Table of Contents
Faster R-CNNs
Deep learning has impacted almost every facet of computer vision that relies on machine learning in a meaningful way. For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neural networks and deep learning. Object detection is no different.
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. (2013). Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g., Haar cascades (Viola and Jones, 2001); HOG + Linear SVM (Dalal and Triggs, 2005)) at every step of the way.
In this lesson, we’ll discuss the Faster R-CNN algorithm and its components, including anchors, the base network, the Region Proposal Network (RPN), and Region of Interest (ROI) pooling. This discussion of Faster R-CNN building blocks will help you understand the core algorithm, how it works, and how end-to-end deep learning object detection is possible.
In the following lesson, we’ll review the TensorFlow Object Detection API, including how to install it, how it works, and how to use the API to train your own Faster R-CNN object detectors on custom datasets.
The current two lessons on Faster R-CNNs, along with the upcoming two lessons on Single Shot Detectors (SSDs), will focus on object detection from a self-driving cars standpoint, demonstrating how to train object detectors to localize street signs and vehicles in images and video streams. You’ll be able to use these discussions and code examples as a starting point for your own projects.
This lesson is the first of a 2-part series on Faster R-CNNs:
- Faster R-CNNs (today’s tutorial)
- Training a Faster R-CNN
To learn about Faster R-CNNs, just keep reading.
Object Detection and Deep Learning
Object detection, regardless of whether performed via deep learning or other computer vision techniques, has three primary goals — given an input image we wish to obtain:
- A list of bounding boxes, or the (x, y)-coordinates for each object in an image
- A class label associated with each bounding box
- The probability/confidence score associated with each bounding box and class label
In previous posts, we reviewed the traditional object detection pipeline, including:
- Sliding windows to localize objects at different locations
- Image pyramids used to detect objects at varying scales
- Classification via a pre-trained CNN
In this manner, we could frame object detection as classification by utilizing sliding windows and image pyramids. The problems with this approach are numerous, but the primary ones include the following:
- Slow and Tedious: Running a sliding window at every location at every layer of an image pyramid is a time-consuming process.
- Lack of Aspect Ratio: Since our CNN requires a fixed-size input, we cannot encode the aspect ratio of a potential object into the ROI extracted and fed into the CNN. This leads to less accurate localizations.
- Error-Prone: Balancing speed (larger sliding window steps and fewer image pyramid layers) with hopefully higher accuracy (more sliding window steps and more pyramid layers) is incredibly challenging. This issue is further compounded by a lack of object aspect ratio in the ROI.
What we need is an end-to-end deep learning-based object detector where we input an image to the network and obtain the bounding boxes and class labels for output. As we’ll see, building an end-to-end object detector is not an easy task.
Measuring Object Detector Performance
When evaluating object detector performance, we use a combination of two evaluation metrics: Intersection over Union (IoU) and mean Average Precision (mAP). You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors (Dalal and Triggs, 2005), Convolutional Neural Network methods, such as Faster R-CNN (Girshick et al., 2015), SSD (Fei-Fei et al., 2004), You Only Look Once (YOLO) (Redmon et al., 2015; Redmon and Farhad, 2016), and others. However, keep in mind that the actual algorithm used to generate the predicted bounding boxes does not matter. In this section, we will start with a discussion of IoU and then move to mAP.
Any algorithm that provides predicted bounding boxes (and optionally class labels) as output can be evaluated using IoU. More formally, to apply IoU to evaluate an arbitrary object detector, we need the following:
- The ground-truth bounding boxes (i.e., the hand-labeled bounding boxes from our testing set that specify where in an image our object is).
- The predicted bounding boxes from our model.
- To compute recall and precision, you’ll also need the ground-truth and predicted class labels.
As long as we have these two sets of bounding boxes, we can apply IoU.
In Figure 1 (left), we have included a visual example of a ground-truth bounding box (green) versus a predicted bounding box (red). Computing IoU can, therefore, be determined by the equation illustration in Figure 1 (right).
