
In this tutorial, you will receive a gentle introduction to training your first Convolutional Neural Network (CNN) using the PyTorch deep learning library. This network will be able to recognize handwritten Hiragana characters.
In training a Convolutional Neural Network (CNN), a dataset provides the necessary variety of inputs and labels that the network needs to learn from. This ensures the model can generalize well when encountering unseen data.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.

Today’s tutorial is part three in our five part series on PyTorch fundamentals:
- What is PyTorch?
- Intro to PyTorch: Training your first neural network using PyTorch
- PyTorch: Training your first Convolutional Neural Network (today’s tutorial)
- PyTorch image classification with pre-trained networks (next week’s tutorial)
- PyTorch object detection with pre-trained networks
Last week you learned how to train a very basic feedforward neural network using the PyTorch library. That tutorial focused on simple numerical data.
Today, we will take the next step and learn how to train a CNN to recognize handwritten Hiragana characters using the Kuzushiji-MNIST (KMNIST) dataset.
As you’ll see, training a CNN on an image dataset isn’t all that different from training a basic multi-layer perceptron (MLP) on numerical data. We still need to:
- Define our model architecture
- Load our dataset from disk
- Loop over our epochs and batches
- Make predictions and compute our loss
- Properly zero our gradient, perform backpropagation, and update our model parameters
Furthermore, this post will also give you some experience with PyTorch’s DataLoader implementation which makes it super easy to work with datasets — becoming proficient with PyTorch’s DataLoader is a critical skill you’ll want to develop as a deep learning practitioner (and it’s a topic that I’ve dedicated an entire course to inside PyImageSearch University).
To learn how to train your first CNN with PyTorch, just keep reading.
CNNs are a type of deep learning algorithm that can analyze and extract features from images, making them highly effective for image classification and object detection tasks. In this tutorial, we will go through the steps of implementing a CNN in PyTorch
PyTorch: Training your first Convolutional Neural Network (CNN)
Throughout the remainder of this tutorial, you will learn how to train your first CNN using the PyTorch framework.
We’ll start by configuring our development environment to install both torch and torchvision, followed by reviewing our project directory structure.
I’ll then show you the KMNIST dataset (a drop-in replacement for the MNIST digits dataset) that contains Hiragana characters. Later in this tutorial, you’ll learn how to train a CNN to recognize each of the Hiragana characters in the KMNIST dataset.
We’ll then implement three Python scripts with PyTorch, including our CNN architecture, training script, and a final script used to make predictions on input images.
By the end of this tutorial, you’ll be comfortable with the steps required to train a CNN with PyTorch.
Updates:
This blog post was last updated in January 2023 with additional explanations of CNNs and PyTorch background information.
Let’s get started!
Configuring your development environment
To follow this guide, you need to have PyTorch, OpenCV, and scikit-learn installed on your system.
Luckily, all three are extremely easy to install using pip:
$ pip install torch torchvision $ pip install opencv-contrib-python $ pip install scikit-learn
If you need help configuring your development environment for PyTorch, I highly recommend that you read the PyTorch documentation — PyTorch’s documentation is comprehensive and will have you up and running quickly.
And if you need help installing OpenCV, be sure to refer to my pip install OpenCV tutorial.
Having problems configuring your development environment?
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
The KMNIST dataset

The dataset we are using today is the Kuzushiji-MNIST dataset, or KMNIST, for short. This dataset is meant to be a drop-in replacement for the standard MNIST digits recognition dataset.
The KMNIST dataset consists of 70,000 images and their corresponding labels (60,000 for training and 10,000 for testing).
There are a total of 10 classes (meaning 10 Hiragana characters) in the KMNIST dataset, each equally distributed and represented. Our goal is to train a CNN that can accurately classify each of these 10 characters.
And lucky for us, the KMNIST dataset is built into PyTorch, making it super easy for us to work with!
Project structure
Before we start implementing any PyTorch code, let’s first review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and pre-trained model.
You’ll then be presented with the following directory structure:
$ tree . --dirsfirst . ├── output │ ├── model.pth │ └── plot.png ├── pyimagesearch │ ├── __init__.py │ └── lenet.py ├── predict.py └── train.py 2 directories, 6 files
We have three Python scripts to review today:
lenet.py: Our PyTorch implementation of the famous LeNet architecturetrain.py: Trains LeNet on the KMNIST dataset using PyTorch, then serializes the trained model to disk (i.e.,model.pth)predict.py: Loads our trained model from disk, makes predictions on testing images, and displays the results on our screen
The output directory will be populated with plot.png (a plot of our training/validation loss and accuracy) and model.pth (our trained model file) once we run train.py.
