Table of Contents
- Evaluating Siamese Network Accuracy (F1-Score, Precision, and Recall) with Keras and TensorFlow
- Building the Face Recognition Application with Siamese Networks
- Introduction to Model Evaluation in Face Recognition
- Introduction to Siamese Networks in Facial Recognition Systems
- Utilizing Siamese Networks for Face Verification
- Overview of the Face Verification Pipeline with Siamese Networks
- Implementing Face Recognition and Verification
- The Role of Siamese Network Training in Enhancing Face Recognition Accuracy
- Evaluating the Accuracy of Siamese Network-Based Face Recognition
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- Project Structure
- Face Recognition Model Evaluation: Understanding Precision, Recall, and F1-Score
- The Importance of a Diverse Test Set in Model Evaluation
- Choosing Representative Subjects for Reliable Evaluation
- Deep Dive into the Model Evaluation Process
- Beyond Accuracy: Exploring Advanced Metrics for Model Evaluation
- Precision, Recall, and F1-Score: Understanding the Core Metrics
- Implementing Precision and Recall Calculations in Python
- Defining Key Evaluation Metrics: Precision and Recall
- Introducing the F1-Score for Balanced Model Assessment
- Importing Essential Libraries for Siamese Network Evaluation
- Detailed Explanation of Metric Calculation in Python
- Crafting a Custom Function for Precision, Recall, and F1-Score
- Defining the Metrics Function for Model Evaluation
- Binary Classification Approach in Metrics Calculation
- Computing True Positives, Negatives, and False Metrics
- Calculating Precision, Recall, and F1-Score in Practice
- Loading and Configuring the Siamese Model for Inference
- Loading the Trained Siamese Model for Evaluation
- Initializing the Siamese Model for Data Analysis
- Setting Up a Data Pipeline for Effective Model Testing
- Creating a Robust Data Pipeline for Model Testing
- Assembling the Test Dataset for Model Accuracy Assessment
- Constructing a Face Database for Comprehensive Testing
- Preparing the Face Database and Test Dataset for Evaluation
- Preparing Face Database Entries for Accurate Model Evaluation
- Structuring Data for Siamese Model Evaluation
- Implementing Predictive Analysis with the Siamese Model
- Making Predictions and Evaluating the Siamese Model
- Conducting Predictive Testing on the Dataset
- Calculating Distances for Facial Recognition
- Analyzing Embedding Distances for Accurate Identification
- Analyzing Distance-Based Predictions in Siamese Networks
- Preparing Data for Accuracy and Class-Wise Metric Evaluation
- Calculating Class-Specific Metrics for In-Depth Analysis
- Leveraging Confusion Matrix for Holistic Performance Insight
- Using Confusion Matrix for Comprehensive Model Evaluation
- Implementing Confusion Matrix in Python for Siamese Model
- Direct Calculation of Recall and Precision from Confusion Matrix
- Deriving Overall Precision, Recall, and F1-Score
- Summary and Conclusion
Evaluating Siamese Network Accuracy (F1 Score, Precision, and Recall) with Keras and TensorFlow
In this tutorial, we will learn to evaluate our trained Siamese network based face recognition application, which we built in the previous tutorials of this series. We will discuss and understand the different metrics (i.e., accuracy, precision, recall, F1 score) that we can use to evaluate our model and analyze its performance on novel unseen faces for face recognition.

Building the Face Recognition Application with Siamese Networks
In the previous tutorial of this series, we discussed how we could put together the modules that we developed in the initial parts of this series to build our end-to-end face recognition application.
Also, we implemented the procedure and code to train our Siamese network based model end-to-end. Furthermore, we discussed in detail the process and code involved in making predictions with our trained model in real-time.
Introduction to Model Evaluation in Face Recognition
In this tutorial, we will take this further and learn how to evaluate our trained model using Keras and TensorFlow. This will allow us to get a sense of its performance on novel unseen data and quantify its generalization capabilities for real-world applications.
This lesson is the last in our 5-part series on Siamese networks and their application in face recognition:
- Face Recognition with Siamese Networks, Keras, and TensorFlow
- Building a Dataset for Triplet Loss with Keras and TensorFlow
- Triplet Loss with Keras and TensorFlow
- Training and Making Predictions with Siamese Networks and Triplet Loss
- Evaluating Siamese Network Accuracy (F1 Score, Precision, and Recall) with Keras and TensorFlow (this tutorial)
To learn how to evaluate the performance of your Siamese Network model, just keep reading.
