Table of Contents
Scaling Kaggle Competitions Using XGBoost: Part 4
Over the last few blog posts of this series, we have been steadily building up toward our grand finish: deciphering the mystery behind eXtreme Gradient Boosting (XGBoost) itself. If you have stuck with us through the entire journey till now (Great work!), you already know that our approach in this series is math-heavy instead of code-heavy.

The reasoning behind that is simple; whatever we have learned till now, be it adaptive boosting, decision trees, or gradient boosting, have very distinct statistical foundations which require you to get your hands dirty with the math behind them. The goal is to nullify the abstraction created by packages as much as possible.
Our final stop of this series will have a similar outlook.
In this tutorial, you will learn the magic behind the critically acclaimed algorithm: XGBoost.
This lesson is the last of a 4-part series on Deep Learning 108:
- Scaling Kaggle Competitions Using XGBoost: Part 1
- Scaling Kaggle Competitions Using XGBoost: Part 2
- Scaling Kaggle Competitions Using XGBoost: Part 3
- Scaling Kaggle Competitions Using XGBoost: Part 4 (this tutorial)
To learn how to conquer the ingenious concept of XGBoost, just keep reading.
Scaling Kaggle Competitions Using XGBoost: Part 4
If you went through our previous blog post on Gradient Boosting, it should be fairly easy for you to grasp XGBoost, as XGBoost is heavily based on the original Gradient Boosting algorithm. We strongly recommend having a strong grip on Parts 1 and 3 of the series and an overall gist of Part 2.
What Is XGBoost?
Although we have already addressed this in the first blog post of this series, let’s go over it again.
XGBoost stands for eXtreme Gradient Boosting, an optimized solution for training in gradient boosting. As argued by many, one of the most powerful classical machine learning algorithms out there today incorporates several features, some of which are:
- Has steps to prevent overfitting (regularization)
- Can work in parallel processing
- Has in-built cross-validation and early stopping
- Results in highly optimized results (deeper trees)
Till now, we have broken down ensemble learning, adaptive boosting, and gradient boosting. But all of these algorithms, despite having a strong mathematical foundation, have some flaws or the other. For example, in the case of adaptive boosting, we see that in most cases, the trees are simple stumps (a single root node with its two children) or the fact that its idea is based on focusing on samples that are wrongly classified.
In the case of gradient boosting, we do see an approach better than the ones we have considered till now, with a solid ensemble progression as well as methods to prevent overfitting. But how to make it even better? That’s where the “Extremeness” of XGBoost comes in. Without further ado, let’s start with our journey.
Our Dummy Dataset
In practical cases, XGBoost is normally applied to huge datasets. For simplicity, we will use a small dummy dataset to understand how regression works in XGBoost (Figure 1).
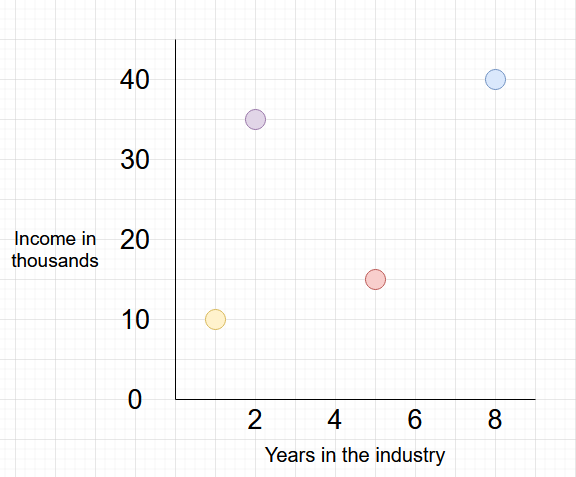
In this dataset, we have the feature as Years in the industry of individuals, with the label being their income. The general notion we will have about this dataset is that more years in the industry will grant you more income. Which means the purple point is our outlier.
Breaking Down the Math
As we had done for Gradient Boosting, let us glance over the math that is behind XGBoost (Figure 2)

Again, don’t be scared of these scary-looking equations, as they are as simple as they can be. Before we begin, just a few points. If you have never come across the term  in Step 2, those are nothing but Hessians, which we get by taking the derivative of the gradients.
in Step 2, those are nothing but Hessians, which we get by taking the derivative of the gradients.
Firstly, we have the definition of the training set, which is _{i=1}^N") refers to the training sample
refers to the training sample  , which has
, which has  features and
features and  labels.
labels.
The loss function again is defined as )") , which is nothing but the loss between labels and prediction
, which is nothing but the loss between labels and prediction ") .
.
Our first step is to create the base model, which we have assumed to be of the value 25. By default, in practice, it is always set to 0.5. However, to better understand the process, we have chosen a value of our own (Figure 3).

