Table of Contents
- Inside Look: Exploring Ollama for On-Device AI
- Introduction to Ollama
- Ollama as a Command Line Interface Tool
- History and Contextual Awareness
- Getting Started with Ollama
- Managing Models with Ollama
- Streamlining Operations and Interaction with Ollama
- Context Awareness in Ollama CLI
- Integrating a Custom Model from Hugging Face into Ollama
- Ollama Python Library: Bridging Python and Ollama with an API-like Interface
- Installation
- Usage
- Streaming Responses
- Comprehensive API Methods with Examples
- Customizing the Client
- Ollama with LangChain
- Bonus: Ollama with a Web UI Using Docker
- Summary
Inside Look: Exploring Ollama for On-Device AI
In this tutorial, you will learn about Ollama, a renowned local LLM framework known for its simplicity, efficiency, and speed. We will explore interacting with state-of-the-art LLMs (e.g., Meta Llama 3 using CLI and APIs) and integrating them with frameworks like LangChain. Let’s dive in!

This lesson is the 2nd of a 4-part series on Local LLMs:
- Harnessing Power at the Edge: An Introduction to Local Large Language Models
- Inside Look: Exploring Ollama for On-Device AI (this tutorial)
- Lesson 3
- Lesson 4
To learn how to interact with Ollama and integrate it with tools like LangChain for enhanced conversational AI applications, just keep reading.
Introduction to Ollama
In our previous blog post, we conducted an extensive exploration of various local LLM frameworks. We introduced the concept of Language Model Locals (LLMs) and discussed the growing need for such models that can operate independently on local machines. We identified around 8-10 frameworks that not only facilitate chatting with LLMs locally through visually appealing UIs but also support retrieval-augmented generation with documents. Moreover, these frameworks allow for the fine-tuning of models on our datasets. Each framework we discussed offers unique features, although many share some overlapping capabilities. This recap sets the stage for today’s focus: diving into Ollama, one of the popular frameworks highlighted previously. We will explore how to set up and interact with Ollama, enhancing its functionality with custom configurations and integrating it with advanced tools like LangChain for developing robust applications.
Overview of Ollama
Ollama stands out as a highly acclaimed open-source framework specifically designed for running large language models (LLMs) locally on-premise devices. This framework supports a wide array of operating systems (e.g., macOS, Linux, and Windows), ensuring broad accessibility and ease of use. The installation process is notably straightforward, allowing users from various technical backgrounds to set up Ollama efficiently.

Once installed, Ollama offers flexible interaction modes: users can engage with it through a Command Line Interface (CLI), utilize it as an SDK (Software Development Kit), or connect via an API, catering to different preferences and requirements. Additionally, Ollama’s compatibility with advanced frameworks like LangChain enhances its functionality, making it a versatile tool for developers looking to leverage conversational AI in robust applications.
Ollama supports an extensive range of models including the latest versions like Phi-3, Llama 3, Mistral, Mixtral, Llama2, Multimodal Llava, and CodeLama, among others. This diverse model support, coupled with various quantization options provided by GGUF, allows for significant customization and optimization to suit specific project needs.
In this tutorial, we will primarily focus on setting up Ollam on a macOS environment, reflecting our development setting for this and future posts in the series. Next, to tap into the capabilities of local LLMs with Ollama, we’ll delve into the installation process on a Mac machine.
Installing Ollama on a MacOS
Installing Ollama on a macOS is a straightforward process that allows you to quickly set up and start utilizing this powerful local LLM framework. Here’s how you can do it:
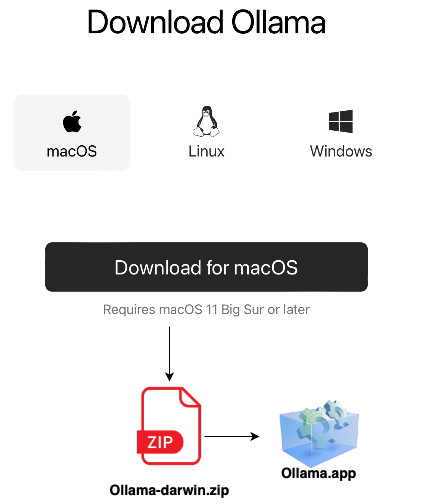
- Download the Installation File
- Navigate to Ollama’s official download page.
- Select macOS as your operating system. This action is illustrated in the diagram below, guiding you through the selection process.
- Launch the Installer
- Once you have downloaded the file, you will receive a ZIP archive. Extract this archive to find the
Ollama.app. - Drag and drop the
Ollama.appinto your Applications folder. This simple step ensures that Ollama is integrated into your macOS system.
- Once you have downloaded the file, you will receive a ZIP archive. Extract this archive to find the
- Start the Application
- Open your Applications folder and double-click on
Ollama.appto launch it. - Ollama will automatically begin running in the background and is accessible via
http://localhost:11434. This means Ollama is now serving locally on your Mac without the need for additional configuration.
- Open your Applications folder and double-click on
- Verify the Installation
- Open your browser.
- Type
http://localhost:11434and press Enter. If Ollama is running correctly, you should see a confirmation that it is running.
This installation not only sets Ollama as a local LLM server but also paves the way for its use as a backend to any LLM framework, enhancing your development capabilities. In future discussions, we’ll explore how to connect Ollama with AnythingLLM and other frameworks, utilizing its full potential in the local LLM ecosystem.
In the next section, we will review how to engage with Ollama’s model registry and begin interacting with various LLMs through this dynamic platform.
Ollama’s Model Registry: A Treasure Trove of LLMs
Ollama’s model registry, accessible at https://ollama.com/library, stands as a testament to the platform’s commitment to ease of access and user experience. It maintains its own curated list of over 100 large language models, including both text and multimodal varieties. This registry, while reflecting a similar diversity as the Hugging Face Hub, provides a streamlined mechanism for users to pull models directly into their Ollama setup.
Highlighted within the registry is Llama 3, an LLM recently released by Meta has become a crowd favorite with over 500,000 pulls, indicative of its widespread popularity and application. Phi-3, with its 3.8 billion parameters, is another feather in Ollama’s cap, offering users Microsoft’s lightweight yet sophisticated technology for state-of-the-art performance.
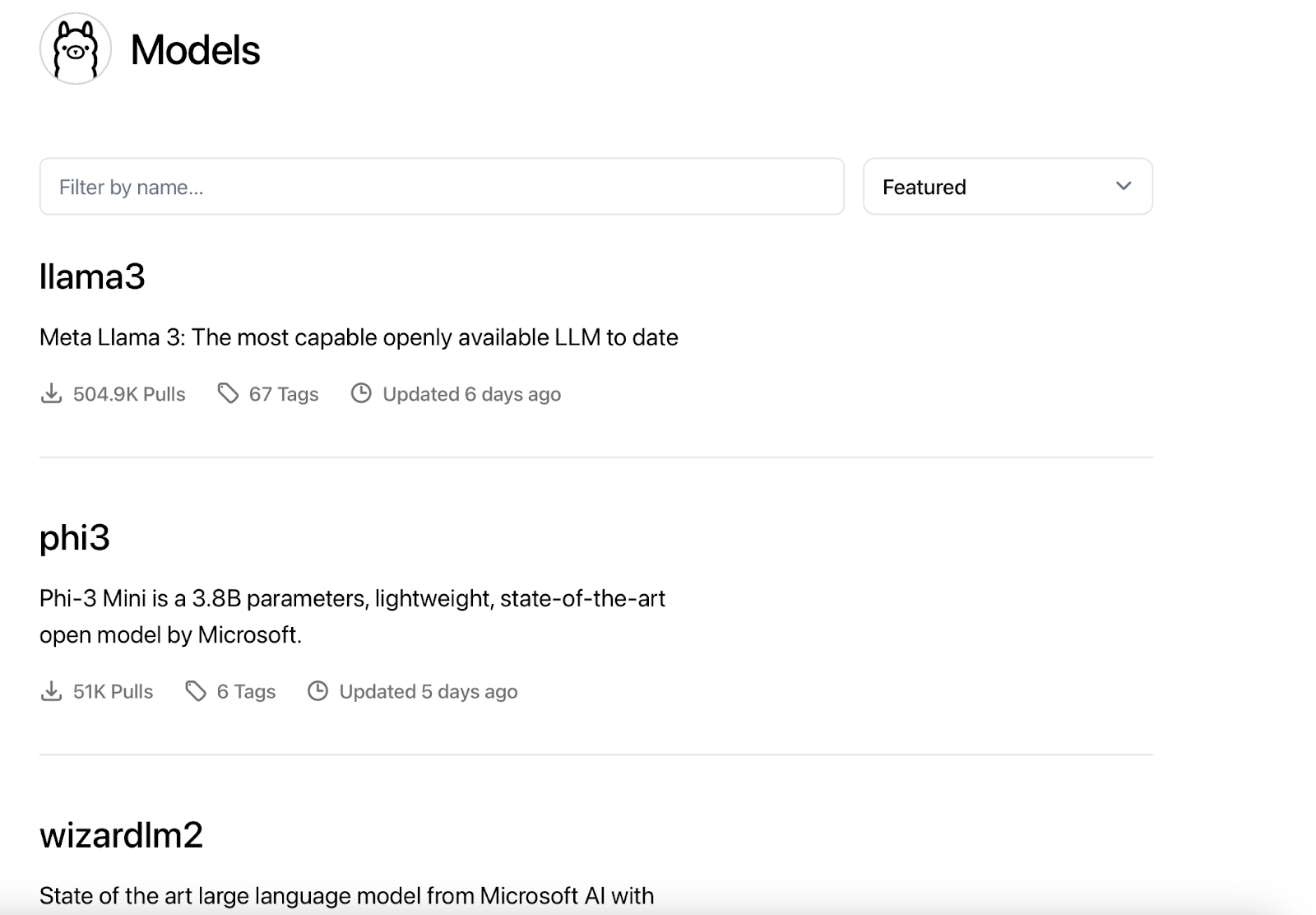
Ollama’s registry is not just a repository; it’s a user-centric platform designed for efficiency. It syncs seamlessly with Ollama’s system, allowing for straightforward integration of models like the versatile Llava for multimodal tasks. This synchronization with Hugging Face models ensures that users have access to a broad and diverse range of LLMs, all while enjoying the convenience and user-friendly environment that Ollama provides.
