
Table of Contents
Fundamentals of Recommendation Systems
In this course, we will explore the fascinating world of recommendation systems. We will start by learning the basics of these systems and then delve into some of the most popular ones in detail.

With the rise of the internet and the increasing use of smart devices, it has become more important than ever to understand user preferences and provide personalized content and services. Web apps can keep users engaged by offering personalization, which is made possible by recommendation engines.
These engines utilize user data (e.g., followers, tweets, pictures, likes and dislikes, ratings, etc.) to deliver personalized recommendations. Understanding the user’s taste is crucial for a successful item recommendation, and various techniques (e.g., machine learning, statistics, probability, and algebra) are used to achieve this.
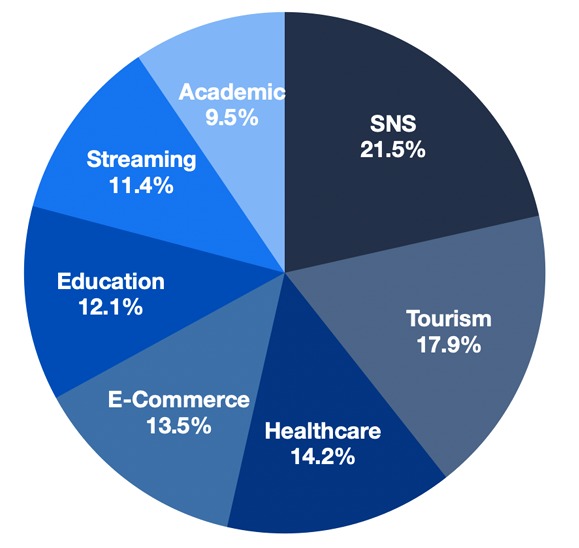
Recommendation systems have become integral to many services and web apps (Figure 1), including Netflix, Amazon, LinkedIn, and YouTube. Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more.
This lesson is designed to give readers a comprehensive understanding of how various tools (e.g., machine learning, statistics, probability, and algebra) are employed to recommend our popular daily applications. By the end of the lesson, readers will have a solid grasp of the underlying principles that enable these applications to make suggestions based on data analysis.
In this tutorial, you will learn the fundamentals of recommendation systems.
This lesson is the 1st of a 3-part series on Deep Dive into Popular Recommendation Engines 101:
- Fundamentals of Recommendation Systems (this tutorial)
- Netflix Movies and Series Recommendation Systems
- LinkedIn Jobs Recommendation Systems
To learn the fundamentals of recommendation systems, just keep reading.
Fundamentals of Recommendation Systems
Recommendation Engines and Their Types
What Are Recommendation Engines?
When recommending items to users, a recommendation engine follows a simple process. It first analyzes the usefulness of each item in a given set (e.g., movies, books, videos, or music) for any user. Once it has determined the utility of each item, it then recommends the item that maximizes the overall utility for a particular user. This is done by finding the item, denoted as  , with the highest utility score when measured against the user. In other words,
, with the highest utility score when measured against the user. In other words,
,")
where ") is the utility function that measures the usefulness of an item
is the utility function that measures the usefulness of an item  for a user
for a user  .
.
Alternatively, a recommendation engine can also suggest a list of top  items from the set
items from the set  based on their utility for a particular user. Overall, a recommendation engine helps users find items that they will enjoy and find useful. Figure 2 illustrates an overall view of a recommendation engine.
based on their utility for a particular user. Overall, a recommendation engine helps users find items that they will enjoy and find useful. Figure 2 illustrates an overall view of a recommendation engine.
