Table of Contents
- Integrating and Scaling Large Language Models with FastChat: A Complete Guide to LMSYS, Configuration, and Advanced Usage
- FastChat: Unlocking the Potential of Large Language Models
- Configuring Your Development Environment
- Project Structure
- Setting Up FastChat for LLM Inference
- Step 1: Create a Conda Environment
- Step 2: Clone the FastChat Repository
- Step 3: Install Rust and CMake on macOS (Optional)
- Step 4: Install FastChat in Editable Mode with Required Components
- Explanation of Dependencies
- Special Notes on Hardware Compatibility
- Wrapping Up
- Models Supported in FastChat
- LMSYS Models
- Other Popular Models
- Quantization and Backend Support
- Unlocking New Models in FastChat: Using the Microsoft Phi-3 Mini Model
- Serving LLMs in FastChat
- Chat with LLMs Using FastChat via Command-Line Interface
- Chat with LLMs Using FastChat via WebGUI
- API-Based Interaction with LLMs Using FastChat
- Question Answering with FastChat and Vicuna v1.5 LLM
- Embedding Comparison with FastChat
- Summary
Integrating and Scaling Large Language Models with FastChat: A Complete Guide to LMSYS, Configuration, and Advanced Usage
In this tutorial, you’ll explore FastChat by LMSYS, focusing on its capabilities for serving large language models. We’ll cover the setup process and demonstrate a practical application by setting up a Q&A system using LangChain and Gradio integrated with FastChat, powered by the OpenAI API with the Vicuna model.
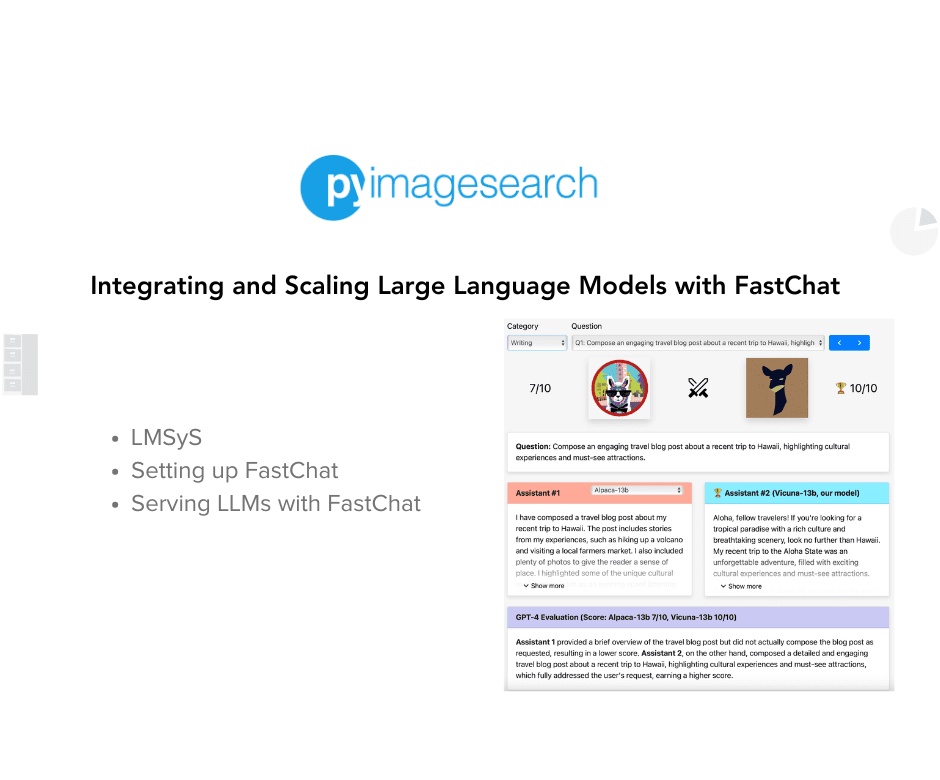
To learn about FastChat’s capabilities, including deploying LLMs, integrating with APIs, using tools like Chatbot Arena and LangChain, and its support for various models and deployment options, just keep reading.
FastChat: Unlocking the Potential of Large Language Models
In today’s rapidly evolving ecosystem of large language models (LLMs), new frameworks emerge almost daily. However, not all of these frameworks offer a comprehensive solution that combines training, serving, evaluation, and deployment in one package. This can be a significant limitation, especially for developers and data scientists who aim to maximize the potential of these advanced tools. FastChat stands out in this landscape as a robust platform specifically designed to meet these needs.
FastChat is an innovative framework developed by LMSYS, an organization dedicated to creating large model systems that are open, accessible, and scalable. It simplifies and streamlines the deployment and management of LLMs for chat-based applications. It offers a comprehensive suite of tools and functionalities that cater to various aspects of handling LLMs, from training and serving to evaluation and deployment.
