
Table of Contents
- Generating Faces Using Variational Autoencoders with PyTorch
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- Project Structure
- About the Dataset
- Configuring the Prerequisites
- Defining the Data Utilities
- Defining the Model Utilities
- Defining the Network
- Training the Variational Autoencoder
- Diving Deep into VAE: Post-Training Discoveries
- Summary
Generating Faces Using Variational Autoencoders with PyTorch
In this tutorial, we’ll dive deep into the realm of Variational Autoencoders (VAEs), using the renowned CelebA dataset as our canvas. Our journey begins with training a VAE on this dataset, setting the stage for a series of captivating experiments. We’ll explore tasks ranging from reconstructing the validation set to sampling from the standard normal distribution, probing the first 50 latent dimensions, and even enhancing visual attributes through the magic of latent space arithmetic.

By the time we conclude, you’ll have a comprehensive understanding of how to implement, train, and experiment with VAEs using PyTorch. Moreover, you’ll grasp the unique characteristics that set VAEs apart in the world of generative models alongside notable counterparts like Generative Adversarial Networks (GANs) and Energy-Based Models (EBMs).
Ready to unravel the intricacies of training and experimenting with Variational Autoencoders on the CelebA dataset using PyTorch? Let’s dive in!
This lesson is the 4th in a 5-part series on Autoencoders:
- Introduction to Autoencoders
- Implementing a Convolutional Autoencoder with PyTorch
- A Deep Dive into Variational Autoencoders with PyTorch
- Generating Faces Using Variational Autoencoders with PyTorch (this tutorial)
- Lesson 5
If you’re eager to master the training of a Variational Autoencoder in PyTorch and delve into intriguing experiments, from reconstructing images to harnessing the wonders of latent space arithmetic using the CelebA dataset, just keep reading.
Configuring Your Development Environment
To follow this guide, you need to have numpy, Pillow, torch, torchvision, matplotlib, pandas, scipy, and imageio libraries installed on your system.
Luckily, all these libraries are pip-installable:
$ pip install numpy==1.25.0 $ pip install Pillow==9.4.0 $ pip install matplotlib==3.7.2 $ pip install pandas==2.0.3 $ pip install torch>=2.0.1 $ pip install torchvision>=0.15.2 $ pip install scipy==1.11.1 $ pip install imageio==2.31.1
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree . . ├── output │ ├── face_morphing.gif │ ├── image_attr_mod_results │ │ ├── image_attr_plot_Attractive.png │ │ ├── image_attr_plot_Blond_Hair.png │ │ ├── image_attr_plot_Eyeglasses.png │ │ ├── image_attr_plot_Male.png │ │ └── image_attr_plot_Smiling.png │ ├── model_weights │ │ ├── best_vae_celeba.pt │ │ └── vae_celeba.pt │ ├── training_progress │ │ ├── epoch11_test_recon.png │ │ ├── epoch1_test_recon.png │ │ ├── epoch21_test_recon.png │ │ ├── epoch31_test_recon.png │ │ ├── epoch41_test_recon.png │ │ └── epoch50_test_recon.png │ ├── vae_latent_distribution.png │ ├── vae_sample_normal_reconstruction.png │ └── vae_val_reconstruction.png ├── pyimagesearch │ ├── __init__.py │ ├── config.py │ ├── data_utils.py │ ├── model_utils.py │ └── network.py ├── test.py └── train.py 6 directories, 24 files
In the pyimagesearch directory, we have the following files:
config.py: This configuration file is for training the variational autoencoderdata_utils.py: This file contains data-related utilities like loading theCelebAdataset, running VAE on a random set of imagesmodel_utils.py: This script hosts the model utilities like loss function, a validation method for evaluating the VAE during the training phase, and most importantly, the post-training analysis functionsnetwork.py: Contains the VAE architecture implementation in PyTorch
In the core directory, we have the following:
train.py: This training script is for training the VAE on theCelebAdatasettest.py: This inference script is for evaluating the trained VAE on the test dataset and conducting post-training analysisoutput: This folder hosts the model weights, training reconstruction progress over each epoch, evaluation on the test set, and post-training analysis of the VAE
About the Dataset
In this tutorial, we employ the CelebA dataset for training our variational autoencoder model.
Overview
The CelebA dataset consists of over 200,000 vibrant celebrity face images, each meticulously annotated with diverse attributes such as eyeglasses, hats, smiles, and more. Each image in the dataset is a 218x178 pixel high-resolution color image, capturing the nuances of facial features and expressions. Figure 2 showcases a selection of these images, highlighting the variety of attributes. The dataset provides a rich playground for exploring advanced machine learning techniques, especially in the realm of generative models.

Class Distribution
The CelebA dataset is a treasure trove of facial data, encompassing over 202,599 celebrity images spanning 10,177 unique identities. Each image in this dataset is meticulously annotated with 40 binary attributes, capturing a wide range of facial features and expressions. These attributes provide a detailed characterization of each face, from the presence of eyeglasses and hats to specific facial expressions like smiles.
In addition to the attribute annotations, the dataset also provides 5 landmark locations for each image, aiding in tasks like facial part localization.
Given its vast diversity and rich annotations, CelebA is not just limited to face attribute recognition. It serves as a versatile resource for various computer vision tasks, including face recognition, detection, landmark localization, and even advanced applications like face editing and synthesis.
Data Preprocessing
For optimal model training, the CelebA images are subjected to several transformations. Initially, they’re randomly flipped horizontally for dataset augmentation. Then, a center crop is applied, focusing on a  pixel region to emphasize primary facial features. Following this, images are resized to
pixel region to emphasize primary facial features. Following this, images are resized to  and converted into PyTorch tensors. Both training and validation datasets undergo these transformations to ensure consistency.
and converted into PyTorch tensors. Both training and validation datasets undergo these transformations to ensure consistency.
