
Keras is undoubtedly my favorite deep learning + Python framework, especially for image classification.

I use Keras in production applications, in my personal deep learning projects, and here on the PyImageSearch blog.
I’ve even based over two-thirds of my new book, Deep Learning for Computer Vision with Python on Keras.
However, one of my biggest hangups with Keras is that it can be a pain to perform multi-GPU training. Between the boilerplate code and configuring TensorFlow it can be a bit of a process…
…but not anymore.
With the latest commit and release of Keras (v2.0.9) it’s now extremely easy to train deep neural networks using multiple GPUs.
In fact, it’s as easy as a single function call!
To learn more about training deep neural networks using Keras, Python, and multiple GPUs, just keep reading.
How-To: Multi-GPU training with Keras, Python, and deep learning
2020-06-16 Update: This blog post is now TensorFlow 2+ compatible! Keras is now built into TensorFlow 2 and serves as TensorFlow’s high-level API. Sentences in this introduction section may be misleading given the update to TensorFlow/Keras; they are left “as-is” for historical purposes.
When I first started using Keras I fell in love with the API. It’s simple and elegant, similar to scikit-learn. Yet it’s extremely powerful, capable of implementing and training state-of-the-art deep neural networks.
However, one of my biggest frustrations with Keras is that it could be a bit non-trivial to use in multi-GPU environments.
If you were using Theano, forget about it — multi-GPU training wasn’t going to happen.
TensorFlow was a possibility, but it could take a lot of boilerplate code and tweaking to get your network to train using multiple GPUs.
I preferred using the mxnet backend (or even the mxnet library outright) to Keras when performing multi-GPU training, but that introduced even more configurations to handle.
All of that changed with François Chollet’s announcement that multi-GPU support using the TensorFlow backend is now baked in to Keras v2.0.9. Much of this credit goes to @kuza55 and their keras-extras repo.
I’ve been using and testing this multi-GPU function for almost a year now and I’m incredibly excited to see it as part of the official Keras distribution.
In the remainder of today’s blog post I’ll be demonstrating how to train a Convolutional Neural Network for image classification using Keras, Python, and deep learning.
The MiniGoogLeNet deep learning architecture
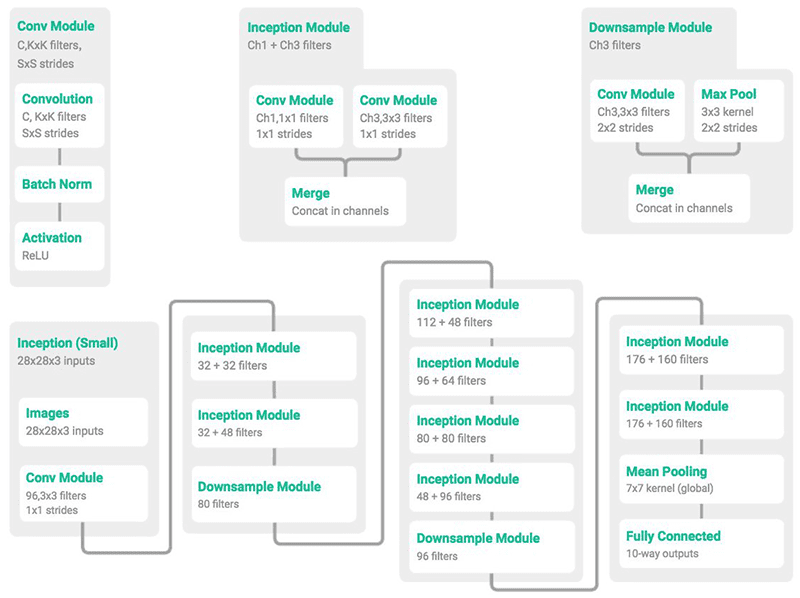
In Figure 1 above we can see the individual convolution (left), inception (middle), and downsample (right) modules, followed by the overall MiniGoogLeNet architecture (bottom), constructed from these building blocks. We will be using the MiniGoogLeNet architecture in our multi-GPU experiments later in this post.