With our project directory structure reviewed, we can move on to implementing our CNN with PyTorch.
Implementing a Convolutional Neural Network (CNN) with PyTorch
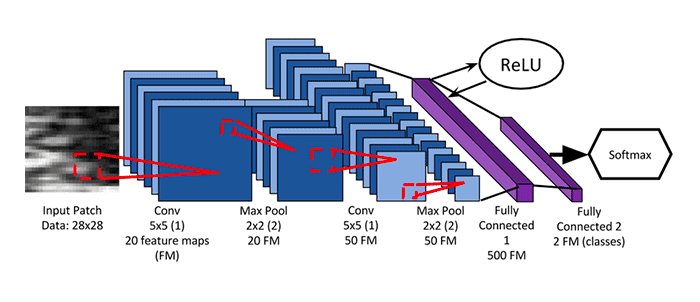
The Convolutional Neural Network (CNN) we are implementing here with PyTorch is the seminal LeNet architecture, first proposed by one of the grandfathers of deep learning, Yann LeCunn.
By today’s standards, LeNet is a very shallow neural network, consisting of the following layers:
(CONV => RELU => POOL) * 2 => FC => RELU => FC => SOFTMAX
As you’ll see, we’ll be able to implement LeNet with PyTorch in only 60 lines of code (including comments).
The best way to learn about CNNs with PyTorch is to implement one, so with that said, open the lenet.py file in the pyimagesearch module, and let’s get to work:
# import the necessary packages from torch.nn import Module from torch.nn import Conv2d from torch.nn import Linear from torch.nn import MaxPool2d from torch.nn import ReLU from torch.nn import LogSoftmax from torch import flatten
Lines 2-8 import our required packages. Let’s break each of them down:
Module: Rather than using theSequentialPyTorch class to implement LeNet, we’ll instead subclass theModuleobject so you can see how PyTorch implements neural networks using classesConv2d: PyTorch’s implementation of convolutional layersLinear: Fully connected layersMaxPool2d: Applies 2D max-pooling to reduce the spatial dimensions of the input volumeReLU: Our ReLU activation functionLogSoftmax: Used when building our softmax classifier to return the predicted probabilities of each classflatten: Flattens the output of a multi-dimensional volume (e.g., a CONV or POOL layer) such that we can apply fully connected layers to it
With our imports taken care of, we can implement our LeNet class using PyTorch:
class LeNet(Module): def __init__(self, numChannels, classes): # call the parent constructor super(LeNet, self).__init__() # initialize first set of CONV => RELU => POOL layers self.conv1 = Conv2d(in_channels=numChannels, out_channels=20, kernel_size=(5, 5)) self.relu1 = ReLU() self.maxpool1 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2)) # initialize second set of CONV => RELU => POOL layers self.conv2 = Conv2d(in_channels=20, out_channels=50, kernel_size=(5, 5)) self.relu2 = ReLU() self.maxpool2 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2)) # initialize first (and only) set of FC => RELU layers self.fc1 = Linear(in_features=800, out_features=500) self.relu3 = ReLU() # initialize our softmax classifier self.fc2 = Linear(in_features=500, out_features=classes) self.logSoftmax = LogSoftmax(dim=1)
Line 10 defines the LeNet class. Notice how we are subclassing the Module object — by building our model as a class we can easily:
- Reuse variables
- Implement custom functions to generate subnetworks/components (used very often when implementing more complex networks, such as ResNet, Inception, etc.)
- Define our own
forwardpass function
Best of all, when defined correctly, PyTorch can automatically apply its autograd module to perform automatic differentiation — backpropagation is taken care of for us by virtue of the PyTorch library!
The constructor to LeNet accepts two variables:
numChannels: The number of channels in the input images (1for grayscale or3for RGB)classes: Total number of unique class labels in our dataset
Line 13 calls the parent constructor (i.e., Module) which performs a number of PyTorch-specific operations.
From there, we start defining the actual LeNet architecture.
