
Table of Contents
Learning JAX in 2023: Part 2 — JAX’s Power Tools grad, jit, vmap, and pmap
In this tutorial, you will learn the power tools of JAX, grad, jit, vmap, and pmap.

This lesson is the 2nd in a 3-part series on Learning JAX in 2023:
- Learning JAX in 2023: Part 1 — The Ultimate Guide to Accelerating Numerical Computation and Machine Learning
- Learning JAX in 2023: Part 2 — JAX’s Power Tools
grad,jit,vmap, andpmap(today’s tutorial) - Learning JAX in 2023: Part 3 — A Step-by-Step Guide to Training Your First Machine Learning Model with JAX
To learn how to use JAX’s power tools, just keep reading.
Learning JAX in 2023: Part 2 — JAX’s Power Tools grad, jit, vmap, and pmap
🙌🏻 Introduction
Welcome to our comprehensive guide on advanced JAX techniques! In the previous tutorial, we were introduced to JAX, and its predecessors autograd and xla. We also briefly looked into numerical computing with JAX.
In this post, we’ll be diving into some of the most powerful and useful features of the JAX library, including grad, jit, vmap, and pmap. These functions allow you to easily and efficiently compute gradients of functions, optimize your code for faster execution, and apply functions to arrays of data in parallel. By the end of this post, you’ll have a solid understanding of how to use these tools to improve the performance and functionality of your numerical computation and machine learning tasks.
We’ll also cover the topic of randomness in JAX, including how to generate and control random numbers for use in your computations. Randomness is an important aspect of many machine learning algorithms, and JAX provides a range of functions and techniques for working with randomness in a controlled and reproducible manner.
Whether you’re a seasoned JAX user or just getting started with the library, we hope you’ll find this post a valuable resource for improving your skills and taking your projects to the next level. So let’s get started!
Configuring Your Development Environment
To follow this guide, you need to have the JAX library installed on your system. JAX is written in pure Python, but it depends on XLA, which needs to be installed as the jaxlib package.
Luckily, jaxlib and jax are pip-installable:
$ pip install jaxlib $ pip install numpy $ pip install autograd $ pip install jax
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
👨🏫 Important Functional Transformations
JAX provides some amazing functional transformation APIs to help you write more efficient and performant code.
Let’s dive into each of these functional transformation APIs in more detail:
grad: allows you to compute gradients of any function with respect to its inputs, which is an essential step in many machine learning algorithms.jit: helps JAX optimize and compile your Python code, significantly boosting performance.vmap: allows you to vectorize your code, meaning that you can apply a function to multiple inputs simultaneously without having to write a loop.pmap: allows you to parallelize your code across multiple devices, making it run much faster.
With these APIs, we can write code that is more readable, faster, and more efficient, and they can be used in a wide variety of machine learning and scientific computing applications.
But what do we mean by functional transformations?
A functional transformation takes a function and transforms it into another.
Pure Functions
Before continuing, we want to take a break and discuss a topic important to understand when using JAX, built around the idea of pure functions. This programming concept is slightly different from what you might be used to, but it’s important to know the basics.
Even though we don’t go too deep into functional programming, we will be sure to explain the basics and what you should and shouldn’t do when using JAX. So keep reading, we will guide you through it!
JAX transformation and compilation are designed to work only on Python functions that are functionally pure: all the input data is passed through the function parameters, all the results are output through the function results. A pure function will always return the same result if invoked with the same inputs.
—The Sharp Bits 🔪 — JAX documentation
If a function ticks the following conditions, it is said to be pure:
- All the inputs get in from the parameters.
- All the outputs are returned from the function.
- Upon sending the same inputs, the results should always be the same.
This means that pure functions do not like stateful elements. What is a state, and what is with these stateful and stateless elements?
In Python, a stateful element refers to an object or data structure with an internal state that can change over time. This means that the object’s behavior or output can be affected by the values it has previously stored or processed.
An example will make the concept easier to understand.
class StateFul:
def __init__(self):
self.state = 0
def change_state(self):
self.state = self.state + 1
output = self.state ** 2
return output
stateful = StateFul()
print(f"Initial state => {stateful.state}")
output = stateful.change_state()
print(f"Output => {output}")
print(f"Changed state => {stateful.state}")
>>> Initial state => 0 >>> Output => 1 >>> Changed state => 1
The code snippet defines a StateFul class. It has a single instance variable state initialized to 0 and a method change_state that increments the state by 1. The method returns the square of the new state.
