
In this tutorial, you will learn how to perform transfer learning for image classification using the PyTorch deep learning library.
This tutorial is part 2 in our 3-part series on intermediate PyTorch techniques for computer vision and deep learning practitioners:
- Image Data Loaders in PyTorch (last week’s tutorial)
- PyTorch: Transfer Learning and Image Classification (this tutorial)
- Introduction to Distributed Training in PyTorch (next week’s blog post)
If you are new to the PyTorch deep learning library, we suggest reading the following introductory series to help you learn the basics and become acquainted with the PyTorch library:
- PyTorch: Training your first Convolutional Neural Network (CNN)
- PyTorch image classification with pre-trained networks
- PyTorch object detection with pre-trained networks
After going through the above tutorials, you can come back here and learn about transfer learning with PyTorch.
To learn how to perform transfer learning for image classification with PyTorch, just keep reading.
PyTorch: Transfer Learning and Image Classification
In the first part of this tutorial, we’ll learn what transfer learning is, including how PyTorch allows us to perform transfer learning.
We’ll then configure our development environment and review our project directory structure.
From there, we’ll implement several Python scripts, including:
- A configuration script to store important variables
- A dataset loader helper function
- A script to build and organize our dataset on disk such that PyTorch’s
ImageFolderandDataLoaderclasses can easily be utilized - A driver script that performs basic transfer learning via feature extraction
- A second driver script that performs fine-tuning by replacing the fully connected (FC) layer head of a pre-trained network with a brand new, freshly initialized, FC head
- A final script that allows us to perform inference with our trained models
We have a lot to review here today, so let’s get started!
What is transfer learning?
Training a Convolutional Neural Network from scratch poses many challenges, most notably the amount of data to train the network and the amount of time it takes for training to take place.
Transfer learning is a technique that allows us to use a model trained for a certain task as a starting point for a machine learning model for a different task.
For example, suppose a model is trained for image classification on the ImageNet dataset. In that case, we can take this model and “re-train” it to recognize classes it was never trained to recognize in the first place!
Imagine, you know how to ride a bicycle and want to ride a motorcycle. Your experience of riding a bicycle — keeping balance, maintaining direction, turning, and braking — will help you learn to ride a motorcycle faster.
This is what transfer learning does in the case of a CNN. Using transfer learning, you can make direct use of a well-trained model by freezing the parameters, changing the output layer, and fine-tuning the weights.
In essence, you can shortcut the entire training procedure and obtain a high accuracy model in a fraction of the time.
How can we perform transfer learning with PyTorch?
There are two primary types of transfer learning:
- Transfer learning via feature extraction: We remove the FC layer head from the pre-trained network and replace it with a softmax classifier. This method is super simple as it allows us to treat the pre-trained CNN as a feature extractor and then pass those features through a Logistic Regression classifier.
- Transfer learning via fine-tuning: When applying fine-tuning, we again remove the FC layer head from the pre-trained network, but this time we construct a brand new, freshly initialized FC layer head and place it on top of the original body of the network. The weights in the body of the CNN are frozen, and then we train the new layer head (typically with a very small learning rate). We may then choose to unfreeze the body of the network and train the entire network.
The first method tends to be easier to work with, as there is less code involved and fewer parameters to tune. However, the second method tends to be more accurate, leading to models that generalize better.
Both transfer learning via feature extraction and fine-tuning can be implemented with PyTorch — I’ll show you how in the rest of this tutorial.
Configuring your development environment
To follow this guide, you need to have OpenCV, imutils, matplotlib, and tqdm installed on your machine.
Luckily, all of these are pip-installable:
$ pip install opencv-contrib-python $ pip install torch torchvision $ pip install imutils matplotlib tqdm
If you need help configuring your development environment for PyTorch, I highly recommend that you read the PyTorch documentation — PyTorch’s documentation is comprehensive and will have you up and running quickly.
And if you need help installing OpenCV, be sure to refer to my pip install OpenCV tutorial.
Having problems configuring your development environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
The Flower photos dataset
Let’s look at the Flowers dataset and visualize a few of the images from that dataset. Figure 2 provides a sense of how the images look.
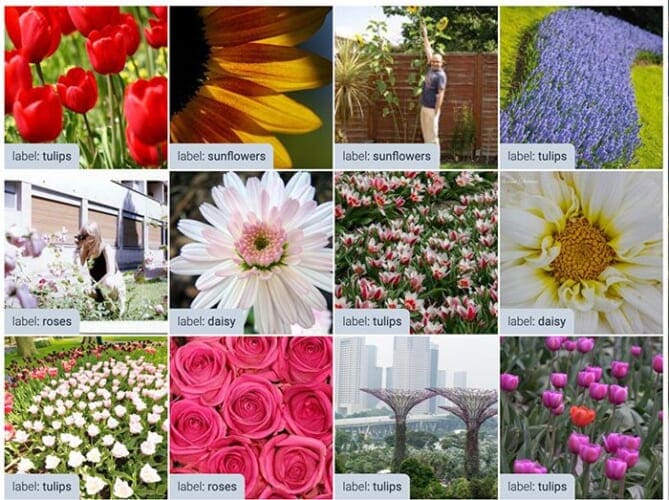
The dataset we’ll be using for our fine-tuning experiments is a dataset of flower images curated by the TensorFlow development team.
Thai dataset 3,670 images belonging to five distinct flower species:
- Daisy: 633 images
- Dandelion: 898 images
- Roses: 641 images
- Sunflowers: 699 images
- Tulips: 799 images
Our job is to train an image classification model to recognize each of these flower species. We’ll achieve this goal by applying transfer learning with PyTorch.
