
Table of Contents
Automatic License Plate Reader Using OCR in Python
In this tutorial, you will build an Automatic License/Number Plate Reader (ANPR) system using PaddleOCR, Hugging Face transformers, and Python.
There are various terms used to refer to a license plate (e.g., license plate, number plate, registration plate, vehicle number plate, and plate number). Regardless of what you call it, the objective remains the same: reading and interpreting the characters on these plates.
In this tutorial, we will use Optical Character Recognition (OCR) and Python to demonstrate how to read and process license plates (ANPR) accurately. Whether you’re a beginner or an experienced coder, this step-by-step guide will provide you with the knowledge and tools needed to implement OCR for vehicle identification effectively.
Automatic License Plate Reader (ANPR) is simply a license plate reader and recognition workflow. This is a critical task in various applications (e.g., traffic monitoring, automated toll collection, and law enforcement).
At PyImageSearch, this has been solved previously using OpenCV: OpenCV: Automatic License/Number Plate Recognition (ANPR) with Python. In this previous post, we solved ANPR using the following steps:
- Loaded an input image from disk
- Found the license plate in the input image
- Performed OCR on the license plate
- Displayed the ANPR result on our screen
In this post, our approach is slightly different and involves two main steps:
- Localization: Using OWL-ViT-2 (from the Hugging Face hub) to detect and localize the license plate within an image.
- Text Extraction: Using PaddleOCR to perform Optical Character Recognition (OCR) on the localized license plate to extract the text.
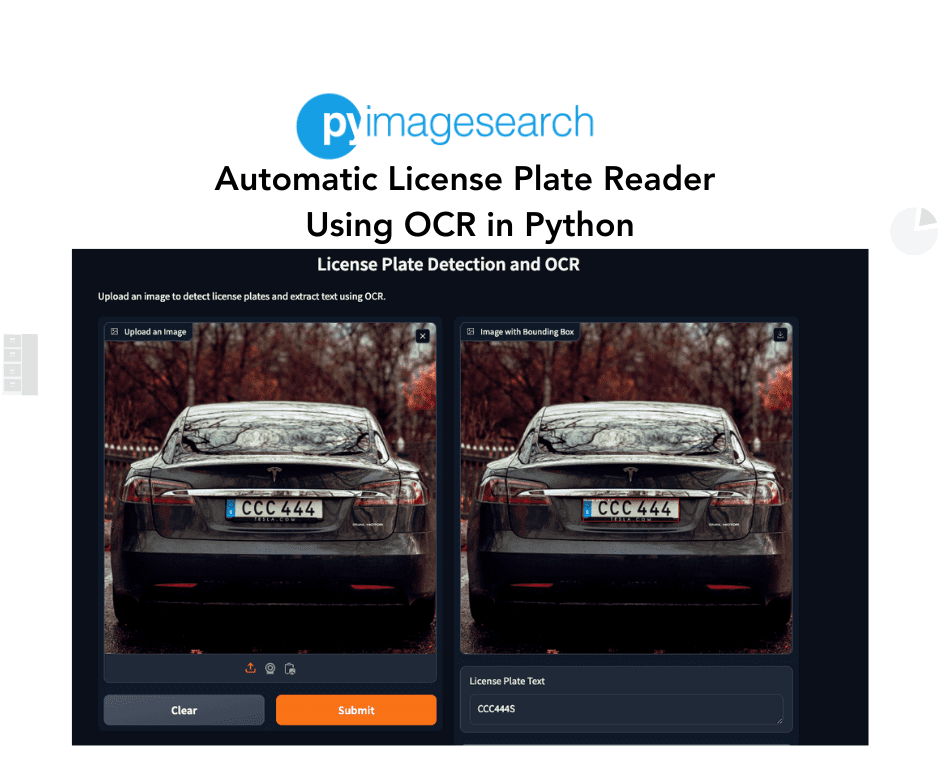
We will also provide a guide on deploying this pipeline using Gradio (shown in Figure 1), a user-friendly tool for building machine-learning web applications.

An ANPR-specific dataset, preferably with plates from various countries and in different conditions, is essential for training robust license plate recognition systems, enabling the model to handle real-world diversity and complexities.
Roboflow offers free tools for each stage of the computer vision pipeline, which will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state-of-the-art dataset libraries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using PyImageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc.), and connect to applications or 3rd-party tools.
To learn how to read license plates using State-of-the-Art models, just keep reading.
License Plate Reader
A license plate reader is a crucial component of various applications (e.g., automated toll collection, traffic monitoring, and law enforcement). Traditionally, detecting license plates involved a combination of image processing techniques and machine learning models. The next section will explore the evolution of license plate reader methods, from early approaches to the advent of detection transformers, highlighting key techniques and their contributions to the field.