For developers who frequent the Hugging Face Hub, Ollama’s model registry represents a familiar yet distinct experience. It encapsulates the essence of what makes Ollama unique: a focus on a seamless user journey from model discovery to local deployment.
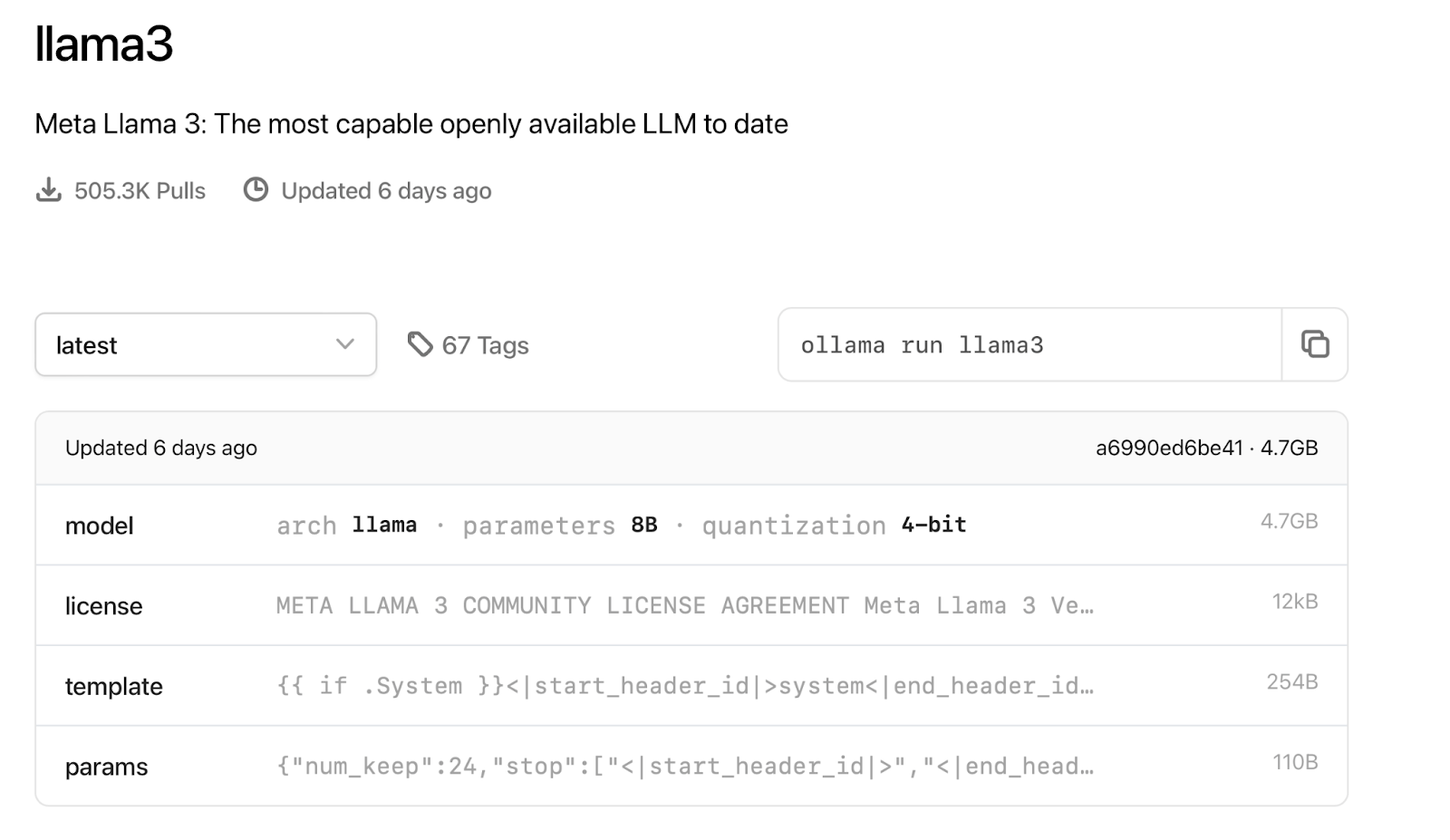
Moving on to the Llama 3 model in the Ollama library, you’re met with a variety of options showcased through 67 tags, indicating different model configurations, including various quantization levels (e.g., 2-bit, 4-bit, 5-bit, and 8-bit). These also encompass instruction-tuned versions specifically optimized for chat and dialogue, indicating Llama 3’s versatility. Ollama sets a default tag that, when the command ollama run llama3 is executed in the terminal, pulls the 8-billion-parameter Llama 3 model with 4-bit quantization.
The various versions of Llama 3 available in the Ollama model library cater to a range of needs, offering both nimble models for quick computations and more substantial versions for intricate tasks. This variety demonstrates Llama 3’s successful adaptation to different quantization levels post-release, ensuring users can select the ideal model specification for their requirements.
The tags allow users to fine-tune their Llama 3 experience, whether they are engaging via CLI or API. They include pre-trained and instruction-tuned models for text and dialogue.
For more detailed instructions and examples on how to utilize these models, please refer to Ollama’s official documentation and CLI commands. These provide straightforward guidance for users to run and interact effectively with Llama 3.
Ollama as a Command Line Interface Tool
In this section, we explore how to effectively use Ollama as a command line interface (CLI) tool. This tool offers a variety of functionalities for managing and interacting with local Large Language Models (LLMs). Ollama’s CLI is designed to be intuitive, drawing parallels with familiar tools like Docker, making it straightforward for users to handle AI models directly from their command line. Below, we walk through several key commands and their uses within the Ollama framework.
History and Contextual Awareness
One of the highlights of using Ollama is its ability to keep track of the conversation history. This allows the model to understand and relate to past interactions within the same session. For example, if you inquire, “Did I ask about cricket till now?” Ollama accurately responds by referencing the specific focus of your conversation on football, demonstrating its capability to contextualize and recall previous discussions accurately.
This section of our guide illustrates how Ollama as a CLI can be a powerful tool for managing and interacting with LLMs efficiently and effectively, enhancing productivity for developers and researchers working with AI models.
