Last updated on July 7, 2021.


In this tutorial you will learn how to use OpenCV to detect text in natural scene images using the EAST text detector.
OpenCV’s EAST text detector is a deep learning model, based on a novel architecture and training pattern. It is capable of (1) running at near real-time at 13 FPS on 720p images and (2) obtains state-of-the-art text detection accuracy.
A dataset comprising images with embedded text is necessary for understanding the EAST Text Detector. It helps the model to learn the diverse scenarios in which text can occur, enhancing its detection capabilities.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.
In the remainder of this tutorial you will learn how to use OpenCV’s EAST detector to automatically detect text in both images and video streams.
A dataset comprising images with embedded text is necessary for understanding the EAST Text Detector. It helps the model to learn the diverse scenarios in which text can occur, enhancing its detection capabilities.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.
To discover how to apply text detection with OpenCV, just keep reading!
- Update July 2021: Added two new sections, including alternative EAST text detector implementations, as well as a section on alternatives to the EAST model itself.
OpenCV Text Detection (EAST text detector)
In this tutorial, you will learn how to use OpenCV to detect text in images using the EAST text detector.
The EAST text detector requires that we are running OpenCV 3.4.2 or OpenCV 4 on our systems — if you do not already have OpenCV 3.4.2 or better installed, please refer to my OpenCV install guides and follow the one for your respective operating system.
In the first part of today’s tutorial, I’ll discuss why detecting text in natural scene images can be so challenging.
From there I’ll briefly discuss the EAST text detector, why we use it, and what makes the algorithm so novel — I’ll also include links to the original paper so you can read up on the details if you are so inclined.
Finally, I’ll provide my Python + OpenCV text detection implementation so you can start applying text detection in your own applications.
Why is natural scene text detection so challenging?

Detecting text in constrained, controlled environments can typically be accomplished by using heuristic-based approaches, such as exploiting gradient information or the fact that text is typically grouped into paragraphs and characters appear on a straight line. An example of such a heuristic-based text detector can be seen in my previous blog post on Detecting machine-readable zones in passport images.
Natural scene text detection is different though — and much more challenging.
Due to the proliferation of cheap digital cameras, and not to mention the fact that nearly every smartphone now has a camera, we need to be highly concerned with the conditions the image was captured under — and furthermore, what assumptions we can and cannot make. I’ve included a summarized version of the natural scene text detection challenges described by Celine Mancas-Thillou and Bernard Gosselin in their excellent 2017 paper, Natural Scene Text Understanding below:
- Image/sensor noise: Sensor noise from a handheld camera is typically higher than that of a traditional scanner. Additionally, low-priced cameras will typically interpolate the pixels of raw sensors to produce real colors.
- Viewing angles: Natural scene text can naturally have viewing angles that are not parallel to the text, making the text harder to recognize.
- Blurring: Uncontrolled environments tend to have blur, especially if the end user is utilizing a smartphone that does not have some form of stabilization.
- Lighting conditions: We cannot make any assumptions regarding our lighting conditions in natural scene images. It may be near dark, the flash on the camera may be on, or the sun may be shining brightly, saturating the entire image.
- Resolution: Not all cameras are created equal — we may be dealing with cameras with sub-par resolution.
- Non-paper objects: Most, but not all, paper is not reflective (at least in context of paper you are trying to scan). Text in natural scenes may be reflective, including logos, signs, etc.
- Non-planar objects: Consider what happens when you wrap text around a bottle — the text on the surface becomes distorted and deformed. While humans may still be able to easily “detect” and read the text, our algorithms will struggle. We need to be able to handle such use cases.
- Unknown layout: We cannot use any a priori information to give our algorithms “clues” as to where the text resides.
As we’ll learn, OpenCV’s text detector implementation of EAST is quite robust, capable of localizing text even when it’s blurred, reflective, or partially obscured:

I would suggest reading Mancas-Thillou and Gosselin’s work if you are further interested in the challenges associated with text detection in natural scene images.
The EAST deep learning text detector
With the release of OpenCV 3.4.2 and OpenCV 4, we can now use a deep learning-based text detector called EAST, which is based on Zhou et al.’s 2017 paper, EAST: An Efficient and Accurate Scene Text Detector.
We call the algorithm “EAST” because it’s an: Efficient and Accurate Scene Text detection pipeline.
The EAST pipeline is capable of predicting words and lines of text at arbitrary orientations on 720p images, and furthermore, can run at 13 FPS, according to the authors.
Perhaps most importantly, since the deep learning model is end-to-end, it is possible to sidestep computationally expensive sub-algorithms that other text detectors typically apply, including candidate aggregation and word partitioning.
To build and train such a deep learning model, the EAST method utilizes novel, carefully designed loss functions.
For more details on EAST, including architecture design and training methods, be sure to refer to the publication by the authors.
Project structure
To start, be sure to grab the source code + images to today’s post by visiting the “Downloads” section. From there, simply use the tree terminal command to view the project structure:
$ tree --dirsfirst . ├── images │ ├── car_wash.png │ ├── lebron_james.jpg │ └── sign.jpg ├── frozen_east_text_detection.pb ├── text_detection.py └── text_detection_video.py 1 directory, 6 files
Notice that I’ve provided three sample pictures in the images/ directory. You may wish to add your own images collected with your smartphone or ones you find online.
We’ll be reviewing two .py files today:
text_detection.py: Detects text in static images.text_detection_video.py: Detects text via your webcam or input video files.
Both scripts make use of the serialized EAST model (frozen_east_text_detection.pb) provided for your convenience in the “Downloads.”
Implementation notes
The text detection implementation I am including today is based on OpenCV’s official C++ example; however, I must admit that I had a bit of trouble when converting it to Python.
To start, there are no Point2f and RotatedRect functions in Python, and because of this, I could not 100% mimic the C++ implementation. The C++ implementation can produce rotated bounding boxes, but unfortunately the one I am sharing with you today cannot.
Secondly, the NMSBoxes function does not return any values for the Python bindings (at least for my OpenCV 4 pre-release install), ultimately resulting in OpenCV throwing an error. The NMSBoxes function may work in OpenCV 3.4.2 but I wasn’t able to exhaustively test it.
I got around this issue by using my own non-maxima suppression implementation in imutils, but again, I don’t believe these two are 100% interchangeable as it appears NMSBoxes accepts additional parameters.
Given all that, I’ve tried my best to provide you with the best OpenCV text detection implementation I could, using the working functions and resources I had. If you have any improvements to the method please do feel free to share them in the comments below.
Implementing our text detector with OpenCV
Before we get started, I want to point out that you will need at least OpenCV 3.4.2 (or OpenCV 4) installed on your system to utilize OpenCV’s EAST text detector, so if you haven’t already installed OpenCV 3.4.2 or better on your system, please refer to my OpenCV install guides.
Next, make sure you have imutils installed/upgraded on your system as well:
$ pip install --upgrade imutils
At this point your system is now configured, so open up text_detection.py and insert the following code:
# import the necessary packages
from imutils.object_detection import non_max_suppression
import numpy as np
import argparse
import time
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str,
help="path to input image")
ap.add_argument("-east", "--east", type=str,
help="path to input EAST text detector")
ap.add_argument("-c", "--min-confidence", type=float, default=0.5,
help="minimum probability required to inspect a region")
ap.add_argument("-w", "--width", type=int, default=320,
help="resized image width (should be multiple of 32)")
ap.add_argument("-e", "--height", type=int, default=320,
help="resized image height (should be multiple of 32)")
args = vars(ap.parse_args())
To begin, we import our required packages and modules on Lines 2-6. Notably we import NumPy, OpenCV, and my implementation of non_max_suppression from imutils.object_detection .
We then proceed to parse five command line arguments on Lines 9-20:
--image: The path to our input image.--east: The EAST scene text detector model file path.--min-confidence: Probability threshold to determine text. Optional withdefault=0.5.--width: Resized image width — must be multiple of 32. Optional withdefault=320.--height: Resized image height — must be multiple of 32. Optional withdefault=320.
Important: The EAST text requires that your input image dimensions be multiples of 32, so if you choose to adjust your --width and --height values, make sure they are multiples of 32!
From there, let’s load our image and resize it:
# load the input image and grab the image dimensions image = cv2.imread(args["image"]) orig = image.copy() (H, W) = image.shape[:2] # set the new width and height and then determine the ratio in change # for both the width and height (newW, newH) = (args["width"], args["height"]) rW = W / float(newW) rH = H / float(newH) # resize the image and grab the new image dimensions image = cv2.resize(image, (newW, newH)) (H, W) = image.shape[:2]
On Lines 23 and 24, we load and copy our input image.
From there, Lines 30 and 31 determine the ratio of the original image dimensions to new image dimensions (based on the command line argument provided for --width and --height ).
Then we resize the image, ignoring aspect ratio (Line 34).