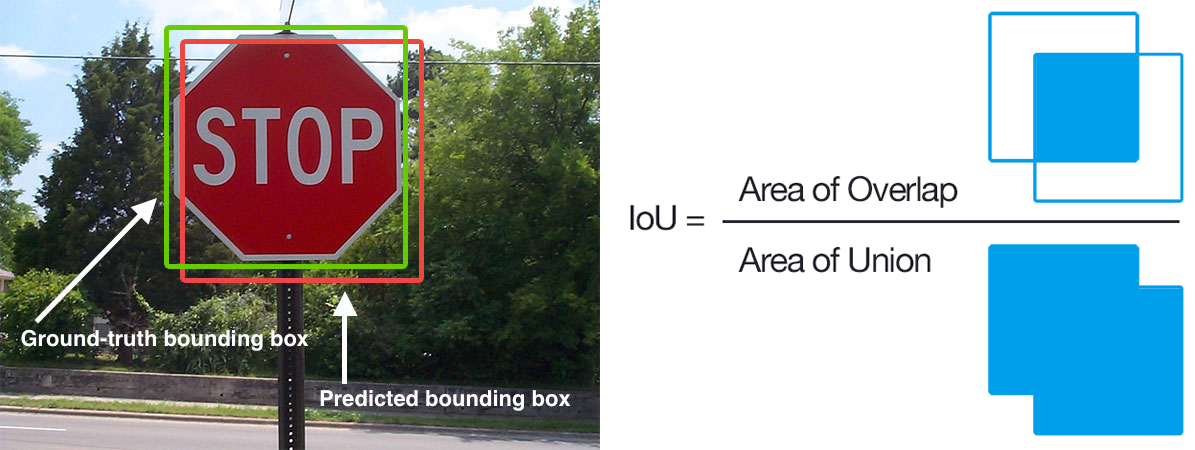
Examining this equation, you can see that IoU is simply a ratio. In the numerator, we compute the area of overlap between the predicted bounding box and the ground-truth bounding box. The denominator is the area of union, or more simply, the area encompassed by both the predicted bounding box and the ground-truth bounding box. Dividing the area of overlap by the area of union yields a final score: the Intersection over Union.
From Where Do the Ground-Truth Examples Come?
Before we get too far, you might wonder where the ground-truth examples come from. We’ve mentioned earlier in this tutorial that our dataset must be “hand labeled,” but what exactly does that mean?
When training your own object detector, you need a dataset. This dataset should be broken into (at least) two groups:
- A training set used for training your object detector
- A testing set for evaluating your object detector
You may also have a validation set used to tune the hyperparameters of your model. Both the training and testing set will consist of the following:
- The actual images themselves
- The bounding boxes associated with the object(s) in the image are simply the (x, y)-coordinates of the object in the image
The bounding boxes for the training and testing sets are hand labeled, hence why we call them the “ground truth.” Your goal is to take the training images + bounding boxes, construct an object detector, and then evaluate its performance on the testing set. An IoU score > 0.5 is normally considered a “good” prediction.
Why Do We Use Intersection over Union (IoU)?
It’s extremely unlikely that the (x, y)-coordinates of our predicted bounding box will exactly match the (x, y)-coordinates of the ground-truth bounding box. Due to varying parameters of our model, such as the layer used for feature extraction, anchor placement, loss function, etc., a complete and total match between predicted and ground-truth bounding boxes is simply unrealistic.
Because coordinates will not match exactly, we need to define an evaluation metric that rewards predicted bounding boxes for heavily overlapping with the ground truth, as Figure 2 demonstrates.

In this illustration, we have included three examples of good and bar IoU scores. Predicted bounding boxes that heavily overlap with the ground-truth bounding boxes have higher scores than those with less overlap. This behavior makes IoU an excellent metric for evaluating custom object detectors.
Again, we aren’t concerned with an exact match of (x, y)-coordinates, but we do want to ensure that our predicted bounding boxes match as closely as possible. IoU can take this fact into account.
Implementing IoU by hand is outside the context of this series, although it is a fairly straightforward process. If you’re interested in learning more about IoU, including a walkthrough of Python code demonstrating how to implement it, please see our earlier blog post.
Mean Average Precision (mAP)
Readers and practitioners new to object detection can be confused by the mAP calculation. This is partially because:
- mAP is a more complicated evaluation metric than traditional accuracy.
- The definition to calculate mAP can even vary from one object detection challenge to another (when we say “object detection challenge,” we are referring to competitions such as COCO, PASCAL VOC, etc.).
Computing the Average Precision (AP) for a particular object detection pipeline is essentially a 3-step process:
- Compute the precision, which is the number of correctly predicted objects
- Compute the recall, which measures how good of a job we did find all the objects
- Average together the maximum precision value across all recall levels in steps of size s
Let’s go ahead and formalize this process a bit by defining the following:
- TP = True positive (correctly predicting an object)
- TN = True negative (correctly predicting the absence of an object)
- FP = False positive (falsely reporting an object when there is none)
- FN = False negative (failing to report the location of an object entirely)
From there, we can define both our precision and recall using the variables above:
(1) 
(2) 
The precision allows us to measure how good of a job we did predicting the location and label of an object. Recall, however, measures how good of a job we did finding and locating all objects.
Now that we have formalized the process, let’s work out an example. To compute the precision, we first apply our object detection algorithm to an input image. The bounding box scores are then sorted in descending order by their confidence (i.e., probability).
