
Table of Contents
- Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time
- Introduction
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- Project Structure
- YOLOv8 Model Export to OAK
- Configuring the Prerequisites
- Defining the Utilities
- Hand Gesture Recognition in Images
- Hand Gesture Recognition in Stream
- Summary
Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time
In this tutorial, you will learn to perform hand gesture recognition using YOLOv8 on the OAK-D platform. In our previous OAK-102 series tutorial:
- We trained the YOLOv8 object detection model in the PyTorch framework using the Ultralytics repository.
- We will take it a step further by deploying the model on the OAK-D device.
- To perform hand gesture recognition on the OAK device, we would optimize the PyTorch model weights into the MyriadX blob file format using the Luxonis toolkit.
- We will then utilize the DepthAI API to run a real-time hand gesture recognition application on the OAK-D device.
By the end of this tutorial, you will have a good understanding of the process involved in deploying an object detection model on the OAK-D platform, as well as the skills to recognize hand gestures using OAK-D’s camera with the help of the DepthAI API in Python.

This lesson is the 2nd in our 3-part series on OAK 102:
- Training the YOLOv8 Object Detector for OAK-D
- Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time (today’s tutorial)
- OAK 102 (lesson 3)
To learn how to run a hand gesture recognition application on OAK-D, just keep reading.
Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time
Introduction
Hand gesture recognition is an emerging field in computer vision focusing on identifying and interpreting human hand gestures using computer vision and deep learning. It has many applications like sign language recognition, human-computer interaction, virtual reality, and gaming.
Computer vision techniques like object detection are used to analyze and interpret images or videos of human movements to recognize hand gestures. However, hand gesture recognition often requires temporal information, which means analyzing the movement of the human body over time for the algorithm to accurately predict the form of the hand gesture.
For instance, if you want to control the volume of your car’s infotainment system through hand gesture recognition, the algorithm must distinguish between volume up and volume down hand gestures. The deep learning model would require temporal information instead of just spatial information to understand the volume up and volume down hand gestures.
Figure 1 shows sample images from the hand gesture recognition dataset with ground-truth bounding boxes annotated in red, belonging to classes four, five, two, and three. In today’s tutorial, we will learn to recognize one of these five hand gestures using the OAK-D platform.

If you’re interested in the capabilities of an OAK device and the computer vision applications it can run, check out the Introduction to OpenCV AI Kit (OAK) tutorial on PyImageSearch. Specifically, you should look at the Applications on OAK section of the tutorial.
If you followed our previous tutorial on the OAK-102 series, you would be familiar with training a state-of-the-art YOLOv8 object detector using PyTorch with Ultralytics repository, which can recognize hand gestures like one, two, and three. The YOLOv8 model was pretrained on the MS COCO dataset and fine-tuned on only 587 hand gesture images. Despite the small number of images used for training, the model performed surprisingly well, achieving 0.824 mAP@0.5 IoU with the Nano variant and 0.887 mAP@0.5 IoU with the Small variant.
This tutorial will take it further and show you how to deploy the hand gesture recognition model onto the OAK-D device. We will first use the Luxonis toolkit to convert and optimize the PyTorch model for hand gesture recognition into the MyriadX blob file format to accomplish this. Next, we will run the converted model on the OAK-D device using still images and the camera stream.
How would you like immediate access to 3,457 images curated and labeled with hand gestures to train, explore, and experiment with … for free. Head over to Roboflow and get a free account to grab these hand gesture images.
Let’s start with today’s tutorial and delve into deploying and running hand gesture recognition applications on the OAK device without further ado.
Configuring Your Development Environment
To follow this guide, you need to have depthai, opencv, and imutils libraries installed on your system.
Luckily, all these libraries are pip-installable:
$ pip install depthai $ pip install opencv-python $ pip install imutils
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in minutes.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code on your Windows, macOS, or Linux system now?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree . . ├── gesture_recognition_model │ ├── yolov8n │ │ ├── yolov8ntrained-simplified.onnx │ │ ├── yolov8ntrained.bin │ │ ├── yolov8ntrained.json │ │ ├── yolov8ntrained.xml │ │ └── yolov8ntrained_gesture_recog.blob │ └── yolov8s │ ├── yolov8strained-simplified.onnx │ ├── yolov8strained.bin │ ├── yolov8strained.json │ ├── yolov8strained.xml │ └── yolov8strained_gesture_recog.blob ├── pyimagesearch │ ├── __init__.py │ ├── config.py │ └── utils.py ├── recognize_camera.py ├── recognize_images.py ├── results │ ├── gesture_camera_v8n.mp4 │ ├── gesture_camera_v8s.mp4 │ ├── gesture_pred_images_v8n │ │ ├── five.jpg │ │ ├── five_2.jpg │ │ ├── four.jpg │ │ ├── one.jpg │ │ ├── three.jpg │ │ └── two.jpg │ └── gesture_pred_images_v8s │ ├── five.jpg │ ├── five_2.jpg │ ├── four.jpg │ ├── one.jpg │ ├── three.jpg │ └── two.jpg ├── test_data │ ├── five.jpg │ ├── five_2.jpg │ ├── four.jpg │ ├── one.jpg │ ├── three.jpg │ └── two.jpg └── test_images 9 directories, 35 files
In the pyimagesearch directory, we have the following files:
config.py: The configuration file for the taskutils.py: The utilities for running the hand gesture recognition on OAK (e.g., creating images and camera pipelines and a few other helper functions)
In the core directory, we have the following:
gesture_recognition_model: Houses the hand gesture recognition trained model files converted to OpenVINO format (.blob) as required by OAK hardware for both YOLOv8n and YOLOv8stest_data: It contains a few hand gesture images from the test set, which therecognize_images.pyscript will userecognize_images.py: The inference script to leverage OAK’s neural accelerator for recognizing hand gestures in imagesrecognize_camera.py: The inference script to run hand gesture recognition with OAK’s color camera
In the results directory, we have:
gesture_pred_images_v8n: Hosts the prediction results performed on thetest_dataimages with the YOLOv8n modelgesture_pred_images_v8s: Hosts the prediction results performed on thetest_dataimages with the YOLOv8s modelgesture_camera_v8n.mp4: The prediction output file when inference is performed with OAK’s 4K color camera leveraging the YOLOv8n modelgesture_camera_v8s.mp4: The prediction output file when inference is performed with OAK’s 4K color camera leveraging the YOLOv8s model
YOLOv8 Model Export to OAK
In this section, we will discuss the steps required to convert the YOLOv8n and YOLOv8s hand gesture recognition models (in PyTorch framework) to MyriadX blob file format.