Lines 16-19 initialize our first set of CONV => RELU => POOL layers. Our first CONV layer learns a total of 20 filters, each of which are 5×5. A ReLU activation function is then applied, followed by a 2×2 max-pooling layer with a 2×2 stride to reduce the spatial dimensions of our input image.
We then have a second set of CONV => RELU => POOL layers on Lines 22-25. We increase the number of filters learned in the CONV layer to 50, but maintain the 5×5 kernel size. Again, a ReLU activation is applied, followed by max-pooling.
Next comes our first and only set of fully connected layers (Lines 28 and 29). We define the number of inputs to the layer (800) along with our desired number of output nodes (500). A ReLU activation follows the FC layer.
Finally, we apply our softmax classifier (Lines 32 and 33). The number of in_features is set to 500, which is the output dimensionality from the previous layer. We then apply LogSoftmax such that we can obtain predicted probabilities during evaluation.
It’s important to understand that at this point all we have done is initialized variables. These variables are essentially placeholders. PyTorch has absolutely no idea what the network architecture is, just that some variables exist inside the LeNet class definition.
To build the network architecture itself (i.e., what layer is input to some other layer), we need to override the forward method of the Module class.
The forward function serves a number of purposes:
- It connects layers/subnetworks together from variables defined in the constructor (i.e.,
__init__) of the class - It defines the network architecture itself
- It allows the forward pass of the model to be performed, resulting in our output predictions
- And, thanks to PyTorch’s autograd module, it allows us to perform automatic differentiation and update our model weights
Let’s inspect the forward function now:
def forward(self, x): # pass the input through our first set of CONV => RELU => # POOL layers x = self.conv1(x) x = self.relu1(x) x = self.maxpool1(x) # pass the output from the previous layer through the second # set of CONV => RELU => POOL layers x = self.conv2(x) x = self.relu2(x) x = self.maxpool2(x) # flatten the output from the previous layer and pass it # through our only set of FC => RELU layers x = flatten(x, 1) x = self.fc1(x) x = self.relu3(x) # pass the output to our softmax classifier to get our output # predictions x = self.fc2(x) output = self.logSoftmax(x) # return the output predictions return output
The forward method accepts a single parameter, x, which is the batch of input data to the network.
We then connect our conv1, relu1, and maxpool1 layers together to form the first CONV => RELU => POOL layer of the network (Lines 38-40).
A similar operation is performed on Lines 44-46, this time building the second set of CONV => RELU => POOL layers.
At this point, the variable x is a multi-dimensional tensor; however, in order to create our fully connected layers, we need to “flatten” this tensor into what essentially amounts to a 1D list of values — the flatten function on Line 50 takes care of this operation for us.
From there, we connect the fc1 and relu3 layers to the network architecture (Lines 51 and 52), followed by attaching the final fc2 and logSoftmax (Lines 56 and 57).
The output of the network is then returned to the calling function.
Again, I want to reiterate the importance of initializing variables in the constructor versus building the network itself in the forward function:
- The constructor to your
Moduleonly initializes your layer types. PyTorch keeps track of these variables, but it has no idea how the layers connect to each other. - For PyTorch to understand the network architecture you’re building, you define the
forwardfunction. - Inside the
forwardfunction you take the variables initialized in your constructor and connect them. - PyTorch can then make predictions using your network and perform automatic backpropagation, thanks to the autograd module
Congrats on implementing your first CNN with PyTorch!
Creating our CNN training script with PyTorch
With our CNN architecture implemented, we can move on to creating our training script with PyTorch.
Open the train.py file in your project directory structure, and let’s get to work:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.lenet import LeNet
from sklearn.metrics import classification_report
from torch.utils.data import random_split
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torchvision.datasets import KMNIST
from torch.optim import Adam
from torch import nn
import matplotlib.pyplot as plt
import numpy as np
import argparse
import torch
import time
Lines 2 and 3 import matplotlib and set the appropriate background engine.
