
In this tutorial, you will learn how to perform object detection with pre-trained networks using PyTorch. Utilizing pre-trained object detection networks, you can detect and recognize 90 common objects that your computer vision application will “see” in everyday life.

Today’s tutorial is the final part in our five part series on PyTorch fundamentals:
- What is PyTorch?
- Intro to PyTorch: Training your first neural network using PyTorch
- PyTorch: Training your first Convolutional Neural Network
- PyTorch image classification with pre-trained networks
- PyTorch object detection with pre-trained networks (today’s tutorial)
Throughout the rest of this tutorial, you’ll gain experience using PyTorch to detect objects in input images using seminal, state-of-the-art image classification networks, including Faster R-CNN with ResNet, Faster R-CNN with MobileNet, and RetinaNet.
To learn how to perform object detection with pre-trained PyTorch networks, just keep reading.
PyTorch object detection with pre-trained networks
In the first part of this tutorial, we will discuss what pre-trained object detection networks are, including what object detection networks are built into the PyTorch library.
From there, we’ll configure our development environment and review our project directory structure.
We’ll review two Python scripts today. The first one will perform object detection in images, while the second one will show you how to perform real-time object detection in video streams (a GPU will be required to obtain real-time performance).
Finally, we’ll wrap up this tutorial with a discussion of our results.
What are pre-trained object detection networks?

Just like the ImageNet challenge tends to be the de facto standard for image classification, the COCO dataset (Common Objects in Context) tends to be the standard for object detection benchmarking.
This dataset includes over 90 classes of common objects you’ll see in the everyday world. Computer vision and deep learning researchers develop, train, and evaluate state-of-the-art object detection networks on the COCO dataset.
Most researchers also publish the pre-trained weights to their models so that computer vision practitioners can easily incorporate object detection into their own projects.
This tutorial will show how to use PyTorch to perform object detection using the following state-of-the-art classification networks:
- Faster R-CNN with a ResNet50 backbone (more accurate, but slower)
- Faster R-CNN with a MobileNet v3 backbone (faster, but less accurate)
- RetinaNet with a ResNet50 backbone (good balance between speed and accuracy)
Ready? Let’s get started.
Configuring your development environment
To follow this guide, you need to have both PyTorch and OpenCV installed on your system.
Luckily, both PyTorch and OpenCV are extremely easy to install using pip:
$ pip install torch torchvision $ pip install opencv-contrib-python
If you need help configuring your development environment for PyTorch, I highly recommend that you read the PyTorch documentation — PyTorch’s documentation is comprehensive and will have you up and running quickly.
And if you need help installing OpenCV, be sure to refer to my pip install OpenCV tutorial.
Having problems configuring your development environment?
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project structure
Before we start reviewing any source code, let’s first review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
You’ll then be presented with the following directory structure:
$ tree . --dirsfirst . ├── images │ ├── example_01.jpg │ ├── example_02.jpg │ ├── example_03.jpg │ ├── example_04.jpg │ ├── example_05.jpg │ └── example_06.jpg ├── coco_classes.pickle ├── detect_image.py └── detect_realtime.py 1 directory, 9 files
Inside the images directory, you’ll find a number of example images where we’ll be applying object detection.
The coco_classes.pickle file contains the names of the class labels our PyTorch pre-trained object detection networks were trained on.
We then have two Python scripts to review:
detect_image.py: Performs object detection with PyTorch in static imagesdetect_realtime.py: Applies PyTorch object detection to real-time video streams
Implementing our PyTorch object detection script
In this section, you will learn how to perform object detection with pre-trained PyTorch networks.
Open the detect_image.py script and insert the following code:
# import the necessary packages from torchvision.models import detection import numpy as np import argparse import pickle import torch import cv2
Lines 2-7 import our required Python packages. The most important import is detection from torchvision.models. The detection module contains PyTorch’s pre-trained object detectors.
Let’s move on to parsing our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to the input image")
ap.add_argument("-m", "--model", type=str, default="frcnn-resnet",
choices=["frcnn-resnet", "frcnn-mobilenet", "retinanet"],
help="name of the object detection model")
ap.add_argument("-l", "--labels", type=str, default="coco_classes.pickle",
help="path to file containing list of categories in COCO dataset")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
We have a number of command line arguments here, including:
--image: The path to the input image we want to apply object detection to--model: The type of PyTorch object detector we’ll be using (Faster R-CNN + ResNet, Faster R-CNN + MobileNet, or RetinaNet + ResNet)--labels: The path to the COCO labels file, containing human readable class labels--confidence: Minimum predicted probability to filter out weak detections
Here, we have a few important initializations:
# set the device we will be using to run the model
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the list of categories in the COCO dataset and then generate a
# set of bounding box colors for each class
CLASSES = pickle.loads(open(args["labels"], "rb").read())
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
Line 23 sets the device we’ll be using for inference (either CPU or GPU).