About LMSYS
LMSYS (Large Model Systems) is an organization driven by the expertise of students and faculty from UC Berkeley’s Skylab. It is focused on pushing the boundaries of large language model development and deployment. LMSYS has developed various significant offerings that complement FastChat, categorized into evaluation systems, datasets, and models.
Evaluation Systems
- Chatbot Arena: Although separate from FastChat, Chatbot Arena by LMSYS integrates seamlessly with it. This platform enables anonymous, randomized evaluations of LLMs through crowdsourcing, featuring a leaderboard based on Elo ratings. It offers a space for testing and comparing different ChatBot models, providing valuable insights into performance capabilities.
- MT-Bench: A set of multi-turn, open-ended questions designed to evaluate chat assistants, using an LLM-as-a-judge methodology to score model responses.
- Arena Hard Auto: An automated pipeline that transforms live data into high-quality benchmarks for assessing chat assistants, featuring more challenging questions than MT-Bench.
Systems
- FastChat: A scalable platform for training, fine-tuning, serving, and evaluating LLM-based chatbots.
- SGLang: Provides an efficient interface and runtime for complex LLM programs.
- S-LoRA: Capable of serving thousands of concurrent LoRA adapters.
Datasets
- LMSYS-Chat-1M: Comprises one million real-world conversations featuring 25 leading LLMs.
- Chatbot Arena Conversations: Contains 33,000 cleaned conversations with pairwise human preferences collected from the Chatbot Arena.
- ToxicChat: A dataset of 10,000 high-quality examples aimed at content moderation in user-AI interactions based on queries from the Vicuna online demo.
Models
- Vicuna: Based on Llama, available in 7B, 13B, and 33B parameter sizes, offering performance that rivals 90% of ChatGPT-4’s quality.
- LongChat: Based on Llama, available in 7B and 13B sizes and is designed for long context lengths ranging from 16K to 32K tokens.
- FastChat-T5: Based on Flan-T5, available in 3B size, a compact yet powerful chat assistant designed for commercial use.
These offerings underscore LMSYS’s dedication to providing robust, scalable, and accessible tools for working with large language models.
Importance and Relevance of FastChat in the Current LLM Ecosystem
The rise of large language models has revolutionized the field of artificial intelligence, enabling new applications and improving existing ones across various domains. However, the complexity of deploying and managing these models can be a barrier to their widespread adoption. FastChat addresses these challenges by providing a user-friendly, scalable, and flexible platform that supports the entire lifecycle of LLM deployment.
Comprehensive Toolset
FastChat’s integrated approach covers all critical aspects of LLM management, from training and fine-tuning models to serving them in real-time and evaluating their performance. This holistic approach reduces the need for multiple disjointed tools, simplifying workflows for developers and data scientists.
Scalability and Flexibility
FastChat is designed to handle large-scale deployments, making it suitable for both small teams and large enterprises. Its support for various installation platforms and deployment types ensures that it can adapt to different environments and requirements. The framework includes a Distributed Multi-Model Serving System with WebUI and OpenAI-compatible RESTful APIs, which enhances its scalability.
For example, the Chatbot Arena, integrated with FastChat, serves over 10 million chat requests for more than 70 LLMs, showcasing its ability to handle high-demand environments effectively.

Enhanced Performance Monitoring
The framework includes robust evaluation tools that help in monitoring model performance, providing insights that can drive continuous improvement and optimization. This capability is crucial for maintaining high-quality, reliable AI applications.
Integration Capabilities
FastChat’s seamless integration with other tools and platforms (e.g., OpenAI, Gradio, and LangChain) extends its functionality and enhances its versatility. This makes it a valuable addition to the toolkit of any AI practitioner working with LLMs.

Support for Cutting-Edge Models and Tools
Developed by LMSYS, FastChat benefits from the organization’s ongoing research and development efforts. LMSYS has introduced several notable models and tools (e.g., Vicuna, Chatbot Arena, and MT-Bench), which further enrich the FastChat ecosystem.

In summary, FastChat emerges as a vital tool in the current LLM landscape, addressing key challenges and enabling more efficient and effective deployment of large language models. Its comprehensive capabilities, combined with its ease of use and scalability, make it an essential framework for developers and data scientists looking to harness the power of LLMs in their applications.
Configuring Your Development Environment
To follow this guide, you need to have the FastChat library and several integration libraries installed on your system. While we will cover the FastChat installation in the next section, this part focuses on installing the additional libraries that will aid in building applications with FastChat.