Data Split
While the CelebA dataset provides a vast collection of celebrity images, it doesn’t come with a predefined training and validation split. We’ve taken the initiative to partition the dataset into training and validation sets for our experiments. Specifically:
- Validation Set Size: We reserve 10% of the total dataset for validation. This subset is instrumental in evaluating the model’s performance on unseen data during the training process and also for the post-training analysis.
- Training Set Size: The remaining 90% of the dataset is dedicated to training the model.
Configuring the Prerequisites
Before we start our implementation, let’s review our project’s configuration. For that, we will move on to the config.py script located in the pyimagesearch directory.
The config.py script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. It also defines the class labels dictionary mapping from an integer to a human-readable format.
# import the necessary packages
import torch
# set device to 'cuda' if CUDA is available, 'mps' if MPS is available,
# or 'cpu' otherwise for model training and testing
DEVICE = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
Line 2 imports the torch module to determine the available computational device (CUDA GPU, MPS, or CPU) for model training and inference.
From Lines 6-12, we set the DEVICE variable based on the available hardware. If CUDA (used for NVIDIA GPUs) is available, DEVICE is set to cuda. If CUDA isn’t available but MPS (Metal Performance Shaders, used for Apple devices) is available, DEVICE is set to “mps”. If neither CUDA nor MPS is available, DEVICE defaults to cpu.
# define model hyperparameters LR = 0.005 IMAGE_SIZE = 64 CHANNELS = 3 BATCH_SIZE = 64 EMBEDDING_DIM = 128 EPOCHS = 50 KLD_WEIGHT = 0.00025 # define the dataset path DATASET_PATH = "dataset/img_align_celeba/img_align_celeba" DATASET_ATTRS_PATH = "dataset/list_attr_celeba.csv" # parameters for morphing process NUM_FRAMES = 50 FPS = 5 # list of labels for image attribute modifier experiment LABELS = ["Eyeglasses", "Smiling", "Attractive", "Male", "Blond_Hair"]
Then, from Lines 15-21, we define various hyperparameters and settings for the model:
LR: Learning rate for the optimizer.IMAGE_SIZE: The size (height and width) of the input images.CHANNELS: Number of channels in the input image (1for grayscale,3for RGB).BATCH_SIZE: Number of samples processed before the model is updated.EMBEDDING_DIM: Dimensionality of the embedding space (for a latent space in a VAE model).EPOCHS: Total number of training epochs.KLD_WEIGHT: Determines the relative importance of the KL divergence term in the VAE loss function. By adjustingKLD_WEIGHT, one can control the balance between the reconstruction term and the regularization term (KLD).
On Lines 24 and 25, we define the dataset and its attributes path on which we would train the VAE model.
On Lines 28-32, several parameters for post-training experiments are defined. These include NUM_FRAMES and FPS for the morphing experiment, as well as the LABELS list for the image attribute modification experiment.
Defining the Data Utilities
In data utilities, we define a custom dataset class named CelebADataset for handling the CelebA dataset, which is a large-scale face attributes dataset. The class is built upon the Dataset class from the PyTorch library, allowing it to be used with PyTorch’s data-loading utilities.
# import the necessary packages import glob import os import matplotlib import numpy as np from PIL import Image
We start by importing the necessary packages, namely glob and Image, for loading the image into the disk and converting into RGB format.
class CelebADataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.all_images = list(glob.iglob(root_dir + "/*.jpg"))
def __len__(self):
return len(self.all_images)
def __getitem__(self, idx):
img_path = self.all_images[idx]
image = Image.open(img_path).convert("RGB")
if self.transform:
image = self.transform(image)
return image
Line 35 defines a new class CelebADataset that inherits from the Dataset class.
The __init__ method (from Lines 36-39) initializes the CelebADataset class:
- It’s invoked when a new instance of the
CelebADatasetclass is created. root_dirspecifies the directory containing the CelebA images.- An optional
transformparameter allows for image transformations, such as resizing or normalization. If not provided, it defaults toNone. self.all_imagescompiles a list of paths for all.jpgimages inroot_dir, utilizing theglob.iglob()function to retrieve these paths.
Then, the __len__ method is defined on Lines 41 and 42, which returns the total number of images in the dataset. It’s a required method for PyTorch datasets, allowing functions like len(dataset) to work.
From Lines 44-49, the __getitem__ method is defined to retrieve a specific image from the dataset given its index idx.
- It first gets the path of the image using the index.
- Then, it opens the image using the
Image.open()method from the PIL library and ensures the image is in RGB format. - If there’s a transformation specified in
self.transform, it’s applied to the image. - Finally, the transformed image is returned.
Defining the Model Utilities
In model utilities we define a custom loss function to compute the loss for a VAE, considering both the reconstruction error and the divergence of the latent variable distribution from a standard normal distribution.
# import the necessary packages
import matplotlib
import numpy as np
from PIL import Image
matplotlib.use("Agg")
import imageio
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
We start by importing the necessary packages from the PyTorch library on Lines 9 and 10. torch is used to compute the mean for kld_loss, and torch.nn.functional contains a set of functions that operate on tensors and is used to compute the mean-squared loss (reconstruction loss).
def loss_function(VAELossParams, kld_weight):
recons, input, mu, log_var = VAELossParams
recons_loss = F.mse_loss(recons, input)
kld_loss = torch.mean(
-0.5 * torch.sum(1 + log_var - mu**2 - log_var.exp(), dim=1), dim=0
)
loss = recons_loss + kld_weight * kld_loss
return {
"loss": loss,
"Reconstruction_Loss": recons_loss.detach(),
"KLD": -kld_loss.detach(),
}
The function loss_function is defined to compute the VAE loss. It takes two arguments:
VAELossParams: A tuple containing the reconstructed output (recons), the original input (input), the mean (mu), and the log variance (log_var) of the latent variables.kld_weight: A scalar that weighs the importance of the KL Divergence (KLD) term in the loss.