For a better understanding of this and the following sections of this tutorial, we highly recommend you check out our previous tutorial on Training the YOLOv8 Object Detector for OAK-D.
By now, you already know that the OAK device is not directly compatible with the popular deep learning frameworks, necessitating the conversion of the model into the MyriadX blob file format, which the device supports.
The underlying reason for this specific model format requirement, and the incompatibility of the widely used deep learning frameworks with the OAK device, is the presence of a visual processing unit within the hardware. This unit is built on Intel’s MyriadX processor, which mandates using the blob file format for models.
To export a YOLOv8 model for deployment on an OAK device, you need to follow several steps to convert the model into the MyriadX blob file format. Here’s a step-by-step guide:
- Model Conversion: First, you need to convert the YOLOv8 model from its native format (typically PyTorch or TensorFlow) to an intermediate format called ONNX (Open Neural Network Exchange).
- Optimization: To ensure optimal performance on the OAK device, you need to optimize the ONNX model using OpenVINO’s Model Optimizer. This step will generate an Intermediate Representation (IR) consisting of two files: an XML file containing the model architecture and a BIN file containing the model weights.
- Blob Conversion: Use OpenVINO’s
compile_toolto convert the optimized IR model to a MyriadX blob file format.
Luckily, Luxonis offers a convenient tool that streamlines converting YOLOv5-v8 PyTorch models to the MyriadX blob file format. For example, in this tutorial, we aim to deploy a YOLOv8 hand gesture recognition model developed in the PyTorch framework on an OAK device for recognizing hand gestures. Hence, this tool is valuable in assisting us with the YOLOv8 PyTorch model conversion to the MyriadX blob file format.
The following steps will guide you through generating MyriadX blob files for YOLOv8n and YOLOv8s models:
- Assuming you’ve completed the previous tutorial, you should have fine-tuned YOLOv8n and YOLOv8s PyTorch model weights (using the hand gesture recognition dataset) saved on your local machine.
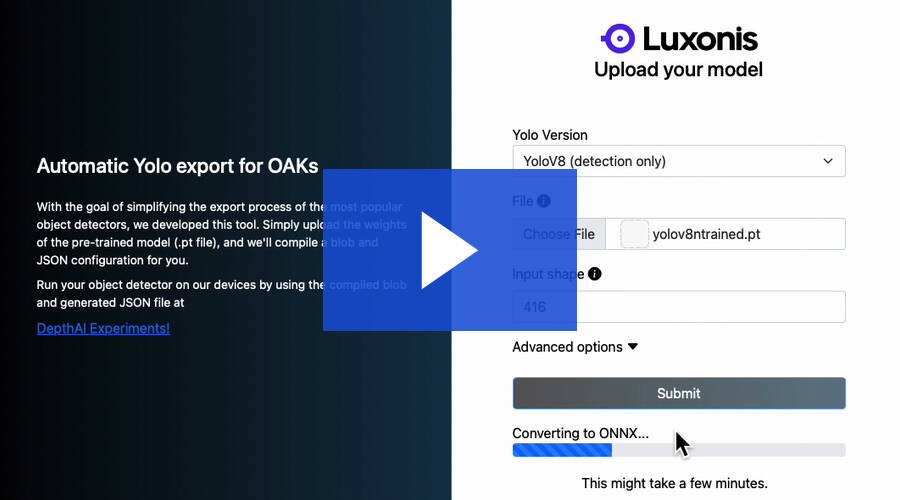
- Navigate to the Automatic Yolo exports for OAKs page.
- As demonstrated in the GIF, set the Yolo Version to “YoloV8 (detection only).”
- In the File section, upload the
yolov8ntrained.ptweights. - Set the Input shape to
416. - Repeat the above steps for the YOLOv8s model, but this time upload the
yolov8strained.ptweights in the File parameter.
Please click the image below to follow the steps to generate the MyriadX blob files for both the YOLOv8n and YOLOv8s models.
Deploy on OAK device: Having generated the blob file, we can proceed to the following section. We will deploy the YOLOv8 model on an OAK device (either OAK-1 or OAK-D) utilizing the DepthAI library.