Project structure
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree --dirsfirst --filelimit 10 . ├── flower_photos │ ├── daisy [633 entries exceeds filelimit, not opening dir] │ ├── dandelion [898 entries exceeds filelimit, not opening dir] │ ├── roses [641 entries exceeds filelimit, not opening dir] │ ├── sunflowers [699 entries exceeds filelimit, not opening dir] │ ├── tulips [799 entries exceeds filelimit, not opening dir] │ └── LICENSE.txt ├── output │ ├── finetune.png │ └── warmup.png ├── pyimagesearch │ ├── config.py │ └── create_dataloaders.py ├── build_dataset.py ├── feature_extraction_results.png ├── fine_tune.py ├── fine_tune_results.png ├── inference.py └── train_feature_extraction.py
The flower_photos directory contains our set of flower images.
We’ll be training our models on this flowers dataset. The output directory will then be populated with our training/validation plots.
Inside the pyimagesearch module, we have two Python files:
config.py: Contains important configuration variables used in our driver scripts.create_dataloaders.py: Implements theget_dataloaderhelper function, responsible for creating aDataLoaderinstance to parse our files from theflower_photosdirectory
We then have four Python drive scripts:
build_dataset.py: Takes theflower_photosdirectory and builds adatasetdirectory. We’ll create special subdirectories to store our training and validation splits, allowing PyTorch’sImageFolderscript to parse the directory and train our model.train_feature_extraction.py: Performs transfer learning via feature extraction and serializes the output model to disk.fine_tune.py: Performs transfer learning via fine-tuning and saves the model to disk.inference.py: Accepts a trained PyTorch model and uses it to make predictions on input flower images.
The .png files in the project directory structure contain the visualizations of our output predictions.
Creating our configuration file
Before implementing any of our transfer learning scripts, we first need to create our configuration file.
This configuration file will store important variables and parameters used across our driver scripts. Instead of re-defining them in every script, we’ll simply define them once here (and thereby make our code cleaner and easier to read).
Open the config.py file in the pyimagesearch module and insert the following code:
# import the necessary packages import torch import os # define path to the original dataset and base path to the dataset # splits DATA_PATH = "flower_photos" BASE_PATH = "dataset" # define validation split and paths to separate train and validation # splits VAL_SPLIT = 0.1 TRAIN = os.path.join(BASE_PATH, "train") VAL = os.path.join(BASE_PATH, "val")
Line 7 defines DATA_PATH, the path to our input flower_photos directory.
We then set the BASE_PATH variable to point to our dataset directory (Line 8). This directory will be created and populated via our build_dataset.py script. When we run our transfer learning/inference scripts, we’ll be reading images from the BASE_PATH directory.
Line 12 sets our validation split to 10%, meaning that we’ll take 90% of our data for training and 10% for validation.
We also define the TRAIN and VAL subdirectories on Lines 13 and 14. Once we run build_dataset.py, we’ll have two subdirectories inside dataset:
dataset/traindataset/val
Each subdirectory will store its respective images for each of the five flower classes.
We’ll fine-tune the ResNet architecture, pre-trained on the ImageNet dataset. This implies that we’ll have to set some important parameters for image pixel scaling:
# specify ImageNet mean and standard deviation and image size MEAN = [0.485, 0.456, 0.406] STD = [0.229, 0.224, 0.225] IMAGE_SIZE = 224 # determine the device to be used for training and evaluation DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
Lines 17 and 18 define the mean and standard deviation of the pixel intensities in the RGB color space.
These values were obtained by researchers training their models on the ImageNet dataset. They looped over all images in the ImageNet dataset, loaded them from disk, and computed the mean and standard deviation of RGB pixel intensities.
The mean and standard deviation values were then used for image pixel normalization before training.
Even though we are not using the ImageNet dataset for transfer learning, we still need to perform the same preprocessing steps that ResNet was trained on; otherwise, the model would not make correct sense of the input image.
Line 19 sets our input IMAGE_SIZE to be 224 × 224 pixels.
The DEVICE variable controls whether we are using our CPU or GPU for training.
Next, we have some variables that will be used for feature extraction and fine-tuning:
# specify training hyperparameters FEATURE_EXTRACTION_BATCH_SIZE = 256 FINETUNE_BATCH_SIZE = 64 PRED_BATCH_SIZE = 4 EPOCHS = 20 LR = 0.001 LR_FINETUNE = 0.0005
When performing feature extraction, we’ll pass images through our network in batches of 256 (Line 25).
Instead of performing transfer learning via fine-tuning, we’ll use image batches of 64 (Line 26).
When performing inference (i.e., making predictions via the inference.py script), we’ll use batch sizes of 4.
Finally, we set the number of EPOCHS we’ll train our model for, the learning rate for feature extraction, and the learning rate for fine-tuning. These values were determined by running simple hyperparameter tuning experiments.
We’ll wrap our up configuration script by setting output file paths:
# define paths to store training plots and trained model
WARMUP_PLOT = os.path.join("output", "warmup.png")
FINETUNE_PLOT = os.path.join("output", "finetune.png")
WARMUP_MODEL = os.path.join("output", "warmup_model.pth")
FINETUNE_MODEL = os.path.join("output", "finetune_model.pth")
Lines 33 and 34 set the file paths to our output training history and serialized model for feature extraction.
Lines 35 and 36 do the same, only for fine-tuning.
Implementing our DataLoader helper
PyTorch allows us to easily construct DataLoader objects from images stored in directories on disk.
Note: If you’ve never used PyTorch’s DataLoader object before, I suggest you read our introduction to PyTorch tutorials, along with our guide on PyTorch image data loaders.