The reconstruction loss measures the difference between the reconstructed output (recons) and the original input (input). It uses the mean squared error (MSE) as the metric.
The KLD loss measures the divergence between the learned latent variable distribution and a standard normal distribution. The formula inside the torch.sum computes the KLD for each data point in the batch. The outer torch.mean then averages the KLD values over the entire batch.
Finally, the function returns a dictionary containing:
- The total VAE loss (
loss). - The reconstruction loss (
Reconstruction_Loss), detached from the computation graph to prevent gradient computations. - The negative KLD loss (
KLD), also detached. The negative sign is used to make the value positive, as the KLD is computed as a negative value in the formula.
Defining the Network
In this section, we will delve into the implementation of the Variational Autoencoder (VAE) architecture using PyTorch.
The beauty of VAEs lies in their training process. They are trained to not only minimize the difference between the original and the reconstructed data (reconstruction loss) but also to ensure that the latent space has certain desirable properties, typically ensured using the Kullback-Leibler divergence.
# import the necessary packages from typing import List import torch import torch.nn as nn from torch import Tensor
We begin by importing List from the typing module, which is a generic type used to define the data type of items within a list. Next, we import torch, torch.nn, and Tensor, crucial for constructing the VAE architecture.
# define a convolutional block for the encoder part of the vae
class ConvBlock(nn.Module):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(ConvBlock, self).__init__()
# sequential block consisting of a 2d convolution,
# batch normalization, and leaky relu activation
self.block = nn.Sequential(
nn.Conv2d(
in_channels, # number of input channels
out_channels=out_channels, # number of output channels
kernel_size=3, # size of the convolutional kernel
stride=2, # stride of the convolution
padding=1, # padding added to the input
),
nn.BatchNorm2d(out_channels), # normalize the activations of the layer
nn.LeakyReLU(), # apply leaky relu activation
)
def forward(self, x):
# pass the input through the sequential block
return self.block(x)
Here, we define a custom neural network module named ConvBlock, which represents a convolutional block tailored for the encoder part of a Variational Autoencoder (VAE).
The ConvBlock class is defined on Line 10, inheriting from nn.Module, which is the base class for all neural network modules in PyTorch.
The __init__ method on Line 11 initializes the ConvBlock class. It takes two arguments: in_channels (number of input channels) and out_channels (number of output channels).
The super() function is called to properly initialize the parent class (nn.Module) on Line 12.
A sequential block named self.block is defined, which will contain a series of layers that the input will pass through in sequence (Lines 15-25). The block consists of:
- 2D Convolution Layer (
nn.Conv2d): This layer applies a 2D convolution operation. The parameters are:in_channels: Number of input channels.out_channels: Number of output channels.kernel_size=3: Size of the convolutional kernel.stride=2: Stride of the convolution.padding=1: Padding added to maintain the spatial dimensions.
- Batch Normalization Layer (
nn.BatchNorm2d): This layer normalizes the activations of the convolutional layer, which can help improve training speed and model performance. - Leaky ReLU Activation (
nn.LeakyReLU): This is an activation function that allows a small gradient when the unit is not active, helping to address the dying ReLU problem.
The forward method defines the forward pass of the ConvBlock on Lines 27-29.
- It takes an input tensor
xand passes it through theself.blocksequential block. - The output of the block is then returned.
# define a transposed convolutional block for the decoder part of the vae
class ConvTBlock(nn.Module):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(ConvTBlock, self).__init__()
# sequential block consisting of a transposed 2d convolution,
# batch normalization, and leaky relu activation
self.block = nn.Sequential(
nn.ConvTranspose2d(
in_channels, # number of input channels
out_channels, # number of output channels
kernel_size=3, # size of the convolutional kernel
stride=2, # stride of the convolution
padding=1, # padding added to the input
output_padding=1, # additional padding added to the output
),
nn.BatchNorm2d(out_channels), # normalize the activations of the layer
nn.LeakyReLU(), # apply leaky relu activation
)
def forward(self, x):
return self.block(x) # pass the input through the sequential block
Next, we define a custom neural network module named ConvTBlock, which represents a transposed convolutional block designed for the decoder part of a Variational Autoencoder (VAE).
The ConvTBlock class is defined on Line 33, inheriting from nn.Module, which is the base class for all neural network modules in PyTorch.
On Line 34, the __init__ method initializes the ConvTBlock class. It takes two arguments: in_channels (number of input channels) and out_channels (number of output channels).
A sequential block named self.block is defined, which will contain a series of layers that the input will pass through in sequence (Lines 38-49). The block consists of:
- 2D Transposed Convolution Layer (
nn.ConvTranspose2d): This layer applies a transposed 2D convolution operation, which is often used for upsampling in decoder architectures. The parameters are:in_channels: Number of input channels.out_channels: Number of output channels.kernel_size=3: Size of the convolutional kernel.stride=2: Stride of the convolution.padding=1: Padding added to maintain the spatial dimensions.output_padding=1: Additional padding added to the output to control the spatial dimensions after the transposed convolution.
- Batch Normalization Layer (
nn.BatchNorm2d): This layer normalizes the activations of the transposed convolutional layer. - Leaky ReLU Activation (
nn.LeakyReLU): This is an activation function that allows a small gradient when the unit is not active, helping to address the dying ReLU problem.
On Lines 51 and 52, the forward function passes the input through the sequential block.
