
Table of Contents
- Deploying a Custom Image Classifier on an OAK-D
- Introduction
- Configuring Your Development Environment
- Having Problems Configuring Your Development Environment?
- Project Structure
- Deploying the Model on OAK
- Configuring the Prerequisites
- Defining the Utilities
- Classify Images
- Classify Camera Stream
- Summary
Deploying a Custom Image Classifier on an OAK-D
In this tutorial, you will learn to deploy the image classification model on OAK that you trained in the TensorFlow framework in the previous tutorial in the OAK-101 series. With the help of the OpenVINO toolkit, you would convert and optimize the TensorFlow FP32 (32-bit floating point) model to the MyriadX blob file format expected by the Visual Processing Unit of the OAK device. The converted blob file would then run image classification inference on the OAK-D using the DepthAI API.
This lesson is the last in our 4-part series on OAK-101:
- Introduction to OpenCV AI Kit (OAK)
- OAK-D: Understanding and Running Neural Network Inference with DepthAI API
- Training a Custom Image Classification Network for OAK-D
- Deploying a Custom Image Classifier on an OAK-D (this tutorial)
To learn how to deploy and run an image classification network inference on OAK-D, just keep reading.
Deploying a Custom Image Classifier on an OAK-D
Introduction
As a deep learning engineer or practitioner, you may be working in a team building a product that requires you to train deep learning models on a specific data modality (e.g., computer vision) on a daily basis.
As an engineer, your work might include more than just running the deep learning models on a cluster equipped with high-end GPUs and achieving state-of-the-art results on the test data. However, optimizing and deploying those best models onto some edge device allows you to put your deep learning models to actual use in an industry where deployment on edge devices is mandatory and can be a cost-effective solution.
For example, for security, traffic management, manufacturing, healthcare, and agriculture applications, a coin-size edge device like OAK-D can be a great hardware to deploy your deep learning models.
In the previous tutorial of this series, we learned to train a custom image classification network for OAK-D using the TensorFlow framework. The image classification model we trained can classify one of the 15 vegetables (e.g., tomato, brinjal, and bottle gourd).
In today’s tutorial, we will take one step further and deploy the image classification model on OAK-D. First, we would learn the process of converting and optimizing the TensorFlow image classification model and then test the converted model on OAK-D with both images and the OAK device camera stream.
This is the last tutorial in our OAK-101 4-part series, and if you followed the series of tutorials from the beginning, we hope you have built strong foundations of the OpenCV AI Kit. We learned the OAK hardware and software stack from the ground level. With this tutorial, we would also learn to deploy an image classification application on the device.
Now, let’s start with today’s tutorial and learn about the deployment on OAK!
Configuring Your Development Environment
To follow this guide, you need to have depthai, opencv, and imutils installed on your system.
Luckily, all these libraries are pip-installable:
$ pip install depthai $ pip install opencv-python $ pip install imutils
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree .
.
├── classify_camera.py
├── classify_image.py
├── openvino_model
│ ├── vegetable_classifier.bin
│ ├── vegetable_classifier.blob
│ ├── vegetable_classifier.mapping
│ └── vegetable_classifier.xml
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── utils.py
├── results
│ ├── pred_camera.mov
│ └── pred_images
│ ├── bean.jpg
│ ├── bitter_gourd.jpg
│ ├── brinjal.jpg
│ ├── cauliflower.jpg
│ ├── cucumber.jpg
│ ├── papaya.jpg
│ └── radish.jpg
└── test_data
├── bean.jpg
├── bitter_gourd.jpg
├── brinjal.jpg
├── cauliflower.jpg
├── cucumber.jpg
├── papaya.jpg
└── radish.jpg
5 directories, 24 files
In the pyimagesearch directory, we have the following:
config.py: The configuration file for the taskutils.py: The utilities for running the image classification on OAK (e.g., creating pipelines and a few other helper functions)
In the core directory, we have the following:
openvino_model: Houses the image classification trained model files converted to OpenVINO format (.blob) as required by OAK hardwaretest_data: It contains a few vegetable images from the test set, which theclassify_image.pyscript will useclassify_image.py: The inference script to leverage OAK’s neural accelerator for classifying imagesclassify_camera.py: The inference script to run image classification with OAK’s camera
In the results directory, we have:
pred_camera.mov: The prediction output file when inference is performed with OAK’s 4K color camerapred_images: Hosts the prediction results performed on thetest_dataimages
Deploying the Model on OAK
In this section, we will broadly discuss the steps required to deploy your custom deep learning model to the OAK device.