Configuring the Prerequisites
Before we start our implementation, let’s review our project’s configuration. For that, we will move on to the config.py script located in the pyimagesearch directory.
The config.py script sets up the necessary paths for the YOLOv8n and YOLOv8s models, their configurations, test data, and output directories for the resulting images and videos. It also defines the camera preview dimensions and label names for the hand gestures.
# import the necessary packages
import os
import glob
# define path to the model, test data directory and results
YOLOV8N_MODEL = os.path.join(
"gesture_recognition_model","yolov8n","yolov8ntrained_gesture_recog.blob"
)
YOLOV8N_CONFIG = os.path.join(
"gesture_recognition_model","yolov8n","yolov8ntrained.json"
)
YOLOV8S_MODEL = os.path.join(
"gesture_recognition_model","yolov8s","yolov8strained_gesture_recog.blob"
)
YOLOV8S_CONFIG = os.path.join(
"gesture_recognition_model","yolov8s","yolov8strained.json"
)
TEST_DATA = glob.glob("test_data/*.jpg")
OUTPUT_IMAGES_YOLOv8n = os.path.join("results", "gesture_pred_images_v8n")
OUTPUT_IMAGES_YOLOv8s = os.path.join("results", "gesture_pred_images_v8s")
OUTPUT_VIDEO_YOLOv8n = os.path.join("results", "gesture_camera_v8n.mp4")
OUTPUT_VIDEO_YOLOv8s = os.path.join("results", "gesture_camera_v8s.mp4")
# define camera preview dimensions same as YOLOv8 model input size
CAMERA_PREV_DIM = (416, 416)
# define the class label names list
LABELS = ["Five", "Four", "One", "Three", "Two"]
On Lines 2 and 3, we import the os and glob modules. Then, from Lines 6-19, we define the following:
- path to the YOLOv8n and YOLOv8s hand gesture recognition models
- test data directory
- output locations for saving inference results of YOLOv8n and YOLOv8s on images and videos
From Lines 28-31, we also define the camera preview dimension and a list of class label names to help decode class predictions to human-readable class names.
Defining the Utilities
Now that the configuration has been defined, we can determine the utilities for creating images, camera DepthAI pipelines, and a few helper functions. The utils.py script defines several functions:
- Helps create the pipeline for hand gesture recognition on OAK with images
- Pipeline for hand gesture recognition on OAK with color camera stream
- Define a few helper functions for loading configuration files, annotating camera frames, and normalizing the predictions
Creating the Images Pipeline
# import the necessary packages
from pyimagesearch import config
import json
import numpy as np
import cv2
from pathlib import Path
import depthai as dai
def create_image_pipeline(config_path, model_path):
# initialize a depthai pipeline
pipeline = dai.Pipeline()
# load model config file and fetch nn_config parameters
print("[INFO] loading model config...")
configPath = Path(config_path)
model_config = load_config(configPath)
nnConfig = model_config.get("nn_config", {})
On Lines 2-7, we import the necessary packages like config from the pyimagesearch module, json for loading model configuration files, cv2 for image-related operations, and most importantly, the depthai module along with the numpy and Path modules.
We define the function create_images_pipeline() that takes config_path and model_path as input parameters on Line 9. Then, a depthai pipeline is initialized on the host, which helps define the nodes, the flow of data, and communication between the nodes (Line 11).
On Lines 15 and 16, we load the model configuration file using the provided config_path and extract the nn_config object from the model configuration on Line 17.
print("[INFO] extracting metadata from model config...")
# using nnConfig extract metadata like classes,
# iou and confidence threshold, number of coordinates
metadata = nnConfig.get("NN_specific_metadata", {})
classes = metadata.get("classes", {})
coordinates = metadata.get("coordinates", {})
anchors = metadata.get("anchors", {})
anchorMasks = metadata.get("anchor_masks", {})
iouThreshold = metadata.get("iou_threshold", {})
confidenceThreshold = metadata.get("confidence_threshold", {})
On Line 22, we extract the relevant metadata NN_specific_metadata using the nnConfig variable. With the help of metadata, we extract information like classes, coordinates, anchors, iouThreshold, and confidenceThreshold. We would pass this information to the detection network node later.
print("[INFO] configuring inputs and output...")
# configure inputs for depthai pipeline
# since this pipeline is dealing with images an XLinkIn node is created
detectionIN = pipeline.createXLinkIn()
# create a Yolo detection node
detectionNetwork = pipeline.create(dai.node.YoloDetectionNetwork)
# create a XLinkOut node for fetching the neural network outputs to host
nnOut = pipeline.create(dai.node.XLinkOut)
print("[INFO] setting stream names for queues...")
# set stream names used in queue to fetch data when the pipeline is started
nnOut.setStreamName("nn")
detectionIN.setStreamName("detection_in")
Next, we create inputs for the depthai pipeline. First, we create an XLinkIn() node since this pipeline deals with images on Line 33. Then, a YoloDetectionNetwork node is created for performing detection and an XLinkOut node for sending the neural network output to the host on Lines 35-37.
On Lines 41 and 42, we set the output stream names, which would later be used in the queue to fetch image and neural network data when the pipeline is started.
print("[INFO] setting YOLO network properties...")