Open the create_dataloaders.py file inside the pyimagesearch module, and let’s get started:
# import the necessary packages from . import config from torch.utils.data import DataLoader from torchvision import datasets import os
Lines 2-5 import our required Python packages, including:
config: The configuration file we created in the previous sectionDataLoader: PyTorch’s data loading class used to handle data batching efficientlydatasets: A submodule from PyTorch that provides access to theImageFolderclass, used to read images from an input directory on diskos: Used to determine the number of cores/workers on a CPU, allowing data loading to take place faster
From there, we define the get_dataloader function:
def get_dataloader(rootDir, transforms, batchSize, shuffle=True): # create a dataset and use it to create a data loader ds = datasets.ImageFolder(root=rootDir, transform=transforms) loader = DataLoader(ds, batch_size=batchSize, shuffle=shuffle, num_workers=os.cpu_count(), pin_memory=True if config.DEVICE == "cuda" else False) # return a tuple of the dataset and the data loader return (ds, loader)
This function accepts four arguments:
rootDir: Path to the input directory containing our dataset on disk (i.e., thedatasetdirectory)transforms: A list of data transforms to perform, including preprocessing steps and data augmentationbatchSize: Size of the batches to be yielded from theDataLoadershuffle: Whether or not to shuffle the data — we’ll shuffle data for training but not for validation
Lines 9 and 10 create our ImageFolder class, used to read images from the rootDir. This is also where we’ll apply our set of transforms.
The DataLoader is then created on Lines 11-14. Here we:
- Pass in our
ImageFolderobject - Set the batch size
- Indicate whether or not shuffling will be performed
- Set
num_workers, which is the number of CPUs/cores on our machine - Set whether or not we’re using GPU memory or not
The resulting ImageFolder and DataLoader instances are returned to the calling function on Line 17.
Creating our dataset organization script
Now that we’ve created our configuration file and implemented our DataLoader helper function, let’s create the build_dataset.py script used to build our dataset directory, along with the train and val subdirectories.
Open the build_dataset.py file in your project directory structure and insert the following code:
# USAGE # python build_dataset.py # import necessary packages from pyimagesearch import config from imutils import paths import numpy as np import shutil import os
Lines 5-9 import our required Python packages. Our imports include:
config: Our Python configuration filepaths: A submodule ofimutilsused to gather paths to images inside a given directorynumpy: Numerical array processingshutil: Used to copy files from one location to anotheros: Operating system module used to create directories on disk
Next, we have our copy_images function:
def copy_images(imagePaths, folder): # check if the destination folder exists and if not create it if not os.path.exists(folder): os.makedirs(folder) # loop over the image paths for path in imagePaths: # grab image name and its label from the path and create # a placeholder corresponding to the separate label folder imageName = path.split(os.path.sep)[-1] label = path.split(os.path.sep)[1] labelFolder = os.path.join(folder, label) # check to see if the label folder exists and if not create it if not os.path.exists(labelFolder): os.makedirs(labelFolder) # construct the destination image path and copy the current # image to it destination = os.path.join(labelFolder, imageName) shutil.copy(path, destination)
The copy_images function requires two arguments:
imagePaths: The paths to all images in a given input directoryfolder: The output base directory where copied images will be stored (i.e., thedatasetdirectory)
Lines 13 and 14 make a quick check to see if the folder directory exists. If the directory does not exist, we create it.
From there, we loop over all imagePaths (Line 17). For each path, we:
- Grab the filename (Line 20)
- Extract the class label from the image path (Line 21)
- Construct the base output directory (Line 22)
If the labelFolder subdirectory does not yet exist, we create it on Lines 25 and 26.
From there, we build the path to the destination file (Line 30) and copy it (Line 31).
Let’s now put this copy_images function to work:
# load all the image paths and randomly shuffle them
print("[INFO] loading image paths...")
imagePaths = list(paths.list_images(config.DATA_PATH))
np.random.shuffle(imagePaths)
# generate training and validation paths
valPathsLen = int(len(imagePaths) * config.VAL_SPLIT)
trainPathsLen = len(imagePaths) - valPathsLen
trainPaths = imagePaths[:trainPathsLen]
valPaths = imagePaths[trainPathsLen:]
# copy the training and validation images to their respective
# directories
print("[INFO] copying training and validation images...")
copy_images(trainPaths, config.TRAIN)
copy_images(valPaths, config.VAL)
Lines 35 and 36 read all imagePaths from our input DATA_PATH (i.e., the flower_photos directory) and then randomly shuffle them.
Lines 39-42 create our training and validation splits based on our VAL_SPLIT percentage.
Finally, we use the copy_images function to copy the trainPaths and valPaths to their respective output directories (Lines 47 and 48).
The following section will make this process more clear, including why we are going through all the trouble to organize our dataset directory structure in this specific manner.
Building our dataset on disk
We are now ready to build our dataset directory. Be sure to use the “Downloads” section of this tutorial to access the source code and example images.
From there, open a shell and execute the following command:
$ python build_dataset.py [INFO] loading image paths... [INFO] copying training and validation images...
After the script executes, you’ll see that a new dataset directory has been created:
$ tree dataset --dirsfirst --filelimit 10
dataset
├── train
│ ├── daisy [585 entries exceeds filelimit, not opening dir]
│ ├── dandelion [817 entries exceeds filelimit, not opening dir]
│ ├── roses [568 entries exceeds filelimit, not opening dir]
│ ├── sunflowers [624 entries exceeds filelimit, not opening dir]
│ └── tulips [709 entries exceeds filelimit, not opening dir]
└── val
├── daisy [48 entries exceeds filelimit, not opening dir]
├── dandelion [81 entries exceeds filelimit, not opening dir]
├── roses [73 entries exceeds filelimit, not opening dir]
├── sunflowers [75 entries exceeds filelimit, not opening dir]
└── tulips [90 entries exceeds filelimit, not opening dir]
Notice that the dataset directory has two subdirectories:
train: Contains training images for each of the five classes.val: Stores the validation images for each of the five classes.