This type of code should look familiar. This follows the Object-Oriented Programming (OOP) paradigm. TensorFlow and PyTorch support the OOP paradigm and love stateful elements. Here the stateful object has a state which can be changed with the change_state method.
Let’s now rewrite the code snippet using the functional programming paradigm.
class StateLess:
def change_state(self, state):
changed_state = state + 1
output = changed_state ** 2
return output, changed_state
stateless = StateLess()
initial_state = 0
print(f"Initial state => {initial_state}")
output, changed_state = stateless.change_state(state=initial_state)
print(f"Output => {output}")
print(f"Changed state => {changed_state}")
>>> Initial state => 0 >>> Output => 1 >>> Changed state => 1
The code defines a StateLess class. It has a method change_state, which takes an input state, increments it, and returns the new state and output as a tuple. The class does not maintain any state internally.
The main difference between StateFul and StateLess is how they handle the concept of state. The StateFul class has an internal state that is modified by the change_state method, while the StateLess class does not have any internal state, and the change_state method takes an input state and generates the new state based on that.
A general strategy to change a StateFul class into a StateLess one is shown in Figures 1 and 2.


With our stateful and stateless class implementation, it might seem that JAX does not like states, which is misleading. JAX has no problem with states. It has a problem with in-place state updation. In the code snippet below, we show how JAX does away with in-place state updation.
class PureState(NamedTuple):
state: Any
def update_state(self, new_state):
return PureState(new_state)
p1 = PureState(1)
p2 = p1.update_state(2)
print(p1) # un-modified
print(p2) # new object
This code defines a NamedTuple class called PureState with one field called state. A namedtuple is a subclass of a tuple that allows you to access its elements by name and index.
The class also defines a method called update_state that returns a new instance of PureState with a different value for the state field.
We create an object of PureState with the value 1 for the state field and assign it to the variable p1. Then we call the update_state method on p1 with the value 2 and assign it to variable p2. The code finally prints both p1 and p2. The output is:
>>> PureState(state=1) >>> PureState(state=2)
This shows that the method call does not modify p1, but a new object is created and returned instead. This example emulates how JAX deals with states and state updations.
jaxpr
Every transformation we cover happens because JAX converts every function into an intermediate language. This intermediate language is called jaxpr. We can inspect each function’s jaxpr using the jax.make_jaxpr method. Understanding jaxpr will give us a deeper understanding of the framework. However, it is not a prerequisite for understanding functional transformations.
Click here to skip directly to functional transformations in JAX
A JAX transformation transforms a Python function into a small and well-behaved intermediate form that is then interpreted with transformation-specific interpretation rules. The Python interpreter distills the essence of a Python function into a statically-typed expression language known as the jaxpr language.
—Understanding Jaxprs — JAX documentation
JAX builds the jaxpr of a function using a process called tracing.
When tracing, JAX wraps each argument with a tracer object. These tracers then record all JAX operations performed on them during the function call (which happens in regular Python). Then, JAX uses the tracer records to reconstruct the entire function. The output of that reconstruction is the jaxpr.
—Understanding Jaxprs — JAX documentation
To understand how the jaxpr language works, it’s important to know its grammar. Understanding the grammar will help you understand what’s happening behind the scenes. Figure 3 explains jaxpr and its components.

To drive things home, let’s look at a function f and its jaxpr consecutively. Figure 4 shows the jaxpr and its various components.