A Small Survey of License Plate Reader Methods
In the early days of license plate readers, methods were heavily reliant on traditional image processing techniques. These methods typically involved a multi-step process:
- LeNet-5: One of the earliest and most well-known convolutional neural network (CNN) architectures, LeNet-5, was developed by Yann LeCun et al. It consists of two sets of convolutional and subsampling layers followed by fully connected layers. Although LeNet-5 was initially designed for digit recognition, its architecture laid the groundwork for more complex models used in license plate readers.
- AlexNet: AlexNet, developed by Alex Krizhevsky et al., brought CNNs into the mainstream by winning the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012. AlexNet consists of five convolutional layers followed by three fully connected layers and utilizes Rectified Linear Units (ReLUs) for non-linear activation. This model demonstrated the power of deep learning in visual tasks and influenced subsequent research in license plate readers.
- R-CNN: The original R-CNN model, developed by Ross Girshick et al., uses a selective search algorithm to generate around 2000 region proposals from an image. Each proposal is then warped to a fixed size and fed into a CNN (e.g., AlexNet) for feature extraction. The features are subsequently classified using linear support vector machines (SVMs ). Although effective, R-CNN was computationally expensive due to the repeated forward passes through the CNN for each region proposal.
- Fast R-CNN: Fast R-CNN, also by Ross Girshick, improved upon the R-CNN by introducing a single-stage training algorithm. It uses a Region of Interest (RoI) pooling layer to extract fixed-size feature maps from the convolutional feature map for each region proposal. This approach allows for a single forward pass through the CNN, significantly reducing computation time and improving training efficiency.
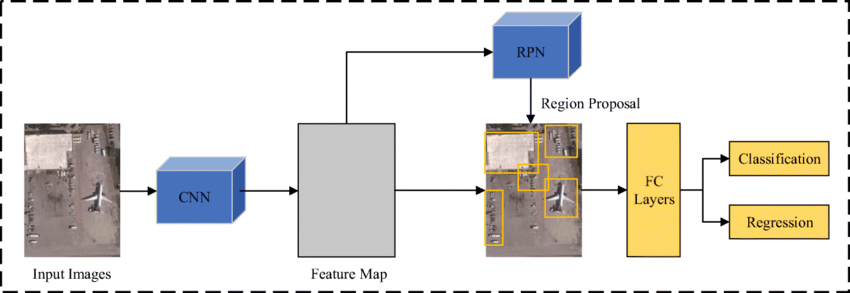
- Faster R-CNN: Faster R-CNN, developed by Shaoqing Ren et al., further advanced the R-CNN series by integrating a region proposal network (RPN) directly into the CNN architecture. The RPN generates region proposals, which are then used by the Fast R-CNN detector. This end-to-end approach streamlines the detection process and achieves state-of-the-art performance.
- Region Proposal Network (RPN): An RPN (shown in Figure 2) consists of a fully convolutional network that generates region proposals by predicting object bounds and scores at each position on a regular grid. It uses anchor boxes of different scales and aspect ratios to handle objects of various sizes and shapes.
Modern-Day Object Detectors
The latest breakthrough in license plate readers is the use of detection transformers, such as the DETR (Detection Transformer) model. Detection transformers address many limitations of previous methods by leveraging the power of transformers, which have revolutionized natural language processing (NLP).
Transformers in Vision: Transformers, originally designed for sequence-to-sequence tasks in NLP, have been adapted for vision tasks. Vision transformers (ViTs) split images into patches and process them as sequences, capturing global context more effectively than CNNs.
DETR: The Detection Transformer (DETR) model combines transformers with CNNs to provide a fully end-to-end object detection system. DETR (shown in Figure 3) eliminates the need for hand-crafted proposals or anchor boxes, simplifying the detection pipeline and improving robustness to various image conditions.
Advantages of Detection Transformers: These models offer multiple benefits (e.g., better handling of occlusions, varying lighting conditions, and complex backgrounds). They also simplify the training process, as they do not require specialized post-processing steps.

Owlv2
OWL-ViT builds on the foundational Vision Transformer architecture but incorporates several enhancements (as shown in Figure 4) to improve its object detection performance:
- Patch Embedding: The input image is divided into fixed-size patches, each of which is linearly embedded into a high-dimensional space. This process transforms the image into a sequence of patch embeddings.
- Transformer Encoder: The sequence of patch embeddings is processed by a series of transformer encoder layers. These layers apply self-attention mechanisms to capture relationships between patches, enabling the model to understand the global structure of the image.
