
This post covers the intuition of Generative Adversarial Networks (GANs) at a high level, the various GAN variants, and applications for solving real-world problems.

This is the first post of a GAN tutorial series:
- Intro to Generative Adversarial Networks (GANs) (this post)
- Get Started: DCGAN for Fashion-MNIST
- GAN Training Challenges: DCGAN for Color Images
How GANs work
GANs are a type of generative models, which observe many sample distributions and generate more samples of the same distribution. Other generative models include variational autoencoders (VAE) and Autoregressive models.
The GAN architecture
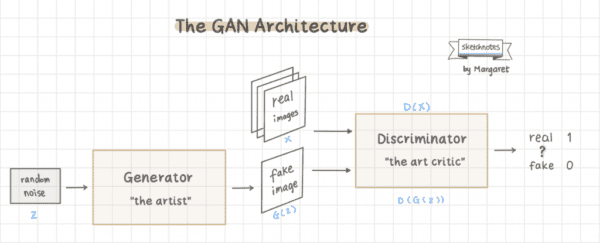
There are two networks in a basic GAN architecture: the generator model and the discriminator model. GANs get the word “adversarial” in its name because the two networks are trained simultaneously and competing against each other, like in a zero-sum game such as chess.

The generator model generates new images. The goal of the generator is to generate images that look so real that it fools the discriminator. In the simplest GAN architecture for image synthesis, the input is typically random noise, and its output is a generated image.
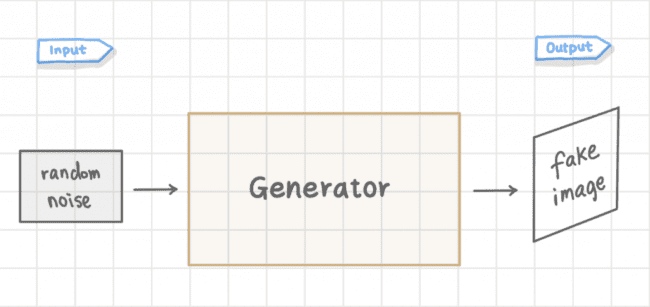
The discriminator is just a binary image classifier which you should already be familiar with. Its job is to classify whether an image is real or fake.
Note: In more complex GANs, we could condition the Discriminator with image or text for Image-to-Image translation or Text-to-Image generation).
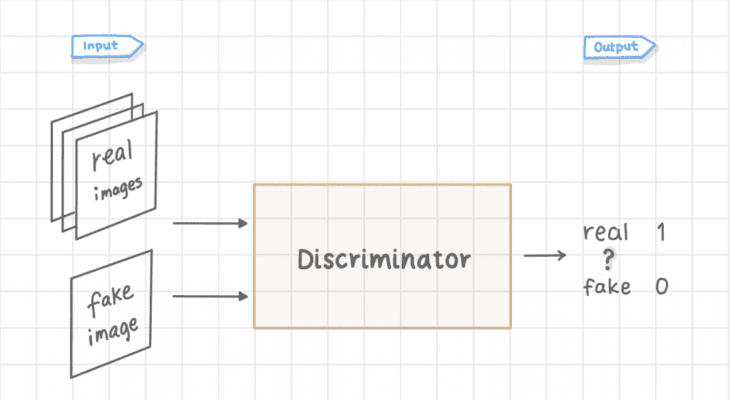
Putting it all together, here is what a basic GAN architecture looks like: the generator makes fake images; we feed both the real images (training dataset) and the fake images into the discriminator in separate batches. The discriminator then tells whether an image is real or fake.
Training GANs
The Minimax game: G vs. D
Most deep learning models (for example, image classification) are based on optimization: finding the low value of the cost function. GANs are different because the two networks: the generator and discriminator, each has its own cost with opposite objectives:
- The generator tries to fool the discriminator into thinking the fake images as real
- The discriminator tries to classify real and fake images correctly
The minimax game math function below illustrates this adversarial dynamic during training. Don’t worry too much if you don’t understand the math, which I will explain in more detail when coding the G loss and D loss in a future DCGAN post.

Both the generator and discriminator improve over time during training. The generator gets better and better at producing images that resemble the training data, while the discriminator gets better at telling the real and fake images apart.
Training GANs is to find an equilibrium in the game when:
- The generator makes data that looks almost identical to the training data.
- The discriminator can no longer tell the difference between the fake images from the real images.
The artist vs. the critic
Mimicking masterpieces is a great way to learn art — “How Artists Are Copying Masterpieces at World-Renowned Museums.” As a human artist mimicking a masterpiece, I’d find the artwork I like as an inspiration and try to copy it as much as possible: the contours, the colors, the compositions and the brushstrokes, and so on. Then a critic takes a look at the copy and tells me whether it looks like the real masterpiece.