def f(arg1, arg2, arg3):
temp = arg1 + arg2
temp = temp * arg3
return temp / 3.0
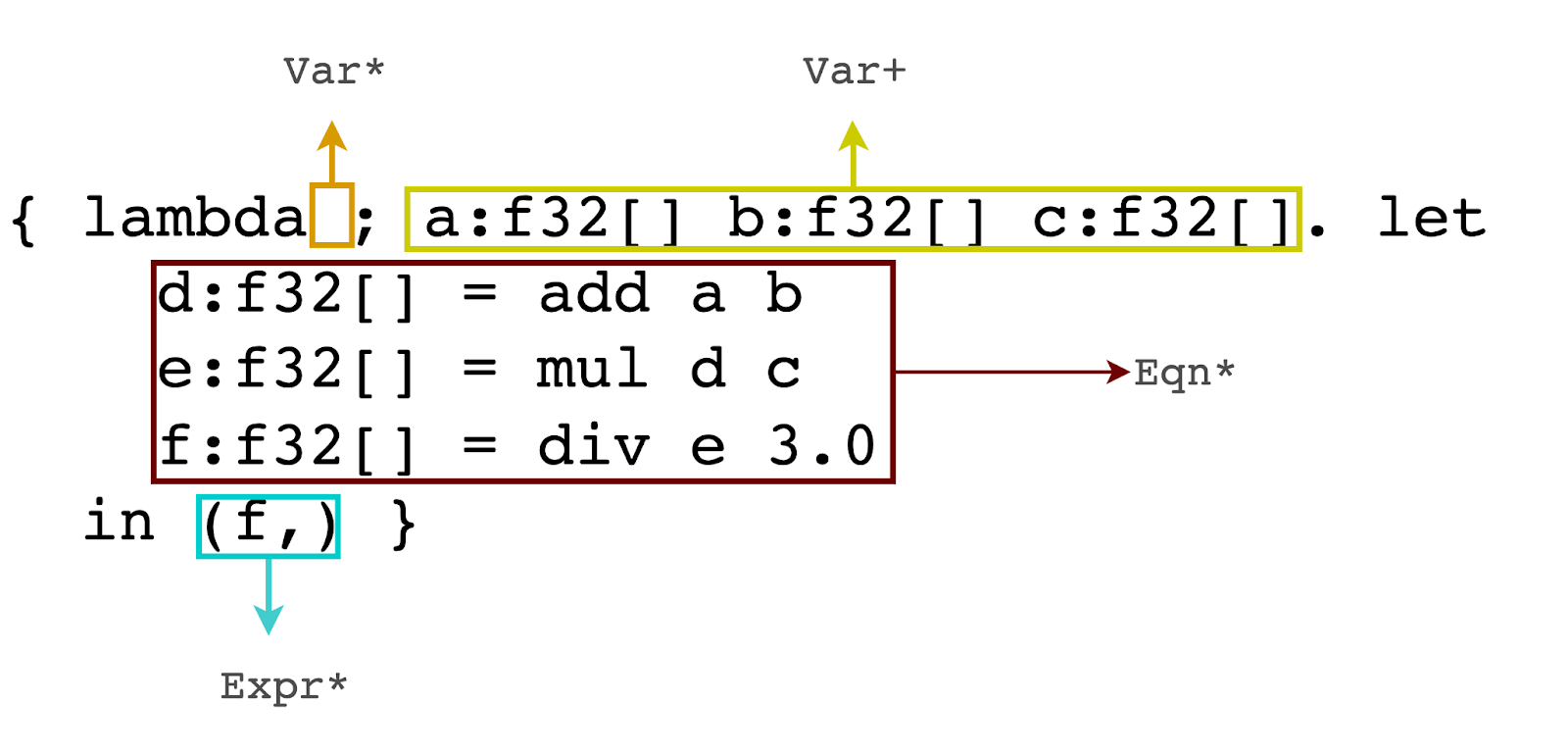
f defined (source: image by the authors).The code defines a function named f, which takes three arguments, arg1, arg2, and arg3. The input arguments are documented in the Var+ list of the jaxpr.
Inside the function, a variable named temp is first assigned the value of the sum of arg1 and arg2. Then, temp is reassigned the value of itself multiplied by arg3. Finally, the function returns the value of temp divided by 3.0. The entire operation is broken down into chunks and displayed in the list of Eqn* of the jaxpr.
The output is captured in the Expr* list of the jaxpr.
Note: The Var* is empty, shown with a box with no elements in Figure 4.
jax.grad
Now that we have a fair amount of understanding about pure functions and transformations, we are ready to talk about the first (and possibly the most used) jax transformation, jax.grad.
With the jax.grad transformation, we can easily compute gradients of functions with respect to their inputs. The autodiff engine in JAX is very similar to that of autograd.
We will start with a function  and then derive its gradient
and then derive its gradient  using the
using the jax.grad transformation.
 = 4x^{3} + 3x^{2} + 2x + 1")
 = 12x^{2} + 6x + 2")
First, we define the function ") and look at its jaxpr representation.
and look at its jaxpr representation.
def f(x):
return 4*x**3 + 3*x**2 + 2*x + 1
make_jaxpr(f)(2.0)
>>> { lambda ; a:f32[]. let
>>> b:f32[] = integer_pow[y=3] a
>>> c:f32[] = mul 4.0 b
>>> d:f32[] = integer_pow[y=2] a
>>> e:f32[] = mul 3.0 d
>>> f:f32[] = add c e
>>> g:f32[] = mul 2.0 a
>>> h:f32[] = add f g
>>> i:f32[] = add h 1.0
>>> in (i,) }
Figure 5 shows a visual map of how the jaxpr looks.
