
Table of Contents
Face Recognition with Siamese Networks, Keras, and TensorFlow
In this tutorial, you will learn about Siamese Networks and how they can be used to develop facial recognition systems. We will discuss the different types of facial recognition approaches and take an in-depth dive into the conceptual details of Siamese networks, which make them an integral part of robust facial recognition applications.

Specifically, we will discuss the following in detail
- The face recognition pipeline and various types of facial recognition approaches
- Difference between face identification and verification
- Metric Learning and Contrastive Losses
This lesson is the 1st in a 5-part series on Siamese Networks and their application in face recognition:
- Face Recognition with Siamese Networks, Keras, and TensorFlow (this tutorial)
- Building a Dataset for Triplet Loss with Keras and TensorFlow
- Triplet Loss with Keras and TensorFlow
- Training and Making Predictions with Siamese Networks and Triplet Loss
- Evaluating Siamese Network Accuracy (F1-Score, Precision, and Recall) with Keras and TensorFlow
In the first part (this tutorial), we will aim to develop a holistic understanding of the different face recognition approaches and discuss the concepts behind contrastive losses, which are used to train Siamese networks.
In the second part, we will dive into the code for building end-to-end facial recognition systems using Siamese networks in Keras and TensorFlow. We will start by loading the Labeled faces in the wild data and prepare for our face recognition application.
Next, in the third part, we will understand the concept and mathematical formulation of triplet loss and write our own loss function in Keras and TensorFlow.
Finally, in the fourth and fifth parts, we will discuss how we can make inference with our end-to-end face recognition system to identify new faces in real-time. We will also discuss the various evaluation metrics to quantify the performance of our face recognition application in the final part of this series.
To learn how to develop Face Recognition applications using Siamese Networks, just keep reading.
Face Recognition with Siamese Networks, Keras, and TensorFlow
Deep learning models tend to develop a bias toward the data distribution on which they have been trained. This refers to the dataset bias problem where deep models overfit to the distribution (e.g., pose, background, color, texture, lighting condition) of training images and are unable to generalize to novel views or instances of the same objects at test time. One naive solution to this problem is to collect and annotate data in all possible backgrounds or views of the depiction of objects. However, this process is infeasible or tedious, leading to high annotation costs.
Thus, practical applications demand the development of models that are robust to nuisances and can generalize to novel unseen views or depictions of an object. For example, to compare if two images belong to the same object category, there is a need to
- develop deep models that are invariant to factors like pose, background, color, texture
- focus on the underlying properties that constitute an object category
One such successful effort toward developing robust deep models was the inception of Siamese networks. In previous tutorials, we have discussed an overview of the intuition and mechanism underlying these networks. In this tutorial, we will look at developing a Siamese network-based facial recognition system.
Face Recognition
Face recognition is an important computer vision task that allows us to identify and verify a person’s identity. It is widely used in the industry for applications such as developing attendance systems, healthcare, security verification, etc.
In previous tutorials, we discussed an overview of the face recognition task and various traditional and modern methods used to build effective face recognition systems.
An important aspect of any effective facial recognition system is its invariance to different views or ways of depicting the same person. For example, a face recognition-based employee attendance system should focus on generalizable features that make up a person’s identity and be robust changes in pose, appearance (e.g., beard, hairstyle, etc.), or unseen views of a given person. This is important since it is infeasible to train the system on all possible variations in the looks of every employee.
Recent advances in face recognition have thus used contrastive losses to train Siamese network-based architectures for building robust face recognition models.
Face Recognition: Identification and Verification
Figure 1 shows a typical face recognition systems pipeline. As we can see, the first stage is the detection stage, where the face is distinguished from the background. This stage may also include an alignment operation that readjusts the pose of the face.
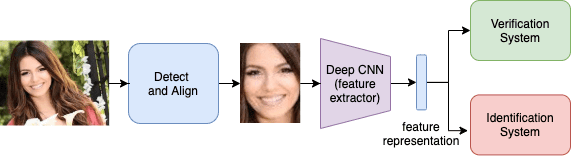
Next, the detected face is cropped and passed to the deep feature extractor. The feature extractor outputs a feature vector for the face, as shown. The deep network is trained such that the output feature representation captures discriminative facial features and is robust to nuances (e.g., lighting, color, texture, beards, etc.).
Finally, the learned feature representation is used to identify or verify the person’s identity.
Next, let us understand in detail the difference between Face Identification and Face Verification tasks.
Face identification refers to the task of identifying a person’s identity and entails assigning a person’s identity to a given input image.
