
Table of Contents
DETR Breakdown Part 2: Methodologies and Algorithms
In this tutorial, we’ll learn about the methodologies applied in DETR.

This lesson is the 2nd of a 3-part series on DETR Breakdown:
- DETR Breakdown Part 1: Introduction to DEtection TRansformers
- DETR Breakdown Part 2: Methodologies and Algorithms (this tutorial)
- DETR Breakdown Part 3: Architecture and Details
To learn about the methodologies applied in Detection Transformers, just keep reading.
DETR Breakdown Part 2: Methodologies and Algorithms
Welcome back to Part 2 of this tutorial series on Detection Transformers. In the previous tutorial DETR Breakdown Part 1: Introduction to DEtection TRansformers, we looked at what factors led to the birth of DETR, what components were added, and what really is the Chemical X that made DETR into the super object detector it is today.
As scientists, learners, and builders, we must seek to understand what causes excellent performances. One of the key components of DETR is a secret sauce called Set Prediction Loss. Today we place this “Set Prediction Loss” under the microscope.
The DETR Model 👁️
First, let us revisit the DETR Model architecture in the interactive diagram below.
Ironically, we will not be demystifying the above architecture in this tutorial. Set Prediction Loss comes in where this architecture ends and outputs predictions. The predictions are matched with the ground truth objects to yield a loss. The model iterates on that and gets better and better and eventually at par with past models like Faster R-CNN.
How? Just keep reading to find out!
Object Detection Set Prediction Loss 📉
DETR infers a fixed-size set of  predictions. Note that is significantly larger than the typical number of objects in an image.
predictions. Note that is significantly larger than the typical number of objects in an image.
One of the main difficulties of training is to score predicted objects with respect to the ground truth. Therefore, Carion et al. (2020) propose the following algorithm.
- A loss that produces an optimal bipartite matching between predicted and ground truth objects
- Optimize the object-specific (bounding box) losses
Optimal Bipartite Matching 🔄
Here let us pause for a moment to understand what is bipartite matching.
Bipartite matching is a mathematical concept from graph theory, often used in computer science and optimization problems. It refers to the process of finding a subset of edges in a bipartite graph such that each vertex in the graph is incident to at most one edge in the subset and the size of the subset is maximized. This subset of edges is called a maximum cardinality matching or simply a maximum matching.
L.R. Ford and D.R. Fulkerson, “Maximal Flow Through a Network,” Canadian Journal of Mathematics, vol. 8, pp. 399-404, 1956.
A bipartite graph is a special type whose vertices can be divided into two disjoint sets such that all edges connect a vertex from one set to another. In other words, no edges connect vertices within the same set.
Bipartite matching is the process of pairing vertices from the two sets so that each vertex is paired with at most one vertex from the other set, and the total number of paired vertices is maximized.
Think of it as finding the best way to match items from two categories, like connecting workers to jobs or students to projects. Each item from one category is paired with at most one item from the other category, and the cost of the pairs is optimal. This is shown in the demo below.
Optimal Bipartite Matching for Objects 🌐
Before we go into how the above concept of bipartite matching can be applied to ground truth and predicted objects, let us first familiarize ourselves with the terminologies and nomenclature.
The process of finding matching pairs is similar to the methods used in previous object detectors for connecting proposed or anchor boxes to actual objects in an image. The main difference is that, for direct set prediction, we need to find unique one-to-one matches without any duplicates. Let’s look at the demo below to understand the pointers better.
 is the ground truth set of objects.
is the ground truth set of objects. is the set of
is the set of  predictions.
predictions.
 is the ground truth set of objects.
is the ground truth set of objects. is the set of
is the set of We already know that is much larger than an image’s actual set of objects. So, to align the ground truth with predictions, we pad ground truth with  (no objects token).
(no objects token).
The task now is to find an optimal bipartite matching between these two sets: ground truth and prediction.
Let  be a set of all the possible permutations of . If
be a set of all the possible permutations of . If  ,
,  . This means that our ground truth set and the prediction set have two elements each. To find the optimal bipartite matching between the two sets, we search for a specific permutation (order) of the predictions, which gives the lowest cost when matched with the ground truth.
. This means that our ground truth set and the prediction set have two elements each. To find the optimal bipartite matching between the two sets, we search for a specific permutation (order) of the predictions, which gives the lowest cost when matched with the ground truth.
