
Optical character recognition, or OCR for short, is used to describe algorithms and techniques (both electronic and mechanical) to convert images of text to machine-encoded text. We typically think of OCR in terms of software. Namely, these are systems that:
- Accept an input image (scanned, photographed, or computer-generated)
- Automatically detect the text and “read” it as a human would
- Convert the text to a machine-readable format so that it can be searched, indexed, and processed within the scope of a larger computer vision system

What is Optical Character Recognition (OCR)?
However, OCR systems can also be mechanical and physical. For example, you may be familiar with electronic pencils that automatically scan your handwriting as you write. Once you are done writing, you connect the pen to your computer (Universal Serial Bus (USB), Bluetooth, or otherwise). The OCR software then analyzes the movements and images recorded by your smartpen, resulting in machine-readable text.
If you’ve used any OCR system, whether it be software such as Tesseract or a physical OCR device, you know that OCR systems are far from accurate. But why is that? On the surface, OCR is such a simple idea, arguably the simplest in the entire computer vision field. Take an image of text and convert it to machine-readable text for a piece of software to act upon. However, since the inception of the computer vision field in the 1960s (Papert, 1966), researchers have struggled immensely to create generalized OCR systems that work in generalized use cases.
The simple fact is that OCR is hard.
There are so many nuances in how humans communicate via writing — we have all the problems of natural language processing (NLP), compounded with the fact that computer vision systems will never obtain 100% accuracy when reading a piece of text from an image. There are too many variables in terms of noise, writing style, image quality, etc. We are a long way from solving OCR.
If OCR had already been solved, this tutorial wouldn’t exist — your first Google search would have taken you to the package you would have needed to confidently and accurately apply OCR to your projects with little effort. But that’s not the world in which we live. While we are getting better at solving OCR problems, it still takes a skilled practitioner to understand how to operate existing OCR tools. That is the reason why this tutorial exists — and I can’t wait to embark on this journey with you.
Learning Objectives
In this tutorial, you will:
- Learn what OCR is
- Receive a brief history lesson on OCR
- Discover common, real-world applications of OCR
- Learn the difference between OCR and orientation and script detection (OSD), a common component inside many state-of-the-art OCR engines
- Discover the importance of image pre-processing and post-processing to improve OCR results
To learn what OCR is and become familiar with OCR tools, just keep reading.
An Introduction to OCR
We’ll begin this section with a brief history of OCR, including how this computer vision subfield came to be. Next, we’ll review some real-world applications of OCR (some of which we’ll be building inside the tutorials). We’ll then briefly discuss the concept of OSD, an essential component of any OCR system. The last part of this tutorial will introduce the concept of image pre-processing and OCR result post-processing, two common techniques used to improve OCR accuracy.
A Brief History of OCR
Early OCR technologies were purely mechanical, dating back to 1914 when “Emanuel Goldberg developed a machine that could read characters and then converted them into standard telegraph code” (Dhavale, 2017, p. 91). Goldberg continued his research into the 1920s and 1930s when he developed a system that searched microfilm (scaled-down documents, typically films, newspapers, journals, etc.) for characters and then OCR’d them.
In 1974, Ray Kurzweil and Kurzweil Computer Products, Inc. continued developing OCR systems, mainly focusing on creating a “reading machine for the blind.” Kurzweil’s work caught industry leader Xerox’s attention, who wished to commercialize the software further and develop OCR applications for document understanding.
Hewlett-Packard (HP) Labs started working on Tesseract in the 1980s. HP’s work was then open-sourced in 2005, quickly becoming the world’s most popular OCR engine. The Tesseract library is very likely the reason you are reading this tutorial now.
As deep learning revolutionized the field of computer vision (as well as nearly every other field of computer science) in the 2010s, OCR accuracy was given a tremendous boost from specialized architectures called long short-term memory (LSTM) networks.
Now, in the 2020s, we’re seeing how OCR has become increasingly commercialized by tech giants such as Google, Microsoft, and Amazon, to name a few. We exist in a fantastic time in the computer science field — never before have we had such powerful and accurate OCR systems. But the fact remains that these OCR engines still take a knowledgeable computer vision practitioner to operate. This text will teach you how to do precisely that.
Applications of OCR
There are many applications of OCR, the original of which was to create reading machines for the blind (Schantz, 1982). OCR applications have evolved significantly since then, including (but not limited to):
- Automatic license/number plate recognition (ALPR/ANPR)
- Traffic sign recognition
- Analyzing and defeating CAPTCHAs (Completely Automated Public Turing tests to tell Computers and Humans Apart) on websites
- Extracting information from business cards
- Automatically reading the machine-readable zone (MRZ) and other relevant parts of a passport
- Parsing the routing number, account number, and currency amount from a bank check
- Understanding text in natural scenes such as the photos captured from your smartphone
If there is text in an input image, we can very likely apply OCR to it — we need to know which techniques to utilize!