# network specific settings - parameters read from config file
# confidence and iou threshold, classes, coordinates are set
# most important the model .blob file is used to load weights
detectionNetwork.setConfidenceThreshold(confidenceThreshold)
detectionNetwork.setNumClasses(classes)
detectionNetwork.setCoordinateSize(coordinates)
detectionNetwork.setAnchors(anchors)
detectionNetwork.setAnchorMasks(anchorMasks)
detectionNetwork.setIouThreshold(iouThreshold)
detectionNetwork.setBlobPath(model_path)
detectionNetwork.setNumInferenceThreads(2)
detectionNetwork.input.setBlocking(False)
With the detectionNetwork node defined, we set the YOLO network properties based on the metadata extracted from the model configuration file from Lines 48-56. One important thing to note is that we load the model weights (i.e., setBlobPath) on Line 54 by passing the model_path as a parameter for the YOLO model.
print("[INFO] creating links...")
# linking the nodes - image node output is linked to detection node
# detection network node output is linked to XLinkOut input
detectionIN.out.link(detectionNetwork.input)
detectionNetwork.out.link(nnOut.input)
# return the pipeline to the calling function
return pipeline
On Lines 61 and 62, we link the detectionIN ( XLinkIn node) output to the YOLO detection network node (detectionNetwork) input and the YOLO detection network node output to the nnOut (XLinkOut node) input.
Finally, the pipeline object is returned to the calling function on Line 65.
Creating the Camera Pipeline
def create_camera_pipeline(config_path, model_path):
# initialize a depthai pipeline
pipeline = dai.Pipeline()
# load model config file and fetch nn_config parameters
print("[INFO] loading model config...")
configPath = Path(config_path)
model_config = load_config(configPath)
nnConfig = model_config.get("nn_config", {})
print("[INFO] extracting metadata from model config...")
# using nnConfig extract metadata like classes,
# iou and confidence threshold, number of coordinates
metadata = nnConfig.get("NN_specific_metadata", {})
classes = metadata.get("classes", {})
coordinates = metadata.get("coordinates", {})
anchors = metadata.get("anchors", {})
anchorMasks = metadata.get("anchor_masks", {})
iouThreshold = metadata.get("iou_threshold", {})
confidenceThreshold = metadata.get("confidence_threshold", {})
# output of metadata - feel free to tweak the threshold parameters
#{'classes': 5, 'coordinates': 4, 'anchors': [], 'anchor_masks': {},
# 'iou_threshold': 0.5, 'confidence_threshold': 0.5}
print(metadata)
We define the function create_camera_pipeline() that takes config_path and model_path as input parameters on Line 67.
The rest of the code from Lines 69-86 is the same as we defined in the create_images_pipeline() function, so we skip the explanation here. But generally, we initialize a pipeline, load the configuration file, and extract metadata from the configuration file.
print("[INFO] configuring source and outputs...")
# define sources and outputs
# since OAK's camera is used in this pipeline
# a color camera node is defined
camRgb = pipeline.create(dai.node.ColorCamera)
# create a Yolo detection node
detectionNetwork = pipeline.create(dai.node.YoloDetectionNetwork)
xoutRgb = pipeline.create(dai.node.XLinkOut)
# create a XLinkOut node for getting the detection results to host
nnOut = pipeline.create(dai.node.XLinkOut)
print("[INFO] setting stream names for queues...")
# set stream names used in queue to fetch data when the pipeline is started
xoutRgb.setStreamName("rgb")
nnOut.setStreamName("nn")
We now establish input and output nodes for the camera pipeline, which differs from the previously defined image pipeline. The input source is an OAK device camera rather than images in this case.
On Lines 97-102, we create the following nodes:
ColorCamera: an input to the detection networkYoloDetectionNetwork: for performing inferenceXLinkOut: for displaying the detection results on the host computer
Then on Lines 106 and 107, we set stream names from respective xoutRgb and nnOut nodes to rgb and nn, which would be passed as a parameter to the OutputQueue for fetching the color frames and detections.
print("[INFO] setting camera properties...")
# setting camera properties like the output preview size,
# camera resolution, color channel ordering and FPS
camRgb.setPreviewSize(config.CAMERA_PREV_DIM)
camRgb.setResolution(dai.ColorCameraProperties.SensorResolution.THE_1080_P)
camRgb.setInterleaved(False)
camRgb.setColorOrder(dai.ColorCameraProperties.ColorOrder.BGR)
camRgb.setFps(40)
On Lines 112-116, we configure the camRgb (ColorCamera node) properties, such as setting the preview window resolution, selecting 1080P as the camera resolution, defining the color channel order as BGR, and establishing a camera frame rate of 40 FPS.
print("[INFO] setting YOLO network properties...")
# network specific settings - parameters read from config file
# confidence and iou threshold, classes, coordinates are set
# most important the model .blob file is used to load weights
detectionNetwork.setConfidenceThreshold(confidenceThreshold)
detectionNetwork.setNumClasses(classes)
detectionNetwork.setCoordinateSize(coordinates)
detectionNetwork.setAnchors(anchors)
detectionNetwork.setAnchorMasks(anchorMasks)
detectionNetwork.setIouThreshold(iouThreshold)
detectionNetwork.setBlobPath(model_path)
detectionNetwork.setNumInferenceThreads(2)
detectionNetwork.input.setBlocking(False)
print("[INFO] creating links...")