# define the main vae class
class CelebVAE(nn.Module):
def __init__(
self, in_channels: int, latent_dim: int, hidden_dims: List = None
) -> None:
super(CelebVAE, self).__init__()
self.latent_dim = latent_dim # dimensionality of the latent space
if hidden_dims is None:
hidden_dims = [32, 64, 128, 256, 512] # default hidden dimensions
# build the encoder using convolutional blocks
self.encoder = nn.Sequential(
*[
# create a convblock for each pair of input and output channels
ConvBlock(in_f, out_f)
for in_f, out_f in zip([in_channels] + hidden_dims[:-1], hidden_dims)
]
) # fully connected layer for the mean of the latent space
self.fc_mu = nn.Linear(hidden_dims[-1] * 4, latent_dim)
# fully connected layer for the variance of the latent space
self.fc_var = nn.Linear(hidden_dims[-1] * 4, latent_dim)
# build the decoder using transposed convolutional blocks
# fully connected layer to expand the latent space
self.decoder_input = nn.Linear(latent_dim, hidden_dims[-1] * 4)
hidden_dims.reverse() # reverse the hidden dimensions for the decoder
self.decoder = nn.Sequential(
*[
# create a convtblock for each pair of input and output channels
ConvTBlock(in_f, out_f)
for in_f, out_f in zip(hidden_dims[:-1], hidden_dims[1:])
]
)
# final layer to reconstruct the original input
self.final_layer = nn.Sequential(
nn.ConvTranspose2d(
hidden_dims[-1],
hidden_dims[-1],
kernel_size=3,
stride=2,
padding=1,
output_padding=1,
),
# normalize the activations of the layer
nn.BatchNorm2d(hidden_dims[-1]),
# apply leaky relu activation
nn.LeakyReLU(),
# final convolution to match the output channels
nn.Conv2d(hidden_dims[-1], out_channels=3, kernel_size=3, padding=1),
# apply tanh activation to scale the output
nn.Tanh(),
)
The CelebVAE class is defined on Line 56, inheriting from nn.Module, the base class for all neural network modules in PyTorch.
The __init__ method initializes the CelebVAE class on Lines 57-59. It takes three arguments:
in_channels: Number of input channels (e.g.,3for RGB images).latent_dim: Dimensionality of the latent space.hidden_dims: List of hidden dimensions for the encoder and decoder. If not provided, a default list is used.
The dimensionality of the latent space is stored in self.latent_dim on Line 62. If hidden_dims is not provided, a default list of dimensions is used (Lines 64 and 65).
The encoder is built using a sequence of ConvBlock layers from Lines 68-74. These convolutional blocks are created for each pair of input and output channels in the hidden_dims list.
Two fully connected layers are defined on Lines 75 and 77:
self.fc_mu: Computes the mean of the latent space.self.fc_var: Computes the variance of the latent space.
From Lines 81-89,
- The decoder starts with a fully connected layer (
self.decoder_input) that expands the latent space. - The hidden dimensions are reversed to build the decoder, which will upsample the data.
- The decoder is built using a sequence of
ConvTBlocklayers, which are transposed convolutional blocks.
The final layer of the VAE is defined to reconstruct the original input from Lines 92-109. It consists of:
- A transposed convolution layer
- Batch normalization
- Leaky ReLU activation
- A final convolution layer to match the number of output channels (
3for RGB images) - A tanh activation to scale the output values between
-1and1
In summary, the CelebVAE class provides a complete architecture for a VAE designed for image data. The VAE consists of an encoder that compresses the input into a latent space and a decoder that reconstructs the input from the latent space. The architecture is modular, allowing for easy adjustments and integration into larger systems. The CelebVAE class also has methods for encoding, decoding, and reparametrization which we will discuss next.
# encoding function to map the input to the latent space
def encode(self, input: Tensor) -> List[Tensor]:
# pass the input through the encoder
result = self.encoder(input)
# flatten the result for the fully connected layers
result = torch.flatten(result, start_dim=1)
# compute the mean of the latent space
mu = self.fc_mu(result)
# compute the log variance of the latent space
log_var = self.fc_var(result)
return [mu, log_var]
Now that the self.encoder is defined, the encode method encodes the data into a latent space. The method takes a tensor named input and returns a list of tensors on Line 112.
On Line 114, the input tensor is passed through an encoder (a series of layers) that transforms the input data into a different representation.
The output from the encoder is flattened on Line 116, starting from the first dimension (start_dim=1). This is often done to prepare the data for fully connected layers, which expect a flat input.
The flattened result is passed through a fully connected layer (fc_mu) to compute the mean (mu) of the latent space on Line 118. In the context of VAEs, the latent space is represented by a distribution, and this step computes the mean of that distribution.
Similarly, on Line 120, the flattened result is also passed through another fully connected layer (fc_var) to compute the log variance (log_var) of the latent space. The variance represents the spread or uncertainty of the distribution, and taking the logarithm of the variance can help with numerical stability and optimization.
Finally, the method returns a list containing the mean and log variance of the latent space on Line 121.
In summary, this encode method is part of the VAE’s architecture that maps input data to a latent space represented by a distribution with a mean (mu) and log variance (log_var). The latent space captures the essential features of the input data in a compressed form.
# decoding function to map the latent space to the reconstructed input
def decode(self, z: Tensor) -> Tensor:
# expand the latent space
result = self.decoder_input(z)
# reshape the result for the transposed convolutions
result = result.view(-1, 512, 2, 2)
# pass the result through the decoder
result = self.decoder(result)
# pass the result through the final layer
result = self.final_layer(result)
return result
After having defined the encode method, we define a decode method for decoding data from a latent space back to its original or reconstructed form. The method takes a tensor named z (which represents points in the latent space) and returns a tensor on Line 124.
On Line 126, the latent space tensor z is passed through a layer (or series of layers) named decoder_input. This step transforms the latent space representation to a form suitable for the subsequent decoding layers.
