Table of Contents
- LlamaIndex: Building a Smarter RAG-Based Chatbot
- Understanding Retrieval Augmented Generation
- Limitations of Standalone Large Language Models in Production
- What Is Retrieval Augmented Generation (RAG)?
- Different Stages of a RAG System
- Introduction to LlamaIndex
- Building a RAG-Based Chatbot with LlamaIndex for AWS
- Summary
LlamaIndex: Building a Smarter RAG-Based Chatbot
In this tutorial, you will learn how to build a RAG-based chatbot using LlamaIndex.

In the dynamic world of artificial intelligence (AI), Retrieval Augmented Generation (RAG) is making waves by enhancing the generative capabilities of Large Language Models (LLMs). At its core, RAG combines the strengths of retrieval- and generation-based models, allowing LLMs to fetch relevant information from a vast database and generate coherent, contextually appropriate responses.
One of the latest advancements in this field is the LlamaIndex, a powerful tool designed to boost the capabilities of RAG-based applications further. LlamaIndex provides a very seamless way of combining retrieval- and generation-based models to build RAG-based applications. In this blog post, we’ll explore the intricacies of LlamaIndex and guide you through the process of building a smarter, more efficient RAG-based chatbot.
To learn how to build a RAG-based chatbot using LlamaIndex, just keep reading.
LlamaIndex: Building a Smarter RAG-Based Chatbot
Understanding Retrieval Augmented Generation
Limitations of Standalone Large Language Models in Production
While LLMs are trained on enormous amounts of data and have shown remarkable capabilities in various applications (e.g., next-word prediction, completion, text summarization, question answering, comprehension, classification, etc.), they are not trained on customized domain-specific tasks.
Imagine a scenario where a large e-commerce company uses a standalone large language model (LLM) to automate the handling of customer queries. In such scenarios, the LLM might not have detailed knowledge about specific products, policies, or services, leading to less accurate or relevant responses.
Suppose, for a moment, we finetune the LLM on past customer queries and their corresponding responses (given by a human assistant). This may solve the problem. But what about keeping them updated? Keeping the LLM updated with the latest product information, policies, and customer service protocols requires continuous retraining, which is resource-intensive.
This is where Retrieval Augmented Generation (RAG) comes into play. RAG (Figure 1) helps by providing LLMs access to our customized and ever-changing data in an efficient way that does not require continuous retraining.
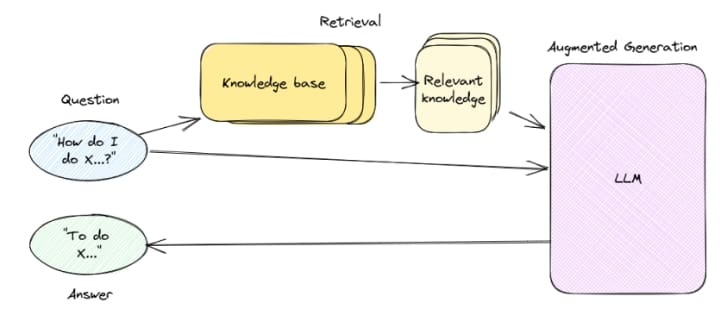
What Is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is an advanced approach in natural language processing (NLP) that combines the strengths of retrieval-based and generation-based models to enhance the performance and accuracy of AI systems, particularly in tasks like question answering and conversational AI.
In the RAG system, the personalized data is organized in the form of an “index” for quick and precise retrieval. Whenever a user issues a query, the system searches to find the most relevant information related to the query from the index. The retrieved information, along with the original query and prompt, are then fed into the LLM for it to respond.
