Table of Contents
- Image Processing with Gemini Pro
- Getting Started with Gemini Pro: An Overview
- Gemini Pro Setup
- Image Processing with Gemini Pro: Python Code Generation
- Comprehensive List of GenAI Models Compatible with Gemini Pro
- Key Advantages of Using Gemini Pro for Image Processing
- Potential Areas for Improvement in Gemini Pro
- Comparing ChatGPT-3.5 and Gemini Pro in Code Generation
- Exploring Bard’s Capabilities in Code Generation
- Concluding Thoughts on Image Processing with Gemini Pro
Image Processing with Gemini Pro
In this tutorial, you will learn how to leverage the Gemini Pro generative model with Google AI Python SDK (software development kit) to generate various image processing techniques in Python. Additionally, we’ll also delve into a comparative analysis with ChatGPT-3.5, offering insights into the strengths and nuances of each.

This lesson is the 2nd of a 6-part series on Gemini Pro.
- Introduction to Gemini Pro Vision
- Image Processing with Gemini Pro (this tutorial)
- Lesson 3
- Lesson 4
- Lesson 5
- Lesson 6
To learn how to use Gemini Pro for generating various image processing techniques and to understand its comparative performance against ChatGPT-3.5, just keep reading.
Image Processing with Gemini Pro
As 2023 drew to a close, DeepMind unveiled Gemini, a cutting-edge AI model that’s changing the game in how we interact with technology. It’s incredibly versatile, able to understand and process a mix of data types — from text and images to video and audio. This model isn’t just a one-size-fits-all solution. It comes in three variants, each designed for different needs and complexities: Ultra, Pro, and Nano.
Figure 1 shows the Google AI Studio snapshot, where using the Gemini Pro model image processing code is generated in Python.
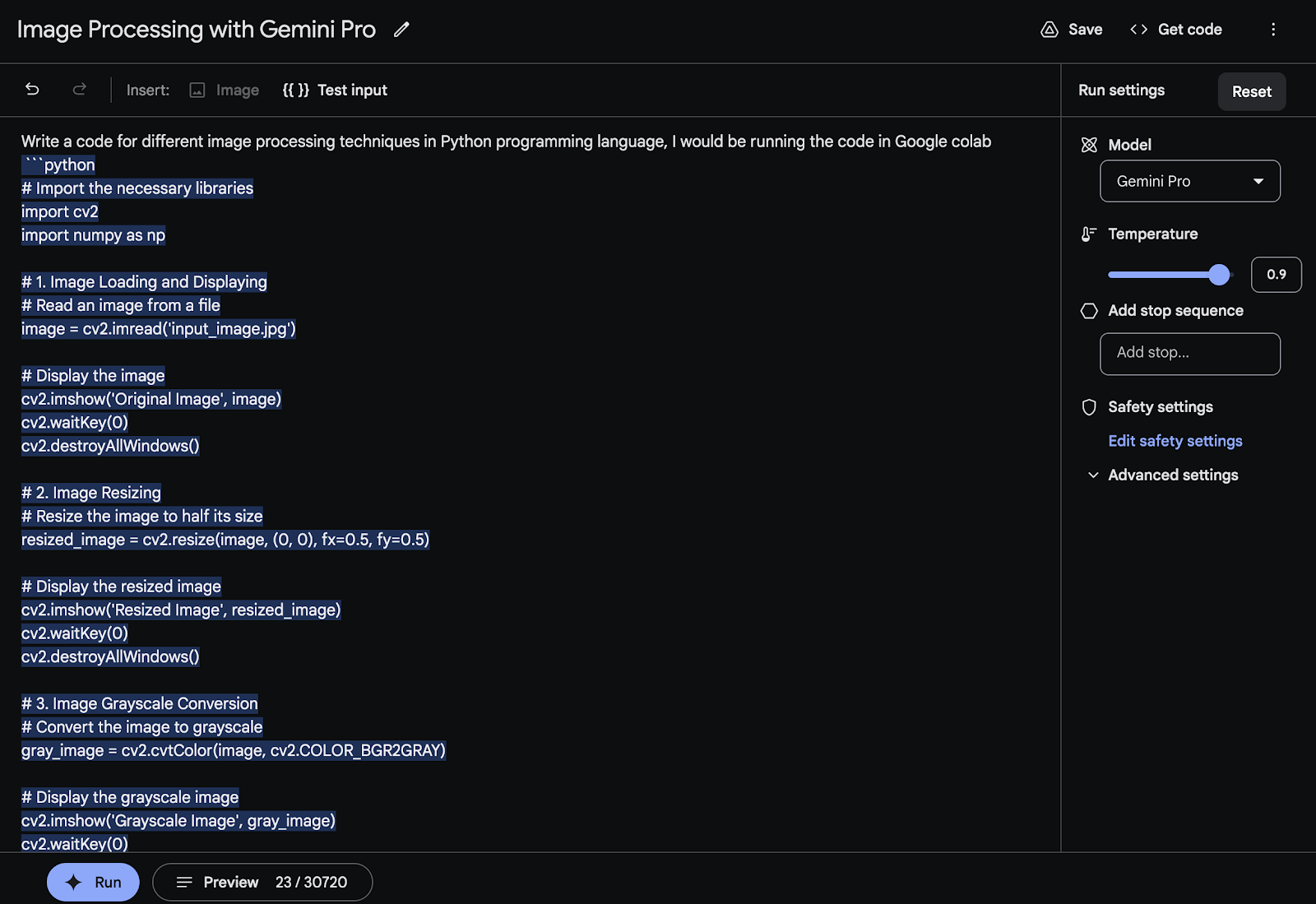
The Google Gemini Ultra model excels in performing intricate tasks with remarkable accuracy, whereas the Gemini Pro model is tailored to drive AI tools efficiently. On the other hand, the Gemini Nano model is specifically developed for seamless functionality on mobile devices.
In direct comparison, Gemini Ultra showcases superior capabilities over GPT-4, particularly in tasks that require a blend of reasoning, mathematics, code generation, and problem-solving skills.
You can find the Gemini Pro variant integrated into platforms like Google Cloud Vertex AI. Bard, a large language model from Google also powered by the LaMDA technology stack, including the Gemini family of models, offers similar capabilities but is not officially available as a separate platform.
