
Table of Contents
- Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series
- Introduction
- U-Net Framework
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- Project Structure
- About the Dataset
- Configuring the Prerequisites
- Defining the Data Utilities
- Defining the Model Utilities
- Defining the Network
- Training the Variational Autoencoder
- Results
- Summary
Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series
Welcome to the fifth and final installment of our Autoencoder series! In this concluding tutorial, we’ll delve deep into the captivating world of image segmentation, harnessing the power of the U-Net architecture. Our playground for this exploration will be the Oxford IIIT Pet Dataset, where we’ll train a U-Net model to masterfully segment images, differentiating intricate details and patterns with precision.

Throughout our journey, we’ve traversed the landscapes of various autoencoder architectures, each with its unique strengths and applications. Now, as we approach the culmination, we’ll cover essential steps such as data preprocessing, model initialization, and iterative training. By the end, you’ll not only have a comprehensive understanding of U-Net’s capabilities but also a holistic view of the autoencoder universe.
You’ll also appreciate the pivotal role of image segmentation in various applications, from medical imaging to autonomous driving, and how U-Net stands out as a beacon in this domain. By the end of this tutorial, you’ll have a robust grasp of how to implement, train, and evaluate the U-Net model using PyTorch.
As we wrap up our Autoencoder series, are you ready to dive into the final chapter and uncover the magic of image segmentation with U-Net in PyTorch? Let’s embark on this grand finale together!
This lesson is the last in a 5-part series on Autoencoders:
- Introduction to Autoencoders
- Implementing a Convolutional Autoencoder with PyTorch
- A Deep Dive into Variational Autoencoders with PyTorch
- Generating Faces Using Variational Autoencoders with PyTorch
- Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series (this tutorial)
To delve into the theoretical aspects of U-Net and subsequently explore its practical implementation for image segmentation in PyTorch, just keep reading.
Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series
Introduction
Image segmentation is a pivotal task in computer vision where each pixel in an image is assigned a specific label, effectively dividing the image into distinct regions. This technique offers a richer understanding of images compared to object detection, which merely encircles an object with a bounding box, or image classification that labels the entire image based on its content.
The power of segmentation is evident in its diverse applications, ranging from medical diagnostics, apparel segmentation, and flood mapping to autonomous vehicle systems.
Broadly, image segmentation is categorized into:
- Semantic Segmentation: Every pixel is labeled based on its class.
- Instance Segmentation: Beyond classifying pixels, this differentiates between individual object instances.
- Panoptic Segmentation: A unified approach that combines both semantic and instance segmentation, aiming to provide a comprehensive understanding of an image by labeling every pixel with either a class label or an individual object instance.
U-Net is a prominent semantic segmentation model initially designed for biomedical image segmentation. Its architecture has also inspired several Generative Adversarial Network (GAN) variations, including the Pix2Pix generator.
U-Net Framework
The U-Net model emerged from the research paper titled U-Net: Convolutional Networks for Biomedical Image Segmentation. Its structure is straightforward, consisting of an encoder for downsampling and a decoder for upsampling, interconnected by skip connections. As depicted in Figure 1, the architecture resembles the letter ‘U’, giving rise to its name, U-Net.
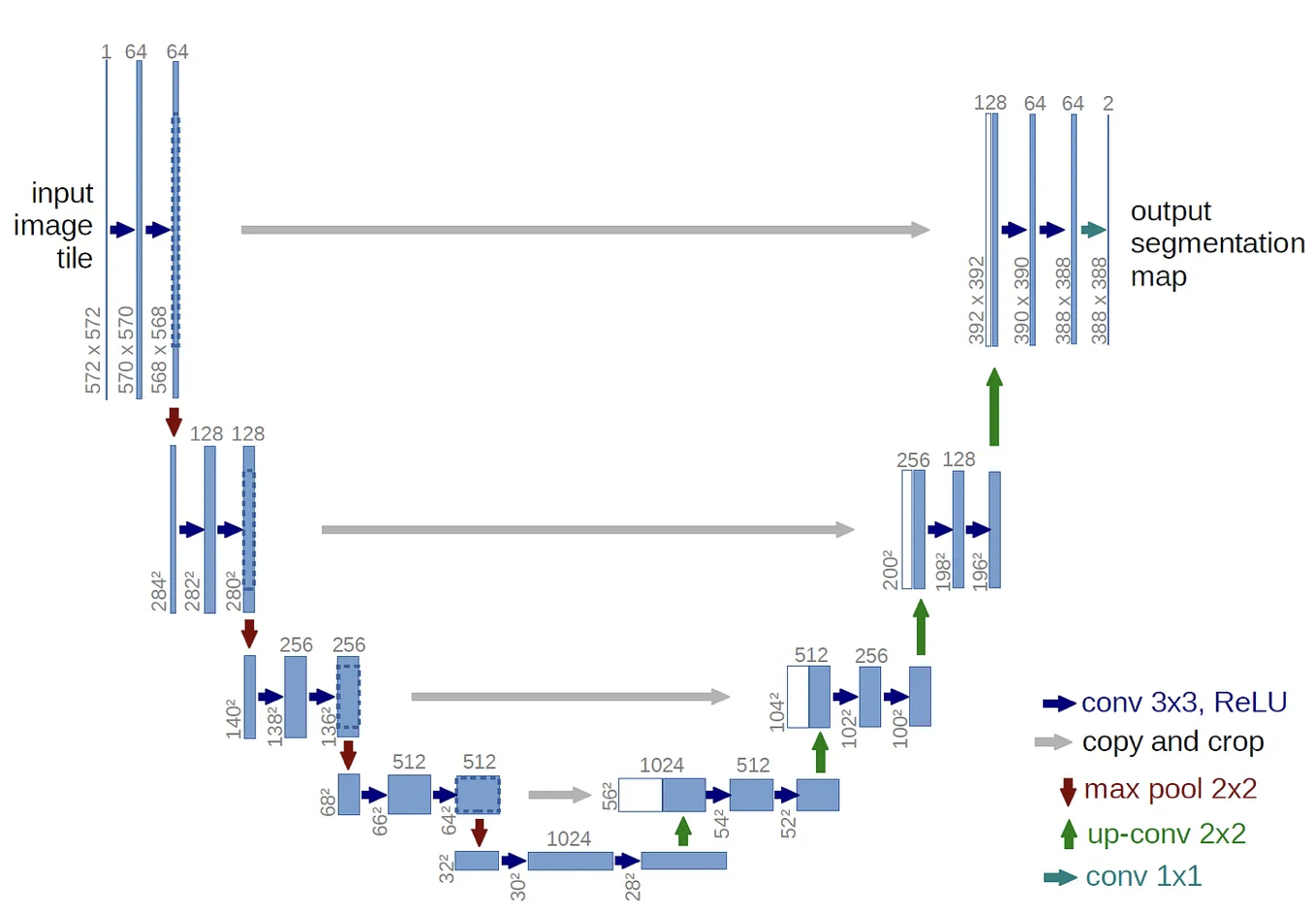
The gray arrows in the U-Net architecture diagram represent the skip connections, a distinctive feature of this model. These connections bridge the encoder’s feature maps directly to the decoder. In traditional autoencoders, the encoder compresses the input into a latent representation, which the decoder then expands to produce the output. However, during this process, some finer details of the input can be lost. Skip connections address this challenge by bypassing the compressed latent representation and directly feeding the detailed information from the encoder to the decoder. This ensures that even minute details from the input are retained in the output.
