In this tutorial, you will build a basic Automatic License/Number Plate Recognition (ANPR) system using OpenCV and Python.
An ANPR-specific dataset, preferably with plates from various countries and in different conditions, is essential for training robust license plate recognition systems, enabling the model to handle real-world diversity and complexities.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.

ANPR is one of the most requested topics here on the PyImageSearch blog.
I’ve covered it in detail inside the PyImageSearch Gurus course, and this blog post also appears as a chapter in my upcoming Optical Character Recognition book. If you enjoy the tutorial, you should definitely take a look at the book for more OCR educational content and case studies!
Automatic License/Number Plate Recognition systems come in all shapes and sizes:
- ANPR performed in controlled lighting conditions with predictable license plate types can use basic image processing techniques.
- More advanced ANPR systems utilize dedicated object detectors, such as HOG + Linear SVM, Faster R-CNN, SSDs, and YOLO, to localize license plates in images.
- State-of-the-art ANPR software utilizes Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) to aid in better OCR’ing of the text from the license plates themselves.
- And even more advanced ANPR systems use specialized neural network architectures to pre-process and clean images before they are OCR’d, thereby improving ANPR accuracy.
Automatic License/Number Plate Recognition is further complicated by the fact that it may need to operate in real time.
For example, suppose an ANPR system is mounted on a toll road. It needs to be able to detect the license plate of each car passing by, OCR the characters on the plate, and then store this information in a database so the owner of the vehicle can be billed for the toll.
Several compounding factors make ANPR incredibly challenging, including finding a dataset you can use to train a custom ANPR model! Large, robust ANPR datasets that are used to train state-of-the-art models are closely guarded and rarely (if ever) released publicly:
- These datasets contain sensitive identifying information related to the vehicle, driver, and location.
- ANPR datasets are tedious to curate, requiring an incredible investment of time and staff hours to annotate.
- ANPR contracts with local and federal governments tend to be highly competitive. Because of that, it’s often not the trained model that is valuable, but instead the dataset that a given company has curated.
For that reason, you’ll see ANPR companies acquired not for their ANPR system but for the data itself!
In this tutorial we’ll be building a basic Automatic License/Number Plate Recognition system. By the end of this guide, you’ll have a template/starting point to use when building your own ANPR projects.
To learn how to build a basic Automatic License Plate Recognition system with OpenCV and Python, just keep reading.
OpenCV: Automatic License/Number Plate Recognition (ANPR) with Python
My first run-in with ANPR was about six years ago.
After a grueling three-day marathon consulting project in Maryland, where it did nothing but rain the entire time, I hopped on I-95 to drive back to Connecticut to visit friends for the weekend.
It was a beautiful summer day. Sun shining. Not a cloud in the sky. A soft breeze blowing. Perfect. Of course, I had my windows down, my music turned up, and I had totally zoned out — not a care in the world.
I didn’t even notice when I drove past a small gray box discreetly positioned along the side of the highway.
Two weeks later … I got the speeding ticket in the mail.
Sure enough, I had unknowingly driven past a speed-trap camera doing 78 MPH in a 65 MPH zone.
That speeding camera caught me with my foot on the pedal, quite literally, and it had the pictures to prove it too. There is was, clear as day! You could see the license plate number on my old Honda Civic (before it got burnt to a crisp in an electrical fire.)
Now, here’s the ironic part. I knew exactly how their Automatic License/Number Plate Recognition system worked. I knew which image processing techniques the developers used to automatically localize my license plate in the image and extract the plate number via OCR.
In this tutorial, my goal is to teach you one of the quickest ways to build such an Automatic License/Number Plate Recognition system.
Using a bit of OpenCV, Python, and Tesseract OCR knowledge, you could help your homeowners’ association monitor cars that come and go from your neighborhood.
Or maybe you want to build a camera-based (radar-less) system that determines the speed of cars that drive by your house using a Raspberry Pi. If the car exceeds the speed limit, you can analyze the license plate, apply OCR to it, and log the license plate number to a database. Such a system could help reduce speeding violations and create better neighborhood safety.