On Google AI Studio, we have an option to choose Gemini Pro or Gemini Pro Vision. If you would like to know more about Gemini Pro Vision, then check out our PyImageSearch tutorial on Introduction to Gemini Pro Vision.
For today’s tutorial, we will be tinkering with the Gemini Pro model, so let’s briefly understand a bit about it!
Getting Started with Gemini Pro: An Overview
Gemini Pro, a generative model from Google, works by taking text as input and producing text as output. The input typically comes in the form of a text prompt, similar to the interaction style with ChatGPT. This model is widely accessible through Google Bard and can also be utilized via Google AI Studio or the Google AI Python SDK. Gemini Pro excels in various applications such as creative writing, summarization, sentiment analysis, and code generation. It supports an impressive array of around 38 languages.
Table 1 offers an in-depth look at the Gemini Pro model (as mentioned in the documentation), showcasing its proficiency in text processing and generation. It details the types of input and output the model can handle, illustrating its capability to engage in multi-turn conversations and tackle zero-shot, one-shot, and few-shot learning tasks.
| Gemini Pro | Model last updated | December 2023 |
| Model code | models/gemini-pro | |
| Model capabilities | • Input: text • Output: text • Generates text. • Can handle multi-turn conversational format. • Can handle zero, one, and few-shot tasks. | |
| Supported generation methods | generateContent | |
| Input token limit | 30720 | |
| Output token limit | 4096 | |
| Model safety | Automatically applied safety settings which are adjustable by developers. See the safety settings topic for details. | |
| Rate limit | 60 requests per minute |
For comparison, OpenAI’s GPT-3.5 typically works within token limits of about 4096 for both inputs and outputs. However, recent updates indicate a possible expansion to approximately 16,000 tokens. These specifications underscore the ability of these models to handle large-scale data inputs and produce detailed outputs, making them well-suited for a broad spectrum of uses, from simple inquiries to intricate conversational exchanges and complex problem-solving activities.
Given that Gemini Ultra surpasses GPT-4 in performance, a more equitable comparison might be between Gemini Pro and GPT-3.5. To fairly assess their capabilities, we’ll provide the same text prompt to both ChatGPT-3.5 and Gemini Pro, allowing us to observe which model delivers superior results.
Gemini Pro Setup
We will use the Google AI Python SDK, which provides programmatic access to the Gemini Pro model, among a few others.