From there, we import a number of notable packages:
LeNet: Our PyTorch implementation of the LeNet CNN from the previous sectionclassification_report: Used to display a detailed classification report on our testing setrandom_split: Constructs a random training/testing split from an input set of dataDataLoader: PyTorch’s awesome data loading utility that allows us to effortlessly build data pipelines to train our CNNToTensor: A preprocessing function that converts input data into a PyTorch tensor for us automaticallyKMNIST: The Kuzushiji-MNIST dataset loader built into the PyTorch libraryAdam: The optimizer we’ll use to train our neural networknn: PyTorch’s neural network implementations
Let’s now parse our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to output trained model")
ap.add_argument("-p", "--plot", type=str, required=True,
help="path to output loss/accuracy plot")
args = vars(ap.parse_args())
We have two command line arguments that need parsing:
--model: The path to our output serialized model after training (we save this model to disk so we can use it to make predictions in ourpredict.pyscript)--plot: The path to our output training history plot
Moving on, we now have some important initializations to take care of:
# define training hyperparameters
INIT_LR = 1e-3
BATCH_SIZE = 64
EPOCHS = 10
# define the train and val splits
TRAIN_SPLIT = 0.75
VAL_SPLIT = 1 - TRAIN_SPLIT
# set the device we will be using to train the model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Lines 29-31 set our initial learning rate, batch size, and number of epochs to train for, while Lines 34 and 35 define our training and validation split size (75% of training, 25% for validation).
Line 38 then determines our device (i.e., whether we’ll be using our CPU or GPU).
Let’s start preparing our dataset:
# load the KMNIST dataset
print("[INFO] loading the KMNIST dataset...")
trainData = KMNIST(root="data", train=True, download=True,
transform=ToTensor())
testData = KMNIST(root="data", train=False, download=True,
transform=ToTensor())
# calculate the train/validation split
print("[INFO] generating the train/validation split...")
numTrainSamples = int(len(trainData) * TRAIN_SPLIT)
numValSamples = int(len(trainData) * VAL_SPLIT)
(trainData, valData) = random_split(trainData,
[numTrainSamples, numValSamples],
generator=torch.Generator().manual_seed(42))
Lines 42-45 load the KMNIST dataset using PyTorch’s build in KMNIST class.
For our trainData, we set train=True while our testData is loaded with train=False. These Booleans come in handy when working with datasets built into the PyTorch library.
The download=True flag indicates that PyTorch will automatically download and cache the KMNIST dataset to disk for us if we had not previously downloaded it.
Also take note of the transform parameter — here we can apply a number of data transformations (outside the scope of this tutorial but will be covered soon). The only transform we need is to convert the NumPy array loaded by PyTorch into a tensor data type.
With our training and testing set loaded, we drive our training and validation set on Lines 49-53. Using PyTorch’s random_split function, we can easily split our data.
We now have three sets of data:
- Training
- Validation
- Testing
The next step is to create a DataLoader for each one:
# initialize the train, validation, and test data loaders trainDataLoader = DataLoader(trainData, shuffle=True, batch_size=BATCH_SIZE) valDataLoader = DataLoader(valData, batch_size=BATCH_SIZE) testDataLoader = DataLoader(testData, batch_size=BATCH_SIZE) # calculate steps per epoch for training and validation set trainSteps = len(trainDataLoader.dataset) // BATCH_SIZE valSteps = len(valDataLoader.dataset) // BATCH_SIZE
Building the DataLoader objects is accomplished on Lines 56-59. We set shuffle=True only for our trainDataLoader since our validation and testing sets do not require shuffling.
We also derive the number of training steps and validation steps per epoch (Lines 62 and 63).
At this point our data is ready for training; however, we don’t have a model to train yet!
Let’s initialize LeNet now:
# initialize the LeNet model
print("[INFO] initializing the LeNet model...")
model = LeNet(
numChannels=1,
classes=len(trainData.dataset.classes)).to(device)
# initialize our optimizer and loss function
opt = Adam(model.parameters(), lr=INIT_LR)
lossFn = nn.NLLLoss()
# initialize a dictionary to store training history
H = {
"train_loss": [],
"train_acc": [],
"val_loss": [],
"val_acc": []
}
# measure how long training is going to take
print("[INFO] training the network...")
startTime = time.time()
Lines 67-69 initialize our model. Since the KMNIST dataset is grayscale, we set numChannels=1. We can easily set the number of classes by calling dataset.classes of our trainData.
We also call to(device) to move the model to either our CPU or GPU.
Lines 72 and 73 initialize our optimizer and loss function. We’ll use the Adam optimizer for training and the negative log-likelihood for our loss function.
When we combine the nn.NLLoss class with LogSoftmax in our model definition, we arrive at categorical cross-entropy loss (which is the equivalent to training a model with an output Linear layer and an nn.CrossEntropyLoss loss). Basically, PyTorch allows you to implement categorical cross-entropy in two separate ways.
