
In this post, I interview Vince DiMascio, CIO/CTO of Berry Appleman & Leiden (BAL), a law firm specializing in corporate immigration.
BAL is using computer vision, machine learning, and artificial intelligence to automatically classify immigration documents, thus helping expedite the arduous task of gathering and validating documents.
Recently, Vince, along with Dr. Tim Oates (my former PhD advisor) published a paper on their work, Immigration Document Classification and Automated Response Generation. This work was a joint effort between BAL and Synaptiq, which Dr. Oates co-founded with his partner, Stephen Sklarew.
Today we’re going to sit down with Vince and discuss their paper, including how their techniques can help immigration teams be more efficient, run with less overhead, and ensure their clients are successful.
An interview with Vince DiMascio, CIO and CTO at Berry Appleman & Leiden (BAL)
Adrian: Hi, Vince! Thank you for being here on the PyImageSearch blog. I know you’re very busy as the CIO of Berry Appleman & Leiden (BAL). We all appreciate you taking the time to be here.
Vince: Thank you for having me. It’s great to chat with you, Adrian.
Adrian: Can you tell us a bit about yourself and your role at BAL?
Vince: I’m the CIO and CTO for BAL. We are a global corporate immigration law firm. We’ve been around for 40 years. Technology has always been central to how we operate and serve our clients.
I joined the firm about five years ago to set the technology strategy and lead the teams to execute it. In my role, I handle anything and everything related to technology. Those duties range from desktop support to Artificial Intelligence (AI) and automation, professional services teams, and a digital products organization that handles the development and introduction of cutting edge products.
Adrian: I’m curious, given that you work for a law firm, how did you first become interested in computer vision and machine learning?
Vince: I happened to be lucky enough to bring the right skills to the right place at the right time.
Before BAL, I was in consulting. I was frequently involved with law firms’ and legal departments’ use of technology. I started looking at machine learning when the federal rules changed in the early 2000s, really giving birth to e-discovery. Back then, we were using machine learning to do things like concept clustering, natural language processing, and even predictive coding to find relevant documents and expedite discovery. That work set me on course to help businesses by responsibly applying cutting edge technology in heavily regulated and high stakes environments.
When I came to BAL, we set our 2020 strategy. We knew we could do a lot for our clients by using data well, applying machine learning, and bringing those together with great design to deliver unmatched products, insights, and experiences. Like litigation, immigration law can be paper-heavy, so I knew we could make an impact by handling unstructured data, optimizing legal workflows with technology, and leveraging AI. That includes developing and operationalizing systems that use computer vision and machine learning.
Adrian: How did you find out about PyImageSearch?
Vince: When we started looking at this as an opportunity, that’s when I found PyImageSearch. I was looking for ways to classify images of documents to sort them out and route them down different workflow paths, including extracting information. For example, a passport could go down a certain path and have information extracted from its machine readable zone area. But a government form might go down a different path, to have a different extraction approach. My searching led me to PyImageSearch, a treasure trove of information, code, and community around computer vision. It helped us as we continued to look at how we could leverage CV internally with BAL. We’ve been subscribers to the PyImageSearch community ever since.

Adrian: What was your experience like working with PyImageSearch’s consulting partner, Synaptiq? Why did you choose to work with them instead of using packaged Artificial Intelligence (AI) and Robotic Processing Automation (RPA) solutions?
Vince: The experience has been outstanding, and that’s why we remain a client. Synaptiq works as partners with us rather than as a traditional vendor. They focus on understanding the problems and opportunities we’re facing. They team up with our legal, data, and products staff to develop solutions with us that we can drive together. We chose them rather than leveraging packaged solutions. We found that, while packaged AI and RPA are good at a lot of things, they’re not great in our focused areas. And we need to be the best at that narrower set of things that we do. Since we’re in uncharted territory on the things we’re doing, it sometimes makes sense to build. We do leverage packaged solutions where appropriate for commodity work. We engineer it ourselves in the areas where we need to deliver unique, exceptional value through new technology.