# linking the nodes - camera stream output is linked to detection node
# RGB frame is passed through detection node linked with XLinkOut
# used for annotating the frame with detection output
# detection network node output is linked to XLinkOut input
camRgb.preview.link(detectionNetwork.input)
detectionNetwork.passthrough.link(xoutRgb.input)
detectionNetwork.out.link(nnOut.input)
# return the pipeline to the calling function
return pipeline
We can omit the explanation of Lines 122-130 since they are identical to the steps we performed while constructing the image pipeline.
Lines 137-139 create connections between the nodes in the DepthAI pipeline:
camRgb.preview.link(detectionNetwork.input): This line connects the output of thecamRgb.previewnode (camera RGB preview) to the input of thedetectionNetworknode (YoloDetectionNetwork). This connection provides the camera’s RGB preview data as input to the object detection network.detectionNetwork.passthrough.link(xoutRgb.input): This line links the passthrough output of thedetectionNetworknode to the input of thexoutRgbnode (XLinkOut). The passthrough output provides the original input image (RGB preview) to be sent to the host and the object detection results. This passthrough connection also helps maintain the synchronization between the RGB frames and the detection results.detectionNetwork.out.link(nnOut.input): This line connects the output of thedetectionNetworknode (YoloDetectionNetwork) to the input of thennOutnode (XLinkOut). This node forwards the object detection results to the host for further processing or display.
The above connections establish a pipeline where the camera RGB preview data is input for the YOLO object detection network. The original input image and the detection results are sent to the host.
Finally, the pipeline object is returned to the calling function on Line 142.
Defining a Few Helper Functions
def load_config(config_path):
# open the config file and load using json module
with config_path.open() as f:
config = json.load(f)
return config
def annotateFrame(frame, detections, model_name):
# loops over all detections in a given frame
# annotates the frame with model name, class label,
# confidence score, and draw bounding box on the object
color = (0, 0, 255)
for detection in detections:
bbox = frameNorm(frame, (detection.xmin, detection.ymin, detection.xmax, detection.ymax))
cv2.putText(frame, model_name, (20, 40), cv2.FONT_HERSHEY_TRIPLEX, 1,
color)
cv2.putText(frame, config.LABELS[detection.label], (bbox[0] + 10, bbox[1] + 25), cv2.FONT_HERSHEY_TRIPLEX, 1,
color)
cv2.putText(frame, f"{int(detection.confidence * 100)}%", (bbox[0] + 10, bbox[1] + 60),
cv2.FONT_HERSHEY_TRIPLEX, 1, color)
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color, 2)
return frame
On Lines 145-149, we define the load_config() function that takes config_path as an argument, opens the configuration file using context managers, and reads its contents. The file’s contents are loaded as a JSON object using the json module and returned to the calling function.
Next, on Lines 151-165, the annotateFrame() method is defined, which takes the following three arguments as an input:
frame: The input image/frame.detections: A list of detected objects in the frame provided by the YOLOv8 object detection network.model_name: The name of the model used for object detection (YOLOv8n/YOLOv8s).
Then the function iterates over each detection in the detections list on Line 156. For each detection, it does the following:
- normalizes the bounding box coordinates using the
frameNormfunction (not shown in the provided code discussed later) - annotates the frame with the
model_namein the top-left corner - annotates the frame with the class label of the detected object using the corresponding label from the
config.LABELSlist - annotates the frame with the detected object’s confidence score (percentage)
- draws a bounding box around the detected object using the
cv2.rectanglefunction
Finally, on Line 165, the annotateFrame function returns the annotated frame after adding the model name, class labels, confidence scores, and bounding boxes for each detected object. This annotated frame can be displayed, saved, or used for further processing.
def to_planar(arr: np.ndarray, shape: tuple) -> np.ndarray: # resize the image array and modify the channel dimensions resized = cv2.resize(arr, shape) return resized.transpose(2, 0, 1) def frameNorm(frame, bbox): # nn data, being the bounding box locations, are in <0..1> range # normalized them with frame width/height normVals = np.full(len(bbox), frame.shape[0]) normVals[::2] = frame.shape[1] return (np.clip(np.array(bbox), 0, 1) * normVals).astype(int)
On Lines 168-171, we define the to_planar() method; it accepts two parameters as input
arr: a numpy array, which represents the input image andshape: a tuple representing the desired shape for the output image
The purpose of the to_planar() method is to resize a given numpy array (image) to the desired shape and modify the channel dimensions using the transpose function.
On Line 173, the frameNorm() function accepts input parameters
frame: a numpy array representing input frame/imagebbox: list or numpy array containing the bounding box locations in the normalized range from0to1
The function normalizes the bounding box locations with respect to the frame dimensions. On Lines 176-178:
- A
normValsnumpy array is initialized with the same length as the input bounding box array and is filled with the frame’s height. - Then, every alternate value in
normValsis set to the frame’s width. - The input bounding box values are clipped to the range
[0, 1]and multiplied by thenormValsto scale the bounding box coordinates to the frame dimensions. - Finally, the scaled bounding box coordinates are converted to integers using the
astype(int)method.
Hand Gesture Recognition in Images
With the configurations and utilities implemented, we can finally get into the code walkthrough of recognizing hand gestures in images with OAK-D.