This specific order is defined by  , where
, where  . First, let’s define the cost function to find the optimal permutation ().
. First, let’s define the cost function to find the optimal permutation ().
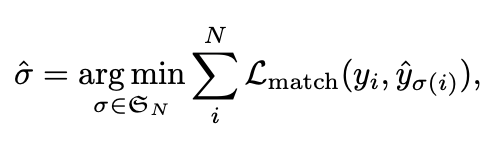
Let us see an example,  the cost function would then look something like this:
the cost function would then look something like this:
- For
 :
: + \mathcal{L}_{\text{match}}(y_{2}, \hat{y}_{2})")
- For
 :
:
 :
: + \mathcal{L}_{\text{match}}(y_{2}, \hat{y}_{2})")
 :
: + \mathcal{L}_{\text{match}}(y_{2}, \hat{y}_{1})")
We will now choose the  that gives us the lowest cost. Upon selecting the permutation that lowers the cost, we eventually get the optimal bipartite matching of the ground truth and the predicted objects. Let’s see this in action in the video below.
that gives us the lowest cost. Upon selecting the permutation that lowers the cost, we eventually get the optimal bipartite matching of the ground truth and the predicted objects. Let’s see this in action in the video below.
Optimize Object Specific Losses 🔧
Now that we have matched the predictions to the ground truth, we apply the Hungarian loss for all matched pairs.
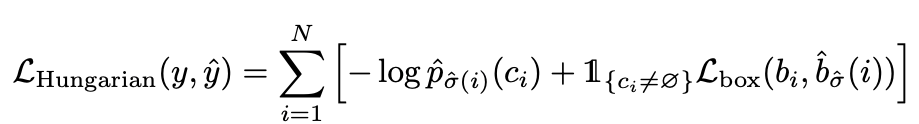
Notice the usage of here that denotes the already optimal permutation for the predictions.
Think of this as the only set of lines in the above diagram that will give you the lowest cost. For example, this is shown in the video below.
Note from the paper: In practice, we down-weight the log-probability term when  by a factor of 10 to account for class imbalance. In the matching cost, we use probabilities instead of log-probabilities. This makes the class prediction term commensurable to
by a factor of 10 to account for class imbalance. In the matching cost, we use probabilities instead of log-probabilities. This makes the class prediction term commensurable to ") , and we observed better empirical performances.
, and we observed better empirical performances.
The L1 loss is commonly used in object detection to measure the difference between the predicted box coordinates and the ground-truth box coordinates. However, this loss can cause issues when dealing with boxes of different sizes.
For instance, consider two boxes with the same relative error (i.e., the same proportion of error compared to the box size) but different sizes. The larger box will have a larger absolute error, which could lead the model to prioritize larger boxes over smaller ones.
A combination of L1 loss and a scale-invariant loss called generalized Intersection over Union (IoU) can address this issue.
The generalized IoU loss measures the overlap between the predicted box and the ground-truth box, considering their sizes. The full expression is shown in the video below.
Using a linear combination of L1 loss and IoU loss, the model can balance the importance of accurately predicting box coordinates and their relative sizes, leading to more consistent performance across boxes of different sizes.
Quiz Time! 🤓
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
As we know by now, DETR has two main components — pièce de résistance, if you will: Set Prediction Loss and Transformer Architecture. In this tutorial, we primarily focused on Set Prediction Loss.
- First, we familiarized ourselves with Object Detection Set Prediction Loss.
- Next, we took a detour to comprehend the workings of Optimal Bipartite Matching.
- Subsequently, we explored how Optimal Bipartite Matching applies to objects.
- Finally, we delved into the mathematics behind optimizing object-specific losses.
In the upcoming and final part of this series, we will reflect on the architecture and intricacies of DETR. We will examine its building blocks, connections, and what makes this model so efficient.
Stay tuned for the upcoming parts of this series, and be sure to share your thoughts and learnings from DETR and what you’re looking forward to. Connect with us on Twitter by tagging @pyimagesearch.
Citation Information
A. R. Gosthipaty and R. Raha. “DETR Breakdown Part 2: Introduction to DEtection TRansformers,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and A. Thanki, eds., 2023, https://pyimg.co/slx2k
@incollection{ARG-RR_2023_DETR-breakdown-part2,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {{DETR} Breakdown Part 2: Introduction to DEtection TRansformers},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/slx2k},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.