Last updated on July 7, 2021.

A couple weeks ago we learned how to classify images using deep learning and OpenCV 3.3’s deep neural network (dnn ) module.
While this original blog post demonstrated how we can categorize an image into one of ImageNet’s 1,000 separate class labels it could not tell us where an object resides in image.
In order to obtain the bounding box (x, y)-coordinates for an object in a image we need to instead apply object detection.
Object detection can not only tell us what is in an image but also where the object is as well.
Object detection algorithms need diverse and high-quality data to perform optimally. A rich dataset library helps train more accurate and adaptable models, ready for real-world detection tasks.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.
With a few images, you can train a working computer vision model in an afternoon. For example, bring data into Roboflow from anywhere via API, label images with the cloud-hosted image annotation tool, kickoff a hosted model training with one-click, and deploy the model via a hosted API endpoint. This process can be executed in a code-centric way, in the cloud-based UI, or any mix of the two.
Over 250,000 developers and machine learning engineers from companies such as Cardinal Health, Walmart, USG, Rivian, Intel, and Medtronic build computer vision pipelines with Roboflow. Get started today, no credit card required.
In the remainder of today’s blog post we’ll discuss how to apply object detection using deep learning and OpenCV.
- Update July 2021: Added a section on alternative deep learning-based object detectors, including articles on how to train R-CNNs from scratch, and more details on bounding box regression.
Object detection with deep learning and OpenCV
In the first part of today’s post on object detection using deep learning we’ll discuss Single Shot Detectors and MobileNets.
When combined together these methods can be used for super fast, real-time object detection on resource constrained devices (including the Raspberry Pi, smartphones, etc.)
From there we’ll discover how to use OpenCV’s dnn module to load a pre-trained object detection network.
This will enable us to pass input images through the network and obtain the output bounding box (x, y)-coordinates of each object in the image.
Finally we’ll look at the results of applying the MobileNet Single Shot Detector to example input images.
In a future blog post we’ll extend our script to work with real-time video streams as well.
Single Shot Detectors for object detection