The output from the decoder_input is reshaped to have a specific shape on Line 128. The method view is used to reshape tensors in PyTorch. The -1 in the first dimension means that this dimension is inferred from the length of the tensor, ensuring that the total number of elements remains the same. The reshaped tensor has dimensions of [batch size, 512 channels, height of 2, width of 2]. This reshaping is typically done to prepare the data for transposed convolutional layers, which expect multi-dimensional input.
The reshaped tensor is then passed through a decoder on Line 130. The decoder’s purpose is to transform the data from the latent space representation back to its original or reconstructed form.
After the decoder, the result is passed through a final layer (or series of layers) named final_layer on Line 132. This step is often used to ensure the output has the desired shape or characteristics, such as applying a tanh activation function to ensure pixel values are between -1 and 1 for image data.
Finally, the method returns the reconstructed data on Line 133.
In summary, the decode method takes points from the latent space and maps them back to the original data space, producing a reconstruction of the original input. This is a crucial part of the autoencoder’s architecture, where the goal is to compress data into a latent space and then reconstruct it with minimal loss of information.
# reparameterization trick to sample from the latent space
def reparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor:
# compute the standard deviation from the log variance
std = torch.exp(0.5 * logvar)
# sample random noise
eps = torch.randn_like(std)
# compute the sample from the latent space
return eps * std + mu
Here, we define a method named reparameterize that belongs to a CelebVAE class. The method takes two tensors: mu (mean of the latent space) and logvar (log variance of the latent space), and returns a tensor on Line 136.
On Line 138, the log variance (logvar) is transformed to get the standard deviation (std). The transformation involves taking the exponential of half the log variance. This is because the variance is the square of the standard deviation, and by taking the exponential of half the log variance, we effectively compute the square root of the variance.
A random noise tensor (eps) is sampled from a standard normal distribution (mean = 0, standard deviation = 1) on Line 140. The shape of this noise tensor is the same as the std tensor, as indicated by the randn_like function.
The final step is to compute the sample from the latent space. This is done by multiplying the random noise (eps) with the standard deviation (std) and then adding the mean (mu) on Line 142, and the resultant is returned to the calling function. This ensures that the sample is drawn from a distribution with the given mean and variance.
# forward pass of the vae
def forward(self, input: Tensor) -> List[Tensor]:
# encode the input to the latent space
mu, log_var = self.encode(input)
# sample from the latent space
z = self.reparameterize(mu, log_var)
# decode the sample, and return the reconstruction
# along with the original input, mean, and log variance
return [self.decode(z), input, mu, log_var]
Finally, we define the forward method that takes a tensor named input and returns a list of tensors. It basically performs the forward pass of a Variational Autoencoder (VAE).
The input tensor is passed through the encode method on Line 147, which was previously explained. This method maps the input data to the latent space and returns the mean (mu) and log variance (log_var) of the latent space distribution.
Using the mean and log variance obtained from the encoding step, the reparameterize method is called to sample a point (z) from the latent space on Line 149. This method uses the reparameterization trick to make the sampling process differentiable, which is crucial for training the VAE using gradient descent.
Finally, in the forward method on Line 152, the following list is returned:
- The reconstruction of the original input, achieved by passing the point
z(sampled from the latent space) through thedecodemethod:self.decode(z). - The original input data (
input). - The mean of the latent space distribution (
mu). - The log variance of the latent space distribution (
log_var).
In summary, the forward method of the VAE takes input data, encodes it to a latent space, samples a point from this latent space using the reparameterization trick, and then decodes this point to produce a reconstruction of the original input. The method returns the reconstructed data along with the original input, mean, and log variance. This information is essential for computing the loss during training, which typically consists of a reconstruction loss and a regularization term based on the mean and log variance.
Training the Variational Autoencoder
In this section, the Variational Autoencoder (VAE) is trained on the CelebA dataset using PyTorch. The training process optimizes both the reconstruction of the original images and the properties of the latent space, leveraging the Kullback-Leibler divergence.
Essential steps include
- data preprocessing
- model initialization
- iterative training across epochs
The best model weights are saved based on validation loss, and periodic visualizations of reconstructed images are generated to monitor progress.
# import the necessary packages import os import torch import torch.optim as optim from pyimagesearch import config, network, data_utils, model_utils from torch.utils.data import DataLoader, random_split from torchvision import transforms
We start by importing the essential libraries and modules for training a VAE using PyTorch on Lines 1-8. It includes standard libraries like os and torch, the optimization method from torch.optim, and custom utilities from pyimagesearch. Additionally, we import data handling tools from torch.utils.data and image transformations from torchvision.transforms.
# create output directory
output_dir = "output"
os.makedirs("output", exist_ok=True)
# create the training_progress directory inside the output directory
training_progress_dir = os.path.join(output_dir, "training_progress")
os.makedirs(training_progress_dir, exist_ok=True)
# create the model_weights directory inside the output directory
# for storing autoencoder weights
model_weights_dir = os.path.join(output_dir, "model_weights")
os.makedirs(model_weights_dir, exist_ok=True)
# define model_weights path including best weights
MODEL_BEST_WEIGHTS_PATH = os.path.join(model_weights_dir, "best_vae_celeba.pt")
MODEL_WEIGHTS_PATH = os.path.join(model_weights_dir, "vae_celeba.pt")
The above code snippet is focused on setting up directories and paths for storing output, training progress, and VAE model weights.
On Lines 11 and 12, an output directory named “output” is defined. The os.makedirs function is used to create this directory. The exist_ok=True argument ensures that no error is raised if the directory already exists.
Inside the main “output” directory, another directory named “training_progress” is created on Lines 15 and 16. This directory is intended to store files related to the training progress of the model.
