
Table of Contents
Automatic Differentiation Part 1: Understanding the Math
In this tutorial, you will learn the math behind automatic differentiation needed for backpropagation.

This lesson is the 1st of a 2-part series on Autodiff 101 — Understanding Automatic Differentiation from Scratch:
- Automatic Differentiation Part 1: Understanding the Math (this tutorial)
- Automatic Differentiation Part 2: Implementation Using Micrograd
To learn about automatic differentiation, just keep reading.
Automatic Differentiation Part 1: Understanding the Math
Imagine you are trekking down a hill. It is dark, and there are a lot of bumps and turns. You have no way of knowing how to reach the center. Now imagine every time you progress, you have to pause, take out the topological map of the hill and calculate your direction and speed for the next set. Sounds painfully less fun, right?
If you have been a reader of our tutorials, you would know what that analogy refers to. The hill is your loss landscape, the topological map is the set of rules for multivariate calculus, and you are the parameters of the neural network. The objective is to reach the global minimum.
And that brings us to the question:
Why do we use a Deep Learning Framework today?
The first thing that pops into the mind is automatic differentiation. We write the forward pass, and that is it; no need to worry about the backward pass. Every operator is automatically differentiated and is waiting to be used in an optimization algorithm (like stochastic gradient descent).
Today in this tutorial, we will walk through the valleys of automatic differentiation.
Introduction
In this section, we will lay out the foundation necessary for understanding autodiff.
Jacobian
Let’s consider a function  .
.  is a multivariate function that simultaneously depends on multiple variables. Here the multiple variables can be
is a multivariate function that simultaneously depends on multiple variables. Here the multiple variables can be  . The output of the function is a scalar value. This can be considered as a neural network that takes an image and outputs the probability of a dog’s presence in the image.
. The output of the function is a scalar value. This can be considered as a neural network that takes an image and outputs the probability of a dog’s presence in the image.
Note: Let us recall that in a neural network, we compute gradients with respect to the parameters (weights and biases) and not the inputs (the image). Thus the domain of the function is the parameters and not the inputs, which helps keep the gradient computation accessible. We need to now think of everything we do in this tutorial from the perspective of making it simple and efficient to obtain the gradients with respect to the weights and biases (parameters). This is illustrated in Figure 1.
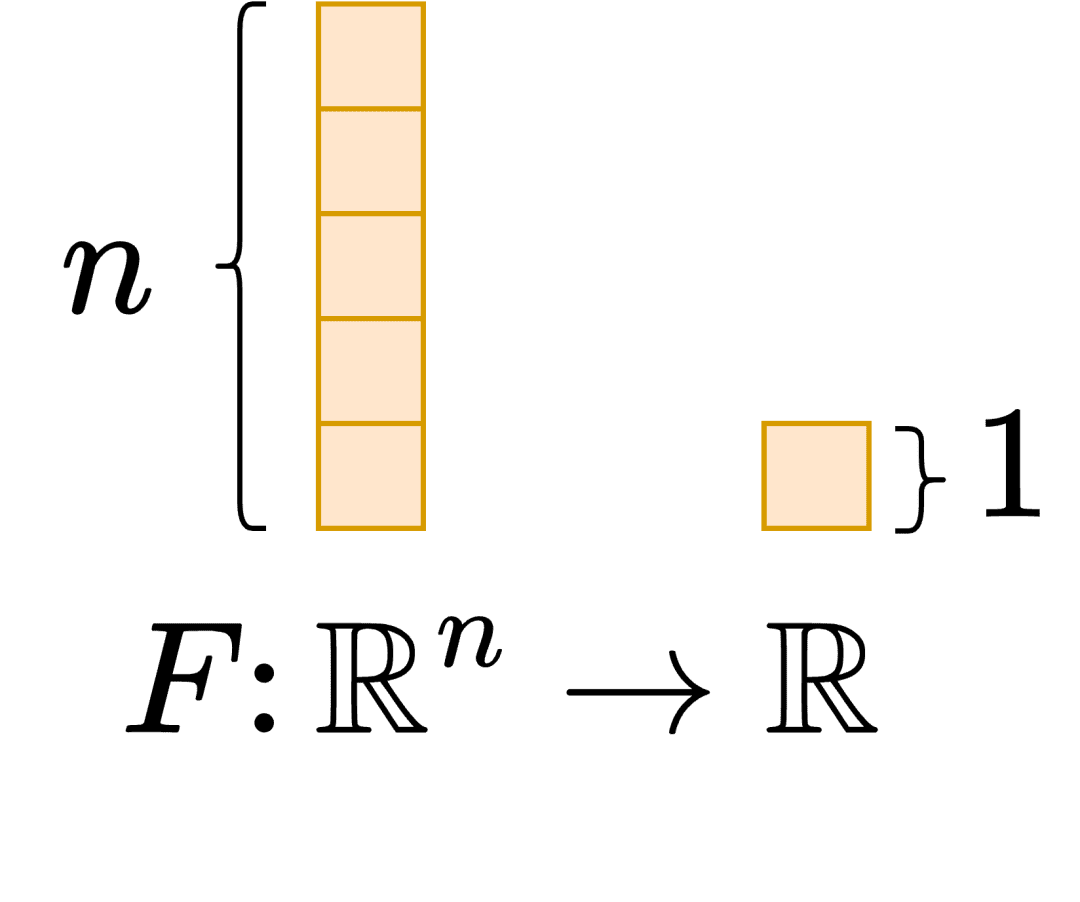
A neural network is a composition of many sublayers. So let’s consider our function ") as a composition of multiple functions (primitive operations).