Get used to seeing both methods as some deep learning practitioners (almost arbitrarily) prefer one over the other.
We then initialize H, our training history dictionary (Lines 76-81). After every epoch we’ll update this dictionary with our training loss, training accuracy, testing loss, and testing accuracy for the given epoch.
Finally, we start a timer to measure how long training takes (Line 85).
At this point, all of our initializations are complete, so it’s time to train our model.
Note: Be sure you’ve read the previous tutorial in this series, Intro to PyTorch: Training your first neural network using PyTorch, as we’ll be building on concepts learned in that guide.
Below follows our training loop:
# loop over our epochs for e in range(0, EPOCHS): # set the model in training mode model.train() # initialize the total training and validation loss totalTrainLoss = 0 totalValLoss = 0 # initialize the number of correct predictions in the training # and validation step trainCorrect = 0 valCorrect = 0 # loop over the training set for (x, y) in trainDataLoader: # send the input to the device (x, y) = (x.to(device), y.to(device)) # perform a forward pass and calculate the training loss pred = model(x) loss = lossFn(pred, y) # zero out the gradients, perform the backpropagation step, # and update the weights opt.zero_grad() loss.backward() opt.step() # add the loss to the total training loss so far and # calculate the number of correct predictions totalTrainLoss += loss trainCorrect += (pred.argmax(1) == y).type( torch.float).sum().item()
On Line 88, we loop over our desired number of epochs.
We then proceed to:
- Put the model in
train()mode - Initialize our training loss and validation loss for the current epoch
- Initialize our number of correct training and validation predictions for the current epoch
Line 102 shows the benefit of using PyTorch’s DataLoader class — all we have to do is start a for loop over the DataLoader object. PyTorch automatically yields a batch of training data. Under the hood, the DataLoader is also shuffling our training data (and if we were doing any additional preprocessing or data augmentation, it would happen here as well).
For each batch of data (Line 104) we perform a forward pass, obtain our predictions, and compute the loss (Lines 107 and 108).
Next comes the all important step of:
- Zeroing our gradient
- Performing backpropagation
- Updating the weights of our model
Seriously, don’t forget this step! Failure to do those three steps in that exact order will lead to erroneous training results. Whenever you write a training loop with PyTorch, I highly recommend you insert those three lines of code before you do anything else so that you are reminded to ensure they are in the proper place.
We wrap up the code block by updating our totalTrainLoss and trainCorrect bookkeeping variables.
At this point, we’ve looped over all batches of data in our training set for the current epoch — now we can evaluate our model on the validation set:
# switch off autograd for evaluation with torch.no_grad(): # set the model in evaluation mode model.eval() # loop over the validation set for (x, y) in valDataLoader: # send the input to the device (x, y) = (x.to(device), y.to(device)) # make the predictions and calculate the validation loss pred = model(x) totalValLoss += lossFn(pred, y) # calculate the number of correct predictions valCorrect += (pred.argmax(1) == y).type( torch.float).sum().item()
When evaluating a PyTorch model on a validation or testing set, you need to first:
- Use the
torch.no_grad()context to turn off gradient tracking and computation - Put the model in
eval()mode
From there, you loop over all validation DataLoader (Line 128), move the data to the correct device (Line 130), and use the data to make predictions (Line 133) and compute your loss (Line 134).
You can then derive your total number of correct predictions (Lines 137 and 138).
We round out our training loop by computing a number of statistics:
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDataLoader.dataset)
valCorrect = valCorrect / len(valDataLoader.dataset)
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}\n".format(
avgValLoss, valCorrect))
Lines 141 and 142 compute our average training and validation loss. Lines 146 and 146 do the same thing, but for our training and validation accuracy.
We then take these values and update our training history dictionary (Lines 149-152).
Finally, we display the training loss, training accuracy, validation loss, and validation accuracy on our terminal (Lines 149-152).
We’re almost there!
Now that training is complete, we need to evaluate our model on the testing set (previously we’ve only used the training and validation sets):
# finish measuring how long training took
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# we can now evaluate the network on the test set
print("[INFO] evaluating network...")