In the first part of this tutorial, you’ll learn and define what Automatic License/Number Plate Recognition is. From there, we’ll review our project structure. I’ll then show you how to implement a basic Python class (aptly named PyImageSearchANPR) that will localize license plates in images and then OCR the characters. We’ll wrap up the tutorial by examining the results of our ANPR system.
What is Automatic License/Number Plate Recognition (ANPR/ALPR)?
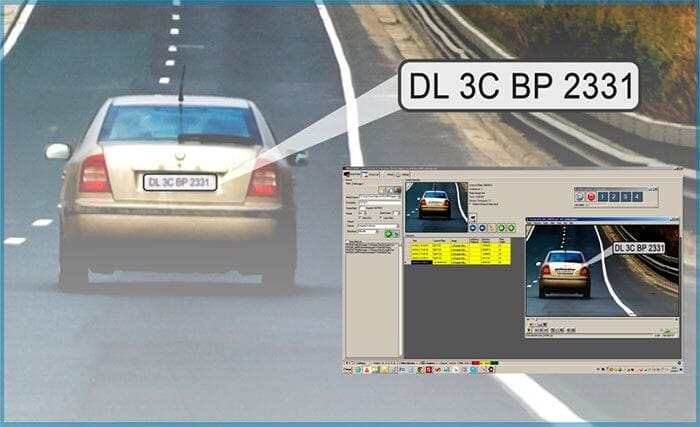
Automatic License/Number Plate Recognition (ANPR/ALPR) is a process involving the following steps:
- Step #1: Detect and localize a license plate in an input image/frame
- Step #2: Extract the characters from the license plate
- Step #3: Apply some form of Optical Character Recognition (OCR) to recognize the extracted characters
ANPR tends to be an extremely challenging subfield of computer vision, due to the vast diversity and assortment of license plate types across states and countries.
License plate recognition systems are further complicated by:
- Dynamic lighting conditions including reflections, shadows, and blurring
- Fast-moving vehicles
- Obstructions
Additionally, large and robust ANPR datasets for training/testing are difficult to obtain due to:
- These datasets containing sensitive, personal information, including time and location of a vehicle and its driver
- ANPR companies and government entities closely guarding these datasets as proprietary information
Therefore, the first part of an ANPR project is usually to collect data and amass enough example plates under various conditions.
So let’s assume we don’t have a license plate dataset (quality datasets are hard to come by). That rules out deep learning object detection, which means we’re going to have to exercise our traditional computer vision knowledge.
I agree that it would be nice if we had a trained object detection model, but today I want you to rise to the occasion.
Before long, we’ll be able to ditch the training wheels and consider working for a toll technology company, red-light camera integrator, speed ticketing system, or parking garage ticketing firm in which we need 99.97% accuracy.
Given these limitations, we’ll be building a basic ANPR system that you can use as a starting point for your own projects.
Configuring your OCR development environment
In this tutorial, we’ll use OpenCV, Tesseract, and PyTesseract to OCR number plates automatically. But before we get ahead of ourselves, let’s first learn how to install these packages.
I recommend installing Python virtual environments and OpenCV before moving forward.
We are going to use a combination of pip, virtualenv, and virtualenvwrapper. My pip install opencv tutorial will help you get up and running with these tools, as well as the OpenCV binaries installed in a Python virtual environment.
You will also need imutils and scikit-image for today’s tutorial. If you’re already familiar with Python virtual environments and the virtualenv + virtualenvwrapper tools, simply install the following packages via pip:
$ workon {your_env} # replace with the name of your Python virtual environment
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install scikit-image
Then it’s time to install Tesseract and its Python bindings. If you haven’t already installed Tesseract/PyTesseract software, please follow the instructions in the “How to install Tesseract 4” section of my blog post OpenCV OCR and text recognition with Tesseract. This will configure and confirm that Tesseract OCR and PyTesseract bindings are ready to go.
Note: Tesseract should be installed on your system (not in a virtual environment). MacOS users should NOT execute any system-level brew commands while they are inside a Python virtual environment. Please deactivate your virtual environment first. You can always workon your environment again to install more packages, such as PyTesseract.