The Inception module in MiniGoogLenet is a variation of the original Inception module designed by Szegedy et al.
I first became aware of this “Miniception” module from a tweet by @ericjang11 and @pluskid where they beautifully visualized the modules and associated MiniGoogLeNet architecture.
After doing a bit of research, I found that this graphic was from Zhang et al.’s 2017 publication, Understanding Deep Learning Requires Re-Thinking Generalization.
I then proceeded to implement the MiniGoogLeNet architecture in Keras + Python — I even included it as part of Deep Learning for Computer Vision with Python.
A full review of the MiniGoogLeNet Keras implementation is outside the scope of this blog post, so if you’re interested in how the network works (and how to code it), please refer to my book.
Otherwise, you can use the “Downloads” section at the bottom of this blog post to download the source code.
Configuring your development environment
To configure your system for this tutorial, I recommend following my How to install TensorFlow 2.0 on Ubuntu guide which has instructions on how to set up your system with your GPU driver, CUDA, and cuDNN.
Additionally, you’ll learn to set up a a convenient Python virtual environment to house your Python packages including TensorFlow 2+.
I don’t recommend using macOS for working with GPUs; please follow this link if you need a non-GPU macOS TensorFlow installation guide (not for today’s tutorial).
Additionally, please note that PyImageSearch does not recommend or support Windows for CV/DL projects.
Training a deep neural network with Keras and multiple GPUs
Let’s go ahead and get started training a deep learning network using Keras and multiple GPUs.
Open up a new file, name it train.py , and insert the following code:
# set the matplotlib backend so figures can be saved in the background
# (uncomment the lines below if you are using a headless server)
# import matplotlib
# matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minigooglenet import MiniGoogLeNet
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.compat.v2.keras.utils import multi_gpu_model
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import argparse
If you’re using a headless server, you’ll want to configure the matplotlib backend on Lines 3 and 4 by uncommenting the lines. This will enable your matplotlib plots to be saved to disk. If you are not using a headless server (i.e., your keyboard + mouse + monitor are plugged in to your system, you can keep the lines commented out).
From there we import our required packages for this script.
Line 7 imports the MiniGoogLeNet from my pyimagesearch module (included with the download available in the “Downloads” section).
Another notable import is on Line 13 where we import the CIFAR10 dataset. This helper function will enable us to load the CIFAR-10 dataset from disk with just a single line of code.
Now let’s parse our command line arguments:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output plot")
ap.add_argument("-g", "--gpus", type=int, default=1,
help="# of GPUs to use for training")
args = vars(ap.parse_args())
# grab the number of GPUs and store it in a conveience variable
G = args["gpus"]
We use argparse to parse one required and one optional argument on Lines 20-25:
--output: The path to the output plot after training is complete.--gpus: The number of GPUs used for training.
After loading the command line arguments, we store the number of GPUs as G for convenience (Line 28).
From there, we initialize two important variables used to configure our training process, followed by defining a polynomial-based learning rate schedule function:
# definine the total number of epochs to train for along with the # initial learning rate NUM_EPOCHS = 70 INIT_LR = 5e-3 def poly_decay(epoch): # initialize the maximum number of epochs, base learning rate, # and power of the polynomial maxEpochs = NUM_EPOCHS baseLR = INIT_LR power = 1.0 # compute the new learning rate based on polynomial decay alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power # return the new learning rate return alpha
We set NUM_EPOCHS = 70 — this is the number of times (epochs) our training data will pass through the network (Line 32).
We also initialize the learning rate INIT_LR = 5e-3 , a value that was found experimentally in previous trials (Line 33).