Figure 2 illustrates how a RAG pipeline functions:
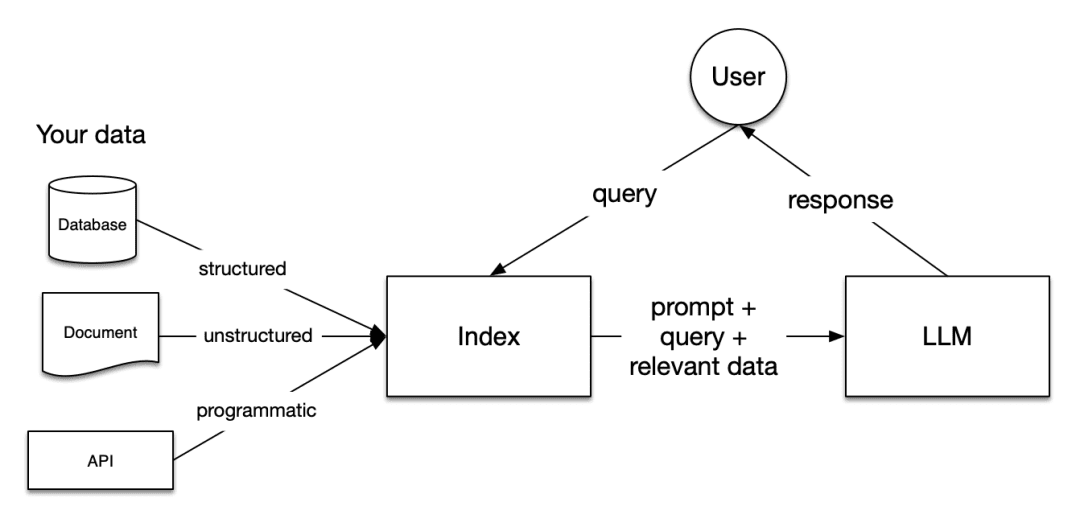
Different Stages of a RAG System
A RAG system comprises the following key stages.
Loading
Your personalized data can reside in different formats. It can either be text, PDFs, website pages, databases, APIs, images, etc. Loading refers to reading that data and parsing the relevant information from each document to be used by the pipeline.
Indexing and Storing
Indexing refers to the stage where the data is organized in the form of an index — a data structure for fast and precise querying. For LLMs, this process usually involves creating vector embeddings — a numerical representation of your data that captures the relevant information.
Once the data is indexed, it is stored in persistent storage to avoid re-indexing it for every query.
Querying
Whenever a user issues a query, the system first queries the index to fetch the most relevant piece of information from the given personalized data. This piece of information is combined with the query and a prompt and then fed to a Large Language Model for generating contextual appropriate responses.
This is where a RAG system helps the LLM by providing access to personalized data efficiently. Further, whenever the data gets updated, one only needs to update the index (by re-indexing), saving them from the resource-intensive process of retraining the LLM.
Evaluating
A crucial part of any pipeline is assessing its effectiveness compared to other methods or after implementing changes. Evaluation offers objective metrics to gauge the accuracy, reliability, and speed of your query responses.
Figure 3 illustrates the flowchart of different stages in a RAG system.

Introduction to LlamaIndex
The LlamaIndex (Figure 4) is a comprehensive framework designed to enhance the development and deployment of language model (LM) applications. It provides a set of tools to build retrieval augmented generation use cases from prototype to production. These tools allow us to ingest, parse, index, and process personalized data efficiently.
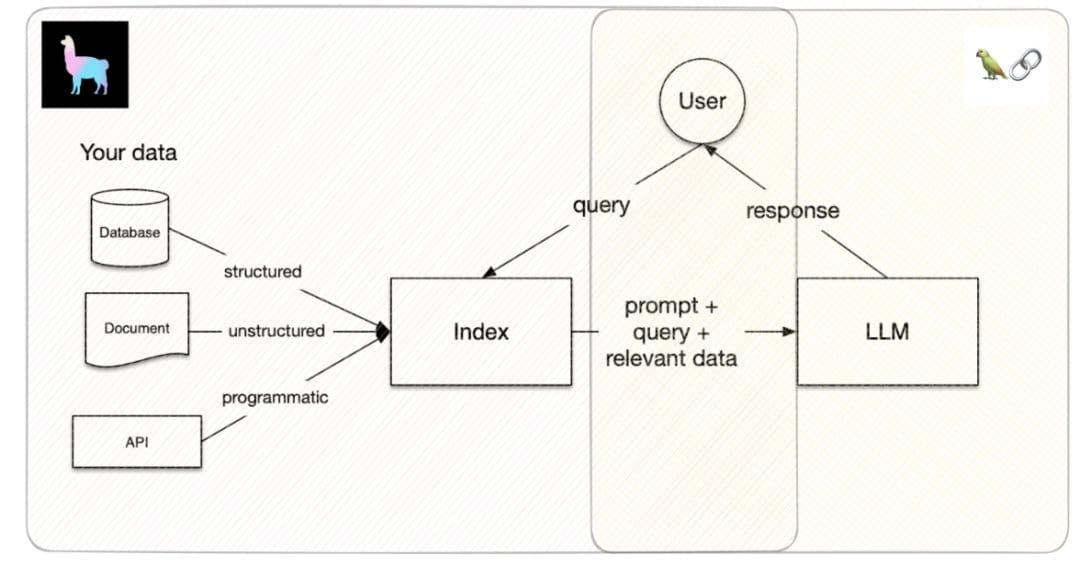
One can use LlamaIndex for almost all use cases, such as:
- Question-Answering Systems: Providing accurate answers using Retrieval Augmented Generation on the indexed data.