Project structure
If you haven’t done so, go to the “Downloads” section and grab both the code and dataset for today’s tutorial. You’ll need to unzip the archive to find the following:
$ tree --dirsfirst . ├── license_plates │ ├── group1 │ │ ├── 001.jpg │ │ ├── 002.jpg │ │ ├── 003.jpg │ │ ├── 004.jpg │ │ └── 005.jpg │ └── group2 │ ├── 001.jpg │ ├── 002.jpg │ └── 003.jpg ├── pyimagesearch │ ├── anpr │ │ ├── __init__.py │ │ └── anpr.py │ └── __init__.py └── ocr_license_plate.py 5 directories, 12 files
The project folder contains:
license_platesanpr.pyPyImageSearchANPRclass responsible for localizing license/number plates and performing OCRocr_license_plate.pyPyImageSearchANPRclass to OCR entire groups of images
Now that we have the lay of the land, let’s walk through our two Python scripts, which locate and OCR groups of license/number plates and display the results.
Implementing ANPR/ALPR with OpenCV and Python
We’re ready to start implementing our Automatic License Plate Recognition script.
As I mentioned before, we’ll keep our code neat and organized using a Python class appropriately named PyImageSearchANPR. This class provides a reusable means for license plate localization and character OCR operations.
Open anpr.py and let’s get to work reviewing the script:
# import the necessary packages from skimage.segmentation import clear_border import pytesseract import numpy as np import imutils import cv2 class PyImageSearchANPR: def __init__(self, minAR=4, maxAR=5, debug=False): # store the minimum and maximum rectangular aspect ratio # values along with whether or not we are in debug mode self.minAR = minAR self.maxAR = maxAR self.debug = debug
If you’ve been following along with my previous OCR tutorials, you might recognize some of our imports. Scikit-learn’s clear_border function may be unfamiliar to you, though — this method assists with cleaning up the borders of images.
Our PyImageSearchANPR class begins on Line 8. The constructor accepts three parameters:
minAR4maxAR: The maximum aspect ratio of the license plate rectangle, which has a default value of5debug
The aspect ratio range (minAR to maxAR) corresponds to the typical rectangular dimensions of a license plate. Keep the following considerations in mind if you need to alter the aspect ratio parameters:
- European and international plates are often longer and not as tall as United States license plates. In this tutorial, we’re not considering U.S. license/number plates.
- Sometimes, motorcycles and large dumpster trucks mount their plates sideways; this is a true edge case that would have to be considered for a highly accurate license plate system (one we won’t consider in this tutorial).
- Some countries and regions allow for multi-line plates with a near 1:1 aspect ratio; again, we won’t consider this edge case.
Each of our constructor parameters becomes a class variable on Lines 12-14 so the methods in the class can access them.
Debugging our computer vision pipeline
With our constructor ready to go, let’s define a helper function to display results at various points in the imaging pipeline when in debug mode:
def debug_imshow(self, title, image, waitKey=False): # check to see if we are in debug mode, and if so, show the # image with the supplied title if self.debug: cv2.imshow(title, image) # check to see if we should wait for a keypress if waitKey: cv2.waitKey(0)
Our helper function debug_imshow (Line 16) accepts three parameters:
titleimage: The image to display inside the OpenCV GUI window.waitKey
Lines 19-24 display the debugging image in an OpenCV window. Typically, the waitKey boolean will be False. However, in this tutorial we have set it to True so we can inspect debugging images and dismiss them when we are ready.
Locating potential license plate candidates
Our first ANPR method helps us to find the license plate candidate contours in an image:
def locate_license_plate_candidates(self, gray, keep=5):
# perform a blackhat morphological operation that will allow
# us to reveal dark regions (i.e., text) on light backgrounds
# (i.e., the license plate itself)
rectKern = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 5))
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKern)
self.debug_imshow("Blackhat", blackhat)
Our locate_license_plate_candidates expects two parameters:
gray: This function assumes that the driver script will provide a grayscale image containing a potential license plate.keep
We’re now going to make a generalization to help us simplify our ANPR pipeline. Let’s assume from here forward that most license plates have a light background (typically it is highly reflective) and a dark foreground (characters).
I realize there are plenty of cases where this generalization does not hold, but let’s continue working on our proof of concept, and we can make accommodations for inverse plates in the future.