When you’re doing that, it’s essential to team up with a partner who has years of data science, machine learning, and computer vision skills across various industries and determine which model to use, which approach to follow, or what framework. Beyond that, we need to decide how we structure our teams, deliver the model, and operationalize it. It’s one thing to do it in a lab. We see that lab model everywhere, especially these days in legal. But to truly bring AI into a business and operationalize it, you need strong business alignment and the right technology capabilities.
Adrian: You and Synaptiq recently published a paper on using computer vision and OCR to automatically process and prepare supporting documents for the United States visa petitions presented at the IEEE / MLLD 2020 International Workshop on Mining and Learning in the Legal Domain in November. Can you explain what MLLD is and why it’s important for legal professionals with scientific backgrounds?
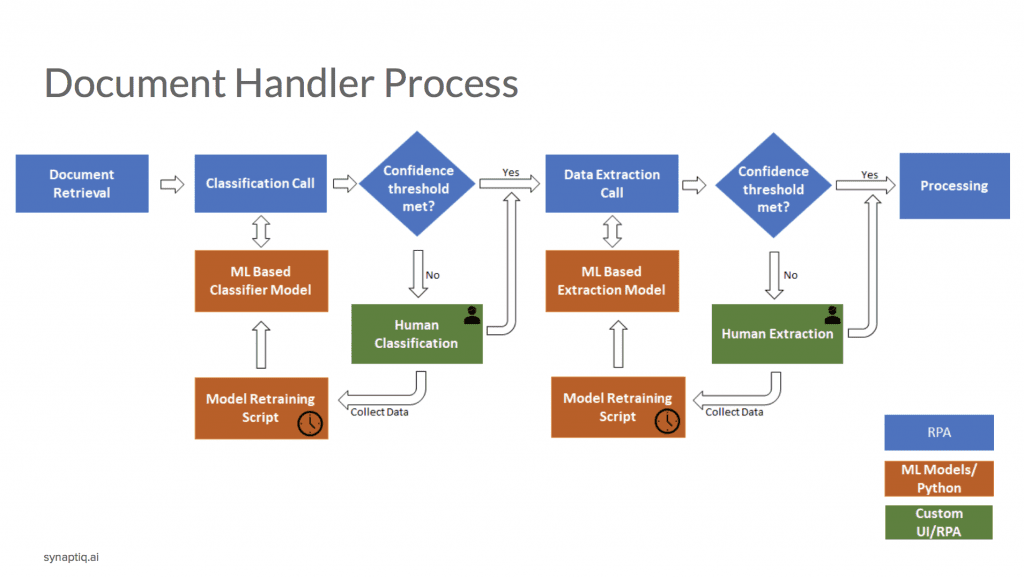
Vince: First, I’d like to clarify what the project is. The system provides our clients with a second set of eyes to help with some of the rote work performed in connection with immigration case processing. The system doesn’t independently automatically process and prepare documents. It enhances quality and turnaround time by classifying documents we receive in the mail. Then it reads those documents to identify what’s being requested. A final step passes that information to a system that works like a copy-paste action to create a draft that a legal professional can use to start the legal work.
This is important for legal professionals, so it was selected to be presented at IEEE-MLLD. It’s truly machine learning, and it’s applicable beyond immigration law. One example of another context is in handling a third-party subpoena. In that context, one party receives a request for documents. The third-party will carefully read the request, identify what’s being requested, and often serve written objections to those requests. So in a similar workflow, this technology would help such third parties see that they’ve identified and addressed what’s being requested, using approved standard form templates and content.
Adrian: What is the typical sequence of events when a prospective employee applies for a U.S. work visa? I imagine a lot of documents are generated and that there is an extensive paper trail.
Vince: The process can be paper-intensive, which is why it’s important to have high performing accurate machine learning systems that can handle documents and document images in ways that go well beyond OCR, and that can evolve. I’m not an attorney, and the process varies to some extent, depending on the visa type and circumstances. I think of the process in a few phases: intake, preparation, filing, and decision.
