Table of Contents
- Introduction to Serverless Model Deployment with AWS Lambda and ONNX
- Understanding ONNX and Why It’s Useful
-
Deep Dive: AWS Lambda, API Gateway, and ONNX Runtime
- AWS Lambda: The Compute Engine for Serverless AI
- Understanding AWS Lambda Pricing for AI Workloads
- AWS Lambda Limitations for AI Models
- API Gateway: Exposing the AI Model as an API
- ONNX Runtime: The Inference Engine
- Why ONNX Runtime for Lambda?
- How ONNX Runtime Works in AWS Lambda
- How These Components Work Together (End-to-End Flow)
- Configuring Your Development Environment
- Project Structure
- Summary
- What’s Next? (Lesson 2 Preview)
Introduction to Serverless Model Deployment with AWS Lambda and ONNX
In this lesson, you’ll learn how AWS Lambda, Amazon API Gateway, and ONNX Runtime enable serverless AI model deployment. We’ll break down how these services interact, examine AWS Lambda’s pricing and architecture, and show how Python-based models and ONNX Runtime make AI inference efficient in serverless environments.

This lesson is the 1st of a 4-part series on AWS Lambda:
- Introduction to Serverless Model Deployment with AWS Lambda and ONNX (this tutorial)
- Lesson 2
- Lesson 3
- Lesson 4
To learn how serverless AI enables model deployment with AWS Lambda, Amazon API Gateway, and ONNX Runtime, just keep reading.
What Is Serverless Model Deployment?
Traditional model deployment involves managing servers and scaling manually — but what is AWS Lambda, and how does it remove that overhead?
This approach can be complex, resource-intensive, and costly — especially if your model is not running continuously.
Serverless model deployment addresses these challenges by eliminating the need for manual server management. With a serverless architecture, your model is packaged as a function that runs only when invoked, automatically scaling up or down based on demand. This allows you to focus on your model logic rather than on infrastructure provisioning and maintenance.
How Does Serverless Deployment Work?
- A user sends an API request (e.g., to classify an image or analyze text).
- The request is routed through Amazon API Gateway, which forwards it to AWS Lambda.
- AWS Lambda loads the AI model and performs inference using ONNX Runtime.
- The inference result is returned to the user via API Gateway.
In Figure 1, a client application sends a request through Amazon API Gateway, which triggers an AWS Lambda function running ONNX Runtime for model inference. The response is then sent back to the client.
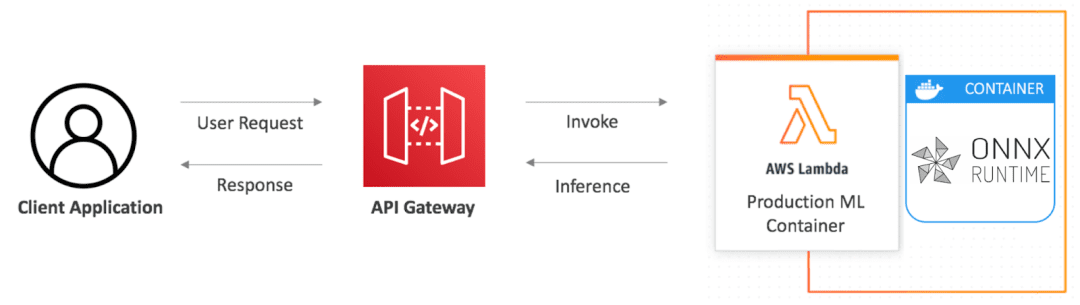
This architecture ensures you pay only for compute time when your model runs, making it highly cost-effective and scalable.
Why Use AWS Lambda for AI Model Inference?
AWS Lambda is a serverless compute service that allows you to run code without provisioning or managing servers. It is ideal for deploying lightweight AI inference models because:
- No Infrastructure Management: AWS handles all server provisioning, scaling, and maintenance.
- Pay-per-Use Pricing: You are only charged for the time your function runs (down to milliseconds).
- Automatic Scaling: Lambda can handle thousands of concurrent requests without manual scaling.
- Seamless API Integration: Works with AWS API Gateway to expose inference models as REST APIs.
Limitations of AWS Lambda for AI Inference
While AWS Lambda is great for serverless AI deployment, it has some limitations:
- Cold Starts: If a Lambda function hasn’t been used for a while, it may take longer to start.
- Execution Time Limit: A single request cannot exceed 15 minutes.
- Memory Constraints: The maximum memory allocation is 10GB, which may not be sufficient for large models.