Fortunately, all of these libraries, including FastChat, are pip-installable:
$ pip install openai==1.34.0 $ pip install gradio==4.36.1 $ pip install langchain==0.2.5 $ pip install scipy==1.14.0
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
From there, take a look at the directory structure:
LLM-Apps-FastChat/ ├── assets │ ├── question-answering-app.png │ └── semantic-similarity-app.png ├── input_data │ ├── input_question_answer_dataset.txt │ └── input_sentence_comparison.txt ├── pyimagesearch │ ├── __init__.py │ ├── embedding_utils.py │ └── index_and_query.py ├── question_answering_app.py ├── requirements.txt ├── semantic_similarities.txt └── semantic_similarity_app.py
The above structure represents the entire project setup for the LLM applications using FastChat. We will go through the key scripts: question_answering_app.py, semantic_similarity_app.py, and the utility scripts inside the pyimagesearch directory. Each script plays a crucial role in processing text, generating embeddings, and setting up a user interface for ease of use.
For the full code and detailed video explanations, please visit PyImageSearch University.
Setting Up FastChat for LLM Inference
In this section, we will set up FastChat for large language model (LLM) inference, focusing on the components necessary for serving. We will use MiniConda to manage our environment.
Step 1: Create a Conda Environment
First, install MiniConda if you haven’t already. Then, create a new Conda environment with Python 3.10:
conda create -n fastchat python=3.10 conda activate fastchat
Step 2: Clone the FastChat Repository
Clone the FastChat repository and navigate to the project folder:
git clone https://github.com/lm-sys/FastChat.git cd FastChat
Step 3: Install Rust and CMake on macOS (Optional)
If you are running on macOS, you need to install Rust and CMake. Use Homebrew to install these dependencies:
brew install rust cmake
Step 4: Install FastChat in Editable Mode with Required Components
Before installing, ensure your pip is upgraded to support PEP 660:
pip install --upgrade pip
Since we will be making some minor changes to the source code to understand how FastChat works, we will install FastChat in editable mode. This will allow us to run FastChat in CLI mode, add print and logging statements, and observe the workflow and data flow through various components.
By installing in editable mode, we can add logging statements in places like cli.py, conversation.py, model_adapter.py, and others to understand the flow of the CLI and how different parts of the code interact.
To install FastChat in editable mode, use the following command:
pip3 install -e ".[model_worker,webui]"
This setup ensures that any changes you make to the code are immediately reflected, which is useful for development and debugging.
If you don’t plan to change the source code or make major modifications like integrating custom models, you can install FastChat in standard mode by omitting the -e flag:
pip3 install ".[model_worker,webui]"
Here’s the pyproject.toml file that outlines the dependencies and extras for FastChat:
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]
name = "fschat"
version = "0.2.36"
description = "An open platform for training, serving, and evaluating large language model based chatbots."
readme = "README.md"
requires-python = ">=3.8"
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
]
dependencies = [
"aiohttp", "fastapi", "httpx", "markdown2[all]", "nh3", "numpy",
"prompt_toolkit>=3.0.0", "pydantic<3,>=2.0.0", "pydantic-settings", "psutil", "requests", "rich>=10.0.0",
"shortuuid", "tiktoken", "uvicorn",
]
[project.optional-dependencies]
model_worker = ["accelerate>=0.21", "peft", "sentencepiece", "torch", "transformers>=4.31.0", "protobuf"]
webui = ["gradio>=4.10"]
train = ["einops", "flash-attn>=2.0", "wandb"]
llm_judge = ["openai<1", "anthropic>=0.3", "ray"]
dev = ["black==23.3.0", "pylint==2.8.2"]
[project.urls]
"Homepage" = "https://github.com/lm-sys/fastchat"
"Bug Tracker" = "https://github.com/lm-sys/fastchat/issues"
[tool.setuptools.packages.find]
exclude = ["assets*", "benchmark*", "docs", "dist*", "playground*", "scripts*", "tests*"]
[tool.wheel]
exclude = ["assets*", "benchmark*", "docs", "dist*", "playground*", "scripts*", "tests*"]
Explanation of Dependencies
The pyproject.toml file lists both the base dependencies and optional dependencies. Here’s a breakdown:
- Base Dependencies: Essential packages required for FastChat are installed. These include:
aiohttpfastapihttpxnumpyrequestsuvicorn- and others
- Optional Dependencies:
- Model Worker: Installs several important packages:
accelerate>=0.21peftsentencepiecetorchtransformers>=4.31.0protobuf
- Web UI: Installs
gradio>=4.10to create a web interface for interacting with the language models. - Train: Includes dependencies for training models.
- LLM Judge: Used for evaluation tasks.
- Dev: Includes development tools like
blackandpylint.
- Model Worker: Installs several important packages:
Understanding the Role of Each Component
- Torch: The
torchlibrary is the core framework for running machine learning models, including those for inference on GPUs or CPUs. It automatically detects your system’s hardware and installs the appropriate version. For example, if you have CUDA 11.8 with NVIDIA driver 520, it will install the CUDA-compatible version oftorch. - Transformers: This library by Hugging Face provides tools for working with transformer-based models, which are crucial for running modern LLMs.
- Accelerate: This helps in optimizing the performance of the model, particularly useful in distributed and multi-GPU setups.