When it comes to deep learning-based object detection there are three primary object detection methods that you’ll likely encounter:
- Faster R-CNNs (Ren et al., 2015)
- You Only Look Once (YOLO) (Redmon et al., 2015)
- Single Shot Detectors (SSDs) (Liu et al., 2015)
Faster R-CNNs are likely the most “heard of” method for object detection using deep learning; however, the technique can be difficult to understand (especially for beginners in deep learning), hard to implement, and challenging to train.
Furthermore, even with the “faster” implementation R-CNNs (where the “R” stands for “Region Proposal”) the algorithm can be quite slow, on the order of 7 FPS.
If we are looking for pure speed then we tend to use YOLO as this algorithm is much faster, capable of processing 40-90 FPS on a Titan X GPU. The super fast variant of YOLO can even get up to 155 FPS.
The problem with YOLO is that it leaves much accuracy to be desired.
SSDs, originally developed by Google, are a balance between the two. The algorithm is more straightforward (and I would argue better explained in the original seminal paper) than Faster R-CNNs.
We can also enjoy a much faster FPS throughput than Ren et al. at 22-46 FPS depending on which variant of the network we use. SSDs also tend to be more accurate than YOLO. To learn more about SSDs, please refer to Liu et al.
MobileNets: Efficient (deep) neural networks
When building object detection networks we normally use an existing network architecture, such as VGG or ResNet, and then use it inside the object detection pipeline. The problem is that these network architectures can be very large in the order of 200-500MB.
Network architectures such as these are unsuitable for resource constrained devices due to their sheer size and resulting number of computations.
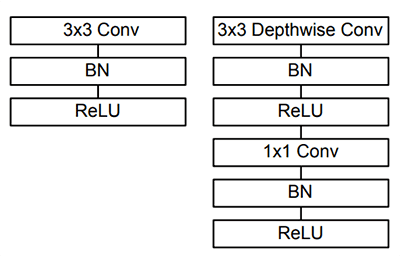
Instead, we can use MobileNets (Howard et al., 2017), another paper by Google researchers. We call these networks “MobileNets” because they are designed for resource constrained devices such as your smartphone. MobileNets differ from traditional CNNs through the usage of depthwise separable convolution (Figure 2 above).
The general idea behind depthwise separable convolution is to split convolution into two stages:
- A 3×3 depthwise convolution.
- Followed by a 1×1 pointwise convolution.
This allows us to actually reduce the number of parameters in our network.
The problem is that we sacrifice accuracy — MobileNets are normally not as accurate as their larger big brothers…
…but they are much more resource efficient.
For more details on MobileNets please see Howard et al.
Combining MobileNets and Single Shot Detectors for fast, efficient deep-learning based object detection
If we combine both the MobileNet architecture and the Single Shot Detector (SSD) framework, we arrive at a fast, efficient deep learning-based method to object detection.
The model we’ll be using in this blog post is a Caffe version of the original TensorFlow implementation by Howard et al. and was trained by chuanqi305 (see GitHub).
The MobileNet SSD was first trained on the COCO dataset (Common Objects in Context) and was then fine-tuned on PASCAL VOC reaching 72.7% mAP (mean average precision).
We can therefore detect 20 objects in images (+1 for the background class), including airplanes, bicycles, birds, boats, bottles, buses, cars, cats, chairs, cows, dining tables, dogs, horses, motorbikes, people, potted plants, sheep, sofas, trains, and tv monitors.
Deep learning-based object detection with OpenCV
In this section we will use the MobileNet SSD + deep neural network (dnn ) module in OpenCV to build our object detector.
I would suggest using the “Downloads” code at the bottom of this blog post to download the source code + trained network + example images so you can test them on your machine.
Let’s go ahead and get started building our deep learning object detector using OpenCV.
Open up a new file, name it deep_learning_object_detection.py , and insert the following code:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
On Lines 2-4 we import packages required for this script — the dnn module is included in cv2 , again, making hte assumption that you’re using OpenCV 3.3.
Then, we parse our command line arguments (Lines 7-16):
--image: The path to the input image.--prototxt: The path to the Caffe prototxt file.--model: The path to the pre-trained model.--confidence: The minimum probability threshold to filter weak detections. The default is 20%.
Again, example files for the first three arguments are included in the “Downloads” section of this blog post. I urge you to start there while also supplying some query images of your own.
Next, let’s initialize class labels and bounding box colors:
# initialize the list of class labels MobileNet SSD was trained to # detect, then generate a set of bounding box colors for each class CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
Lines 20-23 build a list called CLASSES containing our labels. This is followed by a list, COLORS which contains corresponding random colors for bounding boxes (Line 24).
Now we need to load our model:
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
The above lines are self-explanatory, we simply print a message and load our model (Lines 27 and 28).
Next, we will load our query image and prepare our blob , which we will feed-forward through the network:
# load the input image and construct an input blob for the image # by resizing to a fixed 300x300 pixels and then normalizing it # (note: normalization is done via the authors of the MobileNet SSD # implementation) image = cv2.imread(args["image"]) (h, w) = image.shape[:2] blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5)
Taking note of the comment in this block, we load our image (Line 34), extract the height and width (Line 35), and calculate a 300 by 300 pixel blob from our image (Line 36).
Now we’re ready to do the heavy lifting — we’ll pass this blob through the neural network:
# pass the blob through the network and obtain the detections and
# predictions
print("[INFO] computing object detections...")
net.setInput(blob)
detections = net.forward()
On Lines 41 and 42 we set the input to the network and compute the forward pass for the input, storing the result as detections . Computing the forward pass and associated detections could take awhile depending on your model and input size, but for this example it will be relatively quick on most CPUs.
Let’s loop through our detections and determine what and where the objects are in the image:
# loop over the detections
for i in np.arange(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the `detections`,
# then compute the (x, y)-coordinates of the bounding box for
# the object
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# display the prediction
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
print("[INFO] {}".format(label))
cv2.rectangle(image, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(image, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
We start by looping over our detections, keeping in mind that multiple objects can be detected in a single image. We also apply a check to the confidence (i.e., probability) associated with each detection. If the confidence is high enough (i.e. above the threshold), then we’ll display the prediction in the terminal as well as draw the prediction on the image with text and a colored bounding box. Let’s break it down line-by-line:
Looping through our detections , first we extract the confidence value (Line 48).
If the confidence is above our minimum threshold (Line 52), we extract the class label index (Line 56) and compute the bounding box around the detected object (Line 57).
Then, we extract the (x, y)-coordinates of the box (Line 58) which we will will use shortly for drawing a rectangle and displaying text.
Next, we build a text label containing the CLASS name and the confidence (Line 61).
Using the label, we print it to the terminal (Line 62), followed by drawing a colored rectangle around the object using our previously extracted (x, y)-coordinates (Lines 63 and 64).
In general, we want the label to be displayed above the rectangle, but if there isn’t room, we’ll display it just below the top of the rectangle (Line 65).
Finally, we overlay the colored text onto the image using the y-value that we just calculated (Lines 66 and 67).
The only remaining step is to display the result:
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
We display the resulting output image to the screen until a key is pressed (Lines 70 and 71).
OpenCV and deep learning object detection results
To download the code + pre-trained network + example images, be sure to use the “Downloads” section at the bottom of this blog post.
From there, unzip the archive and execute the following command:
$ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_01.jpg [INFO] loading model... [INFO] computing object detections... [INFO] loading model... [INFO] computing object detections... [INFO] car: 99.78% [INFO] car: 99.25%
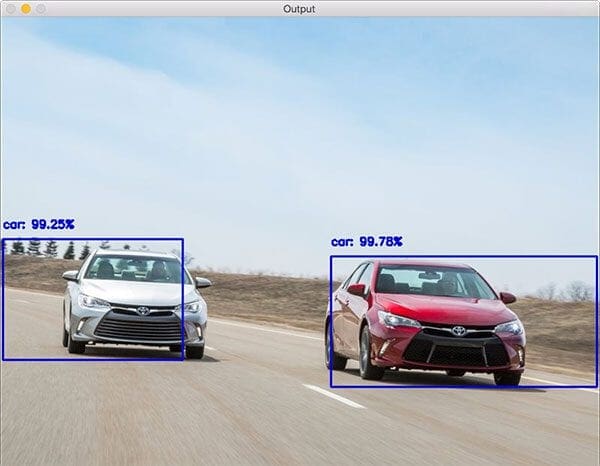
Our first result shows cars recognized and detected with near-100% confidence.
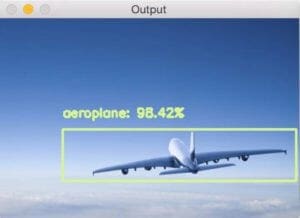
In this example we detect an airplane using deep learning-based object detection:
$ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_02.jpg [INFO] loading model... [INFO] computing object detections... [INFO] loading model... [INFO] computing object detections... [INFO] aeroplane: 98.42%
The ability for deep learning to detect and localize obscured objects is demonstrated in the following image, where we see a horse (and it’s rider) jumping a fence flanked by two potted plants:
$ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_03.jpg [INFO] loading model... [INFO] computing object detections... [INFO] horse: 96.67% [INFO] person: 92.58% [INFO] pottedplant: 96.87% [INFO] pottedplant: 34.42%