- Storage Limits: The total function package size is 250MB, including dependencies.
To work within these constraints, we use ONNX Runtime, which is optimized for fast, lightweight inference, making it a great fit for AWS Lambda.
How Serverless Model Deployment Compares to Traditional Deployment
Compared to EC2, AWS Lambda eliminates idle costs by automatically scaling and billing only for active requests.
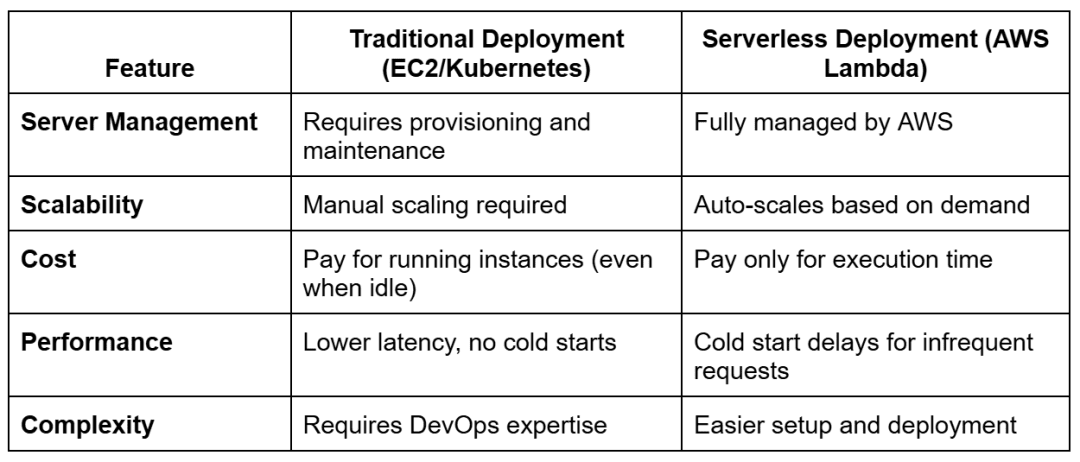
For frequent, large-scale AI workloads, EC2 or Kubernetes might be a better choice. But for lightweight inference models that run intermittently, AWS Lambda is highly cost-efficient and scalable.
Understanding ONNX and Why It’s Useful
As we prepare for serverless AI model deployment, choosing the right model format is crucial for optimizing inference speed and reducing resource consumption. This is where ONNX (Open Neural Network Exchange) comes in.
What Is ONNX?
ONNX is an open-source model format designed to enable interoperability between different machine learning frameworks, such as PyTorch, TensorFlow, and Scikit-learn. It allows models trained in one framework to be exported and run efficiently in another, using ONNX Runtime.
Think of ONNX as a universal language for AI models, enabling them to be more portable and optimized across different environments, including AWS Lambda.
Why Use ONNX for AI Model Deployment?
Deploying machine learning models in serverless environments like AWS Lambda comes with constraints:
- Limited storage (max package size: 250 MB)
- Cold starts (models must load quickly)
- No persistent state (models must be loaded on every request)
ONNX solves these challenges with:
- Compact Model Size: ONNX models are often smaller than raw PyTorch or TensorFlow models, reducing load times.
- Optimized for Fast Inference: ONNX Runtime provides low-latency execution, critical for AWS Lambda’s performance.
- Cross-Framework Compatibility: Convert models from TensorFlow, PyTorch, Scikit-learn, and others into a single ONNX format.
- Support for Hardware Acceleration: ONNX Runtime can leverage CPU optimizations for fast execution without GPUs.
How ONNX Works in AWS Lambda
- Train a Model in PyTorch or TensorFlow.
- Convert it to ONNX format.
- Deploy it using ONNX Runtime on AWS Lambda.
- Inferencing is performed efficiently, with optimized execution for serverless constraints.
How to Convert a PyTorch Model to ONNX
Most deep learning frameworks support exporting models to ONNX. Here’s an example of converting a ResNet model from PyTorch to ONNX:
import torch import torchvision.models as models # Load a pre-trained ResNet model model = models.resnet18(pretrained=True) model.eval() # Define a dummy input tensor dummy_input = torch.randn(1, 3, 224, 224) # Export the model to ONNX format torch.onnx.export(model, dummy_input, "resnet18.onnx", opset_version=11)
This resnet18.onnx file can now be loaded inside AWS Lambda using ONNX Runtime for inference.