- PEFT: Parameter Efficient Fine-Tuning (PEFT) might not be used directly in inference, but it is included as part of the setup for potential future tuning or optimization tasks.
- SentencePiece: This is a text tokenizer and detokenizer library essential for preparing inputs and outputs for the model.
- Gradio: This is used to create interactive web interfaces for model interaction, making it easier to deploy and test models via a web UI.
Special Notes on Hardware Compatibility
- CUDA and NVIDIA GPUs: If you have an NVIDIA GPU and CUDA installed,
torchwill automatically detect this and install the version with CUDA support, allowing you to use thecudadevice flag during inference:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- Apple Silicon (M1, M2, M3): On macOS with Apple Silicon chips,
torchwill install with support for Metal Performance Shaders (MPS):
device = torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
- CPU: For systems without GPU support, the CPU version of
torchis installed by default.
Wrapping Up
By following these steps, you can efficiently set up FastChat for LLM inference. This setup allows you to leverage powerful hardware capabilities for optimal performance while focusing on serving and interacting with large language models through a web interface.
Models Supported in FastChat
Before exploring the various deployment methods for running inference with large language models (LLMs) using FastChat, it’s essential to understand the range of models supported by the platform. FastChat provides a versatile environment that supports numerous models, including those developed by LMSYS and other popular models in the LLM community. Additionally, FastChat allows users to integrate their own custom models, providing flexibility for specific applications.
LMSYS Models
LMSYS has developed several notable models that are fully supported in FastChat:
Vicuna
- Base: Llama for Vicuna versions 0 to 1.3 and Llama 2 for Vicuna version 1.5
- Sizes: 7B, 13B, 33B
- Details: Vicuna is an open-source chatbot model developed by LMSYS. It is trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. Preliminary evaluations using GPT-4 as a judge show that Vicuna-13B achieves more than 90% of the quality of OpenAI’s ChatGPT and Google’s Bard, outperforming other models like LLaMA and Stanford Alpaca in more than 90% of cases. The cost of training Vicuna-13B is around $300. More details are available in the Vicuna blog post.
LongChat
- Base: Llama
- Sizes: 7B, 13B
- Details: LongChat is tailored for handling long context lengths, ranging from 16K to 32K tokens. This model is ideal for applications requiring extended interactions (e.g., detailed consultations or lengthy discussions). LongChat extends Vicuna’s capabilities to manage more extensive dialogues efficiently. Evaluation results show LongChat-13B’s long-range retrieval accuracy is up to 2x higher than that of other long-context open models. For more information, check the LongChat blog post.
FastChat-T5
- Base: Flan-T5
- Size: 3B
- Details: FastChat-T5 is an open-source chatbot trained by fine-tuning Flan-T5-xl (3B parameters) on user-shared conversations collected from ShareGPT. It is based on an encoder-decoder transformer architecture and can generate responses to user inputs autoregressively. FastChat-T5 was trained in April 2023 and is primarily intended for commercial use of large language models and chatbots, but it can also be used for research purposes. For more information, visit the FastChat-T5 Hugging Face page.
Other Popular Models
FastChat supports a wide range of popular models, including but not limited to:
- Llama 3
- Llama 2
- Mistral
- Code Llama
- Qwen
- ChatGLM
- Alpaca
- Dolly
- Falcon
- StableLM
- WizardLM
- and many more!
The FastChat model support readme provides a more detailed list of the model versions and links to their Hugging Face model cards.
Quantization and Backend Support
FastChat supports several advanced quantization methods to enhance the performance and efficiency of large language models (LLMs) on GPUs. These methodologies, such as reducing a model from FP32 to 4-bit, significantly decrease memory usage and increase inference speed, making them ideal for various applications and hardware setups.
Note on GGUF: GGUF is a very popular quantization format used in llama.cpp, it is not currently supported in FastChat.
Let’s look at three of the popular quantization methods that are supported by FastChat, which help enhance the performance and efficiency of LLMs on GPUs:
ExLlamaV2 GPTQ Inference Framework
FastChat integrates the ExLlamaV2 customized kernel to provide faster GPTQ inference speeds. ExLlamaV2 supports different modes, allowing you to use either GPTQ as the backend quantization or the EXL2 method. For more information on ExLlamaV2, refer to the ExLlamaV2 readme provided by FastChat.
GPTQ 4-Bit Inference
FastChat supports GPTQ 4-bit inference with GPTQ-for-LLaMa, offering efficient quantized model performance. It has also provided detailed benchmarks comparing FP16 with GPTQ quantization on the LLaMA-13B model. You can read more about the setup and performance in the GPTQ 4-bit inference readme by FastChat.
AWQ 4-Bit Inference
FastChat integrates Activation-Aware Weight Quantization (AWQ) to provide efficient and accurate 4-bit LLM inference, allowing larger models to run within device memory constraints and accelerating token generation. It has performed benchmarks on various GPUs, including the RTX A6000, RTX 4090, and the Jetson Embedded Orin device, with models like Vicuna 7B/13B and LlaMA 2 7B/13B. The benchmark details are in the AWQ readme provided by FastChat.
