
In this blog post, I interview computer vision and deep learning engineer, Anthony Lowhur. Anthony shares the algorithms and techniques that he used to build a computer vision and deep learning system capable of recognizing 10,000+ Yugioh trading cards.
I love Anthony’s project — and I wish I had it years ago.
When I was a kid, I loved to collect trading cards. I had binders and binders filled with baseball cards, basketball cards, football cards, Pokemon cards, etc. I even had Jurassic Park trading cards!
I cannot even begin to estimate the number of hours I spent organizing my cards, grouping them first by team, then by position, and finally in alphabetical order.
Then, when I was done, I would come up with a “new and better way” to sort the cards and start all over again. At a young age, I was exploring the algorithmic complexity where an eight-year-old can sort cards. At best, I was probably only O(N2), so I had quite a bit of room for improvement.
Anthony has taken card recognition to an entirely new level. Using your smartphone, you can snap a photo of a Yugioh trading card and instantly recognize it. Such an application is useful for:
- Collectors who want to quickly determine if a trading card is already in their collection
- Archivists who want to build databases of Yugioh cards, their attributes, hit points, damage, etc. (i.e., OCR the card after recognition)
- Yugioh players who want not only to recognize a card but also translate it as well (very useful if you cannot read Japanese but want to play with both English and Japanese cards at the same time, or vice versa).
Anthony built his Yugioh card recognition system using several computer vision and deep learning algorithms, including:
- Siamese networks
- Triplet loss
- Keypoint matching for final reranking (this is an especially clever trick that you’ll want to learn more about)
Join me as I sit down with Anthony and discuss his project.
To learn how to recognize Yugioh cards with computer vision and deep learning, just keep reading.
An interview with Anthony Lowhur – Recognizing 10,000 Yugioh Cards with Computer Vision and Deep Learning
Adrian: Welcome, Anthony! Thank you so much for being here. It’s a pleasure to have you on the PyImageSearch blog.
Anthony: Thank you for having me. It’s an honor to be here.
Adrian: Tell us a bit about yourself — where do you work and what is your job?
Anthony: I am currently a full-time computer vision (CV) and machine learning (ML) engineer not far from Washington DC, and I design and build Artificial Intelligence (AI) systems that would be used by clients. I actually graduated and got my bachelor’s from the university not too long ago, so I am still quite fresh in the industry.
Adrian: How did you first become interested in computer vision and deep learning?
Anthony: I was a high school student when I started to learn about a self-driving car competition known as the DARPA Grand Challenge. It is essentially a competition among different universities and research labs to build autonomous vehicles to race against each other in the desert. The car that won the competition was from Stanford University, lead by Sebastian Thrun.
Sebastian Thrun then went on to lead the Google X project in creating a self-driving car. The fact that something previously considered part of science fiction is now becoming a reality really inspired me, and I began learning about computer vision and deep learning after that. I began to do personal projects in CV and ML and began to conduct CV/ML research at REUs (Research Experiences for Undergraduates), and everything took off from there.
Adrian: You just finished developing a computer vision system that can automatically recognize 10,000+ Yugioh cards. Fantastic job! What inspired you to create such a system? And how can such a system help Yugioh players and card collectors?
Anthony: So there is a card game and TV series known as Yugioh that I watched when I was a child. It was something that held my heart to this day, and it brings out the nostalgia of sitting in front of the TV after returning from school each day.

I added the AI because making it was actually a prerequisite to an even bigger project, which was a Yugioh duel disk.
You can read more information about it here: I made a functional Duel Disk (powered by AI).
And here is a demo video:

In a nutshell, it’s a flashy device that allows you to duel each other a few feet away, which made its appearance in the TV series. I thought of this as a fun project to make and show to other Yugioh fans, which was enough to motivate me and continue the project until its prototype completion.
Other than for creating the duel disk, I have had people come to me saying that they were interested in having it either organize their Yugioh card collection or to power one of their app ideas. Though there are some imperfections, it is currently open-sourced on GitHub, so people have the chance to try it out.
Adrian: How did you build your dataset of Yugioh cards? And how many example images per card did you end up with?
Anthony: First, I had to extract our dataset. The card dataset was retrieved from an API. The full-size version of the cards was used: Yu-Gi-Oh! API Guide – YGOPRODECK.
The API was used to download all Yugioh cards (10,856 cards) onto our machine to turn them into a dataset.
However, the main problem is that most cards only contain one card art (and other cards with multiple card arts have card arts that are significantly different from each other). In a machine learning sense, essentially, there are over 10,000 classes where each of those classes contains only one image each.