Furthermore, skip connections are crucial in mitigating the vanishing gradient problem during training. They allow gradients to flow backward more effectively, leading to a more stable and faster training process. This design choice makes U-Net particularly adept at tasks that require high-resolution outputs with intricate details, such as image segmentation.
With a foundational grasp of semantic segmentation and the U-Net framework in place, we’ll now delve into crafting a U-Net using PyTorch, tailored specifically for the Oxford IIIT Pet dataset.
Configuring Your Development Environment
To follow this guide, you need to have numpy, Pillow, torch, torchvision, matplotlib, pandas, scipy, and imageio libraries installed on your system.
Luckily, all these libraries are pip-installable:
$ pip install torch==2.0.1 $ pip install torchvision==0.15.2 $ pip install matplotlib==3.7.2 $ pip install pillow==9.4.0 $ pip install tqdm==4.65.0
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree -L 2 . ├── output │ ├── infer_test_images_post_training │ ├── model_weights │ ├── unet-train-val-dice-plot.png │ └── unet-train-val-loss-plot.png ├── pyimagesearch │ ├── __init__.py │ ├── config.py │ ├── data_utils.py │ ├── model_utils.py │ └── network.py └── train.py 5 directories, 8 files
In the pyimagesearch directory, we have the following files:
config.py: This configuration file is for training the U-Net modeldata_utils.py: This file contains data-related utilities like loading theOxford-IIIT Petdataset, preparing the images with corresponding masks for the image segmentation taskmodel_utils.py: This script hosts the model utilities like multi-class dice coefficient, dice loss, a validation method for evaluating the U-Net during the training phase, and most importantly, testing the model qualitatively post-trainingnetwork.py: Contains the U-Net architecture implementation in PyTorch
Within the main directory, we find:
train.py: This script facilitates the training of U-Net on theOxford-IIIT Petdataset. It logs the dice loss for validation data at the end of each epoch. Once the training is completed, it tests the model qualitatively to assess its image segmentation performance.output: This directory stores the model weights as well as the image segmentation results for each test image, which includes the input image, its predicted mask, and the corresponding ground truth mask.
About the Dataset
In this tutorial, we employ the Oxford-IIIT Pet Dataset for training our U-Net segmentation model.
Overview
The Oxford-IIIT Pet Dataset is a comprehensive collection of 37 different pet breed images, with roughly 200 images for each breed. The images exhibit significant variations in scale, pose, and lighting conditions. As shown in Figure 3, each image in the dataset is meticulously annotated with breed information, a head region of interest (ROI), and a pixel-level trimap segmentation, making it ideal for semantic segmentation tasks. The dataset provides a rich resource for exploring advanced machine learning techniques, especially in image segmentation.

Class Distribution
The Oxford-IIIT Pet Dataset encompasses a diverse range of pet images, totaling over 7,400 images spanning 37 unique breeds. These breeds include popular cats like Abyssinian, Bengal, and Siamese, as well as dogs like Boxer, Beagle, and Pug, among others. Each image in this dataset is accompanied by detailed annotations, including a pixel-level foreground-background segmentation (TriMap) and a tight bounding box (ROI) around the head of the animal.
Given its vast diversity and rich annotations, the Oxford-IIIT Pet Dataset is not just limited to semantic segmentation. It is a versatile resource for various computer vision tasks, including breed classification, head ROI detection, and more.
Data Preprocessing
For the best training outcomes using the Oxford-IIIT Pet Dataset, we apply a series of transformations to the images. Recognizing the diverse dimensions of the original images and their corresponding masks in the dataset, we standardize them to a uniform size of 128x128 pixels. This step guarantees compatibility with the U-Net model’s input specifications. After resizing, the images undergo normalization and are then transformed into PyTorch tensors. These preprocessing steps are consistently applied to both the training and validation datasets to maintain uniformity and enhance the model’s efficacy.
Data Split
The Oxford-IIIT Pet Dataset, while extensive, doesn’t come with a predefined training and validation split. In our approach, we’ve partitioned the dataset into training and validation sets to facilitate model training and evaluation. Specifically:
- Validation Set Size: We reserve 10% of the total dataset for validation. This subset is crucial for gauging the model’s performance on unseen data during the training phase and for post-training assessments.
- Training Set Size: The remaining portion of the dataset is utilized for training the model, ensuring it learns the intricate patterns and features of the pet images.
Configuring the Prerequisites
Before diving into the main implementation, it’s essential to establish the foundational configurations for our project.
The config.py script, housed within the pyimagesearch directory sets up the dataset and model checkpoint directories, defines crucial hyperparameters for training the model, and determines the computational device (GPU or CPU) based on availability. By organizing these configurations, we ensure a streamlined training process and efficient model evaluation.
# import the necessary packages import os # define the dataset directory by constructing the relative path to the data folder in the project root BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DATA_DIR = os.path.join(BASE_DIR, "data") # define the path to the checkpoint MODEL_CHECKPOINT_DIR = "model_weights"
On Line 2, we begin by importing the os module, which assists in setting up the dataset directory.
From Lines 5-8, we establish BASE_DIR, which contains the data folder. This folder is then designated as DATA_DIR. Additionally, we define the path for the model checkpoint.
# define the validation percentage VAL_PERCENT = 0.1 # batch size for training BATCH_SIZE = 128 # learning rate for the optimizer LEARNING_RATE = 1e-5 # momentum for the optimizer MOMENTUM = 0.999 # gradient clipping value (for stability while training) GRADIENT_CLIPPING = 1.0 # weight decay (L2 regularization) for the optimizer WEIGHT_DECAY = 1e-8 # number of epochs for training EPOCHS = 1 # set device to 'cuda' if CUDA is available, 'cpu' otherwise for model training and testing DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
Next, we set up various hyperparameters and configurations for training our model:
- Validation Percentage (
VAL_PERCENT): On Line 10, we define the percentage of the dataset that will be used for validation. In this case, 10% of the dataset will be reserved for validation. - Batch Size (
BATCH_SIZE): On Line 12, the batch size for training is set to128. This determines the number of samples each iteration uses to update the model’s weights. - Learning Rate (
LEARNING_RATE): On Line 14, we specify the learning rate for the optimizer. This hyperparameter controls the step size at each iteration while moving toward a minimum of the loss function. - Momentum (
MOMENTUM): On Line 16, the momentum for the optimizer is set. Momentum helps accelerate the optimizer in the right direction and dampens oscillations. - Gradient Clipping (
GRADIENT_CLIPPING): On Line 18, we set a value for gradient clipping. This is a technique to prevent exploding gradients in neural networks by clipping the gradients during backpropagation to stay below a specified threshold. - Weight Decay (
WEIGHT_DECAY): On Line 20, weight decay (or L2 regularization) is defined. This adds a penalty to the loss function, which encourages the model to have smaller weights, leading to a simpler and more generalized model. - Number of Epochs (
EPOCHS): On Line 22, we specify the number of epochs for training. An epoch is one complete forward and backward pass of all the training examples. - Device Configuration (
DEVICE): On Line 24, we determine the device for training and testing the model. If CUDA is available, we’ll use the GPU by setting the device tocuda. Otherwise, we’ll default to using the CPU by setting the device tocpu.
This configuration ensures that our model is trained efficiently and effectively, leveraging the best practices in deep learning.
Defining the Data Utilities
In our data utilities, we introduce a custom dataset class named OxfordPetDataset tailored for the Oxford-IIIT Pet Dataset, which is a collection of pet images with associated segmentation masks. This class is constructed on top of the Dataset class from the PyTorch library, making it seamlessly compatible with PyTorch’s data-loading utilities.
