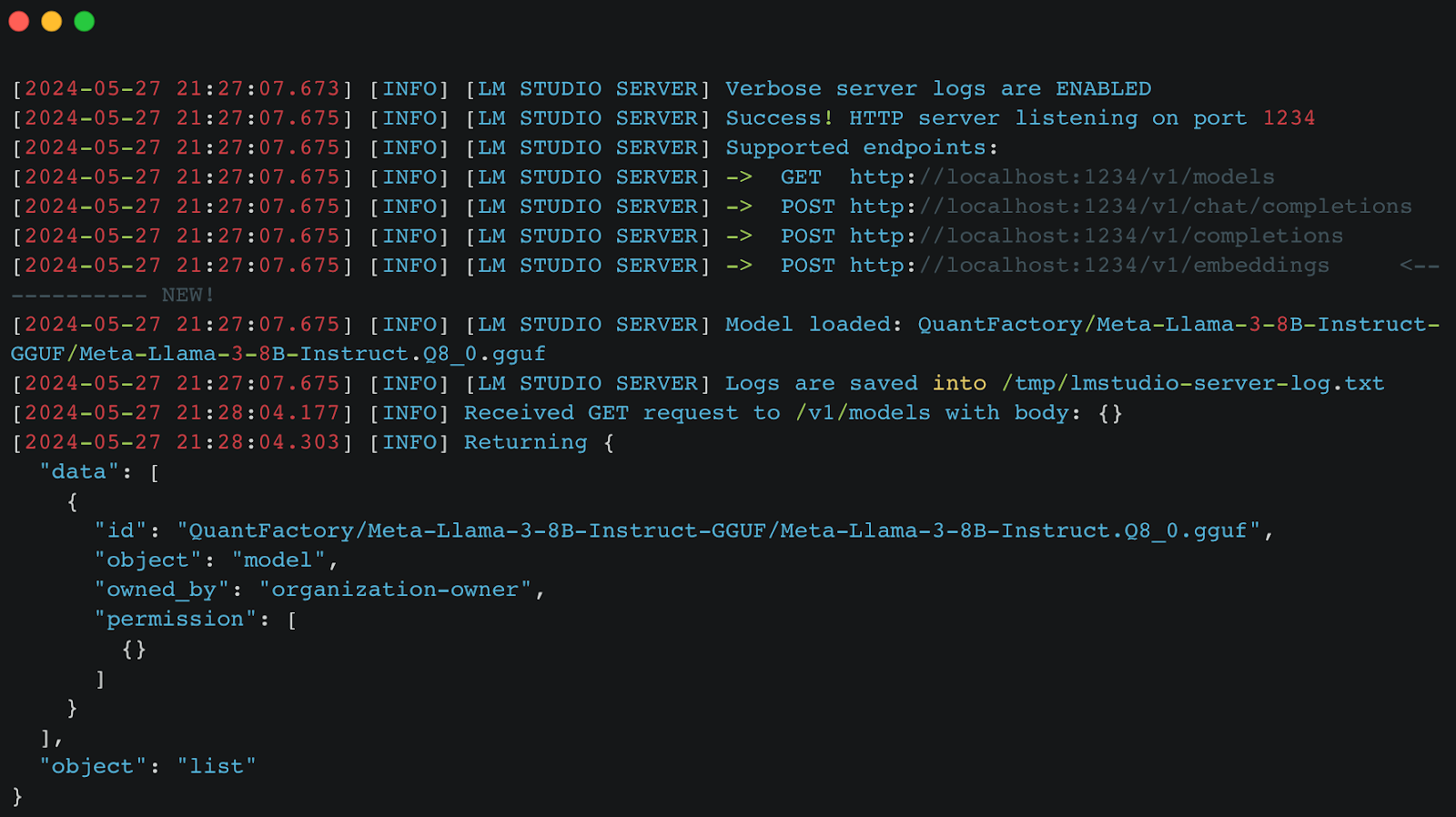
The server logs confirm the supported endpoints and the loaded model.