This is a problem, as traditional deep learning methods would not do well on datasets with lower than a hundred images, let alone one image per class. And I was doing this for 10,000 classes.
As a result, I would have to use one-shot learning to tackle this problem. One-shot learning is a method that compares the similarity between two images rather than predicts a class.
Adrian: With essentially only one example image per card, you don’t have much to learn from a neural network. Did you apply any type of data augmentation? If so, what type of data augmentation did you use?
Anthony: While we are working with only one image per class, we want to see if we can get as much robustness from this model as we possibly can. As a result, we perform image augmentation to create multiple versions of each card art, but with subtle differences (brightness change, contrast change, shifting, etc.). This will give our network slightly more data to work with, allowing our model to generalize better.
Adrian: You now have a dataset of Yugioh cards on your disk. How did you go about choosing a deep learning model architecture?
Anthony: So originally, I experimented with a simple shallow network for the siamese network as a sort of benchmark to measure.
Not surprisingly, the network did not perform that well. The network was underfitting the training data I was giving it, so I thought about resolving that. Adding more layers to the network is one of the remedies to the solution, so I tried out Resnet101, a network widely known for its massive layer depth. That ended up being the architecture I needed as it performed significantly better and was obtaining my accuracy goal. Consequently, this has been the resulting main architecture.
Of course, if I later desire to make the inference time of a single image prediction faster, I could always resort to using a network with fewer layers like VGG16, though.
Adrian: You clearly did your homework here and knew that siamese networks were the best architecture choice for this project. Did you use standard “vanilla” siamese networks with image pairs? Or did you use triplets and triplet loss to train your network?
Anthony: Originally, I tried vanilla siamese networks that mainly used a pair of images to make comparisons, though its limitations started to show.
As a result, I researched other architectures, and I eventually discovered the triplet net. It mainly differs from siamese networks as it uses three images instead of two and uses a different loss function known as triplet loss. It was mainly able to manipulate distances between images using positive and negative anchors during the training process. Consequently, it was relatively quick to implement and just happen to be the resulting solution.
Adrian: At this point, you have a deep learning model that can either identify an input Yugioh card or be very close to returning the correct Yugioh card in the top-10 results. How did you improve accuracy further? Did you employ some sort of image re-ranking algorithm?
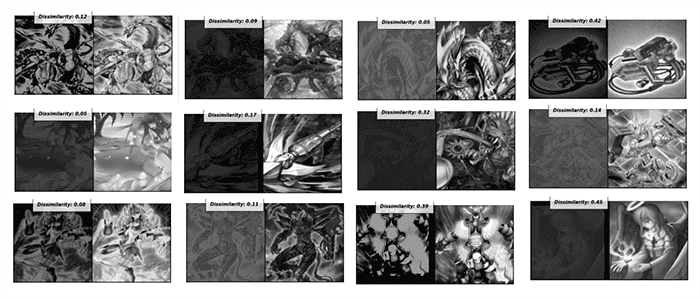
Anthony: So while triplet net made from resnet101 showed significant improvement, there seems to be some borderline cases in which it doesn’t predict the correct rank-1 class but came relatively close. To overcome this, the ORB (Oriented FAST and Rotated BRIEF) algorithm is used as support. ORB is an algorithm that searches for feature points within an image, so if two images are completely identical, the two images should have the same amount of feature points as each other.
This algorithm serves as a support to our one-shot learning method. As soon as our neural network generates a score on all 10,000 cards and ranks them, our ORB takes the top-N card ranking (e.g., top 50 cards) and calculates the number of ORB points on the images. The original similarity score and number of ORB points are then fed into a formula to obtain a final weighted similarity score. The weighted score of the top-N cards is compared, and the scores are rearranged to their final rankings.

Figure 3 shows a previously challenging edge case in which we compare two images of the top card (Dark Magician) in different contrast settings. Originally failed without ORB matching support, but considering the number of feature points in mind, we can get a more accurate ranking.
After some experimentation and tuning of certain values, I improved the number of correct predictions significantly.
Adrian: During your experimentation, you found that even small shifts/translations in your input images could cause significant drops in accuracy, implying that your Convolutional Neural Network (CNN) wasn’t handling translation well. How did you overcome this problem?
Anthony: It was indeed interesting and tricky to deal with this problem. Modern CNNs are in nature not shift-invariant, and that even small translations can confuse it. This is further emphasized by the fact we are dealing with very little data and that the algorithm was reliant on comparing feature maps together to make predictions.