From there, we define the poly_decay function which is the equivalent of Caffe’s polynomial learning rate decay (Lines 35-46). Essentially this function updates the learning rate during training, effectively reducing it after each epoch. Setting the power = 1.0 changes the decay from polynomial to linear.
Next we’ll load our training + testing data and convert the image data from integer to float:
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
From there we apply mean subtraction to the data:
# apply mean subtraction to the data mean = np.mean(trainX, axis=0) trainX -= mean testX -= mean
On Line 56, we calculate the mean of all training images followed by Lines 57 and 58 where we subtract the mean from each image in the training and testing sets.
Then, we perform “one-hot encoding”, an encoding scheme I discuss in more detail in my book:
# convert the labels from integers to vectors lb = LabelBinarizer() trainY = lb.fit_transform(trainY) testY = lb.transform(testY)
One-hot encoding transforms categorical labels from a single integer to a vector so we can apply the categorical cross-entropy loss function. We’ve taken care of this on Lines 61-63.
Next, we create a data augmenter and set of callbacks:
# construct the image generator for data augmentation and construct # the set of callbacks aug = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True, fill_mode="nearest") callbacks = [LearningRateScheduler(poly_decay)]
On Lines 67-69 we construct the image generator for data augmentation.
Data augmentation is covered in detail inside the Practitioner Bundle of Deep Learning for Computer Vision with Python; however, for the time being understand that it’s a method used during the training process where we randomly alter the training images by applying random transformations to them.
Because of these alterations, the network is constantly seeing augmented examples — this enables the network to generalize better to the validation data while perhaps performing worse on the training set. In most situations these trade off is a worthwhile one.
We create a callback function on Line 70 which will allow our learning rate to decay after each epoch — notice our function name, poly_decay .
Let’s check that GPU variable next:
# check to see if we are compiling using just a single GPU
if G <= 1:
print("[INFO] training with 1 GPU...")
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=10)
If the GPU count is less than or equal to one, we initialize the model via the .build function (Lines 73-76), otherwise we’ll parallelize the model during training:
# otherwise, we are compiling using multiple GPUs
else:
# disable eager execution
tf.compat.v1.disable_eager_execution()
print("[INFO] training with {} GPUs...".format(G))
# we'll store a copy of the model on *every* GPU and then combine
# the results from the gradient updates on the CPU
with tf.device("/cpu:0"):
# initialize the model
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=10)
# make the model parallel
model = multi_gpu_model(model, gpus=G)
Creating a multi-GPU model in Keras requires some bit of extra code, but not much!
To start, you’ll notice on Line 86 that we’ve specified to use the CPU (rather than the GPU) as the network context.
Why do we need the CPU?
Well, the CPU is responsible for handling any overhead (such as moving training images on and off GPU memory) while the GPU itself does the heavy lifting.
In this case, the CPU instantiates the base model.
We can then call the multi_gpu_model on Line 92. This function replicates the model from the CPU to all of our GPUs, thereby obtaining single-machine, multi-GPU data parallelism.
When training our network images will be batched to each of the GPUs. The CPU will obtain the gradients from each GPU and then perform the gradient update step.
We can then compile our model and kick off the training process:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=64 * G),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // (64 * G),
epochs=NUM_EPOCHS,
callbacks=callbacks, verbose=2)
2020-06-16 Update: Formerly, TensorFlow/Keras required use of a method called .fit_generator in order to accomplish data augmentation. Now, the .fit method can handle data augmentation as well, making for more-consistent code. This also applies to the migration from .predict_generator to .predict. Be sure to check out my articles about fit and fit_generator as well as data augmentation.
On Line 96 we build a Stochastic Gradient Descent (SGD) optimizer with our initial learning rate.
Subsequently, we compile the model with the SGD optimizer and a categorical crossentropy loss function.
We’re now ready to train the network!
To initiate the training process, we make a call to model.fit and provide the necessary arguments.
We’d like a batch size of 64 on each GPU so that is specified by batch_size=64 * G .