# turn off autograd for testing evaluation
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# initialize a list to store our predictions
preds = []
# loop over the test set
for (x, y) in testDataLoader:
# send the input to the device
x = x.to(device)
# make the predictions and add them to the list
pred = model(x)
preds.extend(pred.argmax(axis=1).cpu().numpy())
# generate a classification report
print(classification_report(testData.targets.cpu().numpy(),
np.array(preds), target_names=testData.classes))
Lines 162-164 stop our training timer and show how long training took.
We then set up another torch.no_grad() context and put our model in eval() mode (Lines 170 and 172).
Evaluation is performed by:
- Initializing a list to store our predictions (Line 175)
- Looping over our
testDataLoader(Line 178) - Sending the current batch of data to the appropriate device (Line 180)
- Making predictions on the current batch of data (Line 183)
- Updating our
predslist with the top predictions from the model (Line 184)
Finally, we display a detailed classification_report.
The last step we’ll do here is plot our training and validation history, followed by serializing our model weights to disk:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
# serialize the model to disk
torch.save(model, args["model"])
Lines 191-201 generate a matplotlib figure for our training history.
We then call torch.save to save our PyTorch model weights to disk so that we can load them from disk and make predictions from a separate Python script.
As a whole, reviewing this script shows you how much more control PyTorch gives you over the training loop — this is both a good and a bad thing:
- It’s good if you want full control over the training loop and need to implement custom procedures
- It’s bad when your training loop is simple and a Keras/TensorFlow equivalent to
model.fitwould suffice
As I mentioned in part one of this series, What is PyTorch, neither PyTorch nor Keras/TensorFlow is better than the other, there are just different caveats and use cases for each library.
Training our CNN with PyTorch
We are now ready to train our CNN using PyTorch.
Be sure to access the “Downloads” section of this tutorial to retrieve the source code to this guide.
From there, you can train your PyTorch CNN by executing the following command:
$ python train.py --model output/model.pth --plot output/plot.png
[INFO] loading the KMNIST dataset...
[INFO] generating the train-val split...
[INFO] initializing the LeNet model...
[INFO] training the network...
[INFO] EPOCH: 1/10
Train loss: 0.362849, Train accuracy: 0.8874
Val loss: 0.135508, Val accuracy: 0.9605
[INFO] EPOCH: 2/10
Train loss: 0.095483, Train accuracy: 0.9707
Val loss: 0.091975, Val accuracy: 0.9733
[INFO] EPOCH: 3/10
Train loss: 0.055557, Train accuracy: 0.9827
Val loss: 0.087181, Val accuracy: 0.9755
[INFO] EPOCH: 4/10
Train loss: 0.037384, Train accuracy: 0.9882
Val loss: 0.070911, Val accuracy: 0.9806
[INFO] EPOCH: 5/10
Train loss: 0.023890, Train accuracy: 0.9930
Val loss: 0.068049, Val accuracy: 0.9812
[INFO] EPOCH: 6/10
Train loss: 0.022484, Train accuracy: 0.9930
Val loss: 0.075622, Val accuracy: 0.9816
[INFO] EPOCH: 7/10
Train loss: 0.013171, Train accuracy: 0.9960
Val loss: 0.077187, Val accuracy: 0.9822
[INFO] EPOCH: 8/10
Train loss: 0.010805, Train accuracy: 0.9966
Val loss: 0.107378, Val accuracy: 0.9764
[INFO] EPOCH: 9/10
Train loss: 0.011510, Train accuracy: 0.9960
Val loss: 0.076585, Val accuracy: 0.9829
[INFO] EPOCH: 10/10
Train loss: 0.009648, Train accuracy: 0.9967
Val loss: 0.082116, Val accuracy: 0.9823
[INFO] total time taken to train the model: 159.99s
[INFO] evaluating network...