- On the left side, the original image is compared with the same image but translated to the right (we jumped up by 0.71 points).
- In the middle image, the original image is compared with the same image but translated to the right and upward.
- In the right image, the original image is compared with the same image but translated to the right and upward.
This problem shows that our model would be very sensitive to slight misalignment and prevent our model from achieving its full potential.
My first approach was to simply augment the data by adding more translations in the data augmentation process. However, this was not enough, and I had to look into other methods.
As a result, I found some research that created the blur pooling algorithm for tackling a similar problem. Blur pooling is a method made to solve the problem of CNNs not being sift-invariant and applied at the end of every convolution layer.
Adrian: Your algorithm works by essentially generating a similarity score for all cards in your dataset. Did you encounter any speed or efficiency issues from comparing an input Yugioh card among 10,000+ cards?
Anthony: So, at this point, I have a model capable of generating similarity scores of every card at a reasonable accuracy. Now all I have to do is generate similarity scores for our input image and all the cards I wish to compare.
If I measure my model’s inference time, we can see that it takes around 0.12 seconds to pass a single image through our Triplet Resnet architecture along with an 0.08-second image preprocessing step. This does not sound bad on the surface, but remember that we have to do this on all cards we have in the dataset. The problem is that there are over 10,000 cards we will have to compare with the input and generate its score.
So if we take the number of seconds it takes to generate a similarity score and the total amount of cards (10,856) there are in the dataset, we get this:
(0.12+0.08) * 10,856 = 2171.2 s
2171.2/60 = 36.2 minutes
To predict what a single input image is, we would have to wait well over 30 minutes. This does not make our model practical to use as a result.
To solve this, I ended up pre-calculating the output convolutional feature maps of all 10,000 cards ahead of time and storing them in a dictionary. The great thing about dictionaries is that retrieving the pre-calculated feature maps from them would be constant time (O(1) time). So this would do a decent job scaling with the number of cards in the dataset.
So what happens is that after training, we iterate through over 10,000 cards, feed them into our triplet net to get the output convolution feature map, and store that in our dictionary. We just iterate through our new dictionary in the prediction phase instead of having our model performing forward propagation 10,000 times.
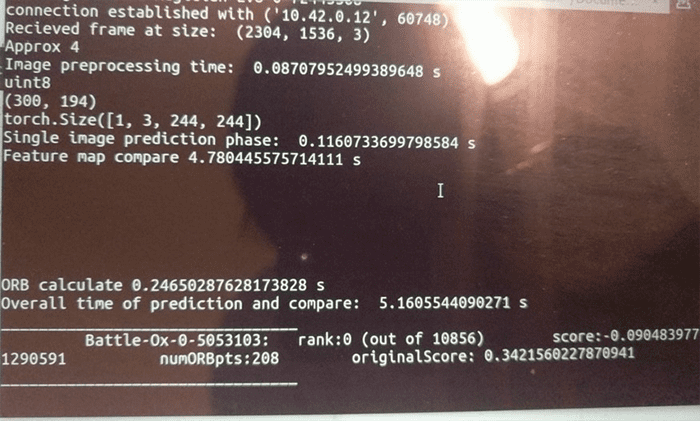
As a result, the previous single-image prediction time of 36 minutes has been significantly reduced by close to 5 seconds. This results in a more manageable model.
Adrian: How did you test and evaluate the accuracy of your Yugioh card recognition system?
Anthony: So overall, I was dealing with essentially two types of datasets.
I used a dataset for training, where official card art images were used from the ygoprodeck (dataset A) along with real-life photos of cards in the wild (dataset B), which were pictures of cards taken by a camera. Dataset B is essentially the ultimate testing dataset I used to succeed in the long run.
The AI/machine learning model was tested on real photos of cards (cards with and without sleeves). This is an example of dataset B.

These types of images are what I ultimately want my AI classifier to be successful in having a camera point down at your card and be able to recognize it.
However, since buying over 10,000 cards and taking pictures of them wasn’t a realistic scenario, I tried the next best thing: to test it on an online dataset of Yugioh cards and artificially add challenging modifications. Modifications included changing brightness, contrast, and shear to simulate Yugioh cards under different lighting/photo quality scenarios in real life (dataset A).