Our training will continue for 70 epochs (which we specified previously).
The results of the gradient update will be combined on the CPU and then applied to each GPU throughout the training process.
Now that training and testing is complete, let’s plot the loss/accuracy so we can visualize the training process:
# grab the history object dictionary
H = H.history
# plot the training loss and accuracy
N = np.arange(0, len(H["loss"]))
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H["loss"], label="train_loss")
plt.plot(N, H["val_loss"], label="test_loss")
plt.plot(N, H["accuracy"], label="train_acc")
plt.plot(N, H["val_accuracy"], label="test_acc")
plt.title("MiniGoogLeNet on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
# save the figure
plt.savefig(args["output"])
plt.close()
2020-06-16 Update: In order for this plotting snippet to be TensorFlow 2+ compatible the H.history dictionary keys are updated to fully spell out “accuracy” sans “acc” (i.e., H["val_accuracy"] and H["accuracy"]). It is semi-confusing that “val” is not spelled out as “validation”; we have to learn to love and live with the API and always remember that it is a work in progress that many developers around the world contribute to.
This last block simply uses matplotlib to plot training/testing loss and accuracy (Lines 110-123), and then saves the figure to disk (Line 126).
If you would like more to learn more about the training process (and how it works internally), please refer to Deep Learning for Computer Vision with Python.
Keras multi-GPU results
Let’s check the results of our hard work.
To start, grab the code from this lesson using the “Downloads” section at the bottom of this post. You’ll then be able to follow along with the results
Let’s train on a single GPU to obtain a baseline:
$ python train.py --output single_gpu.png [INFO] loading CIFAR-10 data... [INFO] training with 1 GPU... [INFO] compiling model... [INFO] training network... Epoch 1/70 - 64s - loss: 1.4323 - accuracy: 0.4787 - val_loss: 1.1319 - val_ accuracy: 0.5983 Epoch 2/70 - 63s - loss: 1.0279 - accuracy: 0.6361 - val_loss: 0.9844 - accuracy: 0.6472 Epoch 3/70 - 63s - loss: 0.8554 - accuracy: 0.6997 - val_loss: 1.5473 - accuracy: 0.5592 ... Epoch 68/70 - 63s - loss: 0.0343 - accuracy: 0.9898 - val_loss: 0.3637 - accuracy: 0.9069 Epoch 69/70 - 63s - loss: 0.0348 - accuracy: 0.9898 - val_loss: 0.3593 - accuracy: 0.9080 Epoch 70/70 - 63s - loss: 0.0340 - accuracy: 0.9900 - val_loss: 0.3583 - accuracy: 0.9065 Using TensorFlow backend. real 74m10.603s user 131m24.035s sys 11m52.143s
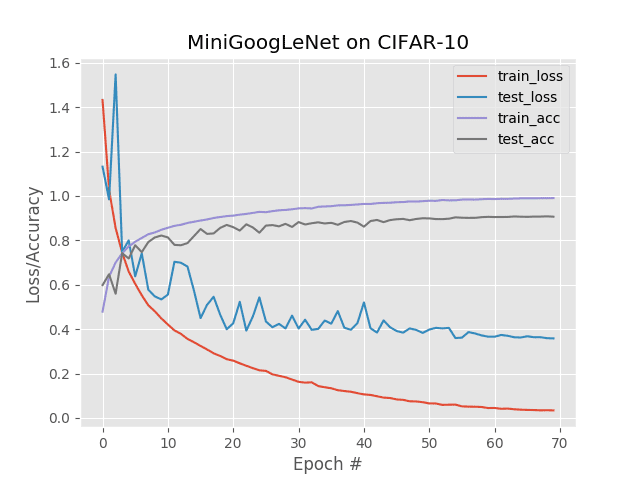
For this experiment, I trained on a single Titan X GPU on my NVIDIA DevBox. Each epoch took ~63 seconds with a total training time of 74m10s.