Orientation and Script Detection
Before we can have a detailed discussion on OCR, we need to briefly introduce the orientation and script detection (OSD), which we’ll cover in more detail in a future tutorial. If OCR is the process of taking an input image and returning the text in both human-readable and machine-readable formats, then OSD is the process of analyzing the image for text meta-data, specifically the orientation and the script/writing style.
The text’s orientation is the angle (in degrees) of the text in an input image. To obtain higher OCR accuracy, we may need to apply OSD to determine the text orientation, correct it, and then apply OCR.
Script and writing style refers to a set of characters and symbols used for written and typed communication. Most of us are familiar with Latin characters, which make up the characters and symbols used by many European and Western countries; however, there are many other forms of writing styles that are widely used, including Arabic, Hebrew, Chinese, etc. Latin characters are very different from Arabic, which is, in turn, distinct from Kanji, a system of Japanese writing using Chinese characters.
Any rules, heuristics, or assumptions an OCR system can make regarding a particular script or writing system will make the OCR engine that much more accurate when applied to a given script. Therefore, we may use OSD information as a precursor to improving OCR accuracy.
The Importance of Pre-Processing and Post-Processing
Many OCR engines (whether Tesseract or cloud-based APIs) will be more accurate if you can apply computer vision and image processing techniques to clean up your images.
For example, consider Figure 1. As humans, we can see the text “12-14” in Figure 1 (top-left), but if you were to run that same image through the Tesseract OCR engine, you would get “12:04” (bottom).
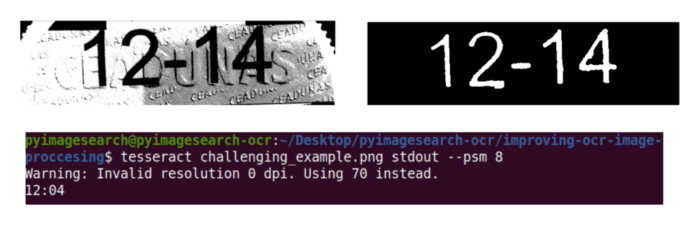
However, if you were to apply some basic image processing operations such as thresholding, distance transforms, and morphological operations, you would end up with a clear image (Figure 1, top-right). When we pass the cleaned-up image through Tesseract, we correctly obtain the text “12-14.”
One of the most common mistakes I see computer vision and deep learning practitioners make is that they assume the OCR engine they are utilizing is also a generalized image processor capable of automatically cleaning up their images. Thanks to advances in the Tesseract OCR engine, OCR systems can conduct automatic segmentation and page analysis; however, these systems are far from being as intelligent as humans, who can near-instantly parse text from complex backgrounds.
OCR engines should be treated like 4th graders who are capable of reading text and need a nudge in the right direction quite often.
As a computer vision and deep learning practitioner, it’s your responsibility to use your CV/DL knowledge to assist the OCR engines. Keep in mind that it’s far easier for an OCR system to recognize a piece of text if it is properly cleaned and segmented first.
You should also consider post-processing your OCR’d text. OCR systems will never be 100% accurate, so you should assume there will be some mistakes. To help with this, ask yourself if it’s possible to apply rules and heuristics. Some example questions to consider:
- Can I apply automatic spellchecking to correct misspelled words from the OCR process?
- Can I utilize regular expressions to determine patterns in my output OCR data and extract only the information I am interested in (i.e., dates or prices from an invoice)?
- Can I leverage my domain knowledge to create heuristics that automatically correct OCR’d text for me?
Creating a successful OCR application is part science, part art. Let’s shift gears and talk about the tools you will need to be a successful OCR practitioner.
Tools, Libraries, and Packages for OCR
Before building our optical character recognition (OCR) projects, we first need to become familiar with the OCR tools available to us.
This portion of the tutorial will review the primary OCR engines, software, and APIs we’ll utilize throughout this lesson. These tools will serve as the foundations we need to build our OCR projects.
Discovering OCR tools and APIs
In the rest of this tutorial, you will:
- Discover the Tesseract OCR engine, the most popular OCR package in the world
- Learn how Python and the
pytesseractlibrary can make an inference with Tesseract - Understand the impact computer vision and image processing algorithms can have on the accuracy of OCR
- Discover cloud-based APIs that can be used for OCR
OCR Tools and Libraries
We’ll start this section of the tutorial with a brief discussion of the Tesseract OCR engine, an OCR package that was originally developed in the 1980s, undergone many revisions and updates since, and is now the most popular OCR system in the world.
Of course, Tesseract isn’t all that helpful if it can only be used as a command line tool — we need APIs for our programming languages to interface with it. Luckily, there are Tesseract bindings available for nearly every popular programming language (Java, C/C++, PHP, etc.), but we’ll be using the Python programming language.
Not only is Python an easy (and forgiving) language to code in, but it’s also used by many computer vision and deep learning practitioners, lending itself nicely to OCR. To interact with the Tesseract OCR engine via Python, we’ll be using pytesseract. However, Tesseract and pytesseract are not enough by themselves. OCR accuracy tends to be heavily dependent on how well we can “clean up” our input images, making it easier for Tesseract to OCR them.