To create your API key, start by visiting Google MakerSuite and sign in with your Google account if you haven’t already. Once logged in, you’ll be directed to the Google AI Studio. Here, you’ll find an option to generate your API key, as illustrated in Figure 2.
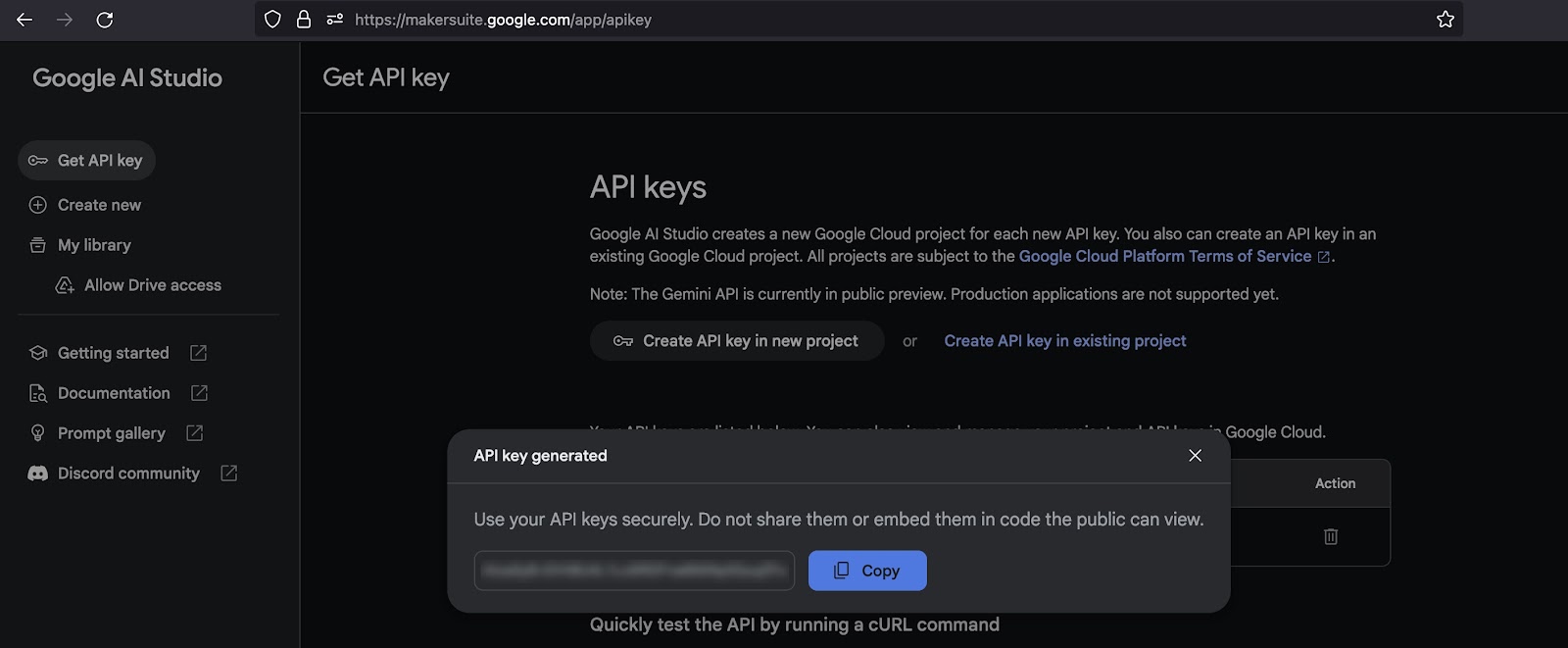
After generating the API key, be sure to copy and store it somewhere safe, as it will be essential for interacting with the Gemini Pro model in your image processing code generation.
Integrating Google AI Python SDK with Gemini Pro
The Google AI Python SDK provides developers with access to Google’s advanced generative AI models (e.g., Gemini and PaLM) for creating AI-driven features and applications.
This SDK caters to various functionalities, including:
- Creating text from text-only inputs
- Generating text from combined text-and-images inputs (multimodal), exclusive to Gemini
- Developing multi-turn conversational interfaces (chat)
- Utilizing embedding features
To interact with Google’s generative models and especially, the Gemini Pro model in Python, we need to install the google-generativeai dependency using pip, as shown below.