By creating a train and val directory, we can now easily utilize PyTorch’s ImageFolder class to build a DataLoader such that we can fine-tune our models.
Implementing feature extraction and transfer learning PyTorch
The first method of transfer learning we are going to implement is feature extraction.
Transfer learning via feature extraction works by:
- Taking a pre-trained CNN (typically on the ImageNet dataset)
- Removing the FC layer head from the CNN
- Treating the output of the body of the network as an arbitrary feature extractor with spatial dimensions
M × N × C
From there, we have two choices:
- Take a standard Logistic Regression classifier (like the one found in the scikit-learn library) and train it on the extracted features from each image
- Or, more simply, place a softmax classifier on top of the body of the network
Either option is viable and more-or-less the “same” as the other.
The first option works great when your dataset of extracted features fits into the RAM of your machine. That way, you load the entire dataset, instantiate an instance of your favorite Logistic Regression classifier model, and then train it.
The problem happens when your dataset is too large to fit into your machine’s memory. When that happens, you could use something like online learning to train your Logistic Regression classifier, but that just introduces another set of libraries and dependencies.
Instead, it’s easier to just leverage the power of PyTorch and create a Logistic Regression-like classifier on top of the extracted features and then train it using PyTorch functions. This is the method we’ll be implementing here today.
Open the train_feature_extraction.py file in your project directory structure, and let’s get started:
# USAGE # python train_feature_extraction.py # import the necessary packages from pyimagesearch import config from pyimagesearch import create_dataloaders from imutils import paths from torchvision.models import resnet50 from torchvision import transforms from tqdm import tqdm from torch import nn import matplotlib.pyplot as plt import numpy as np import torch import time
Lines 5-15 import our required Python packages. Notable imports include:
config: Our Python configuration filecreate_dataloaders: Creates an instance of a PyTorchDataLoaderfrom our inputdatasetdirectoryresnet50: The ResNet model we’ll be utilizing (pre-trained on the ImageNet dataset)transforms: Allows us to define a set of preprocessing and/or data augmentation routines that will be sequentially applied to input imagestqdm: A Python library used to create nicely formatted progress barstorchandnn: Contains PyTorch’s neural network classes and functions
With our imports taken care of, let’s move on to defining our data preprocessing and augmentation pipelines:
# define augmentation pipelines trainTansform = transforms.Compose([ transforms.RandomResizedCrop(config.IMAGE_SIZE), transforms.RandomHorizontalFlip(), transforms.RandomRotation(90), transforms.ToTensor(), transforms.Normalize(mean=config.MEAN, std=config.STD) ]) valTransform = transforms.Compose([ transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), transforms.ToTensor(), transforms.Normalize(mean=config.MEAN, std=config.STD) ])
We build data processing/augmentation steps using the Compose function, found inside the transforms submodule of PyTorch.
First, we create a trainTransform that, given an input image, will:
- Randomly resize and crop the image to
IMAGE_SIZEdimensions - Randomly perform horizontal flipping
- Randomly perform rotation by in the range
[-90, 90] - Converts the resulting image into a PyTorch tensor
- Performs mean subtraction and scaling
We then have our valTransform, which:
- Resizes the input image to
IMAGE_SIZEdimensions - Converts the image to a PyTorch tensor
- Performs mean subtraction and scaling
Notice that we do not perform data augmentation inside the validation transformer — there is no need to perform data augmentation for our validation data.
With both our training and validation Compose objects created, let’s apply our get_dataloader function:
# create data loaders (trainDS, trainLoader) = create_dataloaders.get_dataloader(config.TRAIN, transforms=trainTansform, batchSize=config.FEATURE_EXTRACTION_BATCH_SIZE) (valDS, valLoader) = create_dataloaders.get_dataloader(config.VAL, transforms=valTransform, batchSize=config.FEATURE_EXTRACTION_BATCH_SIZE, shuffle=False)
Lines 32-34 create our training data loaders, while Lines 35-37 create our validation data loaders.
Each of these loaders will yield images from the dataset/train and dataset/val directories, respectively.
Also, note that we do not perform shuffling for our validation data (just like we do not perform data augmentation for validation data).
Let’s now prepare the ResNet50 model for transfer learning via feature extraction:
# load up the ResNet50 model model = resnet50(pretrained=True) # since we are using the ResNet50 model as a feature extractor we set # its parameters to non-trainable (by default they are trainable) for param in model.parameters(): param.requires_grad = False # append a new classification top to our feature extractor and pop it # on to the current device modelOutputFeats = model.fc.in_features model.fc = nn.Linear(modelOutputFeats, len(trainDS.classes)) model = model.to(config.DEVICE)
Line 40 loads ResNet, pre-trained on ImageNet from disk.
Since we’ll be using ResNet for feature extraction, and therefore no actual “learning” needs to take place in the body of the network, we freeze all layers in the body of the network (Lines 44 and 45).
From there, we create a new FC layer head that consists of a single FC layer. Effectively, this layer, when trained with categorical cross-entropy loss, will serve as our surrogate softmax classifier.
This new layer is then appended to the body of the network, and the model itself is moved to our DEVICE (either our CPU or GPU).
Next, we initialize our loss function and optimization method:
# initialize loss function and optimizer (notice that we are only
# providing the parameters of the classification top to our optimizer)
lossFunc = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.fc.parameters(), lr=config.LR)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // config.FEATURE_EXTRACTION_BATCH_SIZE
valSteps = len(valDS) // config.FEATURE_EXTRACTION_BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "train_acc": [], "val_loss": [],
"val_acc": []}
We’ll train our model using the Adam optimizer and categorical cross-entropy loss (Lines 55 and 56).