The OxfordPetDataset class is responsible for loading images and their corresponding masks, preprocessing them by resizing and normalization, and then returning them as PyTorch tensors. It also ensures that the images and masks match dimensions and handles the unique mask values across all images. This class is a fundamental component for efficient data handling and preprocessing during the model training process.
# import the necessary packages from os import listdir from os.path import isfile, join, splitext from pathlib import Path import numpy as np import torch from PIL import Image from torch.utils.data import Dataset from tqdm import tqdm
We begin by importing specific functions from the os module on Lines 2 and 3, which will assist us in handling file and directory operations. The pathlib module’s Path class is also imported on Line 4, offering an object-oriented interface for filesystem paths. For numerical operations and array manipulations, we utilize the numpy library (Line 6). The torch library is essential for our deep learning tasks, while the Dataset class from torch.utils.data provides a template for creating custom datasets (Lines 7 and 9). We also import the Image class from the PIL (Python Imaging Library) to handle image operations on Line 8. Lastly, on Line 10, the tqdm library is incorporated to display progress bars during data processing and model training.
# load image using PIL and return as a PIL Image object
def load_image(filename):
return Image.open(filename)
# function to find unique values in a given mask
def unique_mask_values(idx, mask_dir):
# find the corresponding mask file
mask_file = list(mask_dir.glob(idx + ".png"))[0]
# convert the PIL Image to a numpy array
mask = np.asarray(load_image(mask_file))
# return grayscale mask unique values
return np.unique(mask)
We first define the load_image function on Lines 14 and 15, which takes a filename as its argument. This function utilizes the Image.open method from the PIL to load the image and then returns it as a PIL Image object.
Subsequently, the unique_mask_values function is defined on Lines 19-25, designed to identify and return the unique pixel values in a given mask.
- The function accepts two arguments: the
idx(the identifier or name of the mask) andmask_dir(the directory where the mask files are stored). - Within this function, we first determine the appropriate mask file corresponding to the provided
idxusing theglobmethod. - Once the mask file is identified, it is loaded into a PIL Image object using the previously defined
load_imagefunction. - This image is then converted to a numpy array, allowing us to easily extract and return the unique grayscale values in the mask using numpy’s
uniquefunction.
# defining the dataset class
class OxfordPetDataset(Dataset):
def __init__(self, images_dir: str, mask_dir: str):
# initialize directories
self.images_dir = Path(images_dir)
self.mask_dir = Path(mask_dir)
# generate a list of file ids
self.ids = [
splitext(file)[0]
for file in listdir(images_dir)
if isfile(join(images_dir, file)) and not file.startswith(".")
]
# filter out 1 or 4 channel images
self.ids = [
img_id
for img_id in self.ids
if len(load_image(self.images_dir / f"{img_id}.jpg").split()) not in [1, 4]
]
In the above code, we define a custom dataset class named OxfordPetDataset inherited from PyTorch’s Dataset class. This class is tailored to handle the Oxford Pet dataset, which consists of images and their corresponding masks.
Here’s a breakdown of the class, specifically the __init__ method:
- The method accepts two arguments (
images_dirandmask_dir), representing the directories containing the images and masks, respectively. - The
Pathfunction from thepathliblibrary converts these directory strings intoPathobjects. This makes directory and file manipulations more intuitive and readable. - The
self.idslist is populated with the base filenames (without extensions) of all the image files in theimages_dir. It ensures that only files (not directories) are considered, and any hidden files (those starting with a dot) are excluded. - A subsequent filtering step refines the
self.idslist by excluding images that have either1or4channels. This ensures that the dataset only contains standard RGB images (3 channels). Theload_imagefunction is used to load each image, and thesplitmethod of the PIL Image object determines the number of channels in the image.
# throw an error if no images are found
if not self.ids:
raise RuntimeError(
f"No input file found in {images_dir}, make sure you put your images there"
)
# print the number of examples
print(f"[INFO] Creating dataset with {len(self.ids)} examples")
# find unique mask values across all images
unique = []
for img_id in tqdm(self.ids):
unique_values = unique_mask_values(img_id, self.mask_dir)
unique.append(unique_values)
# sort and print the unique mask values
self.mask_values = list(
sorted(np.unique(np.concatenate(unique), axis=0).tolist())
)
print(f"[INFO] Unique mask values: {self.mask_values}")
The continuation of the __init__ method in the OxfordPetDataset class further refines the dataset’s initialization process:
- Error Handling for Empty Dataset: After filtering the image IDs, the code checks if the
self.idslist is empty on Lines 50-53. If it is, aRuntimeErroris raised, indicating that no valid images were found in the specifiedimages_dir. This is a crucial step to ensure that the dataset is correctly populated and to provide a clear error message if something goes wrong.
- On Line 56, a message is printed to the console, indicating the total number of examples (images) the dataset will work with. This gives a quick overview of the dataset’s size.
- Finding Unique Mask Values (Lines 59-62)
- For segmentation tasks, each pixel in a mask corresponds to a particular class or category. The code iterates over all the image IDs and fetches the unique values in their corresponding masks using the
unique_mask_valuesfunction. These unique values represent the different classes/categories in the segmentation masks. - The
tqdmfunction wraps around the iteration to provide a progress bar, giving a visual indication of how many masks have been processed and how many are left.
- For segmentation tasks, each pixel in a mask corresponds to a particular class or category. The code iterates over all the image IDs and fetches the unique values in their corresponding masks using the
- Storing and Printing Unique Mask Values (Lines 65-68)
- After iterating over all the masks, the unique values are concatenated and sorted. The sorted unique values are then stored in the
self.mask_valueslist. This list provides a consolidated view of all the classes/categories present across all the segmentation masks in the dataset. - A message is printed to the console, displaying these unique mask values. This is helpful for understanding the different classes the model will be trained to recognize.
- After iterating over all the masks, the unique values are concatenated and sorted. The sorted unique values are then stored in the
In summary, this continuation of the __init__ method ensures that the dataset is correctly populated, provides feedback on its size, and identifies the unique classes in the segmentation masks.
# get the number of examples
def __len__(self):
return len(self.ids)
# preprocess the image or mask
@staticmethod
def preprocess(mask_values, pil_img, is_mask):
# resize image
pil_img = pil_img.resize(
(128, 128), resample=Image.NEAREST if is_mask else Image.BICUBIC
)
img = np.asarray(pil_img)
# if it's a mask, remap unique values
if is_mask:
mask = np.zeros((128, 128), dtype=np.int64)
for i, v in enumerate(mask_values):
mask[img == v] = i
return mask
# if it's an image, normalize and rearrange dimensions
else:
img = img.transpose((2, 0, 1))
# normalize the image
if (img > 1).any():
img = img / 255.0
return img
The OxfordPetDataset class is further extended by defining two methods: __len__ and preprocess.
The __len__ method (Lines 71 and 72) returns the number of examples (images) in the dataset. It’s a standard method for PyTorch’s Dataset class, allowing functions like len(dataset) to work correctly. Here, it simply returns the length of the self.ids list, which contains the IDs of all the valid images in the dataset.
Next, we define the static preprocessing method (preprocess) from Lines 75-97:
- This static method is designed to preprocess both images and masks, ensuring they are in the correct format and size for training.
- On Lines 78-80, the input image or mask (
pil_img) is resized to128x128pixels. If it’s a mask, theNEARESTresampling method ensures that the mask values remain integers. For images, theBICUBICresampling method is used for smoother resizing.