Deep Dive: AWS Lambda, API Gateway, and ONNX Runtime
Now that we understand why ONNX is the ideal model format for serverless AI deployment, let’s explore how AWS Lambda, API Gateway, and ONNX Runtime work together to enable scalable, cost-effective AI inference.
AWS Lambda: The Compute Engine for Serverless AI
AWS Lambda is a serverless compute service that runs only when triggered, making it perfect for deploying AI models without managing infrastructure.
How AWS Lambda Works for AI Inference
- A user request (e.g., image classification) is sent via API Gateway.
- API Gateway triggers an AWS Lambda function that loads the AI model.
- ONNX Runtime inside Lambda executes model inference.
- The inference result is returned to API Gateway, which sends it back to the user.
Key Benefits of AWS Lambda for AI
- Scalability: Automatically scales based on demand.
- Cost Efficiency: You only pay for the time the function runs.
- Ease of Deployment: No need to manage servers, load balancers, or scaling policies.
Understanding AWS Lambda Pricing for AI Workloads
AWS Lambda follows a pay-as-you-go pricing model, charging you only for the compute time your function actually uses. Costs depend on two main factors:
- Number of Requests: Each invocation costs a fraction of a cent (the first 1 million requests per month are free).
- Compute Duration: Billed in GB-seconds based on the memory you allocate and the time the function runs.
For example, a 512 MB Lambda function that runs for 1 second costs roughly $0.000000833 per invocation (after the free tier). Even if you process thousands of images, the total monthly cost for lightweight ONNX inference typically remains under a few dollars.
Optimization Tip: Choose the smallest memory size that keeps your inference latency acceptable, and reuse the Lambda container between invocations to reduce cold-start overhead.
Because Lambda scales automatically, you’ll never pay for idle compute — a key advantage over EC2, where instances accrue cost even when idle.
AWS Lambda Limitations for AI Models
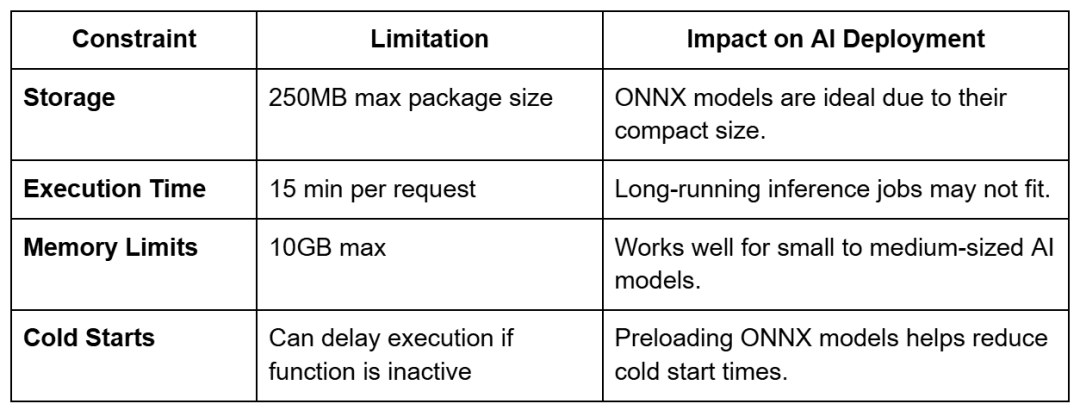
Because of these constraints, using lightweight ONNX models and optimizing Lambda function memory is essential.
API Gateway: Exposing the AI Model as an API
Amazon API Gateway is an AWS service for creating REST, HTTP, and WebSocket APIs at any scale. API Gateway acts as the HTTPS endpoint URL when Amazon API Gateway, along with AWS Lambda, is used to build APIs.
Amazon API Gateway endpoints have this format:
https://{restapi_id}.execute-api.{region}.amazonaws.com/{stage_name}/
Amazon API Gateway can be used for cases that require advanced authorization with Amazon Cognito, throttling, caching, service proxies to other AWS services, usage plans, WebSocket APIs, request/response mapping and validation, and other advanced features.