Figure 2 shows a basic pipeline for performing face identification. The identification pipeline takes as input an image and outputs a probability distribution over the possible person identities.
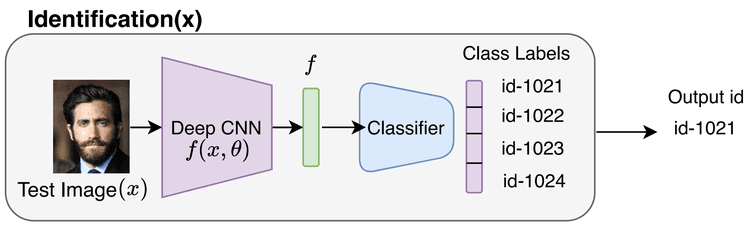
First, the input image is passed through a deep feature extractor to get a feature representation  , as shown in Figure 2. Next, the feature is passed through a classifier network that assigns a person’s identity or id to the given input image. Note that this entails a simple
, as shown in Figure 2. Next, the feature is passed through a classifier network that assigns a person’s identity or id to the given input image. Note that this entails a simple  way multi-class classification problem for a database with personnel (here,
way multi-class classification problem for a database with personnel (here,  persons or classes).
persons or classes).
Since the identification pipeline is a simple multi-class classification, it is trained with the usual softmax and cross entropy loss.
On the other hand, the verification task entails verifying whether two images belong to the same identity.
Figure 3 shows a basic pipeline for performing face verification. The input to the pipeline is the face image  and the face id to be verified, and the output is a binary decision of whether the image belongs to the person with the face id.
and the face id to be verified, and the output is a binary decision of whether the image belongs to the person with the face id.
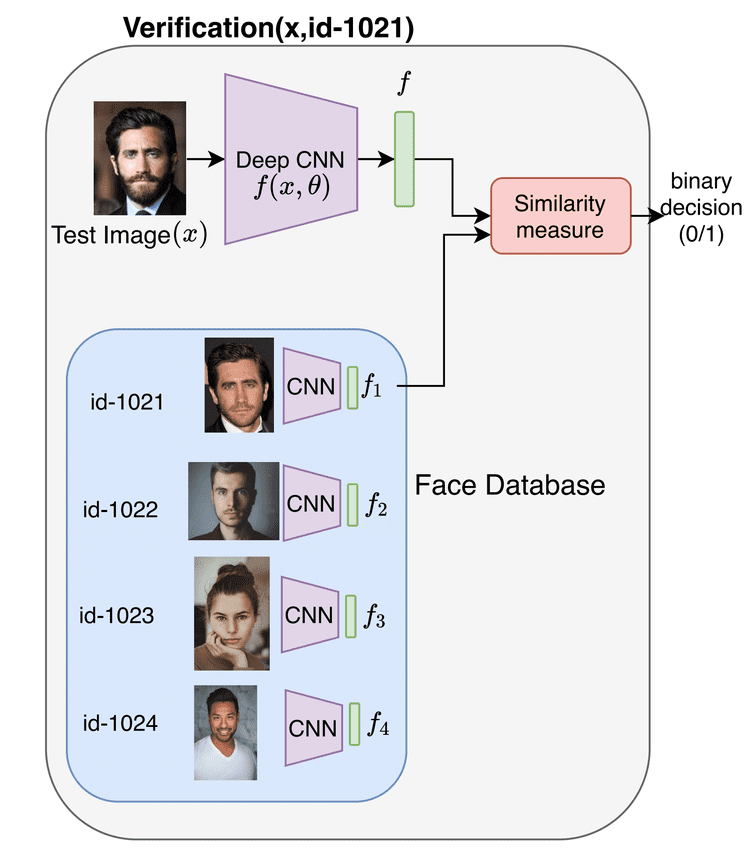
In case of verification, we pre-extract and store the feature representation for all face images in our database, as shown. Given a new image and a Face ID (say id-1021, as shown in Figure 3, we compute the feature representation of the image and compare it with the feature representation of Face ID-1021. The comparison is based on a similarity metric that we will discuss in detail later in the post. Finally, based on a threshold, we can find if the given input image belongs to a particular person in our database.
Identification via Verification
As discussed earlier in the post, identification requires us to train a way classifier to assign the given input face image a particular identity out of the personnel in our database. However, this type of identification system is not scalable if the number of people in our database increases.