Introduction to Siamese Networks in Facial Recognition Systems
In the first part of this series, we tried to understand how Siamese networks can be used to build effective facial recognition systems. Specifically, we discussed the various face recognition techniques and the difference between face identification and verification.
Furthermore, we discussed how verification can be used for identifying faces. We established that it is a much more efficient, scalable, and effective way of implementing face identification as it requires a simple similarity-based comparison approach at inference.
We recommend readers go through the first part of this series to better understand the concepts we will use in this post.
Utilizing Siamese Networks for Face Verification
In this tutorial, we will use our trained Siamese network as a verification system to recognize faces and evaluate their performance on the unseen test set.
Overview of the Face Verification Pipeline with Siamese Networks
Let us get a quick recap first of how the verification pipeline works and allows us to identify faces and how we can evaluate our pipeline on novel unseen faces at test time.
Figure 1 shows the verification pipeline for Face Recognition. Let us discuss this in detail and understand how the performance evaluation can be implemented for such a set-up.
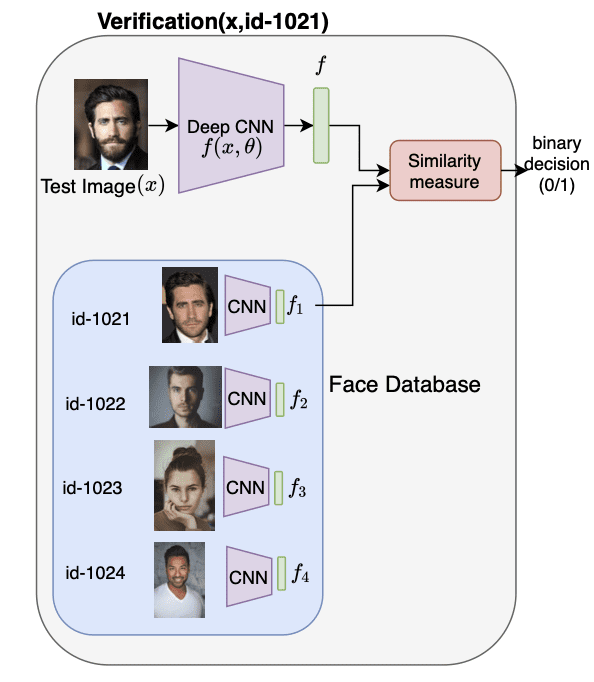
Implementing Face Recognition and Verification
Given that we want to identify people with id-1021 to id-1024, we are given 1 image (or a few samples) of each person, which allows us to add the person to our face recognition database.
We use our model (shown as CNN (convolutional neural network) in Figure 1) to compute the feature embedding corresponding to each face in our database (i.e.,  ,
,  ,
,  ,
,  ) and store the embedding in our database as shown.
) and store the embedding in our database as shown.
Now, given a novel unseen image from our test set (i.e., ") ), we compute its corresponding feature using our trained model as shown.
), we compute its corresponding feature using our trained model as shown.
The Role of Siamese Network Training in Enhancing Face Recognition Accuracy
Note that our Siamese model has been trained so that the distance between the embedding of faces from the same person is lower than the distance between the embedding of faces from different people.
Given this fact, we can simply find the distance between the test image feature  and the features in our face database (, , , ). Then, whichever feature has the minimum distance with our test feature is the identity of the test image.
and the features in our face database (, , , ). Then, whichever feature has the minimum distance with our test feature is the identity of the test image.
For example, in Figure 1, the distance ") will be least compared to
will be least compared to ") ,
, ") , and
, and ") . So we can simply identify the test face image with the
. So we can simply identify the test face image with the id of feature (i.e., id-1021).
Evaluating the Accuracy of Siamese Network-Based Face Recognition
Once all of our test images have been assigned an id using the process explained above, we can evaluate our model by comparing the predicted id and the actual id for a given face to check the correctness of our predictions.
Configuring Your Development Environment
To follow this guide, you need to have the tensorflow and sklearn libraries installed on your system.
Luckily, tensorflow and sklearn are pip-installable:
$ pip install tensorflow $ pip install scikit-learn
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in minutes.
Need Help Configuring Your Development Environment?

Need help configuring your dev environment? Want access to pre-configured Jupyter Notebooks running on Google Colab? Be sure to join PyImageSearch University — you’ll be up and running with this tutorial in minutes.
