
In this tutorial, you will learn how to OCR non-English languages using the Tesseract OCR engine.

If you refer to my previous Optical Character Recognition (OCR) tutorials on the PyImageSearch blog, you’ll note that all of the OCR text is in the English language.
But what if you wanted to OCR text that was non-English?
What steps would you need to take?
And how does Tesseract work with non-English languages?
We’ll be answering all of those questions in this tutorial.
To learn how to OCR text in non-English languages using Tesseract, just keep reading.
Tesseract Optical Character Recognition (OCR) for Non-English Languages
In the first part of this tutorial you will learn how to configure the Tesseract OCR engine for multiple languages, including non-English languages.
I’ll then show you how you can download multiple language packs for Tesseract and verify that it works properly — we’ll use German as an example case.
From there, we will configure the TextBlob package, which will be used to translate from one language into another.
Once we have completed all of this setup, we’ll implement the Project Structure for a Python script that will:
- Accept an input image
- Detect and OCR text in non-English languages
- Translate the OCR’d text from the given input language into English
- Display the results to our terminal
Let’s get started!
Configuring Tesseract OCR for Multiple Languages
In this section, we are going to configure Tesseract OCR for multiple languages. We will break this down, step by step, to see what it looks like on both macOS and Ubuntu.
If you have not already installed Tesseract:
- I have provided instructions for installing the Tesseract OCR engine as well as pytesseract (the Python bindings used to interface with Tesseract) in my blog post OpenCV OCR and text recognition with Tesseract.
- Follow the instructions in the How to install Tesseract 4 section of that tutorial, confirm your Tesseract install, and then come back here to learn how to configure Tesseract for multiple languages.
Technically speaking, Tesseract should already be configured to handle multiple languages, including non-English languages; however, in my experience the multi-language support can be a bit temperamental. We are going to review my method that gives consistent results.
If you installed Tesseract on macOS via Homebrew, your Tesseract language packs should be available in /usr/local/Cellar/tesseract/<version>/share/tessdata where <version> is the version number for your Tesseract install (you can use the tab key to autocomplete to derive the full path on your machine).
If you are running on Ubuntu, your Tesseract language packs should be located in the directory /usr/share/tesseract-ocr/<version>/tessdata where <version> is the version number for your Tesseract install.
Let’s take a quick look at the contents of this tessdata directory with an ls command as shown in Figure 1, below, which corresponds to the Homebrew installation on my macOS for an English language configuration.
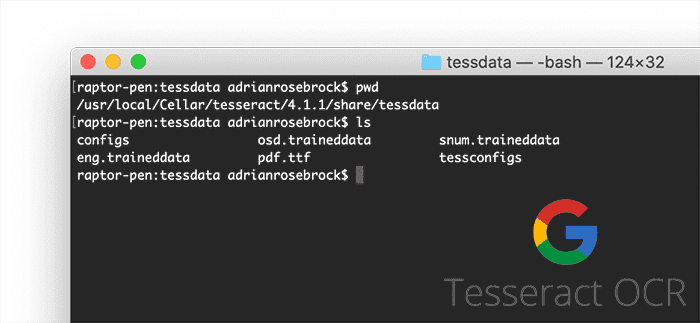
The only language pack installed in macOS Tesseract is English, which is contained in the eng.traineddata file.
So what are these Tesseract files?
eng.traineddataosd.traineddatasnum.traineddatapdf.ttf
In the remainder of this section, I’ll share with you my recommended foolproof method to configure Tesseract for multiple languages. Then we’ll jump into the project structure and actual execution breakdowns.
Download and Add Language Packs to Tesseract OCR

The first version of Tesseract provided support for the English language only. Support for French, Italian, German, Spanish, Brazilian Portuguese, and Dutch were added in the second version.
In the third version, support was dramatically expanded to include ideographic (symbolic) languages such as Chinese and Japanese as well as right-to-left languages such as Arabic and Hebrew.
The fourth version, which we are now using supports over 100 languages and has support for characters and symbols.
Note: The fourth version contains trained models for Tesseract’s legacy and newer, more accurate Long Short-Term Memory (LSTM) OCR engine.
Now that we have an idea of the breadth of supported languages, let’s dive in to see the most foolproof method I’ve found to configure Tesseract and unlock the power of this vast multi-language support:
- Download Tesseract’s language packs manually from GitHub and install them.
- Set the
TESSDATA_PREFIXenvironment variable to point to the directory containing the language packs.
The first step here is to clone Tesseract’s GitHub tessdata repository, which is located here:
https://github.com/tesseract-ocr/tessdata
We want to move to the directory that we wish to be the parent directory for what will be our local tessdata directory. Then, we’ll simply issue the git command below to clone the repo to our local directory.