We know from a priori knowledge (i.e., it’s a validation/testing example, and we, therefore, know the total number of objects in the image) that there are four objects in this pretend image. We seek to determine how many “correct” detections our network made. A “correct” prediction here is one where we have a minimum IoU of 0.5 (this value is tunable depending on the challenge, but 0.5 is a standard value), implying that the predicted bounding box has an overlap of 0.5 with the ground-truth bounding box.
Here is where the calculation becomes more complicated. We need to compute the precision at different recall values (also called “recall levels” or “recall steps”).
For example, let’s pretend we are computing the precision and recall values for the top-3 predictions. Out of the top-3 predictions from our deep learning object detector, we made two correct. Our precision is then the proportion of true positives: 2/3 = 0.667. Our recall is the proportion of the true positives out of all the possible positives in the image: 2/4 = 0.5. We repeat this process for (typically) the top-1 to top-10 predictions. This process yields a list of precision values at different recall values.
The next step is to compute the average for all your top-N values, hence the term Average Precision (AP). We loop over all recall values r, find the maximum precision p that we can obtain with our recall > r, and then compute the average. We now have our average precision for a single evaluation image.
Once we have computed the average precision for all images in our testing/validation set, we perform two more calculations:
- Compute the mean of the APs for each class, giving us a mAP for each class (for many datasets/challenges, you’ll want to examine the mAP class-wise so you can spot if your deep learning object detector is struggling with a specific class).
- Take the mAPs for each class and then average them together, yielding the final mAP for the dataset.
Again, mAP is more complicated than traditional accuracy, so don’t be frustrated if you don’t understand it on the first pass. This is an evaluation metric you’ll want to study multiple times before you fully understand it.
The good news is that most deep learning object detection implementations handle computing mAP for you. Furthermore, the definition of how mAP is calculated highly depends on which object detection library you are using and the particular dataset/challenge where you are working. For more information, including a worked example of how to compute mAP, please see Hui (2018).
The (Faster) R-CNN Architecture
In this section, we’ll review the Faster R-CNN architecture. We’ll start with a brief discussion on R-CNNs and how they have evolved over the series of three publications, leading to the Faster R-CNN architecture that we commonly use now. Finally, we’ll examine the core building blocks of the Faster R-CNN architecture, first at a high level and then again in more detail.
As we’ll see, the Faster R-CNN architecture is complex, with many moving parts. We’ll focus on understanding the tenets of this architecture prior to training the network on our own custom datasets in an upcoming blog post.
A Brief History of R-CNN
To better understand how the Faster R-CNN object detection algorithm works, we first need to review the history of the R-CNN algorithm, including its original incarnation and how it has evolved.
R-CNN
The first R-CNN paper, Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, was published by Girshick et al. (2013). We refer to this initial paper and associated implementation as simply R-CNN. An overview of the original R-CNN algorithm can be found in Figure 3, which includes a 4-step process:
- Step #1: Input an image
- Step #2: Extract region proposals (i.e., regions of the image that potentially contain objects) using an algorithm such as Selective Search (Uijlings et al., 2013).
- Step #3: Use transfer learning, specifically feature extraction, to compute features for each proposal (effectively an ROI) using the pre-trained CNN.
- Step #4: Classify each proposal using the extracted features with a Support Vector Machine (SVM).

In the first step, we input an image into our algorithm. We then run a region proposal algorithm such as Selective Search (or equivalent). The Selective Search algorithm takes the place of sliding windows and image pyramids, intelligently examining the input image at various scales and locations, thereby dramatically reducing the total number of proposal ROIs that will be sent to the network for classification. We can thus think of Selective Search as a smart sliding window and image pyramid algorithm.
Remark: A review of the Selective Search algorithm is outside the scope of this series, so we recommend treating it as a “black box” that intelligently proposes ROI locations to you. For a detailed discussion of Selective Search, refer to Uijlings et al. (2013).
Once we have our proposal locations, we crop them individually from the input image and apply transfer learning via feature extraction. Instead of obtaining the final predictions from the CNN, we utilize feature extraction to enable a downstream classifier to learn more discriminating patterns from these CNN features.
The fourth and final step is to train a series of SVMs on top of these extracted features for each class.
Looking at this pipeline for the original R-CNN, we can clearly see inspirations and parallels from traditional object detectors such as the Dalal and Triggs seminal HOG + Linear SVM framework:
- Instead of applying an exhaustive image pyramid and sliding window, we are swapping in a more intelligent Selective Search algorithm.
- Instead of extracting HOG features from each ROI, we’re now extracting CNN features.
- We’re still training SVM(s) for the final classification of the input ROI; only we’re training this SVM on the CNN features rather than the HOG ones.
The primary reason this approach worked so well is due to the robust, discriminative features learned by a CNN.