First, there’s an “intake” process where you collect the materials you’ll need to file a petition. This is a range of documents and forms, some of which are collected electronically as PDF, Word, or image files. When you have the material you need, you move into the “prepare” phase, where you fill out various forms, some online, some as PDF files. In this phase, you assemble the information into a particular filing order. When the materials are ready, you move to the “filing” phase, where you perform a final review and then file it with the agency, usually with a check for filing fees. At that point, it’s with the government, and you start monitoring the status of the filing. That’s when the United States Citizenship and Immigration Services (USCIS) might send a Request for Evidence (RFE), which is the type of document we trained machine learning systems to classify and read. USCIS will send RFEs when they don’t have enough information to decide the petition. So if you receive an RFE, you’ll need to address it. Eventually, you end up at the “decision” phase, where you get a decision from USCIS.
Adrian: What is an RFE, and how commonplace is this with each job candidate?
Vince: An RFE is a Request for Evidence, which is a request for additional information that the government wants from the foreign national to determine if the application is approved or not. It could be just a missing document, or it could be something that takes more effort to respond to.
Adrian: Tell us about how you came up with the idea of using computer vision and OCR with this process?
Vince: This idea came from our innovation pipeline. We have functions dedicated to defining, piloting, and scaling AI use cases. Unlike the “lab” model we’ve seen repeatedly fail across industries, we embed innovation and AI directly in our business, so we’re aligned with our clients’ needs. We have a formal innovation program where we invite employees and leaders at every level to join and take part in creating new solutions to firm administrative and client challenges alike. Our technical and products teams review and evaluate the ideas in terms of viability and value. We use product management methodology to back into the actual problem and see if we can generalize it to the greatest extent possible. Then we sprint and iterate. This original idea came through that pipeline, and once we evaluated it as a concept, it made sense to do it.
Adrian: You mentioned different phases: Intake, Preparation, Filing, and feeding various documents into those processes. So the system you are developing can differentiate between the document types?
Vince: That’s a good question. On our side, we receive material through a variety of secure channels. The materials are often PDF files, scanned images, or a picture taken from a mobile device. We get an image of this document; it’s fixed, it’s a grid of pixels, and we need to turn that into information we can use. We have to transcribe that image into text information and sometimes put it into a government form. We use novel automated methods to provide high-quality data services and an exceptional experience to our clients. As a simple example, when a foreign national uploads an image of a passport, they don’t have to type in the text. It’s extracted automatically and placed into fields for them. We have automation like that throughout the journey to enhance quality and experience.
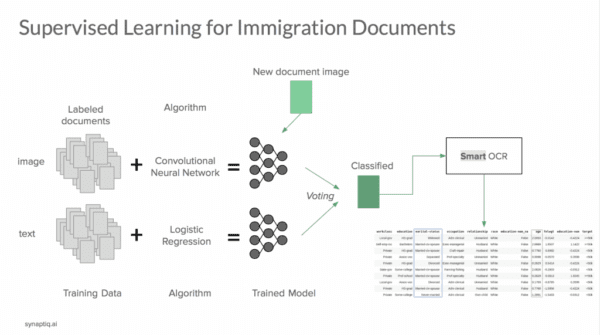
Adrian: Can you give us a high-level overview of the system you and Synaptiq developed?
Vince: We created two systems that work well independently and together.
The first system classifies document images common in U.S. work visa petitions. So you can submit a document image to our service, and the service will tell you the type of document you submitted. For example, a passport, a birth certificate, a certain government form, or an RFE. That system alone helps label or sort documents or priming a downstream text extraction system to know what to look for and where to look when extracting the relevant text.
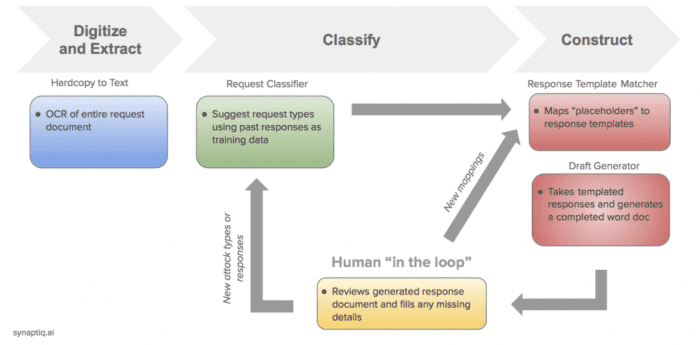
The second system reads RFEs, which are the letters I mentioned earlier. RFEs are issued by the USCIS when it needs more information to decide on an application. You can post the RFE letter to this second system, and it will read the letter and then respond with a list of what additional information the USCIS is asking for in the RFE. Used together, we can give our people and our clients an extra set of eyes to drive quality throughout the paper handling process. This also allows us to catalog the types of government requests and what combination of factors is most likely to give rise to them.