Finally, another directory named “model_weights” is created inside the main “output” directory on Lines 20 and 21. As the name suggests, this directory is intended to store the weights of the trained VAE model.
On Lines 24 and 25, two model paths are defined:
MODEL_BEST_WEIGHTS_PATH: This path points to where the best weights of the model (determined by validation loss) will be saved. The file is named “best_vae_celeba.pt”.MODEL_WEIGHTS_PATH: This path points to where the final weights of the model will be saved, named “vae_celeba.pt”.
In summary, this code sets up a structured directory system for storing various outputs related to training a model, specifically a Variational Autoencoder (VAE) on the CelebA dataset, as suggested by the filenames. This kind of structured setup is common in deep learning projects to organize outputs and model checkpoints systematically.
# Define the transformations
train_transforms = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(148),
transforms.Resize(config.IMAGE_SIZE),
transforms.ToTensor(),
]
)
val_transforms = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(148),
transforms.Resize(config.IMAGE_SIZE),
transforms.ToTensor(),
]
)
The training transformations train_transforms is defined on Lines 28-35:
transforms.RandomHorizontalFlip(): This transformation randomly flips the image horizontally with a default probability of0.5. It’s a common data augmentation technique to increase the diversity of the training data and make the model more robust.transforms.CenterCrop(148): This transformation crops the given image at the center to have a size of148x148pixels.transforms.Resize(config.IMAGE_SIZE): This transformation resizes the image to the size defined in theconfig.IMAGE_SIZE. The exact size is not provided in the snippet, but it’s fetched from a configuration module namedconfig.transforms.ToTensor(): This transformation converts the image (which might be in PIL format or a NumPy array) to a PyTorch tensor. It also scales the pixel values from the range[0, 255]to[0.0, 1.0].
Similar to the training transformations, the validation transformations are identical to the training transformations defined on Lines 37-44. The goal of the validation set is to evaluate the model’s performance on data that it hasn’t seen during training, so it’s typically kept as close to “real-world” data as possible.
In summary, this code sets up image transformations for preprocessing and augmenting training and validation datasets. These transformations help in ensuring that the data fed into the model is of consistent size and format, and they can also enhance the diversity of the training data.
# Instantiate the dataset
celeba_dataset = data_utils.CelebADataset(config.DATASET_PATH, transform=train_transforms)
# Define the size of the validation set
val_size = int(len(celeba_dataset) * 0.1) # 10% for validation
train_size = len(celeba_dataset) - val_size
train_dataset, val_dataset = random_split(celeba_dataset, [train_size, val_size])
# Define the data loaders
train_dataloader = DataLoader(
train_dataset,
batch_size=config.BATCH_SIZE,
shuffle=True,
num_workers=0,
pin_memory=True,
)
val_dataloader = DataLoader(
val_dataset,
batch_size=config.BATCH_SIZE,
shuffle=False,
num_workers=0,
pin_memory=True,
)
On Line 47, a dataset named celeba_dataset is instantiated using the CelebADataset class from the data_utils module. The dataset is set up to apply the previously defined train_transforms to the images. The path to the dataset is fetched from a configuration module named config.
The size of the validation set is set to be 10% of the total dataset. The remaining 90% is used for training on Lines 50 and 51.
The random_split function from PyTorch is used to randomly split the celeba_dataset into training and validation datasets based on the sizes defined in the previous step on Line 53.
A data loader named train_dataloader is defined for the training dataset from Lines 56-62. This data loader will fetch batches of images during training. The batch size is fetched from the config module. The shuffle=True argument ensures that the training data is shuffled at the beginning of each epoch, which is a common practice to ensure that the model doesn’t memorize the order of the data.
Similarly, a data loader named val_dataloader is defined for the validation dataset from Lines 63-69. The data is not shuffled (shuffle=False) since the order doesn’t matter during validation. The pin_memory=True argument is used to speed up data transfer between the CPU and GPU. When set to True, it will allocate the Tensors in CUDA pinned memory, which enables faster data transfer to the CUDA device.
In summary, this code sets up the dataset and data loaders for training and validation. The dataset is split into training and validation subsets, and data loaders are defined to fetch batches of data during the training and validation processes.
model = network.CelebVAE(config.CHANNELS, config.EMBEDDING_DIM) model = model.to(config.DEVICE) # instantiate optimizer, and scheduler optimizer = optim.Adam(model.parameters(), lr=config.LR) scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
On Line 71, a model named model is instantiated using the CelebVAE class from the network module. The model represents a Variational Autoencoder (VAE) tailored for the CelebA dataset, given the name. The model’s architecture requires two parameters: the number of channels in the input images (config.CHANNELS) and the dimension of the embedding or latent space (config.EMBEDDING_DIM). Both parameters are fetched from the config module.
The model is moved to the device specified in config.DEVICE on Line 72. This device can be either a CPU or a GPU (e.g., “cuda:0” for the first GPU). This step ensures that all computations related to the model are performed on the specified device, which is crucial for efficient training, especially when using GPUs.
An optimizer is instantiated to adjust the model’s weights during training on Line 75. The chosen optimizer is the Adam optimizer, a popular optimization algorithm in deep learning. The optimizer requires the model’s parameters (model.parameters()) and a learning rate (config.LR fetched from the config module).
A learning rate scheduler is set up to adjust the learning rate during training dynamically on Line 76. The chosen scheduler is ExponentialLR, which multiplies the learning rate by a factor (gamma) at each epoch. In this case, the learning rate is multiplied by 0.95 at the end of each epoch, leading to a gradual decrease in the learning rate as training progresses. This approach can help in stabilizing training and achieving better convergence.
In summary, this code sets up the model, optimizer, and learning rate scheduler for training. The model is instantiated and moved to the desired computation device, and the necessary tools for training (optimizer and scheduler) are set up.