Getting Started with Ollama
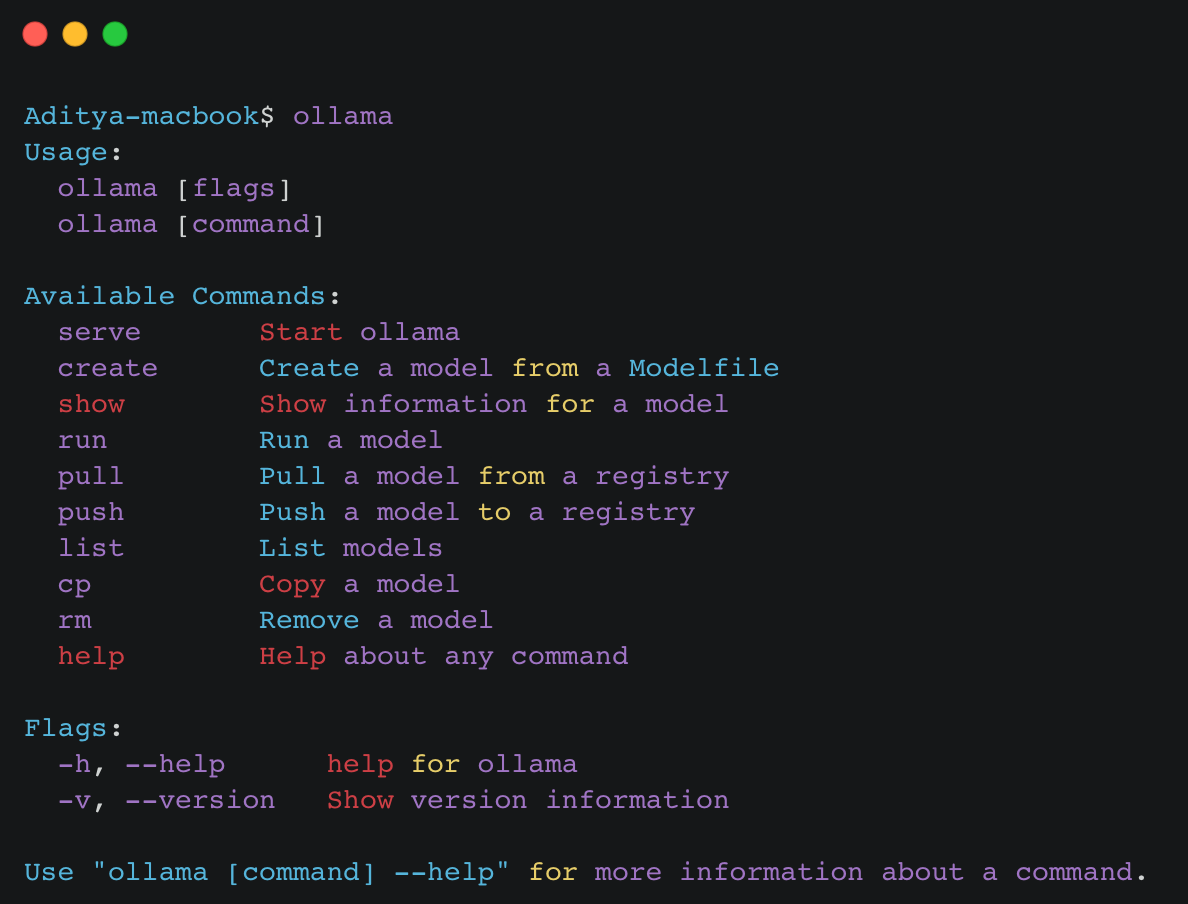
When you type ollama into the command line, the system displays the usage information and a list of available commands (e.g., serve, create, show, list, pull, push, run, copy, and remove). Each command serves a specific purpose:
serve: Launches the ollama service.create: Generates a new model file using a pre-existing model, allowing customization such as setting temperature or adding specific instructions.show: Displays configurations for a specified model.list: Provides a list of all models currently managed within the local environment.pull/push: Manages the import and export of models to and from the ollama registry.run: Executes a specified model.Copy(cp) andRemove(rm): Manages model files by copying or deleting them.
Managing Models with Ollama
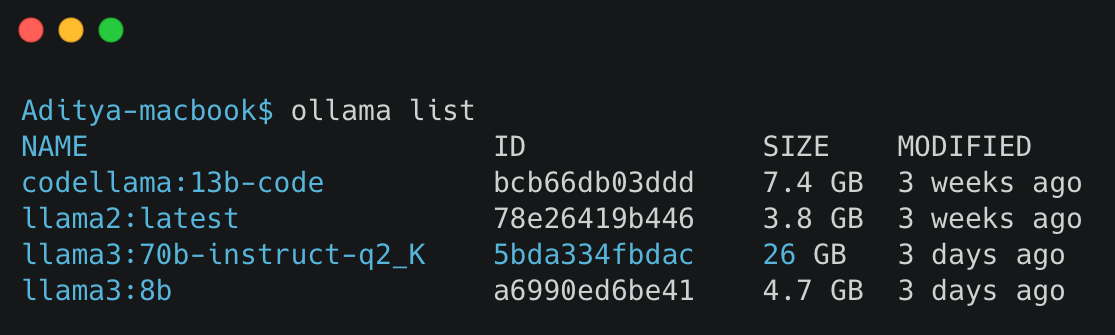
Using ollama list, you can view all models you have pulled into your local registry. For example, the list might include:
- Code Llama: 13 billion parameter model
- Llama 2
- Llama 3: 70 billion parameter instruction fine-tuned with Q2_K quantization
- Llama 3: 8 billion parameter model
- The latest Phi-3 model by Microsoft
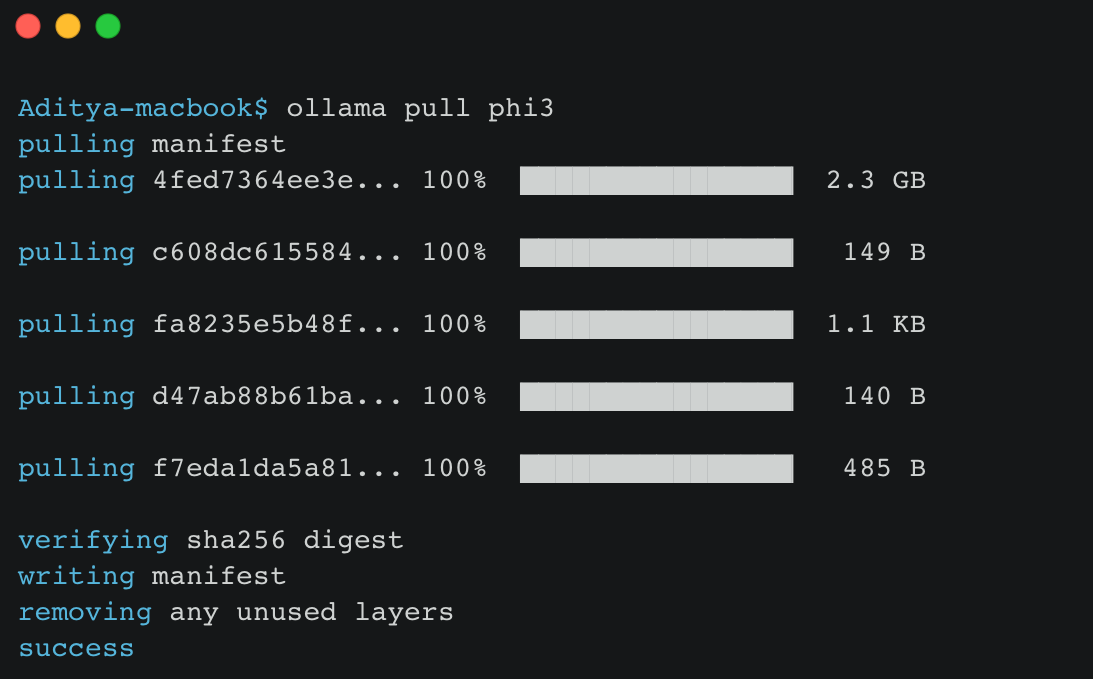
If a desired model isn’t available locally, you can retrieve it using ollama pull. For example, executing ollama pull phi3 retrieves the phi3 model, handling all necessary files and configurations seamlessly, similar to pulling images in Docker.
Streamlining Operations and Interaction with Ollama
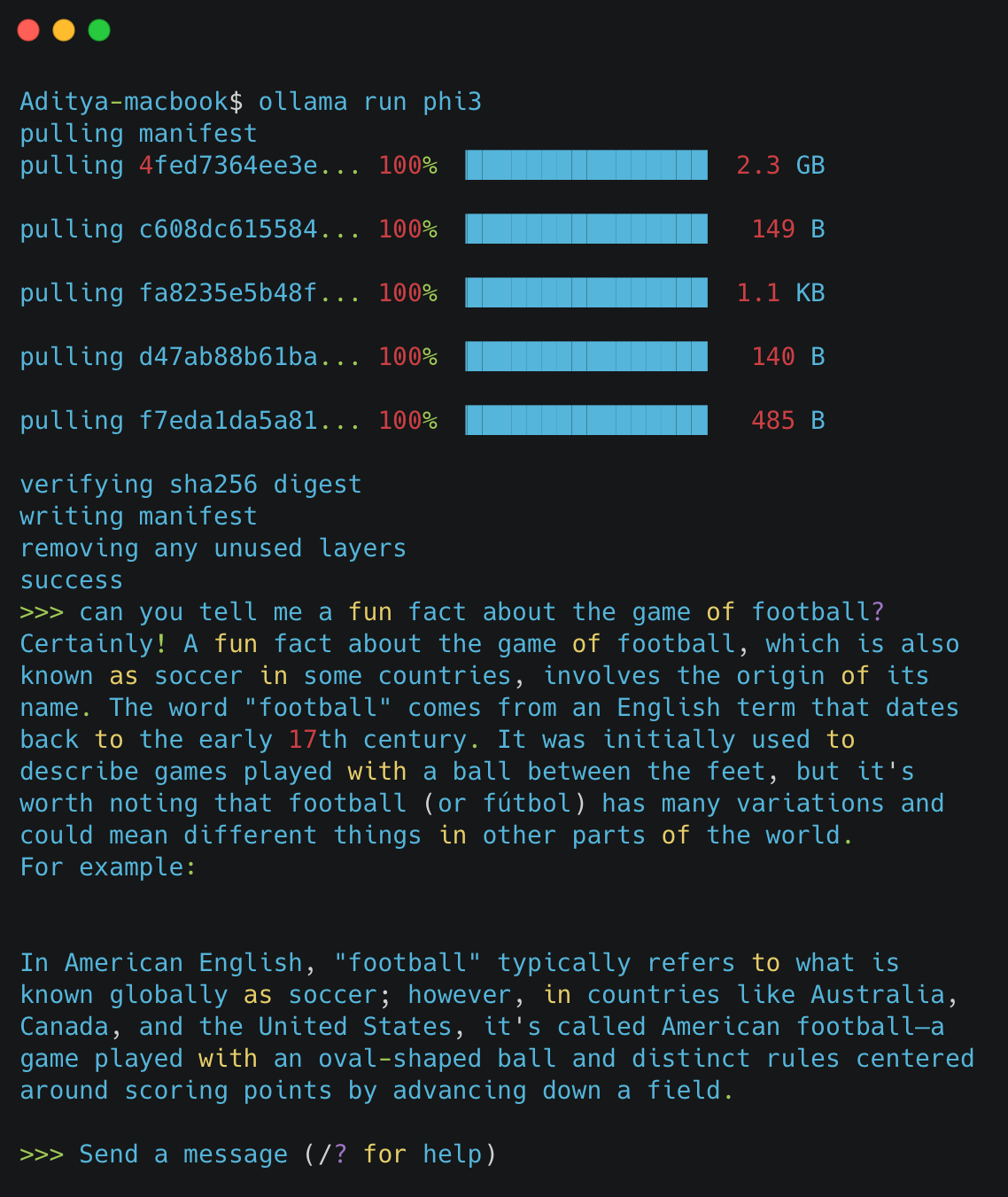
Ollama’s run command not only simplifies model management but also seamlessly integrates the initiation of interactive chat sessions, similar to how Docker handles container deployment and execution. Here’s how the ollama run phi3 command enhances user experience through a series of automated and interactive steps:
- Check Local Availability: Ollama first checks if the model
phi3is available locally. - Automatic Download: If the model is not found locally, Ollama automatically downloads it from the registry. This process involves fetching the model along with any necessary configurations and dependencies.
