Table of Contents
Tools and Methodologies for Studying Causal Effects
This lesson is the 3rd in a 5-part series on Causality in Machine Learning:
- Introduction to Causality in Machine Learning
- Best Machine Learning Datasets
- Tools and Methodologies for Studying Causal Effects (this tutorial)
- A Brief Introduction to Do-Calculus
- Studying Causal Effect with Microsoft’s Do-Why Library
To learn the tools for studying causality in your data, just keep reading.
Tools and Methodologies for Studying Causal Effects
Welcome back to Part 3 of the 5-part series on Causality in Machine Learning. The previous one was all about introducing Causality in the briefest way possible. You can find it right here.
Picking up where we left off, let us revise what we learned in Part 1.
- Ignoring hidden causes in data can mean death for your model
- Counterfactual thinking is a must
- Randomization, Natural Experiments, and Conditioning are the tools of the trade
Right. Now that we have sorted that, let us start with those three vague terms. Randomization, natural experiments, and conditioning, what are they? How do we use them with our data, and why do we need to care?
Well, let us start scratching the list one item at a time.
Randomization
So, what do we mean when we talk about Randomization in the context of Causality? Well, at the core of it, causal knowledge prefers the intervention it demands. What do I mean by that?
In very simple terms, if you say  causes
causes  , you must be able to show to some degree that in the absence of and all other parameters staying constant, will not occur.
, you must be able to show to some degree that in the absence of and all other parameters staying constant, will not occur.
Now, that is a fairly straightforward statement, but the implications go deeper. Suppose you want to prove that ads by ads on Netflix will cause users to delete accounts. That’s a decent assumption, and you start trying to prove it. You remove the cause (Netflix ads) and try to study the user’s behavior, but here’s the catch: you are not exactly studying user behavior. The other parameters are not kept constant. You are not looking at a parallel world where a doppelganger of the user is not shown an ad when they open Netflix.
This is exactly what randomization tries to solve. It tells us that in the context of our experiment (ads on Netflix), if we create a set of users and then randomly assign a user to a group (one group gets shown ads and the other group doesn’t), then we are essentially keeping the “other parameters” constant, as shown in Figure 1.

Two ways we can achieve randomization are:
- A/B testing
- Multi-armed bandits
A/B Test
This is exactly what we were talking about a second back. Create two groups of subjects (A & B group) and treat them differently (ads vs. no ads) and see which one of the groups meets the target (cancellation of subscription). So, in summary, the steps to be followed are:
- Create two groups of subjects
- Expose each of the groups to two different experiments
- Find out which meets the target
The Causal Estimate (CE) for this methodology is the difference in outcome due to option 1 and option 2.

➤ Check out how Netflix actually uses A/B testing in this video.
Multi-Armed Bandits
The second and a little less famous of the randomization strategy is multi-armed bandits. This methodology derives its name from the arms of slot machines. Historically, the infamous problem goes as such:
Given multiple slot machines, a gambler has to decide which arms to pull and how many times in order to maximize profit. Needless to say, countless have been slain by this problem, purely to quench their mathematical curiosity.
This method relies on a very interesting strategy known as Exploit and Explore. Exploit as in figure out the best option and keep repeating it to maximize the target outcome, and Explore as in explore all possible options in the given context of the problem.
One example would be if you had to figure out which Baskin-Robbins ice cream would give you the maximum satisfaction (target outcome), as shown in Figure 2. The steps listed below are some ways to carry out Exploration and Exploitation while maximizing satisfaction.

- Explore only. This means every day, you go to Baskin-Robbins and select a new flavor, try it out, and see if it gives you maximum satisfaction.
- Exploit only. On the first 10 days, you visit Baskin-Robbins and try 10 different flavors. From the 11th day, you keep buying that one flavor that gave you maximum satisfaction from those 10 previously tested ones.
- Epsilon — greedy.
- Strike a balance between exploring an exploit.
- Set an initial epsilon (indicator)
- Based on the value of epsilon (randomly picked), we will either explore or exploit.
- If we exploit, then we pick the best ice cream from already gathered data; if we explore, then we randomly pick an ice cream from the counter.
 = target outcome is the best possible,
= target outcome is the best possible,  = current target outcome and
= current target outcome and  = Causal Estimate
= Causal Estimate

- Use multi-armed bandits only, and only if you have a good number of options to test.
➤ The verdict?
➤ Use Randomization even if it means staying up a couple of nights and designing an experiment in which you must create a parallel universe. In all seriousness, the two methods shown above actually give us a good structure through which we can shape randomized experiments that give us a sense of causal direction.
Natural Experiments
Yep, randomization is hard, and if there is no way for you to intervene, then that ship has sailed. Let’s have a look at what the next best option is. Natural Experiments are a way to test causality by shaping naturally occurring phenomena as an experiment. It’s kind of like cheating, but in a scientific way.
The two most prevalent ways to do this are as follows:
- Regression Discontinuity
- Instrumental Variables
Regression Discontinuity
Let us imagine that we are the top-secret evil society that controls the funding for academic labs. We want to check if granting more funds will cause an increase in lab performance. However, there is a catch: funding is also dependent on the number of papers published (i.e., the number of papers published will have to be above a certain threshold (theta) for the lab to qualify for funding), as shown in Figure 3.