We also compute the number of steps our model will take, as a function of batch size, for both our training and testing sets, respectively (Lines 59 and 60).
Now, it’s time to train the model:
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.EPOCHS)):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (i, (x, y)) in enumerate(trainLoader):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFunc(pred, y)
# calculate the gradients
loss.backward()
# check if we are updating the model parameters and if so
# update them, and zero out the previously accumulated gradients
if (i + 2) % 2 == 0:
opt.step()
opt.zero_grad()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
On Line 69, we loop over our desired number of epochs.
For each batch of data in the trainLoader, we:
- Move the image and class label to our CPU/GPU (Line 85).
- Make predictions on the data (Line 88)
- Compute the loss, calculate the gradients, update the model weights, and zero the gradients (Lines 89-98)
- Accumulate our total training loss for the epoch (Line 102)
- Compute the total number of correct predictions (Lines 103 and 104)
Now that the epoch is complete, we can evaluate the model on the validation data:
# switch off autograd with torch.no_grad(): # set the model in evaluation mode model.eval() # loop over the validation set for (x, y) in valLoader: # send the input to the device (x, y) = (x.to(config.DEVICE), y.to(config.DEVICE)) # make the predictions and calculate the validation loss pred = model(x) totalValLoss += lossFunc(pred, y) # calculate the number of correct predictions valCorrect += (pred.argmax(1) == y).type( torch.float).sum().item()
Notice here that we turn off autograd and put the model in evaluation mode — this is a requirement when evaluating with PyTorch, so don’t forget to do it!
From there, we loop over all data points in our valLoader, make predictions on them, and compute our total loss and number of correct validation predictions.
The following code block aggregates our training/validation loss and accuracy, updates our training history, and then prints the loss/accuracy information to our terminal:
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(valDS)
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
Our final code block plots our training history and serializes our model to disk:
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.WARMUP_PLOT)
# serialize the model to disk
torch.save(model, config.WARMUP_MODEL)
After this script executes, you’ll find a file named warmup_model.pth in your output directory — this file is your serialized PyTorch model, which can then be used to make predictions inside the inference.py script.
PyTorch transfer learning with feature extraction
We are now ready to perform transfer learning via feature extraction with PyTorch.
Make sure that you have:
- Use the “Downloads” section of this tutorial to access the source code, example images, etc.
- Executed the
build_dataset.pyscript to create our dataset directory structure
Provided you’ve accomplished both of these steps, you can move on to running the train_feature_extraction.py script:
$ python train_feature_extraction.py [INFO] training the network... 0% 0/20 [00:00<?, ?it/s][INFO] EPOCH: 1/20 Train loss: 1.610827, Train accuracy: 0.4063 Val loss: 2.295713, Val accuracy: 0.6512 5% 1/20 [00:17<05:24, 17.08s/it][INFO] EPOCH: 2/20 Train loss: 1.190757, Train accuracy: 0.6703 Val loss: 1.720566, Val accuracy: 0.7193 10% 2/20 [00:33<05:05, 16.96s/it][INFO] EPOCH: 3/20 Train loss: 0.958189, Train accuracy: 0.7163 Val loss: 1.423687, Val accuracy: 0.8120 15% 3/20 [00:50<04:47, 16.90s/it][INFO] EPOCH: 4/20 Train loss: 0.805547, Train accuracy: 0.7811 Val loss: 1.200151, Val accuracy: 0.7793 20% 4/20 [01:07<04:31, 16.94s/it][INFO] EPOCH: 5/20 Train loss: 0.731831, Train accuracy: 0.7856 Val loss: 1.066768, Val accuracy: 0.8283 25% 5/20 [01:24<04:14, 16.95s/it][INFO] EPOCH: 6/20 Train loss: 0.664001, Train accuracy: 0.8044 Val loss: 0.996960, Val accuracy: 0.8311 ... 75% 15/20 [04:13<01:24, 16.83s/it][INFO] EPOCH: 16/20 Train loss: 0.495064, Train accuracy: 0.8480 Val loss: 0.736332, Val accuracy: 0.8665 80% 16/20 [04:30<01:07, 16.86s/it][INFO] EPOCH: 17/20 Train loss: 0.502294, Train accuracy: 0.8435 Val loss: 0.732066, Val accuracy: 0.8501 85% 17/20 [04:46<00:50, 16.85s/it][INFO] EPOCH: 18/20 Train loss: 0.486568, Train accuracy: 0.8471 Val loss: 0.703661, Val accuracy: 0.8801 90% 18/20 [05:03<00:33, 16.82s/it][INFO] EPOCH: 19/20 Train loss: 0.470880, Train accuracy: 0.8480 Val loss: 0.715560, Val accuracy: 0.8474 95% 19/20 [05:20<00:16, 16.85s/it][INFO] EPOCH: 20/20 Train loss: 0.489092, Train accuracy: 0.8426 Val loss: 0.684679, Val accuracy: 0.8774 100% 20/20 [05:37<00:00, 16.86s/it] [INFO] total time taken to train the model: 337.24s
Total training time took just over 5 minutes. We obtained 84.26% training accuracy and 87.74% validation accuracy.
Figure 3 displays a plot of our training history.