The problem with the original R-CNN approach is that it’s still incredibly slow. Furthermore, we’re not actually learning to localize via deep neural networks.
Instead, we’re leaving the localization to the Selective Search algorithm — we’re only classifying the ROI once it’s been determined as “interesting” and “worth examining” by the region proposal algorithm, which raises the question: is it possible to obtain end-to-end deep learning-based object detection?
Fast R-CNN
Approximately a year and a half after Girshick et al. (2013) submitted the original R-CNN publication to arXiv, Girkshick (2015) published a second paper, Fast R-CNN. Similar to the original R-CNN, the Fast R-CNN algorithm still utilized Selective Search to obtain region proposals, but a novel contribution was made: Region of Interest (ROI) Pooling. A visualization of the new, updated architecture can be seen in Figure 4.

In this new approach, we apply the CNN to the entire input image and extract a feature map using our network. ROI Pooling works by extracting a fixed-size window from the feature map and then passing it into a set of fully connected layers to obtain the output label for the ROI. We’ll discuss ROI Pooling in more detail in the Region of Interest (ROI) Pooling section, but for now, understand that ROI Pooling operates over the feature map extracted from the CNN and extracts a fixed-size window.
The primary benefit here is that the network is now effectively, end-to-end trainable:
- We input an image and associated ground-truth bounding boxes.
- Extract the feature map.
- Apply ROI pooling and obtain the ROI feature vector.
- Finally, use two sets of fully connected layers to obtain (1) the class label predictions and (2) the bounding box locations for each proposal.
While the network is now end-to-end trainable, performance suffered dramatically at inference (i.e., prediction) time by being dependent on the Selective Search (or equivalent) region proposal algorithm. To make the R-CNN architecture even faster, we need to incorporate the region proposal directly into the R-CNN.
Faster R-CNN
A month after the Fast R-CNN paper was published, Girshick collaborated with Ren, He, and Sun in a 2015 paper, Faster R-NN: Towards Real-Time Object Detection with Region Proposal Networks.
In this work, Girshick et al. created an additional component to the R-CNN architecture, a Region Proposal Network (RPN). As the name of this module sounds, the goal of the RPN is to remove the requirement of running Selective Search prior to inference and instead bake the region proposal directly into the R-CNN architecture.
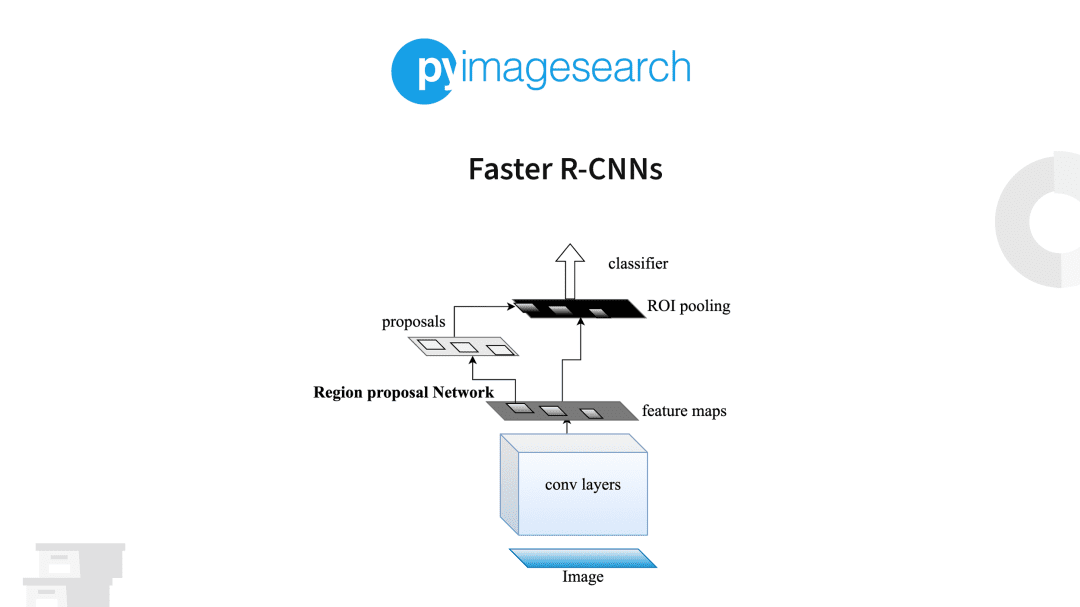
Figure 5 provides a visualization of the updated architecture. Here, an input image is presented to the network, and its features are extracted via pre-trained CNN (i.e., the base network). These features, in parallel, are sent to two different components of the Faster R-CNN architecture.