!pip install -q -U google-generativeai
Line 1: Installs the google-generativeai library.
Now that we have set up the API key to interact with the Gemini Pro model and also installed the google-generativeai package, we are all set to prompt the Gemini Pro model for generating image processing code in Python.
Image Processing with Gemini Pro: Python Code Generation
In this section, we will demonstrate how to use the Google AI Python SDK to generate code using the Gemini Pro model.
import textwrap import google.generativeai as genai from IPython.display import Markdown import PIL.Image import urllib.request
Lines 1-5: Import various modules necessary for handling images, displaying outputs in Colab, and managing API keys securely:
textwrap: for text manipulationgoogle.generativeai(aliased asgenai): the main module for AI functionalitiesIPython.display.Markdown: This module is used for displaying outputs formatted as Markdown within IPython interfaces such as Jupyter Notebooks or Google Colab. It allows for rich text representation, including formatting elements like headers, bold or italic text, bullet lists, and links, directly in the output cells of the notebook.PIL.Imageandurllib.request: are for handling and downloading images
# Used to securely store your API key
from google.colab import userdata
# Or use `os.getenv('GOOGLE_API_KEY')` to fetch an environment variable.
GOOGLE_API_KEY=userdata.get("GEMINI_API_KEY")
genai.configure(api_key=GOOGLE_API_KEY)
Lines 8-11: The google.colab library’s userdata module is used to retrieve an API key for the Gemini model securely. The key, identified by “GEMINI_API_KEY”, is fetched and stored in the variable GOOGLE_API_KEY. Alternatively, one could use os.getenv('GOOGLE_API_KEY') to get the API key from an environment variable.
Finally, genai.configure(api_key=GOOGLE_API_KEY) is called to configure the GenAI library with the retrieved API key, enabling authenticated access to its features and models. This setup is particularly useful in Google Colab notebooks for secure API key management.
for m in genai.list_models(): if "generateContent" in m.supported_generation_methods: print(m.name)
Lines 13-15: The script lists and prints the names of available models in the google-generativeai library that support content generation. This step helps in understanding what models are available for use. We can see from the output below that gemini-pro and gemini-pro-vision are available for use.
models/gemini-pro models/gemini-pro-vision
model = genai.GenerativeModel("gemini-pro")
Line 17: Creates an instance of the GenerativeModel class from the genai library and initializes it with the “gemini-pro” model. This means the variable model now represents the Gemini Pro model, allowing for its use in various AI-driven tasks (e.g., text generation and data analysis).
While the GenerativeModel can accept optional parameters (e.g., generation_config and safety_settings), in this case, they are not explicitly passed, indicating the use of the model’s default settings. The default generation_config includes parameters like temperature, top_p, top_k, and max_output_tokens, influencing the model’s content generation. safety_settings pertain to content filtering thresholds for categories like harassment and hate speech. By omitting these optional parameters, the model operates with its predefined configurations, streamlining setup and usage within the genai library framework. This setup process is crucial for preparing the model for the code generation task.
We will explore the generation_config parameters shortly.
Comprehensive List of GenAI Models Compatible with Gemini Pro
import pprint for model in genai.list_models(): pprint.pprint(model)
Lines 19-21: Imports the pprint module for formatted output and iterates through a list of models provided by the genai library, using genai.list_models(). For each model in this list, it utilizes pprint.pprint() to display the details of the model in a structured and readable format. This approach is particularly useful for examining complex or nested data about each model.
Model(name='models/gemini-pro',
base_model_id='',
version='001',
display_name='Gemini Pro',
description='The best model for scaling across a wide range of tasks',
input_token_limit=30720,
output_token_limit=2048,
supported_generation_methods=['generateContent', 'countTokens'],
temperature=0.9,
top_p=1.0,
top_k=1)
The genai.list_models() function returns details for seven different models within the GenAI framework. Among these, we are particularly interested in the Gemini Pro model. Here’s a breakdown of its key parameters:
- Model Name: ‘models/gemini-pro’
- Version: ‘001’
- Display Name: ‘Gemini Pro’
- Description: Described as “The best model for scaling across a wide range of tasks,” Gemini Pro is positioned as a versatile and scalable solution.