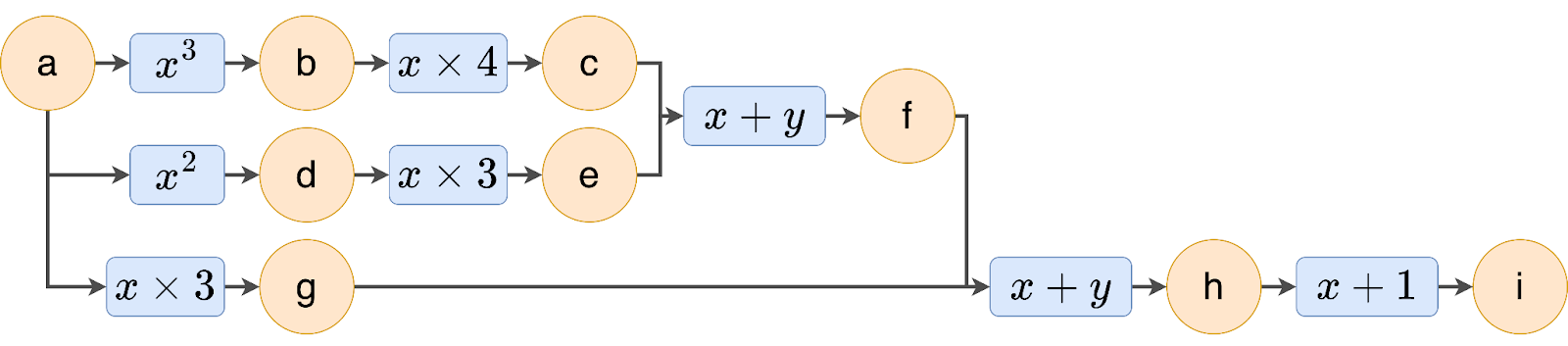
f (source: image by the authors).Let us now see how the derivative of the same function would look. To compute the derivative, we simply call jax.grad(f), where f is the said function. This produces another function instead of a value. Let us now look at the jaxpr of the derivative.
f_bar = grad(f) make_jaxpr(f_bar)(2.0)
>>> { lambda ; a:f32[]. let
>>> b:f32[] = integer_pow[y=3] a
>>> c:f32[] = integer_pow[y=2] a
>>> d:f32[] = mul 3.0 c
>>> e:f32[] = mul 4.0 b
>>> f:f32[] = integer_pow[y=2] a
>>> g:f32[] = integer_pow[y=1] a
>>> h:f32[] = mul 2.0 g
>>> i:f32[] = mul 3.0 f
>>> j:f32[] = add e i
>>> k:f32[] = mul 2.0 a
>>> l:f32[] = add j k
>>> _:f32[] = add l 1.0
>>> m:f32[] = mul 2.0 1.0
>>> n:f32[] = mul 3.0 1.0
>>> o:f32[] = mul n h
>>> p:f32[] = add_any m o
>>> q:f32[] = mul 4.0 1.0
>>> r:f32[] = mul q d
>>> s:f32[] = add_any p r
>>> in (s,) }
Let’s also visualize the jaxpr more intuitively. Figure 6 shows the computation graph for the gradient function.

f (source: image by the authors).Passing a value through the f_bar function would give us the derivative at that point. We will pass x=2.0 to compute the function’s gradient at point 2.0.
f_bar(2.0)
>>> DeviceArray(62., dtype=float32, weak_type=True)
An important point to note here is that with TensorFlow and PyTorch, we had a node (mostly the loss) that was used to build the derivatives. In JAX, it is more intuitive, where a function’s derivative is another function.
Another caveat of using JAX’s jax.grad is that it can be infinitely composable. What if you need the second derivative of the function ?
 = 24x + 6")
f_double_bar = grad(f_bar) f_double_bar(2.0)
>>> DeviceArray(54., dtype=float32, weak_type=True)
The third derivative? Sure!
f_triple_bar = grad(f_double_bar) f_triple_bar(2.0)
>>> DeviceArray(24., dtype=float32, weak_type=True)
grad is an integral part of JAX’s skeleton as it is built on autograd and xla. The advantage of JAX’s grad is that it allows more flexibility and ease of use by making the derivative of a function another function. This is in line with how we think about derivatives mathematically and thus allows us to build more complicated architectures easily.
jax.jit
jax.jit is a Jax function that improves performance by compressing, caching, and optimizing the function’s mathematical operations. When you use jax.jit to transform a function, it takes the equations laid out in the function’s jaxpr and optimizes them by removing unnecessary intermediate values and caching others. This makes the function run faster and more efficiently.