# initialize the best validation loss as infinity
best_val_loss = float("inf")
print("Training Started!!")
# start training by looping over the number of epochs
for epoch in range(config.EPOCHS):
running_loss = 0.0
for i, x in enumerate(train_dataloader):
x = x.to(config.DEVICE)
optimizer.zero_grad()
predictions = model(x)
total_loss = model_utils.loss_function(predictions, config.KLD_WEIGHT)
# Backward pass
total_loss["loss"].backward()
# Optimizer variable updates
optimizer.step()
running_loss += total_loss["loss"].item()
This code snippet is focused on the training loop of a deep learning model using the PyTorch framework.
The best validation loss is initialized to positive infinity on Line 79. This is a common practice to ensure that any subsequent validation loss value will be lower than this initial value, allowing for the tracking of the best model during training.
On Line 83, the outer loop iterates over the number of epochs specified in the config module. Each epoch represents a full pass over the training dataset.
The inner loop on Line 85 iterates over batches of data from the train_dataloader. For each batch, x represents the input data.
The input data x is moved to the device specified in config.DEVICE on Line 86, which can be either a CPU or a GPU.
Before computing the gradients, it’s essential to set the existing gradients to zero (Line 87). This ensures that gradients from previous iterations don’t accumulate.
The input data x is passed through the model to obtain the predictions on Line 89.
The loss is computed using a custom loss function from the model_utils module on Line 91. This function computes a combination of reconstruction loss and a KL divergence term, given the mention of KLD_WEIGHT, which is common in Variational Autoencoders (VAEs).
The gradients of the loss with respect to the model’s parameters are computed using the backward pass on Line 94. The optimizer updates the model’s weights based on the computed gradients (Line 97).
Line 99 updates the running loss by adding the current batch’s loss. This can be used later to compute the average loss for the entire epoch.
In summary, this code sets up and runs the training loop for a deep learning model. The model is trained over a specified number of epochs, with each epoch consisting of multiple batches of data. The model’s weights are updated based on the computed loss and gradients.
# compute average loss for the epoch
train_loss = running_loss / len(train_dataloader)
# compute validation loss for the epoch
val_loss = model_utils.validate(model, val_dataloader, config.DEVICE)
# save best vae model weights based on validation loss
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(
{"vae-celeba": model.state_dict()},
MODEL_BEST_WEIGHTS_PATH,
)
torch.save(
{"vae-celeba": model.state_dict()},
MODEL_WEIGHTS_PATH,
)
print(
f"Epoch {epoch+1}/{config.EPOCHS}, Batch {i+1}/{len(train_dataloader)}, "
f"Total Loss: {total_loss['loss'].detach().item():.4f}, "
f"Reconstruction Loss: {total_loss['Reconstruction_Loss']:.4f}, "
f"KL Divergence Loss: {total_loss['KLD']:.4f}",
f"Val Loss: {val_loss:.4f}",
)
scheduler.step()
The average training loss for the epoch is computed by dividing the accumulated running_loss by the number of batches in the train_dataloader on Line 102.
Line 104 computes the validation loss for the epoch using a validate function from the model_utils module. This function evaluates the model on the validation dataset and returns the average validation loss.
Line 107 checks if the current epoch’s validation loss is lower than the previously recorded best validation loss (best_val_loss); the model’s weights are saved as the best weights. The model’s state dictionary (which contains the weights) is saved to the path specified by MODEL_BEST_WEIGHTS_PATH on Lines 108-112.
Regardless of the validation performance, the model’s weights for the current epoch are saved to the path specified by MODEL_WEIGHTS_PATH on Lines 114-117.
Lines 118-124 print the training and validation statistics for the current epoch. This includes the epoch number, batch number, total loss, reconstruction loss, KL divergence loss, and validation loss.
The learning rate scheduler is updated at the end of the epoch on Line 126. Depending on the scheduler’s configuration, this might adjust the learning rate for the next epoch.
In summary, this code snippet handles end-of-epoch operations during the training of a deep learning model. It computes average training and validation losses, saves model weights, prints training statistics, and updates the learning rate scheduler.
Diving Deep into VAE: Post-Training Discoveries
After successfully training our Variational Autoencoder (VAE) on the CelebA dataset, it’s crucial to evaluate its performance and understand its capabilities. This post-training analysis provides insights into how well the VAE has learned to encode and decode images, and how it manipulates the latent space to generate new, yet familiar, outputs.
These post-training analyses not only validate the effectiveness of our trained VAE but also highlight its potential applications in various domains, from image enhancement to generating entirely new content.
Let’s delve into the experiments conducted.
Reconstructions of Validation Data
One of the primary ways to assess a VAE’s performance is by examining how well it can reconstruct unseen data. By feeding images from the validation set into the VAE, we can compare the original images with their reconstructed counterparts. A successful reconstruction would mean that the VAE has effectively learned the underlying patterns and features of the dataset. Figure 3 showcases some of these reconstructed images from the validation set, demonstrating the VAE’s capability in preserving key details and nuances.

Reconstructions of Points Sampled from Normal Distribution Using the Decoder of Variational Autoencoder
A unique property of VAEs is their ability to generate new images by sampling points from a standard normal distribution and passing them through the decoder. Figure 4 showcases the VAE’s generative capabilities and the diversity of images it can produce.

Distribution Plot of the First 50 Latent Space Points
Visualizing the distribution of latent space points is crucial to understand how closely the VAE aligns with the assumption that these points follow a normal distribution. Figure 5 displays the distribution of the initial 50 points from the 128 embedding dimensions, clearly indicating their close alignment with a standard normal distribution. This observation is not just a testament to the VAE’s training effectiveness but also suggests several key insights:
- Meaningful Representations: The VAE has captured the underlying structure and patterns in the CelebA dataset. This means that it has identified and encoded various facial features and attributes in a structured manner in the latent space.