- The PIL image is converted to a numpy format on Line 81.
- Then, from Lines 84-88, we perform mask processing: If the input is a mask (
is_maskisTrue), the unique mask values are remapped to a continuous range of integers starting from0. This is done using the providedmask_valueslist. A new mask of size128x128is created, and for each unique value inmask_values, the corresponding pixels in the input mask are set to the index of that value inmask_values. This ensures the mask has a consistent set of values, which is crucial for training a segmentation model.
- Image Processing (Lines 91-97):
- If the input is an image (
is_maskisFalse), the image dimensions are rearranged from height × width × channels (HWC) to channels × height × width (CHW), which is the format expected by PyTorch. - The image is then normalized. If any pixel value in the image exceeds
1, the entire image is divided by255.0. This ensures that the pixel values are in the range[0, 1], a common practice to help neural networks converge faster during training.
- If the input is an image (
In essence, the preprocess method ensures that both images and masks are in the right format, size, and value range, making them ready for training the U-Net model for image segmentation tasks.
# get an example using an index
def __getitem__(self, idx):
# get the id using index
name = self.ids[idx]
# find the corresponding mask and image files
mask_file = list(self.mask_dir.glob(name + ".png"))
img_file = list(self.images_dir.glob(name + ".jpg"))
# load the image and mask
mask = load_image(mask_file[0])
img = load_image(img_file[0])
# check if the dimensions match
assert (
img.size == mask.size
), f"Image and mask {name} should be the same size, but are {img.size} and {mask.size}"
# preprocess the image and mask
img = self.preprocess(self.mask_values, img, is_mask=False)
mask = self.preprocess(self.mask_values, mask, is_mask=True)
# return as pytorch tensors
return {
"image": torch.as_tensor(img.copy()).float().contiguous(),
"mask": torch.as_tensor(mask.copy()).long().contiguous(),
}
Finally, we define our last method (i.e., the __getitem__ method), which is an essential part of PyTorch’s Dataset class, allowing for indexed access to dataset items. In the context of the OxfordPetDataset class, this method retrieves a specific image and its corresponding mask based on an index. Here’s a breakdown of the method:
The method starts by fetching the ID of the image and mask using the provided index (idx) on Line 102. This ID is used to locate the corresponding image and mask files.
The method then searches for the image and mask files in their respective directories using the glob method from the pathlib module on Lines 105 and 106. This method returns a list of matching files.
The image and mask files are loaded into memory using the previously defined load_image function (Lines 109 and 110). This function returns a PIL Image object for both the image and mask.
A crucial step is to ensure that the dimensions of the loaded image and mask match. An assertion check is used for this purpose on Lines 113-115. If the dimensions don’t match, an error is raised, indicating the mismatch and the ID of the problematic image and mask.
On Lines 118 and 119, both the image and mask are then preprocessed using the preprocess method. This method resizes the images, normalizes them, and, in the case of masks, remaps their unique values. The processed image and mask are returned in the format PyTorch models expect.
Finally, on Lines 122-125, the preprocessed image and mask are converted to PyTorch tensors using torch.as_tensor. The copy method ensures that a new memory is allocated for the tensor, and the contiguous method ensures that the tensor’s memory layout is contiguous. The image tensor is of type float, while the mask tensor is of type long (used for integer values in PyTorch).
In summary, the __getitem__ method provides a streamlined way to fetch, preprocess, and return a dictionary containing the image and mask tensors. This dictionary format is convenient for training, as it allows easy batching and access to both the input (image) and target (mask) during training.
Defining the Model Utilities
In the model utilities, we’ve implemented functions to compute the Sørensen-Dice coefficient and its associated loss for multi-class image segmentation. The multi_class_dice_coeff function calculates the Dice coefficient for segmentation overlap, while the dice_loss function determines the segmentation loss based on the Dice coefficient. These utilities are essential for evaluating and training our segmentation model on the Oxford-IIIT Pet Dataset.
import torch import torch.nn.functional as F
We start by importing the torch modules that would help us compute the dice_loss during the training and validation of our U-Net model.
def multi_class_dice_coeff(true, logits, eps=1e-7):
"""Computes the Sørensen-Dice coefficient for multi-class.
Args:
true: a tensor of shape [B, 1, H, W].
logits: a tensor of shape [B, C, H, W]. Corresponds to
the raw output or logits of the model.
eps: added to the denominator for numerical stability.
Returns:
dice_coeff: the Sørensen-Dice coefficient.
"""
num_classes = logits.shape[1]
true_1_hot = torch.eye(num_classes)[true.squeeze(1)]
true_1_hot = true_1_hot.permute(0, 3, 1, 2).float()
probas = F.softmax(logits, dim=1)
true_1_hot = true_1_hot.type(logits.type())
dims = (0,) + tuple(range(2, true.ndimension()))
intersection = torch.sum(probas * true_1_hot, dims)
cardinality = torch.sum(probas + true_1_hot, dims)
dice_coeff = (2.0 * intersection / (cardinality + eps)).mean()
return dice_coeff
This function calculates the Sørensen-Dice coefficient, a metric often used in image segmentation tasks to measure the similarity between two samples. It’s especially useful when the classes are imbalanced.
The function takes in three arguments:
true: The ground truth tensor of shape[B, 1, H, W], whereBis the batch size,His the height, andWis the width of the image.logits: The raw output or logits of the model of shape[B, C, H, W], whereCis the number of classes.eps: A small value added to the denominator to prevent division by zero, ensuring numerical stability.
On Lines 27 and 28, the ground truth labels (true) are converted into a one-hot encoded tensor using torch.eye(num_classes). This results in a tensor where each label is represented as a one-hot vector.
The logits are passed through a softmax activation function using F.softmax(logits, dim=1) to convert them into probabilities on Line 29. This ensures that the output values are between 0 and 1 and sum up to 1 across all classes.
The intersection of the predicted probabilities and the one-hot encoded ground truth is calculated using torch.sum(probas * true_1_hot, dims) on Line 32.
The cardinality (or union) is computed on Line 33, which is the sum of the predicted probabilities and the one-hot encoded ground truth: torch.sum(probas + true_1_hot, dims).
The Dice coefficient is then calculated as 2.0 * intersection / (cardinality + eps) on Line 34. The mean of this value is taken across all classes to get the final Dice coefficient.
The function returns the computed Dice coefficient to the calling function on Line 35, which measures the similarity between the predicted segmentation and the ground truth. A value of 1 indicates perfect overlap, while a value of 0 indicates no overlap.
In summary, this function provides a way to compute the Sørensen-Dice coefficient for multi-class image segmentation tasks, measuring how well the model’s predictions align with the actual ground truth.
def dice_loss(true, logits, eps=1e-7):
"""Computes the Sørensen-Dice loss, which is 1 minus the Dice coefficient.
Args:
true: a tensor of shape [B, 1, H, W].
logits: a tensor of shape [B, C, H, W]. Corresponds to
the raw output or logits of the model.
eps: added to the denominator for numerical stability.
Returns:
dice_loss: the Sørensen-Dice loss.
"""
return 1 - multi_class_dice_coeff(true, logits, eps)
Now that we have defined the multi_class_dice_coeff we can use that to compute the Sørensen-Dice loss, which is commonly used in image segmentation tasks. The Dice loss is essentially 1 minus the Dice coefficient. The Dice coefficient measures the similarity between two samples, and by subtracting it from 1, we get a loss value that we can minimize. Here’s a breakdown of the code:
The function takes in three arguments:
true: The ground truth tensor of shape[B, 1, H, W], whereBis the batch size,His the height, and W is the width of the image.logits: The raw output or logits of the model of shape[B, C, H, W], where C is the number of classes.eps: A small value added to the denominator to prevent division by zero, ensuring numerical stability.