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
├── crop_faces.py ├── face_crop_model │ ├── deploy.prototxt.txt │ └── res10_300x300_ssd_iter_140000.caffemodel ├── inference.py ├── pyimagesearch │ ├── config.py │ ├── dataset.py │ └── model.py └── train.py └── evaluate.py
In the previous tutorial, we discussed in detail the train.py file, which implements the code to train our face recognition pipeline, and the inference.py file, which helped us make predictions using our Siamese network based face recognition application.
In this tutorial, we will understand the concepts behind different evaluation metrics and delve deeper into the evaluate.py file, which implements the code to evaluate our trained Siamese network based face recognition model.
Face Recognition Model Evaluation: Understanding Precision, Recall, and F1 Score
Now that we have understood the process of making predictions and evaluating our Siamese network based face recognition model, let us start building our evaluation pipeline.
The Importance of a Diverse Test Set in Model Evaluation
Note that to evaluate our model and get a sense of its performance, we need a test set that is large and diverse enough to output credible metric scores that reflect the ability of our model.
Choosing Representative Subjects for Reliable Evaluation
Most subjects in the face recognition dataset we use for this blog post have very few instances of images, which makes the test set very small and gives unreliable evaluation scores. Thus, we will split our dataset so that our test set contains subjects with multiple image instances per subject.
Specifically, we choose 5 subjects (i.e., Arnold_Schwarzenegger, Hans_Blix, Recep_Tayyip_Erdogan, Kofi_Annan, and John_Kerry) which consists of a large number of image instances per subject for our test set. We keep the rest of the subjects as our train set. Note that these subjects have been randomly chosen and can be replaced with other subjects if required.
Deep Dive into the Model Evaluation Process
Now that we have set up our trained model, face database, and test data, let us discuss the concepts behind the different evaluation metrics that we will use to evaluate the performance of our face recognition model.
Beyond Accuracy: Exploring Advanced Metrics for Model Evaluation
The most common metric to evaluate a model is accuracy, which is simply the fraction of samples whose label was correctly predicted by the model. However, accuracy is a metric computed at the dataset level and can sometimes be misleading, especially when our data is a class imbalance; some classes contain fewer samples than others, and the number of samples of different classes is not of the same scale.
For example, consider a problem where we have 100 samples where 90 belong to Class 1, and 10 belong to Class 2. Given that we have a trivial model that does not learn anything from the data and simply predicts that all samples belong to Class 1, it gets an accuracy of 90% in this setup. Note that, even though the model did not learn anything about the underlying data and simply predicted Class 1 every time, it still got a high accuracy of 90%, which is misleading.
Precision, Recall, and F1 Score: Understanding the Core Metrics
Thus, to comprehensively understand and evaluate the predictions of our model on the test set, we need metrics that can quantify the performance of our model for each class or person in the test set. As discussed, we use a test set with 5 subjects for this tutorial.
Let us consider a subject, say Arnold_Schwarzenegger, and look at how our model can be evaluated for this given class. Figure 2 shows the overview of the predictions we encounter from our trained model.
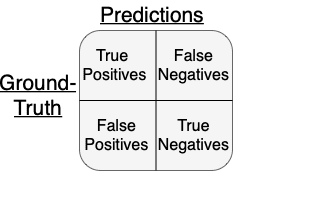
Given that we are analyzing predictions for a given subject or class (e.g., Arnold_Schwarzenegger) in our test set, we view our model outputs as binary predictions, that is, Arnold_Schwarzenegger (positive class, label=1) and not Arnold_Schwarzenegger (negative class, label !=1).
Here, True Positives refers to the samples assigned as positive by the model (i.e., label_pred =1), and their ground-truth label was also positive (label_gt=1). Similarly, True Negatives refers to the samples assigned as negative by the model (i.e., label_pred !=1), and their ground-truth label was also positive (label_gt!=1).
Furthermore, False Positives refers to the samples assigned as positive by the model (i.e., label_pred =1), and their ground-truth label was negative (label_gt!=1). Similarly, False Negatives refers to the samples assigned as negative by the model (i.e., label_pred !=1), and their ground-truth label was positive (label_gt =1).
Implementing Precision and Recall Calculations in Python
Now that we have defined and segregated our samples into True Positives, True Negatives, False Positives, and False Negatives, let us try to use them to compute specific metrics to evaluate our model.
Defining Key Evaluation Metrics: Precision and Recall
Precision can be defined as the fraction of samples where our model correctly predicted label=1 out of all samples where label = 1 was predicted.
Mathematically, this can be formulated as
Precision = TP/TP+FP
Recall can be defined as the fraction of samples where our model predicted label=0 out of all samples where the label_gt=0.
