Table of Contents
- DETR Breakdown Part 1: Introduction to DEtection TRansformers
- Why DETR and What’s So Special? 🤔
- What Is Object Detection? 😯
- So What’s New in DETR? 🎁
- Life Is Not a Bed of Roses 🌹: Past Challenges
- The Key Players 🤾: Main Components of DETR
- In a Nutshell 🔩
- The Problem Statement Reimagined 🧠
- Object Detection from the Old Days 🧓
- Set Prediction for Object Detection 🕵️
- Transformers and Parallel Decoding for Object Detection ⚡
- A Niche Solution 🥳
- Quiz Time! 🤓
- Summary
DETR Breakdown Part 1: Introduction to DEtection TRansformers
In this tutorial, we’ll learn about DETR, an end-to-end trainable deep learning architecture for object detection that utilizes a transformer block.

This lesson is the 1st of a 3-part series on DEtection TRansformers (DETR) Explained: A Comprehensive Guide to DETR in Computer Vision:
- DETR Breakdown Part 1: Introduction to DEtection TRansformers (this tutorial)
- DETR Breakdown Part 2: Methodologies and Algorithms
- DETR Breakdown Part 3: Architecture and Details
To learn about Detection Transformers, just keep reading.
DETR Breakdown Part 1: Introduction to DEtection TRansformers
In this blog post, we explore the revolution in object detection with DETR (the entire architecture is presented in the interactive Figure shown below), a unique approach employing Transformers and set prediction for parallel decoding that reimagines the problem statement, bringing an alternative to traditional methods.
We also uncover how Carion et al. (2020) present a niche solution that transcends the old days of object detection.
As we progress through the tutorial series, we aim to understand the components of the above interactive Figure. But, for now, let us focus on the topics at hand:
- why DETR
- where it came from
- what’s the big deal about it
Why DETR and What’s So Special? 🤔
In a world plagued by hand-crafted features and time-consuming processes, a new architecture emerged from the lab: DETR, the end-to-end object detector that could battle the almighty CNNs in its own field! By combining the strengths of two unlikely parents CNNs and transformers, DETR streamlined the training process, bidding farewell to laborious manual work.
With its unique superpower of attention mechanisms, DETR could identify objects and their relationships with remarkable accuracy.
As news of this extraordinary architecture spread, labs turned to newer possibilities inspired by components from DETR, leading to better image segmentation and object detection models. And so, the legacy of DETR, the end-to-end super object detector, was born.
Today we shall delve into its past, the factors that led to its birth, and how this miracle was even achieved in the first place.
What Is Object Detection? 😯
Alright, so object detection is basically guessing where objects are in an image by drawing boxes around them and figuring out what each object is called.
Previously object detection methods solved the problem of predicting object locations in an image by creating related sub-problems. These sub-problems involve estimating object properties using the image’s numerous predefined regions, points, or centers.
So What’s New in DETR? 🎁
The authors want us to see that object detection is pretty straightforward, but they also point out that people used to tackle it more roundaboutly.
The authors view object detection as a set prediction problem. A set prediction problem is when you try to guess a group of items based on some information. Think of it like trying to figure out which movies your friends might like based on the movies they’ve already watched.
Life Is Not a Bed of Roses 🌹: Past Challenges
Just a heads up: Thinking of object detection as a set prediction problem has some challenges. The biggest one is getting rid of duplicate predictions. Keep this in mind as you go through the rest of the tutorial. It’ll help you better understand why the authors made certain choices and decisions.
The Key Players 🤾: Main Components of DETR
Their paper primarily consists of two main components:
- A unique set-based global loss, which utilizes bipartite matching (an algorithm that facilitates set prediction) to encourage distinct set predictions.
- A transformer-based architecture, which includes both an encoder and a decoder.
In a Nutshell 🔩
By treating object detection as a set prediction problem, the need for manually designed components previously required in object detection tasks to incorporate prior knowledge is eliminated. This approach simplifies the process and streamlines the task.
The Problem Statement Reimagined 🧠
It is important to understand the contribution of this paper in the field of Computer Vision. To make sense of this, we first reimagine the problem statement by understanding object detection as it was in the old days. Next, we look at the two new methodologies that the authors proposed to solve End-to-End Object Detection. And finally, we look at the simple solution provided by the authors.
- Object Detection from the Old Days (problem statement)
- Set Prediction for Object Detection (methodology 1)
- Transformers and Parallel Decoding for Object Detection (methodology 2)
- A Simple Solution (solution)
Object Detection from the Old Days 🧓
Previously object detection methods made predictions relative to some initial guesses.
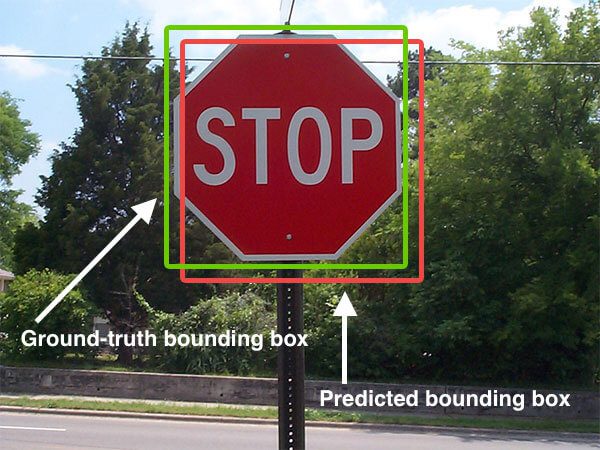
- Single-stage detectors: predict with respect to anchors or a grid of possible object centers (shown in Figure 2)