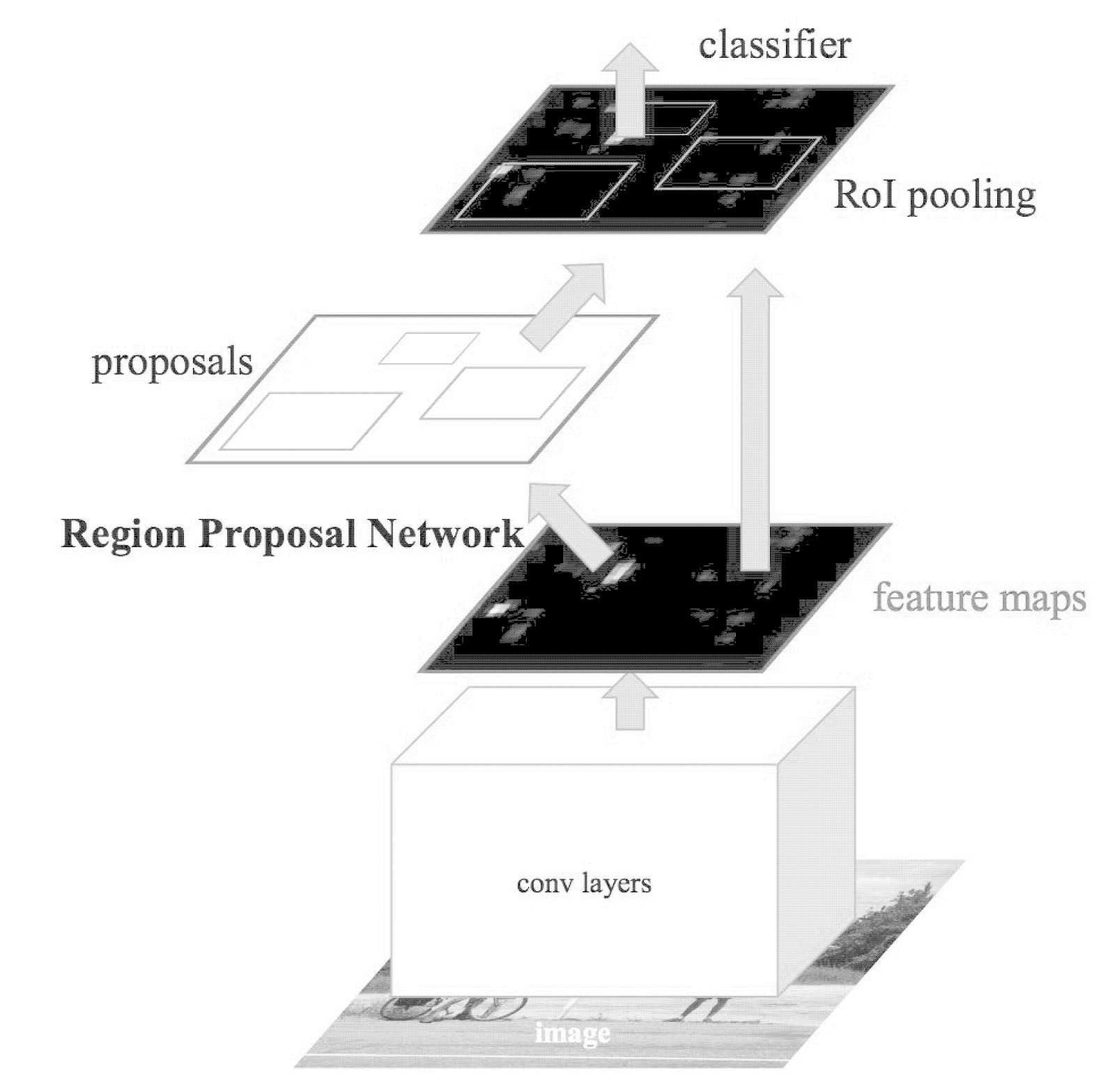
The first component, the RPN, determines where a potential object could be in an image. At this point, we do not know what the object is, just that there is potentially an object at a certain location in the image.
The proposed bounding box ROIs are based on the Region of Interest (ROI) Pooling module of the network along with the extracted features from the previous step. ROI Pooling is used to extract fixed-size windows of features, which are then passed into two fully connected layers (one for the class labels and one for the bounding box coordinates) to obtain our final localizations.
We’ll discuss the RPN in detail inside the Region Proposal Network (RPN) section, but in essence, we will place anchors spaced uniformly across the entire image at varying scales and aspect ratios. The RPN will then examine these anchors and output a set of proposals about where it “thinks” an object exists.