GANs training is similar to that process. We can think of the generator as the artist and the discriminator as the critic. Note the difference in this analogy between the human artist and the machine (GANs) artist, though: the generator doesn’t have access or visibility to the masterpiece that it’s trying to copy. Instead, it only relies on the discriminator’s feedback to improve the images it’s generating.
Evaluation metrics
A good GAN model should have good image quality — for example, not blurry and resembles the training image; and diversity: a good variety of images get generated that approximate the distribution of the training dataset.
To evaluate the GAN model, you can visually inspect the generated images during training or by inference with the generator model. If you’d like to evaluate your GANs quantitatively, here are two popular evaluation metrics:
- Inception Score, which captures both the quality and diversity of the generated images
- Fréchet Inception Distance which compares the real vs. fake images and doesn’t just evaluate the generated images in isolation
GAN variants
Since Ian Goodfellow et al.’s original GANs paper in 2014, there have been many GAN variants. They tend to build upon each other, either to solve a particular training issue or to create new GANs architectures for finer control of the GANs or better images.
Here are a few of these variants with breakthroughs that provided the foundation for future GAN advances. This is by all means not a complete list of all the GAN variants.
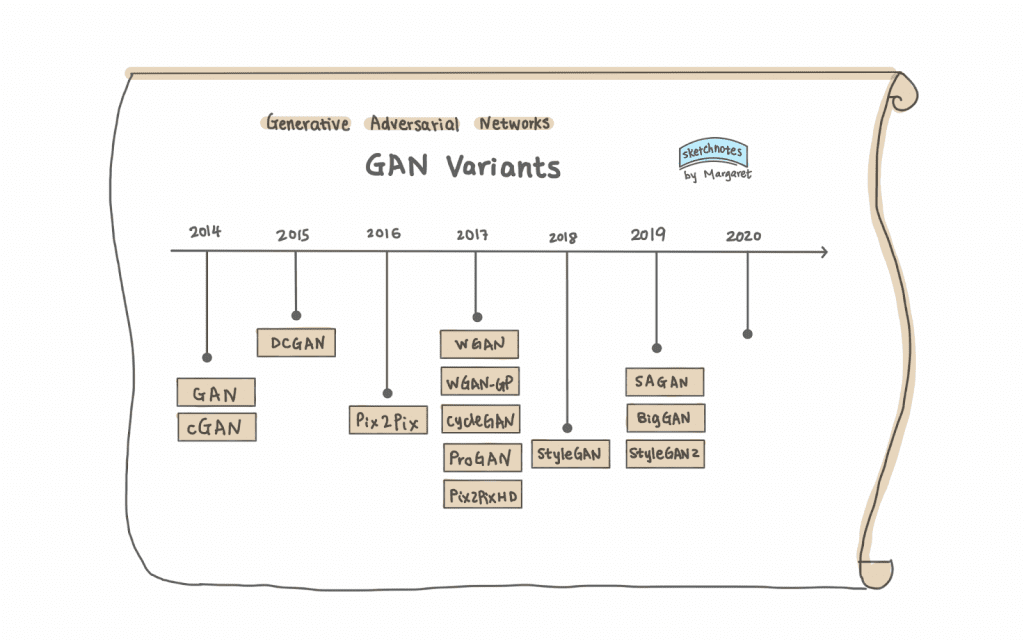
DCGAN (Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks) was the first GAN proposal using Convolutional Neural Network (CNN) in its network architecture. Most of the GAN variations today are somewhat based on DCGAN. Thus, DCGAN is most likely your first GAN tutorial, the “Hello-World” of learning GANs.
WGAN (Wasserstein GAN) and WGAN-GP (were created to solve GAN training challenges such as mode collapse — when the generator produces the same images or a small subset (of the training images) repeatedly. WGAN-GP improves upon WGAN by using gradient penalty instead of weight clipping for training stability.
cGAN (Conditional Generative Adversarial Nets) first introduced the concept of generating images based on a condition, which could be an image class label, image, or text, as in more complex GANs. Pix2Pix and CycleGAN are both conditional GANs, using images as conditions for image-to-image translation.
Pix2PixHD (High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs) disentangles the effects of multiple input conditions and, as in the paper example: control color, texture, and shape of a generated garment image for fashion design. In addition, it can generate realistic 2k high-resolution images.
SAGAN (Self-Attention Generative Adversarial Networks) improves image synthesis quality: generating details using cues from all feature locations by applying the self-attention module (a concept from the NLP models) to CNNs. Google DeepMind scaled up SAGAN to make BigGAN.
BigGAN (Large Scale GAN Training for High Fidelity Natural Image Synthesis) can create high-resolution and high-fidelity images.
ProGAN, StyleGAN, and StyleGAN2 all create high-resolution images.
ProGAN (Progressive Growing of GANs for Improved Quality, Stability, and Variation) grows the network progressively.
StyleGAN (A Style-Based Generator Architecture for Generative Adversarial Networks), introduced by NVIDIA Research, uses the progress growing ProGAN plus image style transfer with adaptive instance normalization (AdaIN) and was able to have control over the style of generated images.
StyleGAN2 (Analyzing and Improving the Image Quality of StyleGAN) improves upon the original StyleGAN by making several improvements in areas such as normalization, progressively growing and regularization techniques, etc.
GAN applications
GANs are versatile and can be used in a variety of applications.
Image synthesis
Image synthesis can be fun and provide practical use, such as image augmentation in machine learning (ML) training or help with creating artwork and design assets.
GANs can be used to create images that never existed before, which is perhaps what GANs are best known for. They can create unseen new faces, cat images and artwork, and more. I’ve included a few high-fidelity images below, which I generated from the websites powered by StyleGAN2. Go to these links, experiment yourself, and see what images you get from your experiments.