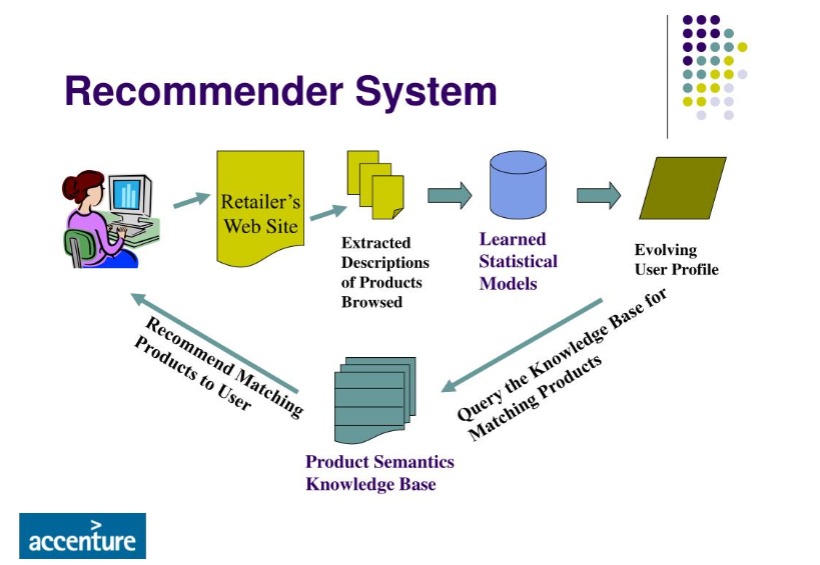
Regarding recommendation systems, the space of possible items can be quite large, with hundreds of thousands or even millions of items in some cases. The utility function typically represents a rating that predicts how likely a user will enjoy a particular item. For example, if a user enjoys action thrillers, he would probably like a Tom Cruise movie if it is recommended.
Each user has a profile with various features (e.g., age, marital status, watching history, recent queries, ratings, etc.). Similarly, an item (e.g., a movie) can be represented by features like genre, year, director, cast, IMDB rating, and so on. The utility function measures the similarity between a user profile and an item feature.
The biggest challenge in creating a recommendation system is the utility function, which needs to be defined for all user-item combinations. Additionally, the user and item space is continually growing and changing. This is where machine learning, statistics, and algebra come into play. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
Content-Based Recommendations
Content-based recommendations (Figure 3) rely on estimating the utility function of an item for a specific user based on their preferences for similar items. This allows the system to suggest items that align with the user’s interests, making it easier to discover new content they’ll enjoy.
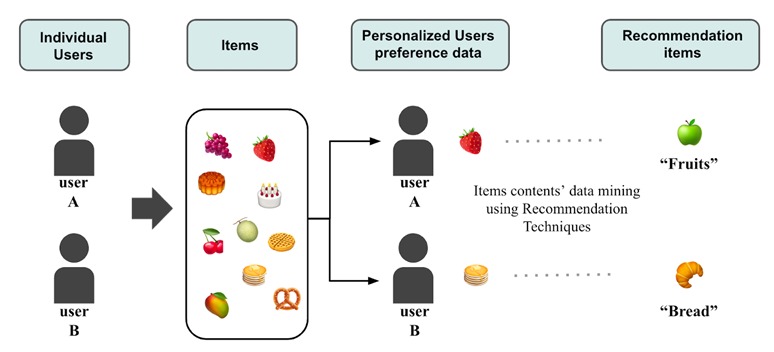
For example, if a user has a liking for horror movies (e.g., “The Conjuring” or “The Nun”), the content-based recommendation system will suggest other horror movies (e.g., “Annabelle”). Ultimately, the system aims to find items that match the user’s preferences and interests, providing them with personalized recommendations.
One of the best-known measures for calculating the utility of an item for user is cosine similarity. To understand this, assume that each item can be represented as a feature vector,
,")
where  represents the weight of the
represents the weight of the  feature (e.g., Whether the movie is a horror or not? Does the film have Tom Cruise as a leading actor?). Note that the weights can be binary or continuous depending on the nature of the feature.
feature (e.g., Whether the movie is a horror or not? Does the film have Tom Cruise as a leading actor?). Note that the weights can be binary or continuous depending on the nature of the feature.