In order to perform text detection using OpenCV and the EAST deep learning model, we need to extract the output feature maps of two layers:
# define the two output layer names for the EAST detector model that # we are interested -- the first is the output probabilities and the # second can be used to derive the bounding box coordinates of text layerNames = [ "feature_fusion/Conv_7/Sigmoid", "feature_fusion/concat_3"]
We construct a list of layerNames on Lines 40-42:
- The first layer is our output sigmoid activation which gives us the probability of a region containing text or not.
- The second layer is the output feature map that represents the “geometry” of the image — we’ll be able to use this geometry to derive the bounding box coordinates of the text in the input image
Let’s load the OpenCV’s EAST text detector:
# load the pre-trained EAST text detector
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
# construct a blob from the image and then perform a forward pass of
# the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
start = time.time()
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
end = time.time()
# show timing information on text prediction
print("[INFO] text detection took {:.6f} seconds".format(end - start))
We load the neural network into memory using cv2.dnn.readNet by passing the path to the EAST detector (contained in our command line args dictionary) as a parameter on Line 46.
Then we prepare our image by converting it to a blob on Lines 50 and 51. To read more about this step, refer to Deep learning: How OpenCV’s blobFromImage works.
To predict text we can simply set the blob as input and call net.forward (Lines 53 and 54). These lines are surrounded by grabbing timestamps so that we can print the elapsed time on Line 58.
By supplying layerNames as a parameter to net.forward, we are instructing OpenCV to return the two feature maps that we are interested in:
- The output
geometrymap used to derive the bounding box coordinates of text in our input images - And similarly, the
scoresmap, containing the probability of a given region containing text
We’ll need to loop over each of these values, one-by-one:
# grab the number of rows and columns from the scores volume, then # initialize our set of bounding box rectangles and corresponding # confidence scores (numRows, numCols) = scores.shape[2:4] rects = [] confidences = [] # loop over the number of rows for y in range(0, numRows): # extract the scores (probabilities), followed by the geometrical # data used to derive potential bounding box coordinates that # surround text scoresData = scores[0, 0, y] xData0 = geometry[0, 0, y] xData1 = geometry[0, 1, y] xData2 = geometry[0, 2, y] xData3 = geometry[0, 3, y] anglesData = geometry[0, 4, y]
We start off by grabbing the dimensions of the scores volume (Line 63) and then initializing two lists:
rects: Stores the bounding box (x, y)-coordinates for text regionsconfidences: Stores the probability associated with each of the bounding boxes inrects
We’ll later be applying non-maxima suppression to these regions.
Looping over the rows begins on Line 68.
Lines 72-77 extract our scores and geometry data for the current row, y.
Next, we loop over each of the column indexes for our currently selected row:
# loop over the number of columns for x in range(0, numCols): # if our score does not have sufficient probability, ignore it if scoresData[x] < args["min_confidence"]: continue # compute the offset factor as our resulting feature maps will # be 4x smaller than the input image (offsetX, offsetY) = (x * 4.0, y * 4.0) # extract the rotation angle for the prediction and then # compute the sin and cosine angle = anglesData[x] cos = np.cos(angle) sin = np.sin(angle) # use the geometry volume to derive the width and height of # the bounding box h = xData0[x] + xData2[x] w = xData1[x] + xData3[x] # compute both the starting and ending (x, y)-coordinates for # the text prediction bounding box endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x])) endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x])) startX = int(endX - w) startY = int(endY - h) # add the bounding box coordinates and probability score to # our respective lists rects.append((startX, startY, endX, endY)) confidences.append(scoresData[x])
For every row, we begin looping over the columns on Line 80.
We need to filter out weak text detections by ignoring areas that do not have sufficiently high probability (Lines 82 and 83).
The EAST text detector naturally reduces volume size as the image passes through the network — our volume size is actually 4x smaller than our input image so we multiply by four to bring the coordinates back into respect of our original image.
I’ve included how you can extract the angle data on Lines 91-93; however, as I mentioned in the previous section, I wasn’t able to construct a rotated bounding box from it as is performed in the C++ implementation — if you feel like tackling the task, starting with the angle on Line 91 would be your first step.
From there, Lines 97-105 derive the bounding box coordinates for the text area.
We then update our rects and confidences lists, respectively (Lines 109 and 110).
We’re almost finished!
The final step is to apply non-maxima suppression to our bounding boxes to suppress weak overlapping bounding boxes and then display the resulting text predictions:
# apply non-maxima suppression to suppress weak, overlapping bounding
# boxes
boxes = non_max_suppression(np.array(rects), probs=confidences)
# loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
# scale the bounding box coordinates based on the respective
# ratios
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
# draw the bounding box on the image
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 255, 0), 2)
# show the output image
cv2.imshow("Text Detection", orig)
cv2.waitKey(0)
As I mentioned in the previous section, I could not use the non-maxima suppression in my OpenCV 4 install (cv2.dnn.NMSBoxes ) as the Python bindings did not return a value, ultimately causing OpenCV to error out. I wasn’t fully able to test in OpenCV 3.4.2 so it may work in v3.4.2.
Instead, I have used my non-maxima suppression implementation available in the imutils package (Line 114). The results still look good; however, I wasn’t able to compare my output to the NMSBoxes function to see if they were identical.
Lines 117-126 loop over our bounding boxes , scale the coordinates back to the original image dimensions, and draw the output to our orig image. The orig image is displayed until a key is pressed (Lines 129 and 130).
As a final implementation note I would like to mention that our two nested for loops used to loop over the scores and geometry volumes on Lines 68-110 would be an excellent example of where you could leverage Cython to dramatically speed up your pipeline. I’ve demonstrated the power of Cython in Fast, optimized ‘for’ pixel loops with OpenCV and Python.
OpenCV text detection results
Are you ready to apply text detection to images?
Start by grabbing the “Downloads” for this blog post and unzip the files.
From there, you may execute the following command in your terminal (taking note of the two command line arguments):
$ python text_detection.py --image images/lebron_james.jpg \ --east frozen_east_text_detection.pb [INFO] loading EAST text detector... [INFO] text detection took 0.142082 seconds
Your results should look similar to the following image:
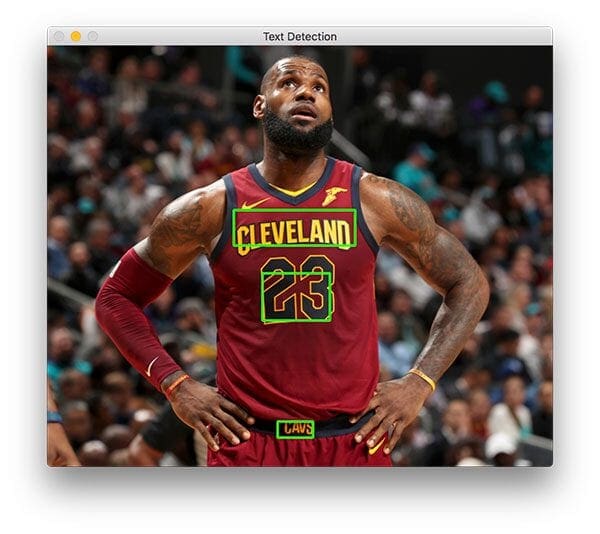
Three text regions are identified on Lebron James.
Now let’s try to detect text of a business sign:
$ python text_detection.py --image images/car_wash.png \ --east frozen_east_text_detection.pb [INFO] loading EAST text detector... [INFO] text detection took 0.142295 seconds

And finally, we’ll try a road sign:
$ python text_detection.py --image images/sign.jpg \ --east frozen_east_text_detection.pb [INFO] loading EAST text detector... [INFO] text detection took 0.141675 seconds

This scene contains a Spanish stop sign. The word, “ALTO” is correctly detected by OpenCV and EAST.
As you can tell, EAST is quite accurate and relatively fast taking approximately 0.14 seconds on average per image.
Text detection in video with OpenCV
Now that we’ve seen how to detect text in images, let’s move on to detecting text in video with OpenCV.
This explanation will be very brief; please refer to the previous section for details as needed.
Open up text_detection_video.py and insert the following code:
# import the necessary packages from imutils.video import VideoStream from imutils.video import FPS from imutils.object_detection import non_max_suppression import numpy as np import argparse import imutils import time import cv2
We begin by importing our packages. We’ll be using VideoStream to access a webcam and FPS to benchmark our frames per second for this script. Everything else is the same as in the previous section.