- Input Token Limit:
30720tokens. This high limit allows for processing large amounts of input data, making it suitable for complex tasks. - Output Token Limit:
2048tokens. This determines the maximum length of the model’s output, balancing detail with conciseness. - Supported Generation Methods: Includes
['generateContent', 'countTokens']. ‘generateContent’ is likely used for generating responses or content, while ‘countTokens’ might be for estimating the token count of a given input or output. - Temperature: Set at
0.9, which implies a higher level of creativity or variability in the model’s responses. A higher temperature typically leads to more diverse and less predictable outputs. - Top-p (Top Probability): Set at
1.0, indicating that the model will consider all possible next tokens (up to the limit set by the temperature) when generating responses, leading to more diverse outputs. - Top-k: Set at
1, suggesting that the model will restrict its choices to the topmost probable next tokens.
In summary, Gemini Pro is characterized by its high input and output token limits and a configuration that favors creative, diverse content generation. Its settings make it well-suited for a wide range of generative tasks, from text generation to complex problem-solving.
def to_markdown(text):
text = text.replace("•", " *")
return Markdown(textwrap.indent(text, "> ", predicate=lambda _: True))
Lines 23-25: Define a helper function to_markdown designed to take a string text and convert it into a formatted Markdown representation, specifically for use in environments like Jupyter notebooks that support Markdown rendering.
- It first replaces all bullet point characters “•” in the text with Markdown’s asterisk-based bullet point syntax (” *”).
- Then, it indents every line of the text with a blockquote symbol (“> “), using the
textwrap.indentfunction. This operation is applied to all lines of the text, as indicated by the lambda functionlambda _: True. - Finally, the function returns the text as a Markdown object, making it ready for display in environments that support Markdown rendering (e.g., Jupyter notebooks).
This process formats the text into a Markdown-compatible layout, which is particularly useful for enhancing the presentation of the text in supported environments.
response = model.generate_content(
"Write a code for different image processing techniques in Python programming language, I would be running the code in Google colab",
stream=True
)
to_markdown(response.text)
Lines 27-30: The code uses the model.generate_content function to generate code based on a text prompt (“Write a code for different image processing techniques in Python programming language, I would be running the code in Google colab”). The stream=True parameter indicates the model’s response will be streamed. Line 31: Following this, to_markdown(response.text) formats the received text response into Markdown, enhancing its readability and presentation, which is particularly useful in Markdown-supported environments (e.g., Jupyter notebooks).
# Load an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Display the image
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
1. Convert an Image to Grayscale
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Convert the image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Display the grayscale image
cv2.imshow('Grayscale Image', gray_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
2. Blur an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Blur the image using a Gaussian filter
blurred_image = cv2.GaussianBlur(image, (5, 5), 0)
# Display the blurred image
cv2.imshow('Blurred Image', blurred_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
3. Sharpen an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Sharpen the image using a Laplacian filter
sharpened_image = cv2.Laplacian(image, cv2.CV_64F)
# Display the sharpened image
cv2.imshow('Sharpened Image', sharpened_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.Detect Edges in an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Detect edges in the image using a Canny edge detector
edges = cv2.Canny(image, 100, 200)
# Display the edge-detected image
cv2.imshow('Edge-Detected Image', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
5. Resize an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Resize the image to half its original size
resized_image = cv2.resize(image, (0, 0), fx=0.5, fy=0.5)
# Display the resized image
cv2.imshow('Resized Image', resized_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
6. Crop an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Crop the image to a specific region
cropped_image = image[y:y+h, x:x+w]
# Display the cropped image
cv2.imshow('Cropped Image', cropped_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
7. Rotate an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Rotate the image by 45 degrees clockwise
rotated_image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# Display the rotated image
cv2.imshow('Rotated Image', rotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
8. Flip an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Flip the image vertically
flipped_image = cv2.flip(image, 0)
# Flip the image horizontally
flipped_image = cv2.flip(image, 1)
# Display the flipped images
cv2.imshow('Vertically Flipped Image', flipped_image)
cv2.imshow('Horizontally Flipped Image', flipped_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
9. Threshold an Image
import cv2
# Load an image
image = cv2.imread('image.jpg')
# Convert the image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Threshold the image using a binary threshold
thresh, binary_image = cv2.threshold(gray_image, 127, 255, cv2.THRESH_BINARY)
# Display the thresholded image
cv2.imshow('Thresholded Image', binary_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
The code generation by Gemini Pro in response to the prompt for image processing techniques in Python does showcase the model’s ability to understand and implement a variety of fundamental image processing operations. Here’s an evaluation of the code output, considering both the positives and the areas that need improvement.