Given these item feature vectors, the user profile vector can be computed as the average of feature vectors of items  (total
(total  items) liked or rated by that user in the past. In other words,
items) liked or rated by that user in the past. In other words,

Once we have the user profile vector, we can use cosine similarity to compute the similarity between the user profile and a new item  . This can be done using the following equation:
. This can be done using the following equation:
 \ = \ \displaystyle\frac{\langle c_j, u \rangle}{\Vert c_j \Vert \cdot \Vert u \Vert},")
where  denotes the dot product operation and
denotes the dot product operation and  denotes the norm of a vector.
denotes the norm of a vector.
It is important to consider certain limitations when utilizing content-based recommendations.
- New users may find establishing a user profile vector difficult due to limited information about their interests. This may result in less meaningful recommendations.
- Additionally, content-based recommendations may become too similar to items the user has already engaged with, leading to overspecialization and limited exploration of new interests.
Collaborative Recommendations
As opposed to content-based recommendations, collaborative systems (Figure 4) are designed to predict the usefulness of an item for a user based on the ratings provided by other users. This means that the system can suggest items that are liked or rated highly by users with similar interests as the given user. For instance, if two users, Mike and John, both prefer horror movies, and Mike likes “The Conjuring.” Then, the collaborative system will also recommend “The Conjuring” to John.
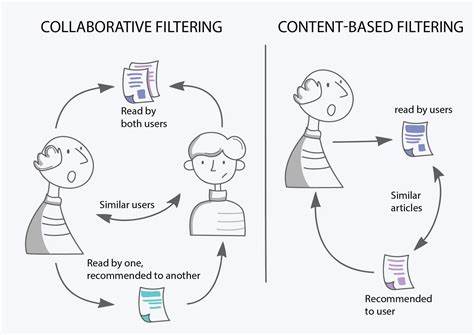
To predict the utility of an un-rated item for a user , we define a set  consisting of
consisting of  users that are most similar to user and have already rated the item . We can find these -closest users by measuring the cosine similarity between them and the given user .
users that are most similar to user and have already rated the item . We can find these -closest users by measuring the cosine similarity between them and the given user .
The utility can thus be estimated as the average of utilities ")
") as follows:
as follows:
 \ = \ \displaystyle\frac{\sum\limits_{i=1}^{K} f(c, u_i)}{K}.")
Here, we have chosen a simple function-like average to aggregate the utilities . In general, the aggregator can be any function.
Like content-based recommendations, collaborative systems have their limitations:
- Identifying the
 -closest users for new users is difficult because of the limited information about their interests. Hence, recommendations won’t be meaningful.
-closest users for new users is difficult because of the limited information about their interests. Hence, recommendations won’t be meaningful. - New items are regularly added to the recommendation systems. Collaborative systems depend on the rating given to an item by other users. Therefore, until a substantial number of users rate the new item, the recommender system cannot recommend it.
- Collaborative systems depend on the availability of similar users who have rated the item we are interested in. But, usually, the number of ratings already obtained could be bigger than the predicted ratings. This makes the recommendations ineffective. This is commonly referred to as the sparsity problem.
Hybrid Recommendations
Hybrid systems are becoming increasingly popular in recommendation engines as they offer the benefits of both content-based and collaborative methods while avoiding some of their limitations. There are different ways to combine both of these methods, which can be classified as follows:
- Ensembling the predictions of both content-based and collaborative systems (e.g., a linear combination of ratings and a voting scheme)
- Incorporating content-based characteristics into a collaborative approach and vice-versa (e.g., collaborative systems can also maintain content-based profiles for each user, which can be used to provide recommendations for uncommonly rated items)
- A unified recommendation system that incorporates both content and collaborative aspects of the recommendation
Evaluating Recommendation Systems
Establishing the qualities that make a recommendation system great is crucial when assessing its effectiveness. In addition, various metrics can be employed to evaluate a recommendation system, and it’s essential to delve into these metrics and understand how they can be used for evaluation purposes.