For convenience, let’s define a new function to decode our predictions function — it will be reused for each frame and make our loop cleaner:
def decode_predictions(scores, geometry): # grab the number of rows and columns from the scores volume, then # initialize our set of bounding box rectangles and corresponding # confidence scores (numRows, numCols) = scores.shape[2:4] rects = [] confidences = [] # loop over the number of rows for y in range(0, numRows): # extract the scores (probabilities), followed by the # geometrical data used to derive potential bounding box # coordinates that surround text scoresData = scores[0, 0, y] xData0 = geometry[0, 0, y] xData1 = geometry[0, 1, y] xData2 = geometry[0, 2, y] xData3 = geometry[0, 3, y] anglesData = geometry[0, 4, y] # loop over the number of columns for x in range(0, numCols): # if our score does not have sufficient probability, # ignore it if scoresData[x] < args["min_confidence"]: continue # compute the offset factor as our resulting feature # maps will be 4x smaller than the input image (offsetX, offsetY) = (x * 4.0, y * 4.0) # extract the rotation angle for the prediction and # then compute the sin and cosine angle = anglesData[x] cos = np.cos(angle) sin = np.sin(angle) # use the geometry volume to derive the width and height # of the bounding box h = xData0[x] + xData2[x] w = xData1[x] + xData3[x] # compute both the starting and ending (x, y)-coordinates # for the text prediction bounding box endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x])) endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x])) startX = int(endX - w) startY = int(endY - h) # add the bounding box coordinates and probability score # to our respective lists rects.append((startX, startY, endX, endY)) confidences.append(scoresData[x]) # return a tuple of the bounding boxes and associated confidences return (rects, confidences)
On Line 11 we define decode_predictions function. This function is used to extract:
- The bounding box coordinates of a text region
- And the probability of a text region detection
This dedicated function will make the code easier to read and manage later on in this script.
Let’s parse our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-east", "--east", type=str, required=True,
help="path to input EAST text detector")
ap.add_argument("-v", "--video", type=str,
help="path to optinal input video file")
ap.add_argument("-c", "--min-confidence", type=float, default=0.5,
help="minimum probability required to inspect a region")
ap.add_argument("-w", "--width", type=int, default=320,
help="resized image width (should be multiple of 32)")
ap.add_argument("-e", "--height", type=int, default=320,
help="resized image height (should be multiple of 32)")
args = vars(ap.parse_args())
Our command line arguments are parsed on Lines 69-80:
--east: The EAST scene text detector model file path.--video: The path to our input video. Optional — if a video path is provided then the webcam will not be used.--min-confidence: Probability threshold to determine text. Optional withdefault=0.5.--width: Resized image width (must be multiple of 32). Optional withdefault=320.--height: Resized image height (must be multiple of 32). Optional withdefault=320.
The primary change from the image-only script in the previous section (in terms of command line arguments) is that I’ve substituted the --image argument with --video.
Important: The EAST text requires that your input image dimensions be multiples of 32, so if you choose to adjust your --width and --height values, ensure they are multiples of 32!
Next, we’ll perform important initializations which mimic the previous script:
# initialize the original frame dimensions, new frame dimensions,
# and ratio between the dimensions
(W, H) = (None, None)
(newW, newH) = (args["width"], args["height"])
(rW, rH) = (None, None)
# define the two output layer names for the EAST detector model that
# we are interested -- the first is the output probabilities and the
# second can be used to derive the bounding box coordinates of text
layerNames = [
"feature_fusion/Conv_7/Sigmoid",
"feature_fusion/concat_3"]
# load the pre-trained EAST text detector
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
The height/width and ratio initializations on Lines 84-86 will allow us to properly scale our bounding boxes later on.
Our output layer names are defined and we load our pre-trained EAST text detector on Lines 91-97.
The following block sets up our video stream and frames per second counter:
# if a video path was not supplied, grab the reference to the web cam
if not args.get("video", False):
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(1.0)
# otherwise, grab a reference to the video file
else:
vs = cv2.VideoCapture(args["video"])
# start the FPS throughput estimator
fps = FPS().start()
Our video stream is set up for either:
- A webcam (Lines 100-103)
- Or a video file (Lines 106-107)
From there we initialize our frames per second counter on Line 110 and begin looping over incoming frames:
# loop over frames from the video stream
while True:
# grab the current frame, then handle if we are using a
# VideoStream or VideoCapture object
frame = vs.read()
frame = frame[1] if args.get("video", False) else frame
# check to see if we have reached the end of the stream
if frame is None:
break
# resize the frame, maintaining the aspect ratio
frame = imutils.resize(frame, width=1000)
orig = frame.copy()
# if our frame dimensions are None, we still need to compute the
# ratio of old frame dimensions to new frame dimensions
if W is None or H is None:
(H, W) = frame.shape[:2]
rW = W / float(newW)
rH = H / float(newH)
# resize the frame, this time ignoring aspect ratio
frame = cv2.resize(frame, (newW, newH))
We begin looping over video/webcam frames on Line 113.
Our frame is resized, maintaining aspect ratio (Line 124). From there, we grab dimensions and compute the scaling ratios (Lines 129-132). We then resize the frame again (must be a multiple of 32), this time ignoring aspect ratio since we have stored the ratios for safe keeping (Line 135).
Inference and drawing text region bounding boxes take place on the following lines:
# construct a blob from the frame and then perform a forward pass # of the model to obtain the two output layer sets blob = cv2.dnn.blobFromImage(frame, 1.0, (newW, newH), (123.68, 116.78, 103.94), swapRB=True, crop=False) net.setInput(blob) (scores, geometry) = net.forward(layerNames) # decode the predictions, then apply non-maxima suppression to # suppress weak, overlapping bounding boxes (rects, confidences) = decode_predictions(scores, geometry) boxes = non_max_suppression(np.array(rects), probs=confidences) # loop over the bounding boxes for (startX, startY, endX, endY) in boxes: # scale the bounding box coordinates based on the respective # ratios startX = int(startX * rW) startY = int(startY * rH) endX = int(endX * rW) endY = int(endY * rH) # draw the bounding box on the frame cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 255, 0), 2)
In this block we:
- Detect text regions using EAST via creating a
bloband passing it through the network (Lines 139-142) - Decode the predictions and apply NMS (Lines 146 and 147). We use the
decode_predictionsfunction defined previously in this script and my imutilsnon_max_suppressionconvenience function. - Loop over bounding boxes and draw them on the
frame(Lines 150-159). This involves scaling the boxes by the ratios gathered earlier.
From there we’ll close out the frame processing loop as well as the script itself:
# update the FPS counter
fps.update()
# show the output frame
cv2.imshow("Text Detection", orig)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# if we are using a webcam, release the pointer
if not args.get("video", False):
vs.stop()
# otherwise, release the file pointer
else:
vs.release()
# close all windows
cv2.destroyAllWindows()
We update our fps counter each iteration of the loop (Line 162) so that timings can be calculated and displayed (Lines 173-175) when we break out of the loop.
We show the output of EAST text detection on Line 165 and handle keypresses (Lines 166-170). If “q” is pressed for “quit”, we break out of the loop and proceed to clean up and release pointers.
Video text detection results
To apply text detection to video with OpenCV, be sure to use the “Downloads” section of this blog post.
From there, open up a terminal and execute the following command (which will fire up your webcam since we aren’t supplying a --video via command line argument):
$ python text_detection_video.py --east frozen_east_text_detection.pb [INFO] loading EAST text detector... [INFO] starting video stream... [INFO] elasped time: 59.76 [INFO] approx. FPS: 8.85
Our OpenCV text detection video script achieves 7-9 FPS.
This result is not quite as fast as the authors reported (13 FPS); however, we are using Python instead of C++. By optimizing our for loops with Cython, we should be able to increase the speed of our text detection pipeline.
Alternative EAST text detection implementations
The EAST text detection model we used here today is a TensorFlow implementation compatible with OpenCV, meaning that you can use either TensorFlow or OpenCV to make text detection predictions with this model.
If you are looking for a PyTorch implementation, I suggest checking out this repo.
What other text detectors can we use besides EAST?
To start, both Tesseract and EasyOCR have both text detection (detecting where text is in an input image) and text recognition (OCR’ing the text itself):
- This tutorial shows you how to use Tesseract to perform text detection
- And this tutorial covers text detection with EasyOCR
Both of those tutorials utilize deep learning-based models to perform text detection and localization.
However, depending on your project, you may be able to get away with using basic image processing and computer vision techniques to perform text detection. The following tutorials show you how to do exactly that:
- Detecting machine-readable zones in passport images
- Recognizing digits with OpenCV and Python
- Credit card OCR with OpenCV and Python
- Bank check OCR with OpenCV and Python (Part I)
- Bank check OCR with OpenCV and Python (Part II)
While traditional computer vision and image processing techniques may not be as generalizable as deep learning-based text detection techniques, they can work surprisingly well in some situations.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post, we learned how to use OpenCV’s new EAST text detector to automatically detect the presence of text in natural scene images.
The text detector is not only accurate, but it’s capable of running in near real-time at approximately 13 FPS on 720p images.
In order to provide an implementation of OpenCV’s EAST text detector, I needed to convert OpenCV’s C++ example; however, there were a number of challenges I encountered, such as:
- Not being able to use OpenCV’s
NMSBoxesfor non-maxima suppression and instead having to use my implementation fromimutils. - Not being able to compute a true rotated bounding box due to the lack of Python bindings for
RotatedRect.
I tried to keep my implementation as close to OpenCV’s as possible, but keep in mind that my version is not 100% identical to the C++ version and that there may be one or two small problems that will need to be resolved over time.