Lines 30 and 31 perform a blackhat morphological operation to reveal dark characters (letters, digits, and symbols) against light backgrounds (the license plate itself). As you can see, our kernel has a rectangular shape of 13 pixels wide x 5 pixels tall, which corresponds to the shape of a typical international license plate.
If your debug option is on, you’ll see a blackhat visualization similar to the one in Figure 2 (bottom):

As you can see from above, the license plate characters are clearly visible!
In our next step, we’ll find regions in the image that are light and may contain license plate characters:
# next, find regions in the image that are light
squareKern = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
light = cv2.morphologyEx(gray, cv2.MORPH_CLOSE, squareKern)
light = cv2.threshold(light, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
self.debug_imshow("Light Regions", light)
Using a small square kernel (Line 35), we apply a closing operation (Lines 36) to fill small holes and help us identify larger structures in the image. Lines 37 and 38 perform a binary threshold on our image using Otsu’s method to reveal the light regions in the image that may contain license plate characters.
Figure 3 shows the effect of the closing operation combined with Otsu’s inverse binary thresholding. Notice how the regions where the license plate is located are almost one large white surface.

Figure 3 shows the region that includes the license plate standing out.
The Scharr gradient will detect edges in the image and emphasize the boundaries of the characters in the license plate:
# compute the Scharr gradient representation of the blackhat
# image in the x-direction and then scale the result back to
# the range [0, 255]
gradX = cv2.Sobel(blackhat, ddepth=cv2.CV_32F,
dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = 255 * ((gradX - minVal) / (maxVal - minVal))
gradX = gradX.astype("uint8")
self.debug_imshow("Scharr", gradX)
Using cv2.Sobel, we compute the Scharr gradient magnitude representation in the x-direction of our blackhat image (Lines 44 and 45). We then scale the resulting intensities back to the range [0, 255] (Lines 46-49).
Figure 4 demonstrates an emphasis on the edges of the license plate characters:

As you can see above, the license plate characters appear noticeably different from the rest of the image.
We can now smooth to group the regions that may contain boundaries to license plate characters:
# blur the gradient representation, applying a closing
# operation, and threshold the image using Otsu's method
gradX = cv2.GaussianBlur(gradX, (5, 5), 0)
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKern)
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
self.debug_imshow("Grad Thresh", thresh)
Here we apply a Gaussian blur to the gradient magnitude image (gradX) (Line 54). Again we apply a closing operation (Line 55) and another binary threshold using Otsu’s method (Lines 56 and 57).
Figure 5 shows a contiguous white region where the license plate characters are located:

At first glance, these results look cluttered. The license plate region is somewhat defined, but there are many other large white regions as well. Let’s see if we can eliminate some of the noise:
# perform a series of erosions and dilations to clean up the
# thresholded image
thresh = cv2.erode(thresh, None, iterations=2)
thresh = cv2.dilate(thresh, None, iterations=2)
self.debug_imshow("Grad Erode/Dilate", thresh)
Lines 62 and 63 perform a series of erosions and dilations in an attempt to denoise the thresholded image:

As you can see in Figure 6, the erosion and dilation operations cleaned up a lot of noise in the previous result from Figure 5. We clearly aren’t done yet though.
Let’s add another step to the pipeline, in which we’ll put our light regions image to use:
# take the bitwise AND between the threshold result and the
# light regions of the image
thresh = cv2.bitwise_and(thresh, thresh, mask=light)
thresh = cv2.dilate(thresh, None, iterations=2)
thresh = cv2.erode(thresh, None, iterations=1)
self.debug_imshow("Final", thresh, waitKey=True)
Back on Lines 35-38, we devised a method to highlight lighter regions in the image (keeping in mind our established generalization that license plates will have a light background and dark foreground).
This light image serves as our mask for a bitwise-AND between the thresholded result and the light regions of the image to reveal the license plate candidates (Line 68). We follow with a couple of dilations and an erosion to fill holes and clean up the image (Lines 69 and 70).
Our "Final" debugging image is shown in Figure 7. Notice that the last call to debug_imshow overrides waitKey to True, ensuring that as a user, we can inspect all debugging images up until this point and press a key when we are ready.