In this example we can see a beer bottle is detected with an impressive 100% confidence:
$ python deep_learning_object_detection.py --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_04.jpg [INFO] loading model... [INFO] computing object detections... [INFO] bottle: 100.00%

Followed by another horse image which also contains a dog, car, and person:
$ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_05.jpg [INFO] loading model... [INFO] computing object detections... [INFO] car: 99.87% [INFO] dog: 94.88% [INFO] horse: 99.97% [INFO] person: 99.88%

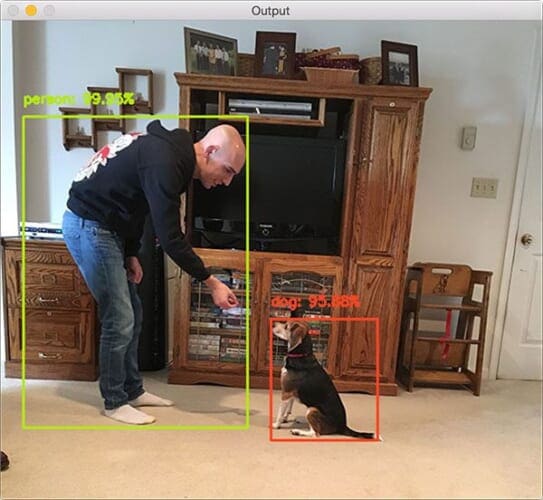
Finally, a picture of me and Jemma, the family beagle:
$ python deep_learning_object_detection.py \ --prototxt MobileNetSSD_deploy.prototxt.txt \ --model MobileNetSSD_deploy.caffemodel --image images/example_06.jpg [INFO] loading model... [INFO] computing object detections... [INFO] dog: 95.88% [INFO] person: 99.95%

Unfortunately the TV monitor isn’t recognized in this image which is likely due to (1) me blocking it and (2) poor contrast around the TV. That being said, we have demonstrated excellent object detection results using OpenCV’s dnn module.
Alternative deep learning object detectors
In this post, we used OpenCV and the Single Shot Detector (SSD) model for deep learning-based object detection.
However, there are deep learning object detectors that we can apply, including:
- YOLO object detection with OpenCV
- YOLO and Tiny-YOLO object detection on the Raspberry Pi and Movidius NCS
- Faster R-CNN and OpenCV
- Mask R-CNN and OpenCV (technically an “instance segmentation” model)
- RetinaNet object detector
Additionally, if you are interested in learning how to train your own custom deep learning object detectors, including obtaining a deeper understanding of the R-CNN family of object detectors, be sure to read this four-part series:
- Turning any CNN image classifier into an object detector with Keras, TensorFlow, and OpenCV
- OpenCV Selective Search for Object Detection
- Region proposal object detection with OpenCV, Keras, and TensorFlow
- R-CNN object detection with Keras, TensorFlow, and Deep Learning
From there, I recommend studying the concept of bounding box regression in more detail:
- Object detection: Bounding box regression with Keras, TensorFlow, and Deep Learning
- Multi-class object detection and bounding box regression with Keras, TensorFlow, and Deep Learning
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: May 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we learned how to perform object detection using deep learning and OpenCV.
Specifically, we used both MobileNets + Single Shot Detectors along with OpenCV 3.3’s brand new (totally overhauled) dnn module to detect objects in images.
As a computer vision and deep learning community we owe a lot to the contributions of Aleksandr Rybnikov, the main contributor to the dnn module for making deep learning so accessible from within the OpenCV library. You can find Aleksandr’s original OpenCV example script here — I have modified it for the purposes of this blog post.
In a future blog post I’ll be demonstrating how we can modify today’s tutorial to work with real-time video streams, thus enabling us to perform deep learning-based object detection to videos. We’ll be sure to leverage efficient frame I/O to increase the FPS throughout our pipeline as well.
To be notified when future blog posts (such as the real-time object detection tutorial) are published here on PyImageSearch, simply enter your email address in the form below.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