The next step is calculating the residuals (-15, 10, -10, 15). Up until now, you will find a lot of similarities with Gradient Boosting.
The difference starts when the first unique XGBoost tree is built. Assume our first node splits the residuals based on the feature being greater than/not greater than 1.5 “Years in the industry” (Figure 4).
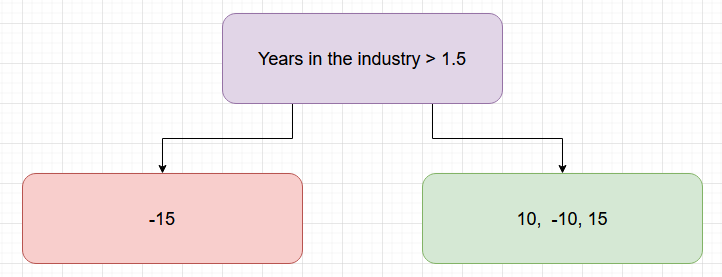
Note that trees are normally deeper and more complex, but we have taken this example for easier understanding. Before we progress further, let’s calculate something called the similarity score: ^2/(\text{number of residuals} + \lambda)") . Here,
. Here,  is the regularizer.
is the regularizer.
But before that, let us understand how we got there. In Step 2 of Figure 2, we see a calculation of gradients and Hessians. As mentioned in the earlier blog, the loss function normally used here is  (y_i - p_i)^2") . Taking the first-order derivative (gradient) gives us nothing but
. Taking the first-order derivative (gradient) gives us nothing but ") , which is the residual.
, which is the residual.
The Hessian is the second-order derivative, giving us the value 1 here. That makes the Output of a node which is represented by /(\text{sum of Hessians} + \lambda)") as
as ") (such insane simplification, right?).
(such insane simplification, right?).
In the second part of Step 2, a few equations need to be followed for the tree to be created. Here,  value is the Output value without the . Solving for the optimization problem gives us nothing but .
value is the Output value without the . Solving for the optimization problem gives us nothing but .
Let us assume that is 0, so the score for the root node (purple) becomes 0.
The score for the red node becomes 225.
The score for the green node becomes 75.
Next, we calculate something known as the  value for this tree, which is
value for this tree, which is  , which for this tree becomes
, which for this tree becomes 300.
Let’s try another tree now, where the root node has a different split condition (Figure 5)
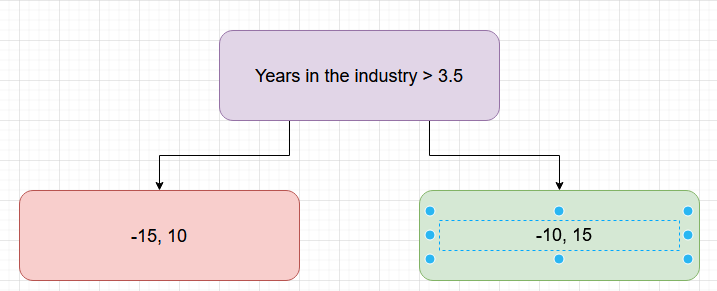
Now, the score for the red node becomes 12.5.
The score for the green node becomes 12.5 again. This brings the for the tree as 24.
This way, we can actually estimate which tree has a better gain and hence will function better, and this way, we can estimate which tree branch to consider for our final structure. But the green branch node in Figure 4 can be split further. Let’s repeat the process for it! (Figure 6).
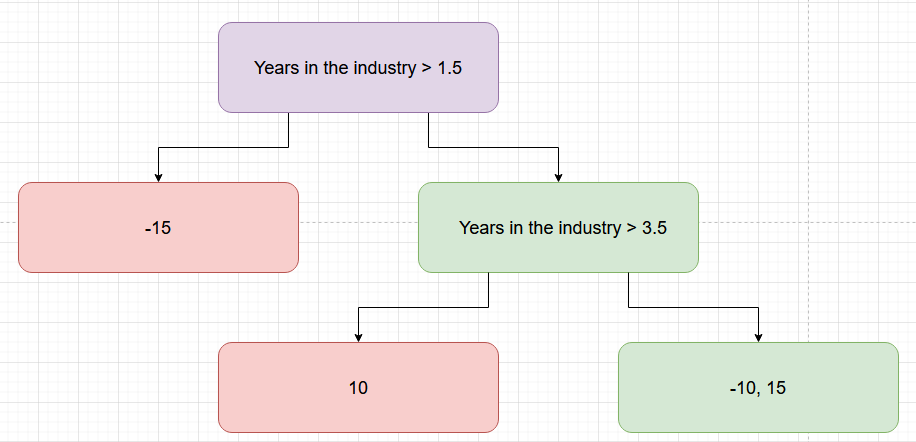
For this particular split condition, the of the right subtree becomes  , which comes to
, which comes to 37.5.