Unlocking New Models in FastChat: Using the Microsoft Phi-3 Mini Model
In this section, we explore integrating a new model into FastChat beyond the officially supported list. FastChat provides the flexibility to add and run new local models, and we decided to experiment with the Phi-3-Mini-4K-Instruct Model by Microsoft, which is not listed among the supported models by FastChat.
While FastChat supports a variety of models, the documentation outlines specific steps for adding new models, including creating a conversation template and implementing a model adapter. Our goal here is to demonstrate how to successfully run the Phi-3 model in FastChat and understand the underlying processes involved.
Insights and Debugging Process
The complete video detailing the integration and debugging process of the Microsoft Phi-3 Mini model with FastChat is available inside PyImageSearch University. This includes a comprehensive walkthrough of how FastChat processes model integrations, especially a non-supported model, when running a model for chatting in CLI mode.
Key Points Covered in the Video
- Exploring Adapters: We delve into the different adapters used by FastChat (e.g., the VicunaAdapter and BaseAdapter) to understand their roles in loading models.
- Loading Mechanisms: We examine the
load_modelandload_compress_modelfunctions, detailing how FastChat handles model loading and memory optimization. - Debugging Insights: We show step-by-step debugging processes to verify model loading and ensure compatibility with custom models.
By understanding these internals, you can confidently integrate and run custom models in FastChat, extending its utility beyond the officially supported list.
Steps to Add a New Model (as per FastChat Documentation)
- Implement a Conversation Template: Create a conversation template tailored to the new model.
- Implement a Model Adapter: Develop a model adapter specific to the new model to handle loading and configuration.
- Update Supported Models: Optionally, add the new model to the list of supported models in FastChat.
In our case, we explored whether these steps are strictly necessary or if we can bypass some of them for certain models, like the Phi-3 model.
This deep dive into model integration with FastChat provides valuable insights for those looking to extend FastChat’s capabilities. By following the steps and understanding the underlying mechanisms, you can effectively run a wide range of custom models, making FastChat a versatile tool in your AI toolkit.
Serving LLMs in FastChat
Now, this is the most interesting and important section in today’s lesson. We’ve covered quite a lot of ground, discussing FastChat, the work of the LMSYS organization, and how to set it up. We’ve also explored adding custom models and the different types of models supported in FastChat. This is where things get exciting as we dive into the core topic: serving LLMs in FastChat.
FastChat provides various methods to deploy and interact with language models, offering flexibility and convenience for different use cases. In this section, we’ll cover the following deployment options:
- Command-Line Interface (CLI)
- WebGUI
- API-Based Deployment
- OpenAI-Compatible API
- LangChain Integration
Chat with LLMs Using FastChat via Command-Line Interface
FastChat offers a straightforward Command-Line Interface (CLI) to interact with language models. This section will cover how to use the CLI, important arguments, and how to handle different configurations.
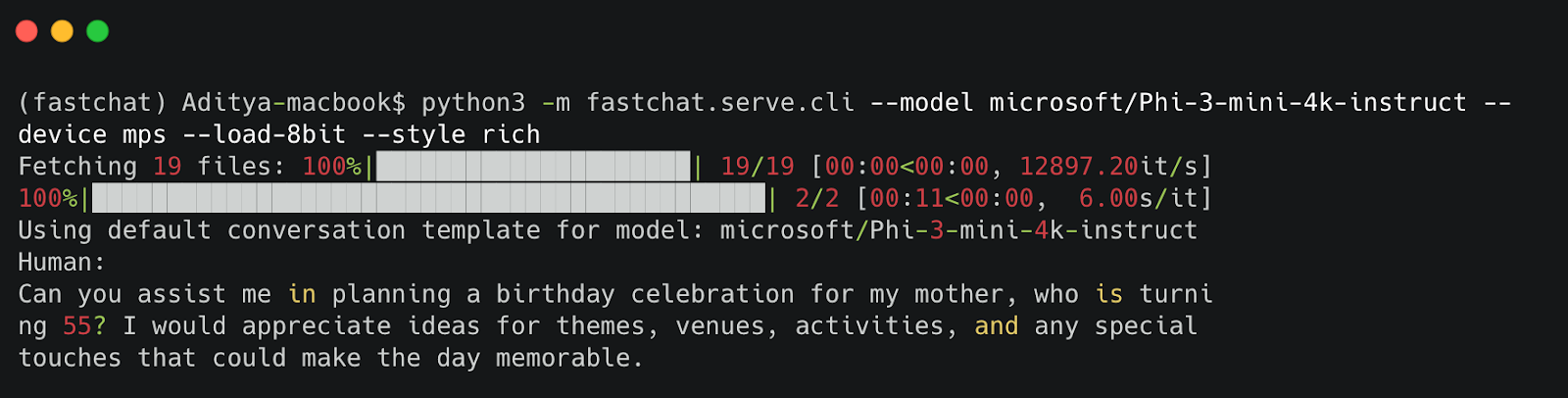
To use the CLI, you can run the following command:
python3 -m fastchat.serve.cli --model <model-path>
The main script for the CLI is located in the serve directory, specifically cli.py. Here’s a detailed explanation of some key arguments and their usage:
Model Path:
The --model argument specifies the path to the model weights. This can be a local folder on your device or a Hugging Face Repo ID.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct
If you run the command as is, it will expect CUDA to be available for GPU acceleration. If CUDA is not available, you will get an assertion error.