The steps that take place when you wrap a function with jax.jit:
- Define a function
 .
. - Transform the function with
jax.jit. - Run the function once (warmup step), which helps trace the function. The traced jaxpr is now compiled with the XLA compiler.
- Run the compiled version of the function.
Let’s benchmark a simple matrix multiplication operation using the jit compilation technique. We define a function called matrix_mul that takes two inputs, a and b. These inputs are matrices. The function uses a Jax function called matmul to multiply the two matrices together and returns the result.
We also generate two matrices of random numbers called a and b using Jax’s random function with a specific seed key and given shapes. Random number generation will be discussed in a later section. We call the matrix_mul function with the previously generated matrices as inputs and return the jaxpr representation of the matrix multiplication.
def matrix_mul(a, b):
return jnp.matmul(a, b)
key = jax.random.PRNGKey(42)
a = jax.random.normal(key, shape=(1000, 5000))
b = jax.random.normal(key, shape=(5000, 1000))
make_jaxpr(matrix_mul)(a, b)
>>> { lambda ; a:f32[1000,5000] b:f32[5000,1000]. let
>>> c:f32[1000,1000] = dot_general[
>>> dimension_numbers=(((1,), (0,)), ((), ()))
>>> precision=None
>>> preferred_element_type=None
>>> ] a b
>>> in (c,) }
We call the matrix multiplication here! Notice the function block_until_ready(). It is helpful to ensure that a specific computation is completed before moving on to the next step in your code, without any race conditions.
# Normal computation %timeit -n5 matrix_mul(a, b).block_until_ready()
>>> 3.9 ms ± 26.7 µs per loop (mean ± std. dev. of 7 runs, 5 loops each)
Now for the jitted matrix multiplication function. We pass the original matrix_mul function through jax.jit to get an optimized version of the function. Now we observe the jaxpr representation of the jitted function.
jit_matrix_mul = jit(matrix_mul) make_jaxpr(jit_matrix_mul)(a, b)
>>> { lambda ; a:f32[1000,5000] b:f32[5000,1000]. let
>>> c:f32[1000,1000] = xla_call[
>>> call_jaxpr={ lambda ; d:f32[1000,5000] e:f32[5000,1000]. let
>>> f:f32[1000,1000] = dot_general[
>>> dimension_numbers=(((1,), (0,)), ((), ()))
>>> precision=None
>>> preferred_element_type=None
>>> ] d e
>>> in (f,) }
>>> name=matrix_mul
>>> ] a b
>>> in (c,) }
The important thing to note here is the xla_call inside the jaxpr. This means that the jit compiled function is indeed compiled with the help of the XLA compiler.
Let’s call the compiled function and see the time improvements.
# warmup warmup_results = jit_matrix_mul(a, b) # ⚡️ speed em up! %timeit -n5 jit_matrix_mul(a, b).block_until_ready()
>>> 2.83 ms ± 167 µs per loop (mean ± std. dev. of 7 runs, 5 loops each)
This is great! Why not just use jax.jit with every function that we write?
Unfortunately, we cannot. To understand why we cannot, let’s consider the following code snippet.
@jit
def f(x):
if x > 0:
return x+1
else:
return x
This code defines a function f(x) that takes in a single argument x. The function checks if x is greater than 0. If it is, the function returns x+1. If x is not greater than 0, the function returns x.
Note: We also jit compile the function f(x) using the decorator @jit operator.
Let’s now call the compiled function with 10 as its input.
try:
f(10)
except Exception as ex:
print(f"Type of exception => {type(ex).__name__}")
print(f"Exception => {ex}")
>>> Type of exception => ConcretizationTypeError >>> Exception => Abstract tracer value encountered where concrete value is expected: Traced<ShapedArray(bool[], weak_type=True)>with<DynamicJaxprTrace(level=0/1)> >>> The problem arose with the `bool` function. >>> The error occurred while tracing the function f at <ipython-input-42-a19f4335b9ae>:1 for jit. This concrete value was not available in Python because it depends on the value of the argument 'x'. >>> See https://jax.readthedocs.io/en/latest/errors.html#jax.errors.ConcretizationTypeError
The problem arises because of tracing. The jaxpr representation needs a value to trace the python control flow (here, the if statement). If we are too specific with the values of elements, we might not be able to use them for other values.