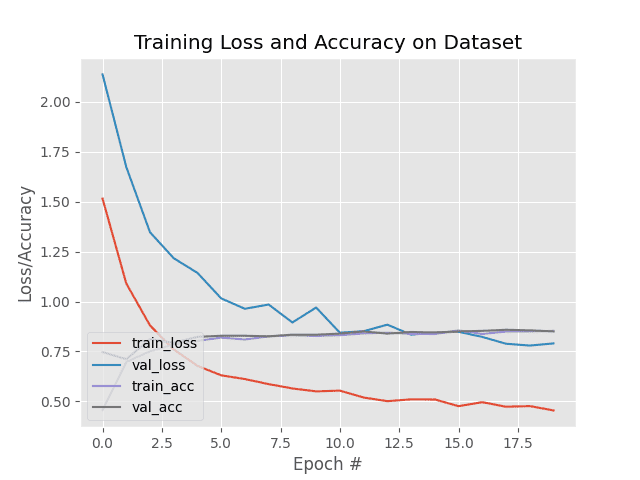
Not too bad for how little time we invested in the training process!
Fine-tuning a CNN with PyTorch
So far in this tutorial, you have learned how to perform transfer learning via feature extraction.
This method works well in some cases, but its simplicity has its drawbacks, namely that both accuracy and the ability of the model to generalize can suffer.
Most forms of transfer learning apply fine-tuning, which is the topic of this section.
Similar to feature extraction, we start by removing the FC layer head from the network, but this time we create a brand new layer head with a set of linear, ReLU, and dropout layers, similar to what you would see on a modern state-of-the-art CNN.
We then perform some combination of:
- Freezing all layers in the body of the network and training the layer head
- Freezing all layers, training the layer head, and then unfreezing the body and training that too
- Simply leaving all layers unfrozen and training them all together
Exactly which method you use is an experiment you’ll run for yourself — be sure to measure which one gives you the lowest loss and highest accuracy!
Let’s learn how to apply fine-tuning via transfer learning with PyTorch. Open the fine_tune.py file in your project directory structure, and let’s get started:
# USAGE # python fine_tune.py # import the necessary packages from pyimagesearch import config from pyimagesearch import create_dataloaders from imutils import paths from torchvision.models import resnet50 from torchvision import transforms from tqdm import tqdm from torch import nn import matplotlib.pyplot as plt import numpy as np import shutil import torch import time import os
We start on Lines 5-17 by importing our required Python packages. Note that these imports are essentially identical to our previous script.
We then define our training and validation transforms, just like we did for feature extraction:
# define augmentation pipelines trainTansform = transforms.Compose([ transforms.RandomResizedCrop(config.IMAGE_SIZE), transforms.RandomHorizontalFlip(), transforms.RandomRotation(90), transforms.ToTensor(), transforms.Normalize(mean=config.MEAN, std=config.STD) ]) valTransform = transforms.Compose([ transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), transforms.ToTensor(), transforms.Normalize(mean=config.MEAN, std=config.STD) ])
The same is true for our data loaders — they are instantiated in the exact same manner as in feature extraction:
# create data loaders (trainDS, trainLoader) = create_dataloaders.get_dataloader(config.TRAIN, transforms=trainTansform, batchSize=config.FINETUNE_BATCH_SIZE) (valDS, valLoader) = create_dataloaders.get_dataloader(config.VAL, transforms=valTransform, batchSize=config.FINETUNE_BATCH_SIZE, shuffle=False)
The real change comes when we load ResNet from disk and modify the architecture itself, so let’s inspect this section closely:
# load up the ResNet50 model model = resnet50(pretrained=True) numFeatures = model.fc.in_features # loop over the modules of the model and set the parameters of # batch normalization modules as not trainable for module, param in zip(model.modules(), model.parameters()): if isinstance(module, nn.BatchNorm2d): param.requires_grad = False # define the network head and attach it to the model headModel = nn.Sequential( nn.Linear(numFeatures, 512), nn.ReLU(), nn.Dropout(0.25), nn.Linear(512, 256), nn.ReLU(), nn.Dropout(0.5), nn.Linear(256, len(trainDS.classes)) ) model.fc = headModel # append a new classification top to our feature extractor and pop it # on to the current device model = model.to(config.DEVICE)
Line 41 loads our ResNet model from disk with weights pre-trained on the ImageNet dataset.
In this particular fine-tuning example, we are going to construct a new FC layer head and then train both the FC layer head and the body of the network at the same time.
However, we first need to pay close attention to the batch normalization layers in the network architecture. These layers have specific mean and standard deviation values that were obtained when the network was originally trained on the ImageNet dataset.
We do not want to update these statistics during training, so we make any instances of BatchNorm2d frozen on Lines 46-48.
If you are performing fine-tuning in a network that utilizes batch normalization, make sure you freeze those layers before you start training!
From there, we construct our new headModel which consists of a series of FC => RELU => DROPOUT layers (Lines 51-59).
The output of the final Linear layer is the number of classes in the dataset (Line 58).
Finally, we add the new headModel to the network, thereby replacing the old FC layer head.
Note: If you want additional details on transfer learning, feature extraction, and fine-tuning, I suggest you read the following tutorials — Transfer Learning with Keras and Deep Learning; Fine-tuning with Keras and Deep Learning; and Keras: Feature extraction on large datasets with Deep Learning.
With our “network surgery” done, we can move on to instantiating our loss function and optimizer:
# initialize loss function and optimizer (notice that we are only
# providing the parameters of the classification top to our optimizer)
lossFunc = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=config.LR)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // config.FINETUNE_BATCH_SIZE
valSteps = len(valDS) // config.FINETUNE_BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "train_acc": [], "val_loss": [],
"val_acc": []}
And from there, we start our training pipeline:
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.EPOCHS)):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (i, (x, y)) in enumerate(trainLoader):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFunc(pred, y)
# calculate the gradients
loss.backward()
# check if we are updating the model parameters and if so
# update them, and zero out the previously accumulated gradients
if (i + 2) % 2 == 0:
opt.step()
opt.zero_grad()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
At this point, the code to fine-tune our model is identical to the feature extraction method, so you can defer to the previous section for a detailed review of the code.