$ git clone https://github.com/tesseract-ocr/tessdata
Note: Be aware that at the time of this writing, the resulting tessdata directory will be ~4.85GB, so make sure you have ample space on your hard drive.
The second step is to set up the TESSDATA_PREFIX environment variable to point to the directory containing the language packs. We’ll change directory (cd) into the tessdata directory and use the pwd command to determine the full system path to the directory:
$ cd tessdata/ $ pwd /Users/adrianrosebrock/Desktop/tessdata
Your tessdata directory will have a different path from mine, so make sure you run the above commands to determine the path specific to your machine!
From there, all you need to do is set the TESSDATA_PREFIX environment variable to point to your tessdata directory, thereby allowing Tesseract to find the language packs. To do that, simply execute the following command:
$ export TESSDATA_PREFIX=/Users/adrianrosebrock/Desktop/tessdata
Again, your full path will be different from mine, so take care to double-check and triple-check your file path.
Project Structure
Let’s review the project structure.
Once you grab the files from the “Downloads” section of this article, you’ll be presented with the following directory structure:
$ tree --dirsfirst --filelimit 10 . ├── images │ ├── arabic.png │ ├── german.png │ ├── german_block.png │ ├── swahili.png │ └── vietnamese.png └── ocr_non_english.py 1 directory, 6 files
The images/ sub-directory contains several PNG files that we will use for OCR. The titles indicate the native language that will be used for the OCR.
The Python file ocr_non_english.py, located in our main directory, is our driver file. It will OCR our text in its native language, and then translate from the native language into English.
Verifying Tesseract Support for Non-English Languages
At this point, you should have Tesseract correctly configured to support non-English languages, but as a sanity check, let’s validate that the TESSDATA_PREFIX environment variable is set correctly by using the echo command:
$ echo $TESSDATA_PREFIX /Users/adrianrosebrock/Desktop/tessdata
Remember, your tessdata directory will be different from mine!
We should move from the tessdata directory to the project images directory so we can test non-English language support. We can do this by supplying the --lang or -l command line argument, specifying the language we want Tesseract to use when OCR’ing.
$ tesseract german.png stdout -l deu
Here, I am OCR’ing a file named german.png where the -l parameter indicates that I want Tesseract to OCR German text (deu).
To determine the correct three-letter country/region code for a given language, you should:
- Inspect the
tessdatadirectory. - Refer to the Tesseract documentation, which lists the languages and corresponding codes that Tesseract supports.
- Use this webpage to determine the country code for where a language is predominantly used.
- Finally, if you still cannot derive the correct country code, use a bit of Google-foo, and search for three-letter country codes for your region (it also doesn’t hurt to search Google for Tesseract <language name> code).
With a little bit of patience, along with some practice, you’ll be OCR’ing text in non-English languages with Tesseract.
Environmental Setup for the TextBlob Package
Now that we have Tesseract set up and have added support for a non-English language, we need to set up the TextBlob package.
Note: This step assumes that you are already working in a Python3 virtual environment (e.g. $ workon cv where cv is the name of a virtual environment — yours will probably be different).
To install textblob is just one quick command:
$ pip install textblob
Great job setting up your environmental dependencies!
Implementing Our Tesseract with Non-English Languages Script
We are now ready to implement Tesseract for non-English language support. Let’s review the existing ocr_non_english.py from the downloads section.
Open up the ocr_non_english.py file in your project directory, and insert the following code:
# import the necessary packages
from textblob import TextBlob
import pytesseract
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-l", "--lang", required=True,
help="language that Tesseract will use when OCR'ing")
ap.add_argument("-t", "--to", type=str, default="en",
help="language that we'll be translating to")
ap.add_argument("-p", "--psm", type=int, default=13,
help="Tesseract PSM mode")
args = vars(ap.parse_args())
Line 5 imports TextBlob, which is a very useful Python library for processing textual data. It can perform various natural language processing tasks such as tagging parts of speech. We will use it to translate OCR’d text from a foreign language into English. You can read more about TextBlob here: https://textblob.readthedocs.io/en/dev/
We then import pytesseract, which is the Python wrapper for Google’s Tesseract OCR library (Line 6).
Our command line arguments include (Lines 12-19):
--image: The path to the input image to be OCR’d.--lang--to: The language into which we will be translating the native OCR text.--psmdefaultis for a page segmentation mode of13, which treats the image as a single line of text. For our last example today, we will OCR a full block of text of German. For this full block, we will use a page segmentation mode of3which is fully automatic page segmentation without Orientation and Script Detection (OSD).