Let’s try another split condition (Figure 7).
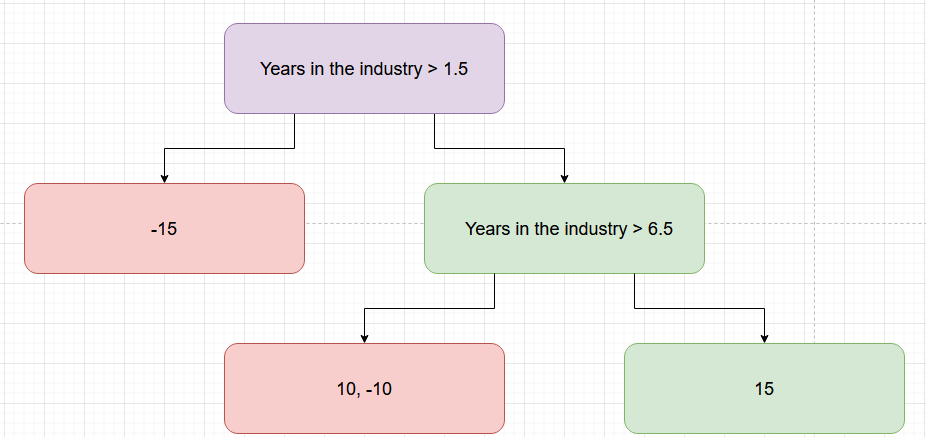
For this particular split condition, the of the right subtree becomes  , which equals
, which equals 150. This better enables us to go for this split condition instead.
But we are getting quite ahead of ourselves. We have the first tree, we have mapped the labels according to the split conditions, and in some nodes, we have reached singular values!
Unfortunately, we are missing a key concept. If you have followed the previous tutorial, recap that we didn’t want a single tree to overfit on our data points. Here, to calculate the output, we simply use the formula ") , which we have spoken about earlier.
, which we have spoken about earlier.
For our dummy scenario, the value is set to 0. So for “Years in the industry,” equals 1 would give us the output value of  , equaling
, equaling  . But this just means that the tree is severely overfitting on single data points.
. But this just means that the tree is severely overfitting on single data points.
This is where comes in. If we set any value for , the Similarity scores also fall (due to ) being in the denominator, and the output value is also less. For the example above, the output value becomes  .
.
Couple this with a suitable value for the learning_rate (0.3), and we get, for “Years in the industry” equals to 1, ") , which is
, which is 22.75. This is an improvement over the baseline prediction and a bit closer to the actual label of 10! This way, the process is repeated, and we get closer and closer to our desired area of the label.
There’s another thing left to check out, which is called pruning. Pruning is taken in its literal sense of removing branches based on our requirements. So let’s jump back to when we had the initial values calculated for our tree.
The right subtree had a value of 150 (Figure 7). We compare it to a value  , and if the result is negative, we remove this subtree and move on to the root. If the root gain comparison also is negative, we remove the tree altogether.
, and if the result is negative, we remove this subtree and move on to the root. If the root gain comparison also is negative, we remove the tree altogether.
The output calculation is similar to Gradient Boosting. We use our base predictor (25 in our case) and then add the outputs we receive from each tree (coupled with the learning rate) to get our final result.
That concludes the math behind an XGBoost Regressor. There are many similarities with Gradient Boosting, but the way the trees are created is very different.
Configuring Your Development Environment
To follow this guide, you need to have the OpenCV library installed on your system.
Luckily, OpenCV is pip-installable:
$ pip install opencv-contrib-python
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes.
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Applying XGBoost on a Problem Statement
Now that we have finished deciphering XGBoost regression, let’s try it out on a problem statement! We will be using the Wine Quality dataset from Kaggle and seeing how XGBoost performs on a dataset filled with many features from which to choose!
First, let us download the dataset from Kaggle into our local Colab session.
# initialize colab file operations from google.colab import files files.upload() # make sure kaggle.json file is present !ls -lha kaggle.json # install the kaggle package !pip install -q kaggle !mkdir -p /.kaggle !cp kaggle.json ~/.kaggle/ # set permissions for the kaggle.json !chmod 600 ~/.kaggle/kaggle.json # download the required dataset from kaggle !kaggle datasets download -d yasserh/wine-quality-dataset !unzip -qq wine-quality-dataset.zip
On Line 2, we will utilize the colab file operation and upload our own unique kaggle.json file in the session (Line 3). On Line 6, we have just kept an additional sanity check for the file.