precision recall f1-score support
o 0.93 0.98 0.95 1000
ki 0.96 0.95 0.96 1000
su 0.96 0.90 0.93 1000
tsu 0.95 0.97 0.96 1000
na 0.94 0.94 0.94 1000
ha 0.97 0.95 0.96 1000
ma 0.94 0.96 0.95 1000
ya 0.98 0.95 0.97 1000
re 0.95 0.97 0.96 1000
wo 0.97 0.96 0.97 1000
accuracy 0.95 10000
macro avg 0.95 0.95 0.95 10000
weighted avg 0.95 0.95 0.95 10000
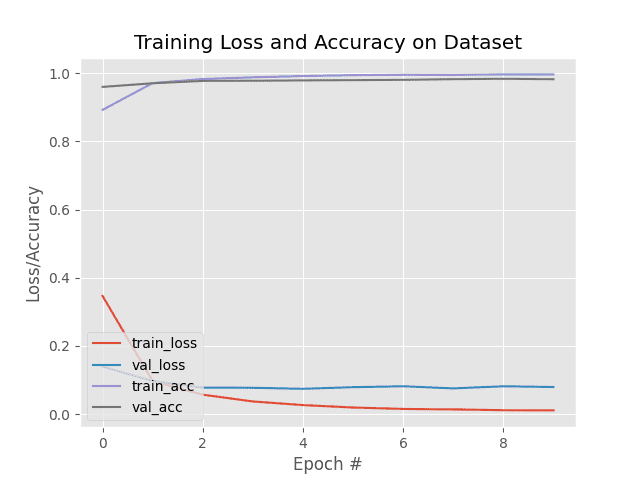
Training our CNN took ≈160 seconds on my CPU. Using my GPU training time drops to ≈82 seconds.
At the end of the final epoch we have obtained 99.67% training accuracy and 98.23% validation accuracy.
When we evaluate on our testing set we reach ≈95% accuracy, which is quite good given the complexity of the Hiragana characters and the simplicity of our shallow network architecture (using a deeper network such as a VGG-inspired model or ResNet-like would allow us to obtain even higher accuracy, but those models are more complex for an introduction to CNNs with PyTorch).
Furthermore, as Figure 4 shows, our training history plot is smooth, demonstrating there is little/no overfitting happening.
Before moving to the next section, take a look at your output directory:
$ ls output/ model.pth plot.png
Note the model.pth file — this is our trained PyTorch model saved to disk. We will load this model from disk and use it to make predictions in the following section.
Implementing our PyTorch prediction script
The final script we are reviewing here will show you how to make predictions with a PyTorch model that has been saved to disk.
Open the predict.py file in your project directory structure, and we’ll get started:
# set the numpy seed for better reproducibility import numpy as np np.random.seed(42) # import the necessary packages from torch.utils.data import DataLoader from torch.utils.data import Subset from torchvision.transforms import ToTensor from torchvision.datasets import KMNIST import argparse import imutils import torch import cv2
Lines 2-13 import our required Python packages. We set the NumPy random seed at the top of the script for better reproducibility across machines.
We then import:
DataLoader: Used to load our KMNIST testing dataSubset: Builds a subset of the testing dataToTensor: Converts our input data to a PyTorch tensor data typeKMNIST: The Kuzushiji-MNIST dataset loader built into the PyTorch librarycv2: Our OpenCV bindings which we’ll use for basic drawing and displaying output images on our screen
Next comes our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, required=True,
help="path to the trained PyTorch model")
args = vars(ap.parse_args())
We only need a single argument here, --model, the path to our trained PyTorch model saved to disk. Presumably, this switch will point to output/model.pth.
Moving on, let’s set our device:
# set the device we will be using to test the model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the KMNIST dataset and randomly grab 10 data points
print("[INFO] loading the KMNIST test dataset...")
testData = KMNIST(root="data", train=False, download=True,
transform=ToTensor())
idxs = np.random.choice(range(0, len(testData)), size=(10,))
testData = Subset(testData, idxs)
# initialize the test data loader
testDataLoader = DataLoader(testData, batch_size=1)
# load the model and set it to evaluation mode
model = torch.load(args["model"]).to(device)
model.eval()
Line 22 determines if we will be performing inference on our CPU or GPU.
We then load the testing data from the KMNIST dataset on Lines 26 and 27. We randomly sample a total of 10 images from this dataset on Lines 28 and 29 using the Subset class (which creates a smaller “view” of the full testing data).
A DataLoader is created to pass our subset of testing data through the model on Line 32.
We then load our serialized PyTorch model from disk on Line 35, passing it to the appropriate device.
Finally, the model is placed into evaluation mode (Line 36).
Let’s now make predictions on a sample of our testing set:
# switch off autograd with torch.no_grad(): # loop over the test set for (image, label) in testDataLoader: # grab the original image and ground truth label origImage = image.numpy().squeeze(axis=(0, 1)) gtLabel = testData.dataset.classes[label.numpy()[0]] # send the input to the device and make predictions on it image = image.to(device) pred = model(image) # find the class label index with the largest corresponding # probability idx = pred.argmax(axis=1).cpu().numpy()[0] predLabel = testData.dataset.classes[idx]
Line 39 turns off gradient tracking, while Line 41 loops over all images in our subset of the test set.