The deep learning model could be in any format like PyTorch, TensorFlow, or Caffe, depending on the framework where the model was trained. Now the goal is to deploy the model on the OAK device and perform inference. However, the limitation is that the OAK device does not directly support any of these frameworks, so we need to convert the model to the MyriadX blob format supported by the OAK device.
The main reason why only a specific model format is required and the prominent deep learning frameworks don’t work directly on an OAK device is that the hardware has a visual processing unit based on Intel’s MyriadX processor, which requires the model in blob file format.
Figure 2 shows the steps required to convert the deep learning model from frameworks like PyTorch or TensorFlow to MyriadX blob file format and deploy them on the OAK device.
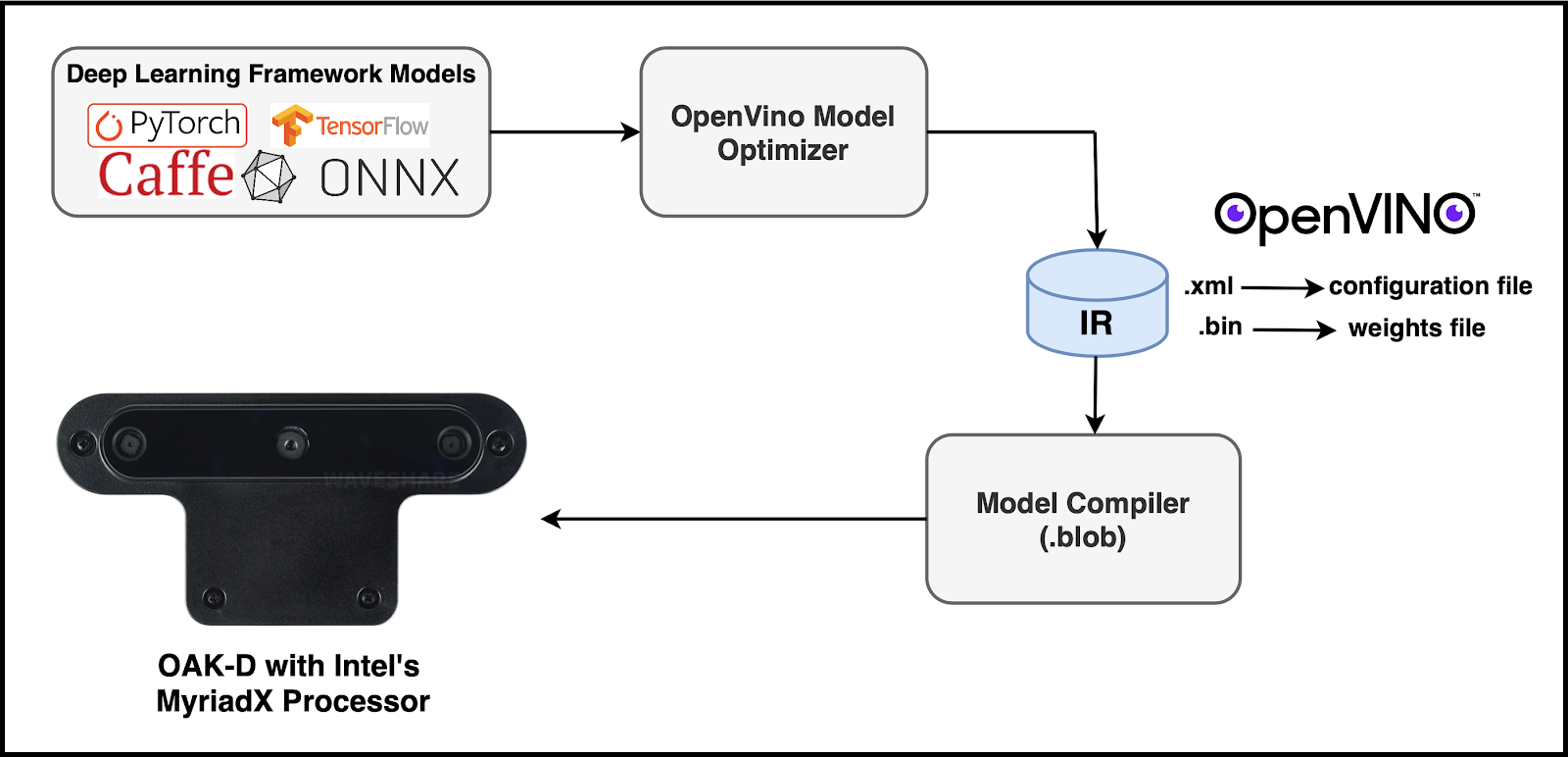
The process of converting the image classification model (in the TensorFlow framework) can be achieved in mainly 4-5 steps:
- Installation and validation of the OpenVINO toolkit 2021.4.752 version
- Converting the image classification TensorFlow model to IR (intermediate representation) using OpenVINO Model Optimizer. The IR consists of the model configuration in
.xmlformat and the weights of the trained model in.binformat. - An optional step is to validate the intermediate representation by running inference on sample test images. It’s a sanity check to ensure the conversion from TensorFlow to IR works as expected.