as a composition of multiple functions (primitive operations).
 \ = \ D \circ C \circ B \circ A")
The function is composed of four primitive functions, namely  . For anyone new to composition, we can call to be a function where
. For anyone new to composition, we can call to be a function where )))") is equal to .
is equal to .
The next step would be to find the gradient of . However, before diving into the gradients of the function, let us revisit Jacobian matrices. It turns out that the derivatives of a multivariate function are a Jacobian matrix consisting of partial derivatives of the function w.r.t. all the variables upon which it depends.
Consider two multivariate functions,  and
and  , which depend on the variables
, which depend on the variables  and
and  . The Jacobian would look like this:
. The Jacobian would look like this:
}}{\partial{x, y}} \ = \ \begin{bmatrix} \displaystyle\frac{\partial u}{\partial x} & \displaystyle\frac{\partial u}{\partial y}\\ \\ \displaystyle\frac{\partial v}{\partial x} & \displaystyle\frac{\partial v}{\partial y} \end{bmatrix}")
Now let’s compute the Jacobian of our function . We need to note here that the function depends of  variables , and outputs a scalar value. This means that the Jacobian will be a row vector.
variables , and outputs a scalar value. This means that the Jacobian will be a row vector.
 \ = \ \displaystyle\frac{\partial{y}}{\partial{x}} \ = \ \begin{bmatrix} \displaystyle\frac{\partial y}{\partial x_{1}} & \ldots & \displaystyle\frac{\partial y}{\partial x_{n}} \end{bmatrix}")
Chain Rule
Remember how our function is composed of many primitive functions? The derivative of such a composed function is done with the help of the chain rule. To help our way into the chain rule, let us first write down the composition and then define the intermediate values.
 = D(C(B(A(x))))") is composed of:
is composed of:
")
")
")
")
Now that the composition is spelled out, let’s first get the derivatives of the intermediate values.
 = \displaystyle\frac{\partial{y}}{\partial{c}}")
 = \displaystyle\frac{\partial{c}}{\partial{b}}")
 = \displaystyle\frac{\partial{b}}{\partial{a}}")
 = \displaystyle\frac{\partial{a}}{\partial{x}}")
Now with the help of the chain rule, we derive the derivative of the function .
 \ = \ \displaystyle\frac{\partial{y}}{\partial{c}} \displaystyle\frac{\partial{c}}{\partial{b}} \displaystyle\frac{\partial{b}}{\partial{a}} \displaystyle\frac{\partial{a}}{\partial{x}}")
Mix the Jacobian and Chain Rule
After knowing about the Jacobian and the Chain Rule, let us visualize the two together. Shown in Figure 2.

The derivative of our function is just the matrix multiplication of the Jacobian matrices of the intermediate terms.
Now, this is where we ask the question:
Does it matter the order in which we do the matrix multiplication?
Forward and Reverse Accumulations
In this section, we try to understand the answer to the question of ordering the Jacobian matrix multiplication.