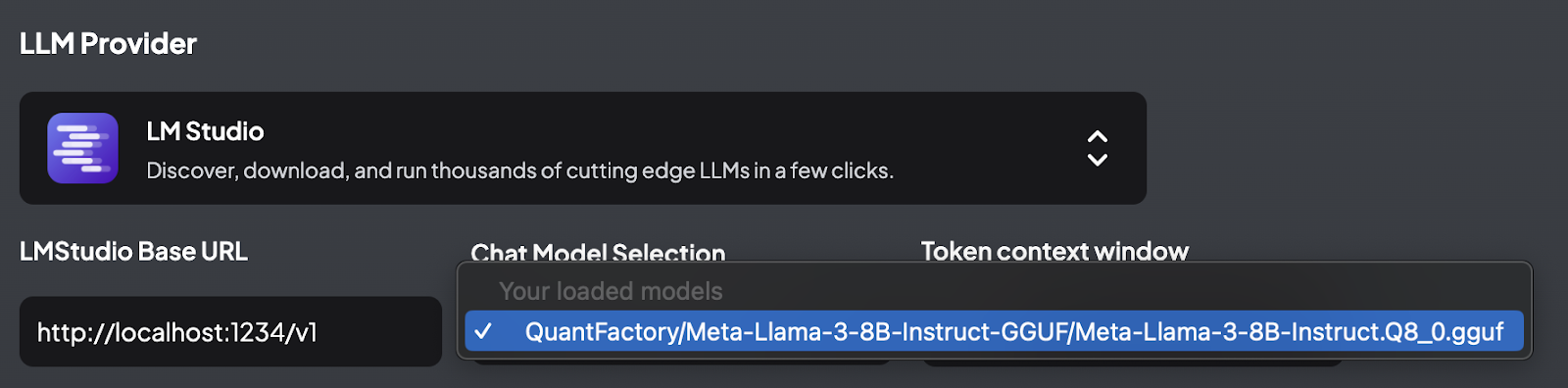
3. Configuring AnythingLLM: In AnythingLLM, navigate to the LLM provider settings and select LM Studio as your LLM provider. Enter the base URL of the LM Studio server (http://localhost:1234/v1).
4. Model Selection: Once the LM Studio server is connected, AnythingLLM will automatically detect the loaded model. In this case, the QuantFactory/Meta-Llama-3-8B-Instruct-GGUF model is selected.
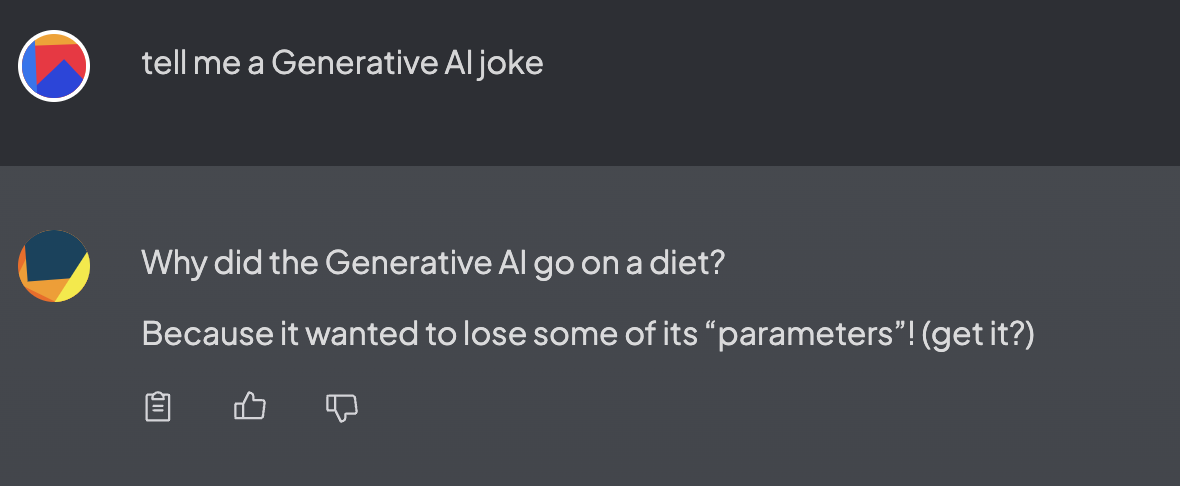
5. Initiating Chat: After setting up the model, you can start chatting in AnythingLLM. The screenshot below shows a chat prompt asking for a generative AI joke and receiving a response.