You should notice that our license plate contour is not the largest, but it’s far from being the smallest. At a glance, I’d say it is the second or third largest contour in the image, and I also notice the plate contour is not touching the edge of the image.
Speaking of contours, let’s find and sort them:
# find contours in the thresholded image and sort them by # their size in descending order, keeping only the largest # ones cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cnts = imutils.grab_contours(cnts) cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:keep] # return the list of contours return cnts
To close out our locate_license_plate_candidates method, we:
- Find all contours (Lines 76-78)
- Reverse-sort them according to their pixel area while only keeping at most
keepcontours - Return the resulting sorted and pruned list of
cnts(Line 82).
Take a step back to think about what we’ve accomplished in this method. We’ve accepted a grayscale image and used traditional image processing techniques with an emphasis on morphological operations to find a selection of candidate contours that might contain a license plate.
I know what you are thinking: “Why haven’t we applied deep learning object detection to find the license plate? Wouldn’t that be easier?”
While that is perfectly acceptable (and don’t get me wrong, I love deep learning!), it is a lot of work to train such an object detector on your own. We’re talking requires countless hours to annotate thousands of images in your dataset.
But remember we didn’t have the luxury of a dataset in the first place, so the method we’ve developed so far relies on so-called “traditional” image processing techniques.
If you’re hungry to learn the ins and outs of morphological operations (and want to be a more well-rounded computer vision engineer), I suggest you enroll in the PyImageSearch Gurus course.
Pruning license plate candidates
In this next method, our goal is to find the most likely contour containing a license plate from our set of candidates. Let’s see how it works:
def locate_license_plate(self, gray, candidates, clearBorder=False): # initialize the license plate contour and ROI lpCnt = None roi = None # loop over the license plate candidate contours for c in candidates: # compute the bounding box of the contour and then use # the bounding box to derive the aspect ratio (x, y, w, h) = cv2.boundingRect(c) ar = w / float(h)
Our locate_license_plate function accepts three parameters:
gray: Our input grayscale imagecandidates: The license plate contour candidates returned by the previous method in this classclearBorder
Before we begin looping over the license plate contour candidates, first we initialize variables that will soon hold our license plate contour (lpCnt) and license plate region of interest (roi) on Lines 87 and 88.
Starting on Line 91, our loop begins. This loop aims to isolate the contour that contains the license plate and extract the region of interest of the license plate itself. We proceed by determining the bounding box rectangle of the contour, c (Line 94).
Computing the aspect ratio of the contour’s bounding box (Line 95) will help us ensure our contour is the proper rectangular shape of a license plate.
As you can see in the equation, the aspect ratio is a relationship between the width and height of the rectangle.
# check to see if the aspect ratio is rectangular if ar >= self.minAR and ar <= self.maxAR: # store the license plate contour and extract the # license plate from the grayscale image and then # threshold it lpCnt = c licensePlate = gray[y:y + h, x:x + w] roi = cv2.threshold(licensePlate, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
If the contour’s bounding box ar does not meet our license plate expectations, then there’s no more work to do. The roi and lpCnt will remain as None, and it is up to the driver script to handle this scenario.
Hopefully, the aspect ratio is acceptable and falls within the bounds of a typical license plate’s minAR and maxAR. In this case, we assume that we have our winning license plate contour! Let’s go ahead and populate lpCnt and our roi:
lpCntc(Line 102).roi
Let’s wrap up the locate_license_plate method so we can move onto the next phase:
# check to see if we should clear any foreground
# pixels touching the border of the image
# (which typically, not but always, indicates noise)
if clearBorder:
roi = clear_border(roi)
# display any debugging information and then break
# from the loop early since we have found the license
# plate region
self.debug_imshow("License Plate", licensePlate)
self.debug_imshow("ROI", roi, waitKey=True)
break
# return a 2-tuple of the license plate ROI and the contour
# associated with it
return (roi, lpCnt)
If our clearBorder flag is set, we can clear any foreground pixels that are touching the border of our license plate ROI (Lines 110 and 111). This helps to eliminate noise that could impact our Tesseract OCR results.