- Initiate Model Execution: Once the model is available locally, Ollama starts running it.
- Start Chat Session: Alongside running the model, Ollama immediately initiates a chat session. This allows you to interact with the model directly through the command line. You can begin asking questions or making requests right away, and the model will respond based on its training and capabilities.
This dual-functionality of the run command — managing both the deployment and interactive engagement of models — greatly simplifies operations. It mirrors the convenience observed in Docker operations, where the docker run command fetches an image if not present locally and then launches it, ready for use. In a similar vein, ollama run ensures that the model is not only operational but also interactive as soon as it is launched, significantly enhancing productivity and user engagement by combining deployment and direct interaction in a single step.
Context Awareness in Ollama CLI
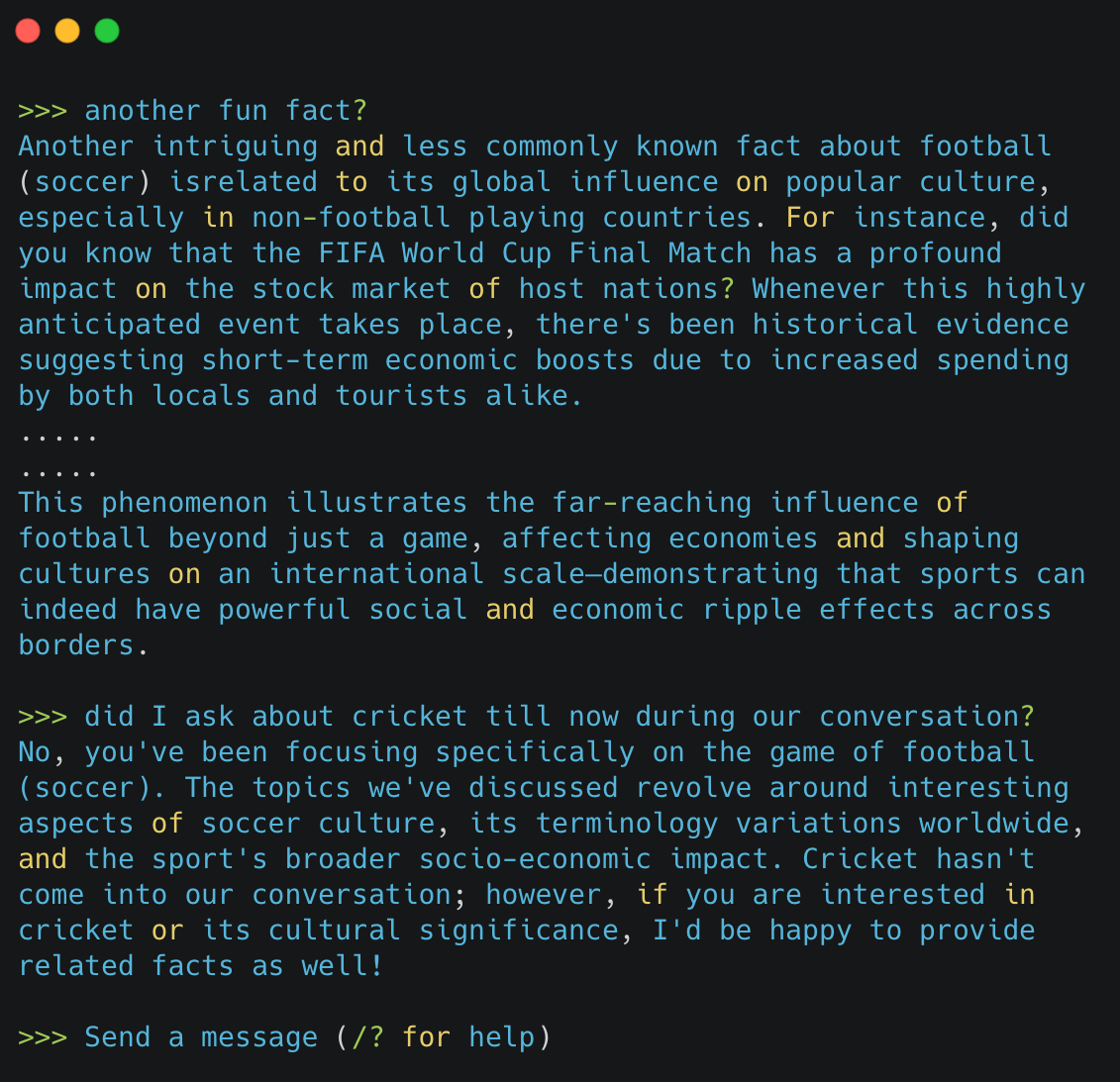
Ollama’s strength in contextual recall becomes apparent in how it manages the conversation flow. If you follow up with a request for “another fun fact?” without specifying the topic, Ollama understands from the context that the discussion still revolves around football. It then provides additional information related to the original topic, maintaining a coherent and relevant dialogue without needing repeated clarifications.
This capability is crucial for creating a natural and engaging user experience, where the model not only answers questions but also remembers the context of the interaction. It eliminates the need for users to repetitively specify the topic, making the dialogue flow more naturally and efficiently.
Verifying Contextual Understanding and History
Ollama’s contextual understanding is further highlighted when you query whether a particular topic (e.g., cricket) has been discussed. The model accurately recounts the focus of the conversation on football and confirms that cricket has not been mentioned. This demonstrates Ollama’s ability to track conversation history and understand the sequence of topics discussed.
Additionally, when prompted about past discussions, Ollama can succinctly summarize the topics covered, such as aspects of soccer culture, its terminology variations worldwide, and its socio-economic impacts. This not only shows the model’s recall capabilities but also its understanding of the discussion’s scope and details.
Integrating a Custom Model from Hugging Face into Ollama
In the realm of on-device AI, Ollama not only serves as a robust model hub or registry for state-of-the-art models like Phi-3, Llama 3, and multimodal models like Llava, but it also extends its functionality by supporting the integration of custom models. This flexibility is invaluable for users who wish to incorporate models fine-tuned on specific datasets or those sourced from popular repositories like Hugging Face.
While Ollama’s repository is extensive, it might not always house every conceivable model, especially given the vast landscape of foundation models. A noteworthy example is the work done by “Bloke,” a contributor who has extensively quantized various models for easier deployment. For this walkthrough, we’ll focus on integrating a quantized model from Bloke’s collection, specifically tailored for medical chats.
Downloading the Medicine Model from Hugging Face and Preparing Ollama Model Configuration File
- Downloading the Model:
- Visit this link to Bloke’s repository on Hugging Face for the medicine chat GGUF model.
- Navigate to the ‘Files and Versions’ section to download a quantized GGUF model, available in various bit configurations (2-bit to 8-bit).
- Preparing the Configuration File:
- Once downloaded, place the model file in the same directory as your configuration file.
- Create a configuration file. This file should reference the model file (e.g.,
medicine_chat_q4_0.GGUF), and can include parameters (e.g., temperature) to adjust the model’s response creativity.