- Chatbots: Enhancing conversations using context-aware responses.
- Document Understanding: Parsing and extracting relevant information from documents (e.g., text files, PDFs, website pages, etc.).
- Autonomous Agents: LLM-powered agents that can perform research and take actions based on data.
- Multi-Modal Applications: Combining text, images, and other data types for comprehensive analysis.
Core Components of LlamaIndex
The following is a detailed breakdown of its key components and functionalities.
Data Ingestion
The LlamaIndex data connector allows easy integration, ingestion, parsing, and processing of various types of data sources (e.g., APIs, PDFs, text files, SQL databases, etc.).
Data Indexing
Index structures help create efficient data structures from the raw inputs for quick and precise retrieval. Index structures help convert these raw inputs to their intermediate representations (often vector embeddings) that are optimized for LLM consumption, ensuring high performance during data queries.
Query Engines
The LlamaIndex facilitates natural language queries over indexed data, making it easier to interact with complex datasets. Retrieval Augmented Generation (RAG) enhances the relevance and accuracy of responses by combining context with large language models (LLMs) during inference. This approach ensures that the generated responses are more precise and contextually appropriate.
LlamaIndex Engines provide natural language access to your data through powerful interfaces. Query engines are designed for question-answering tasks, such as those found in a RAG pipeline. In contrast, chat engines support conversational interactions, allowing for multi-message, back-and-forth exchanges with your data.
Evaluating and Benchmarking
Response Evaluation involves determining how well LLM-generated responses meet specific criteria for relevance and accuracy. Retrieval Evaluation focuses on the efficiency of the data retrieval process, ensuring that the most pertinent information is sourced for each query.
Observability and Evaluation
Integrated monitoring tools enable developers to track and assess the performance of their LLM applications in real-time. This allows for immediate insights and adjustments, ensuring that the applications run smoothly and efficiently.
Additionally, these tools facilitate rigorous experimentation with various configurations. Developers can optimize performance and swiftly identify any issues, creating a continuous cycle of evaluation and improvement for their applications.
Building a RAG-Based Chatbot with LlamaIndex for AWS
In this section, we will use LlamaIndex to build a RAG-based Chatbot (Figure 5) that can answer questions related to Amazon Web Services (AWS). We will use the AWS Case Studies and Blogs as an index to make the chatbot responses more contextually relevant.
Such a chatbot can be used in industry to automate the handling of customer inquiries related to AWS.
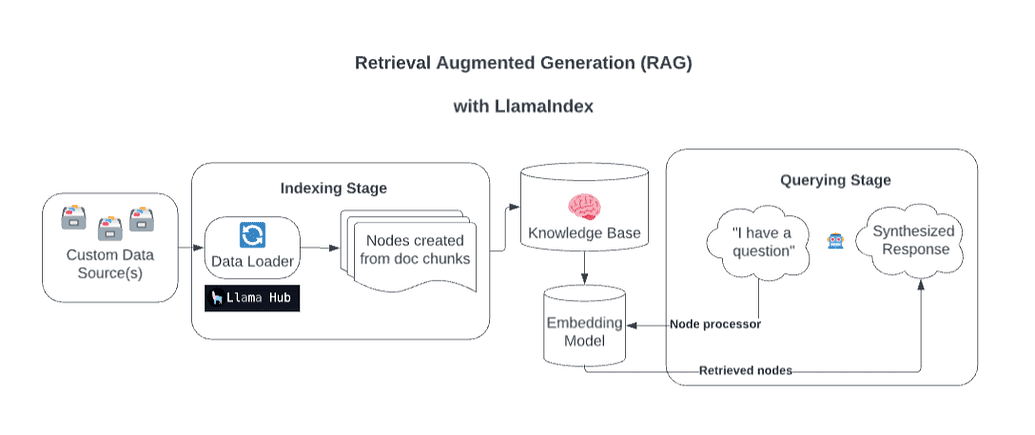
Downloading the Dataset
To start, we will first download the AWS Case Studies and Blogs dataset which is a collection of text files of Amazon Web Services (AWS) case studies and blog articles related to Generative AI and Large Language Models. Of the text files, 90% are case studies, and the rest are blog articles. The primary purpose of this dataset is to use it as a corpus for Retrieval Augmented Generation (RAG) with Large Language Models (LLMs).