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
import argparse
import cv2
import depthai as dai
# parse arguments
parser = argparse.ArgumentParser()
parser.add_argument("-m", "--model", help="Provide model name for inference",
default='yolov8n', type=str)
args = parser.parse_args()
We start by importing the necessary packages on Lines 6-10:
configmodule from thepyimagesearchpackage, which contains configuration settings or constantsutilsfrom thepyimagesearchpackage, which provides utility functions for creating image and camera pipelinesargparsefor parsing command line argumentscv2for performing image and video processing tasksdepthaimodule for creating DepthAI pipelines for OAK-D
Then, on Lines 13-16, we create a command line argument -m or --model where users can provide the model name for hand gesture recognition which can be either YOLOv8n or YOLOv8s.
# initialize a depthai camera pipeline
print("[INFO] initializing a depthai images pipeline...")
model_name = args.model
# if the model for inference is nano variant create image pipeline
# with nano variant config file and model weights
if model_name.lower() == "yolov8n":
pipeline = utils.create_image_pipeline(config_path=config.YOLOV8N_CONFIG,
model_path=config.YOLOV8N_MODEL)
output_image_path = config.OUTPUT_IMAGES_YOLOv8n
# if the model for inference is small variant create image pipeline
# with small variant config file and model weights
else:
pipeline = utils.create_image_pipeline(config_path=config.YOLOV8S_CONFIG,
model_path=config.YOLOV8S_MODEL)
output_image_path = config.OUTPUT_IMAGES_YOLOv8s
On Line 21, we assign the model name provided via command line arguments to the model_name variable.
Then from Lines 24-34:
- If the model name equals
yolov8n, we create an image pipeline using the utility functionutils.create_image_pipelinewith the YOLOv8 Nano variant configuration file and model weights (specified in theconfigmodule). Also, via theconfigmodule, set theoutput_image_pathvariable to the appropriate output directory for the YOLOv8 Nano variant. - If the model name is not
yolov8n, then we perform the same steps as above, but only this time, we initialize the image pipeline with YOLOv8 Small variant configuration and model weights file.
In summary, the code initializes an image pipeline using the DepthAI library. Then, it sets up the appropriate configuration, model weights, and output image path based on the model name provided by the user.
# pipeline defined, now the device is assigned and pipeline is started
with dai.Device(pipeline) as device:
# define the queues that will be used in order to communicate with
# depthai and then send our input image for predictions
detectionIN = device.getInputQueue("detection_in")
detectionNN = device.getOutputQueue("nn")
print("[INFO] loading image from disk...")
for img_path in config.TEST_DATA:
# load the input image and then resize it
image = cv2.imread(img_path)
image_res = cv2.resize(image, config.CAMERA_PREV_DIM)
# create a copy of image for inference
image_copy = image.copy()
# initialize depthai NNData() class which is fed with the
# image data resized and transposed to model input shape
nn_data = dai.NNData()
nn_data.setLayer(
"input",
utils.to_planar(image_copy, config.CAMERA_PREV_DIM)
)
# send the image to detectionIN queue further passed
# to the detection network for inference as defined in pipeline
detectionIN.send(nn_data)
Next, on Lines 37-59, we set up the DepthAI device and process a list of test images for recognizing hand gestures using the previously initialized pipeline. The input images are resized and preprocessed before being fed to the YOLO network for inference. The processed images are then sent to the DepthAI device for hand gesture recognition.
On Line 37, we create a context for the DepthAI device using the with statement, which ensures that the device is properly closed after use. The device is initialized with the previously created pipeline.
Two queues for communicating with the OAK device are defined on Lines 40 and 41:
detectionIN: input queue for sending images to the device for detectiondetectionNN: output queue for receiving the detection results from the device
On Lines 44-59, we iterate over the test images specified in the config.TEST_DATA variable. For each test image, we
- load the image using the
cv2.imreadfunction - resize the loaded image to the dimensions specified in
config.CAMERA_PREV_DIMusing thecv2.resizemethod - create a copy of the loaded image for preprocessing
- initialize a
dai.NNData()object to store the preprocessed image data - preprocess the copied image to the model input shape and set the preprocessed image data as the input layer of the
dai.NNData()object - send the preprocessed image data to the
detectionINqueue, which is further passed to the YOLO detection network for inference as defined in the image pipeline inutils.py
print("[INFO] fetching neural network output for {}".
format(img_path.split('/')[1]))
# fetch the neural network output
inDet = detectionNN.get()
# if detection is available for given image, fetch the detections
if inDet is not None:
detections = inDet.detections
# if object detected, annotate the image
image_res = utils.annotateFrame(image_res, detections, args.model.lower())
# finally write the image to the output path
cv2.imwrite(
output_image_path +"/"+img_path.split('/')[1],
image_res
)
With the image loaded from the disk, preprocessed, and inferred with the YOLO detection network, as a final step, we now fetch the neural network predictions (hand gesture recognition) for each test image, annotate the image with the detections, and finally save the annotated image to the disk.
On Line 64, we fetch the neural network output for the current image using the detectionNN.get() method and store the result in the inDet variable.
Next, on Lines 66-70, we check if the fetched neural network output is not None, meaning detections are available for the given image:
- If detections are available, extract them from the
inDetobject using the detections attribute and store them in the detections variable. - Annotate the resized image (
image_res) with the detections using theutils.annotateFramefunction. The function, as discussed before, draws bounding boxes and labels for each detected object on the image.