- Detection Head: The output from the transformer encoder is fed into a detection head, which generates bounding boxes and class labels for objects within the image. The detection head is designed to handle an open-ended set of object classes, leveraging the model’s open-world learning capabilities.
- Contrastive Learning: OWL-ViT employs contrastive learning techniques to enhance its ability to distinguish between different objects. This approach involves training the model to maximize the similarity between representations of the same object while minimizing the similarity between representations of various objects.

PaddleOCR
PaddleOCR is a versatile OCR system that combines multiple deep-learning models to detect and recognize text in images accurately. It is designed to be highly flexible and efficient, supporting multiple languages and character types. The system is built on PaddlePaddle (PArallel Distributed Deep LEarning), which ensures it benefits from the platform’s high performance and scalability.
Architecture of PaddleOCR
PaddleOCR’s architecture consists of several key components (as shown in Figure 5):
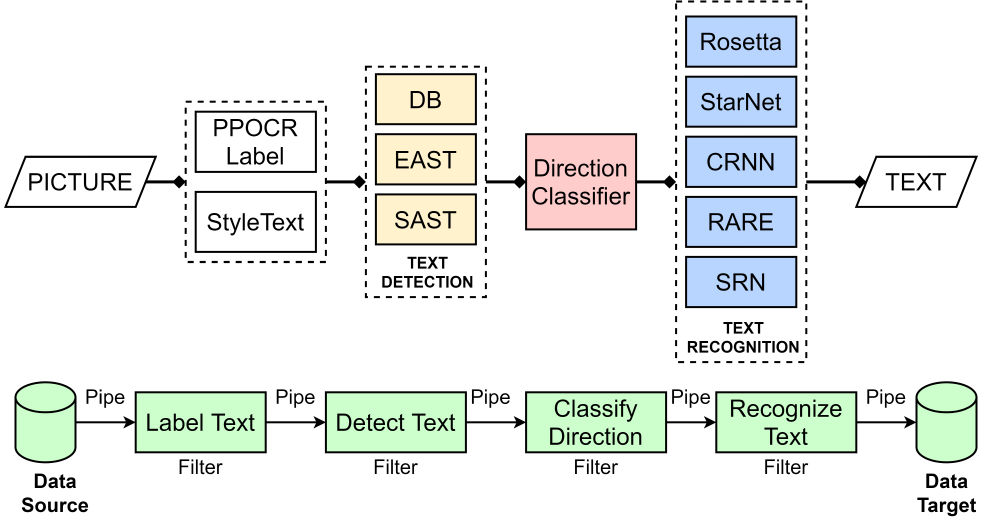
- Text Detection: Identifying the regions in an image that contain text.
- Text Recognition: Converting the detected text regions into machine-readable text.
- Post-Processing: Refining the recognized text to improve accuracy and readability.
- Text Detection Models:
- Differentiable Binarization (DB): An efficient and accurate text detector that uses a differentiable binarization module to handle complex text layouts.
- EAST (Efficient and Accurate Scene Text Detector): A robust detector that balances speed and accuracy by predicting word or text-line-level quadrangles.
- Text Recognition Models:
- CRNN (Convolutional Recurrent Neural Network): This type of neural network combines CNNs and RNNs to recognize text sequences. It captures both spatial features and sequential dependencies.
- Attention OCR: Uses attention mechanisms to improve the recognition of irregular text by focusing on relevant parts of the text region.
Configuring Your Development Environment
To follow this guide, you need to have the OpenCV library installed on your system.
Luckily, both transformers and paddleOCR are pip-installable:
$ pip install -q paddlepaddle $ pip install -q "paddleocr>=2.0.1" $ pip install transformer
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Setup and Imports
First, we need to set up our environment by installing the necessary libraries. We install paddlepaddle for running PaddleOCR and paddleocr itself, which will be used for Optical Character Recognition (OCR) tasks later on.
!pip install -q paddlepaddle !pip install -q "paddleocr>=2.0.1"
Next, we download and unzip a dataset of car plate images from Kaggle. This dataset will be used to test our object detection and OCR processes.