JAX bypasses this constraint by introducing different levels of abstractions that can be used to trace the python function. For jax.jit, the level is ShapedArray. This tracer object does not have a value but does have a shape. If we condition this tracer object with no (concrete) value, the tracing operation fails with ConcretizationTypeError.
What is PyImageSearch if we cannot solve the problem shown above? Here is a code snippet that would handle the jitting of the function with conditions.
@jit
def f(x):
return jnp.where(x > 0, x + 1, x)
The rule of thumb about jitting a function is to use a pure function with no side effects and know when and what to trace.
JAX VMAP
You can vectorize functions using JAX VMAP as part of JAX. This allows you to vectorize functions over multiple axes with minimal code changes.
It takes a function, an in_axes parameter that specifies which input axes to map over, and an out_axes parameter that specifies where the mapped axis should appear in the output. JAX VMAP then returns a new function that applies the original function to each slice of the input along the mapped axes, and stacks the results along the output axis.
JAX VMAP can help you write concise and efficient code for machine learning research, especially when working with accelerators like GPUs and TPUs.
Overall, jax vmap is a powerful tool that can be used to improve the performance of functions that are applied to multiple inputs. However, it is important to be aware of the limitations of jax vmap before using it.
JAX VMAP FAQ
jax vmap is a function that can be used to vectorize a function across a given axis. This means that the function can be applied to multiple inputs at the same time, which can significantly improve performance.
The syntax for jax vmap is as follows:
jax.vmap(func, in_axes=None)
The func argument is the function that you want to vectorize. The in_axes argument is a list of axes that you want to vectorize over. If in_axes is None, then all axes will be vectorized.
Here are some examples of how to use jax vmap:
def f(x): return x * x # Vectorize f over the first axis. g = jax.vmap(f, in_axes=(0,)) # Apply g to a batch of inputs. y = g(jnp.array([1, 2, 3])) # y will be equal to [1, 4, 9]. def conv(x, w): return jnp.convolve(x, w, mode=”valid”) # Vectorize conv over the first axis of x and the second axis of w. h = jax.vmap(conv, in_axes=(0, 1)) # Apply h to a batch of inputs. z = h(jnp.array([1, 2, 3]), jnp.array([1, 2])) # z will be equal to [2, 4].
There are several benefits to using jax vmap, including:
Improved performance: jax vmap can significantly improve the performance of functions that are applied to multiple inputs.
Reduced memory usage: jax vmap can reduce the memory usage of functions that are applied to multiple inputs.
Increased portability: jax vmap can make functions more portable, as they can be applied to inputs of different sizes.
There are a few limitations to using jax vmap, including:
Not all functions can be vectorized: some functions cannot be vectorized, as they depend on the order of the inputs.
Can be difficult to debug: jax vmap can make it more difficult to debug functions, as the output of the function may be different when it is vectorized.
Can be inefficient for small inputs: jax vmap may not be efficient for small inputs, as the overhead of vectorization may outweigh the benefits.
jax.vmap
When working on a codebase, it is important to consider the scalability and flexibility of the code. Let’s say you are working on a codebase designed to work with 1D arrays, but you realize that it would be beneficial to make the code compatible with batches of data. This is a common problem that many developers face when working with large datasets.
You, determined to make the necessary changes, refactor the entire codebase to include batching. However, after a few hours of work and encountering multiple errors, you realize that the task may be more difficult than you initially anticipated.
This is where the concept of jax.vmap comes into play. jax.vmap is a function provided by the Jax library that allows you to apply a function to a batch of inputs in a vectorized manner, which can greatly simplify the process of working with batches of data. With jax.vmap, you can apply a function to a batch of inputs with a single call rather than iterating over each input individually.
Let’s understand this with the following example.
a = jnp.array([1.0, 4.0, 0.5])
b = jnp.arange(5, 10, dtype=jnp.float32)
def weighted_mean(a, b):
output = []
for idx in range(1, b.shape[0]-1):
output.append(jnp.mean(a + b[idx-1 : idx+2]))
return jnp.array(output)
print(f"a => {a.shape}")
print(f"b => {b.shape}")
output = weighted_mean(a, b)
print(f"output => {output.shape}")
The weighted_mean(a, b) function takes in two arguments, a and b, and creates an empty list called output. Then we iterate over the indices of the b array, starting from the 1st index to the second-last index.