In any case, I hope you enjoyed today’s tutorial on text detection with OpenCV!
To download the source code to this tutorial, and start applying text detection to your own images, just enter your email address in the form below.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Oh man, great article Adrian. Thanks for sharing with the rest of the world.
I just have a toy project for text detection. The only caveat that my text might be in English or Arabic, so I will see if this can somehow help me out!
Thanks!
I haven’t personally tried with non-English words but a PyImageSearch reader on LinkedIn posted an example of correctly detecting Tamil text. It may work for your project as well, be sure to give it a try!
I tried on mixed Bulgarian/English – it works perfect.
One question – how to extract boundered text?
Regards.
You can use array slicing:
roi = image[startY:endY, startX:endX]How you approach this?
hi iam also intersted doing research in text detection can yo please send that code to me that works for both lnguages
Thanks for the great article. It is pretty accurate and fast.
I wonder how may:
1. I tune the implementation for Chinese characters which is square shape
2. I train it with Chinese chars
3. Find the post for Tamil text
What exactly do you mean can you share the url of the article with that other language detection?
Very nice tutorial. I just didn’t get how, after getting the bounding boxes, how to actually get the detected text
Be sure to see my reply to FUXIN YU 🙂
Correction: the EAST paper is from 2017, not 2007. I was really surprised to see a 2007 paper to have a RPN-like CNN structure. 😉
That was indeed a typo on my part, thank you for pointing it out! I’ve corrected the post.
Hi Author,
Thanks for your posting, this is really good material to learn ML and CV.
one question, how to get the text content which has been recognized in the box?
Thanks,
Fred
Once you have the ROI of the text area you could pass it into an algorithm that that is dedicated to performing Optical Character Recognition (OCR). I’ll be posting a separate guide that demonstrates how to combine the text detection with the text recognition phase, but for the time being you should refer to this guide on Tesseract OCR.
Hello Adrian,
Great post! As far as the text extraction goes I think we should take into concideration what was already written in the “Natural Scene Text Understanding” paper.
Basically, even if the text areas are properly located, you should do some image processing taking into account variations in lighting, color, hue, saturation, light reflection etc. Once the extracted pieces of the image have been cleaned up, OCR should work more reliably.
Though I’m not sure if an additional, well trained neural network would not even be better – that would offer more options for retraining for different charcter sets and languages…
Hi Adrian,
First of all thanks a lot for posting this brilliant article.It helps a lot.
Also when can we expect to get article on how to combine text detection with text recognition.
Need it a bit urgently 🙁
I’m honestly not sure, Gaurav. I have some other posts I’m working on and then I’ll be swinging back to text recognition. Likely not for another few weeks/months.
Thanks for the update Adrian. But can you guide me some path may be some links/post to refer on how to do text recognition after text detection. It would be really helpful.
Hi Adrian,
If you will be making a guide for OCR this dataset may interest you: http://artelab.dista.uninsubria.it/downloads/datasets/automatic_meter_reading/gas_meter_reading/gas_meter_reading.html
It contains images of gas counters with all the annotations (coordinates of boxes and digits). I trained a model with that dataset and it performed really well even with different fonts. If you happen to know a similar dataset please tell me, thanks and great post!
Wow, this is a really, really cool dataset — thank you for sharing, Joan! What type of model did you train on the data? I see they have annotations for both segmentation of the meter followed by the detection of the digits.
Used a HOG to extract the features and passed it to a SVM
Awesome! I’ll look into this further.
hi thanks for your tutorial
I am using Anaconda3
how can I import imutils to my Anaconda3
I’m not an Anaconda user but you should be able to pip install it once you’ve created an environment:
$ pip install imutilsAdditionally, this thread on GitHub documents users who had trouble installing imutils for one reason or another. Be sure to give it a read.
13fps on what hardware RPi? Tegra?
The authors reported 13 FPS on a standard laptop/desktop. The benchmark was not on the Pi.
Great work again Adrian. thanks a lot. I recently noticed that Opencv in version 3.4.2 support one of the best and most accurate tensorflow models: Faster rcnn inception v2 in object detection. In some recent posts of your blog you used caffe model in opencv. Could on please make a post on implementation of faster rcnn inception v2 on Opencv?
Thank you for the suggestion Farshad, I will try to do a post on Faster R-CNNs.
Cool post. Does this method also work on vertical text???
Nice! Couldn’t have read this at a better time. Thanks alot! Also nice guitar man \m/
I’ve been recently searching for a good scene text detection/recognition implementation for a little project of mine. Thinking of somehow using TextBoxes++ (https://arxiv.org/abs/1801.02765) but now can try out EAST.
Awesome! Definitely try EAST and let me know how it goes, Joppu!
Hi Adrain. As I tried to run the codes, I got the error:
AttributeError: module ‘cv2.dnn’ has no attribute ‘readNet’
Checking for the solution online, the function is not available in python using this reference.
https://github.com/opencv/opencv/issues/11226
P.S. I have installed the latest version of opencv 3.4.2.17.
Thoughts on this one?
Hey Ronrick — I’m not sure why that may happening. Try building OpenCV 4 and see if that resolves the issue. Here is an OpenCV 4 + Ubuntu install tutorial and here is an OpenCV 4 + macOS install tutorial. I hope that resolve the issue for you!
Remove that slash while running the file from cmd i.e.
$ python text_detection.py –image images/car_wash.png –east
frozen_east_text_detection.pb
Great post-Adrian. I myself was trying to tweak f-RCNN for text detection on Sanskrit document images, but the results were far from satisfactory. I’ll try this out. Thanks a lot 🙂
I hope it helps with your text detection project, Deepayan! Let me know how it goes.
another great & update article :), but the resulting bounding box doesn’t rotate when the text is rotated? or I miss something?
Yes. To quote the post:
“To start, there are no Point2f and RotatedRect functions in Python, and because of this, I could not 100% mimic the C++ implementation. The C++ implementation can produce rotated bounding boxes, but unfortunately the one I am sharing with you today cannot.”
And secondly:
“I’ve included how you can extract the angle data on Lines 91-93; however, as I mentioned in the previous section, I wasn’t able to construct a rotated bounding box from it as is performed in the C++ implementation — if you feel like tackling the task, starting with the angle on Line 91 would be your first step.”
The conclusion also mentions this behavior as well. Please feel free to work with the code, I’ve love to have a rotated bounding box version as well!
Hi, Adrian
Thanks for the sharing,the script works well.Could you please explain more about the lines in function decode_predictions especially the computation of bounding box?
Hi Adrian,
Thank you for this sharing. In addition, could you please let me know whether we can use this EAST text detector to recognize other languages like Spanish, Korea, Mandarin and so on?
Hey Danny, you should see my reply to Adam, the very first commenter on the post. I haven’t tried with non-English words but a PyImageSearch reader was able to detect Tamil text so I imagine it will work for other texts as well. You should download some images with Spanish, Korean, Mandarin, etc. and give it a try!
Hi Adrian
I noticed that the bounding box on rotated text wasn’t quite enclosing all of the text. I’ve calculated a more accurate bounding box by replacing lines 102-109 in text_detection.py with the following
# A more accurate bounding box for rotated text offsetX = offsetX + cos * xData1[x] + sin * xData2[x] offsetY = offsetY - sin * xData1[x] + cos * xData2[x] # calculate the UL and LR corners of the bounding rectangle p1x = -cos * w + offsetX p1y = -cos * h + offsetY p3x = -sin * h + offsetX p3y = sin * w + offsetY # add the bounding box coordinates rects.append((p1x, p1y, p3x, p3y))tom
Thank you for sharing, Tom! I’m going to test this out as well and if it works, likely update the blog post 🙂
Hi Tom,
thanks for sharing your code. I compared it to Adrians version and need to state that your coordinates in fact are a bit more precise (at least for my use case –> text detection from scanned pdf).
Therefore, thanks a ton.
Best regards,
Tobi
Hi Adrian,
Great work. I got this to work.
But I have one issue. Your prediction (inference) time is 0.141675 seconds. When I run it, I get 0.413854 seconds.
I am using a Pascal GPU (p2.xlarge) on AWS cloud. Do need to configure something else for faster predictions. What are you using for running your code ?
Thanks again.
Hakan
I was using my iMac to run the code. You should not need any other additional optimizations provided you followed one of my OpenCV install tutorials to install OpenCV.
Ok great Adrian thanks !
where do I find the ‘frozen_east_text_detection.pb’ model ?
You can find the pre-trained model in the “Downloads” section of the blog post. Use the “Downloads” section to download the code along with the text detection model.
Great article Adrian, incredible! Thanks a lot for your valuable tutorials! I am really looking forward to read the article about the text extraction from ROIs.
Thanks Antonio! I’m so happy you enjoyed the guide. I’m looking forward to writing the text recognition tutorial but it will likely be a few more weeks.