With our imports, convenience function, and command line args ready to go, we just have a few initializations to handle before we loop over frames:
# load the input image and convert it from BGR to RGB channel
# ordering
image = cv2.imread(args["image"])
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# OCR the image, supplying the country code as the language parameter
options = "-l {} --psm {}".format(args["lang"], args["psm"])
text = pytesseract.image_to_string(rgb, config=options)
# show the original OCR'd text
print("ORIGINAL")
print("========")
print(text)
print("")
In this section, we are going to load the image from a file, change the order of the color channels of the image, set the options for Tesseract, and perform optical character recognition on the image in its native language.
Line 24 loads the image using cv2.imread while on Line 25 swaps the color channels from Blue-Green-Red (BGR) to Red-Green-Blue (RGB) so the image is compatible with Tesseract, which takes an input image with an RGB color channel ordering.
From there, we supply the options for Tesseract (Line 28) which include:
- The native language to be used by Tesseract to OCR the image (
-l). - The Page Segmentation Mode option (
-psm). These correspond to the input arguments that we supply on our command line when we run this program.
Next, we will wrap up this section by showing the OCR’d results from Tesseract in the native language (Lines 32-35):
# translate the text into a different language
tb = TextBlob(text)
translated = tb.translate(to=args["to"])
# show the translated text
print("TRANSLATED")
print("==========")
print(translated)
Now that we have the text OCR’d in the native language, we are going to translate the text from the native language specified by our --lang command line argument to the output language described by our --to command line argument.
We abstract the text to a textblob using TextBlob (Line 38). Then, we translate the final language on Line 39 using tb.tranlsate. We wrap up by printing the results of the translated text (Lines 42-44). Now you have a complete workflow that includes OCR’ing the text in the native language and translated it into your desired language.
Great job implementing Tesseract for different languages — it was relatively straightforward, as you can see. Next, we’ll ensure that our script and Tesseract are firing on all cylinders.
Tesseract OCR and Non-English Languages Results
It’s time for us to put Tesseract for non-English languages to work!
Open up a terminal, and execute the following command from the main project directory:
$ python ocr_non_english.py --image images/german.png --lang deu ORIGINAL ======== Ich brauche ein Bier! TRANSLATED ========== I need a beer!
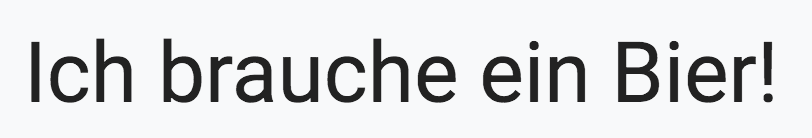
In Figure 3, you can see an input image with the text “Ich brauche ein Bier!” which is German for “I need a beer!”
By passing in the --lang deu flag, we were able to tell Tesseract to OCR the German text, which we then translated to English.
Let’s try another example, this one with Swahili input text:
$ python ocr_non_english.py --image images/swahili.png --lang swa ORIGINAL ======== Jina langu ni Adrian TRANSLATED ========== My name is Adrian
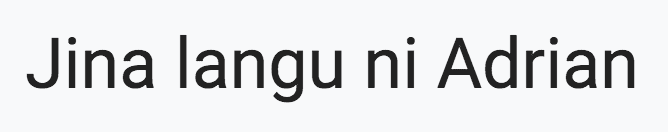
The --lang swa flag indicates that we want to OCR Swahili text (Figure 4).
Tesseract correctly OCR’s the text “Jina langu ni Adrian,” which when translated to English, is “My name is Adrian.”
This example shows how to OCR text in Vietnamese, which is a different script/writing system than the previous examples:
$ python ocr_non_english.py --image images/vietnamese.png --lang vie ORIGINAL ======== Tôi mến bạn.. TRANSLATED ========== I love you..

By specifying the --lang vie flag, Tesseract is able to successfully OCR the Vietnamese “Tôi mến bạn,” which translates to “I love you” in English.
This next example is in Arabic:
$ python ocr_non_english.py --image images/arabic.png --lang ara ORIGINAL ======== أنا أتحدث القليل من العربية فقط.. TRANSLATED ========== I only speak a little Arabic ..

Using the --lang ara flag, we’re able to tell Tesseract to OCR Arabic text.
Here, we can see that the Arabic script “أنا أتحدث القليل من العربية فقط.” roughly translates to “I only speak a little Arabic” in English.