For example, if a new person is added to the database, we will have to re-train the identification system built for classes on the new  classes from scratch. This is because previously, the classifier had neurons, and now we need a classifier with neurons. This inhibits the efficiency and scalability of the system, as every time a new face is added, the entire training procedure has to be repeated.
classes from scratch. This is because previously, the classifier had neurons, and now we need a classifier with neurons. This inhibits the efficiency and scalability of the system, as every time a new face is added, the entire training procedure has to be repeated.
Thus, a more efficient and effective way of implementing identification is by using the similarity-based comparison approach in verification.
Figure 4 shows how identification can be implemented using verification techniques. Given an input image , we can run our verification algorithm times for each of the Face IDs in our database. We can find the identity of the given face as the Face ID for which the binary output of the verification algorithm is true (i.e., the match for the input image is found).
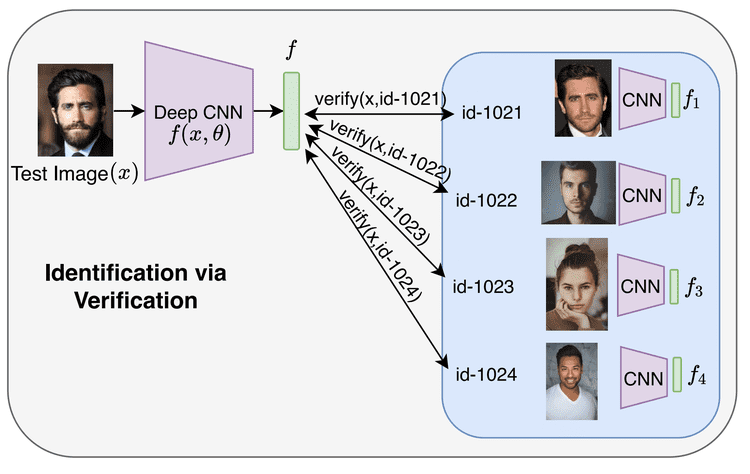
The benefit of using verification for identification is that if we add a new face to our database of faces, we just need to run the verification algorithm times for identification without the need to re-train the network.
Thus we observe that the classifier-based identification approach inhibits scalability due to the fixed number of neurons in the final layer. However, the similarity-based comparison approach used in verification is more efficient and scalable when new faces are added to the face database.
Metric Learning: Contrastive Losses
As discussed in the previous section, the similarity-based comparison approach of face recognition allows us to build more efficient and scalable systems than the classification-based approach.
Thus, in order to build effective face recognition systems, we need to develop training strategies that can enable us to build an embedding space where similar face images or face images of a given person are clustered together and face images of different people are farther apart.
The most common way to implement this for neural networks is by using deep metric learning.
In simple words, metric learning is a paradigm where our network is trained in such a way that representations of similar images are close to each other in an embedding space and images of different objects are farther apart. The idea of “similarity” here is defined based on a specific distance metric in the embedding space, which quantifies semantic similarity and whether the images belong to the same or different object or person.
Contrastive Losses
Contrastive losses are a group of loss functions that allow us to learn an embedding space where semantically similar inputs or images are embedded closer to each other when compared to dissimilar inputs. These losses are often used to train neural networks to learn a distance measure that can more effectively quantify the similarity between input images than predefined distance measures (e.g., euclidean distance, absolute distance, etc.).
There are different formulations of contrastive losses (e.g., ranking loss, pairwise contrastive loss, triplet loss, quadruplet loss, etc.). However, all these variants share the same basic idea and properties. Let us discuss this in detail with the help of an example.
Figure 5 displays a general setup showing how contrastive losses are used to learn a feature representation.
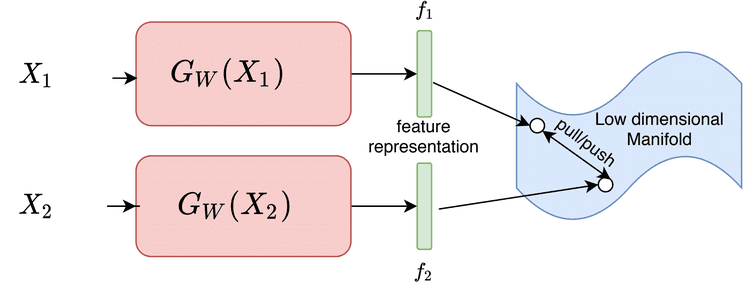
Our aim is to learn a mapping  from input space
from input space  to feature space . Here, the function is parameterized with weights
to feature space . Here, the function is parameterized with weights  , which are shared between the two branches. This can be interpreted as applying a complex transformation on the input space , which would project the inputs to feature space .
, which are shared between the two branches. This can be interpreted as applying a complex transformation on the input space , which would project the inputs to feature space .