- Next, we convert the intermediate representation to MyriadX blob file format using the Model Compiler.
- Finally, we can deploy the
.blobfile format on the OAK device and perform inference using the file and DepthAI API software stack.
Launch Jupyter Notebook on Google Colab by clicking on the link above
Most of the heavy lifting in the entire conversion process is done with the OpenVINO toolkit, which takes care of the most important intermediate step. The OpenVINO toolkit consists of a Model Optimizer and a Myriad Compiler.
The Model Optimizer can input any of the mentioned formats (first block Fig. 2) to produce an intermediate representation which can then be compiled to a .blob file format using the MyriadX compiler and finally deployed directly into the OAK device.
Configuring the Prerequisites
Before we start our implementation, let’s review our project’s configuration pipeline. Then, we will move on to the config.py script located in the pyimagesearch directory.
# import the necessary packages
import os
import glob
# define path to the model, test data directory and results
VEGETABLE_CLASSIFIER = os.path.join(
"openvino_model","vegetable_classifier.blob"
)
TEST_DATA = glob.glob("test_data/*.jpg")
OUTPUT_IMAGES = os.path.join("results", "pred_images")
OUTPUT_VIDEO = os.path.join("results", "pred_camera.mov")
# define image height and width, and camera preview dimensions
IMG_DIM = (224, 224)
CAMERA_PREV_DIM = (480, 480)
# define the class label names list
LABELS = [
"Bean", "Bitter_Gourd", "Bottle_Gourd", "Brinjal", "Broccoli",
"Cabbage", "Capsicum", "Carrot", "Cauliflower", "Cucumber",
"Papaya", "Potato", "Pumpkin", "Radish", "Tomato",
]
The config.py script sets up the necessary variables and paths for running the image classification model on images and camera streams to classify vegetables.
On Lines 2 and 3, we import the os and glob modules. Then, from Lines 6-11, we define the following:
- path to the vegetable classifier model
- test data directory
- output locations for images and videos
From Lines 14-22, we also define the dimensions for images and camera previews and a list of class label names to help decode class predictions to human-readable class names.
Defining the Utilities
Now that the configuration has been defined, we can determine the utilities for creating OAK pipelines and a few helper functions for resizing the input and normalizing the predictions. The utils.py script defines several functions:
- Helps create the pipeline for inference on OAK with images
- Pipeline for inference on OAK with color camera stream
- Define a softmax function to convert predictions into probabilities and a function to resize input and swap channel dimensions
Creating the Images Pipeline
# import the necessary packages
from pyimagesearch import config
from pathlib import Path
import numpy as np
import cv2
import depthai as dai
def create_pipeline_images():
print("[INFO] initializing pipeline...")
# initialize a depthai pipeline
pipeline = dai.Pipeline()
# configure inputs for depthai pipeline
classifierIN = pipeline.createXLinkIn()
classifierIN.setStreamName("classifier_in")
On Lines 2-6, we import the necessary packages:
configfrom thepyimagesearchmodulePathfrompathlib, which would help in loading the model from disknumpyfor softmax computationcv2for resizing and other image-related utilitiesdepthailibrary
We define the function create_pipeline_images() on Line 8. Then, a depthai pipeline is initialized on the host, which helps define the nodes, the flow of data, and communication between the nodes (Line 11).