For our final example, let’s OCR a large block of German text:
$ python ocr_non_english.py --image images/german_block.png --lang deu --psm 3 ORIGINAL ======== Erstes Kapitel Gustav Aschenbach oder von Aschenbach, wie seit seinem fünfzigsten Geburtstag amtlich sein Name lautete, hatte an einem Frühlingsnachmittag des Jahres 19.., das unserem Kontinent monatelang eine so gefahrdrohende Miene zeigte, von seiner Wohnung in der Prinz- Regentenstraße zu München aus, allein einen weiteren Spaziergang unternommen. Überreizt von der schwierigen und gefährlichen, eben jetzt eine höchste Behutsamkeit, Umsicht, Eindringlichkeit und Genauigkeit des Willens erfordernden Arbeit der Vormittagsstunden, hatte der Schriftsteller dem Fortschwingen des produzierenden Triebwerks in seinem Innern, jenem »motus animi continuus«, worin nach Cicero das Wesen der Beredsamkeit besteht, auch nach der Mittagsmahlzeit nicht Einhalt zu tun vermocht und den entlastenden Schlummer nicht gefunden, der ihm, bei zunehmender Abnutzbarkeit seiner Kräfte, einmal untertags so nötig war. So hatte er bald nach dem Tee das Freie gesucht, in der Hoffnung, daß Luft und Bewegung ihn wieder herstellen und ihm zu einem ersprießlichen Abend verhelfen würden. Es war Anfang Mai und, nach naßkalten Wochen, ein falscher Hochsommer eingefallen. Der Englische Garten, obgleich nur erst zart belaubt, war dumpfig wie im August und in der Nähe der Stadt voller Wagen und Spaziergänger gewesen. Beim Aumeister, wohin stillere und stillere Wege ihn geführt, hatte Aschenbach eine kleine Weile den volkstümlich belebten Wirtsgarten überblickt, an dessen Rande einige Droschken und Equipagen hielten, hatte von dort bei sinkender Sonne seinen Heimweg außerhalb des Parks über die offene Flur genommen und erwartete, da er sich müde fühlte und über Föhring Gewitter drohte, am Nördlichen Friedhof die Tram, die ihn in gerader Linie zur Stadt zurückbringen sollte. Zufällig fand er den Halteplatz und seine Umgebung von Menschen leer. Weder auf der gepflasterten Ungererstraße, deren Schienengeleise sich einsam gleißend gegen Schwabing erstreckten, noch auf der Föhringer Chaussee war ein Fuhrwerk zu sehen; hinter den Zäunen der Steinmetzereien, wo zu Kauf TRANSLATED ========== First chapter Gustav Aschenbach or von Aschenbach, like since his fiftieth Birthday officially his name was on one Spring afternoon of the year 19 .. that our continent for months showed such a threatening expression from his apartment in the Prince Regentenstrasse to Munich, another walk alone undertaken. Overexcited by the difficult and dangerous, just now a very careful, careful, insistent and Accuracy of the morning's work requiring will, the writer had the swinging of the producing Engine inside, that "motus animi continuus", in which according to Cicero the essence of eloquence persists, even after the Midday meal could not stop and the relieving Slumber not found him, with increasing wear and tear of his strength once was necessary during the day. So he had soon after Tea sought the free, in the hope that air and movement would find him restore it and help it to a profitable evening would. It was the beginning of May and, after wet and cold weeks, a wrong one Midsummer occurred. The English Garden, although only tender leafy, dull as in August and crowded near the city Carriages and walkers. At the Aumeister, where quiet and Aschenbach had walked the more quiet paths for a little while overlooks a popular, lively pub garden, on the edge of which there are a few Stops and equipages stopped from there when the sun was down made his way home outside the park across the open corridor and expected, since he felt tired and threatened thunderstorms over Foehring, at the northern cemetery the tram that takes him in a straight line to the city should bring back. By chance he found the stopping place and his Environment of people empty. Neither on the paved Ungererstrasse, the rail tracks of which glisten lonely against each other Schwabing extended, was still on the Föhringer Chaussee See wagon; behind the fences of the stonemasons where to buy

In just a few seconds, we were able to OCR the German text and then translate it to English.
So really, the biggest challenge OCR’ing non-English languages is configuring your tessdata and language packs — after that, OCR’ing non-English languages is as simple as setting the correct country/region/language code!
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post, you learned how to configure Tesseract to OCR non-English languages.
Most Tesseract installs will naturally handle multiple languages with no additional configuration; however, in some cases you will need to:
- Manually download the Tesseract language packs
- Set the
TESSDATA_PREFIXenvironment variable to point the language packs - Verify that the language packs directory is correct
Failure to complete the above three steps may prevent you from using Tesseract with non-English languages, so make sure you follow the steps in this tutorial closely!
Provided you do so, you shouldn’t have any issues OCR’ing non-English languages.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.