We then load our class labels from disk (Line 27) and initialize a random color for each unique label (Line 28). We’ll use these colors when drawing predicted bounding boxes and labels on our output image.
Next, we define a MODELS dictionary to map the name of a given object detector to its corresponding PyTorch function:
# initialize a dictionary containing model name and its corresponding
# torchvision function call
MODELS = {
"frcnn-resnet": detection.fasterrcnn_resnet50_fpn,
"frcnn-mobilenet": detection.fasterrcnn_mobilenet_v3_large_320_fpn,
"retinanet": detection.retinanet_resnet50_fpn
}
# load the model and set it to evaluation mode
model = MODELS[args["model"]](pretrained=True, progress=True,
num_classes=len(CLASSES), pretrained_backbone=True).to(DEVICE)
model.eval()
PyTorch provides us with three object detection models:
- Faster R-CNN with a ResNet50 backbone (more accurate, but slower)
- Faster R-CNN with a MobileNet v3 backbone (faster, but less accurate)
- RetinaNet with a ResNet50 backbone (good balance between speed and accuracy)
We then load the model from disk and send it to the appropriate DEVICE on Lines 39 and 40. We pass in a number of key parameters, including:
pretrained: Tells PyTorch to load the model architecture with pre-trained weights on the COCO datasetprogress=True: Displays download progress bar if model has not already been downloaded and cachednum_classes: Total number of unique classespretrained_backbone: Also provide the backbone network to the object detector
We then place the model in evaluation mode on Line 41.
With our model loaded, let’s move on to preparing our input image for object detection:
# load the image from disk image = cv2.imread(args["image"]) orig = image.copy() # convert the image from BGR to RGB channel ordering and change the # image from channels last to channels first ordering image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = image.transpose((2, 0, 1)) # add the batch dimension, scale the raw pixel intensities to the # range [0, 1], and convert the image to a floating point tensor image = np.expand_dims(image, axis=0) image = image / 255.0 image = torch.FloatTensor(image) # send the input to the device and pass the it through the network to # get the detections and predictions image = image.to(DEVICE) detections = model(image)[0]
Lines 44 and 45 load our input image from disk and clone it so that we can draw the bounding box predictions on it later in this script.
We then preprocess our image by:
- Converting color channel ordering from BGR to RGB (since PyTorch models were trained on RGB-ordered images)
- Swapping color channel ordering from “channels last” (OpenCV and Keras/TensorFlow default) to “channels first” (PyTorch default)
- Adding a batch dimension
- Scaling pixel intensities from the range [0, 255] to [0, 1]
- Converting the image from a NumPy array to a tensor with a floating point data type
The image is then moved to the appropriate device (Line 60). At that point, we pass the image through the model to obtain our bounding box predictions.
Let’s loop over our bounding box predictions now:
# loop over the detections
for i in range(0, len(detections["boxes"])):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections["scores"][i]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the detections,
# then compute the (x, y)-coordinates of the bounding box
# for the object
idx = int(detections["labels"][i])
box = detections["boxes"][i].detach().cpu().numpy()
(startX, startY, endX, endY) = box.astype("int")
# display the prediction to our terminal
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
print("[INFO] {}".format(label))
# draw the bounding box and label on the image
cv2.rectangle(orig, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(orig, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
# show the output image
cv2.imshow("Output", orig)
cv2.waitKey(0)
Line 64 loops over all detections from the network. We then grab the confidence (i.e., probability) associated with the detection on Line 67.
We filter out weak detections that do not meet our minimum confidence test on Line 71. Doing so helps filter out false-positive detections.
From there, we:
- Extract the
idxof the class label with the largest corresponding probability (Line 75) - Obtain the bounding box coordinates and convert them to integers (Lines 76 and 77)
- Display the prediction to our terminal (Lines 80 and 81)
- Draw the predicted bounding box and class label on our output image (Lines 84-88)
We wrap up the script by displaying our output image with bounding boxes drawn on it.
Object detection with PyTorch results
We are now ready to see some PyTorch object detection results!