Device:
By default, the CLI uses CUDA for GPU acceleration. If no GPU is available or if running on a different backend, you can specify the device.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --device cpu
On a Mac with Apple Silicon, use the Metal Performance Shaders (MPS) backend. MPS is a PyTorch backend that uses the Metal GPU framework for acceleration on macOS.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --device mps
Note: When running the CLI without specifying a device, FastChat defaults to expecting CUDA. If CUDA is not available, such as on a Mac with Apple Silicon or a machine without a GPU, it results in an error: “Torch not compiled with CUDA enabled.”
Memory Management:
Load 8-bit: Enable 8-bit compression to reduce memory usage by approximately half. This can be especially useful when running large models on limited hardware.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --load-8bit
CPU Offloading:
Offload parts of the model to CPU memory, which requires 8-bit compression. This allows you to run larger models even if your GPU memory is limited.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --load-8bit --cpu-offloading
Multiple GPUs:
You can use MultiGPU to achieve Model Parallelism by aggregating GPU memory from multiple GPUs on the same machine. This allows you to handle larger models that do not fit into a single GPU’s memory.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --num-gpus 2
Max GPU Memory:
Specify the maximum memory per GPU for storing model weights. This allows the allocation of more memory for activations, enabling longer context lengths or larger batch sizes.
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --max-gpu-memory 20G
Other Parameters:
- Temperature: Adjusts the creativity of the model’s responses.
- Max New Tokens: Limits the number of tokens generated in a response.
- Style: Enables rich text output for better text streaming quality. However, it may not be compatible with all terminals.
Example command for running a model with multiple configurations:
python3 -m fastchat.serve.cli --model microsoft/Phi-3-mini-4k-instruct --device mps --load-8bit --num-gpus 2 --max-gpu-memory 20G --temperature 0.7

These configurations and options allow you to tailor the CLI to fit your specific hardware and use cases, providing a robust and flexible way to interact with language models in FastChat.
Chat with LLMs Using FastChat via WebGUI
FastChat provides a powerful and flexible solution for serving AI models through a web-based interface. In this section, we’ll explore how to set up FastChat using the WebGUI, including the necessary components and commands. This guide will help you understand the architecture and get your models up and running with ease.

Overview of FastChat’s WebGUI Architecture
FastChat’s architecture is designed to manage and serve AI models through a web interface efficiently. It consists of three main components:
- Web Servers: Interface with users and provide the web-based user interface (UI). The Gradio server handles user inputs, displays responses, and manages the chat interface. It supports interactive components like text boxes, buttons, and sliders to create a seamless user experience.
- Model Workers: Host one or more AI models and handle the computational tasks. They load the models, process input data, generate responses, and handle embedding tasks if needed. The model workers are capable of running various models, including those configured for high throughput and specialized configurations like GPTQ, AWQ, and ExLlama.
- Controller: Coordinates the interactions between the web servers and model workers. It manages worker registration, monitors their status through heartbeats, and dispatches tasks based on the configured dispatch method (e.g., shortest queue or lottery). The controller ensures efficient resource allocation and task distribution to maintain performance and scalability.

Control Plane
The control plane is responsible for managing the system’s overall configuration, control, and state. It coordinates and directs how data should be processed and handled. In the context of FastChat, the controller serves as the control plane.
Purpose
- Manages the registration of model workers.
- Monitors their status.
- Handles task dispatching.
- Ensures the system is running smoothly.
Data Plane
The data plane is responsible for the actual processing and handling of the data. It carries out the tasks as directed by the control plane. In FastChat, the model workers and the Gradio web server function as parts of the data plane.
- Model Workers: Perform the computational tasks of processing inputs and generating model outputs.
- Gradio Web Server: Handles user interactions, sends user inputs to the model workers, and displays the outputs to the users.
This setup allows for scalable and flexible deployment, enabling you to serve multiple models with varying throughput requirements.