I then executed the following command to train with all four of my Titan X GPUs:
$ python train.py --output multi_gpu.png --gpus 4 [INFO] loading CIFAR-10 data... [INFO] training with 4 GPUs... [INFO] compiling model... [INFO] training network... Epoch 1/70 - 21s - loss: 1.6793 - accuracy: 0.3793 - val_loss: 1.3692 - accuracy: 0.5026 Epoch 2/70 - 16s - loss: 1.2814 - accuracy: 0.5356 - val_loss: 1.1252 - accuracy: 0.5998 Epoch 3/70 - 16s - loss: 1.1109 - accuracy: 0.6019 - val_loss: 1.0074 - accuracy: 0.6465 ... Epoch 68/70 - 16s - loss: 0.1615 - accuracy: 0.9469 - val_loss: 0.3654 - accuracy: 0.8852 Epoch 69/70 - 16s - loss: 0.1605 - accuracy: 0.9466 - val_loss: 0.3604 - accuracy: 0.8863 Epoch 70/70 - 16s - loss: 0.1569 - accuracy: 0.9487 - val_loss: 0.3603 - accuracy: 0.8877 Using TensorFlow backend. real 19m3.318s user 104m3.270s sys 7m48.890s
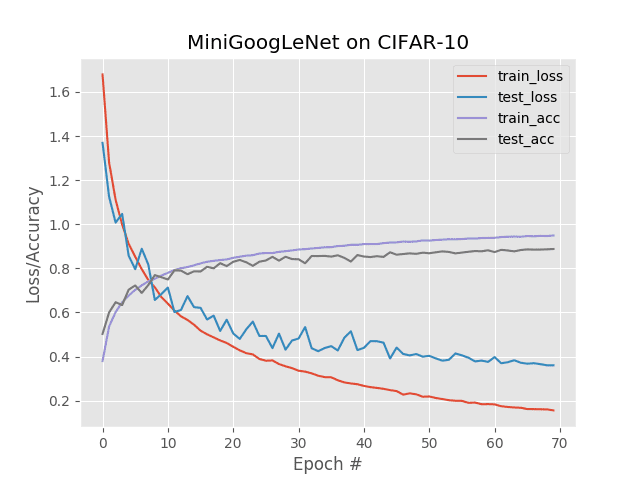
Here you can see the quasi-linear speed up in training: Using four GPUs, I was able to decrease each epoch to only 16 seconds. The entire network finished training in 19m3s.
As you can see, not only is training deep neural networks with Keras and multiple GPUs easy, it’s also efficient as well!
Note: In this case, the single GPU experiment obtained slightly higher accuracy than the multi-GPU experiment. When training any stochastic machine learning model, there will be some variance. If you were to average these results out across hundreds of runs they would be (approximately) the same.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we learned how to use multiple GPUs to train Keras-based deep neural networks.
Using multiple GPUs enables us to obtain quasi-linear speedups.
To validate this, we trained MiniGoogLeNet on the CIFAR-10 dataset.
Using a single GPU we were able to obtain 63 second epochs with a total training time of 74m10s.
However, by using multi-GPU training with Keras and Python we decreased training time to 16 second epochs with a total training time of 19m3s.
Enabling multi-GPU training with Keras is as easy as a single function call — I recommend you utilize multi-GPU training whenever possible. In the future I imagine that the multi_gpu_model will evolve and allow us to further customize specifically which GPUs should be used for training, eventually enabling multi-system training as well.
Ready to take a deep dive into deep learning? Follow my lead.
If you’re interested in learning more about deep learning (and training state-of-the-art neural networks on multiple GPUs), be sure to take a look at my new book, Deep Learning for Computer Vision with Python.
Whether you’re just getting started with deep learning or you’re already a seasoned deep learning practitioner, my new book is guaranteed to help you reach expert status.
To learn more about Deep Learning for Computer Vision with Python (and grab your copy), click here.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