The Reimagined Problem Statement: The quality of the predictions relied a lot on how the initial guesses were made. So, instead of using handcrafted methods, we need a way to directly predict the set of detections.
Set Prediction for Object Detection 🕵️
In image processing applications, the basic set prediction task is multilabel classification. But first, let us quickly recap what multilabel and multiclass mean.
Multiclass: An image belonging to one class out of several possible classes (an example of Multiclass object detection is shown in Figure 3).

Multilabel: An image with multiple labels assigned to it simultaneously (an example of Multilabel object detection is shown in Figure 4).

The baseline approach for multilabel classification is called one-vs-rest. Here we train a binary classification model for each label and then try to predict which labels are present in the image and which are not. Of course, this technique works well only when the labels are mutually exclusive.
In the object detection pipeline, near-identical boxes are quite common. This fails the above-explained one-vs-rest approach. Instead, the authors use direct set prediction with a twist to achieve set prediction in such a scenario.
Note: In direct set prediction, we need a way to consider the relationships between all the predicted elements to avoid duplicates.
This is where the authors use the Hungarian algorithm (covered in upcoming tutorials of this series), which helps them match the ground truth (actual data) with their predictions smartly.
Transformers and Parallel Decoding for Object Detection ⚡
Attention mechanisms aggregate information from the entire input sequence. These are more suitable for long sequence representations.
To gain confidence and a better understanding of Transformers and their underlying principles, we recommend watching Video 1, which provides a comprehensive overview and intuitive explanation of Transformers.
Let’s pause and ponder on this for a second. What could go wrong if we input an image, and the object detection model predicts the objects (bounding boxes) in parallel?
While a model outputs all the objects in parallel, each prediction does not have the context of all the other predictions, unlike in autoregressive methods. This can create two problems:
- The parallel model outputs duplicates.
- The parallel model can output objects in a different order each time.
A Niche Solution 🥳
DETR addresses its challenges by combining bipartite matching loss and transformers. The matching loss function helps to pair each prediction with a unique ground truth object, so duplicates aren’t a concern.
Additionally, the bipartite matching loss doesn’t care about the order of predicted objects, meaning we don’t need to worry about the sequence in which predictions are made.
Quiz Time! 🤓
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Let’s take a moment to recap what we’ve learned in this tutorial so far:
- We explored the challenges and pain points of object detection before the advent of DETR.
- We briefly introduced DETR’s innovative features and main components, including Set Prediction Loss and the Transformer-based architecture.
- We reformulated the problem statement to better align with DETR’s approach.
- We familiarized ourselves with the two key components of DETR and how they address the problem statement.
In the next two tutorials of this series, we’ll delve into the tools, methodologies, and architecture of DETR in greater detail, providing a more comprehensive understanding of this groundbreaking approach.
However, valuable research is about more than just reading papers and admiring the brilliance of their authors. It’s also about asking ourselves what we would do in their position and how we would design an architecture to tackle these challenges if DETR didn’t exist.
Stay tuned for the upcoming parts of this series, and be sure to share your thoughts and learnings from DETR and what you’re looking forward to. Connect with us on Twitter by tagging @pyimagesearch.
Citation Information
A. R. Gosthipaty and R. Raha. “DETR Breakdown Part 1: Introduction to DEtection TRansformers,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and A. Thanki, eds., 2023, https://pyimg.co/fhm45
@incollection{ARG-RR_2023_DETR-breakdown-part1,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {{DETR} Breakdown Part 1: Introduction to DEtection TRansformers},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/fhm45},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.