To clean up and pre-process our images, we’ll use OpenCV, the de facto standard library for computer vision and image processing. We’ll also use machine learning and deep learning Python libraries, including scikit-learn, scikit-image, Keras, TensorFlow, etc., to train our custom OCR models. Finally, we’ll briefly review cloud-based OCR APIs that we’ll cover later in this tutorial.
Tesseract
The Tesseract OCR engine was first developed as closed source software by Hewlett-Packard (HP) Labs in the 1980s. HP used Tesseract for their OCR projects with the majority of the Tesseract software written in C. However, when Tesseract was initially developed, very little was done to update the software, patch it, or include new state-of-the-art OCR algorithms. Tesseract, while still being utilized, essentially sat dormant until it was open-sourced in 2005. Google then started sponsoring the development of Tesseract in 2006. You may recognize the Tesseract logo in Figure 2.
The combination of legacy Tesseract users and Google’s sponsorship brought new life into the project in the late 2000s, allowing the OCR software to be updated, patched, and new features added. The most prominent new feature came in October 2018 when Tesseract v4 was released, including a new deep learning OCR engine based on long short-term memory (LSTM) networks. The new LSTM engine provided significant accuracy gains, making it possible to accurately OCR text, even under poor, non-optimal conditions.
Additionally, the new LSTM engine was trained in over 123 languages, making it easier to OCR text in languages other than English (including script-based languages, such as Chinese, Arabic, etc.). Tesseract has long been the de facto standard for open-source OCR, and with the v4 release, we’re now seeing even more computer vision developers using the tool. If you’re interested in learning how to apply OCR to your projects, you need to know how to operate the Tesseract OCR engine.
Python
We’ll be using the Python programming language for all examples in this tutorial. Python is an easy language to learn. It’s also the most widely used language for computer vision, machine learning, and deep learning — meaning that any additional computer vision/deep learning functionality we need is only an import statement way. Since OCR is, by nature, a computer vision problem, using the Python programming language is a natural fit.
PyTesseract
PyTesseract is a Python package developed by Matthias Lee, a PhD in computer science, who focuses on software engineering performance. The PyTesseract library is a Python package that interfaces with the tesseract command line binary. Using only one or two function calls, we can easily apply Tesseract OCR to our OCR projects.
OpenCV
To improve our OCR accuracy, we’ll need to utilize computer vision and image processing to “clean up” our input image, making it easier for Tesseract to correctly OCR the text in the image.
To facilitate our computer vision and image processing operations, we’ll use the OpenCV library, the de facto standard for computer vision and image processing. The OpenCV library provides Python bindings, making it a natural fit into our OCR ecosystem. The logo for OpenCV is shown in Figure 3.
Keras, TensorFlow, and scikit-learn
There will be times when applying basic computer vision and image processing operations is insufficient to obtain sufficient OCR accuracy. When that time comes, we’ll need to apply machine learning and deep learning.
The scikit-learn library is the standard package used when training machine learning models with Python. Keras and TensorFlow give us all the power of deep learning in an easy-to-use API. You can see logos for each of these tools in Figure 4.

Cloud OCR APIs
There will be times when simply no amount of image processing/cleanup and combination of Tesseract options will give us accurate OCR results:
- Perhaps Tesseract was never trained on the fonts in your input image
- Perhaps no pre-trained “off-the-shelf” models can correctly localize text in your image
- Or maybe it would take too much effort to develop a custom OCR pipeline, and you’re instead looking for a shortcut
When those types of scenarios present themselves, you should consider using cloud-based OCR APIs such as Microsoft Azure Cognitive Services, Amazon Rekognition, and the Google Cloud Platform (GCP) API. The logos for popular APIs are shown in Figure 5. These APIs are trained on massive text datasets, potentially allowing you to accurately OCR complex images with a fraction of the effort.

The downsides are, of course:
- These are paid APIs, meaning that you need to pay to use them
- An internet connection is required to submit images to them and retrieve the results
- The network connection implies there will be latency between submitting the image and obtaining the OCR result, making it potentially unusable for real-time applications
- You don’t “own” the entire OCR pipeline. You will be locked into the vendor you are using for OCR.
That said, these OCR APIs can be incredibly useful when developing your OCR projects, so we’ll be covering them in a later tutorial.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you were introduced to the field of optical character recognition (OCR). From my experience, I can attest that OCR seems easy on the surface but is most definitely a challenging domain when you need to develop a working system. Keep in mind that the field of computer vision has existed for over 50 years, yet researchers have yet to create generalized OCR systems that are highly accurate. We’re certainly getting closer with prominent cloud service provider APIs, but we have a long way to go.
You also received an overview of the tools, programming languages, and libraries common in OCR. If you feel overwhelmed by the number of tools available to you, don’t worry, we’ll methodically build on each one, stair-stepping your knowledge from an OCR beginner to an experienced OCR practitioner who is confident applying OCR to your projects.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.