Finally, on Lines 73-76, the annotated image is written to the output path using the cv2.imwrite function.
Results
Great! Now that we have completed implementing the code for hand gesture recognition in images, it’s time to examine the results.
Figure 3 displays the hand gesture recognition outcomes on several test images using YOLOv8n when supplied to the OAK device. The figure shows that the converted (.blob) and optimized hand gesture recognition model identifies hand gestures in the test images well. However, among the six samples:
- one False Positive (2nd row, 3rd image classified
oneastwo) - one False Negative (1st row, 2nd image failed to recognize hand gesture
fivethough it was tough).

Figure 4 showcases the hand gesture recognition results using the YOLOv8s variant on the same sample test images when executed on the OAK device. As observed in the figure, the YOLOv8s variant performed slightly better than the YOLOv8n variant, as it detected the hand gesture five (in the 1st row, 2nd image). However, this time the model failed to detect the hand gesture one (in the 2nd row, 3rd image), resulting in one False Negative.
Nonetheless, the overall performance was impressive. It would be intriguing to compare the performance of YOLOv8s and YOLOv8n when running hand gesture recognition on a camera stream.

We can safely conclude that our DepthAI implementation for hand gesture recognition in images is effective. However, the minor inaccuracies observed in the test images depend on the model, which could potentially be improved for even better performance.
Hand Gesture Recognition in Camera Stream
Fantastic! We have now acquired the skill of identifying hand gestures in images using an OAK device. Next, it’s time to take things to the next level and utilize the OAK’s color camera to categorize the frames. This transition to leveraging OAK’s camera stream is where we believe the OAK module truly shines in practical application.
# import the necessary packages
from pyimagesearch import config
from pyimagesearch import utils
from imutils.video import FPS
import argparse
import time
import cv2
import depthai as dai
# parse arguments
parser = argparse.ArgumentParser()
parser.add_argument("-m", "--model", help="Provide model name for inference",
default='yolov8n', type=str)
args = parser.parse_args()
We start by importing the necessary packages on Lines 6-12
configandutilsmodules from thepyimagesearchpackage, which contains configuration settings/constants and utility functions for creating OAK pipelinesFPSmodule fromimutils.videohelps us compute how long the hand gesture recognition takes to perform inference on each frameargparsefor parsing command line argumentscv2for performing image and video processing tasksdepthaimodule for creating DepthAI pipelines for OAK
Then, on Lines 15-18, we create a command line argument -m or --model where users can provide the model name for hand gesture recognition which can be either YOLOv8n or YOLOv8s.
When the script is run, args will be a namespace object containing the values of any arguments passed to the script. If the -m argument is not provided, args.model will have the default value of yolov8n. If the -m argument is provided, its value will be stored in args.model.
# initialize a depthai camera pipeline
print("[INFO] initializing a depthai camera pipeline...")
model_name = args.model
# if the model for inference is nano variant create camera pipeline
# with nano variant config file and model weights
if model_name.lower() == "yolov8n":
pipeline = utils.create_camera_pipeline(config_path=config.YOLOV8N_CONFIG,
model_path=config.YOLOV8N_MODEL)
output_video = config.OUTPUT_VIDEO_YOLOv8n
# if the model for inference is small variant create camera pipeline
# with small variant config file and model weights
else:
pipeline = utils.create_camera_pipeline(config_path=config.YOLOV8S_CONFIG,
model_path=config.YOLOV8S_MODEL)
output_video = config.OUTPUT_VIDEO_YOLOv8s
# set the video codec to use with video writer
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
# create video writer object with parameters: output video path,
# video codec, frame rate of output video, and dimensions of video frame
out = cv2.VideoWriter(
output_video,
fourcc,
20.0,
config.CAMERA_PREV_DIM
)
On Lines 22-36, we initialize a depthai camera pipeline for hand gesture recognition using the YOLOv8 Nano or Small model.
Based on the model variant (determined by args.model), we select the appropriate configuration file and model weights for the YOLOv8 Nano or Small variant on Lines 26-36:
- If the model variant is YOLOv8 Nano (
yolov8n), it creates a camera pipeline with the configuration file and model weights specified for the Nano variant. - If the model variant is not YOLOv8 Nano, it assumes the model is the Small variant (
yolov8s). It creates a camera pipeline with the configuration file and model weights specified for the Small variant.
We also set the output_video path where the inference results will be stored as a video.
Next, on Line 39, we set the video codec to MJPG using the cv2.VideoWriter_fourcc function.
Finally, on Lines 42-47, we create an OpenCV VideoWriter object that will be used to save the processed video with hand gesture recognition annotations. The VideoWriter is initialized with the following:
- The output video path differs for the Nano and Small variants.
- The
MJPGvideo codec. - The frame rate of the output video is set to
20frames per second (FPS). - The dimensions of the video frame are specified by
config.CAMERA_PREV_DIM.
# pipeline defined, now the device is assigned and pipeline is started with dai.Device(pipeline) as device: # output queues will be used to get the rgb frames # and nn data from the outputs defined above qRgb = device.getOutputQueue(name="rgb", maxSize=4, blocking=False) qDet = device.getOutputQueue(name="nn", maxSize=4, blocking=False) # initialize variables like frame, start time for NN FPS # also start the FPS module timer, define color pattern for FPS text frame = None startTime = time.monotonic() fps = FPS().start() counter = 0 color2 = (255, 255, 255)
Then, we set up and start the depthai camera pipeline using the previously created pipeline configuration. We also initialize variables for processing video frames and calculating FPS.