On Lines 14 and 15, we configure the pipeline’s inputs by creating an XLinkIn object and setting the stream name to classifier_in. This stream name is used to specify the input source for the pipeline. In this case, the image classifier model will classify objects in the images.
In short, the XLinkIn, if you recall from the 2nd tutorial of this series, will help send image data from the host to the OAK device, which then would be fed to the classifier for prediction.
# configure vegetable classifier model and set its input
print("[INFO] initializing vegetable classifier network...")
classifierNN = pipeline.create(dai.node.NeuralNetwork)
classifierNN.setBlobPath(
str(Path(config.VEGETABLE_CLASSIFIER).resolve().absolute())
)
classifierIN.out.link(classifierNN.input)
# configure outputs for depthai pipeline
classifierNNOut = pipeline.createXLinkOut()
classifierNNOut.setStreamName("classifier_nn")
classifierNN.out.link(classifierNNOut.input)
# return the pipeline
return pipeline
On Lines 19-22, we create a NeuralNetwork node and set the blob path to the path of the classifier model. We then configured the vegetable classifier model, and this step is similar to how we load weights to a neural network model in TensorFlow or PyTorch.
On Line 23, the classifierNN object is linked to the classifierIN object, which was created earlier to define the input stream name.
Then from Lines 26-31,
- We configure the outputs for the
depthaipipeline by creating anXLinkOutobject. - The output stream name is set to
classifier_nn. This stream name is used to specify the output source for the pipeline, in this case, the output of the neural network classifier. - The
classifierNNobject is linked to theclassifierNNOutobject, which was created to define the output stream name. - Finally, the function returns the pipeline object configured with the classifier model and input/output streams to the calling function.
Creating the Camera Pipeline
def create_pipeline_camera():
print("[INFO] initializing pipeline...")
# initialize a depthai pipeline
pipeline = dai.Pipeline()
# configure vegetable classifier model and set its input
print("[INFO] initializing vegetable classifier network...")
classifierNN = pipeline.create(dai.node.NeuralNetwork)
classifierNN.setBlobPath(
str(Path(config.VEGETABLE_CLASSIFIER).resolve().absolute())
)
Next, we define the create_pipeline_camera() that initializes a depthai pipeline on Line 36. We then define the NeuralNetwork node and set the blob path to the path of the classifier model (Lines 40-43).
This function is similar to the create_pipeline_images() function, but here we do not define the input stream or the XLinkIn node since we would leverage the OAK module’s in-built camera as an input to the image classifier model.
# create and configure the color camera properties
print("[INFO] Creating Color Camera...")
cam_rgb = pipeline.create(dai.node.ColorCamera)
cam_rgb.setPreviewSize(config.CAMERA_PREV_DIM)
cam_rgb.setInterleaved(False)
cam_rgb.setResolution(
dai.ColorCameraProperties.SensorResolution.THE_1080_P
)
cam_rgb.setBoardSocket(dai.CameraBoardSocket.RGB)
cam_rgb.setColorOrder(dai.ColorCameraProperties.ColorOrder.RGB)
Now we create and configure the color camera properties by creating a ColorCamera node and setting the preview size, interleaved status, resolution, board socket, and color order.
From Lines 47-54,
- The
cam_rgbobject is created from the pipeline object, allowing it to be connected to the pipeline. This would act as an input to the classifier model. - Then the
setPreviewSizemethod sets the resolution of the preview window to theCAMERA_PREV_DIMvariable defined earlier inconfig. - Next, the
setInterleaved(False)method disables the interleaved mode. This means the depth and color frames will not be interleaved together. - The
setResolutionmethod sets the camera resolution to 1080p. It can also be set to different resolutions. - The
setBoardSocketmethod connects the camera to the RGB port of the camera board. - Finally, the
setColorOrdermethod sets the order of the color channels to RGB.
# create XLinkOut node for displaying frames
cam_xout = pipeline.create(dai.node.XLinkOut)
# set stream name as rgb
cam_xout.setStreamName("rgb")
# link the camera preview to XLinkOut node input
cam_rgb.preview.link(cam_xout.input)
From Lines 56-61,
- An
XLinkOutnode is created (i.e.,cam_xoutvariable), which would help display frames on the host side. - The stream name is set to
rgb. This name would be passed as a parameter to theOutputQueuefor fetching the color frames. - Then the camera preview is linked to the
XLinkOutnode (cam_xout) input by linking the output of thecam_rgbobject’s preview property to the input of thecam_xoutobject. This allows the frames captured by the color camera to be output to the specified stream, namedrgb. This stream can then be used for displaying or saving video frames.