To get started with FastChat, you’ll need to launch the controller, model workers, and the Gradio web server. Here are the detailed steps and commands to follow:
Launch the Controller
The controller is responsible for managing distributed model workers. It registers workers, monitors their health, and dispatches tasks. Run the following command to start the controller:
python3 -m fastchat.serve.controller
This will initialize the controller, making it ready to coordinate with model workers. The controller periodically removes stale workers who do not send heartbeats within the configured expiration time, ensuring the system remains responsive and healthy.
Launch the Model Worker(s)
Next, launch the model workers that will host your AI models. These workers are responsible for executing the models, handling input, and generating output. Use the following command, replacing lmsys/vicuna-7b-v1.5 with the path to your model:
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
Wait until the process finishes loading the model and you see “Uvicorn running on…”. The model worker will automatically register itself with the controller. Model workers manage various configurations such as device type (CPU, GPU, NPU), number of GPUs, and memory allocation, ensuring efficient model execution.
The model worker handles tasks by receiving input data, processing it using the loaded model, and generating the output. It communicates with the controller via HTTP requests to register itself, send heartbeats, and receive tasks.
Test the Model Worker Connection
To ensure that your model worker is properly connected to the controller, send a test message. This step verifies the communication between the controller and the model worker:
python3 -m fastchat.serve.test_message --model-name vicuna-7b-v1.5
You should see a short output confirming the connection. This test ensures that the model worker can handle requests and generate responses correctly.
Launch the Gradio Web Server
The Gradio web server provides the user interface for interacting with your models. It manages user inputs, displays responses, and handles the overall chat interface. Launch it using the following command:
python3 -m fastchat.serve.gradio_web_server
This will start the Gradio server, and you can open your browser to begin chatting with the model. If the models do not show up, try rebooting the Gradio web server. The Gradio server supports various features (e.g., interactive components, parameter adjustment, and response regeneration), providing a comprehensive user experience.
Launch Multi-Tab Gradio Server
For a more comprehensive user interface that includes the Chatbot Arena tabs, which provide different model interactions in separate tabs, launch a multi-tab Gradio server:
python3 -m fastchat.serve.gradio_web_server_multi
This configuration enhances the user experience by providing multiple tabs for different chat models or features within the same interface. Users can switch between various models and configurations seamlessly.
By following these steps, you can efficiently set up and scale FastChat to serve AI models via a web-based interface. Whether you’re serving a single model or multiple models, FastChat provides the flexibility and performance needed to handle a variety of use cases. This guide, combined with detailed explanations of the controller, model worker, and Gradio web server scripts, should help you create a comprehensive and scalable deployment for serving AI models using FastChat.
API-Based Interaction with LLMs Using FastChat
FastChat provides robust capabilities for API-based interactions, enabling seamless integration with various applications. This includes OpenAI-compatible RESTful APIs as well as support for LangChain, a popular library for developing applications using large language models. Both integrations enhance the FastChat ecosystem, allowing you to leverage powerful features to build sophisticated applications on top of LLMs.
OpenAI-Compatible RESTful APIs and SDK
FastChat provides OpenAI-compatible APIs for its supported models, allowing it to serve as a local drop-in replacement for OpenAI APIs. The FastChat server is compatible with both the OpenAI Python library and cURL commands. This compatibility extends to running the REST APIs inside a Google Colab notebook, providing flexibility in different development environments.
When you spin up an OpenAI-compatible RESTful API, it leverages FastAPI, providing a FastAPI Swagger interface for easy interaction with your models. As shown in the image below, the Swagger interface allows you to interact with the API directly from your browser, making it simple to test and debug.

The OpenAI-compatible API server in FastChat uses FastAPI to create various endpoints, such as:
- List Models: Retrieve the list of available models.
- Chat Completions: Generate chat completions using the specified model.
- Completions: Generate text completions.
- Embeddings: Compute embeddings for the input text.
Refer to the video at PyImageSearch University for a walkthrough of using the OpenAI API with Python code and cURL commands. This video provides comprehensive coverage of these topics, ensuring you can effectively leverage FastChat’s API capabilities in your projects.
LangChain Integration
LangChain is a library that facilitates application development by leveraging large language models (LLMs) and enabling their composition with other sources of computation or knowledge. FastChat’s OpenAI-compatible API server supports LangChain, making it easy to use open models within the LangChain framework.

Question Answering with FastChat and Vicuna v1.5 LLM
In this section, we delve into an exciting application of FastChat — question answering using FastChat and the Vicuna v1.5 LLM with LangChain integration. As demonstrated in the screenshot below, we have set up a seamless integration where users can upload a text file, create an index, and then ask questions related to the content of the file. This powerful combination leverages the strengths of LangChain and FastChat to provide accurate and context-aware responses.

In the example shown, we have uploaded the “state_of_the_union.txt” file and asked a question regarding the measures taken by the United States in response to Russia’s invasion of Ukraine. The system successfully indexed the document and provided a comprehensive answer, showcasing the capability of Vicuna v1.5 to understand and generate relevant responses based on the provided context.