Here are some of the input images and the card art from the dataset:
And these are the final results:
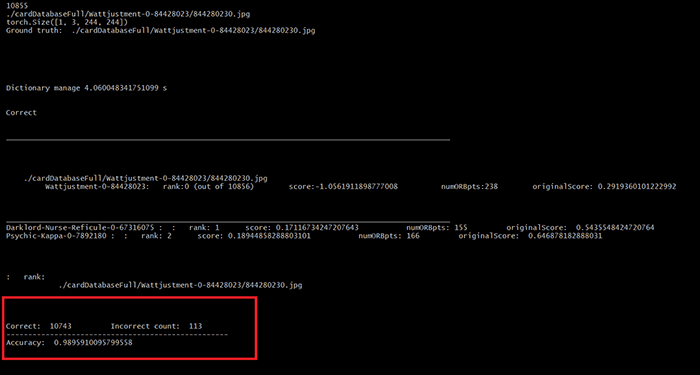
 99% accuracy with Yugioh card recognition.
99% accuracy with Yugioh card recognition. Here are a few examples of the card recognizer in action:

The AI classifier managed to achieve around 99% accuracy on all the cards in the game of Yugioh.
This was meant to be a quick project, so I am happy with the progress. I may try to see if I can gather more Yugioh cards and try to improve the system.
Adrian: What are the next steps for your project?
Anthony: There are definitely some imperfections that prevent my model from reaching its full potential.
The dataset used for training were official card art images from the ygoprodeck (dataset A) and not real-life photos of cards in the wild (dataset B), which are pictures of cards taken by a camera.
The 99% accuracy results were from training and testing on dataset A while the trained model was also tested on a handful of cards on dataset B. However, we don’t have a lot of data for dataset B to perform actual training on it or even mass-evaluation. This repo proves that our model can learn Yugioh cards through dataset A and has the potential to succeed with dataset B, which is the more realistic and natural set of images goal for our model. Setting up a data collection infrastructure to mass-collect image samples for dataset B would significantly advance this project and help confirm the model’s strength.
This program also does not have a proper object detector and just uses simple image processing methods (4 point transformation) to get the card’s bounding box and align it. Using a proper object detector like YOLO (you only look once) would be ideal, which would also help detect multiple demo cards.
More accurate and realistic image augmentation methods would help add glares, more natural lighting, and warps, which may help my model adapt from dataset A to even more real-life images.
Adrian: You’ve been a PyImageSearch reader and customer since 2017! Thank you for supporting PyImageSearch and me. What PyImageSearch books and courses do you own? And how did they help prepare you for this project’s completion?
Anthony: I currently own the Deep Learning for Computer Vision for Python bundle as well as the Raspberry Pi for Computer Vision book.
The time gap between reading your books and my attempt at this project is around 3 years, so there have been many things I have experienced and picked up from various sources along the way.
The PyImageSearch blog and Deep Learning for Computer Vision with Python bundle have been part of my immense journey, teaching me and strengthening my computer vision and deep learning fundamentals. Thanks to the bundle, I became aware of more architectures like Resnet and methods like transfer learning. They have helped form my base knowledge to dive into more advanced concepts that I would not have normally experienced.
By the time I started to tackle the Yugioh project, most of the concepts that I had applied in the project were second nature to me. They gave me the confidence to plan out and experiment with models until I received satisfying results.
Adrian: Would you recommend these books and courses to other budding developers, students, and researchers trying to learn computer vision, deep learning, and OpenCV?
Anthony: Certainly, books such as Deep Learning for Computer Vision with Python have a wealth of knowledge that can be used to jumpstart or strengthen anyone’s computer vision and machine learning journey. Its explanations for each topic, along with code examples, make it easy to follow along with giving a wide breadth of information. It has definitely strengthened my fundamentals in the field and helped me transition into being able to pick up even more advanced topics that I would not have learned otherwise.
Adrian: If a PyImageSearch reader wants to chat about your project, what is the best place to connect with you?
Anthony: The best way to contact me is through my email at antlowhur [at] yahoo [dot] com
You can also reach me on LinkedIn, Medium, and if you want to see more of my projects, check out my GitHub page.
Summary
Today we interviewed Anthony Lowhur, computer vision and deep learning engineer.
Anthony created a computer vision project capable of recognizing over 10,000 Yugioh trading cards.
His algorithm worked by:
- Using data augmentation to generate additional data samples for each Yugioh card
- Training a siamese network on the data
- Pre-computing feature maps and distances between cards (useful to achieve faster card recognition)
- Utilizing keypoint matching to rerank the top outputs from the siamese network model
Overall, his system was nearly 99% accurate!
To be notified when future tutorials and interviews are published here on PyImageSearch, simply enter your email address in the form below!

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.