For each image, we:
- Grab the current image and turn it into a NumPy array (so we can draw on it later with OpenCV)
- Extracts the ground-truth class label
- Sends the
imageto the appropriatedevice - Uses our trained LeNet model to make predictions on the current
image - Extracts the class label with the top predicted probability
All that’s left is a bit of visualization:
# convert the image from grayscale to RGB (so we can draw on
# it) and resize it (so we can more easily see it on our
# screen)
origImage = np.dstack([origImage] * 3)
origImage = imutils.resize(origImage, width=128)
# draw the predicted class label on it
color = (0, 255, 0) if gtLabel == predLabel else (0, 0, 255)
cv2.putText(origImage, gtLabel, (2, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, color, 2)
# display the result in terminal and show the input image
print("[INFO] ground truth label: {}, predicted label: {}".format(
gtLabel, predLabel))
cv2.imshow("image", origImage)
cv2.waitKey(0)
Each image in the KMNIST dataset is a single channel grayscale image; however, we want to use OpenCV’s cv2.putText function to draw the predicted class label and ground-truth label on the image.
To draw RGB colors on a grayscale image, we first need to create an RGB representation of the grayscale image by stacking the grayscale image depth-wise a total of three times (Line 58).
Additionally, we resize the origImage so that we can more easily see it on our screen (by default, KMNIST images are only 28×28 pixels, which can be hard to see, especially on a high resolution monitor).
From there, we determine the text color and draw the label on the output image.
We wrap up the script by displaying the output origImage on our screen.
Making predictions with our trained PyTorch model
We are now ready to make predictions using our trained PyTorch model!
Be sure to access the “Downloads” section of this tutorial to retrieve the source code and pre-trained PyTorch model.
From there, you can execute the predict.py script:
$ python predict.py --model output/model.pth [INFO] loading the KMNIST test dataset... [INFO] Ground truth label: ki, Predicted label: ki [INFO] Ground truth label: ki, Predicted label: ki [INFO] Ground truth label: ki, Predicted label: ki [INFO] Ground truth label: ha, Predicted label: ha [INFO] Ground truth label: tsu, Predicted label: tsu [INFO] Ground truth label: ya, Predicted label: ya [INFO] Ground truth label: tsu, Predicted label: tsu [INFO] Ground truth label: na, Predicted label: na [INFO] Ground truth label: ki, Predicted label: ki [INFO] Ground truth label: tsu, Predicted label: tsu
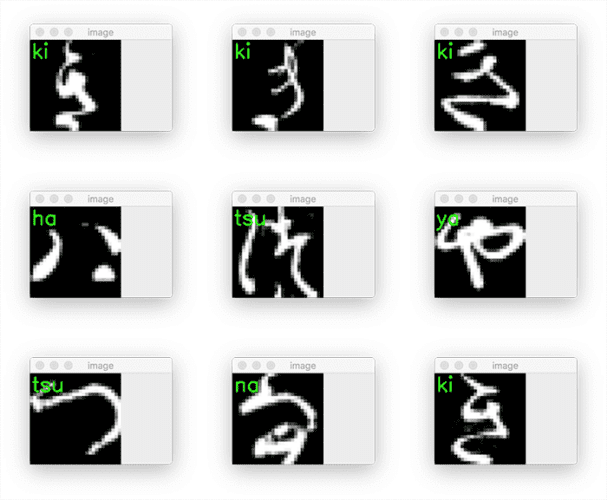
As our output demonstrates, we have been able to successfully recognize each of the Hiragana characters using our PyTorch model.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to train your first Convolutional Neural Network (CNN) using the PyTorch deep learning library.
You also learned how to:
- Save our trained PyTorch model to disk
- Load it from disk in a separate Python script
- Use the PyTorch model to make predictions on images
This sequence of saving a model after training, and then loading it and using the model to make predictions, is a process you should become comfortable with — you’ll be doing it often as a PyTorch deep learning practitioner.
Speaking of loading saved PyTorch models from disk, next week you will learn how to use pre-trained PyTorch to recognize 1,000 image classes that you often encounter in everyday life. These models can save you a bunch of time and hassle — they are highly accurate and don’t require you to manually train them.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.