The text extraction components embedded in the classifier and the RFE reader are the systems’ unsung heroes. Machine learning techniques, such as those used to remove noise, deskew, or leverage custom language models to get text extraction right, are critical to achieving high-quality results. All of that is available in PyImageSearch books for understanding, code for delivering, and VMs to run it.
Adrian: On the initial application processing, how accurate is the first pass, and what type of QC is recommended for the attorneys to conduct?
Vince: It’s really important to reiterate that nothing works independently and autonomously here. We have humans in the loop on every step of this, given the stakes. Empirical results suggest that our approach achieves considerable accuracy.
Our attorneys aren’t QCing. They’re doing the legal work. The systems are double-checking materials handled and generated in connection with that work, so we add another layer of review and the second set of hands to the operation. It gives our people “superpowers.”
Adrian: During the initial application processing, does your method gather data and fill out forms on the attorney’s behalf, or does it also detect potential issues or points of contention (for example, would it flag if a passport is set to expire or if there appears to be a gap in the individual’s work authorization?)
Vince: That’s a great question because this solution isn’t filling out forms. First, it’s classifying documents. If it finds an RFE, it then can read the text from the letter, interpret the text, and select a specifically curated form template for the attorney to use. It can also merge some data into the document from our case management system, just like Microsoft Word or Google Docs does, but it’s not drafting a response. We have other data health mechanisms in the filing process that address the date-related issues you’re referencing.
Adrian: Can your solution be used on all RFEs, or does it need to be trained on the specific RFE type first?
Vince: It’s flexible. An RFE typically is based on a template USCIS provides its officers as a starting point. The officers customize the RFE based on the application. So we maintain a table of RFE reasons for each type of RFE, and when we send the letter to the system, we also tell the system what kind of visa it is. And it uses that information to determine which set of known reasons to use in the language model. Again, we could just as easily load a table of common subpoena requests and their classifications and use it for a subpoena response process.
Adrian: For the more complex RFE, such as the specialty occupation RFE, how does this generate the initial response for the lawyer to review and edit? What documents is it pulling from to counter the RFE? And for this RFE type specifically, how “complete” is the first draft of the response to the human attorneys?
Vince: Just like USCIS, we maintain model documents, which are standard form templates that have placeholders for address, salutation, formatting, standard paragraphs, and that sort of thing. There’s a standard mail-merge to insert data such as the client company name, foreign national name, etc., that’s been around for a long time. That’s all there is related to the use of templates. The attorney authors the response’s substance. It’s just creating a skeleton from where the human starts regarding the completeness. You can think of it as a more “enhanced draft,” along with a list of what’s being requested.
Adrian: How does the machine taking care of the repetitive administrative work allow the attorney to focus on more time-intensive and specialized legal work for their client?
Vince: The system adds additional reviewers to drive the work quality. And so, the real business value of this tool is a greater, perhaps more robust response than you might get from another firm without a subsequent set of eyes to catch every nuance. We can also drive analytics that inform the legal strategy underlying the response language. The goal is to create a virtuous cycle in which we constantly improve our responses to ever-shifting government requests and do so in the most efficient way possible. Then we merge data from our databases into the templates, which is standard practice.
Adrian: How does your solution help BAL, and more importantly, how does it help your clients be more successful?
Vince: Given that it’s enhancing the quality of our work specifically around RFEs and on the intake side, it allows us to capture and label more information to see the trends in the attacks for a particular occupation, for particular industries, or more broadly. This helps us deliver valuable talent management insights to our clients.