It’s important to note here that the RPN is not actually labeling the ROI; instead, it’s computing its “objectness score” and asking: “Does this region look like an object of some sort?” We like to think of the RPN and objectness score as a binary classifier where the RPN labels each ROI as “background” or “foreground.” If the RPN believes the ROI is “foreground,” then the ROI is worth further consideration by the ROI Pooling and final label + bounding box fully connected layers.
At this point, the entire architecture is end-to-end trainable, and the complete object detection pipeline takes place inside the network, including:
- Region proposal
- Feature extraction
- Computing the bounding box coordinates of the objects
- Providing class labels for each bounding box
Furthermore, depending on which GPU and base architecture are used, it’s now possible to obtain ≈ 7−10 frames per second (FPS), a huge step toward making real-time object detection with deep learning a reality.
Now that we have a brief introduction to the components in a (Faster) R-CNN architecture, let’s examine each in more detail.
The Base Network
In Figure 6, we can see the general modules in the Faster R-CNN architecture. After we input the image into the architecture, the first component we come across is the base network. The base network is typically a CNN pre-trained for a particular classification task. This CNN will be used for transfer learning, particularly feature extraction.

CONV and POOL layers. This process allows our network to handle input images of arbitrary spatial dimensions. The features are then fed into the RPN and ROI Pooling modules. In object detection, we typically use a CNN pre-trained on the ImageNet dataset. We use a pre-trained CNN here as the features learned by a particular layer are often transferrable to classification tasks outside where the original network was trained.
The original Faster R-CNN paper used VGG (Simonyan and Zisserman, 2014) and ZF (Zeiler and Fergus, 2013) as the base networks. Today, we would typically swap in a deeper, more accurate base network, such as ResNet (He et al., 2015; He et al., 2016), or a smaller, more compact network for resource-contained devices (e.g., MobileNets).
One important aspect of object detection networks is that they should be fully convolutional, not to be confused with fully connected. A fully convolutional neural network does not contain the fully connected layers typically found at the end of a network prior to making output predictions. In image classification, removing the fully connected layers is normally accomplished by applying average pooling across the entire volume prior to a single dense softmax classifier used to output the final predictions.
A fully convolutional neural network enjoys two primary benefits that include:
- Fast, due to all convolution operations
- Able to accept images of any spatial resolution (i.e., width and height), provided that the image and network can fit into memory, of course
When implementing object detection with deep learning it’s important that we do not rely on fixed-size input images that require us to force the image to a specific dimension. Not only can fixed sizes distort the aspect ratio of the input image, but they also have the even worse side effect of making it extremely challenging for the network to detect small objects. If we reduce the spatial dimensions of our image too much, small objects will now appear as tiny pixel blobs, too small for the network to detect. Therefore, it’s important that we allow the network to accept arbitrary spatial resolution images and let the input image size be a decision made by the network developer or engineer.
However, in the case of VGG in Girshick et al., we know there are fully connected layers at the end of VGG — it is thus not a fully convolutional network. There is a way to change the behavior of the CNN, though. Keep in mind that we only need the output of a specific CONV (or POOL) layer in the network — this output is our feature map, the process of which is visualized in Figure 6.
We can obtain this feature map by propagating the input image through the network and stopping at our target layer (we do not have to pass the image through the entire network to obtain our feature map). The fact that VGG originally only accepted a 224×224 input image is entirely arbitrary now that we’re only interested in the output of a specific CONV + POOL layer. This feature map will be used by the Region Proposal Network and ROI Pooling module later in the Faster R-CNN architecture.
Anchors
In traditional object detection pipelines, we would use either (1) a combination of a sliding window + image pyramid or (2) a Selective Search-like algorithm to generate proposals for our classifier. Since our goal is to develop an end-to-end object detector using deep learning that includes the proposal module, we need to define a method that will generate our proposal ROIs.
The core separation between classification and object detection is the prediction of bounding boxes, or (x, y)-coordinates surrounding an object. Thus, we might expect our network to return a tuple consisting of the bounding box coordinates of a particular object. However, there is a problem with this approach, namely:
- How do we handle a network predicting values outside the boundaries of the image?
- How do we encode restrictions such as xmin < xmax and ymin < ymax?
This is a near-impossible problem to solve. However, the solution proposed by Girshick et al., called anchors, is a clever and novel one.
Instead of trying to predict the raw (x, y)-coordinates of the bounding boxes, we can instead learn to predict their offsets from the reference boxes: ∆x−center, ∆y−center, ∆width, and ∆height. These delta values allow us to obtain a better fit to our reference box without predicting the actual raw (x, y)-coordinates, enabling us to bypass the potentially impossible problem of encoding bounding box “rules” into the network.
So, from where do these reference bounding boxes come? We need to generate the anchors ourselves without utilizing a Selective Search algorithm. To accomplish this, we first need to sample points uniformly across an input image (Figure 7, left). Here, we can see an input image of 600×400 pixels. We have labeled each point at a regularly sampled integer (at an interval of 16 pixels) with a blue circle.