The function computes the Dice coefficient by calling the previously defined multi_class_dice_coeff function with the ground truth (true), logits (logits), and the epsilon value (eps).
The Dice loss is then calculated as 1 minus the Dice coefficient: 1 - multi_class_dice_coeff(true, logits, eps).
The function returns the computed Dice loss. Since the Dice coefficient measures similarity (with 1 being perfect similarity), the Dice loss (1 minus the Dice coefficient) will be close to 0 when the predicted segmentation closely matches the ground truth and will be larger when they differ.
In summary, the dice_loss function provides a way to compute the Sørensen-Dice loss for multi-class image segmentation tasks. By minimizing this loss during training, the model is encouraged to produce segmentations that closely match the ground truth.
Defining the Network
In this section, we introduce the architecture of a custom U-Net model implemented using PyTorch. The U-Net architecture is renowned for its efficacy in image segmentation tasks. Our custom U-Net comprises a series of contracting (downsampling) layers, followed by expansive (upsampling) layers.
The DualConv module represents a block of two convolutional layers, each followed by batch normalization and a ReLU activation. The Contract and Expand modules handle the downsampling and upsampling processes, respectively. The architecture culminates in a FinalConv layer, which maps the feature representations to the desired number of classes. This U-Net variant is tailored for semantic segmentation on the Oxford-IIIT Pet Dataset.
# import the necessary packages import torch import torch.nn as nn import torch.nn.functional as F
To build the U-Net network, we import torch, torch.nn, and torch.nn.functional modules from Lines 2-4.
class DualConv(nn.Module):
def __init__(self, input_ch, output_ch):
super(DualConv, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(input_ch, output_ch, 3, padding=1, bias=False),
nn.BatchNorm2d(output_ch),
nn.ReLU(inplace=True),
nn.Conv2d(output_ch, output_ch, 3, padding=1, bias=False),
nn.BatchNorm2d(output_ch),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.conv_block(x)
We define a custom PyTorch module named DualConv. This module represents a common architectural pattern in convolutional neural networks, especially in U-Net-like architectures.
Line 7 declares a new class, DualConv, that inherits from nn.Module, which is the base class for all neural network modules in PyTorch.
The initializer method (Line 8) for the DualConv class takes two arguments: input_ch (number of input channels) and output_ch (number of output channels).
Line 9 calls the initializer of the parent class (nn.Module). It’s a necessary step when you’re overriding the __init__ method in a subclass.
From Lines 10-17, we define a sequential block of layers, which will be executed in the order they are defined. The block consists of:
- A 2D convolution layer with kernel size
3x3, padding of1(to maintain spatial dimensions), and no bias. - Batch normalization for the output channels.
- ReLU activation function.
- Another 2D convolution layer, similar to the first.
- Another batch normalization.
- Another ReLU activation function.
Next, on Lines 19 and 20, the forward method defines the forward pass of the module. In PyTorch, when you call a module like a function, it internally calls this forward method. It passes the input tensor x through the conv_block (the sequence of layers defined in the __init__ method) and returns the result.
In summary, the DualConv class represents a block with two consecutive convolutional layers, each followed by batch normalization and a ReLU activation.
class Contract(nn.Module):
def __init__(self, input_ch, output_ch):
super(Contract, self).__init__()
self.down_conv = nn.Sequential(nn.MaxPool2d(2), DualConv(input_ch, output_ch))
def forward(self, x):
return self.down_conv(x)
Next, we define a custom PyTorch module named Contract. The Contract module represents the contracting or downsampling path in U-Net architecture. Let’s break down the code:
Line 23 declares a new class, Contract, that inherits from nn.Module, which is the base class for all neural network modules in PyTorch.
The initializer for the Contract class on Line 24 takes two arguments: input_ch (number of input channels) and output_ch (number of output channels).
Line 25 calls the initializer of the parent class (nn.Module). It’s a necessary step when you’re overriding the __init__ method in a subclass.
Line 26 defines a sequential block of layers, which will be executed in the order they are defined. The block consists of:
nn.MaxPool2d(2): A 2D max pooling layer with a kernel size of2x2. This layer is responsible for downsampling the spatial dimensions of the input by half, which is a common operation in the contracting path of U-Net architectures.DualConv(input_ch, output_ch): An instance of the previously definedDualConvmodule. This module contains two convolutional layers, each followed by batch normalization and a ReLU activation.
Then, Lines 28 and 29 define the forward method that passes the input tensor x through the down_conv sequential block (which contains the max pooling and DualConv layers) and returns the result.
In summary, the Contract class represents a downsampling block that first applies max pooling to reduce the spatial dimensions of the input and then processes the result through two convolutional layers (via the DualConv module). This block is a fundamental component of the contracting path in U-Net architectures, allowing the network to capture and process features at different scales.
class Expand(nn.Module):
def __init__(self, input_ch, output_ch):
super(Expand, self).__init__()
self.up = nn.ConvTranspose2d(input_ch, input_ch // 2, kernel_size=2, stride=2)
self.conv = DualConv(input_ch, output_ch)
def forward(self, x1, x2):
x1 = self.up(x1)
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
x1 = F.pad(
x1, [diff_x // 2, diff_x - diff_x // 2, diff_y // 2, diff_y - diff_y // 2]
)
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
After defining the custom Contract class next up, we define a custom PyTorch module named Expand. The Expand module represents the expansive or upsampling path in U-Net architecture. Let’s understand it line-by-line:
On Line 32, we declare a new class, Expand, that inherits from nn.Module, the base class for all neural network modules in PyTorch.
The initializer for the Expand class takes two arguments: input_ch (number of input channels) and output_ch (number of output channels) on Line 33.
Line 35 defines a transposed convolution (also known as deconvolution) layer. It’s used for upsampling the spatial dimensions of the input. The kernel size is set to 2x2, and the stride is 2, effectively doubling the spatial dimensions of the input.
An instance of the previously defined DualConv module, which contains two convolutional layers, each followed by batch normalization and a ReLU activation, is defined on Line 36.
The forward method on Line 38 takes two inputs: x1 (from the previous layer) and x2 (from the corresponding layer in the contracting path).
The forward function performs following operations:
x1 = self.up(x1): Upsamples thex1tensor using the transposed convolution layer.diff_yanddiff_x: These lines compute the difference in height (diff_y) and width (diff_x) between the tensorsx2andx1. This difference arises because of possible discrepancies in spatial dimensions due to pooling and upsampling operations.x1 = F.pad(...): This line pads thex1tensor to make its spatial dimensions match those ofx2. The padding is symmetrically applied.x = torch.cat([x2, x1], dim=1): This line concatenates the tensorsx2andx1along the channel dimension. This operation fuses the features from the contracting path (x2) with the upsampled features (x1).- Finally, on Line 46, the concatenated tensor
xis then passed through theDualConvmodule.