Root Mean Square Error
Root mean square error (RMSE) is one of the simplest ways to evaluate a recommendation engine. RMSE measures how good the predicted utility of an item for user is compared to the user’s actual ratings. Mathematically,
 \in R} (f(c, u) - r_{cu})^2}{\vert R \vert}},")
where  is the rating given by user to item and
is the rating given by user to item and  is the set of users and items for which we already have the ratings.
is the set of users and items for which we already have the ratings.
Precision@K
Precision measures the efficiency of a machine learning algorithm. For a recommendation system, Precision@K measures the fraction of top- recommendations which are actually relevant to the user. Relevant recommendations are those the user will probably like the recommended item.
Suppose, the recommendation system recommends top- items  to a user based on their utilities. And assume that the set
to a user based on their utilities. And assume that the set  represents the top- items that are actually relevant for the user (i.e., ground-truth recommendations). The Precision@K is then defined as
represents the top- items that are actually relevant for the user (i.e., ground-truth recommendations). The Precision@K is then defined as

Recall@K
Recall measures the effectiveness of a machine learning system. For a recommendation system, Recall@K measures the fraction of relevant items covered in the top- recommendations.
Suppose, the recommendation system recommends top- items  to a user based on their utilities. And assume that the set represents the top- items that are actually relevant for the user (i.e., ground-truth recommendations). Recall@K is then defined as
to a user based on their utilities. And assume that the set represents the top- items that are actually relevant for the user (i.e., ground-truth recommendations). Recall@K is then defined as

We can define several other metrics based on precision-recall (e.g., F-score, ROC (receiver operator characteristic) curve, AUC (area under the curve), etc.). This is described in Table 1.
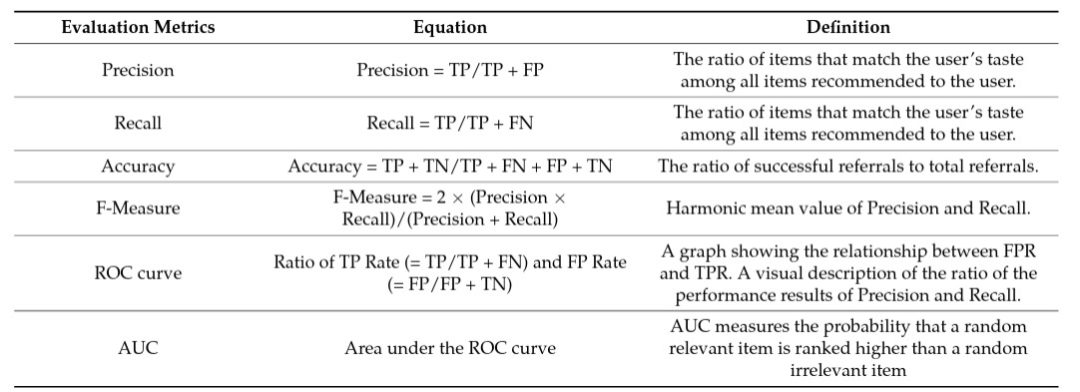
Mean Reciprocal Rank
Suppose the item is the topmost relevant item in the ground-truth recommendations and ranks  in the top- recommendations provided by the recommendation engine. Then, the mean reciprocal rank (MRR) is defined as the “multiplicative inverse” of the rank of the most relevant item :
in the top- recommendations provided by the recommendation engine. Then, the mean reciprocal rank (MRR) is defined as the “multiplicative inverse” of the rank of the most relevant item :

where  is the number of users for which we have provided recommendations.
is the number of users for which we have provided recommendations.
Recommendation Techniques
Data mining techniques are incredibly valuable for uncovering patterns and correlations within data. This information can then be used to make recommendations (e.g., suggesting similar items or grouping users with similar interests). Figure 5 provides an overview of the various data mining techniques commonly used in recommendation engines today, and we’ll delve into each of these techniques in more detail.