For each index, it calculates the mean of the subarray a + b[idx-1 : idx+2]. The mean of the resulting array is then appended to the output list. Finally, the function returns the output list converted to a JAX array.
>>> a => (3,) >>> b => (5,) >>> output => (3,)
Here, we add the batch dimension to our inputs. We transform our weighted_mean function into another function that can now handle input batches.
# Let's include the batch dim to the inputs
batch_size = 8
batched_a = jnp.stack([a] * batch_size)
batched_b = jnp.stack([b] * batch_size)
print(f"batched_a => {batched_a.shape}")
print(f"batched_b => {batched_b.shape}")
>>> batched_a => (8, 3) >>> batched_b => (8, 5)
batched_weighted_mean = vmap(weighted_mean)
batched_output = batched_weighted_mean(batched_a, batched_b)
print(f"batched output => {batched_output.shape}")
>>> batched output => (8, 3)
With the jax.vmap transformation, the function that once worked on 1D arrays can now work with 2D arrays with a batch dimension.
JAX PMAP
JAX PMAP is a feature of JAX that enables parallel computation across multiple devices, such as GPUs or TPUs.
JAX PMAP transforms a function into one that can be executed in parallel on different slices of the input data, using a single-program multiple-data (SPMD) model. JAX PMAP can be combined with other JAX transformations, such as automatic differentiation and XLA compilation, to write high-performance machine learning code in Python.
In this section, we will answer some common questions about JAX PMAP:
- How does PMAP work in JAX?
- PMAP works by applying a function to each slice of the input data along a specified axis, and then stacking the results along the same axis. The input data must be sharded across the devices, meaning that each device holds a different piece of the data. The function can also use collective operations, such as all-reduce or all-gather, to communicate between devices using a named axis.
- How is PMAP different from VMAP?
- VMAP is another JAX feature that vectorizes a function over an axis of the input data, but it does not parallelize the computation across devices. VMAP pushes the mapped axis down into primitive operations, while PMAP replicates the function and executes each replica on its own device. VMAP can handle arbitrary nested axes, while PMAP currently only supports one mapped axis at a time.
- What does JAX stand for Python?
- JAX stands for “Just-in-time compilation for Accelerated numerical eXpressions.” JAX is a Python library that extends NumPy with automatic differentiation and XLA compilation, allowing users to write fast and flexible numerical code in Python.
- What is JAX used for?
- JAX is mainly used for machine learning research, especially for developing new models and algorithms that require custom gradients, vectorization, or parallelization. JAX can also be used for general scientific computing, such as solving differential equations, optimizing functions, or simulating physical systems.
References:
- https://jax.readthedocs.io/en/latest/_autosummary/jax.pmap.html
- https://www.tensorflow.org/probability/examples/Distributed_Inference_with_JAX
jax.pmap
When working with large datasets on multiple devices, it is important to parallelize the data to make the most of the available resources.
The pmap transformation in JAX is a powerful tool that allows us to harness the parallelization capabilities of the library. With pmap, we can apply a function to a batch of inputs in a parallelized manner. It is worth noting that the pmap transformation can be used not only on TPUs but also on other parallel devices like multiple GPUs.
For example, we will run our code on a TPU. We can use the pmap transformation to parallelize our computations across the multiple cores of the TPU.
import jax.tools.colab_tpu jax.tools.colab_tpu.setup_tpu() import jax jax.devices()
>>> [TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0), >>> TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1), >>> TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0), >>> TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1), >>> TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0), >>> TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1), >>> TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0), >>> TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)]
from jax import numpy as jnp from jax import pmap from jax import random key = random.PRNGKey(42) a = random.normal(key, shape=(3000,5000)) b = random.normal(key, shape=(5000,3000)) matrix_mul = lambda a, b: jnp.matmul(a, b) matrix_mul(a, b).shape
>>> (3000, 3000)
Now let us run the same code with the pmap transformed matrix_mul function.
n_devices = jax.local_device_count() a = random.normal(key, shape=(n_devices, 3000, 5000)) b = random.normal(key, shape=(n_devices, 5000, 3000)) parallel_matrix_mul = pmap(matrix_mul) parallel_matrix_mul(a, b).shape
>>> (8, 3000, 3000)
We can see the altered shape of the result, which refers to the number of devices used for parallelization.
And that brings us to the end of the section on functional transformations in JAX. We looked at some boilerplate code on how to get started with grad, which is a version of autograd native to JAX. We also understood the do’s and don’ts of applying jit on a function. Finally, we looked at how vmap and pmap allows us to optimize code for batches and multiple devices. In the next section, we learn about randomness in JAX.