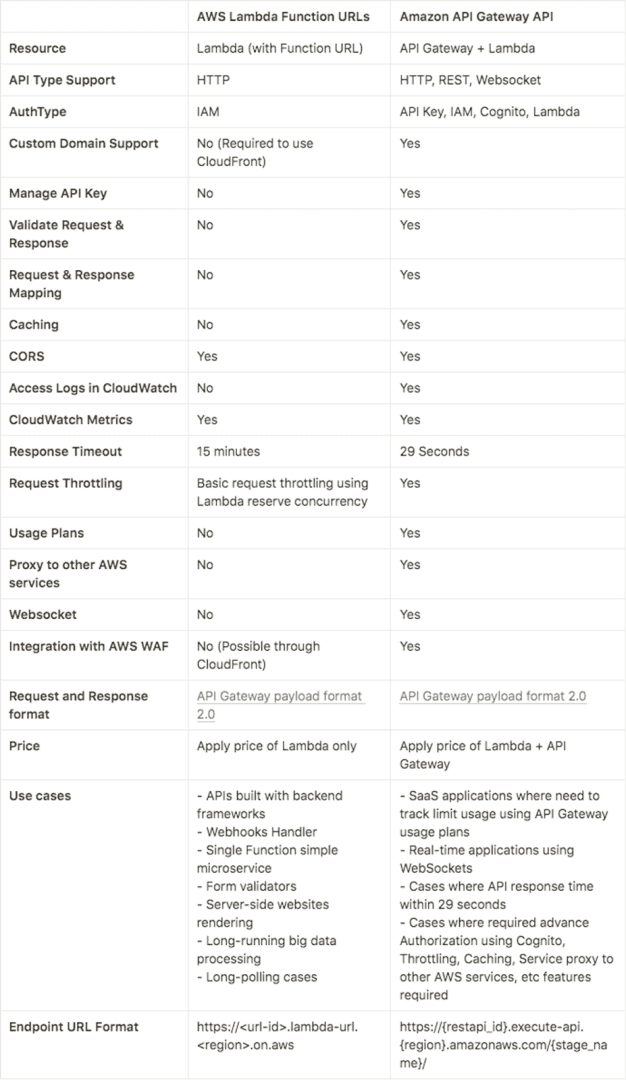
What API Gateway Does
- Receives requests from client applications.
- Validates and authenticates the requests.
- Routes requests to AWS Lambda for inference.
- Formats the response and sends it back to the client.
💡 Without API Gateway, Lambda functions would not have a public endpoint for inference requests.
ONNX Runtime: The Inference Engine
ONNX Runtime is an open-source, high-performance inference engine developed by Microsoft to efficiently execute ONNX models. It is designed for optimal performance and supports a wide range of hardware, including CPUs, GPUs, and specialized accelerators. Designed for both cloud and edge environments, ONNX Runtime is specifically built to ensure fast and consistent inferencing of ONNX models across multiple platforms.
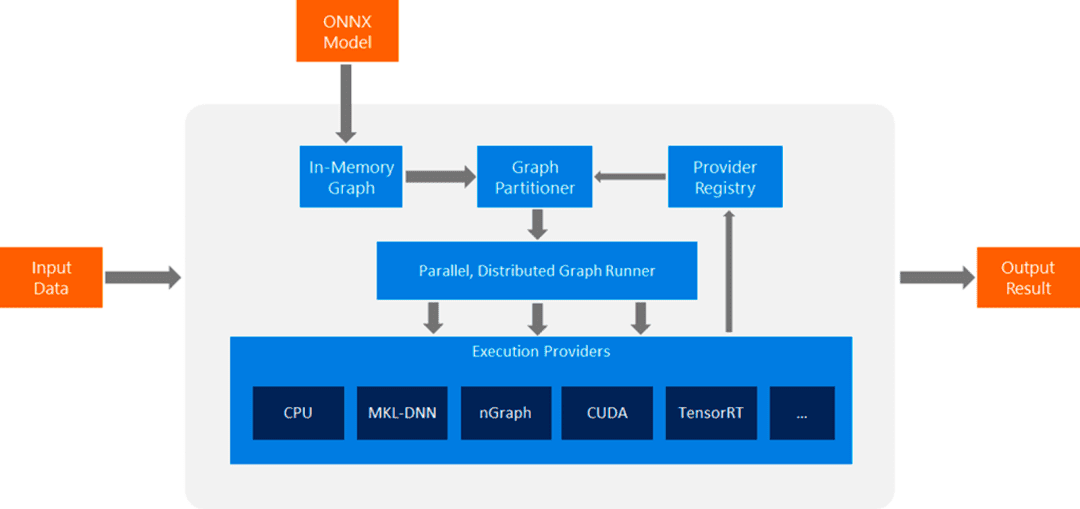
ONNX Runtime execution process: Input data is processed through an in-memory graph, partitioned, and executed across different hardware providers (CPU, MKL-DNN, CUDA, TensorRT) for efficient inference.