Lines 116 and 117 display our:
licensePlateroi: Our final license plate ROI (Figure 8, bottom)
Again, notice that the last call to debug_imshow of this function overrides waitKey to True, ensuring that as a user we have the opportunity to inspect all debugging images for this function and can press a key when we are ready.
After that key is pressed, we break out of our loop, ignoring other candidates. Finally, we return the 2-tuple consisting of our ROI and license plate contour to the caller.

The bottom result is encouraging because Tesseract OCR should be able to decipher the characters.
Defining Tesseract ANPR options including an OCR Character Whitelist and Page Segmentation Mode (PSM)
Leading up to this point, we’ve used our knowledge of OpenCV’s morphological operations and contour processing to both find the plate and ensure we have a clean image to send through the Tesseract OCR engine.
It is now time to do just that. Shifting our focus to OCR, let’s define the build_tesseract_options method:
def build_tesseract_options(self, psm=7):
# tell Tesseract to only OCR alphanumeric characters
alphanumeric = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
options = "-c tessedit_char_whitelist={}".format(alphanumeric)
# set the PSM mode
options += " --psm {}".format(psm)
# return the built options string
return options
Tesseract and its Python bindings brother, PyTesseract, accept a range of configuration options. For this tutorial we’re only concerned with two:
- Page Segmentation Method (PSM): Tesseract’s setting indicating layout analysis of the document/image. There are 13 modes of operation, but we will default to
7— “treat the image as a single text line” — per thepsmparameter default. - Whitelist: A listing of characters (letters, digits, symbols) that Tesseract will consider (i.e., report in the OCR’d results). Each of our whitelist characters is listed in the
alphanumericvariable (Line 126).
Lines 127-130 concatenate both into a formatted string with these option parameters. If you’re familiar with Tesseract’s command line arguments, you’ll notice that our PyTesseract options string has a direct relationship.
Our options are returned to the caller via Line 133.
The central method of the PyImageSearchANPR class
Our final method brings all the components together in one centralized place so our driver script can instantiate a PyImageSearchANPR object, and then make a single function call. Let’s implement find_and_ocr:
def find_and_ocr(self, image, psm=7, clearBorder=False):
# initialize the license plate text
lpText = None
# convert the input image to grayscale, locate all candidate
# license plate regions in the image, and then process the
# candidates, leaving us with the *actual* license plate
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
candidates = self.locate_license_plate_candidates(gray)
(lp, lpCnt) = self.locate_license_plate(gray, candidates,
clearBorder=clearBorder)
# only OCR the license plate if the license plate ROI is not
# empty
if lp is not None:
# OCR the license plate
options = self.build_tesseract_options(psm=psm)
lpText = pytesseract.image_to_string(lp, config=options)
self.debug_imshow("License Plate", lp)
# return a 2-tuple of the OCR'd license plate text along with
# the contour associated with the license plate region
return (lpText, lpCnt)
This method accepts three parameters:
image: The three-channel color image of the rear (or front) of a car with a license plate tagpsmclearBorder
Given our function parameters, we now:
- Convert the input
imageto grayscale (Line 142) - Determine our set of license plate
candidatesfrom ourgrayimage via the method we previously defined (Line 143) - Locate the license plate from the
candidatesresulting in ourlpROI (Lines 144 and 145)
Assuming we’ve found a suitable plate (i.e., lp is not None), we set our PyTesseract options and perform OCR via the image_to_string method (Lines 149-152).
Finally, Line 157 returns a 2-tuple consisting of the OCR’d lpText and lpCnt contour.
Phew! You did it! Nice job implementing the PyImageSearchANPR class.
If you found that implementing this class was challenging to understand, then I would recommend you study Module 1 of the PyImageSearch Gurus course, where you’ll learn the basics of computer vision and image processing.
In our next section, we’ll create a Python script that utilizes the PyImageSearchANPR class to perform Automatic License/Number Plate Recognition on input images.
Creating our license/number plate recognition driver script with OpenCV and Python
Now that our PyImageSearchANPR class is implemented, we can move on to creating a Python driver script that will:
- Load an input image from disk
- Find the license plate in the input image
- OCR the license plate
- Display the ANPR result to our screen
Let’s take a look in the project directory and find our driver file ocr_license_plate.py:
# import the necessary packages from pyimagesearch.anpr import PyImageSearchANPR from imutils import paths import argparse import imutils import cv2
Here we have our imports, namely our custom PyImageSearchANPR class that we implemented in the “Implementing ANPR/ALPR with OpenCV and Python” section and subsections.