We also install the following packages:
kaggle: command line API for downloading the datasets from Kaggle.llama-index: to load various LlamaIndex components.llama-index-llms-huggingfaceandllama-index-embeddings-huggingface: for loading embedding and generative models from Hugging Face.
$ pip install kaggle llama-index llama-index-llms-huggingface llama-index-embeddings-huggingface $ kaggle datasets download -d harshsinghal/aws-case-studies-and-blogs $ unzip /content/aws-case-studies-and-blogs.zip -d /content/aws-case-studies-and-blogs/
Building the Vector Store Index
Now that we have downloaded the dataset, it is time to load and process it. For this, we will use LlamaIndex data connectors that help ingest, parse, and process data from various sources (e.g., APIs, PDFs, text files, website pages, etc.).
In our case, the AWS Case Studies and Blog dataset comprises only text files. Hence, we will use SimpleDirectoryReader from llama_index.core to read and parse all the text documents present in the data folder.
Next, we perform indexing, which converts these text documents to their vector embeddings and builds an index structure for efficient and relevant retrieval. For this, we load a bge-base embedding model using HuggingFaceEmbedding API from llama_index.embeddings.huggingface.
Lastly, we use VectorStoreIndex from llama_index.core to build a vector embedding store for our documents. Once we have generated the index, we store it in our storage to avoid indexing every time.
import os
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
Settings
)
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# bge-base embedding model
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
# check if storage already exists
PERSIST_DIR = "./aws-storage-index"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader("/content/aws-case-studies-and-blogs/").load_data()
print("Total documents : ", len(documents))
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
On Line 14, we first set the embedding model to “BAAI/bge-base-en-v1.5”. Then, on Line 18, we check if a storage directory (PERSIST_DIR) exists. If it doesn’t, we read documents from a specified directory, create an index from these documents, and save the index for future use (Lines 20-24). If the storage directory already exists, it loads the existing index from storage (Lines 27 and 28).
Loading and Running an LLM Locally
We have created our index, so now it is time to load an LLM locally for building the chatbot. This LLM will be integrated with LlamaIndex to provide context-aware responses to user queries.
Here, we load the TinyLlama/TinyLlama-1.1B-Chat-v1.0 from the Hugging Face transformers library. This is the chat model finetuned on top of TinyLlama (1.1B Llama model on 3 trillion tokens) on a variant of the UltraChat dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")
model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0", torch_dtype=torch.float16, low_cpu_mem_usage=True)
tokenizer.save_pretrained("tinyllama-tokenizer")
model.save_pretrained("tinyllama-model", max_shard_size="1000MB")
To show the power of RAG, we will first query our loaded LLM without LlamaIndex (i.e., in standalone mode). We use the Hugging Face transformers library to create a text-generation pipeline using the TinyLlama/TinyLlama-1.1B-Chat-v1.0 model.
As a sample query, we ask the LLM: “What are different use cases of Amazon Sagemaker?”
from transformers import pipeline, AutoTokenizer
import torch
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto",
device='cuda'
)
prompt = "What are different use cases of Amazon Sagemaker?"
sequences = pipe(
prompt,
max_new_tokens=100,
do_sample=True,
top_k=10,
return_full_text = False,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
On Lines 42-49, we initialize the pipeline with our model and its tokenizer, set the data type to bfloat16, and configure it to use a CUDA device. Then, on Lines 51-59, we provide a sample query and generate text sequences based on this query, with a maximum of 100 new tokens, sampling enabled, and a top-k sampling strategy. Finally, on Lines 61 and 62, we print the generated text for each sequence.
From the output of the above code, you will notice that the LLM fails to generate accurate and contextually aware responses. In fact, it will generate an empty response.
This shows that open-source foundational LLMs might not have detailed knowledge about specific products, policies, or services and lead to less accurate or relevant responses.
Retrieving Context and Querying the LLM
Here, we update the LlamaIndex Settings.llm so that our standalone LLM now has access to the vector store index (created on AWS case studies and blogs) and can use it to retrieve relevant context for user queries.