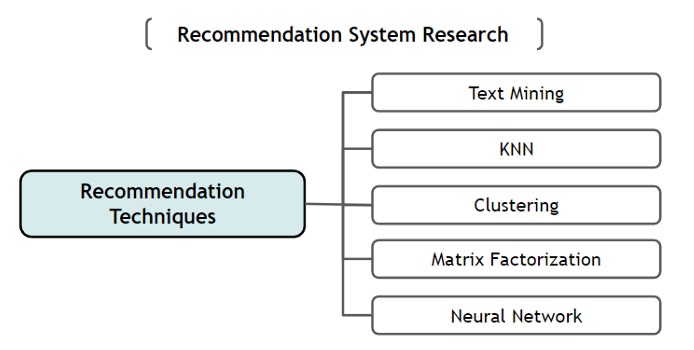
Text Mining
Text mining (Figure 6) is a powerful tool for extracting valuable information from textual data. This can be especially useful when recommending blogs, news articles, and other text-based content. For example, with a content-based recommendation system, text mining can help to identify and recommend similar items by analyzing the underlying semantic structure of each piece. Similarly, for collaborative recommendation models, text mining can help to evaluate the semantic knowledge of information data between users, enabling the system to make more accurate item recommendations based on similarity.
For example, term frequency–inverse document frequency (TF-IDF) (Figure 7) is a popular text-mining technique in content-based recommendations. The TF-IDF algorithm assigns weight to different keywords in a text according to the number of repetitions and the whole corpus. It comprises the following:
- Term frequency (TF) assigns weight proportional to the times a keyword occurs in a text. In other words, more repetitions mean that the keyword is essential in the given text.
- Inverse document frequency (IDF) assigns weight inversely proportional to the times the keyword occurs in the whole corpus. It is less important if a keyword is present in most of the text corpus.
This technique expresses a text item as a feature vector, which can be used to compute cosine similarity with other item feature vectors.

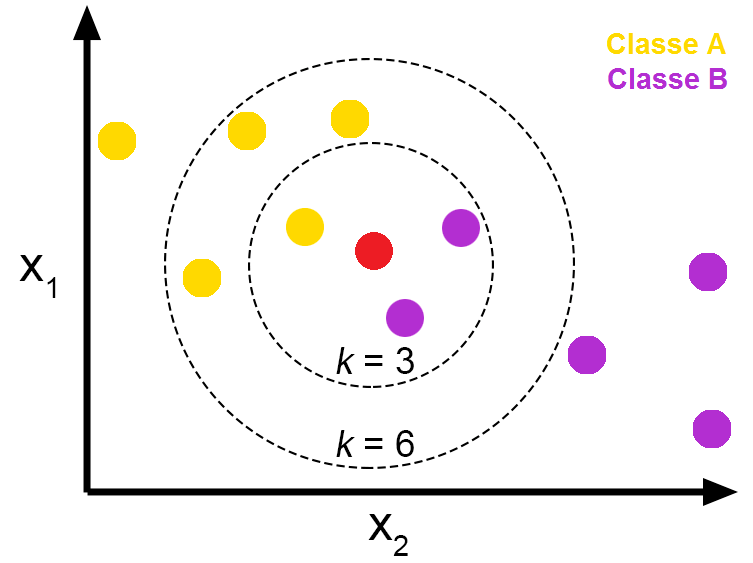
K-Nearest Neighbor
K-nearest neighbor (KNN) (Figure 8) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g., Euclidean distance, cosine similarity, or Pearson correlation). In a collaborative recommendation model, the KNN algorithm can identify the -closest users to a given user. The item ratings of these -closest neighbors are then used to recommend items to the given user. For a content-based recommendation, the algorithm can find -similar items for a particular item previously rated by the user.
Clustering
Clustering is a class of algorithms that segregates the data into a set of definite clusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., -means and spectral clustering) can be used in recommendation engines.
For example, -means (Figure 9) works by first selecting random points as cluster centers. Then, it assigns each data point in the data to the nearest cluster center. After that, it calculates the mean of all data points assigned to each cluster and moves the cluster center to that mean. This process is repeated until the cluster centers no longer move.