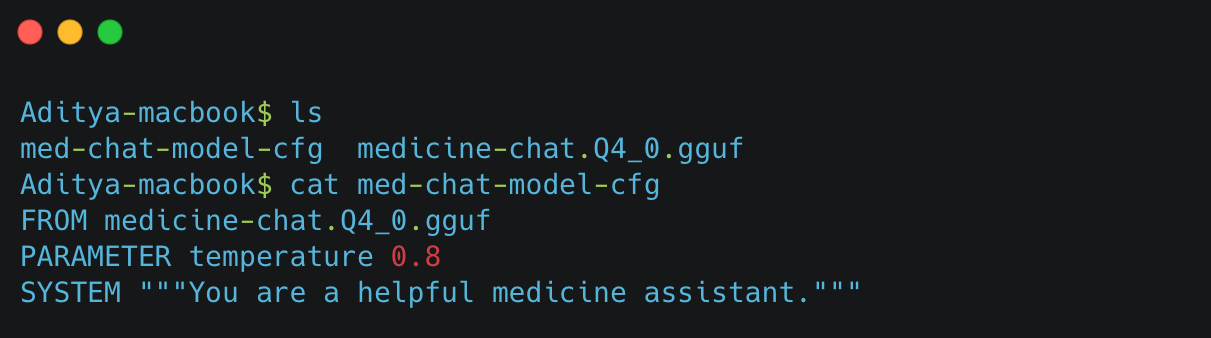
Creating the Model and Listing in Ollama
Once you’ve configured your model settings in the med-chat-model-cfg file, the next step is to integrate this model into Ollama. This process involves creating the model directly within Ollama, which compiles it from the configuration you’ve set, preparing it for deployment much like building a Docker image.
Using the appropriate command in Ollama (refer to the provided image for the exact command), you can initiate the creation of your custom model. This procedure constructs the necessary layers and settings specified in your configuration file, effectively building the model ready for use.
After the model creation, it’s essential to confirm that the model is correctly integrated and ready for use. By executing the listing command in Ollama (ollama list), you can view all available models. This list will include your newly created medicine-chat:latest model, indicating it is successfully integrated and available in Ollama’s local model registry alongside other pre-existing models.
These steps ensure that your custom model is not only integrated but also prepared and verified for deployment, facilitating immediate use in various applications, particularly those requiring specific configurations like medical chat assistance.
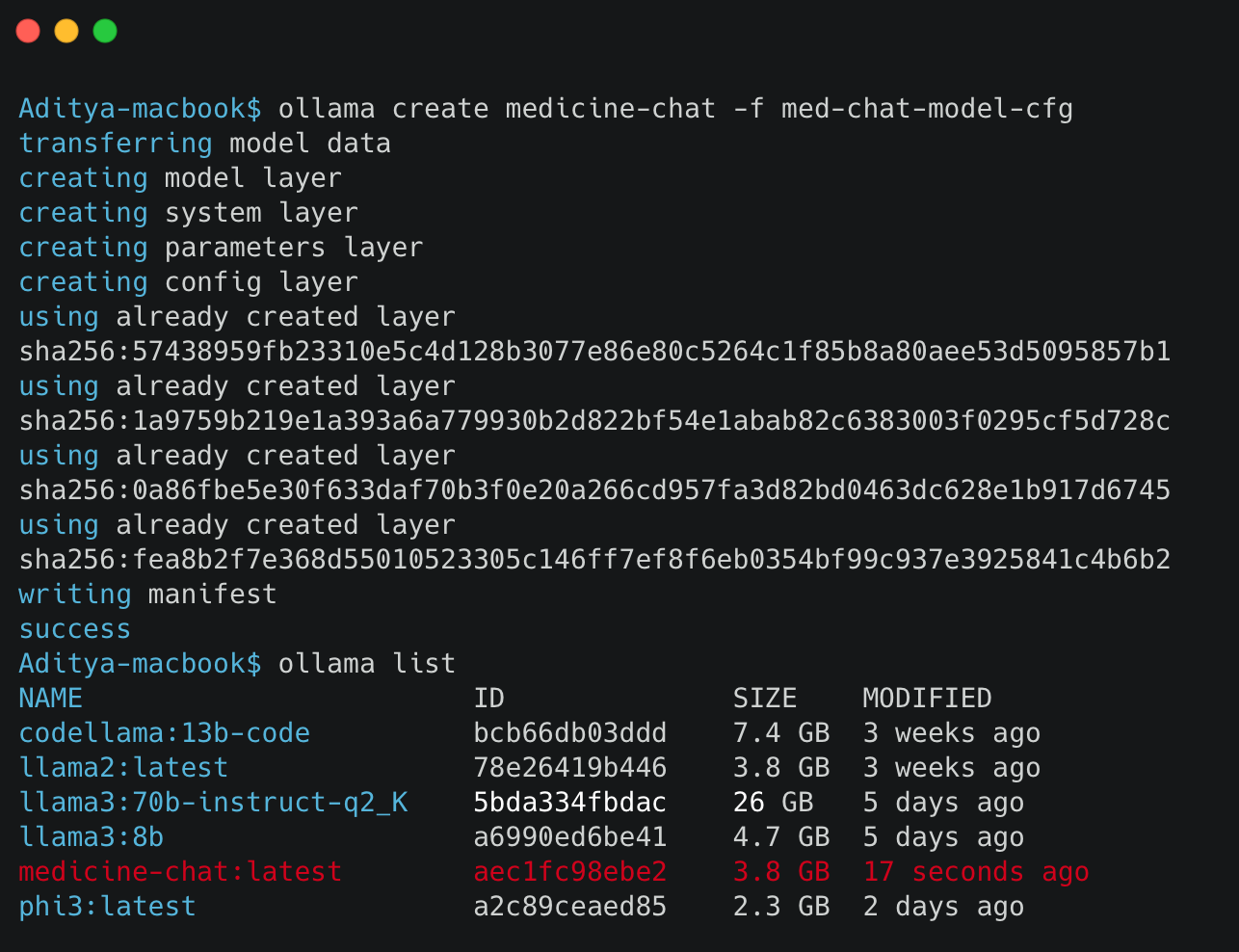
Running the Model
Once your model is integrated and listed in Ollama, the next step is to deploy and test its functionality to ensure it operates as expected. Initiate the model using ollama run followed by the model name, that is, medicine-chat:latest (as shown in the image below) to start an interactive session.
Then, next we provide a sample prompt to test its functionality, such as asking about monosomy. Although the initial response might be incorrect (e.g., suggesting 46,XX), the model provides a detailed explanation, correcting itself and confirming the right answer as 45,X.
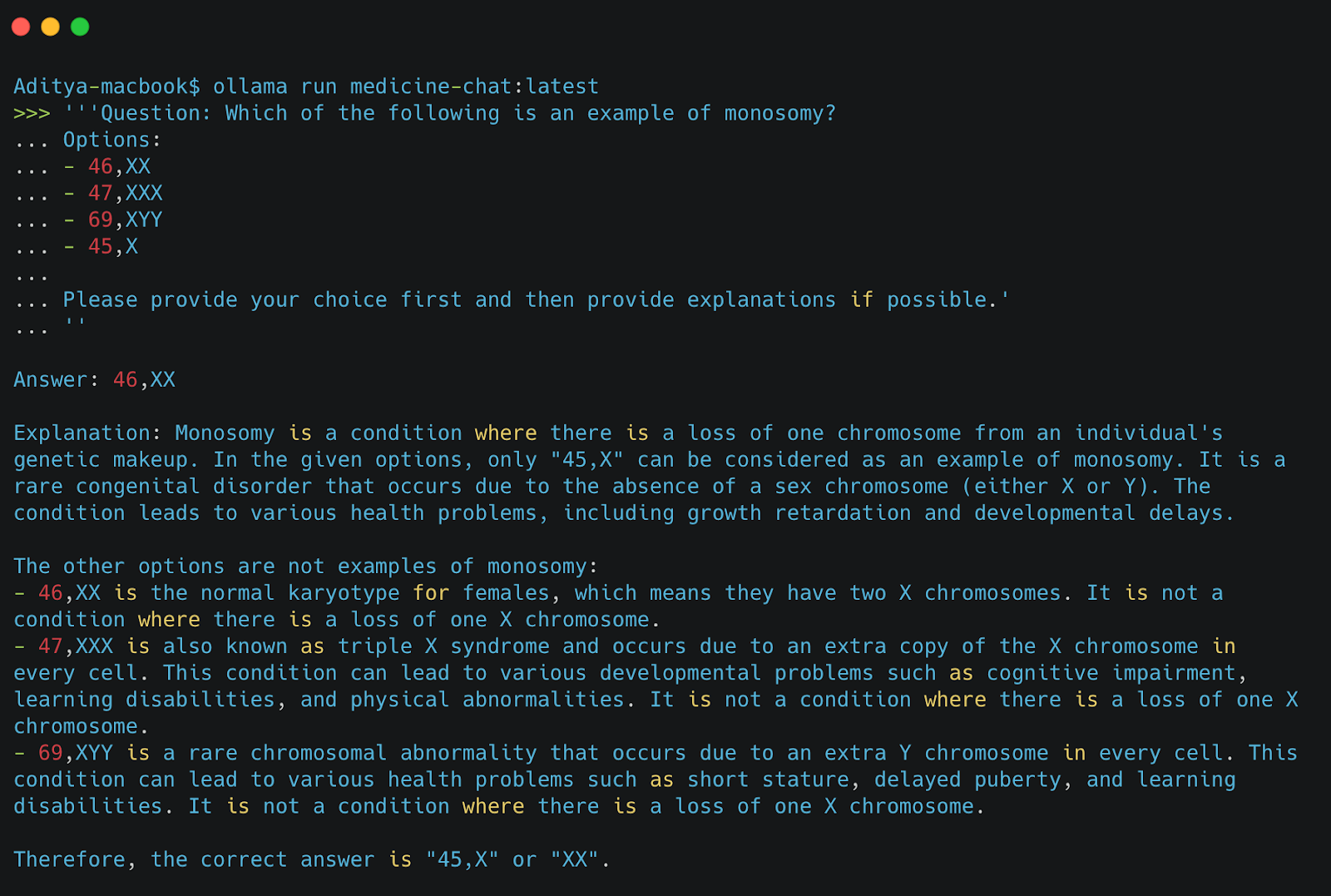
This example illustrates how Ollama’s flexibility not only supports running pre-existing models from its registry but also seamlessly integrates and executes custom models sourced externally. This capability empowers users to leverage specialized AI directly on their devices, enhancing Ollama’s utility across diverse applications.