# resize the camera frames to dimensions expected by neural network
print("[INFO] Creating ImageManip node...")
manip = pipeline.create(dai.node.ImageManip)
manip.initialConfig.setResize(config.IMG_DIM)
# link the camera preview to the manipulation node for resize
cam_rgb.preview.link(manip.inputImage)
# link the output of resized frame to input of neural network
manip.out.link(classifierNN.input)
Then, on Lines 65 and 66, we create the ImageManip node, which is used for image manipulation and the initial configuration of the manipulation node is set with the dimensions defined in the config.IMG_DIM variable.
It then links the camera preview to the manipulation node input by linking the output of the cam_rgb object’s preview property to the input of the manip object on Line 68.
On Line 70, the output of the image manipulation node is then linked to the input of the classifierNN object, which is the neural network classifier model. This allows the camera frames to be passed through the image manipulation node to be resized to the required dimensions before being passed to the classifier model.
# configure outputs for depthai pipeline
xout_nn = pipeline.create(dai.node.XLinkOut)
xout_nn.setStreamName("nn")
classifierNN.out.link(xout_nn.input)
# return the pipeline
return pipeline
On Lines 73-75, we link the classifierNN (image classifier) output to an XLinkOut node, allowing us to display or save the image classification predictions. We would extract the predictions using the nn stream name.
Finally, on Line 78, the function returns the pipeline object, which has been configured with the classifier model, color camera, image manipulation node, and input/output streams.
def softmax(x):
# compute softmax values for each set of scores in x.
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def to_planar(arr: np.ndarray, shape: tuple) -> np.ndarray:
# resize the image array and modify the channel dimensions
resized = cv2.resize(arr, shape)
return resized.transpose(2, 0, 1)
From Lines 80-83, we define the softmax() function, which calculates the softmax values for a given set of scores in x. The softmax function is a commonly used activation function in neural networks, particularly in the output layer, to return the probability of each class.
The to_planar() function takes in two arguments: an array and a tuple representing the shape (Lines 86-89).
- It resizes the array to the given shape using the
cv2library - Then modifies the channel dimensions by transposing the array so that
- the first dimension represents the channels
- the second dimension represents the rows
- the third dimension represents the columns
In short, the to_planar() function helps reshape image data before passing it to the neural network.
Classify Images
With the configurations and utilities implemented, we can finally get into the code walkthrough of classifying images on OAK-D.
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
import os
import numpy as np
import cv2
import depthai as dai
# initialize a depthai images pipeline
print("[INFO] initializing a depthai image pipeline...")
pipeline = utils.create_pipeline_images()
We start by importing the necessary packages, including the config and utils modules from pyimagesearch, and the os, numpy, cv2, and depthai modules on Lines 2-7.
The magic happens on Line 11, where we initialize the depthai images pipeline by calling the create_pipeline_images() function from the utils module.
The create_pipeline_images() function
- Creates and configures a pipeline for running the vegetable classifier model on images.
- The pipeline object returned by the function is assigned to the variable
pipeline. - It would create a pipeline that is ready to process images and perform inference using the
depthailibrary and the vegetable classifier model.
# pipeline defined, now the device is assigned and pipeline is started
with dai.Device(pipeline) as device:
# define the queues that will be used in order to communicate with
# depthai and then send our input image for predictions
classifierIN = device.getInputQueue("classifier_in")
classifierNN = device.getOutputQueue("classifier_nn")
Now that the pipeline is created, a context manager is created using the with statement and the Device class from depthai on Line 14.
It assigns the pipeline object created earlier to the Device class. This will establish a connection between the pipeline and the device, which is necessary for the pipeline to run.
Then on Lines 17 and 18, two queues are defined, classifierIN and classifierNN, that will be used to communicate with the device and send input images for predictions.