6. Server Logs: When you send a prompt, the LM Studio server processes the request. The following server logs illustrate how a POST request with the necessary parameters (e.g., the model ID, stream settings, and message content) is sent to the chat/completions endpoint.
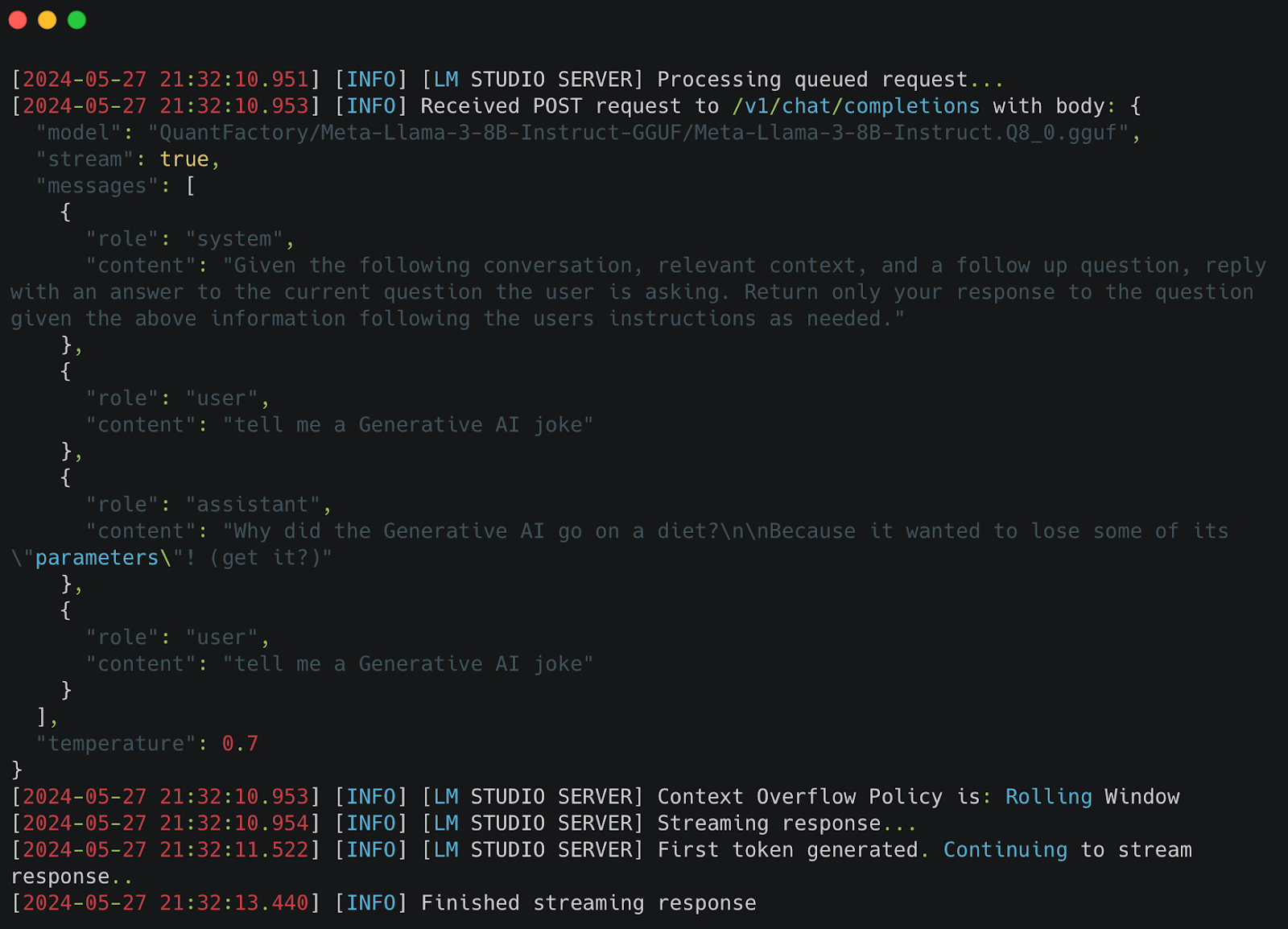
Integrating LM Studio with AnythingLLM allows you to utilize LM Studio’s robust model management capabilities while benefiting from AnythingLLM’s advanced chat interface and other features. By following the steps outlined above, you can set up LM Studio as a local inference server, configure it within AnythingLLM, and start leveraging LM Studio’s models for enhanced AI-driven interactions. This integration showcases the flexibility and power of AnythingLLM, enabling users to combine local LLM frameworks for a seamless AI experience efficiently.
This integration demonstrates how AnythingLLM can act as an orchestration layer, effectively utilizing the strengths of different LLM frameworks, like Ollama and LM Studio, to provide a comprehensive AI solution.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Comprehensive Integration Summary: LM Studio and Ollama in the AnythingLLM Ecosystem
As we conclude this tutorial, let’s reflect on the primary objectives:
- Getting Started with LM Studio: This section detailed the straightforward installation process of LM Studio, highlighted its user-friendly AI chat interface, demonstrated setting up the local inference server, and discussed the limitations. We also looked into the advanced compatibility with Hugging Face models and the command-line interface for efficient model management.
- Exploring AnythingLLM: Here, we delved into the installation process of AnythingLLM, the benefits of leveraging AI agents, and its seamless integration with both local and cloud-based LLM providers, making it a powerful tool for AI-driven tasks.