64×64 (red), 128×128 (green), 256×256 (blue); and aspect ratio: 1:1, 2:1, 1:2. The next step is to create a set of anchors at each sampled point. As in the original Faster R-CNN publication, we’ll generate 9 anchors (fixed bounding boxes) with varying sizes and aspect ratios surrounding a given sampled point.
The colors of the bounding boxes are our scales/sizes: 64×64, 128×128, and 256×256. For each scale, we also have the aspect ratio, 1:1, 1:2, and 2:1. Each combination of scale and aspect ratio yields nine total anchors. This scale and aspect ratio combination yields considerable coverage over all possible object sizes and scales in the input image (Figure 7, right).
However, there is a problem once we break down the total number of anchors generated:
- If we use a stride of 16 pixels (the default for Faster R-CNN) on a
600×800image, we’ll obtain1,989total positions. - With 9 anchors surrounding each of the
1,989positions, we now have a total of1,989×9 = 17,901bounding box positions for our CNN to evaluate.
If our CNN classified each of the 17,901 bounding boxes, our network would be only slightly faster than exhaustively looping over each combination of sliding window and image pyramid. Luckily, with the Region Proposal Network (RPN), we can dramatically reduce the number of candidate proposal windows, leaving us with a much more manageable size.
Region Proposal Network (RPN)
If the goal of generating anchors is to obtain good coverage over all possible scales and sizes of objects in an image, the goal of the Region Proposal Network (RPN) is to prune the number of generated bounding boxes to a more manageable size.
The RPN module is simplistic yet powerful, consisting of two outputs. The top of the RPN module accepts an input, which is our convolutional feature map from The Base Network section. We then apply a 3×3 CONV, learning 512 filters.
These filters are fed into two paths in parallel. The first output (left) of the RPN is a score that indicates whether the RPN thinks the ROI is foreground (worth examining further) or background (discard). Figure 8 provides a visualization of labeling the “objectness” of an input ROI.

Again, the RPN is not actually labeling the ROI — it’s just trying to determine if the ROI is either background or foreground. The actual labeling of the ROI will occur later in the architecture (Region-Based Convolutional Neural Network section). The dimensionality of this output is 2×K, where K is the total number of anchors, one output for the foreground probability, and the second for the background probability.
The second output (right) is our bounding box regressor used to adjust the anchors to better fit the object that it is surrounding. Adjusting the anchors is again accomplished via 1×1 convolution, but this time outputting a 4×K volume. The output is 4×K as we predict the 4 delta (i.e., offset) values: ∆x−center, ∆y−center, ∆width, ∆height.
Provided that our foreground probability is sufficiently large, we then apply the following:
- Non-maxima suppression to suppress overlapping
- Proposal selection
There will naturally be many overlapping anchor locations as per the above Anchors section — non-maxima suppression helps reduce the number of locations to pass on to the ROI Pooling module. We further reduce the number of locations to pass into the ROI pooling module via proposal selection. Here we take only the top N proposals and discard the rest.
In the original Faster R-CNN publication (Girshick et al. 2015) set N = 2,000, but we can get away with a much smaller N (e.g., N = 10, 50, 100, 200) and still obtain good predictions. The next step in the pipeline would be to propagate the ROI and deltas to the Region of Interest (ROI) Pooling module, but let’s first discuss how we might train the RPN.
Training the RPN
During training, we take our anchors and put them into two different buckets:
- Bucket #1 — Foreground: All anchors that have a 0.5 IoU with a ground-truth object bounding box.
- Bucket #2 — Background: All anchors that have < 0.1 IoU with a ground-truth object.
Based on these buckets, we randomly sample between the two to maintain an equal ratio between background and foreground.
From there, we need to consider our loss functions. In particular, the RPN module has two loss functions associated with it. The first loss function is for classification, which measures the accuracy of the RPN predicting foreground vs. background (binary cross-entropy works nicely here).
The second loss function is for our bounding box regression. This loss function only operates on the foreground anchors, as background anchors would have no sense of a bounding box (and we should have already detected “background” and discarded it).
For the bounding box regression loss function, Girshick et al. utilized a variant of L1 loss called Smooth L1 loss. Since it’s unrealistic for us to 100% accurately predict the ground-truth coordinates of a bounding box (addressed in the Measuring Object Detector Performance section), Smooth L1 loss allows bounding boxes that are “sufficiently close” to their corresponding ground-truth boxes to be essentially correct and thereby diminish the impact of the loss.