Ollama Python Library: Bridging Python and Ollama with an API-Like Interface
The Ollama Python library provides a seamless bridge between Python programming and the Ollama platform, extending the functionality of Ollama’s CLI into the Python environment. This library enables Python developers to interact with an Ollama server running in the background, much like they would with a REST API, making it straightforward to integrate Ollama’s capabilities into Python-based applications.
Installation
Getting started with the Ollama Python library is straightforward. It can be installed via pip, Python’s package installer, which simplifies the setup process:
pip install ollama
This command installs the Ollama library, setting up your Python environment to interact directly with Ollama services.
Usage
The Ollama Python library is designed to be intuitive for those familiar with Python. Here’s how you can begin interacting with Ollama immediately after installation:
import ollama
response = ollama.chat(model='llama2', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
This simple example sends a message to the Ollama service and prints the response, demonstrating how easily the library can facilitate conversational AI models.
Streaming Responses
For applications requiring real-time interactions, the library supports response streaming. This feature is enabled by setting stream=True, which allows the function calls to return a Python generator. Each part of the response is streamed back as soon as it’s available:
import ollama
stream = ollama.chat(
model='llama2',
messages=[{'role': 'user', 'content': 'Why is the sky blue?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
Comprehensive API Methods with Examples
The Ollama Python library mirrors the functionality of the Ollama REST API, providing comprehensive control over interactions with models. Here’s how you can utilize these methods in your Python projects:
- Chat: Initiate a conversation with a specified model.
response = ollama.chat(model='llama2', messages=[{'role': 'user', 'content': 'Why is the sky blue?'}])
print(response['message']['content'])
- Generate: Request text generation based on a prompt.
generated_text = ollama.generate(model='llama2', prompt='Tell me a story about space.') print(generated_text)
- List: Retrieve a list of available models.
models = ollama.list() print(models)
- Create: Create a new model with custom configurations.
modelfile = ''' FROM llama2 SYSTEM You are Mario from Super Mario Bros. ''' ollama.create(model='super_mario', modelfile=modelfile)
- Pull: Download a model from the server.
ollama.pull('llama2')
- Embeddings: Generate embeddings for a given prompt.
embeddings = ollama.embeddings(model='llama2', prompt='The sky is blue because of Rayleigh scattering.') print(embeddings)
These code snippets provide practical examples of how to implement each function provided by the Ollama Python library, enabling developers to effectively manage and interact with AI models directly from their Python applications.
Customizing the Client
For more advanced usage, developers can customize the client configuration to suit specific needs:
from ollama import Client
client = Client(host='http://localhost:11434')
response = client.chat(model='llama2', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
This customization allows for adjustments to the host settings and timeouts, providing flexibility depending on the deployment environment or specific application requirements.
Overall, the Ollama Python library acts as a robust conduit between Python applications and the Ollama platform. It offers developers an API-like interface to harness the full potential of Ollama’s model management and interaction capabilities directly within their Python projects. For additional resources and more advanced usage examples, refer to the Ollama Python GitHub repository, which served as a key reference for the comprehensive API section discussed here.
Ollama with LangChain
Ollama can be seamlessly integrated with LangChain through the LangChain Community Python library. This library offers third-party integrations that adhere to the base interfaces of LangChain Core, making them plug-and-play components for any LangChain application.
What Is LangChain?
LangChain is a versatile framework for embedding Large Language Models (LLMs) into various applications. It supports a diverse array of chat models, including Ollama, and allows for sophisticated operation chaining through its expressive language capabilities.
The framework enhances the entire lifecycle of LLM applications, simplifying:
- Development: Utilize LangChain’s open-source components and third-party integrations to build robust applications rapidly.
- Productionization: Employ tools like LangSmith to monitor, inspect, and refine your models, ensuring efficient optimization and reliable deployment.
- Deployment: Easily convert any model sequence into an API with LangServe, facilitating straightforward integration into existing systems.
How to Implement Ollama with LangChain?
To integrate Ollama with LangChain, begin by installing the necessary community package:
pip install langchain-community
After installation, import the Ollama module from the langchain_community.llms class:
from langchain_community.llms import Ollama
Next, initialize an instance of the Ollama model, ensuring that the model is already available in your local Ollama model registry, which means it should have been previously pulled to your system:
llm = Ollama(model="phi3")
You can now utilize this instance to generate responses. For example:
response = llm.invoke("Tell me a joke")
print(response)
Here’s a sample output from the model:
"Why don't scientists trust atoms? Because they make up everything!\n\nRemember, jokes are about sharing laughter and not intended to offend. Always keep the atmosphere light-hearted and inclusive when telling humor."
Important Considerations
Before running this integration:
- Ensure that the Ollama application is active on your system.
- The desired model must be pre-downloaded via Ollama’s CLI or Python API. If not, you may encounter an
OllamaEndpointNotFoundError, prompting you to download the model.
This integration exemplifies how Ollama and LangChain can work together to enhance the utility and accessibility of LLMs in application development.
Bonus: Ollama with a Web UI Using Docker
This section is featured as a bonus because it highlights a substantial enhancement in Ollama’s capabilities. When we began preparing this tutorial, we hadn’t planned to cover a Web UI, nor did we expect that Ollama would include a Chat UI, setting it apart from other Local LLM frameworks like LMStudio and GPT4All.
Ollama is supported by Open WebUI (formerly known as Ollama Web UI). Open Web UI is a versatile, feature-packed, and user-friendly self-hosted Web UI designed for offline operation. It accommodates a range of LLM runners, including Ollama and APIs compatible with OpenAI.
The GIF below offers a visual demonstration of Ollama’s Web User Interface (Web UI), showcasing its intuitive design and seamless integration with the Ollama model repository. This interface simplifies the process of model management, making it accessible even to those with minimal technical expertise.
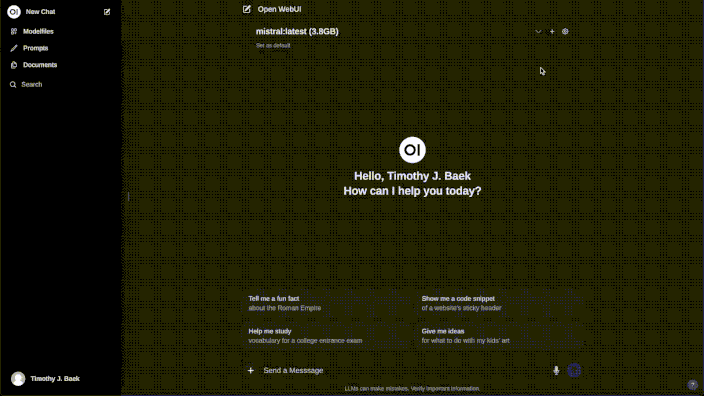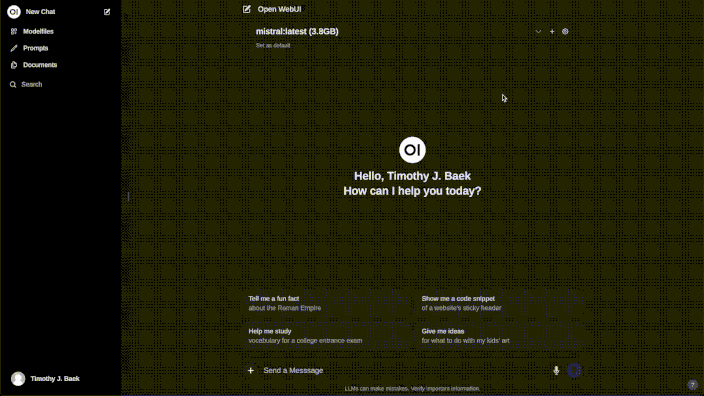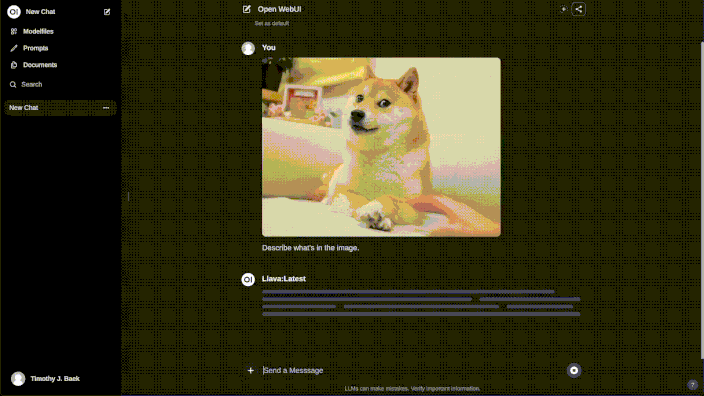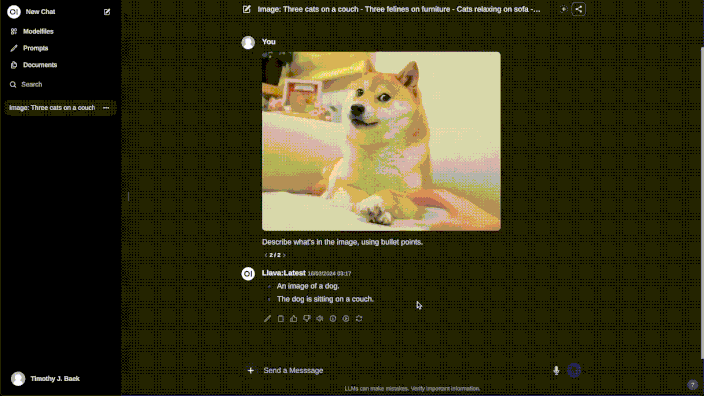
Here’s an overview of the key functionalities displayed in the GIF:
- Access and Interface: The GIF begins by showing how users can easily access the Web UI. This centralized platform is where all interactions with Ollama’s capabilities begin.