In summary, the Expand class represents an upsampling block in the U-Net architecture. It first upsamples the input tensor, then pads it to match the spatial dimensions of a corresponding tensor from the contracting path, concatenates the two tensors, and finally processes the result through two convolutional layers (via the DualConv module). This block allows the network to combine low-level features from the contracting path with upsampled high-level features, enabling precise localization in the segmentation output.
class FinalConv(nn.Module):
def __init__(self, input_ch, output_ch):
super(FinalConv, self).__init__()
self.conv = nn.Conv2d(input_ch, output_ch, kernel_size=1)
def forward(self, x):
return self.conv(x)
The FinalConv module represents the final convolutional layer in a U-Net architecture, which is used to map the combined features of the network to the desired number of output channels (e.g., the number of classes in a segmentation task). Let’s break down the code:
Line 49 declares a new class, FinalConv, that inherits from nn.Module. The initializer for the FinalConv class takes two arguments: input_ch (number of input channels) and output_ch (number of output channels) on Line 50.
Line 52 defines a 2D convolutional layer with a kernel size of 1x1. A 1x1 convolution is often used in neural networks to change the number of channels without altering the spatial dimensions of the feature map. In this context, it’s used to map the combined features of the U-Net to the desired number of output channels.
In the forward method on Lines 54 and 55, the input tensor x is passed through the 1x1 convolutional layer.
In summary, the FinalConv class represents the final mapping in the U-Net architecture. It uses a 1x1 convolution to adjust the number of channels in the output tensor to match the desired number of classes or segments. This is a common technique in segmentation networks to produce an output with the same spatial dimensions as the input but with each pixel assigned a class label.
class CustomUNet(nn.Module):
def __init__(self, input_channels, num_classes):
super(CustomUNet, self).__init__()
self.initial = DualConv(input_channels, 64)
self.down1 = Contract(64, 128)
self.down2 = Contract(128, 256)
self.down3 = Contract(256, 512)
self.down4 = Contract(512, 1024)
self.up1 = Expand(1024, 512)
self.up2 = Expand(512, 256)
self.up3 = Expand(256, 128)
self.up4 = Expand(128, 64)
self.final = FinalConv(64, num_classes)
def forward(self, x):
x1 = self.initial(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.final(x)
return logits
We have defined the building blocks that make a U-Net architecture basically the contracting path, a bottleneck, and an expansive that characterizes a U-Net with a symmetric shape. We are all set to now join all the blocks together in the CustomUNet class.
The initializer for the CustomUNet class on Line 59 takes two arguments: input_channels (number of input channels of the image) and num_classes (number of output classes for segmentation).
Lines 61-70 define the layers of the U-Net:
self.initial: Initial dual convolutional block.self.down1toself.down4: Contracting path layers that downsample the feature maps.self.up1toself.up4: Expansive path layers that upsample the feature maps and concatenate them with the corresponding feature maps from the contracting path.self.final: Final convolutional layer that maps the combined features to the desired number of output classes.
Lines 72-83 define the forward pass through the U-Net layers accepting the input x:
- The input
xis passed through the initial dual convolutional block. - It then goes through the contracting path (
down1todown4). - The feature maps are then passed through the expansive path (
up1toup4), where they are upsampled and concatenated with the corresponding feature maps from the contracting path. - Finally, the combined feature maps are passed through the final convolutional layer to produce the output logits.
The forward method returns the output logits on Line 83, which are used to compute the segmentation mask.
In summary, the CustomUNet class defines a U-Net architecture for image segmentation. The U-Net first contracts the input image to extract high-level features and then expands it to produce a segmentation mask with the same spatial dimensions as the input. The architecture is symmetric, with skip connections between the contracting and expansive paths to retain spatial information.
Training the Variational Autoencoder
In this section, we train a U-Net model on the Oxford IIIT Pet Dataset using PyTorch. The training process involves optimizing the model to minimize the difference between the predicted masks and the true masks. Key steps encompass:
- Data preparation and splitting into training and validation sets.
- Model initialization.
- Iterative training across epochs with loss computation and backpropagation.
- Periodic evaluation of the validation set and saving model checkpoints.
- Visualization of model predictions to monitor progress.
Post-training, the model’s performance is evaluated on a test set, and sample predictions are visualized.
# USAGE # python train.py # import the necessary packages import os from pathlib import Path import torch import torch.nn as nn from torch import optim from torch.utils.data import DataLoader, random_split from torchvision.datasets import OxfordIIITPet from tqdm import tqdm from pyimagesearch import config, data_utils, model_utils, network
As always, we start by import the necessary packages such as
-
osfor operating system-dependent functionality Pathfor handling filesystem pathstorchandtorch.nnfor PyTorch-related operations like gradient clipping, defining PyTorch data types, and cross-entropy loss.optimfromtorch, which contains neural network optimizers like SGD, Adam, etc.- Import
DataLoaderandrandom_splitfor loading and splitting the dataset. - Import the
OxfordIIITPetclass from thetorchvision.datasetsmodule. This class provides an easy way to download and use the Oxford IIIT Pet dataset. - The
tqdmmodule for extensible progress bars for loops and other computations. - Finally, import various modules and utilities from our custom
pyimagesearchpackage. Contains custom implementations or utilities related to configuration (config), data processing (data_utils), model-related utilities (model_utils), and the U-Net (network) in thepyimagesearchdirectory.
In summary, this script sets up the necessary packages and modules to train a U-Net on the Oxford IIIT Pet dataset.
def main():
# create parent folder to store all the results
parent_folder = "output"
if not os.path.exists(parent_folder):
os.makedirs(parent_folder)
The main() function handles the setup of the training environment for the Oxford IIIT Pet dataset, trains the U-Net model, and evaluates its performance on test data. Let’s delve into the function’s details step by step:
We begin by creating a directory called output. This is where all the outcomes, from U-Net model weights to the predicted masks for the test images after training, will be saved.
It checks if this directory exists using os.path.exists(parent_folder). If it doesn’t, it creates the directory using os.makedirs(parent_folder).
print("[INFO] Fetching the Oxford IIIT Pet Dataset from cache or downloading it")
# load the dataset
dataset = OxfordIIITPet(
root=config.DATA_DIR, target_types="segmentation", download=True
)
# define the paths to the images and segmentation maps directories
images_dir = "./data/oxford-iiit-pet/images"
mask_dir = "./data/oxford-iiit-pet/annotations/trimaps"
print("[INFO] Preparing the dataset for training")
# initialize the OxfordPetDataset class
dataset = data_utils.OxfordPetDataset(images_dir=images_dir, mask_dir=mask_dir)
# split into train / validation partitions
n_val = int(len(dataset) * config.VAL_PERCENT)
n_train = len(dataset) - n_val
train_set, val_set = random_split(
dataset, [n_train, n_val], generator=torch.Generator().manual_seed(0)
)
# create data loaders for training and validation
train_loader = DataLoader(train_set, batch_size=config.BATCH_SIZE, shuffle=True)
val_loader = DataLoader(
val_set, batch_size=config.BATCH_SIZE, shuffle=False, drop_last=True
)
On Line 24, a message is printed to inform the user that the Oxford IIIT Pet Dataset is being fetched. From Lines 26-28, the OxfordIIITPet class from torchvision.datasets is used to load the dataset. If the dataset isn’t present in the specified directory (config.DATA_DIR), it will be downloaded. The dataset is loaded with the target type set to “segmentation”, indicating that segmentation masks will be fetched along with the images.
On Lines 31 and 32, the paths to the directories containing the images and segmentation maps (masks) are defined.
Next, we prepare the dataset for training by printing a message to inform the user that the dataset is being prepared for training on Line 34.
On Line 36, a custom OxfordPetDataset class (defined in the data_utils module) is initialized with the paths to the images and masks. This class contains custom logic to process and load the images and masks in a format suitable for training.