With training complete, we can then move on to the validation part of the epoch:
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (x, y) in valLoader:
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation loss
pred = model(x)
totalValLoss += lossFunc(pred, y)
# calculate the number of correct predictions
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(valDS)
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
After validation is complete, we plot our training history and serialize our model to disk:
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.FINETUNE_PLOT)
# serialize the model to disk
torch.save(model, config.FINETUNE_MODEL)
After executing the train_feature_extraction.py script, you will find a trained model named finetune_model.pth in your output directory.
You can use this model with inference.py to make predictions on new images.
PyTorch fine-tuning results
Let’s now apply fine-tuning using PyTorch.
Again, make sure you have:
- Used the “Downloads” section of this tutorial to download the source code, dataset, etc.
- Executed the
build_dataset.pyscript to create ourdatasetdirectory
From there, you can execute the following command:
$ python fine_tune.py [INFO] training the network... 0% 0/20 [00:00<?, ?it/s][INFO] EPOCH: 1/20 Train loss: 0.857740, Train accuracy: 0.6809 Val loss: 2.498850, Val accuracy: 0.6512 5% 1/20 [00:18<05:55, 18.74s/it][INFO] EPOCH: 2/20 Train loss: 0.581107, Train accuracy: 0.7972 Val loss: 0.432770, Val accuracy: 0.8665 10% 2/20 [00:38<05:40, 18.91s/it][INFO] EPOCH: 3/20 Train loss: 0.506620, Train accuracy: 0.8289 Val loss: 0.721634, Val accuracy: 0.8011 15% 3/20 [00:57<05:26, 19.18s/it][INFO] EPOCH: 4/20 Train loss: 0.477470, Train accuracy: 0.8341 Val loss: 0.431005, Val accuracy: 0.8692 20% 4/20 [01:17<05:10, 19.38s/it][INFO] EPOCH: 5/20 Train loss: 0.467796, Train accuracy: 0.8368 Val loss: 0.746030, Val accuracy: 0.8120 25% 5/20 [01:37<04:53, 19.57s/it][INFO] EPOCH: 6/20 Train loss: 0.429070, Train accuracy: 0.8523 Val loss: 0.607376, Val accuracy: 0.8311 ... 75% 15/20 [04:51<01:36, 19.33s/it][INFO] EPOCH: 16/20 Train loss: 0.317167, Train accuracy: 0.8880 Val loss: 0.344129, Val accuracy: 0.9183 80% 16/20 [05:11<01:17, 19.32s/it][INFO] EPOCH: 17/20 Train loss: 0.295942, Train accuracy: 0.9013 Val loss: 0.375650, Val accuracy: 0.8992 85% 17/20 [05:30<00:58, 19.38s/it][INFO] EPOCH: 18/20 Train loss: 0.282065, Train accuracy: 0.9046 Val loss: 0.374338, Val accuracy: 0.8992 90% 18/20 [05:49<00:38, 19.30s/it][INFO] EPOCH: 19/20 Train loss: 0.254787, Train accuracy: 0.9116 Val loss: 0.302762, Val accuracy: 0.9264 95% 19/20 [06:08<00:19, 19.25s/it][INFO] EPOCH: 20/20 Train loss: 0.270875, Train accuracy: 0.9083 Val loss: 0.385452, Val accuracy: 0.9019 100% 20/20 [06:28<00:00, 19.41s/it] [INFO] total time taken to train the model: 388.23s
Since our model is more complex (due to adding the new FC layer head to the body of the network), training is now taking ~6.5 minutes.
However, in Figure 4, we obtain higher accuracy than our simple feature extraction method (90.83%/90.19% versus 84.26%/87.74%, respectively):
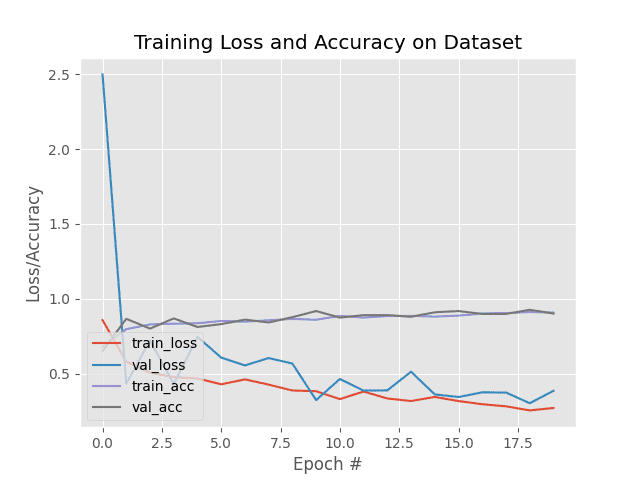
While performing fine-tuning does take more work, you’ll often find that accuracy is higher, and your model will generalize better.
Implementing our PyTorch prediction script
So far, you’ve learned two ways to apply transfer learning with PyTorch:
- Feature extraction
- Fine-tuning
Both methods have resulted in models obtaining 80-90% accuracy …
… but how do we use these models to make predictions?
The answer is to use our inference.py script:
# USAGE # python inference.py --model output/warmup_model.pth # python inference.py --model output/finetune_model.pth # import the necessary packages from pyimagesearch import config from pyimagesearch import create_dataloaders from torchvision import transforms import matplotlib.pyplot as plt from torch import nn import argparse import torch
We start our inference.py script with a number of imports, including:
config: Our configuration filecreate_dataloaders: Our helper utility to create aDataLoaderobject from an input directory of images (in this case, ourdataset/valdirectory)transforms: Applies data preprocessing in a sequential mannermatplotlib: Displays our output images and predictions to our screentorchandnn: Our PyTorch bindingsargparse: Parses any command line arguments
Speaking of command line arguments, let’s parse them now:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
args = vars(ap.parse_args())
We only need a single argument here, --model, which is the path to our trained PyTorch model residing on disk.