Why ONNX Runtime for Lambda?
- Lightweight: Uses minimal resources, reducing cold start times
- Optimized for CPUs: Works efficiently without requiring GPUs
- Faster Model Execution: Loads and executes ONNX models faster than traditional deep learning frameworks
How ONNX Runtime Works in AWS Lambda
- The ONNX model is preloaded inside the Lambda function.
- When a request comes in, ONNX Runtime executes inference in milliseconds.
- The output is returned via API Gateway.
import onnxruntime as ort
import numpy as np
# Load the ONNX model
session = ort.InferenceSession("resnet18.onnx")
def predict(data: list):
inputs = np.array(data, dtype=np.float32)
outputs = session.run(None, {"input": inputs})
return {"predictions": outputs}
How These Components Work Together (End-to-End Flow)
- A user sends an API request (
POST /infer) with an image (e.g.,cat.jpg). - API Gateway validates the request (optionally using authentication such as an API Key or Cognito) and forwards it to AWS Lambda.
- AWS Lambda (running FastAPI) processes the request:
- The image is preprocessed (resized, normalized).
- ONNX Runtime loads the ONNX model and runs inference.
- The predicted class index is mapped to an ImageNet label (e.g.,
"Siamese cat").
- The result is returned to the user via API Gateway in JSON format:
{
"predicted": "Siamese cat"
}
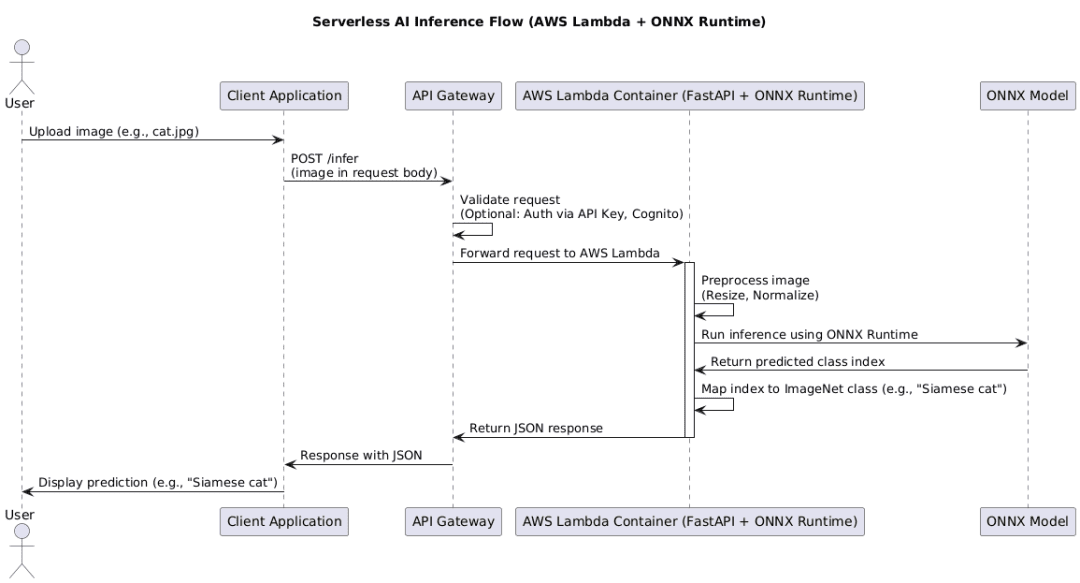
This combination makes AI inference scalable, cost-efficient, and easy to deploy.
Configuring Your Development Environment
Although this lesson focuses on architecture, we’ll prepare the environment for Python-based AWS Lambda deployments used in upcoming lessons.
To follow this guide, you need to set up a development environment with Python, AWS tools, and Node.js for both backend and frontend development.
Install Python Dependencies
Run the following command to install the required Python packages:
$ pip install fastapi[all]==0.98.0 numpy==1.25.2 onnxruntime==1.15.1 mangum==0.17.0 Pillow==9.5.0 timm==0.9.5 onnx==1.14.0
Install Node.js and npm for the Frontend
Since we’ll be building a Next.js frontend in later lessons, install Node.js now:
# Download and install Node.js (includes npm) https://nodejs.org/en/download/
Verify installation:
node -v npm -v
Other Required Tools
- AWS CLI: Required for configuring and deploying FastAPI to AWS Lambda.