The classifierIN variable is assigned the input queue for the classifier_in stream, and the classifierNN variable is assigned the output queue for the classifier_nn stream, defined in the create_pipeline_images() function. These queues will send images to the pipeline for image classification and receive the predictions from the pipeline.
print("[INFO] loading image from disk...")
for img_path in config.TEST_DATA:
# load the input image and then resize it
image = cv2.imread(img_path)
image_copy = image.copy()
nn_data = dai.NNData()
nn_data.setLayer(
"input",
utils.to_planar(image_copy, config.IMG_DIM)
)
classifierIN.send(nn_data)
On Line 21, we start to iterate over the list of image paths stored in the config.TEST_DATA. On Lines 23 and 24, we read the image using cv2 from the disk and create a copy of the original image.
Then on Lines 25-29,
- An
nn_dataobject is created and set to the neural network’s input layer using thesetLayer()method. - The
utils.to_planar()function is called to reshape the image to the dimensions specified in theIMG_DIMvariable of theconfigmodule.
Finally, on Line 30, the send() method of the classifierIN queue is called to send the image to the pipeline for image classification. The pipeline uses the classifier model to classify objects in the image and returns the predictions through the classifierNN queue, which can be used for further processing or display purposes.
print("[INFO] fetching neural network output for {}".
format(img_path.split('/')[1]))
in_nn = classifierNN.get()
# apply softmax on predictions and
# fetch class label and confidence score
if in_nn is not None:
data = utils.softmax(in_nn.getFirstLayerFp16())
result_conf = np.max(data)
if result_conf > 0.5:
result = {
"name": config.LABELS[np.argmax(data)],
"conf": round(100 * result_conf, 2)
}
else:
result = None
On Line 34, the neural network (stored in the variable classifierNN) is used to classify the image, and the output is stored in in_nn. In short, we get the neural network output from the queue.
From Lines 38-47,
- If the output is not
None(i.e., the classification was successful), it applies the softmax function on the output to get the probability scores for each class. - Next, the function extracts the class label by getting the index of the maximum probability and then using it to look up the corresponding label in the
config.LABELSlist. - It also extracts the confidence score by getting the maximum probability value itself.
- If the maximum probability is greater than
0.5, it stores the class label and confidence score in a dictionary and assigns it to theresultvariable. Otherwise, it assignsresulttoNone.
# if the prediction is available,
# annotate frame with prediction and show the frame
if result is not None:
cv2.putText(
image,
"{}".format(result["name"]),
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
0.9,
(255, 255, 255),
thickness=2,
lineType=cv2.LINE_AA
)
cv2.putText(
image,
"Conf: {}%".format(result["conf"]),
(10, 60),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
(255, 255, 255),
thickness=2,
lineType=cv2.LINE_AA
)
cv2.imwrite(
config.OUTPUT_IMAGES +"/"+img_path.split('/')[1],
image
)
Now that we have the image classification prediction for an image, we are all set to display the class label (name) and confidence score (conf) of the image classification on the image itself using the cv2 module.
From Lines 51-76,
- If the classification result is not
None(i.e., the classification was successful), we use thecv2.putText()function to write the class label and confidence score on the image. - The first
cv2.putText()call writes the class label at coordinates(10, 30)on the image, and the second one writes the confidence score at(10, 60). - The
cv2.imwrite()function saves the image with the annotation to the specified location.
Results
Figure 3 shows the image classification results on a few sample test images when fed to the OAK device. From the below figure, we can see that the converted (.blob) and optimized image classification model does pretty well in classifying the test images. However, it misclassified papaya as pumpkin with a confidence score of 52.49%.

Classify Camera Stream
Great! So we just learned how to run neural network inference on images with an OAK device. Let’s now dive one step further and use the OAK’s color camera to classify the frames, which in our opinion, is where you put your OAK module to real use, catering to a wide variety of applications discussed in the 1st blog post of this series.
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
from imutils.video import FPS
import numpy as np
import cv2
import depthai as dai
# initialize a depthai camera pipeline
print("[INFO] initializing a depthai camera pipeline...")
pipeline = utils.create_pipeline_camera()
frame = None
fps = FPS().start()
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter(
config.OUTPUT_VIDEO,
fourcc,
20.0,
config.CAMERA_PREV_DIM
)
On Lines 2-7, we import the necessary packages like config, utils, OpenCV, NumPy, and the depthai library. We also import the FPS module, which would help us compute how long the image classification takes to perform inference on each frame.
On Line 12, we call utils.create_pipeline_camera(), which initializes the depthai pipeline for capturing video frames from the OAK camera and performing image classification.