We provide the same sample query: “What are different use cases of Amazon Sagemaker?” to our index.
from llama_index.llms.huggingface import HuggingFaceLLM
Settings.llm = HuggingFaceLLM(
context_window=2048,
max_new_tokens=256,
generate_kwargs={"temperature": 0.1, "do_sample": False},
tokenizer_name="tinyllama-tokenizer",
model_name="tinyllama-model",
tokenizer_kwargs={"max_length": 512},
model_kwargs={"torch_dtype": torch.float16}
)
# We can now query the index
query_engine = index.as_query_engine(similarity_top_k=2) # similarity_top_k is the number of documents the engine will retrieve from the index for context
response = query_engine.query("What are different use cases of Amazon Sagemaker?")
print(response)
On Lines 63-72, we first configure our language model using the HuggingFaceLLM class from the llama_index library. We set various parameters, including the context window, maximum new tokens, and generation settings, and specify the tokenizer and model names along with their respective configurations. Then, on Line 75, we initialize a query engine from the previously created index, setting it to retrieve the top two most similar documents for context. Finally, on Lines 76 and 77, we query the index and print the response.
This time, from the output (Figure 6) of the above code, we can see that the response to the same user query is contextually relevant.

By loading the same index in a chat mode now, we can convert our LLM to a RAG-based Chatbot.
import warnings
warnings.simplefilter("ignore")
query_engine = index.as_chat_engine()
print("Your bot is ready to talk! Type your messages here or send 'stop'")
while True:
query = input("<|user|>\n")
if query == 'stop':
break
response = query_engine.chat(query)
print("\n", response, "\n")
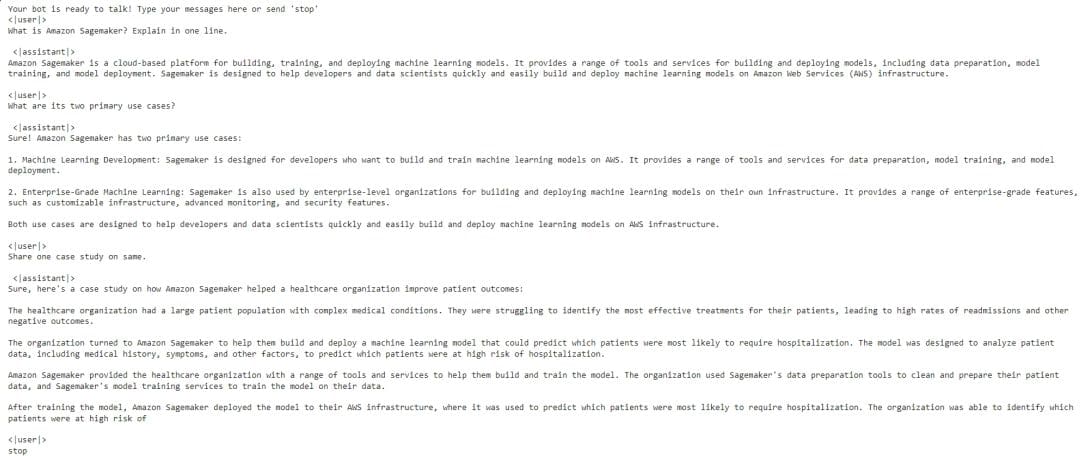
Figure 7 shows a sample conversation between the user and the chatbot assistant regarding Amazon Sagemaker:
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In the blog post, we explore the concept of Retrieval Augmented Generation (RAG) and its significance in enhancing the capabilities of LLMs. We start by understanding the limitations of standalone large language models in production, which often struggle with providing accurate and contextually relevant responses. RAG addresses these limitations by integrating retrieval mechanisms that augment the generation process, ensuring more precise and context-aware outputs.
We then delve into the different stages of a RAG system, including loading, indexing and storing, querying, and evaluation. The post introduces the LlamaIndex, a tool designed to streamline these processes. We discuss its core components (e.g., data ingestion, data indexing, query engines, and evaluation and benchmarking).
Finally, we walk through the following steps of building a RAG-based chatbot:
- using LlamaIndex for AWS
- covering dataset downloading
- building the vector store index
- running a local LLM
- retrieving context for querying
This comprehensive guide equips us with the knowledge to create more intelligent and efficient chatbots.
Citation Information
Mangla, P. “LlamaIndex: Building a Smarter RAG-Based Chatbot,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/0jvku
@incollection{Mangla_2024_LlamaIndex-Building-Smarter-RAG-Based-Chatbot,
author = {Puneet Mangla},
title = {LlamaIndex: Building a Smarter RAG-Based Chatbot},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/0jvku},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.