- Docker (Optional): If you plan to test AWS Lambda functions locally. You can follow this step-by-step guide: Getting Started with Docker. As a data scientist, Docker is an essential tool for your local development setup.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
Here is the directory layout we will progressively leverage as we move through the series:
resnet-aws-serverless-classifier/ ├── src/ │ ├── server.py │ ├── convert.py │ ├── onnxt.py │ ├── onnx_local.py │ └── __init__.py ├── models/ │ ├── resnetv2_50.onnx │ └── imagenet_classes.txt ├── data/ │ ├── cat.jpg / dog.jpg │ ├── cat_base64.txt │ ├── event.json / payload.json / response.json ├── tests/ │ ├── prepare_event.py │ ├── test_boto3_lambda.py │ └── test_lam.py ├── frontend/ ├── Dockerfile ├── Dockerfile.local ├── docker-compose.local.yml ├── dev.sh ├── requirements.txt ├── requirements-local.txt ├── .dockerignore ├── .gitignore └── README.md
Progression Overview
Lesson 1 (Introduction): Concepts: AWS Lambda, API Gateway, and ONNX rationale. Light glance at ONNX runtime inference.
Lesson 2 (Model Conversion and Testing): Use convert.py and onnxt.py to produce and validate the ONNX model. Populate models/ and exercise sample inputs in data/.
Lesson 3 (FastAPI and Local Runtime): Implement inference route in server.py. Run locally with requirements-local.txt. Optionally introduce Dockerfile.local and dev.sh for iterative development.
Lesson 4 (Container Packaging Preparation): Refine server.py for container execution, ensure minimal dependencies (requirements.txt), and verify Docker build workflow.
Subsequent lessons will build on this foundation (deployment, invocation patterns, event crafting, frontend integration, and full stack exposure) using the remaining directories (tests/, data/ events, frontend/).
Notes
convert.pygenerates the ONNX model if not pre-downloaded.onnxt.pyhelps compare PyTorch vs ONNX outputs early.requirements.txtstays minimal for production images;requirements-local.txtsupports experimentation.tests/scripts simulate Lambda and API Gateway events once the deployment workflow is introduced.frontend/remains inactive until backend endpoints are stable.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This AWS Lambda lesson covered the fundamentals of serverless AI architecture, setting the foundation for building Python-based inference workflows in the next lesson.
In this lesson, we explored the fundamentals of serverless AI deployment and how AWS Lambda, API Gateway, and ONNX Runtime work together to create a scalable, cost-efficient AI inference pipeline. We started with an overview of serverless AI, discussing its advantages and limitations, and why AWS Lambda is a great fit for lightweight AI models.
We then introduced ONNX (Open Neural Network Exchange) as an optimized model format for inference in serverless environments. By using ONNX Runtime, we can significantly reduce model loading time and execution overhead, making it ideal for AWS Lambda’s constraints. Next, we took a deep dive into how AWS Lambda processes AI inference requests, how API Gateway acts as the front-end for serverless APIs, and why ONNX Runtime enables fast and efficient inference.
To ensure a smooth development workflow, we set up our local environment, installed the necessary dependencies, and ran a basic FastAPI server to simulate inference requests. Finally, we explored the project’s directory structure and how each file contributes to the final deployment.
What’s Next? (Lesson 2 Preview)
In the next lesson, we will convert a trained PyTorch model to ONNX format to make it ready for serverless inference. This is a crucial step in optimizing AI models for deployment, ensuring they load efficiently inside AWS Lambda.
We will also write a FastAPI endpoint to handle inference requests and then run it inside a Docker container. Running FastAPI in Docker mimics the AWS Lambda runtime environment, allowing us to debug and verify our model predictions before deployment.
By the end of Lesson 2, we will have converted a pre-trained PyTorch model to ONNX, compared its performance against the original model, and tested inference using ONNX Runtime. This will set the stage for Lesson 3, where we build a FastAPI inference server, containerize it with Docker, and run it locally to ensure a consistent environment before deploying to AWS Lambda in later lessons.
Stay tuned as we move one step closer to deploying a serverless AI-powered API on AWS Lambda!
Citation Information
Singh, V. “Introduction to Serverless Model Deployment with AWS Lambda and ONNX,” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/9yexs
@incollection{Singh_2025_intro-to-serverless-model-deployment-w-aws-lambda-and-onnx,
author = {Vikram Singh},
title = {{Introduction to Serverless Model Deployment with AWS Lambda and ONNX}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
year = {2025},
url = {https://pyimg.co/9yexs},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.