Hi Adrian
Wonderful progress as usual
But I have a question please
I want to build the model “`frozen_east_text_detection.pb“` myself. Are there some guidelines?
thank you for your effort
For training instructions, you’ll want to refer to the official EAST model repo that was published by the authors of the paper.
I do not know what to say
Thank you very much
Best of luck training your own model, Mohamed!
Thanks Adrian
Good luck to you always
Hi,
Thank you for the post and the codes!
I am using windows 7, python 3.6
I have openCV 3.2.0 installed in my machine. But I am not able to install openCV 3.4.2 or above. Is there any way to install it on my machine or do I have to install in virtual machine?
Thanks!
To be honest, I’m not a Windows user and I do not support Windows here on the PyImageSearch blog. I have OpenCV install tutorials for macOS, Ubuntu, and Raspbian, so if you can use one of those, please do. Otherwise, if you’re a Windows user, you’ll want to refer to the OpenCV documentation.
Hi, I am using windows7 too, and execute this code without trouble. Adrian Rosebrock, thanks by your code, this tutorial is awesome.
More details:
– Python 3.6.5
– Opencv 3.4.2
– Windows 10
Thanks Deiner 🙂
Hi, Adrian, thank you for your effort. when i run the project, i meet the problem ‘Unknown layer type Shape in op feature_fusion/Shape in function populateNet ‘. and in my computer ‘net = cv2.dnn.readNet(args[‘east’])’ should be replaced by the ‘net = cv2.dnn.readNetFromTensorflow(args[‘east’])’, i have installed the Opencv3.4.2, could tell me how to solve the problems? Thank you so much!!!
Hey Trami — have you tried using the cv2.dnn.readNetFromTensorflow function? Did that resolve the issue?
yes using cv2.dnn.readNetFromTensorflow still working. if your using same camera for two python files which calls as sub process , the opencv versions above 3.2 the camera release function doesn’t work after i mailed to opencv they told me to install opencv 4.0-alpha but couldn’t find a way to install in my anaconda environment after searching opencv 3.4.0.14 contains readNEtFromTensorflow and camera release function working
pip install opencv-python==3.4.0.14
thank you
You should follow one of my OpenCV install guides to install OpenCV 4.
Hi Adrian,
Why, scores and geometry’s shape are [1 180 80] [1 5 80 80]
oo,321/4=80
Hi Adrian
I made a few mods to the code and created a few different NMS implementations that will accept rectangles, rotated rectangles or polygons as input.
The net of the changes:
1. Decode the EAST results
2. Rotate the rectangles
3. Run the rotated rectangles through NMS (Felzenswalb, Malisiewicz or FAST)
4. Draw the NMS-selected rectangles on the original image
The code repo is here: https://bitbucket.org/tomhoag/opencv-text-detection/
I pushed the README to medium here: https://medium.com/@tomhoag/opencv-text-detection-548950e3494c
tom
This is awesome, thank you so much for sharing Tom!
My pleasure — thank you for the great post.
I split out the nms specific stuff into a PyPi package: nms
https://pypi.org/project/nms/
nms.readthedocs.io
Hello tom, how i can apply your work to the Tesseract OCR? Im having a trouble on how to extract the ROI of your work. Thanks! 🙂
Great article as always Adrian!
I was wondering something : in your Youtube video, the words “Jaya”, “the” and “Cat” are detected separately by the algorithm. Would it be possible to modify it so that the whole textline “Jaya the Cat” is detected in a single textbox?
Technically yes. For this algorithm you would compute the bounding box for all detected bounding box coordinates. From there you could extract the region as a single text box.
I’m not sure I understand correctly.
In the Figure 1 of this article, the left image shows two lines: “First Eastern National” and “Bus Times”. How could your method detect that there are indeed _two_ lines with 3 words in the upper one and 2 in the other?
Figure 1 shows examples of images that would be very challenging for text detectors to detect. You could determine two lines based on the bounding boxes supplied by the text detector — one for the first line and a second bounding box for the second line.
Thanks!
Hi adrain,
i have in run a code
please help me to slove this problem.
…
net = cv2.dnn.readNet(args[“east”])
AttributeError: module ‘cv2.dnn’ has no attribute ‘readNet’
Double-check your OpenCV version. You will need at least OpenCV 3.4.1 to run this script (it sounds like you have an older version).
i have 3.4.1 opencv version.
please give me some another suggestion
Did you install OpenCV with the contrib module enabled? Make sure you are following one of my OpenCV install tutorials.
From what I have tried you need at least opencv 3.4.2
I have the same issue
What version of OpenCV are you using?
I was getting the same error with opencv-python 3.4.0.12 on windows. The issue was resolved after upgrading opencv-python to 3.4.2.17.
Hi,
I also want to recognize detected text from the video.to do that I hope to crop the image with maximum ROI which we identified as words.then I pass this to tesseract OCR to recognize words. Can I know this method is ok to do words recognition?
Thank You
I’ll be covering exactly how to do this process in a future blog post but in the meantime I always recommend experimenting. Your approach is a good one, I recommend you try it and see what types of results you get.
Hi Adrian
is this possible to recognise the test
Once you’ve detected text in an image you can apply OCR. I’ll be covering the exact process in a future tutorial, stay tuned!
Is there any way to use the video text detecion using the Raspberry Camera V2?
Yes. Replace Line 102 with
vs = VideoStream(usePiCamera=True).start()Very intresting! It’s possible to convert in real text with OpenCV or I need to use OCR?
Thanks.
Once you’ve detected the text you will need to OCR it. I’ll be demonstrating how to perform such OCR in a future tutorial 🙂
It’s possibile OCR with OpenCV or you work with others like tesseract?
OpenCV itself does not include any OCR functionality, it’s normally handed off to a dedicated OCR library like Tesseract or the Google Vision API.
I would suggest adding a CRNN model on top of the east detector.
For anyone who is following along with this post, here is the link to the text detection + OCR post I was referring to.
How to print probability that this image has this much 99 percent probability it has text? or image has 0 percent probability that it does not has text?
Are you referring to a specific region of the image having text? Or the image as a whole?
Hi Adrian
I apologize for my inaccurate questions
But I would like to know why the attached form in the downloads is less accurate than the model in the warehouse recommended by the team. in this place:
(https://github.com/argman/EAST)
Have you modified something to comply with opencv?
The method I’ve used here is a port of the EAST model. As I’ve mentioned in the blog post the code itself cannot computed the rotated bounding boxes.
Hi Adrian,
Can you please help me out in understanding how i can break the bounding box to alphabets instead of full words ?
For eg if i have a number 56 0 08
I am able to do it using findcontours… but its not giving accuracy when the digits are very close. Two digits are being considered as one.
So the results i get is 56 0 and 08.. But it should be 5 6 0 0 8.
Can you please suggest some eay to tackle this
If your image is “clean” enough you can perform simple image processing via thresholding/edge detection and contours to extract the digit. For more complex scenes you may need some sort of semantic segmentation. Stay tuned for next week’s blog post where I’ll be discussing how you can actually OCR the text detected by EAST.
If you are interested in making your own model and import it to opencv, check this link.
https://github.com/opencv/opencv/issues/12491
Hello adrian, Your work is really amazing!! I’m getting some issues with final bounding boxes after nonMaxSupression. I’m getting almost all characters before supression, but in final result some characters are not considered in the bounding boxes because of supression algorith. So, I thought about taking only outer boxes(implementing own algorithm) But ‘rects’ have so many x-y co-ordinates i’m unable to get which co-ordinates are of one box and which are of the other boxes. Do you have any suggestion or solution for this?
The “rects” list is just your set of bounding box coordinates so I’m not sure what you mean by being unable to get coordinates belong to which box. Each entry in “rects” is a unique bounding box.
Hi,
The weights file you have used in this blog to show the inference was obtained by training on which dataset?
Be sure to refer to the re-implementation of the EAST model for more information on the dataset and training procedure.
Hey Adrian,
Do you know if this same EAST algorithm will be able to locate the bounding boxes of handwritten text?
Thanks
Hey Adrian,
The article was really helpful. I was wondering if you could guide me with segregating handwritten text and machine printed text in a picture of a document.
Hello, I was wondering if there is a version that would output the actual text observed. Thanks!
Yes. See this tutorial on OpenCV OCR.
When you run Adrian’s text_Detection.py using Python 3.6 and OpenCV 3.4.3 on Windows 10,
If the line, <> shows an error saying cv2.dnn does not have readNet as a valid function, then you can do the following and eliminate the error:
Open Windows command Line and enter pip install opencv-contrib-python
I tried this and it works.
It sounds like you are using an older version of OpenCV. Can you confirm which version of OpenCV you are using?
Hi Adrian,
It’s great blog post.
Currently, I’m working on a project that is related with detect object in technical drawing image (eg. CAD scan image). So I need to detect lines, numbers, text in image.
I tested with your code in this blog. But the accuracy seems not good.
If you have any idea to improve, please share with me !
image example here: https://imgur.com/a/PN5J6CJ
Thanks
Adrian, how did you freeze the model, ( convert .ckpt to .pb )?