Next, we split the loaded dataset on Lines 39-43:
- The dataset is split into training and validation sets. The size of the validation set is determined by the
config.VAL_PERCENTvalue (e.g., ifVAL_PERCENTis 0.1, then 10% of the dataset will be used for validation). - The
random_splitfunction from PyTorch is used to perform the split. A manual seed is set to ensure reproducibility.
After splitting the dataset we create the training and validation data loaders on Lines 46-49:
- The training data loader shuffles the data before each epoch, ensuring that the model sees the training examples in a different order after each epoch.
- The validation data loader doesn’t shuffle the data and drops the last batch if its size is smaller than the specified batch size (
config.BATCH_SIZE).
In summary, we ensure that the dataset is available, process it, split it into training and validation sets, and create data loaders to load batches of data during training efficiently.
# call the UNet class from the network.py file and initialize the model
model = network.CustomUNet(input_channels=3, num_classes=3)
model.to(device=config.DEVICE)
# set up the optimizer, the categorical loss, the learning rate scheduler
optimizer = optim.RMSprop(
model.parameters(),
lr=config.LEARNING_RATE,
weight_decay=config.WEIGHT_DECAY,
momentum=config.MOMENTUM,
foreach=True,
)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, "max", patience=5
) # goal: maximize Dice score
criterion = nn.CrossEntropyLoss()
The above code continues the setup process for training the U-Net model on the Oxford IIIT Pet dataset.
The U-Net model is initialized using the CustomUNet class from the network module on Line 52. This class is the U-Net architecture we discussed earlier. The model expects input images with 3 channels (RGB) and is designed to predict 3 classes, hence input_channels=3 and num_classes=3.
The model is then moved to the appropriate device (either CPU or GPU) using the .to() method on Line 53. The device is specified in the config.DEVICE variable.
On Lines 56-62, we set the optimizer for our U-Net model. The RMSprop optimizer is chosen for training the model. The optimizer is initialized with various hyperparameters like learning rate, weight decay, and momentum, all of which are fetched from the config module.
A learning rate scheduler is set up to adjust the learning rate during training on Lines 63-65. Specifically, the ReduceLROnPlateau scheduler is used, which reduces the learning rate when a metric has stopped improving.
The scheduler is set to monitor the Dice score (a common metric for segmentation tasks) and aims to maximize it. If the Dice score doesn’t improve for 5 epochs (patience=5), the learning rate will be reduced.
Lastly, we introduce an extra loss function, specifically the CrossEntropyLoss, as our chosen loss function. This is frequently selected for multi-class classification challenges. In terms of segmentation, every pixel in the image is categorized into a specific class, turning it into a classification task on a per-pixel basis. To optimize our segmentation model, we’ll employ a blend of Dice loss and CrossEntropy loss functions.
In summary, this code section sets up the U-Net model, optimizer, learning rate scheduler, and loss function, all essential components for training a deep learning model. The chosen configurations and hyperparameters are based on best practices and the specific requirements of the segmentation task on the Oxford IIIT Pet dataset.
# initialize lists for storing loss and validation Dice scores over epochs
epoch_losses = []
val_scores = []
train_scores = []
val_losses = []
print("[INFO] Starting training")
# begin training
for epoch in range(1, config.EPOCHS + 1):
# set the model to training mode
model.train()
# initialize the epoch loss and epoch Dice score variables to store the loss and Dice score for each epoch
epoch_loss = 0
epoch_dice_score = 0
# create a progress bar for training and wrap it with tqdm to display progress during training
with tqdm(total=n_train, desc=f"Epoch {epoch}/{config.EPOCHS}", unit="img") as pbar:
# iterate over the training set
for batch in train_loader:
# extract the image and mask batch, and move the batch to the device
images, true_masks = batch["image"], batch["mask"]
# move images and masks to correct device and type
images = images.to(
device=config.DEVICE,
dtype=torch.float32,
memory_format=torch.channels_last,
)
true_masks = true_masks.to(device=config.DEVICE, dtype=torch.long)
# predict the mask using the model
masks_pred = model(images)
# compute the cross-entropy loss and the Dice loss for the predicted masks vs. the true masks
loss = criterion(masks_pred, true_masks)
loss += model_utils.dice_loss(true_masks, masks_pred)
# zero the gradients
optimizer.zero_grad(set_to_none=True)
# backpropagate the loss
loss.backward()
# clip the gradients to prevent exploding gradients
torch.nn.utils.clip_grad_norm_(model.parameters(), config.GRADIENT_CLIPPING)
# update the weights
optimizer.step()
# update the progress bar
pbar.update(images.shape[0])
# update the epoch loss
epoch_loss += loss.item()
# update the progress bar with the loss for the current batch
pbar.set_postfix(**{"loss (batch)": loss.item()})
# compute Dice score for training set for this batch and add it to the epoch Dice score
dice_score_batch = model_utils.multi_class_dice_coeff(
true_masks, masks_pred
)
epoch_dice_score += (
dice_score_batch.item()
) # Sum up the Dice score for each batch
In the above code, we start with the training loop of the U-Net model for image segmentation. Let’s discuss the detailed breakdown:
We start by initializing a few lists to store the loss and Dice scores for both training and validation over the epochs on Lines 69-72. These lists will help in tracking the model’s performance over time.
The training loop runs for a specified number of epochs, as defined in the config.EPOCHS variable on Line 76. At the start of each epoch, the model is set to training mode using model.train() on Line 78. This ensures that certain layers like dropout and batch normalization work in training mode.
A progress bar is created using tqdm to provide a visual representation of the training progress for each epoch on Line 83.
For each batch in the training data loader (train_loader), the following steps are performed (Lines 85-127):
- The images and their corresponding masks are extracted from the batch and moved to the appropriate device (CPU or GPU).
- The model predicts the masks for the input images.
- The loss is computed using the CrossEntropy loss (
criterion) and the Dice loss. Both losses are summed up to get the final loss for the batch. - The gradients are zeroed out, the loss is backpropagated, and the model’s weights are updated using the optimizer.
- The gradients are clipped to a specified value (from
config.GRADIENT_CLIPPING) to prevent exploding gradients, which can destabilize the training. - The weights of the model are updated.
- The progress bar is updated with the number of images processed and the loss for the current batch.
- The loss for each batch is added to the epoch’s loss, which will later be averaged to get the mean loss for the epoch.
- The Dice score for the batch is computed and added to the epoch’s Dice score to compute the average Dice score for the epoch.
In summary, this section represents the core training loop where the model learns to predict segmentation masks for the input images. The combination of CrossEntropy and Dice loss ensures that the model not only classifies each pixel correctly but also produces masks that overlap well with the ground truth. The progress bar provides a real-time update on the training progress, making it easier to monitor the model’s performance.