Let’s now create a transform object for our input images:
# build our data pre-processing pipeline testTransform = transforms.Compose([ transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)), transforms.ToTensor(), transforms.Normalize(mean=config.MEAN, std=config.STD) ]) # calculate the inverse mean and standard deviation invMean = [-m/s for (m, s) in zip(config.MEAN, config.STD)] invStd = [1/s for s in config.STD] # define our de-normalization transform deNormalize = transforms.Normalize(mean=invMean, std=invStd)
Just like our validation transformer in the previous section, all we’ll be doing here is:
- Resizing our input images to
IMAGE_SIZEdimensions - Converting the image to a PyTorch tensor
- Applying mean scaling to the input image
However, to display the output images to our screen, we’ll actually need to “denormalize” them. Lines 28 and 29 compute the inverse mean and standard deviation while Line 32 creates a deNormalize transform.
Using the deNormalize transform, we’ll be able to “undo” the testTransform, and then display the output image from our screen.
Let’s now build a DataLoader for our config.VAL directory:
# initialize our test dataset and data loader
print("[INFO] loading the dataset...")
(testDS, testLoader) = create_dataloaders.get_dataloader(config.VAL,
transforms=testTransform, batchSize=config.PRED_BATCH_SIZE,
shuffle=True)
From there, we can set our target computation device and load our trained PyTorch model:
# check if we have a GPU available, if so, define the map location
# accordingly
if torch.cuda.is_available():
map_location = lambda storage, loc: storage.cuda()
# otherwise, we will be using CPU to run our model
else:
map_location = "cpu"
# load the model
print("[INFO] loading the model...")
model = torch.load(args["model"], map_location=map_location)
# move the model to the device and set it in evaluation mode
model.to(config.DEVICE)
model.eval()
Lines 40-47 check to see if we are using our CPU or GPU.
Lines 51-55 proceed to:
- Load our trained PyTorch mode from disk
- Move it to our target
DEVICE - Place the model in evaluation mode
Let’s now grab a random set of testing data from our testLoader:
# grab a batch of test data
batch = next(iter(testLoader))
(images, labels) = (batch[0], batch[1])
# initialize a figure
fig = plt.figure("Results", figsize=(10, 10))
And finally, we can make predictions on our test data:
# switch off autograd
with torch.no_grad():
# send the images to the device
images = images.to(config.DEVICE)
# make the predictions
print("[INFO] performing inference...")
preds = model(images)
# loop over all the batch
for i in range(0, config.PRED_BATCH_SIZE):
# initalize a subplot
ax = plt.subplot(config.PRED_BATCH_SIZE, 1, i + 1)
# grab the image, de-normalize it, scale the raw pixel
# intensities to the range [0, 255], and change the channel
# ordering from channels first tp channels last
image = images[i]
image = deNormalize(image).cpu().numpy()
image = (image * 255).astype("uint8")
image = image.transpose((1, 2, 0))
# grab the ground truth label
idx = labels[i].cpu().numpy()
gtLabel = testDS.classes[idx]
# grab the predicted label
pred = preds[i].argmax().cpu().numpy()
predLabel = testDS.classes[pred]
# add the results and image to the plot
info = "Ground Truth: {}, Predicted: {}".format(gtLabel,
predLabel)
plt.imshow(image)
plt.title(info)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
Line 65 turns off autograd computation (a requirement when placing a PyTorch model in evaluation mode) while Line 67 sends the images to the appropriate DEVICE.
Line 71 makes predictions on the images using our trained model.
To visualize the predictions, we first need to loop over them on Line 74. Inside the loop, we proceed to:
- Initialize a subplot to display the image and prediction (Line 76)
- Denormalize the image by “undoing” the mean scaling and swapping color channel ordering (Lines 81-84)
- Grabbing the ground-truth label (Lines 87 and 88)
- Grabbing the predicted label (Lines 91 and 92)
- Adding the image, ground-truth, and predicted label to the plot (Lines 95-99)
The output visualization is then displayed on our screen.
Making predictions with our trained PyTorch model
Let’s now make predictions using our inference.py script and our trained PyTorch models.
Go to the “Downloads” section of this tutorial to access the source code, datasets, etc., and from there, you can execute the following command:
$ python inference.py --model output/finetune_model.pth [INFO] loading the dataset... [INFO] loading the model... [INFO] performing inference...
You can see the results in Figure 5.

Here you can see that we have correctly classified our flower images — and best of all, we were able to obtain such high accuracy with little effort on our part due to transfer learning.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to perform transfer learning using PyTorch.
Specifically, we discussed two types of transfer learning:
- Transfer learning via feature extraction
- Transfer learning via fine-tuning
The first method is typically easier to implement and requires less effort. However, it tends to be less accurate than the second method.
I typically recommend using the feature extraction method to obtain a baseline accuracy. If the accuracy is sufficient for your application, fantastic! You’re done, and you can continue building the rest of your project.
However, if accuracy is not sufficient, then you should apply fine-tuning and see if you can boost your accuracy higher.
In either case, transfer learning, whether via feature extraction or fine-tuning, tends to save you a ton of time and effort, as opposed to training your model from scratch.
Citation Information
Rosebrock, A. “PyTorch: Transfer Learning and Image Classification,” PyImageSearch, 2021, https://pyimagesearch.com/2021/10/11/pytorch-transfer-learning-and-image-classification/
@article{Rosebrock_2021_Transfer,
author = {Adrian Rosebrock},
title = {{PyTorch}: Transfer Learning and Image Classification},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/10/11/pytorch-transfer-learning-and-image-classification/}, }
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.