Key Advantages of Using Gemini Pro for Image Processing
- Gemini Pro successfully generates syntactically correct Python code for each requested image processing task, demonstrating a good grasp of the OpenCV library functions.
- The code snippets are well-structured and easy to understand, indicating a clear approach to each task.
- The model covers a comprehensive range of image processing techniques, from basic operations (e.g., grayscale conversion and resizing) to more complex procedures (e.g., edge detection and thresholding).
- Each operation is effectively isolated, which makes the individual blocks of code reusable and modular for different purposes.
Potential Areas for Improvement in Gemini Pro
- The code uses
cv2.imshowfor display, which is not suitable for Google Colab environments since they cannot create windows to display images. In Colab,matplotlib,cv2_imshow, or IPython’sdisplayfunctions should be used to show images inline. - The code does not include any package installation instructions, which are necessary in a Colab notebook since OpenCV is not pre-installed.
- The model redundantly imports the
cv2library before each task, which is unnecessary and not a best practice in Python scripting. A single import at the beginning of the script would suffice. - There’s an issue with the flip operation where the horizontal flip would overwrite the vertical flip because the same variable name is used for both operations.
- For the crop operation, the required parameters
x,y,w, andhare not defined, which would result in an error if the code were run as is. - Repeated Code Blocks: The code includes repeated blocks for loading and displaying images for each image processing technique. This could be optimized by loading the image once and then applying different processing techniques to the same image. Similarly, a function could be defined for displaying images to reduce repetition.
- Code Comments and Documentation: While the code is generally clear, it lacks comments explaining each processing step or the choice of parameters (e.g., kernel sizes in blurring or thresholds in edge detection). Adding comments would make the code more understandable, especially for users who are new to image processing.
- Use of Variables for File Paths: The code uses a hardcoded file path (
image.jpg) for loading images. It’s generally a good practice to define file paths as variables at the beginning of the script, making it easier to change the file path without having to search through the entire code.
In conclusion, while Gemini Pro shows proficiency in generating code for various image processing techniques, the output requires adjustments not just for compatibility with the Google Colab environment, but also to adhere to best coding practices. This includes optimizing import statements, fixing variable overwrites, and ensuring completeness in function parameters. Regardless of the environment used for execution, these improvements are necessary to enhance the functionality and efficiency of the code.
Despite these areas for enhancement, the code demonstrates a strong foundational understanding of image processing tasks using Python and OpenCV, making it a valuable resource with some refinement.
Comparing ChatGPT-3.5 and Gemini Pro in Code Generation
In the following segment, we examine ChatGPT-3.5’s prowess in generating Python code for image processing by using the same prompt provided to Gemini Pro. The previous section has already dissected Gemini Pro’s code generation in depth. Here, we shift our lens to ChatGPT-3.5, presenting its generated code to juxtapose against Gemini Pro’s capabilities.
