
Table of Contents
- Attending to Channels Using Keras and TensorFlow
- Squeeze-and-Excitation Networks
- Configuring Your Development Environment
- Having Problems Configuring Your Development Environment?
- Project Structure
- Configuring the Prerequisites
- Preprocessing the CIFAR-10 Dataset
- Defining Our Training Model Architecture
- Training the Squeeze-and-Excitation Network
- Summary
Attending to Channels Using Keras and TensorFlow
Using Convolutional Neural Networks (CNNs), we can make our model figure out both spatial and channel-wise features from images. However, the spatial features were focused on how to figure out the hierarchical patterns.
In this tutorial, you will learn about Attending to Channels Using Keras and TensorFlow, a novel research idea where your model focuses on the channel-wise representation of information to better process and understand data.
To learn how to implement Channel Attention, just keep reading.
Attending to Channels Using Keras and TensorFlow
In 2017, Hu et al. released the paper titled Squeeze-and-Excitation Networks. Their approach was based on the notion that somehow focusing on the channel-wise feature representation and the spatial features will yield better results.
The idea was a novel architecture that adaptively assigns a weighted value to channel-wise features, essentially modeling interdependencies between the channels.
This proposed architecture was called the Squeeze-and-Excitation (SE) network. The authors successfully reached the goal of utilizing the added power of channel feature recalibration to help the network focus more on essential features while simultaneously suppressing less important ones.
Squeeze-and-Excitation Networks
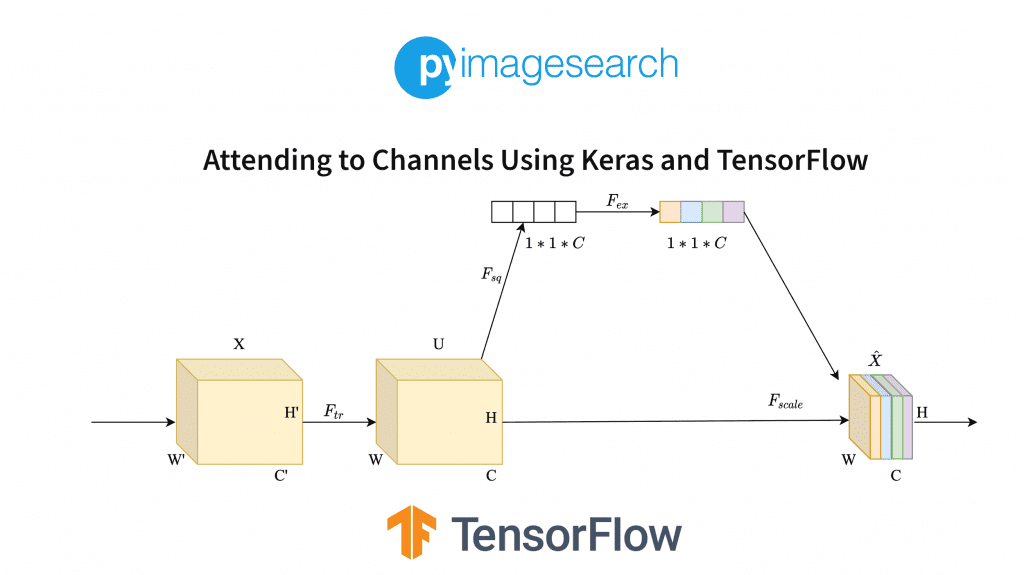
The SE network block can be an attachable module to any standard convolution neural network. The complete architecture of the network can be seen in Figure 1.
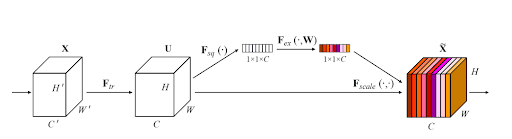
Let’s go over the complete architecture once before moving on to the code.
First, we have an input data  , of dimensions
, of dimensions  . is passed through a transformation (consider it to be a convolution operation)
. is passed through a transformation (consider it to be a convolution operation)  .
.
Now we have  feature map of dimensions
feature map of dimensions  . We know that another normal convolution operation will give us channels that will have some spatial information or the other.
. We know that another normal convolution operation will give us channels that will have some spatial information or the other.
But what if we take a different route? We use the operation  to squeeze out our input feature map . Now we have a representation of the shape
to squeeze out our input feature map . Now we have a representation of the shape  . This is considered a global representation of the channels.
. This is considered a global representation of the channels.
Now we will apply the “excite” operation. We will simply create a small dense network with a sigmoid activation function. This ensures that we are not using a simple one-hot encoding of this representation.
One-hot encoding defeats the purpose of achieving emphasis on multiple channels, not just one. We can get a general idea of the dense network from Figure 2.

Through the excitation section of this block, we aim to create a little network void of linearity. You can see how the shapes of the layers change as we progress through the network.
The first dense layer decreases the filters using a ratio  . This reduces the computational complexity while the network’s intention of a non-linear, sigmoidal nature is maintained.