Before we go further, we need to write a little string-cleanup utility:
def cleanup_text(text): # strip out non-ASCII text so we can draw the text on the image # using OpenCV return "".join([c if ord(c) < 128 else "" for c in text]).strip()
Our cleanup_text function simply accepts a text string and parses out all non-alphanumeric characters. This serves as a safety mechanism for OpenCV’s cv2.putText function, which isn’t always able to render special characters during image annotation (OpenCV will render them as “?”, question marks).
As you can see, we’re ensuring that only ASCII characters with ordinals [0, 127] pass through. If you are unfamiliar with ASCII and alphanumeric characters, check out my post OCR with Keras, TensorFlow, and Deep Learning or grab a copy of my upcoming OCR book, which cover this extensively.
Let’s familiarize ourselves with this script’s command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input directory of images")
ap.add_argument("-c", "--clear-border", type=int, default=-1,
help="whether or to clear border pixels before OCR'ing")
ap.add_argument("-p", "--psm", type=int, default=7,
help="default PSM mode for OCR'ing license plates")
ap.add_argument("-d", "--debug", type=int, default=-1,
help="whether or not to show additional visualizations")
args = vars(ap.parse_args())
Our command line arguments include:
--input--clear-border--psm7indicates that Tesseract should only look for one line of text.--debug
With our imports in place, text cleanup utility defined, and an understanding of our command line arguments, now it is time to automatically recognize license plates!
# initialize our ANPR class anpr = PyImageSearchANPR(debug=args["debug"] > 0) # grab all image paths in the input directory imagePaths = sorted(list(paths.list_images(args["input"])))
First, we instantiate our PyImageSearchANPR object while passing our --debug flag (Line 26). We also go ahead and bring in all the --input image paths with imutils’ paths module (Line 29).
We’ll process each of our imagePaths in hopes of finding and OCR’ing each license plate successfully:
# loop over all image paths in the input directory
for imagePath in imagePaths:
# load the input image from disk and resize it
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
# apply automatic license plate recognition
(lpText, lpCnt) = anpr.find_and_ocr(image, psm=args["psm"],
clearBorder=args["clear_border"] > 0)
# only continue if the license plate was successfully OCR'd
if lpText is not None and lpCnt is not None:
# fit a rotated bounding box to the license plate contour and
# draw the bounding box on the license plate
box = cv2.boxPoints(cv2.minAreaRect(lpCnt))
box = box.astype("int")
cv2.drawContours(image, [box], -1, (0, 255, 0), 2)
# compute a normal (unrotated) bounding box for the license
# plate and then draw the OCR'd license plate text on the
# image
(x, y, w, h) = cv2.boundingRect(lpCnt)
cv2.putText(image, cleanup_text(lpText), (x, y - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 2)
# show the output ANPR image
print("[INFO] {}".format(lpText))
cv2.imshow("Output ANPR", image)
cv2.waitKey(0)
Looping over our imagePaths, we load and resize the image (Lines 32-35).
A call to our find_and_ocr method — while passing the image, --psm mode, and --clear-border flag — primes our ANPR pipeline pump to spit out the resulting OCR’d text and license plate contour on the other end.
You’ve just performed ANPR/ALPR in the driver script! If you need to revisit this method, refer to the walkthrough in the “The central method of the PyImageSearchANPR class” section, bearing in mind that the bulk of the work is done in the class methods leading up to the find_and_ocr method.
Assuming that both lpText and lpCnt did not return as None (Line 42), let’s annotate the original input image with the OCR result. Inside the conditional, we:
- Calculate and draw the bounding box of the license plate contour (Lines 45-47)
- Annotate the cleanedup
lpTextstring (Lines 52-54) - Display the license plate string in the terminal and the annotated image in a GUI window (Lines 57 and 58)
You can now cycle through all of your --input directory images by pressing any key (Line 59).
You did it! Give yourself a pat on the back before proceeding to the results section — you deserve it.