Be sure to access the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, let’s apply object detection:
$ python detect_image.py --model frcnn-resnet \ --image images/example_01.jpg --labels coco_classes.pickle [INFO] car: 99.54% [INFO] car: 99.18% [INFO] person: 85.76%

The object detector we are using here is a Faster R-CNN with a ResNet50 backbone. Due to how the network is designed, Faster R-CNNs tend to be really good at detecting small objects in images — this is evidenced by the fact that not only are each of the cars detected in the input image, but also one of the drivers (whom is barely visible to the human eye).
Here is another example image using our Faster R-CNN object detector:
$ python detect_image.py --model frcnn-resnet \ --image images/example_06.jpg --labels coco_classes.pickle [INFO] dog: 99.92% [INFO] person: 99.90% [INFO] chair: 99.42% [INFO] tv: 98.22%

Here, we can see that our output object detections are quite accurate. Our model accurately detects me and Jemma, the family beagle, in the foreground of the scene. It also detects the television and chair in the background.
Let’s try one final image, this one of a more complicated scene that really demonstrates how good Faster R-CNN models are at detecting small objects:
$ python detect_image.py --model frcnn-resnet \ --image images/example_05.jpg --labels coco_classes.pickle \ --confidence 0.7 [INFO] horse: 99.88% [INFO] person: 99.76% [INFO] person: 99.09% [INFO] dog: 93.22% [INFO] person: 83.80% [INFO] person: 81.58% [INFO] truck: 71.33%
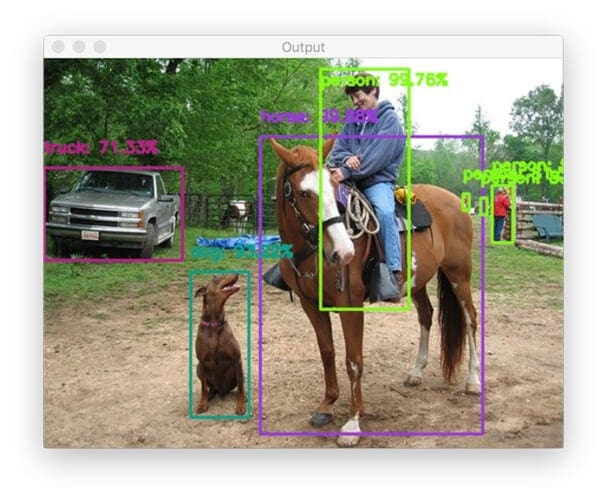
Notice here how we are manually specifying our --confidence command line argument of 0.7, meaning that object detections with a predicted probability > 70% will be considered a true-positive detection (if you remember, the detect_image.py script defaults the minimum confidence to 90%).
Note: Lowering our default confidence will allow us to detect more objects but perhaps at the expense of false-positives.
That said, as the output of Figure 5 shows, our model has made highly accurate predictions. We’ve not only detected the foreground objects such as the dog, horse, and person on the horse, but we’ve also detected background objects, including the truck and multiple people in the background.
As an exercise to gain more experience with object detection using PyTorch, I suggest you swap out the --model command line argument for frcnn-mobilenet and retinanet, and then compare the results of your output.
Implementing real-time object detection with PyTorch
In our previous section, you learned how to apply object detection to single images at PyTorch. This section will show you how to use PyTorch to apply object detection to video streams.
As you’ll see, much of the code from the previous implementation can be reused, with only minor changes.
Open the detect_realtime.py script in your project directory structure, and let’s get to work:
# import the necessary packages from torchvision.models import detection from imutils.video import VideoStream from imutils.video import FPS import numpy as np import argparse import imutils import pickle import torch import time import cv2
Lines 2-11 import our required Python packages. All these imports are essentially the same as our detect_image.py script, but with two notable additions:
VideoStream: Accesses our webcamFPS: Measures our approximate frames per second throughput rate of our object detection pipeline
Next comes our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", type=str, default="frcnn-resnet",
choices=["frcnn-resnet", "frcnn-mobilenet", "retinanet"],
help="name of the object detection model")
ap.add_argument("-l", "--labels", type=str, default="coco_classes.pickle",
help="path to file containing list of categories in COCO dataset")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
Our first switch, --model controls which PyTorch object detector we want to utilize.
The --labels argument provides the path to the COCO class files file.
And finally, the --confidence switch allows us to provide a minimum predicted probability to help filter out weak, false-positive detections.
The next code block handles setting our inference device (CPU or GPU), along with loading our class labels:
# set the device we will be using to run the model
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the list of categories in the COCO dataset and then generate a
# set of bounding box colors for each class
CLASSES = pickle.loads(open(args["labels"], "rb").read())
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
When performing object detection in video streams, I highly recommend that you use a GPU — a CPU will be too slow for anything close to real-time performance.