There are two extremes in which we could order the multiplications: the forward accumulation and the reverse accumulation.
Forward Accumulation
If we order the multiplication from right to left in the same order in which the function was evaluated, the process is called forward accumulation. The best way to think about the ordering is to place brackets in the equation, as shown in Figure 3.
 \ = \ \displaystyle\frac{\partial{y}}{\partial{c}} \left(\frac{\partial{c}}{\partial{b}} \left(\frac{\partial{b}}{\partial{a}} \displaystyle\frac{\partial{a}}{\partial{x}}\right)\right)")
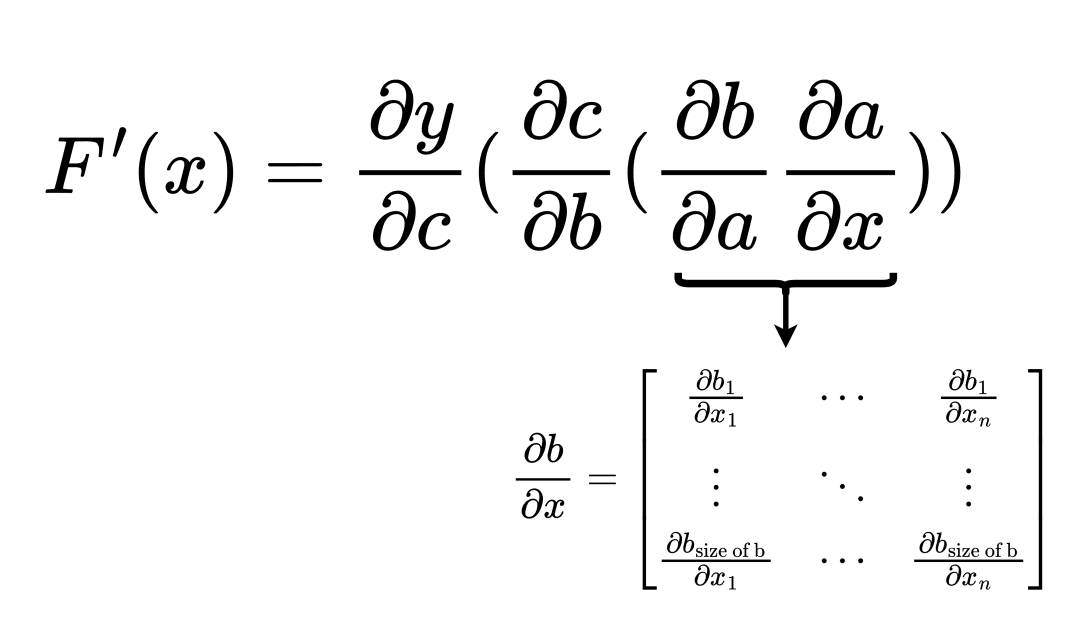
With the function  , the forward accumulation process is matrix multiplication in all the steps. This is more FLOPs.
, the forward accumulation process is matrix multiplication in all the steps. This is more FLOPs.
Note: Forward accumulation is beneficial when we want to get the derivative of a function  .
.
Another way to understand forwarding accumulation is to think of a Jacobian-Vector Product (JVP). Consider a Jacobian ") and a vector . The Jacobian-Vector Product would look to be
and a vector . The Jacobian-Vector Product would look to be v")
v \ = \ \displaystyle\frac{\partial{y}}{\partial{c}} \left(\displaystyle\frac{\partial{c}}{\partial{b}} \left(\displaystyle\frac{\partial{b}}{\partial{a}} \left(\displaystyle\frac{\partial{a}}{\partial{x}} v\right)\right)\right)")
This is done for us to have matrix-vector multiplication at all the stages (which makes the process more efficient).
➤ Question: If we have a Jacobian-Vector Product, how can we obtain the Jacobian from it?
➤ Answer: We pass a one-hot vector and get each column of the Jacobian one at a time.
So we can think of forwarding accumulation as a process in which we build the Jacobian per column.
Reverse Accumulation
Suppose we order the multiplication from left to right, in the opposite direction to which the function was evaluated. In that case, the process is called reverse accumulation. The diagram of the process is illustrated in Figure 4.