Are you asking how to convert a TensorFlow model to OpenCV format? If you can clarify I can point you in the right direction.
When training EAST, the created model is in .ckpt, how to convert that .ckpt model to .pb so that I am able to use in your opencv version of EAST?
Refer to the official OpenCV documentation — they include scripts to covert the model to make it compatible with OpenCV directly.
I found CRNN model a great addition on top of east detectors to make full OCR. I had trained it on custom data and it works well.
original paper:http://arxiv.org/abs/1507.05717.
https://github.com/vinayakkailas/Deeplearning-OCR
Thanks for sharing, Vinayak!
The model has already been implemented and trained in this post. Do you mean how to train the EAST model from scratch?
Hi!
Thanks for sharing the frozen model for east text detector.
I am currently working on a project where I need to use the tensorflow Lite model for mobile application. To convert the frozen model to tf lite I need to know the names of the input and output tensors. Could you please provide me with the same?
Thanks
Hey Ritika — I would suggest reaching out to the authors of the EAST paper model (linked to in this blog post). They will be able to provide more suggestions into the model and layer naming conventions.
Thanks for sharing. I‘m using opencv3.4.1 with python on Mac, is it ok for the version requirement?
Yes, OpenCV 3.4.1 should be sufficient.
Hi Adrian,
thanks so much for this post and in general this whole website. I’m really getting in love with computer vision and will try to learn more. As of so I have two particular questions regarding your code or to be more precise about the math behind.
My questions refer to the first part of your post (text detection in a single image)
1. You wrote in one of your comments (code line 87):
“compute the offset factor as our resulting feature maps will be 4x smaller than the input image”
Where did you get this information and why is it?
2. Can you explain a bit more detailed how the formula in line 102/103 works (endX, endY)?
I know that we can use the sinus and cosine functions to find the coordinates but I don’t know how this exactly works. I couldn’t find some good explanations for this in the web. Probably you have a good resource?
Thanks in advance.
Best regards,
Tobi
Take a look at the EAST publication that I linked to in the post. You also might want to look at the architecture visualization and see how the volume size changes as data passes through the network. As for your second question, I think you’re asking where to learn trigonometry? Let me know if I understood your question correctly.
Hi Adrian,
thanks for your answer, I will check the paper.
Regarding my second question, yes it’s about learning the trigonometry. I already checked some resources where I learned (refreshed) a bit about cosine and sine but I couldn’t transfer this knowledge to the formula you used. Maybe you have some better resources?
Best regards,
Tobi
Hi,
Thank so much for posting this and sharing your knowledge. I love reading your post. This code works very well.
I was wondering is there any way to detect blocks for a single line at a time.
Thanks for posting! Great article. One question, could I use EAST text detector to only detect digits?
EAST doesn’t provide you with any context of what the text actually contains, only that text exists somewhere in an image. Therefore, no, you cannot instruct EAST to detect digits. Instead, you would want to perform text recognition and then use Tesseract to return only digits.
Could I replace the training data (presumably English text training data) with digit (math formula training data) and train the same architecture? My purpose is to build an app that can detect then recognize and grade math worksheet problems from photos.
Presumably yes but you’ll also want to refer to the official EAST GitHub repo that I linked to inside the post.
Hi, Adrian
Thanks for sharing, I have problem when I run the codes on my Pi with webcam suddenly my Pi restarting
please help me to slove this problem 🙁
It sounds like your Pi may be becoming overheating and is restarting or there is some sort of physical issue with your Raspberry Pi. Can you try with a different Pi?
Thanks Adrian for sharing such grate info.
I want to read the detected text from live video and for this I thought of first separating the frame in which text is detected and then apply OCR on frame to read the text. But I observed to identify the frame it is very slow and time consuming process.
Could you please suggest fast solution to read text from live video.
You would want to push the computation and forward pass of the network to your GPU but unfortunately that’s non-trivial with OpenCV and CUDA right now. I imagine that will be possible in the near future.
Great Work Brother.
You are doing awesome job.
Can you please provide c++ code as well. Because I am unable to understand the code in python, also, I am not getting any tutorial of Scene Text Detection in C++.
Please help…
I linked to the C++ implementation from my original blog post. Make sure you’re reading the full post.
Hi Adrian,
Thanks for this great post. I have set up an environment using Python 3.7.1 and OpenCV 3.4.3.18 (from your pip install opencv post). The script runs like a charm but rather slow:
[INFO] loading EAST text detector…
[INFO] text detection took 0.569462 seconds
I run this on a Microsoft Surface Pro 4 Windows 10 in the most minimal virtual env required for this script. Why is it on Windows10 that slow compared to your benchmark?
Thanks for your earliest reply.
Wim
Hey Wim — I’m not sure why the code would be so much slower on a Surface Pro. I’m not personally familiar with the hardware.
Hi Adrian,
Thank you for such a great blog.
I am currently working on text detection on ATM slips.
The texts are very small and when I pass the whole slip into EAST, It does not give a correct detection.
I wanted to ask:
1. How many images and annotations will be needed to train EAST.
2. Can you please suggest me few datasets similar to ATM slip font.
3. Can you please suggest me few free text annotation tools.
I’m not sure of any existing ATM slip dataset. You may need to curate one yourself. Good annotation tools include imglab and LabelMe/LabelImg.
Hi Adrian
Thanks for sharing, please what is the CNN architecture used ?
For more details on the EAST CNN architecture be sure to refer to their official GitHub.
Adrian I mean that you did not use neither “LeNet” , “AlexNet” , “ZFNet” , “GoogLeNet” , “VGGNet” or RestNet ?
Again, kindly refer to the GitHub link and associated paper I have provided you with. Read them and your question will be answered.
Hi Adrian! Thank you for this post. You’re awesome!
I’m trying to compare my last model with the .pb model that you’re using here. But my last model has the following files: foo.data, bar.index, checkpoint and .data-0000-of-0001. How I get the .pb file from these files to then pass it through the method: cv2.rnn.readNet(“my_old_model.pb”)?
Thank you!
You need to convert your TensorFlow model to OpenCV format using OpenCV’s TensorFlow conversion tools. To be honest I’ve never tried that process so I cannot give you instructions on how to proceed.
Hi Adrian,
Thanks for sharing this work.
I was wondering is there any way to print the text and digits that are detected from the image after extracting the bounding box using array slicing.
Yes, see this tutorial where I combine the EAST text detector with OCR.
Hi Adrian,
Thanks for this and many other great posts! Learning a lot.
I wonder if there is a way to get more precise bounding boxes around words (or even letters).
I can see on your demo that EAST is pretty powerful for detecting the ‘general’ region where the text lies (and then we have powerful tools to infer the ‘content’ of the text from there), but if I wanted to have ‘coordinates’ or ‘height’ of the letters or words,
the current code would not be enough.
Is there a way to play with this?
You can just extract the startX, startY, endX, endY from the code. Do some simple coding, like center points (i.e: (startX + endX) / 2 ))
Height would be just (endX – startX) etc.
Hopes this help
Hi, thanks for writing this one. Are there any way that I can retrain this network?
The current model doesn’t work super well on my test images.
Thanks
San
You would need to refer to the documentation provided by the EAST text detection GitHub repo.
Hi Adrian,
Very good article, and very good detail explanation.
I implement all this on my raspberry pi 2 model B. I got time use around 14 seconds for an image text detection.
is that normal?
Yes, that is entirely normal. The Raspberry Pi is too underpowered to run these deep learning-based text detection models.
Thanks for such a great article.
I need some help getting text within each text boundary.
Any ideas how can we do that ?
See this tutorial.
Thanks for the amazing article!
i am getting this error
i am running this in ubuntu18.04, py3.6
: cannot connect to X server
i am unable to view the output image
Are you SSH’ing into your system? If so, make sure you enable X11 forwarding:
$ ssh -X user@your_ip_addressHi Adrian,
My laptop’s Cpu is getting used 100% after running text detection video script .. is it normal?
Absolutely normal. The deep learning-based EAST text detector takes up quite a bit of CPU cycles.
Hi,
we are facing the following errors while executing the code. please help out as soon as possible.
orig = image.copy()
AttributeError: ‘NoneType’ object has no attribute ‘copy’
Double-check your path to the input image. The path is invalid and “cv2.imread” is returning “None”. You can read more about NoneType errors, including how to resolve them, here.
Thank you very much for your good writing and code.
If the size of the input image is 672 x 512, how do you think about resizing the width and height to the nearest size while maintaining a multiple of 32?
I am wondering which case in the resize case below shows the best result.
– case 1: 640 x 480 (both width and height are multiples of 32 and resize to nearest size)
– case 2: 640 x 640 (the width is a multiple of 32 and the height resizes to the same size as the width)
– case 3: 480 x 480 (the height is a multiple of 32, resize to the same size as the width)
– case 4: 320 x 320 (the resize size used in your code)
Hello,
Thank you for this tutorial. I’m willing to use another frozen model and i would like to know how to choose the output name?