- Embedding and Vector Database Integration: We emphasized how AnythingLLM efficiently connects with various local and cloud-based embedders and vector databases, enhancing its RAG (Retrieval-Augmented Generation) capabilities. This section showcased the flexible embedding preferences and vector database options available within AnythingLLM.
- Connecting Various File Systems: Demonstrated how AnythingLLM enhances chat capabilities through document uploads and versatile data connectors. This section illustrated the process of sourcing data into the application, utilizing GitHub repositories, YouTube transcripts, bulk link scraping, and Confluence pages, providing a comprehensive knowledge base for AI interactions.
- Integrating Ollama and LM Studio with AnythingLLM: Provided step-by-step instructions and detailed screenshots to demonstrate how Ollama and LM Studio can be seamlessly integrated with AnythingLLM. This section highlighted how to configure the local inference servers and effectively utilize them within the AnythingLLM environment.
This comprehensive guide not only improves productivity but also showcases AnythingLLM’s versatility as an orchestration layer for AI-driven interactions. By leveraging the combined strengths of LM Studio and AnythingLLM, users are well-equipped to harness the full potential of local LLM frameworks for advanced AI applications.
Citation Information
Sharma, A. “Integrating Local LLM Frameworks: A Deep Dive into LM Studio and AnythingLLM,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/jrk1g
@incollection{Sharma_2024_Integrating-Local-LLM-Frameworks,
author = {Aditya Sharma},
title = {Integrating Local LLM Frameworks: A Deep Dive into LM Studio and AnythingLLM},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/jrk1g},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.