Certainly! Here's an example code that demonstrates various image processing techniques using Python in a Google Colab environment. We'll use the popular libraries OpenCV and Matplotlib for image manipulation and visualization. First, make sure you have OpenCV and Matplotlib installed in your Colab environment:
```python
!pip install opencv-python-headless
!pip install matplotlib
```
Now, let's proceed with the code for various image processing techniques:
```python
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load an image from your Colab environment
image_path = 'path_to_your_image.jpg'
img = cv2.imread(image_path)
# Display the original image
plt.figure(figsize=(8, 8))
plt.subplot(331)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.title('Original Image')
plt.axis('off')
# Convert image to grayscale
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.subplot(332)
plt.imshow(gray_img, cmap='gray')
plt.title('Grayscale Image')
plt.axis('off')
# Resize the image
new_size = (300, 300)
resized_img = cv2.resize(img, new_size)
plt.subplot(333)
plt.imshow(cv2.cvtColor(resized_img, cv2.COLOR_BGR2RGB))
plt.title('Resized Image')
plt.axis('off')
# Apply Gaussian Blur
blurred_img = cv2.GaussianBlur(img, (9, 9), 0)
plt.subplot(334)
plt.imshow(cv2.cvtColor(blurred_img, cv2.COLOR_BGR2RGB))
plt.title('Blurred Image')
plt.axis('off')
# Edge Detection using Canny
edges = cv2.Canny(img, 100, 200)
plt.subplot(335)
plt.imshow(edges, cmap='gray')
plt.title('Edge Detection (Canny)')
plt.axis('off')
# Histogram Equalization
equalized_img = cv2.equalizeHist(gray_img)
plt.subplot(336)
plt.imshow(equalized_img, cmap='gray')
plt.title('Histogram Equalization')
plt.axis('off')
# Thresholding
_, thresh_img = cv2.threshold(gray_img, 127, 255, cv2.THRESH_BINARY)
plt.subplot(337)
plt.imshow(thresh_img, cmap='gray')
plt.title('Thresholding')
plt.axis('off')
# Rotate the image
angle = 45
rows, cols, _ = img.shape
rotation_matrix = cv2.getRotationMatrix2D((cols/2, rows/2), angle, 1)
rotated_img = cv2.warpAffine(img, rotation_matrix, (cols, rows))
plt.subplot(338)
plt.imshow(cv2.cvtColor(rotated_img, cv2.COLOR_BGR2RGB))
plt.title('Rotated Image')
plt.axis('off')
# Invert colors
inverted_img = cv2.bitwise_not(img)
plt.subplot(339)
plt.imshow(cv2.cvtColor(inverted_img, cv2.COLOR_BGR2RGB))
plt.title('Inverted Image')
plt.axis('off')
plt.tight_layout()
plt.show()
```
Make sure to replace `'path_to_your_image.jpg'` with the path to the image you want to process. This code snippet demonstrates loading, resizing, grayscale conversion, blurring, edge detection, histogram equalization, thresholding, rotation, and color inversion. You can further customize and extend these techniques as per your image processing requirements in Google Colab.
ChatGPT-3.5’s response exhibits a comprehensive approach, beginning with installation instructions for OpenCV and Matplotlib, essential for image processing in Google Colab. The code generated by ChatGPT-3.5 demonstrates a range of techniques (e.g., grayscale conversion, resizing, blurring, edge detection, histogram equalization, thresholding, rotation, and color inversion). Notably, it employs Matplotlib for displaying images, aligning well with Google Colab’s environment. This demonstrates ChatGPT-3.5’s understanding of the Colab platform and its limitations compared to traditional Python environments.
In contrast to Gemini Pro’s individual and repeated code blocks for each technique, ChatGPT-3.5’s output is streamlined into a single script with a subplot for each technique, offering a more integrated and visually cohesive presentation. This approach, along with the inclusion of Matplotlib for image display, suggests a nuanced understanding of Python scripting in a notebook environment.
Overall, ChatGPT-3.5’s generation, while covering a similar breadth of techniques, showcases a more Colab-friendly approach and a unified structure that facilitates easy comparison and visualization of different image processing results within a single script. This contrasts with Gemini Pro’s more segmented, task-specific code blocks, each independently handling image loading and display.
Exploring Bard’s Capabilities in Code Generation
In our quest to compare the capabilities of various AI-driven generation models, we also explored Bard, powered by Gemini. Like Gemini Pro and ChatGPT-3.5, Bard was prompted to generate Python code for image processing, compatible with Google Colab. This comparison aims to evaluate how each model interprets and responds to the same task (even though Bard is powered with Gemini), particularly focusing on their adaptability to the Colab environment.