Region of Interest (ROI) Pooling
The goal of the ROI Pooling module is to accept all N proposal locations from the RPN module and crop out feature vectors from the convolutional feature map in The Base Network section (Figure 9). Cropping feature vectors is accomplished by:
- Using array slicing to extract the corresponding patch from the feature map
- Resizing it to 14×14×D where D is the depth of the feature map
- Applying a max pooling operation with 2×2 strides, yielding a 7×7×D feature vector.

The final feature vector obtained from the ROI Pooling module can now be fed into the Region-Based Convolutional Neural Network (covered in the next section), which we will use to obtain the final bounding box coordinates for each object along with the corresponding class label.
For more information on how ROI Pooling is implemented, please see the original Girshick et al. (2015) publication as well as the excellent tutorial, Faster R-CNN: Down the Rabbit Hole of Modern Object Detection.
Region-Based Convolutional Neural Network
The final stage in our pipeline is the Region-Based Convolutional Neural Network, or as we know it, R-CNN. This module serves two purposes:
- Obtain the final class label predictions for each bounding box location based on the cropped feature map from the ROI Pooling module.
- Further refine the bounding box prediction (x, y)-coordinates for better prediction accuracy.
The R-CNN component is implemented via two fully connected layers, as Figure 10 demonstrates. On the far left, we have the input to our R-CNN, which are the feature vectors obtained from the ROI Pooling module. These features pass through two fully connected layers (each 4096-d) before being passed into the final two FC layers, yielding our class label (or background class) along with the bounding box delta values.

FC layers (each 4096-d), similar to the final layers of classification networks trained on ImageNet. The output of these FC layers feeds into the network’s final two FC layers. One FC layer is N +1-d, a node for each class label plus an additional label for the background. The second FC layer is 4×N, representing the deltas for the final predicted bounding boxes. One FC layer has N +1 nodes, where N is the total number of class labels. Adding the extra dimension indicates the background class, in case our RPN module lets a background region through.
The second FC layer is 4×N. The N here is again our total number of class labels. The four values are our corresponding deltas for ∆x−center, ∆y−center, ∆width, and ∆height, which will be transformed into our final bounding boxes.
These two outputs again imply that we’ll have two loss functions:
- Categorical cross-entropy for classification
- Smooth L1 loss for bounding box regression
We use categorical cross-entropy rather than binary cross-entropy to compute probabilities for each of our N classes versus the binary case (background vs. foreground) in the RPN module. The final step is to apply non-maxima suppression class-wise to our set of bounding boxes. These bounding boxes and associated class labels are considered the final predictions from our network.
The Complete Training Pipeline
We have a choice to make when training the entire Faster R-CNN pipeline. The first choice is to train the RPN module, obtain satisfactory results, and then move on to training the R-CNN module. The second choice is to combine the four loss functions (two for the RPN module, two for the R-CNN module) via weighted sum and then jointly train all four. Which one is better?
In nearly all situations, you’ll find that jointly training the entire network end-to-end by minimizing the weighted sum of the four loss functions not only takes less time but also obtains higher accuracy as well.
In an upcoming tutorial, we’ll learn how to use the TensorFlow Object Detection API to train our own Faster R-CNN networks. If you’re interested in more details on the Faster R-CNN pipeline, RPN, and ROI Pooling modules, along with additional notes on how we jointly minimize the four loss functions, be sure to refer to the original Faster R-CNN publication as well as the TryoLabs article.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we started by reviewing the Faster R-CNN architecture, along with its earlier variants, by Girshick et al. (2013), Girshick et al. (2015), and Girshick (2015). The R-CNN architecture has undergone a few iterations and improvements, but with the latest Faster R-CNN architecture, we can train end-to-end deep learning object detectors.
The architecture itself includes four primary components. The first component is the base network (i.e., ResNet, VGGNet, etc.), which is used as a feature extractor.
We then have the Region Proposal Network (RPN), which accepts a set of anchors and outputs proposals as to where it thinks objects are in an image. It’s important to note that the RPN does not know the object in the image, just that a potential object exists at a given location.
Region of Interest Pooling extracts feature maps from each proposal region.
Finally a Region-Based Convolutional Neural Network is used to (1) obtain the final class label predictions for the proposal and (2) further refine the proposal locations for better accuracy.
Given the large number of moving parts in the R-CNN architecture, it is not advisable to implement the entire architecture by hand. Instead, it’s recommended to use existing implementations such as the TensorFlow Object Detection API or Luminoth from TryoLabs.
In an upcoming lesson, we will learn how to train a Faster R-CNN using the TensorFlow Object Detection API to detect and recognize common United States street/road signs.
Citation Information
Martinez, H. “Faster R-CNNs,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/iaxmq
@incollection{Martinez_2023_FasterRCNNs,
author = {Hector Martinez},
title = {Faster {R-CNNs}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/iaxmq},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.