Then, on Line 15, a new instance of the FPS class is defined, which is used to keep track of the frames per second (FPS) at which the pipeline is running or, let’s say, the time inference takes on an OAK device.
Since we are also interested in saving the prediction of the camera stream as a video, on Line 17, we specify a codec (fourcc) to be used for writing the video and creating a VideoWriter object. The codec being used is XVID.
From Lines 18-23, we define the video writer object, which takes several of the following parameters:
- the output video path along with the filename
- next, we pass the codec defined on Line 17
- the frame rate at which the video will be saved is set to
20.0 - the dimensions of the video frames via the
config.CAMERA_PREV_DIMparameter
# Pipeline defined, now the device is assigned and pipeline is started
with dai.Device(pipeline) as device:
# Output queues will be used to get the rgb frames and
# nn data from the outputs defined above
q_rgb = device.getOutputQueue(name="rgb", maxSize=1, blocking=False)
q_nn = device.getOutputQueue(name="nn", maxSize=1, blocking=False)
Similar to the classifying images section, a context manager is created using the with statement and the Device class from depthai on Line 26.
Inside the block, on Lines 30 and 31,
- We create two output queues, one for the RGB frames and one for the neural network data.
- The first queue,
q_rgb, is created by calling thedevice.getOutputQueue()function, passing in the name of the output queue (rgb), the maximum size of the queue (1), and the blocking parameter (False). - The second queue,
q_nn, is also created in the same way as the first queue, but with the namenninstead ofrgb.
# `get_frame()` fetches frame from OAK,
# resizes and returns the frame to the calling function
def get_frame():
in_rgb = q_rgb.get()
new_frame = np.array(in_rgb.getData())\
.reshape((3, in_rgb.getHeight(), in_rgb.getWidth()))\
.transpose(1, 2, 0).astype(np.uint8)
new_frame = cv2.cvtColor(new_frame, cv2.COLOR_BGR2RGB)
return True, np.ascontiguousarray(new_frame)
result = None
Next, we define a function named get_frame() which
- fetches a frame from the OAK device
- resizes it
- returns the frame to the calling function
On Line 36, we fetch a frame from the q_rgb queue by calling q_rgb.get(). Then, on Lines 37-39,
- Reshape the frame data into a 3-dimensional array, with dimensions (height, width, 3) to match the expected dimensions of an image.
- Transpose the array’s dimensions to (height, width, 3).
- Change the data type of the array to
uint8, which is used to represent 8-bit unsigned integers in NumPy.
On Line 40, the color space of the frame is converted from BGR to RGB using the cv2.cvtColor() function.
Finally, the function returns a tuple containing a Boolean value (True) and the processed frame as a contiguous array on Line 41.
while True:
read_correctly, frame = get_frame()
if not read_correctly:
break
# fetch neural network prediction
in_nn = q_nn.tryGet()
With the frame and neural network data queues defined and the frame postprocessing helper function in place, we start the while loop on Line 45.
In general, the above code runs a loop that captures video frames from the OAK device, processes them, and fetches neural network predictions from the q_nn queue.
On Line 46, we call the get_frame() function to fetch a new frame. The function returns a tuple containing a Boolean value indicating whether the frame was read correctly and the frame itself.
On Lines 48 and 49, we check if the Boolean value is false, which would indicate that the frame was not read correctly. If that’s the case, the loop is broken.
If the Boolean value is true, the code fetches a neural network prediction from the q_nn queue by calling the q_nn.tryGet() function (Line 52).
# apply softmax on predictions and
# fetch class label and confidence score
if in_nn is not None:
data = utils.softmax(in_nn.getFirstLayerFp16())
result_conf = np.max(data)
if result_conf > 0.5:
result = {
"name": config.LABELS[np.argmax(data)],
"conf": round(100 * result_conf, 2)
}
else:
result = None
Now that we have the neural network prediction, we apply a softmax function on the output of the neural network in_nn and then extract the class label and confidence score from the resulting data.
On Lines 56-65,
- We check if the neural network output is not
None. - If not
None, we apply the softmax function on the output to get the probability scores for each class by callingutils.softmax(in_nn.getFirstLayerFp16()). - We extract the confidence score by getting the maximum probability value with
np.max(data). - The function extracts the class label by getting the index of the maximum probability and then using it to look up the corresponding label in the
config.LABELSlist. - If the maximum probability is greater than
0.5, we store the class label and confidence score in a dictionary and assign it to theresultvariable. Otherwise, assignresulttoNone.