Where do come from? (not found in the EAST publication) :
“feature_fusion/Conv_7/Sigmoid”,
“feature_fusion/concat_3”
Thank you.
Those are from the model architecture themselves. They were defined when actually implementing the architecture itself.
Hi
What hardware are you running please?
My Raspberry Pi 3B takes 17 seconds to do a single image detection from a jpeg file, yours takes 0.14 seconds.
Cheers
Steve
I’m using an iMac Pro with a 3Ghz Intel Zeon W processor. The Raspberry Pi will be FAR too slow to run this code (it just doesn’t have enough computational horsepower).
Hi,
Can i opencv-3.3.0 to run this code. Or anyways to upgarde version 3.3 to 4. Since i have already installed 3.3.
You’ll need either OpenCV 3.4 or OpenCV 4 for this tutorial. Make sure you upgrade from OpenCV 3.3.
I’m having a error when i try to run text_detection_video.py
————–
usage: text_detection_video.py [-h] -east EAST [-v VIDEO] [-c MIN_CONFIDENCE]
[-w WIDTH] [-e HEIGHT]
text_detection_video.py: error: the following arguments are required: -east/–east
————–
that’s the error i got when i run the code. please answer thank you 🙂
It’s okay if you are new to Python and command line arguments but you need to read this tutorial first. From there you’ll understand command line arguments and be able to execute the script.
hi how can i use my own model, the pb file , for detection. i can the east argument, bu it doesn’t work
Hi Adrian,
A very useful knowledge base. Could you please guide me on how to find the contours of the detected text. so that i can mask the same
See this tutorial where I extract the bounding box of the text and pass it through the OCR engine. Once you have the bounding box you can mask the text.
Thanks for the quick reply Adrian.
The problem i am trying to solve is to extract graphics and text separately from the image and process them. While the suggested approach works perfectly for text recognition. I want the image with just the graphics to process them into vectors.
Using the bounding box to erase the text causes at times parts of graphics to be erased as well. So i was hoping to find a way of getting the edge contours of the identified text in some way to then erase them
You’re trying to compute a mask for the actual text then? That sounds more like an instance segmentation problem. I don’t know of any instance segmentation models for pure text though, you may need to do some research there.
# compute the offset factor as our resulting feature
# maps will be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
Hi there, why do you use 4 times here?
Because the input spatial dimensions were reduced by a factor of four. We need to obtain the offset coordinates in terms of the original input image.
Thanks very much for these interesting blogs.
But I am a little bit disappointed in openCV 🙁 as this text detector doesn’t perform well on angled or small text. And sometimes tesseract can’t recognise or makes no sense as the text detector couldn’t make an accurate region proposal in the first step.
I made some improvements based on your code by letting tesseract search a little bit around the proposed text region. It is more accurate but a bit less efficient.
your code has a small bug. The bounding box will be overflow in some cases. To that you should do
startX, endX = np.clip([startX, endX], 0, W)
startY, endY = np.clip([startY, endY], 0, H)
after
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY – (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX – w)
startY = int(endY – h)
how can i train my own network using EAST algoritham.?
Refer to the EAST creators official GitHub page.
Hey,
Thank you for the great Article. It helped me a lot in learning. This works perfectly for the normal orientation. Please tell me what changes do I need if the letters are upside down or sideways. I
How to unfreeze frozen_east_detection.pb into actual model. I actually wanted to see the coding behind it. I am a beginner in this field. Wanted to know what is happening behind the scene.
The EAST detection model was pre-trained. If you’re new to computer vision and deep learning I would recommend reading through Deep Learning for Computer Vision with Python so you can learn how to train your own networks.
Hi ,Adrina…can i print the detected text on python shell+?
Yes, take a look at this tutorial on OpenCV OCR.
how can i merge my own trained data into this work ?
Refer to the GitHub repo referenced in the body of the blog post. Follow the instructions from the authors (again, in the GitHub repo I linked to).
Hi Adrian,
This is the first neural net I’ve seen where the size of the image just had to be a multiple of a number rather than a specific dimension. I’ve looked through the East Github page and am not seeing the mechanism that allows that to happen.
I’ve tested this code out on images of size 8384 x 1600 (email ad) and it works beautifully, so clearing it isn’t just resizing to 32 x 32.
Is this so obvious that I’m overlooking it? Do you know of any papers or documentation that I could look into?
Good day! How can i get the result of the captured character in the video? Because i want to put it in a text file. Hope you can answer me, thank you :).
No problem, just refer to this tutorial.
How about if I want to send the captured characters in the database, how is it?
That’s not really a computer vision problem. That’s a general programming/engineering problem. I would recommend you take the time to read up on Python programming and basic databases. From there you can continue with your project.
Sir where can i find the dataset for this?
You mean the dataset the EAST model was trained on? Refer to the author’s GitHub page which I’ve linked to from the body of the post.
Greetings Adrian,
Thank you for writing a great article. This is the first time i have worked with neural networks and while i was going through your tutorial i found out that the dimension of the input image should be a multiple of 32. I referred the IEEE Paper of the EAST Algorithm but i couldn’t figure out why the input has to be a multiple of 32. It would be great if you have any documentations regarding this.
Thank You.
If I am only interested in number detection(from 0-9), is there any way for me to retrain the model? Or how do I eliminate other texts except numbers with the current model?
Take a look at the Tesseract documentation. There is a set of parameters you can supply to only extract digits (but I can’t remember it off the top of my head, sorry).
Any idea why the performance of text detection is very bad? The text is clear, since I’m using a screen shot of my phone. The whole image has loads of text (image screen shot from a calendar) but I only get on 1 confidence/match. I’m using full res image: 1920 by 864.
Great article. I’ve learned so much from in you in a matter of days. What about detecting blocks of text as one object? For example, address labels on an envelope. From this article I feel confident that I could detect individual words (and maybe lines), but could you treat the entire address label as a single rectangular object and train the model to detect that?
You would want to define a heuristic to group them, such as “all bounding boxes within N pixels of each other should be grouped together”. Loop over the bounding boxes, check to see if any are close, and if so, group them.
Brilliant read with so much detailed information!
Following from the previous question. How would one structure the code to group bounding boxes for individual text detection and output?
After all text been detected in a natural image.
Thanks in advance
What do you mean by “group bounding boxes”? How should the bounding boxes be grouped?
Great article but can you provide the dataset for static text detection or any source where i can get it?
Great article Adrian, and so useful !!
In your opinion is it possible to use EAST model as a base and put a classification layer on top of it. Then train it to classify detected text into one of few trained classes – say whether the detected word is “dog” or “cat” ?
A lot like it is done with image classification…
That would be overkill and wouldn’t work well. Instead, follow this tutorial on OpenCV + OCR. Just OCR the word itself.
Hi, I’m running this code and it’s executing without any error.
However, even in the simplest images, the scores being predicted are in the negative power of the exponent. Everything is coming to be lesser than 0.5 (default min confidence).
Can anyone please help?
Could you please help me, I Always get the text:
orig = image.copy()
NameError: name ‘image’ is not defined
Can you tell me where I can find my mistake?
Another question: I was searching for a Programm which helps me recognizing the contours of some letters. If the Programm recognized the conture I will teach him a lane to rewrite the letter. Is this possible with EAST?
It sounds like you’re copying and pasting the code. Don’t do that. You likely inserted an error accidentally when copying and pasting. Use the “Downloads” section of the post to download the code.
It was really a great and amazing project. I just want a little help as i am not that much expert in python coding for image processing. Can anybody help me to show the text that is being detected???
You can follow this tutorial.
Hi Adrian!
Has anybody done optimization of your implementation using Cython? Do you know?
How do we store the detected text by time frame?
Like
Time: 0:39:43
Text: Prey
The timestamp of a video? Or a real-time video display?
Hi I need to build a model to extract handwriting from images, please suggest me how much will i be benefited if i consult the described model or if not please suggest that as well.
Thanks in advance
Vivek
Trying to create a handwriting recognition system from scratch can be super challenging (and not something I really recommend). Have you tried using an off-the-shelf solution such as Google Vision API yet? It includes a text recognition component which may work for you.
Hi,
I i’m new to opencv (and using open cv sharp :s) and managed to implement you code in c# – but… I have an issue and wondered if you knew in general why the scores and geometry rows and cols are both -1
I have tried loads of different images.
Any thought would be great.
Thanks
Congrats on implementing the text detector in C#, Mick! However, I’m not sure why that would happen. It may be an issue with the C# OpenCV bindings but I’m not familiar with the C# + OpenCV bindings so unfortunately I don’t have any suggestions on the issue.
OK – Thanks anyway. I just followed your tutorial and did it in python to see it working and to get my head into the theory and it’s very cool 🙂
Can you “compile” python into a DLL or such, or is it interpreted only (this is the first time I’ve used it, in case that wasn’t very obvious :))
I’m writing an app for our factory that has to read some numbers on a box about 4 or 5 times a second. Will probably use a “simpler” OCR for that, just playing for the mo.