 \ = \ \left(\left(\displaystyle\frac{\partial{y}}{\partial{c}} \displaystyle\frac{\partial{c}}{\partial{b}}\right) \displaystyle\frac{\partial{b}}{\partial{a}} \right)\displaystyle\frac{\partial{a}}{\partial{x}}")
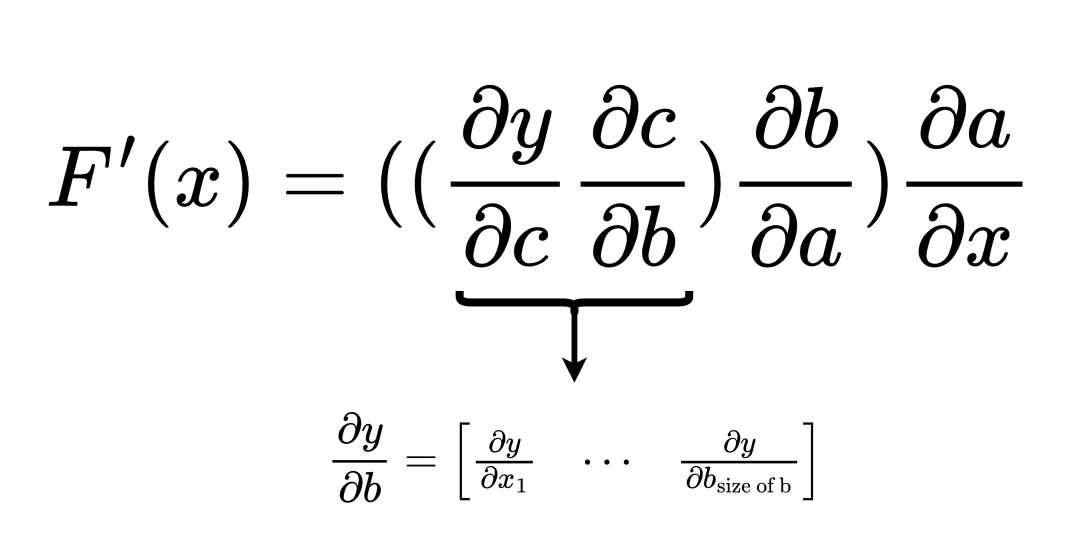
As it turns out, with reverse accumulation deriving the derivative of a function is a vector to matrix multiplication at all steps. This means that for the particular function, reverse accumulation has lesser FLOPs than forwarding accumulation.
Another way to understand forwarding accumulation is to think of a Vector-Jacobian Product (VJP). Consider a Jacobian and a vector . The Vector-Jacobian Product would look to be ")
 \ = \ \left(\left(\left(v^{T} \displaystyle\frac{\partial{y}}{\partial{c}}\right) \displaystyle\frac{\partial{c}}{\partial{b}}\right) \displaystyle\frac{\partial{b}}{\partial{a}}\right)\displaystyle\frac{\partial{a}}{\partial{x}}")
This allows us to have vector-matrix multiplication at all stages (which makes the process more efficient).
➤ Question: If we have a Vector-Jacobian Product, how can we obtain the Jacobian from it?
➤ Answer: We pass a one-hot vector and get each row of the Jacobian one at a time.
So we can think of reverse accumulation as a process in which we build the Jacobian per row.
Now, if we consider our previously mentioned function , we know that the Jacobian is a row vector. Therefore, if we apply the reverse accumulation process, which means the Vector-Jacobian Product, we can obtain the row vector in one shot. On the other hand, if we apply the forward accumulation process, the Jacobian-Vector Product, we will obtain a single element as a column, and we would need to iterate to build the entire row.
This is why reverse accumulation is used more often in the Neural Network literature.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we studied the math of automatic differentiation and how it is applied to the parameters of a Neural Network. The next tutorial will expand on this and see how we can implement automatic differentiation using a python package. The implementation will involve a step-by-step walkthrough of creating a python package and using it to train a neural network.
Did you enjoy a math-heavy tutorial on the fundamentals of automatic differentiation? Let us know.
Twitter: @PyImageSearch
References
Citation Information
A. R. Gosthipaty and R. Raha. “Automatic Differentiation Part 1: Understanding the Math,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and A. Thanki, eds., 2022, https://pyimg.co/pyxml
@incollection{ARG-RR_2022_autodiff1,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Automatic Differentiation Part 1: Understanding the Math},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/pyxml},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.