We then define our MODELS dictionary, just like in the previous script:
# initialize a dictionary containing model name and its corresponding
# torchvision function call
MODELS = {
"frcnn-resnet": detection.fasterrcnn_resnet50_fpn,
"frcnn-mobilenet": detection.fasterrcnn_mobilenet_v3_large_320_fpn,
"retinanet": detection.retinanet_resnet50_fpn
}
# load the model and set it to evaluation mode
model = MODELS[args["model"]](pretrained=True, progress=True,
num_classes=len(CLASSES), pretrained_backbone=True).to(DEVICE)
model.eval()
Lines 41-43 load the PyTorch object detection model from disk and place it in evaluation mode.
We are now ready to access our webcam:
# initialize the video stream, allow the camera sensor to warmup,
# and initialize the FPS counter
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
fps = FPS().start()
We insert a small sleep statement to allow our camera sensor to warm up.
A call to the start method of FPS allows us to start timing our approximate frames per second throughput rate.
The next step is to loop over frames from our video stream:
# loop over the frames from the video stream while True: # grab the frame from the threaded video stream and resize it # to have a maximum width of 400 pixels frame = vs.read() frame = imutils.resize(frame, width=400) orig = frame.copy() # convert the frame from BGR to RGB channel ordering and change # the frame from channels last to channels first ordering frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) frame = frame.transpose((2, 0, 1)) # add a batch dimension, scale the raw pixel intensities to the # range [0, 1], and convert the frame to a floating point tensor frame = np.expand_dims(frame, axis=0) frame = frame / 255.0 frame = torch.FloatTensor(frame) # send the input to the device and pass the it through the # network to get the detections and predictions frame = frame.to(DEVICE) detections = model(frame)[0]
Lines 56-58 read a frame from the video stream, resize it (the smaller the input frame, the faster inference will be), and then clone it so we can draw on it later.
Our preprocessing operations are identical to our previous script:
- Convert from BGR to RGB channel ordering
- Switch from “channels last” to “channels first” ordering
- Add a batch dimension
- Scale the pixel intensities in the frame from the range [0, 255] to [0, 1]
- Convert the frame to a floating point PyTorch tensor
The preprocessed frame is then moved to the appropriate device, after which predictions are made (Lines 73 and 74).
Processing the results of the object detection model is identical to that of predict_image.py:
# loop over the detections
for i in range(0, len(detections["boxes"])):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections["scores"][i]
# filter out weak detections by ensuring the confidence is
# greater than the minimum confidence
if confidence > args["confidence"]:
# extract the index of the class label from the
# detections, then compute the (x, y)-coordinates of
# the bounding box for the object
idx = int(detections["labels"][i])
box = detections["boxes"][i].detach().cpu().numpy()
(startX, startY, endX, endY) = box.astype("int")
# draw the bounding box and label on the frame
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
cv2.rectangle(orig, (startX, startY), (endX, endY),
COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(orig, label, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
Finally, we can display the output frame to our window:
# show the output frame
cv2.imshow("Frame", orig)
key = cv2.waitKey(1) & 0xFF
# if the 'q' key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
We continue to monitor our FPS until we click on the window opened by OpenCV and press the q key to exit the script, after which we stop our FPS timer and display (1) the elapsed time of the script and (2) approximate frames per second throughput information.
PyTorch real-time object detection results
Let’s learn how to apply object detection to video streams using PyTorch.
Be sure to access the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, you can execute the detect_realtime.py script:
$ python detect_realtime.py --model frcnn-mobilenet \ --labels coco_classes.pickle [INFO] starting video stream... [INFO] elapsed time: 56.47 [INFO] approx. FPS: 6.98
Using our Faster R-CNN model with a MobileNet background (best for speed) we’re achieving ≈7 FPS per second. We’re not quite at true real-time speed of > 20 FPS, but with a faster GPU and more optimization we could easily get there.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to perform object detection with PyTorch and pre-trained networks. You gained experience applying object detection with three popular networks:
- Faster R-CNN with ResNet50 backbone
- Faster R-CNN with MobileNet backbone
- RetinaNet with ResNet50 backbone
When it comes to both accuracy and detecting small objects, Faster R-CNN will perform very well. However, that accuracy comes at a cost — Faster R-CNN models tend to be much slower than Single Shot Detectors (SSDs) and YOLO.
To help speed up the Faster R-CNN architecture, we can swap out the computationally expensive ResNet backhone for a lighter, more efficient (but less accurate) MobileNet backbone. Doing so will give you a boost in speed.
Otherwise, RetinaNet is a nice compromise between speed and accuracy.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.