Next, we install the kaggle package and set permissions for the session to use the file (Lines 9-14). Our final step is downloading the exact dataset we require (Line 17 and 18).
# import necessary packages import numpy as np import pandas as pd import seaborn as sns import xgboost as xgb from sklearn import ensemble import matplotlib.pyplot as plt from imblearn.over_sampling import SMOTE from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split %matplotlib inline
Next, we import the necessary packages according to our needs. We have used packages like XGBoost, pandas, numpy, matplotlib, and a few packages from scikit-learn. For better plots, we have used the matplotlib magic function inline (Line 30).
Applying XGBoost to Our Dataset
Next, we will do some exploratory data analysis and prepare the data for feeding the model.
# read the csv and check for unique values in the labels
wineDf = pd.read_csv('/content/wine-quality-dataset/WineQT.csv')
wineDf["quality"].unique()
# check the label distribution
lblDist = sns.countplot(x='quality', data=wineDf)
On Lines 33 and 34, we read the csv file and then display the unique labels we are dealing with. For good measure, let’s check the distribution of labels in this particular dataset (Figure 9).
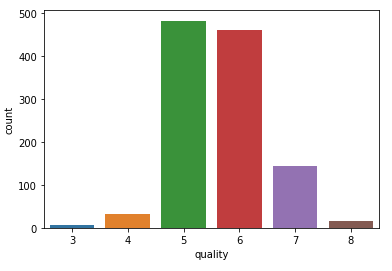
Figure 9 shows that there are very few samples with labels 3, 4, and 8. Will this be a problem for our XGBoost regressor? Let’s find out.
# prepare data for model feeding
X, y = wineDf.iloc[:, :11].values, wineDf.iloc[:, 11]
xTrain, xTest, yTrain, yTest = train_test_split(X, y, test_size=0.20)
# define the XGBoost regressor according to your specifications
xgbModel = xgb.XGBRegressor(
n_estimators=500,
gamma=0,
max_depth=5
)
Next, we split the features and the labels on Line 40 and used scikit-learn to split the dataset into training and testing sets (Line 41).
The XGBoost regressor is defined on Lines 44-48. We use 500 trees, with a value of 0 and a maximum depth of each tree of 5. You are free to use different values and check how it affects the results.
# fit the training data in the model xgbModel.fit(xTrain, yTrain) # check the score of the algorithm on test data xgbModel.score(xTest, yTest)
On Lines 51-54, we fit the training data into our regressor and then score it on the test data. Unfortunately, the test data score has come only to 41% accuracy.
This goes against all the claims and praises we have heard about XGBoost, but don’t worry. Our regressor has no fault for this poor score. The distribution of data is such that XGBoost experiences extremely low samples of certain classes, due to which it fails to learn about them properly. The low number can also sometimes make it such that the regressor will face only 2-4 samples of a particular class in the training set.
To fix this, we will introduce intentional oversampling of our data to make the labels have a similar number of samples and not pose any problems.
# prepare resampled data for model feeding X, y = SMOTE().fit_resample(X, y) xTrain, xTest, yTrain, yTest = train_test_split(X, y, test_size=0.20) # fit the training data in the model xgbModel.fit(xTrain, yTrain) # check the score of the algorithm on test data xgbModel.score(xTest, yTest)
To introduce oversampling, we will use the imblearn package. On Line 57, we prepare our dataset again for model feeding, but this time without the problem of poor distribution.
The train-test split is created again, and the training data is fed to the model (Lines 58-61). Upon scoring the predictions on the test data (Line 64), we see that we have now achieved 92% accuracy! Our task is now complete.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Our journey of uncovering XGBoost and its prerequisites finally ends here. We took on the task of deciphering why it worked so well for such huge competitions and tried to uncover the simple bits of mathematics it has. Starting with defining simple decision trees, we moved on to uncover why adaptive boosting was an important milestone in our journey. Then we touched upon Gradient Boosting Regression trees and built our foundational knowledge about their mathematics. We utilized those concepts and turned them to the Extreme level, where we finally addressed eXtreme Gradient Boosting.
The math behind these concepts was devastatingly simple, hiding behind a canopy of difficult-looking mathematical algorithms. Once we addressed them one by one, all of their facades fell like dominos. While they are extremely interesting to decipher, each concept has its own uniqueness that makes them stand apart.
We hope you have enjoyed this journey, but above all, be sure to try it out for yourself!
Citation Information
Martinez, H. “Scaling Kaggle Competitions Using XGBoost: Part 4,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2023, https://pyimg.co/onx24
@incollection{Martinez_2023_XGBoost4,
author = {Hector Martinez},
title = {Scaling {Kaggle} Competitions Using {XGBoost}: Part 4},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/onx24},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.