Mathematically, this can be formulated as
Recall = TP/FN+TP
Introducing the F1 Score for Balanced Model Assessment
Next, we define the F1 score, which is simply the harmonic mean of the precision and recall and gives us a holistic overview of the performance of our model by taking into account both the precision and recall abilities of the model.
F1 = 2*precision*recall / precision+recall
Importing Essential Libraries for Siamese Network Evaluation
# import the necessary packages from pyimagesearch.model import SiameseModel from matplotlib import pyplot as plt from pyimagesearch import config from sklearn.metrics import confusion_matrix from tensorflow import keras import tensorflow as tf import numpy as np import os
Detailed Explanation of Metric Calculation in Python
We start by importing the important packages on Lines 2-9, which include SiameseModel (Line 2), the matplotlib library for plotting visualizations (Line 3), the config file (Line 4), and the confusion_matrix function from the metrics module of sklearn (Line 5).
Furthermore, we also import the keras library (Line 6), tensorflow library (Line 7), numpy (Line 8), and os module (Line 9) for various deep learning or matrix or manipulation functionalities, as always.
Crafting a Custom Function for Precision, Recall, and F1 Score
### define function to compute metrics
def metrics(predictions, label_gt):
TP_binary = np.logical_and(predictions, label_gt)
FP_binary = np.logical_and(predictions, np.logical_not(label_gt))
TN_binary = np.logical_and(np.logical_not(predictions), np.logical_not(label_gt))
FN_binary = np.logical_and(np.logical_not(predictions), label_gt)
TP = sum(TP_binary )
FP = sum(FP_binary )
TN = sum(TN_binary )
FN = sum(FN_binary )
precision = TP/(TP+FP)
recall = TP/(FN+TP)
F1 = (2*precision*recall)/(precision+recall)
return precision, recall, F1
Defining the Metrics Function for Model Evaluation
We first define our metrics function (Lines 12-27), which will be used to compute the values of the metrics to evaluate our trained Siamese network model. The function inputs predictions from our trained model and the corresponding ground-truth label (i.e., label_gt).
Binary Classification Approach in Metrics Calculation
Let us understand how we will compute the metrics we defined above for a given class. Given that we are analyzing predictions for a given subject, say, subject 1 or Class 1 (as discussed above), we will create two binary arrays.
One, whose entries state whether a sample in our test set belongs to Class 1 as per the model predictions, and the other, whose entries state whether a sample in our test set actually belongs to Class 1 as per ground truth.
Note that the predictions input argument is the binary array stating whether the model predicts that a given sample in our test set belongs to the class under consideration (1 if yes, 0 if no). Similarly, the label_gt argument is a binary array stating whether the ground-truth label of a given sample in our test set belongs to the class under consideration (1 if yes, 0 if no).
Computing True Positives, Negatives, and False Metrics
Now, we are ready to compute the true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN).
We can compute the true positives by simply taking the logical AND operation of the binary predictions and label_gt as shown on Line 13 (since the output will be 1 when the model prediction and their ground-truth label are both positive).
Similarly, we can compute the false positives as (predictions) AND (NOT label_gt), the true negatives as (NOT predictions) AND (NOT label_gt), and the false negatives as (NOT predictions) AND (label_gt), as shown on Lines 14-16.
Finally, we compute the total number of TP, FP, TN, and FN by simply summing over the computed binary arrays TP_binary, FP_binary, TN_binary, and FN_binary, as shown on Lines 18-21.
Calculating Precision, Recall, and F1 Score in Practice
We are now ready to compute our precision, recall, and F1 score. As shown on Lines 23-25, we calculate these metrics using the formulas that we discussed above and return their values on Line 27.
Loading and Configuring the Siamese Model for Inference
modelPath = config.MODEL_PATH
### Loading pre-trained siamese model for inference
print(f"[INFO] loading the siamese network from {modelPath}...")
siameseNetwork = keras.models.load_model(filepath=modelPath)
siameseModel = SiameseModel(
siameseNetwork=siameseNetwork,
margin=0.5,
lossTracker=keras.metrics.Mean(name="loss"),
)
Loading the Trained Siamese Model for Evaluation
Now that we have completed the definition of our metrics function, let us load our trained Siamese model and evaluate its performance.
On Line 29, we get our modelPath, where we save our trained Siamese model after training. On Line 33, we loaded our trained Siamese model, which we had saved at the modelPath location. As we had discussed in detail in the inference section of the previous tutorial, this can be done using the load_model function of keras, as shown.