Zalando Research uses GANs to generate fashion designs based on color, shape, and texture (Disentangling Multiple Conditional Inputs in GANs).
Fashion++ by Facebook Research goes beyond generating fashion into recommending fashion change recommendations: “what is fashionable?”

GANs can also help train reinforcement agents. For example, NVIDIA’s GameGAN simulates the game environments.
Image-to-image translation
Image-to-image translation is a computer vision task that translates the input image to another domain (e.g., color or style) while preserving the original image content. This is perhaps one of the most important tasks to use GANs in art and design.
Pix2Pix (Image-to-Image Translation with Conditional Adversarial Networks) is a conditional GAN that was perhaps the most famous image-to-image translation GAN. However, one major drawback of Pix2Pix is that it requires paired training image datasets.

CycleGAN was built upon Pix2Pix and only needs unpaired images, much easier to come by in the real world. It can convert images of apples to oranges, day to night, horses to zebras … ok. These may not be real-world use cases to start with; there are so many other image-to-image GANs developed since then for art and design.

Now you can translate your selfie to comics, painting, cartoons, or any other styles you can imagine. For example, I can use White-box CartoonGAN to turn my selfie into a cartoonized version:

Colorization can be applied to not only black and white photos but also artwork or design assets. In the artwork making or UI/UX design process, we start with outlines or contours and then coloring. Automatic colorization could help provide inspiration for artists and designers.
Text-to-Image
We’ve seen a lot of Image-to-Image translation examples by GANs. We could also use words as the condition to generate images, which is much more flexible and intuitive than using class labels as the condition.
Combining NLP and computer vision has become a popular research area in recent years. Here are a few examples: StyleCLIP and Taming Transformers for High-Resolution Image Synthesis.

Beyond images
GANs can be used for not only images but also music and video. For example, GANSynth from the Magenta project can make music. Here is a fun example of GANs on video motion transfer called “Everybody Dance Now” (YouTube | Paper). I’ve always loved watching this charming video where the dance moves by professional dancers get transferred to the amateurs.
Other GAN applications
Here are a few other GAN applications:
- Image inpainting: replace the missing portion of the image.
- Image uncropping or extension: this could be useful in simulating camera parameters in virtual reality.
- Super-resolution (SRGAN & ESRGAN): enhance an image from lower-resolution to high resolution. This could be very helpful in photo editing or medical image enhancements.
Here is an example of how GANs can be used for climate change. Earth Intelligent Engine, an FDL (Frontier Development Lab) 2020 project, uses Pix2PixHD to simulate what an area would look like after flooding.
We have seen GAN demos from papers, research labs. and open source projects. These days we are starting to see real commercial applications using GANs. Designers are familiar with using design assets from icons8. Take a look at their website, and you will notice the GAN applications: from the Smart Upscaler, Generated Photos to Face Generator.
Summary
In this post, you learned a high-level overview of GANs, their variants, and fun applications. While most of the examples in this post are about using GANs for art and design, the same techniques can be easily adapted and applied to many other fields: medicine, agriculture, and climate change. As you see in the post, GANs are powerful and versatile. I hope you are excited to dive deeper into GANs: follow along with the upcoming posts as we explore GANs in depth with code examples!

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.