# compute average loss and Dice score for this epoch
avg_loss = epoch_loss / len(train_loader)
avg_dice_score = epoch_dice_score / len(train_loader)
# append the average loss and Dice score to the respective lists
epoch_losses.append(avg_loss)
train_scores.append(avg_dice_score)
# print the average loss and Dice score for this epoch
print(
f"[INFO] Epoch {epoch} finished! Loss: {avg_loss}, Train Dice Score: {avg_dice_score}"
)
# evaluation at the end of the epoch on the validation set
val_score, val_loss = model_utils.evaluate(
model, val_loader, config.DEVICE, criterion=criterion
)
# update the learning rate scheduler based on the validation Dice score
scheduler.step(val_score)
# print the validation loss and Dice score for this epoch
print(f"[INFO] Validation Loss: {val_loss}, Validation Dice score: {val_score}")
# append the validation loss and Dice score to the respective lists
val_losses.append(val_loss)
val_scores.append(val_score)
# visualize one random test image and its corresponding predicted and ground truth masks per epoch
model_utils.test_model(
model, config.DEVICE, val_loader, epoch, parent_folder=parent_folder
)
# save the model checkpoint after each epoch
Path(parent_folder, config.MODEL_CHECKPOINT_DIR).mkdir(parents=True, exist_ok=True)
state_dict = model.state_dict()
state_dict["mask_values"] = dataset.mask_values
# construct the path for saving the checkpoint
checkpoint_path = os.path.join(
parent_folder, config.MODEL_CHECKPOINT_DIR, f"checkpoint_epoch{epoch}.pth"
)
torch.save(state_dict, checkpoint_path)
print(f"[INFO] Checkpoint {epoch} saved at: {checkpoint_path}")
print(
"[INFO] Training is completed, let's now run the inference with trained UNET on the test set"
)
model_utils.test_model_post_training(
model, config.DEVICE, val_loader, epoch, sample_size=50, parent_folder=parent_folder
)
if __name__ == "__main__":
main()
After all batches are processed in an epoch we further proceed to the evaluation phase for the U-Net model on the validation dataset as well as saving the model weights.
After processing all batches in an epoch, the average loss and Dice score for the epoch are computed by dividing the accumulated values by the number of batches on Lines 130 and 131.
These average values are then appended to their respective lists (epoch_losses and train_scores) for tracking purposes on Lines 133 and 134. The average loss and Dice score for the epoch are printed to the console on Lines 137-139.
After each training epoch, the model is evaluated on the validation dataset using the model_utils.evaluate function on Lines 142-144. This function returns the Dice score and loss for the validation set.
The learning rate scheduler adjusts the learning rate based on the validation Dice score on Line 146. The validation loss and Dice score are printed to the console and appended to their respective lists (val_losses and val_scores) on Lines 148-151.
A utility function, model_utils.test_model, is called to visualize the model’s predictions on a random sample from the validation set on Lines 153-155. This helps in visually assessing the model’s performance.
After each epoch, the model’s weights (state dictionary) are saved as a checkpoint on Lines 158-167. This ensures that the training progress is preserved, and the model can be resumed or used for inference later. The checkpoint is saved in a specified directory (config.MODEL_CHECKPOINT_DIR), and the filename indicates the epoch number.
Once all epochs are completed, a message is printed to indicate the end of training on Lines 169-171.
The model_utils.test_model_post_training function is called to run inference on a sample of the validation set and visualize the results on Lines 172-174. This provides a comprehensive view of the model’s qualitative performance after training on the test dataset.
The main function is executed if the script is run as the main module on Lines 177 and 178. This initiates the entire training and validation process.
In summary, this section of the code ensures that after each training epoch, the model is evaluated on a validation set to gauge its performance. The results are visualized, and the model’s weights are saved as checkpoints. This structured approach ensures that the training process is transparent and that the model’s progress can be monitored and resumed if necessary.
Results
Qualitative Results
Here, in Figure 4, we present a selection of sample results obtained from the model on the testing dataset. Each result includes an input image, the corresponding predicted mask, and the ground-truth mask.




These above visualizations provide insight into how well the model performs on various test images.
Quantitative Results
In addition to qualitative assessments, we present quantitative measures to evaluate the model’s performance.
Figure 5 plot illustrates the training and validation loss throughout the training process:
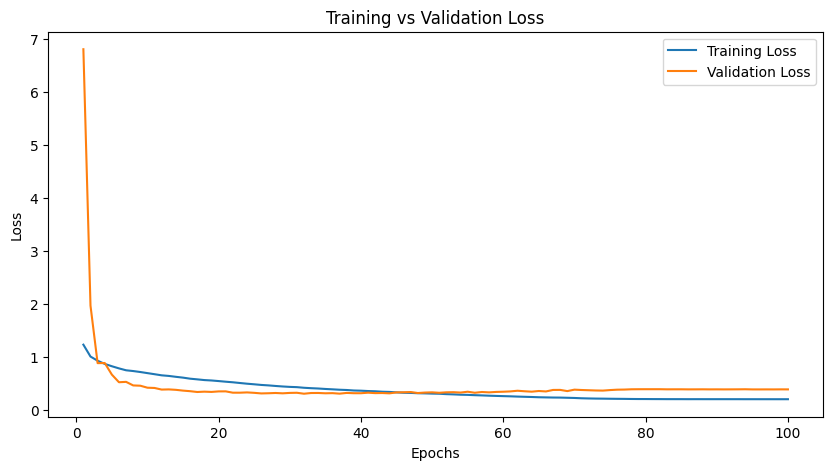
The loss values help us understand how well the model converges and whether it’s overfitting or underfitting.
The Dice Score is a widely used metric in image segmentation tasks. It measures the model’s accuracy in capturing object boundaries and regions. Figure 6 plot below displays the training and validation Dice Scores:
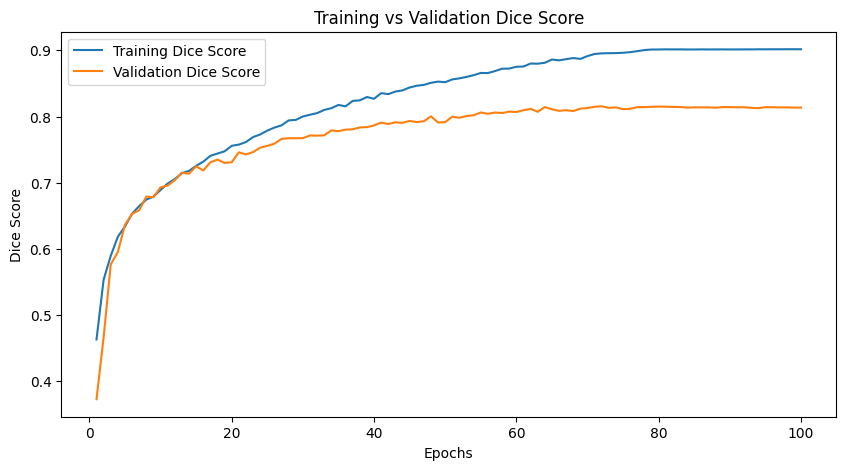
These plots offer insights into the model’s ability to segment objects of interest in the images accurately.
These combined qualitative and quantitative results give us a comprehensive view of the model’s performance in various aspects of the segmentation task.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: August 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we journeyed through the intricacies of U-Net, a renowned architecture for image segmentation. We began with the foundational concepts of U-Net, highlighting its encoder-decoder structure and the significance of skip connections. The Oxford IIIT Pet dataset was introduced, detailing its composition and the essential preprocessing steps for optimal training.
As we delved deeper, we discussed the configuration essentials, utility functions, and the blueprint of the U-Net architecture. The tutorial’s core revolved around the training regimen, offering a step-by-step guide to harnessing the power of U-Net on the Oxford dataset.
Upon concluding the training, we transitioned into an analysis phase, showcasing the model’s prowess through qualitative and quantitative results. By the end, readers gained a holistic grasp of image segmentation with U-Net and its application on the Oxford dataset.
Citation Information
Sharma, A. “Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/6x01s
@incollection{Sharma_2023_ImageSegmentationUNetPyTorch,
author = {Sharma},
title = {Image Segmentation with {U-Net} in {PyTorch}: The Grand Finale of the Autoencoder Series},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/6x01s},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.