Here is the detailed process:
- Embedding Creation
- The
upload_and_create_indexfunction creates an instance ofOpenAIEmbeddingsto generate embeddings for the text file content. TextLoader, a utility from LangChain, loads the text from the uploaded file.VectorstoreIndexCreatorfrom LangChain takes the embeddings and creates an index from the text chunks.
- The
- Question Handling
- The
ask_questionfunction checks if an index is available. - If an index is available, the question is embedded in it, and the index is queried for the most similar text chunks to the question.
- The matching text chunks are then used to generate a response.
- The
- Gradio Interface
- The Gradio interface is set up to allow users to upload a text file, create an index, and ask questions.
upload_and_create_indexis connected to the file upload and index creation buttons.ask_questionis connected to the question input and answer output elements.
To learn how to set up this integration and see the production-ready code in action, refer to the video available at PyImageSearch University. The video includes detailed instructions and production code, ensuring you can replicate and extend this functionality for your own applications. Access to the full code and video tutorial is exclusively available to our subscribers at PyImageSearch University.
This setup highlights the practical application of integrating LangChain with FastChat and demonstrates how powerful language models (e.g., Vicuna v1.5) can be utilized to create sophisticated question-answering systems.
Embedding Comparison with FastChat
In addition to question answering, FastChat can also be used for embedding comparison tasks. This section demonstrates how to use FastChat to compute embeddings for different texts and calculate their cosine similarities. By leveraging these capabilities, you can measure the similarity between various text snippets, which can be useful in applications (e.g., document clustering, content recommendation, and plagiarism detection).
Purpose
This application computes embeddings for various texts using FastChat’s API and calculates the cosine similarity between these embeddings to measure their similarity. The cosine similarity score helps determine how close or distant the text embeddings are from each other, providing a quantitative measure of text similarity.
Process Overview
- Text Definition: Define a set of texts to be compared. These texts can be sentences, paragraphs, or entire documents.
- Embedding Retrieval: Use FastChat’s API to get embeddings for each text. The embeddings are high-dimensional vectors representing the semantic content of the texts.
- Similarity Calculation: Calculate the cosine similarity between the embeddings of different texts. Cosine similarity measures the cosine of the angle between two vectors, providing a value between
-1(completely dissimilar) and1(completely similar). - Result Display: Print the cosine similarity scores. These scores help identify which texts are more similar to each other.
Detailed Steps
Text Definition
Start by defining the set of texts you want to compare. These texts can be any textual data you are interested in analyzing. For example:
- ‘Artificial intelligence is transforming industries across the globe.’
- ‘Machine learning provides systems the ability to automatically learn and improve from experience.’
- ‘Deep learning is a subset of machine learning in artificial intelligence.’
- ‘Mount Everest is the highest mountain in the world.’
Embedding Retrieval
Next, use FastChat’s API to get embeddings for each text. The API provides a convenient way to generate these embeddings using a pre-trained language model. In this case, we use the Vicuna v1.5 model by LMSYS to generate the embeddings.
Similarity Calculation
With the embeddings obtained, calculate the cosine similarity between the embeddings of different texts. Cosine similarity measures the cosine of the angle between two vectors, providing a value between -1 (completely dissimilar) and 1 (completely similar).
Result Display
Print the cosine similarity scores. These scores help identify which texts are more similar to each other.
Visit PyImageSearch University to see the complete code and a detailed video explanation of this process. Here, you will find step-by-step instructions on how to implement embedding comparison using FastChat’s API, including detailed descriptions and practical examples.

What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this comprehensive guide, we explored the capabilities and functionalities of FastChat, a robust framework developed by LMSYS for integrating and scaling large language models (LLMs). Starting with an introduction to the platform, we detailed its significance in the current LLM ecosystem, emphasizing its role in enhancing the deployment and management of chat-based applications.
The guide covered step-by-step instructions for configuring the development environment, including setting up FastChat and the necessary tools and dependencies. We discussed the various models supported by FastChat, such as LMSYS models and other popular models, highlighting features like quantization and backend support. Additionally, we provided insights into deploying LLMs through FastChat using different interfaces such as command-line, WebGUI, and API-based interactions.
Special attention was given to practical applications like question answering systems and embedding comparisons, utilizing tools like LangChain and Gradio integrated with FastChat, powered by models like Vicuna v1.5.
Overall, this guide serves as a vital resource for developers and data scientists seeking to leverage FastChat for effective deployment and management of large language models. It ensures they can harness the full potential of these advanced tools in their projects.
Citation Information
Martinez, H. “Integrating and Scaling Large Language Models with FastChat,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Sharma, eds., 2024, https://pyimg.co/nzvaw
@incollection{Martinez_2024_FastChat,
author = {Hector Martinez},
title = {Integrating and Scaling Large Language Models with FastChat},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Aditya Sharma},
year = {2024},
url = {https://pyimg.co/nzvaw},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.