🎱 How Does JAX Handle Randomness?
Random numbers are an important tool for many machine learning and deep learning applications. They are used at various pipeline stages for initializing model parameters and augmenting data. The process of generating random numbers algorithmically is called pseudo-random number generation (PRNG). It’s important to note that these generated numbers are not truly random but rather mimic data properties when sampled from a random distribution.
The design of the jax.numpy library, which provides support for numerical computation in JAX, is largely based on the structure of the popular NumPy library. However, there is one key area where jax.numpy intentionally diverges from NumPy: random number generation. In other words, JAX handles random numbers differently than NumPy.
Before diving into how JAX generates and serves random numbers, let’s review how NumPy does it. NumPy provides several functions for generating random numbers from various probability distributions (e.g., the uniform, normal, and exponential distributions). These functions are located in the numpy.random module, and they use the Mersenne Twister PRNG algorithm to generate their sequences of random numbers. The Mersenne Twister is a widely used PRNG algorithm that is known for its good statistical properties and long periods. Yet, it can be slow for very large arrays and unsuitable for parallel computations.
Now that we have a basic understanding of PRNG and how NumPy generates random numbers, we can explore how JAX handles randomness. As we’ll see, JAX provides several advanced features and tools for working with randomness that go beyond what is available in NumPy.
import numpy as np
# random number generation using numpy
np.random.seed(42)
rn1 = np.random.normal()
rn2 = np.random.normal()
print(f"NumPy Random Number Generation: {rn1: .2f} {rn2: .2f}")
>>> NumPy Random Number Generation: 0.50 -0.14
Note: Although the seed is set once, the two generated numbers are different.
This means that numpy sets a global seed, and the state can be modified every time np.random.normal() is called.
The developers of JAX found this undesirable. This is because JAX requires the code to be:
- reproducible
- parallelizable
- vectorizable
To accommodate this, JAX does not use a global state. Random functions in JAX, therefore, consume the global state directly through something called a key (a fancy way of saying seed). Let us see how this works:
from jax import random
key = random.PRNGKey(65)
print(key)
jrn1 = random.normal(key)
jrn2 = random.normal(key)
print(f"JAX Random Number Generation: {jrn1: .2f} {jrn2: .2f}")
>>> [ 0 65] >>> JAX Random Number Generation: 0.05 0.05
As you can see, they are exactly the same! This means we can pass the exact same key everywhere and get the same random number as and when desired. Well, not so fast.
Feeding the same key to different random generators can result in a correlation in output. We do not want that in a Deep Learning architecture.
The trick is to split the key into as many subkeys as you need and then use the subkey. Let us see how this works.
print("JAX original key", key)
mod_key, subkey = random.split(key)
print("JAX modified key", mod_key)
print("JAX sub key", subkey)
>>> JAX original key [ 0 65] >>> JAX modified key [2260844589 1152238433] >>> JAX sub key [2316561322 4079994326]
Note: We always use either the new modified key or the new subkey when needed in later parts and never the old key.
Summary
In this blog post, we provided an in-depth guide to some of the most powerful and useful features of the JAX library (i.e., grad, jit, vmap, and pmap) and also how to work with random numbers in JAX.
Overall, these tools can greatly improve the performance and functionality of your numerical computation and machine learning tasks. By mastering these functions and understanding how to generate random numbers in JAX, we’ll be well-equipped to tackle a wide range of challenging problems.
Now that we have a solid foundation in these advanced JAX techniques, we’re ready to put our skills to the test by training a machine learning model from scratch using JAX. In the next part of this series, we’ll guide you through the process of training a simple neural network with JAX, including how to define the model, load and preprocess data, and optimize the model using gradient descent.
We’ll also cover more advanced techniques for training neural networks with PyTrees. By the end of this series, you’ll have a strong understanding of how to use JAX. So stay tuned, and get ready to dive into the exciting world of machine learning with JAX!
Credits
We acknowledge the detailed review and discussion from Jake Vanderplas.
Citation Information
A. R. Gosthipaty and R. Raha. “Learning JAX in 2023: Part 2 — JAX’s Power Tools grad, jit, vmap, and pmap,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and A. Thanki, eds., 2023, https://pyimg.co/tb9d7
@incollection{ARG-RR_2023_JAX2,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Learning {JAX} in 2023: Part 2 — {JAX}'s Power Tools grad, jit, vmap, and pmap},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/tb9d7},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.