On Line 50, the dai.Device class is used as a context manager to ensure the device is properly initialized and cleaned up. The pipeline configuration is passed to the device when it is created.
Next, on Lines 54 and 55, two output queues are created using the device.getOutputQueue() method, which is used to retrieve the RGB video frames and neural network (NN) inference results. These queues are named “rgb” and “nn” (remember we named them while creating the camera pipeline using .setStreamName()), with a maximum size of 4, and are set to non-blocking mode. In non-blocking mode, the oldest data will be overwritten with new data if the queue is full.
On Lines 59-63, several variables are initialized, such as
frame: for storing the current video frame being processed,startTime: the starting time for calculating the neural network FPS, using thetime.monotonic()function, which returns the current time in seconds,fps: An instance of an FPS utility class is created and started to measure the frames per second of the video processing,counter: A counter variable, initialized to0, which may be used to count frames or other events during processing,color2: A color tuple(255, 255, 255)representing white in BGR color space, which will be used to annotate video frames with FPS information.
print("[INFO] starting inference with OAK camera...")
while True:
# fetch the RGB frames and YOLO detections for the frame
inRgb = qRgb.get()
inDet = qDet.get()
if inRgb is not None:
# convert inRgb output to a format OpenCV library can work
frame = inRgb.getCvFrame()
# annotate the frame with FPS information
cv2.putText(frame, "NN fps: {:.2f}".format(counter / (time.monotonic() - startTime)),
(2, frame.shape[0] - 4), cv2.FONT_HERSHEY_TRIPLEX, 0.8, color2)
# update the FPS counter
fps.update()
if inDet is not None:
# if inDet is not none, fetch all the detections for a frame
detections = inDet.detections
counter += 1
if frame is not None:
# annotate frame with detection results
frame = utils.annotateFrame(frame, detections, args.model.lower())
# display the frame with gesture output on the screen
cv2.imshow(args.model.lower(), frame)
# write the annotated frame to the file
out.write(frame)
# break out of the while loop if `q` key is pressed
if cv2.waitKey(1) == ord('q'):
break
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
out.release()
cv2.destroyAllWindows()
With the pipeline started and queues defined, we start the infinite while loop, which continuously fetches RGB frames and YOLOv8 detections from two different input queues (qRgb and qDet) on Lines 66-69.
On Lines 71-78, if an RGB frame is available:
- It is converted to a format that the OpenCV library can process.
- Then annotated with the FPS (Frames Per Second) information. The FPS information is calculated using a counter, and the time elapsed since the start of the inference process.
- The FPS counter is updated every time an RGB frame is processed.
Next, on Lines 80-83, if a YOLO detection is available, the detections for that frame are fetched, and the counter is incremented.
Suppose a frame is available, and the detections for that frame have been fetched. In that case, the frame is annotated with the detection results using the annotateFrame() function from the utils module on Lines 85-87. The annotated frame is then displayed on the screen and written to an output file on Lines 89 and 93.
Finally, on Lines 96 and 97, we check if the user pressed the ‘q’ key, at which point the while loop is broken, and the inference process is stopped. The FPS information is then printed to the console, the output file is released, and the OpenCV windows are destroyed on Lines 100-105.
Results
We have done an amazing job implementing hand gesture recognition on the camera stream using OAK! And we are thrilled to share the fantastic inference results we achieved with both the YOLOv8n and YOLOv8s variants. Can you believe that YOLOv8s performed exceptionally well in recognizing all five hand gestures with barely any false positives or negatives? It is undoubtedly the clear winner here!
In terms of FPS, YOLOv8n achieved a speed of approximately 25 FPS, which is impressive. But wait, YOLOv8s is no slouch either, with a commendable speed of around 13 FPS.
The video below displays the hand gesture recognition inference results with the YOLOv8 Nano variant:
The video below displays the hand gesture recognition inference results with the YOLOv8 Small variant:
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Congratulations! You have now completed this tutorial, and we hope it has provided valuable insights into creating a hand gesture recognition application on OAK-D using YOLOv8n and YOLOv8s object detectors.
We began by outlining the project structure and proceeded with a detailed walkthrough of the process, which included the following:
- Exporting the YOLOv8 PyTorch model to OAK
- Configuring prerequisites
- Defining utilities
- Creating image and camera pipelines
- Defining helper functions
Following this, we implemented hand gesture recognition in images and camera streams using the previously defined pipelines and utilities.
To conclude the tutorial, we compared the results of the YOLOv8n and YOLOv8s variants, emphasizing the superior performance of the YOLOv8s variant in camera streams.
Additionally, we highlighted the near real-time performance achieved with both YOLOv8n and YOLOv8s variants for hand gesture recognition in camera streams, demonstrating their effectiveness in practical applications.
Citation Information
Sharma, A. “Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2023, https://pyimg.co/92by6
@incollection{Sharma_2023_Hand-Gesture-Recognition-YOLOv8-OAK-D,
author = {Aditya Sharma},
title = {Hand Gesture Recognition with {YOLOv8} on {OAK-D} in Near Real-Time},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/92by6},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.