Initializing the Siamese Model for Data Analysis
Next, we create our siameseModel using the SiameseModel class as we had done during inference in the previous tutorial.
Setting Up a Data Pipeline for Effective Model Testing
faceDatabasePath = 'cropped_face_database' img_height, img_width = config.IMAGE_SIZE print(f"[INFO] Setting-up Data Pipeline...") test_ds = tf.keras.utils.image_dataset_from_directory( config.TEST_DATASET, seed=123, image_size=(img_height, img_width), batch_size=1) face_ds = tf.keras.utils.image_dataset_from_directory( faceDatabasePath, seed=123, image_size=(img_height, img_width), batch_size=1)
Creating a Robust Data Pipeline for Model Testing
Now that we have loaded our trained model, let us create our data pipeline for conducting the evaluation. On Lines 40 and 41, we define the path to our face database (i.e., faceDatabasePath) and get the image’s dimensions, respectively.
Assembling the Test Dataset for Model Accuracy Assessment
On Lines 44-48, we use the tf.keras.utils.image_dataset_from_directory function to create our test dataset. This function takes as arguments the path to the test data (i.e., config.TEST_DATASET), seed to ensure reproducibility, the image’s dimensions to output, and the batch_size as shown.
Constructing a Face Database for Comprehensive Testing
Similarly, on Lines 50-54, we use the tf.keras.utils.image_dataset_from_directory function to create a dataset for our face database entries. This function takes as arguments the path to the faceDatabasePath, used to ensure reproducibility, the image’s dimensions to output, and the batch_size as shown.
Preparing the Face Database and Test Dataset for Evaluation
faces = []
faceLabels = []
for entry in face_ds:
face, faceLabel = entry
face_image = face/255
faces.append(face_image)
faceLabels.append(faceLabel)
Preparing Face Database Entries for Accurate Model Evaluation
Now that we have created our data pipeline for evaluation, let us prepare our database entries. As discussed above, our face database contains 1 image corresponding to each of the 5 classes in our test set.
Structuring Data for Siamese Model Evaluation
We create two lists to store the faces in our database and their corresponding labels (i.e., faces and faceLabels). Next, we loop over the face or entries in our face database (Line 59), and for each entry, we first get the corresponding face and faceLabel (Line 60). We then divide our face image by 255 to normalize the pixels from 0-1. Finally, we append the face and faceLabel to the corresponding lists, as shown on Lines 62 and 63.
Implementing Predictive Analysis with the Siamese Model
print(f"[INFO] Making Predictions on Test Set...") predictions = [] labels = [] for batch in test_ds: batch_img, label = batch image = batch_img/255
Making Predictions and Evaluating the Siamese Model
Let us now make predictions with the help of our trained Siamese model.
Conducting Predictive Testing on the Dataset
We iterate over the batches in the test dataset (Line 69) and unpack the batch to get the batch_img and label, as shown on Line 70. Next, we normalize the batch_img by dividing the pixel values by 255.
Calculating Distances for Facial Recognition
pred_distances = []
We then create the preds list to store the predictions of our trained model (Line 72). Then, we iterate over the face images in our face database. For each anchor in our database, we use the siameseModel to get the distances between the embeddings, as we did during the inference stage in our previous tutorial. Let us discuss this process in detail.
Analyzing Embedding Distances for Accurate Identification
for anchor in faces:
(apDistance, anDistance) = siameseModel((image , anchor, image))
pred_distances.append(apDistance.numpy())
Note that the siameseModel takes as input 3 images and outputs the distances between the embeddings of the first and second images (i.e., apDistance) and the first and the third images (i.e., anDistance). Here, the apDistance (Line 75) is the distance between the embeddings of our test image and the face in our face database (i.e., anchor). Note that the anDistance will be 0 here as it is simply the distance between the embeddings of the same image.
We convert the apDistance to numpy and append it to our pred_distances list (Line 76). Note that this implies that the pred_distances list will contain the distance between the embeddings of the image in our test set and the embeddings of the 5 anchors in our face database.
Analyzing Distance-Based Predictions in Siamese Networks
predictions.append(faceLabels[np.argmin(pred_distances)][0]) labels.append(label.numpy()[0])
Now that we have the distances of our test image from the embeddings of the 5 anchors in our face database, we get the label corresponding to the anchors, which has the minimum distance, and append it to the predictions list (Line 77). We also append the ground-truth label of the image in our test_Set to the labels list (Line 78).