- Model Selection and Management: Users proceed to the settings, where they can select from a variety of models. The GIF illustrates the straightforward process of navigating to the model section and choosing the desired model.
- Model Integration: After selecting a model (e.g., “Llava”), it is downloaded directly from Ollama’s repository. This process mirrors what would traditionally be handled via command line interfaces or APIs but is visualized here in a more user-friendly manner.
- Operational Use: With the model downloaded, the GIF shows how users can then easily upload images and utilize the model’s capabilities, such as generating descriptive bullet points about an image’s contents.
- Enhanced Usability: The Web UI not only makes it easier to manage and interact with advanced models but also enhances the overall user experience by providing a graphical interface that simplifies complex operations.
The integration of Ollama’s Web UI represents a significant step forward in making advanced modeling tools more accessible and manageable. This is ideal for users across various domains who require a straightforward solution to leverage powerful models without delving into more complex technical procedures.
Key Features of Ollama’s Web UI
The GIF included in this post offers a glimpse into the innovative features of Ollama’s Web User Interface (Web UI), demonstrating its intuitive design and seamless integration with the Ollama model repository. While the GIF showcases some of these features, the actual list of capabilities extends far beyond, making it a powerful tool for both novices and seasoned tech enthusiasts. Here’s a detailed list of some standout features that enhance the user experience:
- 🖥️ Intuitive Interface: Inspired by user-friendly designs like ChatGPT, the interface ensures a smooth user experience.
- 📱 Responsive Design: The Web UI adapts flawlessly to both desktop and mobile devices, ensuring accessibility anywhere.
- ⚡ Swift Responsiveness: Experience rapid performance that keeps pace with your workflow.
- 🚀 Effortless Setup: Quick installation options with Docker or Kubernetes enhance user convenience.
- 🌈 Theme Customization: Personalized interface with a selection of themes to fit your style.
- 💻 Code Syntax Highlighting: Code more efficiently with enhanced readability features.
- ✒️🔢 Full Markdown and LaTeX Support: Take your content creation to the next level with extensive formatting options.
- 📚 Local & Remote RAG Integration: Integrate and manage documents directly in your chats for a comprehensive chat experience.
- 🔍 RAG Embedding Support: Tailor your document processing by selecting different RAG embedding models.
- 🌐 Web Browsing Capability: Directly incorporate web content into your interactions for enriched conversations.
This extensive toolkit provided by Ollama’s Web UI not only elevates the user interface but also deeply enhances the functionality, making complex tasks simpler and more accessible. Whether you’re managing data, customizing your workspace, or integrating diverse media, Ollama’s Web UI is equipped to handle an array of challenges, paving the way for a future where technology is more interactive and user-centric.
Certainly! Here’s a structured section for your blog that introduces the installation process of the Open Web UI, incorporating all the details you’ve provided:
Setting Up Open Web UI on Your Local Machine
As we delve into setting up the Open Web UI, it’s crucial to ensure a smooth and efficient installation. This user-friendly interface sits on top of the Ollama application, enhancing your interaction capabilities. Let’s walk through the steps to get the Web UI running locally, which builds upon the foundational Ollama application required for both CLI and API interactions.
Prerequisites
Before we begin the installation of the Open Web UI, there are a couple of essential prerequisites:
- Ollama Application Running: Ensure that the Ollama application is operational in the background. The Open Web UI leverages this application, requiring it to be active on your local server, typically on port
11434. This setup is crucial as the Web UI acts as a wrapper, utilizing the core functionalities provided by Ollama.
- Docker Installation: Your system must have Docker installed to run the Web UI. If you’re new to Docker, feel free to explore our series on Docker, which provides a comprehensive guide to getting started with Docker installations and operations.
Running the Open Web UI
With the prerequisites in place, you can proceed to launch the Open Web UI:
docker run -d \ -p 3000:8080 \ --add-host=host.docker.internal:host-gateway \ -v open-webui:/app/backend/data \ --name open-webui \ --restart always \ ghcr.io/open-webui/open-webui:main
Let’s try to understand the above command in detail:
docker run -d: This command runs a new container in detached mode, meaning the container runs in the background and does not block the terminal or command prompt.-p 3000:8080: This option maps port 8080 inside the container to port 3000 on the host. This means that the application inside the container that listens on port 8080 is accessible using port 3000 on the host machine.--add-host=host.docker.internal:host-gateway: This option adds an entry to the container’s/etc/hostsfile.host.docker.internalis a special DNS name used to refer to the host’s internal IP address from within the container.host-gatewayallows the container to access network services running on the host.-v open-webui:/app/backend/data: This mounts the volume namedopen-webuiat the path/app/backend/datawithin the container. This is useful for persistent data storage and ensuring that data generated by or used by the application is not lost when the container is stopped or restarted.--name open-webui: Assigns thename open-webuito the new container. This is useful for identifying and managing the container using Docker commands.--restart always: Ensures that the container restarts automatically if it stops. If the Docker daemon restarts, the container will restart unless it is manually stopped.ghcr.io/open-webui/open-webui:main: Specifies the Docker image to use. This image is pulled from GitHub Container Registry (ghcr.io) from the repositoryopen-webui, using themaintag.
Accessing Open Web UI
Once the Docker container is up and running, you can access the Open Web UI by navigating to http://localhost:3000 in your web browser. This port forwards to port 8080 inside the Docker container, where the Web UI is hosted.
On your first visit, you’ll be prompted to create a user ID and password. This step is crucial for securing your access and customizing your experience. Once set up, you can start exploring the powerful features of the Open Web UI. If you’ve previously downloaded any LLMs using Ollama’s CLI, they will also appear in the UI. Isn’t that incredibly convenient?
Installing and setting up the Open Web UI is straightforward — ensure your Ollama application is running, install Docker if you haven’t, and execute a single Docker command. This setup provides a robust platform for enhancing your interactions with Ollama’s capabilities right from your local machine. Enjoy the seamless integration and expanded functionality that the Open Web UI brings to your workflow!