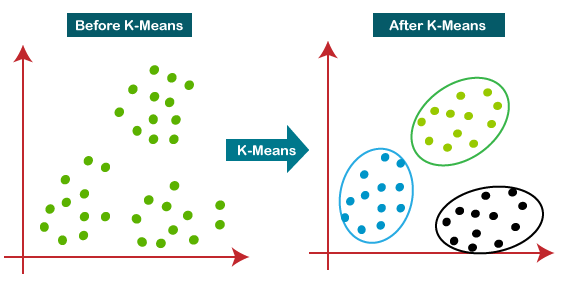
Clustering is mainly used in collaborative settings to segregate users into similar interest groups. This way, the recommendation problem boils down to finding relevant items for a cluster rather than for each user separately.
Matrix Factorization
Matrix factorization is a technique used to find the transformation that expresses the user information and preference into the same latent space by decomposing the user’s evaluation data stored in a rating matrix. Singular value decomposition (SVD) is a popular matrix factorization method that transforms the user and selected items into a space of the same latent factor.
To understand this, assume a rating matrix  (of size
(of size  ) whose
) whose  entry
entry ") is
is 1 if user  rated the item
rated the item  and
and 0 if it is unrated. Now, given this user-item matrix , the SVD (Figure 10) decomposes that matrix so that you have a user matrix and an item matrix independently. In other words,

where  is a user matrix of size
is a user matrix of size  ,
,  is a
is a  diagonal matrix consisting of singular values along the principal diagonal, and
diagonal matrix consisting of singular values along the principal diagonal, and  is the item matrix of size
is the item matrix of size  . This way, the SVD decomposes the original matrix into a user and an item matrix that transforms the user and items into the same latent factor of dimension . Note that in Figure 10,
. This way, the SVD decomposes the original matrix into a user and an item matrix that transforms the user and items into the same latent factor of dimension . Note that in Figure 10,  .
.
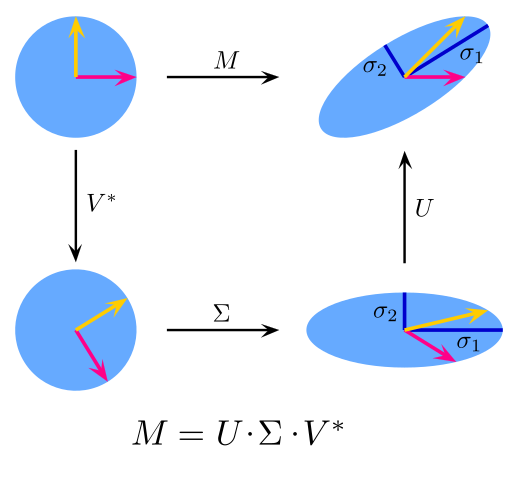
SVD is popularly used in recommendation engines to find similar items and users via their respective user and item matrices.
Neural Networks
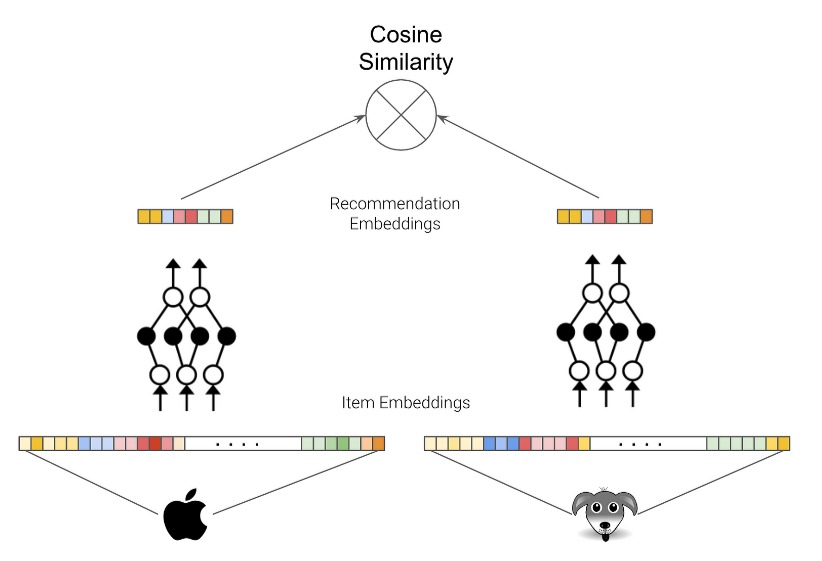
Neural networks have become increasingly popular in recommendation engines due to their ability to capture complex patterns in user-item data. They can now process various data (e.g., speech, text, images, tables, and graphs), making them suitable for various recommendation settings.