# if the prediction is available,
# annotate frame with prediction and display it
if result is not None:
cv2.putText(
frame,
"{}".format(result["name"]),
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
0.9,
(255, 255, 255),
thickness=2,
lineType=cv2.LINE_AA
)
cv2.putText(
frame,
"Conf: {}%".format(result["conf"]),
(10, 60),
cv2.FONT_HERSHEY_SIMPLEX,
0.7,
(255, 255, 255),
thickness=2,
lineType=cv2.LINE_AA
)
On Lines 69-89, the OpenCV library puts text on the frame. The text added to the frame is the class label of the prediction and the confidence score of the prediction made on the frame.
# update the FPS counter
fps.update()
# display the output
cv2.imshow("rgb", frame)
# break out of the loop if `q` key is pressed
if cv2.waitKey(1) == ord('q'):
break
# write the annotated frame to the file
out.write(frame)
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
out.release()
cv2.destroyAllWindows()
From Lines 92-99,
- The frames per second (FPS) counter is updated using the
fps.update()method. - The output image is displayed on the screen using
cv2.imshow("rgb", frame). - If the user presses the
qkey, thewhileloop breaks, and the program continues to execute the next line of code outside the loop.
The output image is also written to a file using out.write(frame) on Line 102. After the loop is broken, the fps.stop() method is called to stop the timer on Line 105.
The elapsed time and approximate FPS are printed to the console on Lines 106 and 107. The out.release() method is then used to release the file, and cv2.destroyAllWindows() is used to close all open windows, effectively ending the program (Lines 110 and 111).
Results
Below are the inference results on the video stream, and the predictions seem good. Initially, the network misclassified capsicum as brinjal. The image classification network achieved 30 FPS real-time speed on the OAK device.
Where to buy an OAK-D
The OAK-D device is available for purchase from a variety of retailers, including:
- Luxonis
- ThinkRobotics
- OpenCV.AI
- Waveshare
The OAK-D device is also available for purchase directly from the OAK-D website.
When purchasing an OAK-D device, it is important to make sure that you are buying from a reputable retailer. The OAK-D device is a powerful and versatile tool, and it is important to make sure that you are getting a genuine product.
Here are some of the factors to consider when choosing a retailer to purchase an OAK-D device from:
- Reputation: Make sure that the retailer has a good reputation and that they are selling genuine OAK-D devices.
- Price: The OAK-D device is a relatively expensive device, so it is important to find a retailer that is offering a competitive price.
- Shipping: Make sure that the retailer offers free shipping or that the shipping costs are reasonable.
- Warranty: Make sure that the retailer offers a warranty on the OAK-D device. This will protect you in case the device is defective or damaged.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
With this, we have come to the end of the OAK-101 series. We hope you enjoyed this series on OpenCV AI Kit as much as we did! But hold tight, as we will soon come back with OAK-102, where we would like to cover a few more advanced computer vision applications using OAK devices.
For now, let’s quickly summarize what we learned today.
In last week’s tutorial, we trained an image classification model on a vegetable image dataset in the TensorFlow framework. In this tutorial, we optimized that trained TensorFlow classification model for the OAK device.
We first learned the model deployment process for OAK; specifically, we discussed the process of taking the deep learning trained model in various frameworks (e.g., TensorFlow, PyTorch, Caffe) to the intermediate representation to the .blob format supported by the OAK device. To achieve this, we discussed the role of the OpenVINO toolkit.
Then, we covered the conversion and optimization process of the trained image classification TensorFlow model to the .blob format. Finally, as a sanity check, we tested the model in Google Colab with some sample vegetable test images before feeding the OAK with the optimized model.
With our image classification model converted to the .blob format, we used the DepthAI API to run inference on OAK with images and camera video streams.
Finally, we examined the classification results of both images and video streams. Then, we computed the end-to-end runtime performance for the video inference pipeline, and the OAK device achieved real-time speed (i.e., 30 FPS).
Citation Information
Sharma, A. “Deploying a Custom Image Classifier on an OAK-D,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2023, https://pyimg.co/tnx0u
@incollection{Sharma_2023_Deploy-CIC-OAK-D,
author = {Aditya Sharma},
title = {Deploying a Custom Image Classifier on an {OAK-D}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/tnx0u},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.