Here's a code template incorporating various image processing techniques in Python, compatible with Google Colab:
Python
import cv2
import numpy as np
# Load the image
img = cv2.imread('path/to/your/image.jpg')
# Check if image loaded successfully
if img is None:
print("Error loading image")
exit()
# **1. Resizing**
resized_img = cv2.resize(img, (300, 200)) # Resize to width=300, height=200
# **2. Grayscale conversion**
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# **3. Blurring**
blurred_img = cv2.blur(img, (5, 5)) # Apply Gaussian blur with kernel size 5x5
# **4. Edge detection**
edges = cv2.Canny(img, 100, 200) # Apply Canny edge detection
# **5. Thresholding**
ret, thresh = cv2.threshold(gray_img, 127, 255, cv2.THRESH_BINARY)
# **6. Morphological operations (optional)**
kernel = np.ones((5, 5), np.uint8)
erosion = cv2.erode(img, kernel, iterations=1)
dilation = cv2.dilate(img, kernel, iterations=1)
# **7. Display or save results**
cv2.imshow('Original Image', img)
cv2.imshow('Resized Image', resized_img)
cv2.imshow('Grayscale Image', gray_img)
cv2.imshow('Blurred Image', blurred_img)
cv2.imshow('Edge Detection', edges)
cv2.imshow('Thresholded Image', thresh)
# Optionally display erosion and dilation results
cv2.waitKey(0)
cv2.destroyAllWindows()
# **8. Save results to files (optional)**
cv2.imwrite('resized_image.jpg', resized_img)
cv2.imwrite('grayscale_image.jpg', gray_img)
# ... and so on
To run this code in Google Colab:
Create a new Colab notebook.
Install the OpenCV library: !pip install opencv-python
Upload your image file to Colab or provide a public link to it.
Replace 'path/to/your/image.jpg' with the actual path or link to your image.
Run the code cells.
Key points:
Import necessary libraries: cv2 for image processing and numpy for numerical operations.
Load the image: Use cv2.imread() to load the image from a file.
Apply techniques: Use functions like cv2.resize(), cv2.cvtColor(), cv2.blur(), cv2.Canny(), and cv2.threshold() for various image processing tasks.
Display or save results: Use cv2.imshow() to display images and cv2.imwrite() to save them to files.
Remember to:
Adjust parameters (e.g., kernel sizes, thresholds) as needed for your specific image and desired results.
Explore additional techniques and functions available in OpenCV for more advanced image processing tasks.
Bard’s response, while acknowledging Google Colab compatibility, interestingly still resorts to using cv2.imshow for displaying images. This is a crucial observation, as cv2.imshow does not function in Google Colab’s environment, where images need to be displayed inline using libraries like Matplotlib or IPython’s display methods. Despite this, Bard’s code is comprehensive and well-structured, covering a range of image processing techniques (e.g., resizing, grayscale conversion, blurring, edge detection, thresholding, and morphological operations).
Each technique is clearly outlined and applied to the image, with additional checks for successful image loading. Bard also provides instructions for saving the processed images, which is useful for documenting changes. However, the reliance on cv2.imshow indicates a gap in adapting the code for the specific runtime environment of Colab, similar to what was observed with Gemini Pro.
While Bard’s generated code is functionally rich and demonstrates a strong understanding of OpenCV’s capabilities, the oversight in display methods for Colab suggests a need for more contextual awareness in code generation. This comparison highlights the nuances in how AI models interpret and respond to coding tasks, revealing both their strengths and areas for further development.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Concluding Thoughts on Image Processing with Gemini Pro
This blog post explored the capabilities of Gemini Pro, a key component of the Google AI Python SDK, in the context of image processing. It began with an introduction to Gemini Pro, detailing its role in AI-driven image manipulation. The setup process for Gemini Pro was outlined, guiding readers through the Google AI Python SDK.
Central to the post was an analysis of the Python code generated by Gemini Pro for various image processing tasks. The code’s precise syntax and clear structure were commended. However, shortcomings were also identified, including issues like environment-specific limitations for Google Colab, errors, and variables being overwritten in the generated code. These highlighted the need for improvements in both adaptability and accuracy.
The post then shifted to comparing Gemini Pro with ChatGPT-3.5 and Bard, focusing on their code generation for similar image processing tasks. ChatGPT-3.5 stood out for its ability to produce code compatible with Google Colab, using Matplotlib for image display, a feature that Gemini Pro and Bard missed. Additionally, ChatGPT-3.5 showed fewer errors and variable conflicts.
In conclusion, the post reflected that while Gemini Pro shows promise in code generation for image processing, it falls short in environment adaptability and error-free code generation, areas where ChatGPT-3.5 excels. The comparison suggested that Google’s Gemini Pro, despite its advanced capabilities, still requires enhancements in flexibility and debugging to match the contextual awareness and error management seen in ChatGPT-3.5.
Citation Information
Sharma, A. “Image Processing with Gemini Pro,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/sotef
@incollection{Sharma_2024_Image-Processing-with-Gemini-Pro,
author = {Aditya Sharma},
title = {Image Processing with Gemini Pro},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/sotef},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.