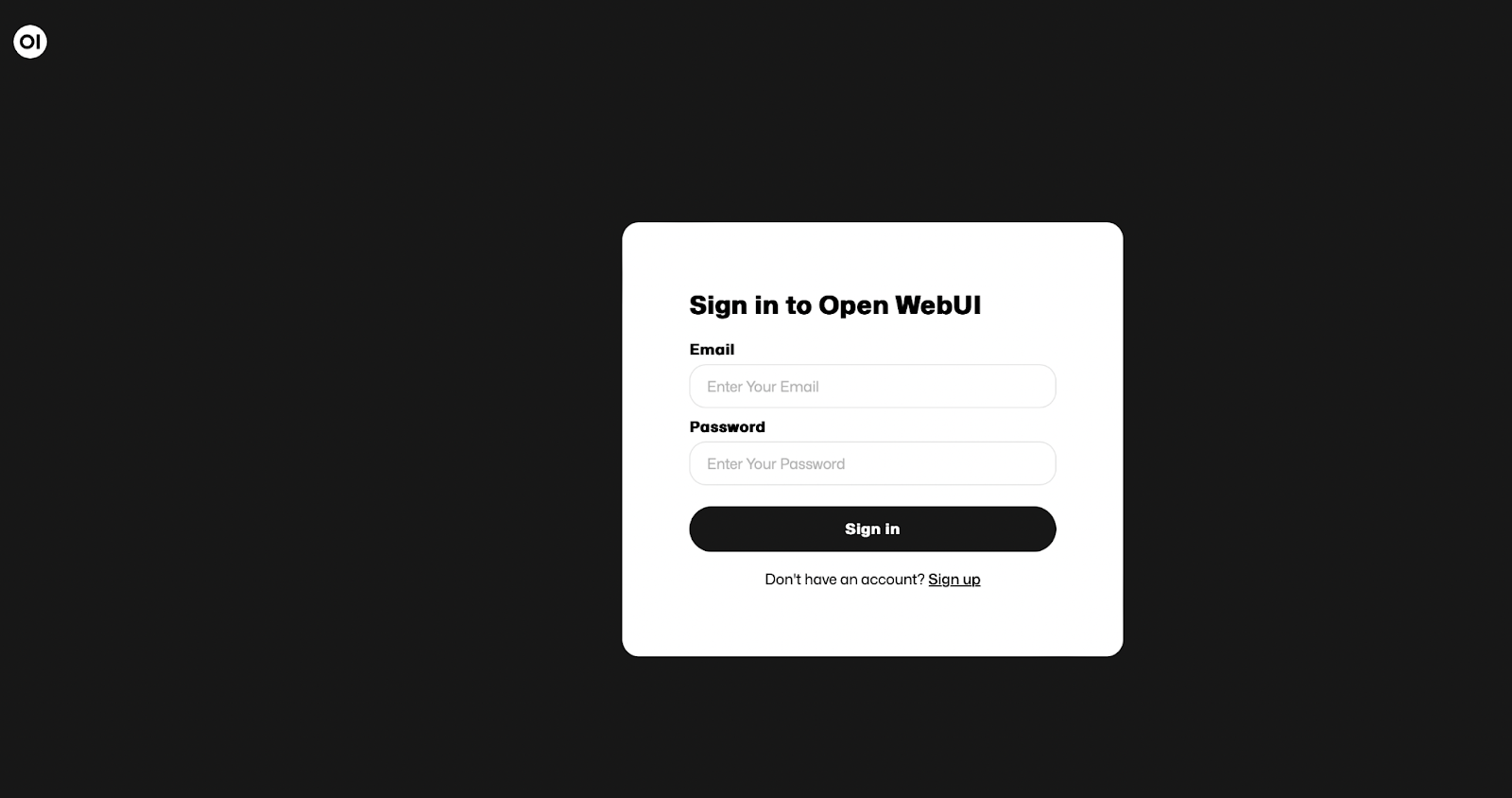
Login Screen
The login screen is the primary gateway for accessing the Open Web UI. It features fields for entering an email and password, with options for users to sign in or sign up. Crucially, due to the Docker container’s volume mount setup, the user data, including login credentials, are stored persistently. This means that when the container is restarted, it retains the user data from the Open WebUI and the Platform as a Service (PaaS) app backend within the specified directory, ensuring continuity and security of access.
Model Selection Screen
This screen showcases the integration with local Ollama configurations, displaying models such as CodeLlama, Llama2, Llama3:70b, Llama3:8b, and MedicineChat, which were previously downloaded via Ollama’s CLI from model registries like Hugging Face. These models appear in the dropdown menu due to their configurations being established locally through Ollama’s CLI. The flexibility of the Web UI extends to managing these models directly from the interface, enhancing usability by allowing users to pull or interact with models from the registry without needing to revert to the CLI.
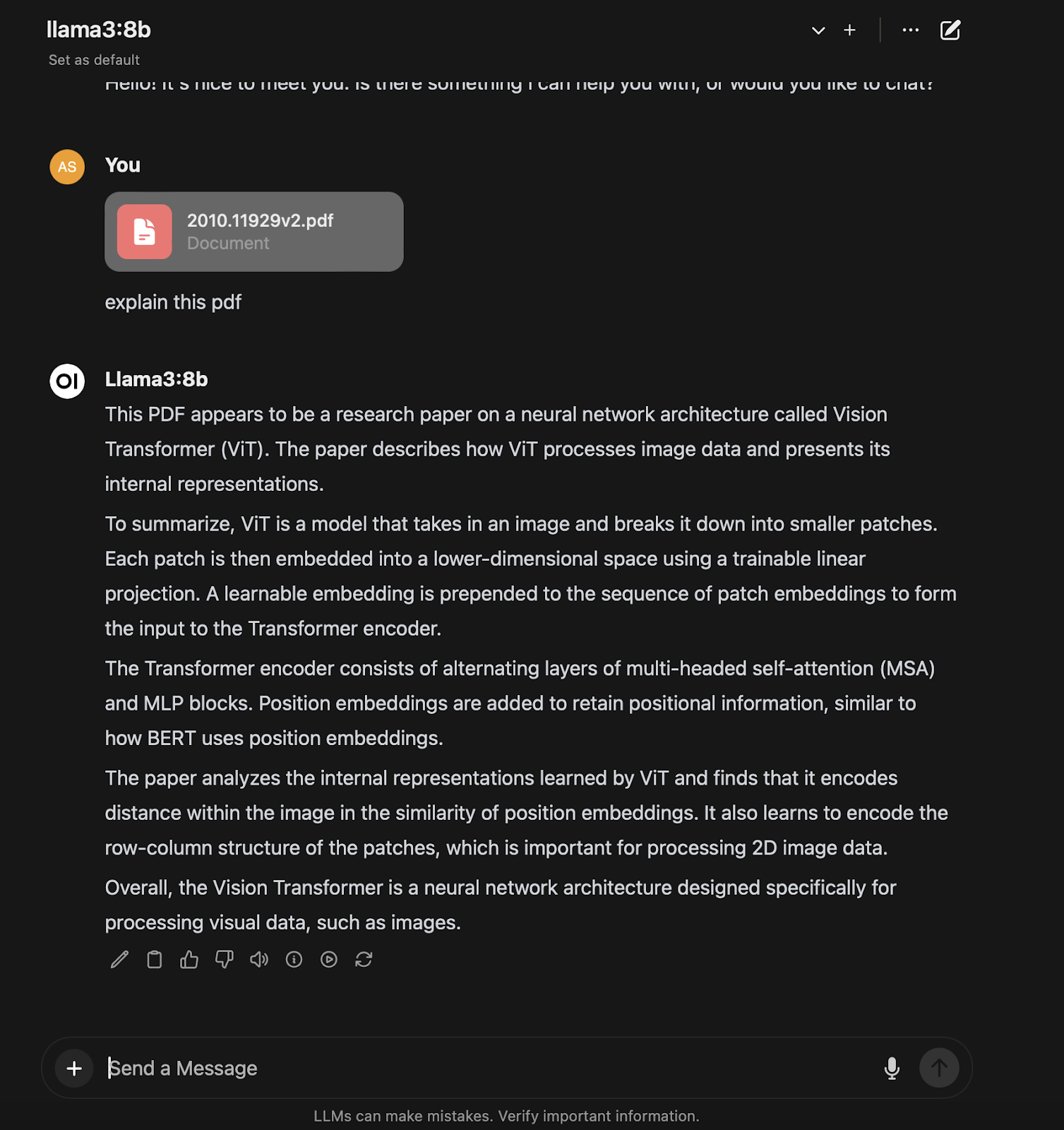
Chat Screen with PDF Explanation Screen
This feature is particularly innovative, allowing users to upload and analyze PDF documents directly through the Web UI. In the demonstrated case, the Llama3:8b model is selected to interpret a document about Vision Transformers (ViT). The ability to select a model for specific content analysis and to receive a detailed summary directly on the platform exemplifies the practical utility of the Web UI. It not only simplifies complex document analysis but also makes advanced AI insights accessible through an intuitive interface. These features are available in the paid version of ChatGPT-4, but in Open Web UI, they are offered for free. Of course, the performance and accuracy may vary.
Overall, these features highlight the Open Web UI’s robust functionality, designed to facilitate seamless interaction with advanced machine learning models, ensuring both efficiency and ease of use in handling AI-driven tasks.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This comprehensive tutorial explores the expansive world of Ollama, a platform designed for managing and interacting with Large Language Models (LLMs). The guide starts with an “Introduction to Ollama,” offering insights into the platform’s capabilities, particularly its role in on-device AI applications.
The post delves into practical aspects, with sections on installing Ollama on MacOS and managing models through its command line interface. It highlights the rich repository available in Ollama’s Model Registry and outlines the process of integrating custom models from external sources like Hugging Face.
Further, the tutorial discusses the Ollama Python Library in detail, which bridges Python programming with Ollama through an API-like interface, making it easier for developers to streamline their interactions with LLMs.
Next, we delve into integrating Ollama with LangChain using the LangChain Community Python library. This allows developers to incorporate Ollama’s LLM capabilities within LangChain’s framework to build robust AI applications. We cover the installation, setting up an Ollama instance, and invoking it for enhanced functionality.
A significant portion is dedicated to setting up the Ollama Web UI using Docker, which includes detailed steps from installation to accessing the Web UI. This part of the guide enhances user interaction by explaining specific UI screens like the login screen, model selection, and PDF explanation features.
The tutorial concludes with a section on the additional benefits of using the Web UI. It ensures that readers are well-equipped to utilize Ollama’s full suite of features, making advanced LLM technology accessible to a broad audience.
This guide is an essential resource for anyone interested in leveraging the power of LLMs through the Ollama platform. It guides users from basic setup to advanced model management and interaction.
Citation Information
Sharma, A. “Inside Look: Exploring Ollama for On-Device AI,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/16eu7
@incollection{Sharma_2024_Exploring-Ollama-On-Device-AI,
author = {Aditya Sharma},
title = {Inside Look: Exploring Ollama for On-Device AI},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/16eu7},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.