Mick.
Hi Mick,
Can you share the C# Code with me? I cant get it running with C#. That would be great.
Thank you
In response to the -1 in the c# code, there is actually something wrong width the Width/heigth property in the opencvsharp wrapper. If you use the Property Size() and than X and Y it works fine.
Hi Mick,
would you please share your C# implementation with me? It would be amazing to have it and to know how it works in C#!
Thank you
hello Adrian
after the text detection how do I convert the data into text like if on the image it say hello i need the output to be hello so i can execute functions after comparision of the 2 strings please help
See this OpenCV OCR tutorial.
Hi Adrian,
Thank you very much for such an amazing course! You’re Genious!
Could you please help, how to use EAST text detection with GRAYSCALE image?
Many thanks.
Just stack the gray image 3 times to create a 3-channel image:
image = np.dstack([gray, gray, gray])Thank you very much!
You are welcome!
Hi Adrian this is great content! One question though for my application it would be interesting to understand how to generate a boolean that indicates if there is any text at all in the image. What would you suggest for this application?
Loop over all text detections and check to see if there is any detection that has a > X% confidence (you define X% yourself). If so, set the boolean to True.
Good Afternoon Adrian;
Loads of Love from India.
I really enjoy reading your articles, I new to computer vision and have some doubts.
Can you tell me what are these rows and columns in the scores volume as score contains the probability whether text is present or not.
What is xdata0,xdata1,xdata2,xdata3,xdata4.
and my last doubt is I did not understood your step of calculating h,w, endx, endy, startx, starty.
Regards
Satyam Sareen
hi adrian i want to try this code OpenCV Text Detection (EAST text detector) and i have downloaded it from here, but where is the datset? can you please provide me the dataset?
Kindly refer to the blog post where I link you to the authors of the EAST paper publication and the dataset they used.
Hi Adrian,
i would like to know how to make and get bounding boxes of single characters instead of the whole length of characters.
ex= Adrian (get bounding boxes for A, D, R, I A, N )
your help is much appreciated
Thanks
HI Adrian , First of all thanks for the brilliant post , I want to detect the text only on the number plates leaving the rest , how i could achieve this .
Thanks in advance
I cover ANPR/ALPR inside the PyImageSearch Gurus course. I suggest you start there.
How can I have a text detection and text recognition in one poject?
please I need your help!!
You can do that using this tutorial.
Great post Adrian. Love your work as always.
I am trying to use the c++ version of this (provided by opencv) to detect lines, although I am having trouble understanding that for line detection. Could you please help me on how I can detect lines of words using your script? Probably I can then try to convert it into c++
Hey Adrian,
For some reason single letters or single characters are not detected.
Is there a way to get the EAST text detector to detect single letters?
Thanks so much for the tutorials, They are ace!
Hi Adrian,
Thank you very much for the brilliant tutorial. I learnt a lot from it and was able to run it successfully on individual images.
If I want to run similar OCR on a full pdf file and save the recognised text into a word document, how should I approach it? Did you already do a tutorial on this?
I previously used just pytesseract ocr which was not very efficient. The OpenCV and tesseract combination you used here was much better. I want to implement this for a pdf now and see how much better the result would be.
Thanks,
Vijay
Have you tried this tutorial?
Hi Adrian,
Does EAST have problems with character such as ‘#’,’-‘,’_’,’\’,’/’,'[‘,’]’, and so on? I’d like to detect sequences of letters, numbers and characters, often containing German abbreviations.
The program throws several overlapping boxes for a single sequence. I tried to avoid this with overlapThresh=0.00001, but this hasn’t changed anything.
Hey adrian, thank you very much for this post. I’m learning a lot from you.
Please could you tell me after getting the bounding boxes, how to get/display the detected text?
Thank you veryyyyyyy much
See this tutorial on OpenCV OCR.
Hey, I’m trying to implement your code, however, I have an issue where no module of cv2 is detected. Also, it sometimes keeps outputting AttributeError: ‘NoneType’ object has no attribute ‘copy’
Any help would be appreciated, thanks!
Double check the path to your input image as it’s likely incorrect causing “cv2.imread” to return “None”.
Great article and just at the right time when I am searching to do a project on text detection. I have one question. You have included frozen_east_text_detection.pb in the downloads. Can you please tell me the source of this file?
Hey Sovit — I’ve answered that question both inside this blog post and in multiple responses to readers questions. Kindly take the time to read them, thanks 🙂
Thanks for the quick reply. And yeah! found it in the blog post.
Thank, for sharing such a relevant concept. can you how to use east in case of notebook.
You mean a Jupyter Notebook? Yes, just supply the path to the trained EAST model.
H Adrian,
great work must admit!
I’m trying for my research to use EAST dnn under C++. However, I’m stack on “readNetFromTensorflow”. The reason for this is lack of pbtxt file. I already did some research about how to generate for opencv the .pbtxt file. However, the best way is to get the original one frozen together with .pb.
Do you have access to pbtxt file for EAST model?
I think this will help many others people interested to use this model!
Hi Adrian,
Great work, really appreciate it. I am trying to use this to crop out words from handwritten documents, and i want to tell you it is working great. There is one small issue i am facing, small words or single letter words.
For example ‘ My name is Ajinkya. I work as a Developer’. So if i have a document with the above text written on it, so words like ‘is’, ‘I’, ‘as’, ‘a’ are not being recognized. Can you please suggest me how can i make the detection better? I have tried playing with the height and width.
Thank you
Hi
how is it possible to print the detected text ???
Yes, see my tutorial on OpenCV OCR.
But frame rate drops on webcam live feed
What is the solution ???
That’s because the model is too computationally expensive to run in real-time on your CPU. You would need to utilize a GPU.
hi,
I need to detect fonts that are not horizontal. Is there a good solution?
Thanks in advance.
Hey Max, I know that Tesseract supports vertical detection of chinese characters, but you will need to look at the list of languages that tesseract supports to see if they support vertically aligned characters in the language you want.
Hello everyone,
Firstly, thank you Adrian for your solutions.
I am trying to adapt it for invoices case.
The results are pretty good but some important text I want to extract are not boxed.
The shape of my image is 2475×3504. I change default with and height to 2560 x 3584 but it is not enough.
The text not boxed is on a a grey/dark background.
Do you have any idea?
It would be easier if I could sent you an example.
Thank you
Thanks for the contents.
One question.
So, now we can detect the text and draw the boxes around the text. What should I do if I want to get the detected text values? For example, in the Arbor CAR WASH image, once detecting the text, how can I get the detected text out as a string value of “Arbor CAR WASH” ?
See this tutorial.
Do you have any examples of recognizing text with a pre-trained model like mobilenet or similar?
Why to convert the image into blob before passing into model. I tried input image directly pass into in forward method, it throws me error. What is the reason to convert into blob.
The blob format is required as it performs preprocessing to the image. You can read more about it here.
How do you run this like from only one .py file? Not save the text.py file then have to run from command prompt?
Hello, Adrian, can you please provide the script that you used to convert the trained TensorFlow model into .pb format.
Sorry, the model was already converted when I wrote the post.
Thank you vey much for this helpful tutorial.
I jus have one query. I tried implementing it on an Image with Arabic and English text and as expected it only detected the English text. Would you please give me an idea on how I can solve this and where should I start?
Thanks a gain
You need to change the language on the config line, you will see where it says eng, you need to change it to whatever tesseract’s name for arabic is.
I couldn’t install the imutils package and couldn’t import non_max_supression. please help me
You can install “imutils” using the following command:
$ pip install imutilsHi, How can i get the texts which are detected ? I read a comment where you told you would be working on an article demonstrating it
I think you’re referring to this OpenCV OCR tutorial.
Hey Adrian, I read in the responses above that some people asked you how to apply this to other languages, such as chinese. You told them to try it and get back to you.
I tried it and presently I’m getting worse results than just sending the unprocessed image to tesseract.
I opened paint and typed 我叫麦瀚, saved as a jpg with a white background.
Then I edited the language in the config variable of your program to search for simplified chinese characters as per tesseracts language naming conventions.
config = (“-l chi_sim –oem 1 –psm 7”)
I ran the program and got incorrect boxes and incorrect chinese results.
OCR Text
============
我 吊 志日 时
You may note that there are five characters in this result, compared to the four characters from the picture (我叫麦瀚) and only the first character was correctly detected.
I only edited the one line of your program i mentioned above, do you think I have forgotten to edit some critical part of your program?
Do you have any advice on how to tweak this program for better results on non english character sets?
I want to OCR hardcoded chinese subtitles from chinese TV shows so that I can easily look up words I don’t know. I am hoping to use your example as a stepping stone towards that goal.
Thanks for sharing the results, Michael. I’m not sure why that may be without digging into more detail with it. I’m planning on doing more OCR content soon, including OCR in non-English languages, so be sure to check back then!