Preparing Data for Accuracy and Class-Wise Metric Evaluation
labels = np.asarray(labels) predictions = np.asarray(predictions) print(f"[INFO] Evaluating the model...") ##Computing Metrics N = labels.shape[0] accuracy = (labels == predictions).sum() / N
Finally, we convert our labels and predictions lists to numpy arrays to prepare them for computing the metrics (Lines 81 and 82).
On Line 87, we get the total number of samples in our test set (i.e., N) and compute the accuracy, as shown on Line 88.
Calculating Class-Specific Metrics for In-Depth Analysis
for pos_label in [0,1,2,3,4]:
pred = (predictions == pos_label)
label_gt = (labels == pos_label)
precision, recall, F1_score = metrics(pred,label)
Furthermore, to compute the class-wise metrics as we had discussed above in this tutorial, we iterate through all unique class labels in our test set (Line 90) and compute the binary pred and label_gt arrays for each class and pass them to our metrics function that we defined above (Lines 91 and 92).
This function outputs each class’s corresponding precision, recall, and F1_score (Line 94).
With this, we complete computing the metrics for each class in our test set.
Leveraging Confusion Matrix for Holistic Performance Insight
Now that we have discussed in detail the concept behind precision and recall and understood how to compute them for each class in the face recognition problem, let us look at another concept that makes it easier to get a sense of the performance of our model and allows us to directly compute precision and recall for all classes at once making the process more efficient.
Using Confusion Matrix for Comprehensive Model Evaluation
The confusion matrix allows us to summarize the predictions of our recognition model and makes it easier to evaluate the holistic and class-wise performance of our trained system. Specifically, the confusion matrix simply conveys how our trained model classified the samples of a given ground-truth class.
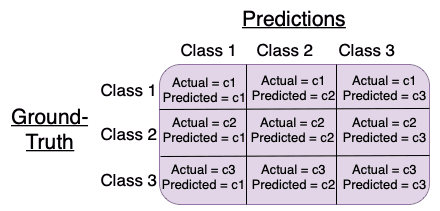
Figure 3 shows an example of a typical confusion matrix for three classes and depicts how the different rows and columns of the matrix are filled. Each entry  in the
in the  th row and
th row and  th column of the confusion matrix denotes the number of samples with the ground-truth label as th class and predicted label as th class as shown in the figure.
th column of the confusion matrix denotes the number of samples with the ground-truth label as th class and predicted label as th class as shown in the figure.
Implementing Confusion Matrix in Python for Siamese Model
Let’s go ahead and compute the confusion matrix for our trained Siamese model to understand this better.
Direct Calculation of Recall and Precision from Confusion Matrix
cm = confusion_matrix(labels, predictions) recall = np.diag(cm) / np.sum(cm, axis = 1) precision = np.diag(cm) / np.sum(cm, axis = 0)
Note that the confusion matrix can be simply computed using the confusion_matrix function from sklearn (Line 96). Now that we have the confusion matrix, we can easily directly compute the recall and precision for all classes together (Lines 97 and 98).
Notice that the precision and recall computed from the confusion matrix match the ones we computed before using the mathematical formula.
Deriving Overall Precision, Recall, and F1 Score
recallOverall = np.mean(recall) precisionOverall = np.mean(precision) F1_overall = 2*recallOverall*precisionOverall/(recallOverall+precisionOverall)
Finally, to get the overall precision and recall, we simply average the precision and recall values over all classes (Lines 100 and 101).
We can also compute the overall F1 score by taking the harmonic mean of our computed values (Line 102).
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary and Conclusion
In this tutorial, we discussed how to evaluate our trained Siamese network based face recognition model using Keras and TensorFlow.
Specifically, we tried to understand how we could evaluate a face verification pipeline during the inference stage and delved deeper into the concepts behind different dataset level and class level metrics which can be used to evaluate the performance of our trained model.
Furthermore, we discussed and implemented the code to build our evaluation pipeline and discussed the confusion matrix, which allows us to get a holistic sense of the predictions of the model and its performance.
Citation Information
Chandhok, S. “Evaluating Siamese Network Accuracy (F1 Score, Precision, and Recall) with Keras and TensorFlow,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/dq1w5
@incollection{Chandhok_2024_Evaluating_Siamese,
author = {Shivam Chandhok},
title = {Evaluating Siamese Network Accuracy (F1 Score, Precision, and Recall) with Keras and TensorFlow},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/dq1w5},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.