!kaggle datasets download -d andrewmvd/car-plate-detection !unzip -q /content/car-plate-detection.zip
We import the required libraries for our tasks. We use the pipeline from the transformers library for setting up a zero-shot object detection model. The PIL library is used for image processing.
from transformers import pipeline from PIL import Image from PIL import ImageDraw
We specify the model checkpoint for the object detection pipeline. The model google/owlv2-base-patch16-ensemble is used for zero-shot object detection, which allows us to detect objects without having a pre-defined set of classes. We set the model to use a GPU if available.
checkpoint = "google/owlv2-base-patch16-ensemble"
detector = pipeline(
model=checkpoint,
task="zero-shot-object-detection",
device="cuda"
)
We load an image from the dataset. This image will be used as input for our object detection and OCR tasks. The image is then displayed to verify it has been loaded correctly.
original_image = Image.open("/content/images/Cars0.png")
original_image
Object Detection
We perform object detection on the loaded image to locate the license plate. The detector pipeline is used with the candidate_labels parameter set to ["license plate"], indicating we want to detect license plates.
prediction = detector(
original_image,
candidate_labels=["license plate"],
)[0]
print(prediction)
The prediction variable contains the results of the object detection. It includes the coordinates of the bounding box around the detected license plate, the label of the detected object, and the detection’s confidence score.
To visualize the detection, we copy the original image and use ImageDraw to draw the bounding box and label the image. The bounding box coordinates (xmin, ymin, xmax, ymax) are extracted from prediction and used to draw a rectangle. We also add the label and the confidence score as text on the image.
temporary_image = original_image.copy()
draw = ImageDraw.Draw(temporary_image)
box = prediction["box"]
label = prediction["label"]
score = prediction["score"]
xmin, ymin, xmax, ymax = box.values()
draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
draw.text((xmin, ymin), f"{label}: {round(score, 2)}", fill="white")
temporary_image
We then crop the image to isolate the detected license plate. This cropped image will be used as input for the OCR task.
cropped_image = original_image.crop(list(box.values())) cropped_image
OCR
We import additional libraries for the OCR task. PaddleOCR is used to perform OCR on the cropped license plate image, and cv2 and numpy are used for image processing.
from paddleocr import PaddleOCR, draw_ocr import cv2 import numpy
We initialize the OCR model from PaddleOCR. The use_angle_cls parameter is set to True to enable text angle classification, and the language is set to English (lang="en").
ocr = PaddleOCR(use_angle_cls=True, lang="en")
We convert the cropped image to a numpy array, which is required for PaddleOCR. We also convert the image from RGB to BGR format as PaddleOCR expects images in BGR format.
cropped_numpy_image = numpy.array(cropped_image) cropped_numpy_image_rgb = cropped_numpy_image[:, :, ::-1].copy()
We perform OCR on the cropped image to extract the text from the license plate. The ocr method returns a list of results, where each result contains the detected text and other details. We print the extracted license plate number.
result = ocr.ocr(cropped_numpy_image_rgb, cls=True)
print(f"License Plate Number: {result[0][0][1][0]}")
Gradio
We install Gradio to create an interactive web interface for our object detection and OCR pipeline. This allows us to create a web application where users can upload images and see the results. The complete code for creating a deployable application for the zero-shot license plate reader is posted inside PyImageSearch University.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
By combining OWL-ViT for license plate localization and PaddleOCR for text extraction, we can build a robust and flexible ANPR or license plate recognition system. Deploying this system with Gradio allows for easy interaction and customization, making it suitable for a wide range of applications. This approach leverages state-of-the-art models and user-friendly tools to deliver an effective solution for real-world use cases.
There are some immediate real-world applications of combining OWL-ViT and PaddleOCR.
- Real-Time License Plate Recognition
- Application: Automated toll collection, traffic monitoring.
- Workflow: OWL-ViT localizes license plates; PaddleOCR extracts text.
- Benefits: High accuracy and real-time processing on ANPR with Python.
- Document Digitization
- Application: Digital archiving, automated form processing.
- Workflow: OWL-ViT segments document sections; PaddleOCR extracts text.
- Benefits: Scalability and versatility for various document types.
- Retail and Inventory Management
- Application: Automated checkout inventory tracking.
- Workflow: OWL-ViT detects product labels; PaddleOCR reads text using Python.
- Benefits: Improved efficiency and inventory accuracy.
- Assistive Technologies
- Application: Tools for visually impaired, real-time translation.
- Workflow: OWL-ViT detects text regions; PaddleOCR reads or translates text.
- Benefits: Enhanced accessibility and real-time interaction.
Citation Information
A. R. Gosthipaty and R. Raha. “Automatic License Plate Reader Using OCR in Python,” PyImageSearch, P. Chugh, S. Huot, and K. Kidriavsteva, eds., 2024, https://pyimg.co/a5fgs
@incollection{ARG-RR_2024_ALPR-OCR-Python,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Automatic License Plate Reader Using OCR in Python},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva},
year = {2024},
url = {https://pyimg.co/a5fgs},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.