The objective is to learn the parameters such that the high dimensional inputs  and
and  are mapped onto a low dimension manifold (or embedding space) . Their corresponding feature representations
are mapped onto a low dimension manifold (or embedding space) . Their corresponding feature representations  and
and  in the embedding space should be close to each other if the inputs and are similar. Otherwise, they should be farther apart.
in the embedding space should be close to each other if the inputs and are similar. Otherwise, they should be farther apart.
Mathematically, we want to learn the parameters such that the distance between the features ") and
and ") , that is,
, that is,
 = {||G_W (X_1) - G_W (X_2)||}_{2},")
approximates the similarity between the inputs and .
This objective can be achieved using a contrastive loss function which will
- pull the points in the feature space (i.e.,
 and
and  ) closer together if the input images belong to the same class or person
) closer together if the input images belong to the same class or person - push them further apart if they belong to different classes or persons
Let us consider the example of the simplest form of contrastive loss (i.e., pairwise contrastive loss) to understand this better.
![L_\text{contrastive}(W,Y,X_{1},X_{2}) = (1-Y)/2(D_{W})^2+Y/2[\max(0,m-D_{W}^2)]](https://b2633864.smushcdn.com/2633864/wp-content/latex/cc1/cc1bf9f8a141e8c4c0d89786076007aa-ffffff-000000-0.png?size=480x19&lossy=2&strip=1&webp=1 "L_\text{contrastive}(W,Y,X_{1},X_{2}) = (1-Y)/2(D_{W})^2+Y/2[\max(0,m-D_{W}^2)]")
where  is a margin.
is a margin.
The equation above shows the mathematical formulation of the pairwise contrastive loss. Here, denotes the parameters of our mapping function and  is a binary identifier equal to 0 if and belong to the same class or person and 1, otherwise.
is a binary identifier equal to 0 if and belong to the same class or person and 1, otherwise.
For the case when  , that is, when and belong to the same class or person, the loss reduces to
, that is, when and belong to the same class or person, the loss reduces to
 = 1/2(D_{W})^2")
Minimizing this expression will minimize  , which is the distance between the representations and (i.e., it will pull the features close to each other).
, which is the distance between the representations and (i.e., it will pull the features close to each other).
On the other hand, in the case when  , that is, when and belong to a different class or person, the loss reduces to
, that is, when and belong to a different class or person, the loss reduces to
![L_\text{contrastive}(W,X_{1},X_{2}) = 1/2[\max(0,m-D_{W}^2)]](https://b2633864.smushcdn.com/2633864/wp-content/latex/09f/09fb5323a953391560f53bb4f10aa23d-ffffff-000000-0.png?size=323x19&lossy=2&strip=1&webp=1 "L_\text{contrastive}(W,X_{1},X_{2}) = 1/2[\max(0,m-D_{W}^2)]")
Notice that the minimum value of this expression (which is 0) occurs when  , that is
, that is  . This implies minimizing this loss to ensure that the features and are at least apart by a distance of
. This implies minimizing this loss to ensure that the features and are at least apart by a distance of  in the feature space.
in the feature space.
Thus, the loss formulation ensures that similar points are close together in the features space and dissimilar points are separated at least by a distance of in the feature space.
Notice that the important principles that allow us to learn such a system and should be satisfied by any contrastive loss formulation are
- Semantically similar points in input space should be mapped close to each other on the low-dimension manifold
- The learned distance metric should be able to map unseen or new inputs
- The mapping learned should be invariant to complex transformations
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we discussed the concepts of facial recognition and gained an in-depth understanding of a typical face recognition pipeline. Specifically, we discussed the differences between face identification and verification and how the similarity-based comparison approach used in verification allows us to build efficient and scalable face recognition systems.
Next, we tried to understand the intuition behind metric learning and Siamese networks, which allow us to build robust similarity-based face recognition applications. Finally, we discussed the setup and mathematical formulation of contrastive loss functions, which are pivotal in training similarity-based Siamese networks.
Credits
This post is inspired by the amazing National Programme on Technology Enhanced Learning (NPTEL) Deep Learning for Computer Vision course, which the author contributed to while working at IIT Hyderabad.
Citation Information
Chandhok, S. “Face Recognition with Siamese Networks, Keras, and TensorFlow,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2023, https://pyimg.co/odny2
@incollection{Chandhok_2023_Face_recognition,
author = {Shivam Chandhok},
title = {Face Recognition with {Siamese Networks, Keras, and TensorFlow}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2023},
note = {https://pyimg.co/odny2},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.