+e")
Use the linear regression model to estimate the outcome, however, and this may be counterintuitive if there is a discontinuous jump at the point where  or when your threshold is reached. The measure of this discontinuity is your Causal Estimate. If there is a small jump, funding probably does not play a big role in lab performance, and we can continue to be greedy evil super-villains. If the jump is huge enough, then we have problems and might have to release some of our super-villain money as research grants.
or when your threshold is reached. The measure of this discontinuity is your Causal Estimate. If there is a small jump, funding probably does not play a big role in lab performance, and we can continue to be greedy evil super-villains. If the jump is huge enough, then we have problems and might have to release some of our super-villain money as research grants.
Instrumental Variable
Before diving deep into this particular, let us revise some of the previous concepts we glided past.
Outcome Variable: This is a notation (almost always  ) used to denote the final outcome of our causal experiments.
) used to denote the final outcome of our causal experiments.
Treatment Variable: This is another useful notation (almost always  ) used to denote the treatment in our causal experiments. In the context of the Netflix ads, problem = showing ads on Netflix, or = not showing ads on Netflix.
) used to denote the treatment in our causal experiments. In the context of the Netflix ads, problem = showing ads on Netflix, or = not showing ads on Netflix.
Instrumental Variable: This is used to denote the variable that affects our outcome through our treatment variable. This variable does not have the scope to affect the outcome directly but influences the treatment variable, thereby indirectly affecting the outcome.
Confused? Let’s take a look at an example:
Imagine we have now joined a publishing company as a data scientist. A strange rumor is abuzz in the marketing department. It is believed that more Twitter mentions ( ) will always cause more book sales (
) will always cause more book sales ( ). As data scientists, only we can debunk or solidify this rumor. Let’s look at the causal graphs in Figures 4 and 5.
). As data scientists, only we can debunk or solidify this rumor. Let’s look at the causal graphs in Figures 4 and 5.


Consider the following:
Let us try to model the two causal graphs shown above using simple regression equations. A list of notations is given below:
 = Original figure for book sales.
= Original figure for book sales. = Original number of twitter mentions.
= Original number of twitter mentions. = Generated number of twitter mentions from regression equations.
= Generated number of twitter mentions from regression equations. = Generated number of book sales from regression equations.
= Generated number of book sales from regression equations. = Causal Estimate from the experiment
= Causal Estimate from the experiment- The terms
 ,
,  , , , , and
, , , , and  are regression coefficients and error terms.
are regression coefficients and error terms.
 = Original figure for book sales.
= Original figure for book sales. = Generated number of twitter mentions from regression equations.
= Generated number of twitter mentions from regression equations. ,
,  ,
,  ,
,  , and
, and Now, let us see what a regression equation for the first figure will look like.
 + e")
Now, as the author tweeting will be our instrumental variable, let us frame a different regression equation.
+e")
 ,
,  , and
, and  is used through a method of least squares to generate
is used through a method of least squares to generate  . This is different from as this has been generated specifically using the variable of the author tweeting excerpts. This will now be used in another regression equation to generate the new figure for book sales.
. This is different from as this has been generated specifically using the variable of the author tweeting excerpts. This will now be used in another regression equation to generate the new figure for book sales.
 + e")