- Smooth Interpolations: The normally distributed latent space allows for smooth interpolations between different points. This capability means that transitioning between two facial images would result in a coherent morphing effect, with intermediate images appearing realistic.
- Potential for Data Generation: With a densely populated and normally distributed latent space, we can sample points and decode them to generate new, synthetic images of faces that, while not part of the original dataset, still appear realistic.
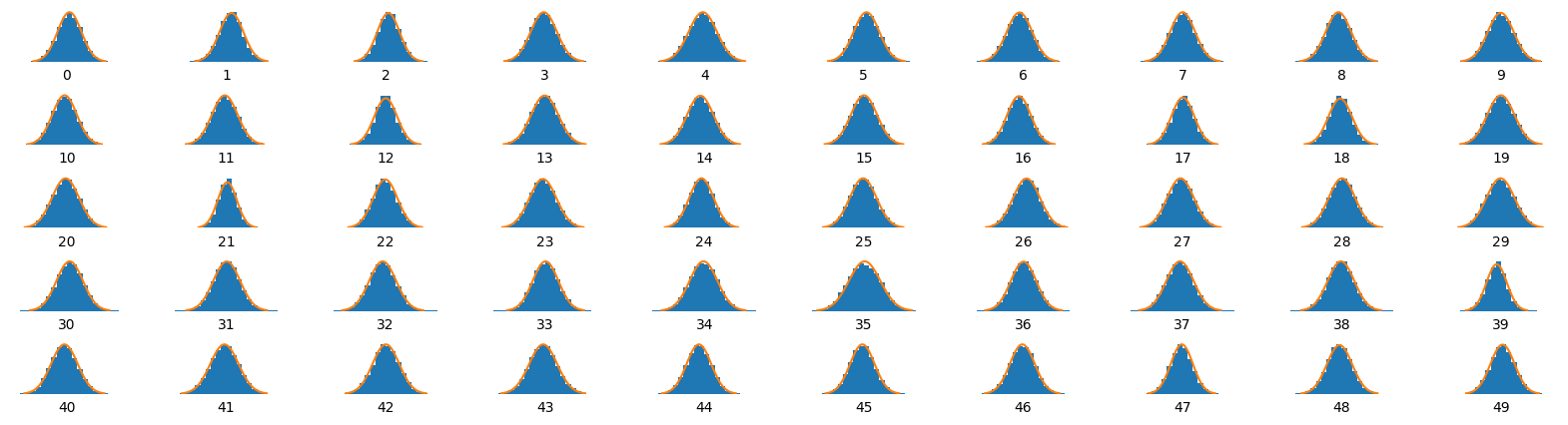
In essence, the distribution of these latent points validates that our VAE has effectively learned meaningful and structured representations of the data. The potential clusters or patterns observed might correspond to different facial features or attributes present in the CelebA dataset.
Latent Space Arithmetic for Visual Attribute Enhancement Using CelebA Labels
The latent space of a VAE isn’t just a jumble of numbers; it’s a rich space where arithmetic operations can lead to meaningful transformations in the generated images. By tweaking certain dimensions in the latent space, we can enhance or modify specific visual attributes in the output images, such as adding a smile or changing the hairstyle. This experiment demonstrates the power and flexibility of VAEs in image manipulation.
In Figure 6, by leveraging the latent space arithmetic, the VAE emphasizes the presence of eyeglasses on the generated face. This is achieved by adding the computed ‘eyeglasses’ vector to the latent representations, demonstrating the model’s precision in feature enhancement.

In Figure 7, the VAE introduces a distinct smile by manipulating the latent vectors with the ‘smiling’ attribute vector. This exemplifies the model’s capability to control and modify emotional expressions in the generated output.

Figure 8 showcases the VAE’s ability to modify gender-specific features. By adjusting the latent vectors with the ‘male’ attribute vector, a more pronounced male representation is generated, highlighting the model’s adaptability.

Figure 9 reveals the VAE’s adeptness in hair color manipulation. By fine-tuning the latent vectors with the ‘blonde’ attribute vector, the model transitions the generated face to exhibit blonde hair, emphasizing its precision in feature alteration.

In Figure 10, the VAE accentuates features commonly associated with attractiveness by manipulating latent vectors with the ‘attractive’ attribute vector. The result is a refined and aesthetically appealing image, showcasing the model’s expertise in nuanced feature enhancement and its understanding of complex attributes like attractiveness.

What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This tutorial delves deep into the intricacies of training a Variational Autoencoder (VAE), starting with a comprehensive look at the CelebA dataset. We discuss its overview, class distribution, and the essential preprocessing steps undertaken to ensure the data is prepared for training. The tutorial also sheds light on how the dataset is partitioned into training and validation sets.
As we transition into the technical aspects, we outline the configuration of prerequisites, followed by the establishment of data and model utilities. This sets the stage for defining the VAE network architecture, a pivotal component in our tutorial.
The heart of the tutorial is the training process of the VAE, where we elucidate the methodologies and nuances involved. Post-training, we embark on an analytical journey, assessing the VAE’s performance through various experiments. These range from reconstructing validation data to intriguing tasks like latent space arithmetic, leveraging the CelebA labels.
By the end of this tutorial, readers will have a holistic understanding of VAEs, from dataset nuances to the power of generative models in image reconstruction and manipulation.
Citation Information
Sharma, A. “Generating Faces Using Variational Autoencoders with PyTorch,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/j7t95
@incollection{Sharma_2023_VAEsPyTorch,
author = {Aditya Sharma},
title = {Generating Faces Using Variational Autoencoders with {PyTorch}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/j7t95},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.