ANPR results with OpenCV and Python
We are now ready to apply Automatic License/Number Plate Recognition using OpenCV and Python.
Start by using the “Downloads” section of this tutorial to download the source code and example images.
From there, open up a terminal and execute the following command for our first group of test images:
$ python ocr_license_plate.py --input license_plates/group1 [INFO] MH15TC584 [INFO] KL55R2473 [INFO] MH20EE7601 [INFO] KLO7BF5000 [INFO] HR26DA2330

As you can see, we’ve successfully applied ANPR to all of these images, including license/number plate examples on the front or back of the vehicle.
Let’s try another set of images, this time where our ANPR solution doesn’t work as well:
$ python ocr_license_plate.py --input license_plates/group2 [INFO] MHOZDW8351 [INFO] SICAL [INFO] WMTA
While the first result image has the correct ANPR result, the other two are wildly incorrect.
The solution here is to apply our clear_border function to strip foreground pixels that touch the border of the image that confuse Tesseract OCR:
$ python ocr_license_plate.py --input license_plates/group2 --clear-border 1 [INFO] MHOZDW8351 [INFO] KA297999 [INFO] KE53E964
clear_border option to “group 2” vehicle images, we see an improvement in the results. However, we still have OCR mistakes present in the top-right and bottom examples. We’re able to improve the ANPR OCR results for these images by applying the clear_border function.
However, there is still one mistake in each example. In the top-right case, the letter “Z” is mistaken for the digit “7”. In the bottom case, the letter “L” is mistaken for the letter “E”.
Although these are understandable mistakes, we would hope to do better.
While our system is a great start (and is sure to impress our friends and family!), there are some obvious limitations and drawbacks associated with today’s proof of concept. Let’s discuss them, along with a few ideas for improvement.
Limitations and drawbacks

As the previous section’s ANPR results showed, sometimes our ANPR system worked well and other times it did not. Furthermore, something as simple as clearing any foreground pixels that touch the borders of the input license plate improved license plate OCR accuracy.
Why is that?
The simple answer here is that Tesseract’s OCR engine can be a bit sensitive. Tesseract will work best when you provide it with neatly cleaned and pre-processed images.
However, in real-world implementations, you may not be able to guarantee clear images. Instead, your images may be grainy or low quality, or the driver of a given vehicle may have a special cover on their license plate to obfuscate the view of it, making ANPR even more challenging.
As I mentioned in the introduction to this tutorial (and I’ll reiterate in the summary), this blog post serves as a starting point to building your own Automatic License/Number Plate Recognition systems.
This method will work well in controlled conditions, but if you want to build a system that works in uncontrolled environments, you’ll need to start replacing components (namely license plate localization, character segmentation, and character OCR) with more advanced machine learning and deep learning models.
If you’re interested in more advanced ANPR methods, please let me know what challenges you’re facing so I can develop future content for you!
Credits
The collection of images we used for this ANPR example was sampled from the dataset put together by Devika Mishra of DataTurks. Thank you for putting together this dataset, Devika!
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: January 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to build a basic Automatic License/Number Plate Recognition system using OpenCV and Python.
Our ANPR method relied on basic computer vision and image processing techniques to localize a license plate in an image, including morphological operations, image gradients, thresholding, bitwise operations, and contours.
This method will work well in controlled, predictable environments — like when lighting conditions are uniform across input images and license plates are standardized (such as dark characters on a light license plate background).
However, if you are developing an ANPR system that does not have a controlled environment, you’ll need to start inserting machine learning and/or deep learning to replace parts of our plate localization pipeline.
HOG + Linear SVM is a good starting point for plate localization if your input license plates have a viewing angle that doesn’t change more than a few degrees. If you’re working in an unconstrained environment where viewing angles can vary dramatically, then deep learning-based models such as Faster R-CNN, SSDs, and YOLO will likely obtain better accuracy.
Additionally, you may need to train your own custom license plate character OCR model. We were able to get away with Tesseract in this blog post, but a dedicated character segmentation and OCR model (like the ones I cover inside the PyImageSearch Gurus course) may be required to improve your accuracy.
I hope you enjoyed this tutorial!
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.