. This reduces the computational complexity while the network’s intention of a non-linear, sigmoidal nature is maintained.
The final sigmoid layer of your SE block outputs a channel-wise relation, which you apply to your feature map . Now you have achieved a convolution block output where the importance of channels is also specified! (Check Figure 1 for the colored output at the end. The color scheme represents channel-wise importance.)
Configuring Your Development Environment
To follow this guide, you need to have the OpenCV library installed on your system.
Luckily, OpenCV is pip-installable:
$ pip install opencv-contrib-python $ pip install tensorflow
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes.
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
!tree . . ├── output.txt ├── pyimagesearch │ ├── config.py │ ├── data.py │ ├── __init__.py │ └── model.py ├── README.md └── train.py 1 directory, 7 files
First, let’s check the pyimagesearch directory:
config.py: Contains an end-to-end configuration pipeline of the complete project.data.py: Contains utility functions to process the data.model.py: Contains the model architecture to be used for our project.__init__.py: Creates the directory within a python directory for easier package calling and usage.
In the core directory, we have :
output.txt: A text file containing the outputs of our project.train.py: Contains the training procedure of our project.
Configuring the Prerequisites
First, we will review the config.py script located in our code’s pyimagesearch directory. This script contains several defined parameters and hyperparameters to be used throughout the project pipeline.
# define the number of convolution layer filters and dense layer units CONV_FILTER = 64 DENSE_UNITS = 4096 # define the input shape of the dataset INPUT_SHAPE = (32, 32, 3) # define the block hyperparameters for the VGG models BLOCKS = [ (1, 64), (2, 128), (2, 256) ] # number of classes in the CIFAR-10 dataset NUMBER_CLASSES = 10 # the ratio for the squeeze-and-excitation layer RATIO = 16 # define the model compilation hyperparameters OPTIMIZER = "adam" LOSS = "sparse_categorical_crossentropy" METRICS = ["acc"] # define the number of training epochs and the batch size EPOCHS = 100 BATCH_SIZE = 32
On Lines 2 and 3, we have defined the number of convolution filters and dense nodes to be used later while defining our model.
On Line 6, the input shape of our image dataset is defined.
The block hyperparameters for the VGG model are defined on Lines 9-13. It is in the tuple format containing the number of layers and the number of filters for the layer. This is followed by specifying the number of classes in the dataset (Line 16).
The ratio required for the excitation block has been defined on Line 19. Then, on Lines 22-24, the model specifications like optimizer, loss, and metrics are specified.
Our final configuration variables are epochs and batch size (Lines 27 and 28).
Preprocessing the CIFAR-10 Dataset
For our project today, we will be using the CIFAR-10 dataset to train our model. The dataset will provide us with 60000 instances of 32×32×3 images, each pertaining to one of 10 classes.
Before plugging it into our project, we will perform some preprocessing to make the data better suited for training. For that, let’s move into the data.py script in the pyimagesearch directory.
# import the necessary packages from tensorflow.keras.datasets import cifar10 import numpy as np def standardization(xTrain, xVal, xTest): # extract the mean and standard deviation from the train dataset mean = np.mean(xTrain) std = np.std(xTrain) # standardize the training, validation, and the testing dataset xTrain = ((xTrain - mean) / std).astype(np.float32) xVal = ((xVal - mean) / std).astype(np.float32) xTest = ((xTest - mean) / std).astype(np.float32) # return the standardized training, validation and the testing # dataset return (xTrain, xVal, xTest)
We have used tensorflow to directly load the cifar10 dataset into our project (Line 2).
The first preprocessing function we will be using is standardization (Line 5). It uses training images, validation images, and testing images as its arguments.
We grab the mean and standard deviation of the training set on Lines 7 and 8. We will be using these values to alter all our splits. On Lines 11-13, we normalize the training set, validation set, and test set according to the training set’s mean and standard deviation values.
You might think that why are we altering the pixel values of our images knowingly? This is so that we can adjust the distribution of our complete dataset into a more refined curve. This helps our model understand the data much better and make predictions more accurately.
The only downside to this is that we also have to alter our inference images this way before feeding them to our model, or we will most likely get a wrong prediction for them.
def get_cifar10_data(): # get the CIFAR-10 data (xTrain, yTrain), (xTest, yTest) = cifar10.load_data() # split the training data into train and val sets trainSize = int(0.9 * len(xTrain)) ((xTrain, yTrain), (xVal, yVal)) = ( (xTrain[:trainSize], yTrain[:trainSize]), (xTrain[trainSize:], yTrain[trainSize:])) (xTrain, xVal, xTest) = standardization(xTrain, xVal, xTest) # return the train, val, and test datasets return ((xTrain, yTrain), (xVal, yVal), (xTest, yTest))
Our next function is get_cifar10_data on Line 19. We use tensorflow to load the cifar10 dataset and unpack it into training and test sets.