Deep neural networks (Figure 11) are used to learn user and item embeddings, which are vectors representing entity features. These embeddings help ensure that similar entities (e.g., users or items) have similar distances in the vector space. Neural networks can also be trained on multiple objectives simultaneously, making them a highly effective data mining technique.
An active area of research in recommendation systems is a bandit-based algorithm, a form of reinforcement learning that tries to balance exploring and exploiting possibilities. These algorithms can consider multiple objectives and metrics related to user satisfaction. For example, an additional objective in a music recommender system can be to provide “fairness” for new and long-tailed artists.
Graph neural networks (GNNs) are another area of active research, as they can extract information from graphs that capture the interactions between customers and items. GNNs have an advantage over sequence-based neural nets as there is no necessarily fixed order of items a user might like.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this lesson, we learned the fundamentals of recommendation systems. Recommendation systems deliver personalization by ranking users’ items (e.g., movies) based on their interests and preferences.
Given an item, a recommendation engine measures the usefulness or utility of that item for a user. The central challenge in the recommendation system is to develop the utility function, as it is not defined for all combinations of users and items.
Based on the nature of the utility function, recommendation systems can be categorized into three types:
- Content-based
- Collaborative
- Hybrid
Content-based recommendation systems try to recommend items similar to those the user already liked or rated. On the other hand, collaborative systems suggest items rated or liked by other users with similar interests as the given user. However, both these settings suffer from drawbacks (e.g., sparsity, new user problems, new item problems, overspecialization, etc.). Hybrid systems combine content-based and collaborative methods to avoid these issues.
There are several measures to evaluate the goodness of a recommendation system.
Root mean square error (RMSE) measures how good the predicted utility of an item for a user is compared to actual ratings provided by the user. Precision@K measures the fraction of top- recommendations relevant to the user. Recall@K measures the fraction of relevant items which are covered in top- recommendations. Finally, mean reciprocal rank (MRR) is defined as the average “multiplicative inverse” of the rank of the most relevant item.
Various data mining algorithms are used in recommendation systems to derive useful information (e.g., patterns and correlations in data). These techniques include: text mining, nearest neighbor, clustering, matrix factorization, and neural networks.
Text mining is useful in extracting useful information from textual data. It can recommend similar items by performing a semantic analysis of the item.
For example, the K-nearest neighbor algorithm can identify the -closest users to a given user. The item ratings of these -closest neighbors can then be used to recommend items to the given user.
Clustering is mainly used in collaborative settings to segregate users into similar interest groups.
Matrix factorization is a technique used to find the transformation that expresses the user information and preference into the same latent space by decomposing the user’s evaluation data stored in a rating matrix.
Lastly, neural networks can capture complex patterns in user-item data and process various data (e.g., speech, text, images, tables, graphs, etc.).
In subsequent lessons, we will dive into the details of some of the popular recommendation systems around us. So stay tuned for our upcoming tutorial on Netflix movies and series recommendation systems!
Citation Information
Mangla, P. “Fundamentals of Recommendation Systems,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/9kf03
@incollection{Mangla_2023_FRS,
author = {Puneet Mangla},
title = {Fundamentals of Recommendation Systems},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/9kf03},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.