➤ The verdict?
➤ If you have a scenario like the ones we presented and there are naturally occurring experiments like academic grants for labs above a certain threshold and authors tweeting excerpts from their books, do go for methodologies that leverage these occurrences. This will always give us a better edge and, in the end, present a better-rounded picture of cause and effect.
Observational Data
Now comes the hard part. You can’t intervene and create randomized experiments. You can’t find occurrences in your data that qualify as natural experiments. All you are left with is cold hard, observational data from 2 years back. This is the most explored and most complex part of causal analysis.
TLDR;
You are doomed.
Largely speaking, to estimate causality from observational data only, there are 3 major steps.
- Assume a graphical model
- Make stratifications (different groups)
- Compare the treatment across stratifications
How do we do this? Again, we have 2 strategies that are quite fail-proof and widely used.
- Many of these methods are more theoretical, which means you’ll probably have to spend more time with a notebook figuring out all the variables before jumping into code/math.
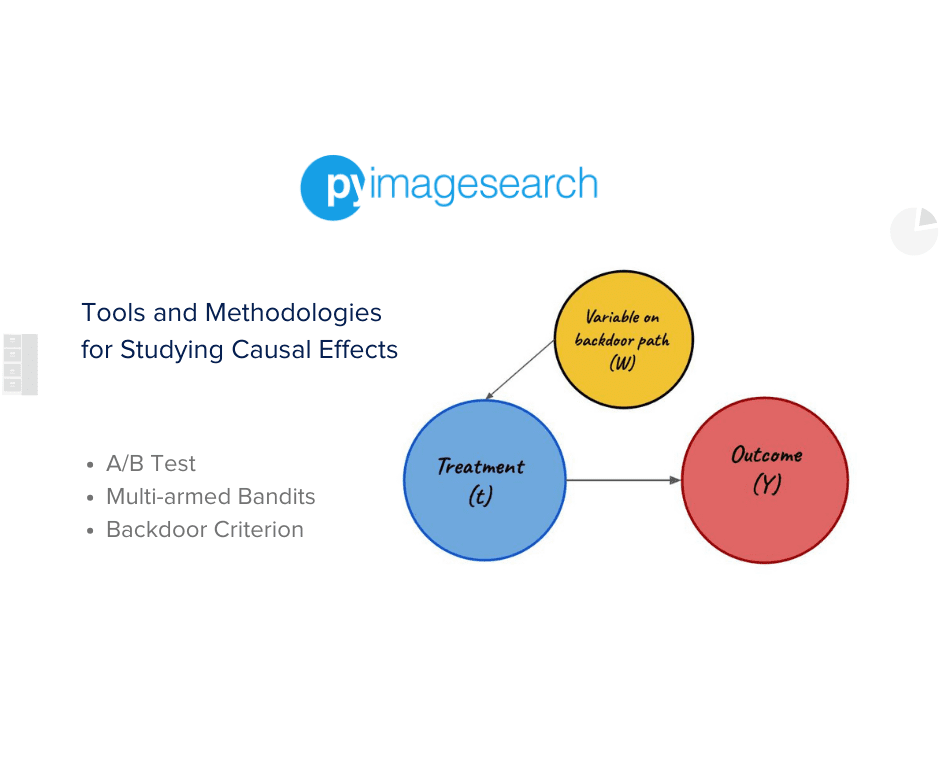
Backdoor Criterion
Block all the backdoor paths, that is, block all the non-causal associations and study the final outcome based on the treatment. So, what is a backdoor criterion again?
A set of variables  satisfies the backdoor criteria if the following are true:
satisfies the backdoor criteria if the following are true:
 blocks all the backdoor paths from treatment (
blocks all the backdoor paths from treatment ( ) to outcome (
) to outcome ( )
)- does not contain any descendants of treatment ().
Wait, so what is a backdoor?
Well, there is a lot of mathematical jargon available to define it, but the general thumb-rule is
- Arrows pointing away from treatment () are frontdoors.
- Arrows pointing toward treatment () are backdoors.
We illustrate these using the following two diagrams in Figures 6 and 7.


Now, if we simply hold or any other variable like , which is on a backdoor path as constant, we will effectively close that backdoor path. Allowing us to measure the effect of treatment () on the outcome ().
Propensity Score Matching
This is another strategy that proves really useful when finding out causal effects from observational data. The steps to perform Propensity Score Matching are a bit complicated, but let’s break them down into chunks. We will also use an example to understand the strategy better.
Let us suppose we are a multi-national bank, and we are trying to find out if winning a lottery causes people to invest more in stocks, illustrated in the following causal graph in Figure 8.

- First, we find the propensity score, that is, the probability or likelihood that the individual receives a certain treatment. In the above example, this will be the probability that a certain individual wins the lottery.
- Match the individuals that have matching propensity scores. If we have a matching probability score of two individuals, then we match them together. Nearest neighbor matching and greedy optimal matching are some of the techniques.
- Verify the quality of matches. So, if two individuals having a similar chance of winning a lottery are matched, we verify the matching using statistical methods. These methods are -tests and standardized bias and can also be done using graphical representations.
- Outcome Analysis. Check how many of those matches (groups) won the lottery. In this step, we try to find the mean outcome across matches and study the trend. This gives us an estimate of the causal effect over a number of groups.
➤ The verdict?
➤ This is the toughest of the lot. Remember, causal connections are heavily dependent on counterfactual thinking, but shaping existing data and conditioning on particular parameters and variables to prove a hypothesis can be a tiresome and sometimes thankless job.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
We realized this was quite bigger than promised. We wanted to provide a sense of the various methodologies and examples in one place so that it can be used as a reference in times of need. From the next blog onwards, we will focus on each of these segments and try to look at some examples and notebooks (Python codes) to understand causality. If you have any constructive feedback, do let us know in the comments.
References
Citation Information
A. R. Gosthipaty and R. Raha. “Tools and Methodologies for Studying Causal Effects,” PyImageSearch, P. Chugh, S. Huot, and K. Kidriavsteva, eds., 2023, https://pyimg.co/3sa8x
@incollection{ARG-RR_2023_Causality_Tools_Methodologies,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Tools and Methodologies for Studying Causal Effects},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva},
year = {2023},
url = {https://pyimg.co/3sa8x},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.