Adrian: What are your next steps with the project? Are you continuing to develop and refine the system?
Vince: We’re going to keep running it, training it, and finding ways to deliver value to our clients with it. The idea is, if we know everything about RFE volume, what’s in the letters, what if there’s seasonality or spikes, etc., we can have that information at hand right away to advise our clients. Our clients want data-driven insights as part of our services. The days of anecdotes are in the past.
Adrian: Is there any advice you would give to someone who wants to follow in your footsteps, learn computer vision and deep learning, and then publish a paper or do work in the legal space?
Vince: Pick a project that you care about and start building. Sign up for PyImageSearch, and go through the training available there, get the books, sign up for the community, begin to collaborate there. It’s a tremendously valuable set of resources and a large active community. The resources are accelerators to understanding, developing, and deploying these capabilities. And documents are probably the most boring chapters. There are lessons and code about handling streaming video, photos, license plates, wild animals, detective surveillance to find out who is stealing beer from your refrigerator. It’s amazing, accessible, practical, and fun. Find something that has business value, be scientific about executing it, and take the time to write it down. Applied AI is still rare, despite all the hype you hear about it, so if you build something and use it, your chances of getting accepted to a major and prestigious conference like this may be better than you think.
Adrian: What’s next for BAL and AI in 2021?
Vince: It’s about pushing the envelope and continuing to lead our industry in how we deliver technology, experience, and insights for our clients. That means embedding intelligence everywhere as we evolve our AI-first operating model. And to do that, we’re growing our technology, product, and design teams to maintain the distance we have from our competitors.
An interesting area of pursuit is leveraging AI without undermining the attorney-client relationship’s importance. Human interaction is fundamental to the work we do. So we enhance the quality and speed with which we help our clients answer questions, queries, problem resolution, and see that data interaction occurs, so it’s not an impediment. We also use AI to enable our professionals to deliver legal services than any other firm better.
BAL has always led the industry in terms of technology innovation. For a few examples, just this year, we were awarded Best Legal Solution for our Cobalt digital platform, an IDG CIO 100 award for our tech teams, and a Business Transformation 150 award from Constellation Research for our work in innovating. We will continue to deliver cutting-edge technology-enabled services and digital products that globally power human achievement.
Adrian: If a PyImageSearch reader wants to go through the paper, where can they find it?
Vince: You can download a PDF of the paper from arXiv here: https://arxiv.org/abs/2010.01997
Adrian: Excellent. Congrats again on the paper, and thank you for taking the time to chat with me today. I look forward to keeping in touch.
Vince: Thank you, Adrian, me too. Looking forward to chatting with you again soon.
Summary
In this blog post, we interviewed Vince DiMascio, CIO/CTO of Berry Appleman & Leiden (BAL), a law firm specializing in corporate immigration.
BAL has recently worked with Synaptiq, an artificial intelligence consulting company cofounded by my former PhD advisor, Dr. Tim Oates.
Together, BAL and Synaptiq have published a paper on automatic immigration document classification, a system that allows immigration firms to be more efficient when responding to Request for Evidence (RFEs) from the US government.
Their system is a success, demonstrating how AI can be applied to nearly every field in the world.
If you’re interested in working with Synaptiq and seeing how artificial intelligence can be leveraged to make your company more efficient and profitable, just fill out this form for a free initial consultation.
PyImageSearch Consulting Services
I’ve teamed up with my former PhD advisor, Dr. Tim Oates, and Stephen Sklarew, a product and technology executive consultant, to offer PyImageSearch Consulting for Computer Vision, Deep Learning, and Artificial Intelligence through Synaptiq.
Founded in 2015, Synaptiq is a full-scale artificial intelligence consultancy with over 40 clients in more than 20 sectors worldwide. Our seasoned team of experts, including 16 Data Scientists (6 with PhDs), partner directly with each client to identify and deliver impactful solutions to real-world problems AI solves best.
If you are interested in working with Synaptiq, the consulting firm Vince DiMascio collaborated with on this solution (and PyImageSearch’s official consulting partner), use this link to tell us more about your project.
We look forward to hearing from you and learning more about your project.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.