Next, on Lines 24-27, we use indexing to split the training set into two parts: the training and validation sets. Before returning the 3 splits, we use the standardization function previously created to preprocess the dataset (Lines 28-31).
Defining Our Training Model Architecture
With our data pipeline all set to work, the next thing on our checklist is the model architecture. For that, we will be moving to the model.py script located in the pyimagesearch directory.
The model architecture is heavily inspired by the Idiomatic Programmer’s model zoo.
# import the necessary packages from tensorflow.keras.layers import GlobalAveragePooling2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Multiply from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import Dense from tensorflow.keras.layers import ReLU from tensorflow.keras import Input from tensorflow.keras import Model from tensorflow import keras class VGG: def __init__(self, inputShape, ratio, blocks, numClasses, denseUnits, convFilters, isSqueezeExcite, optimizer, loss, metrics): # initialize the input shape, the squeeze excitation ratio, # the blocks for the VGG architecture, and the number of # classes for the classifier self.inputShape = inputShape self.ratio = ratio self.blocks = blocks self.numClasses = numClasses # initialize the dense layer units and conv filters self.denseUnits = denseUnits self.convFilters = convFilters # flag that decides whether to add the squeeze excitation # layer to the network self.isSqueezeExcite = isSqueezeExcite # initialize the compilation parameters self.optimizer = optimizer self.loss = loss self.metrics = metrics
To make things simpler, we have created a class template for our model architecture on Line 13, naming it VGG.
The first function we have is __init__, which takes in the following arguments (Lines 14-36).
inputShape: Determines the input data shape to feed our model.ratio: Determines the ratio during theexcitationmodule for dimensional reduction.blocks: Specifies the number of layer blocks we want.numClasses: Specifies the number of output classes we require.denseUnits: Specifies the number of dense nodes.convFilters: Specifies the number of convolution filters of aconvlayer.isSqueezeExcite: A check to see if a block is a SE block.optimizer: Defines the optimizer to be used for the model.loss: Defines the loss to be used for the model.metrics: Defines the metrics to be considered for model training.
def stem(self, inputs): # pass the input through a CONV => ReLU layer block x = Conv2D(filters=self.convFilters, kernel_size=(3, 3), strides=(1, 1), padding="same", activation="relu")(inputs) # return the processed inputs return x def learner(self, x): # build the learner by stacking blocks of convolutional layers for numLayers, numFilters in self.blocks: x = self.group(x, numLayers, numFilters) # return the processed inputs return x
Next, we have foundational functions. The first one is stem (Line 38), which takes in a layer input as its argument. Then, inside the function, it passes the layer input through a convolution layer and returns the outputs (Lines 40-44).
The following function on Line 46 is learner. It takes a layer input as its argument. The purpose of this function is to stack blocks of layers.
We have previously defined blocks as a collection of tuples containing layers and filters for the layers together. We iterate over those on Line 48. On Line 49, a function called group is referenced, which is defined after this.
def group(self, x, numLayers, numFilters): # iterate over the number of layers and build a block with # convolutional layers for _ in range(numLayers): x = Conv2D(filters=numFilters, kernel_size=(3, 3), strides=(1, 1), padding="same", activation="relu")(x) # max pool the output of the convolutional block, this is done # to reduce the spatial dimension of the output x = MaxPooling2D(2, strides=(2, 2))(x) # check if we are going to add the squeeze excitation block if self.isSqueezeExcite: # add the squeeze excitation block followed by passing the # output through a ReLU layer x = self.squeeze_excite_block(x) x = ReLU()(x) # return the processed outputs return x
The previously referenced function group is defined on Line 54. It takes in the layer input, number of layers, and number of filters as arguments.
On Lines 57, we iterate over the number of layers and add convolution layers. Once out of the loop, we add a max pooling layer (Line 63).
On Line 66, we check if the model is an SE network and accordingly add an SE block on Line 69. This is followed by a ReLU layer.
def squeeze_excite_block(self, x): # store the input shortcut = x # calculate the number of filters the input has filters = x.shape[-1] # the squeeze operation reduces the input dimensionality # here we do a global average pooling across the filters, which # reduces the input to a 1D vector x = GlobalAveragePooling2D(keepdims=True)(x) # reduce the number of filters (1 x 1 x C/r) x = Dense(filters // self.ratio, activation="relu", kernel_initializer="he_normal", use_bias=False)(x) # the excitation operation restores the input dimensionality x = Dense(filters, activation="sigmoid", kernel_initializer="he_normal", use_bias=False)(x) # multiply the attention weights with the original input x = Multiply()([shortcut, x]) # return the output of the SE block return x
Finally, we reach the SE block (Line 75). But, first, we store the input for later use on Line 77.
On Line 80, we calculate the number of filters for squeeze operation.
On Line 85, we have the squeeze operation. Next is the excitation operation. We first reduce the number of filters to  for purposes explained in the introduction section by adding a dense layer with nodes. (For a quick reminder, it is for complexity reduction.)
for purposes explained in the introduction section by adding a dense layer with nodes. (For a quick reminder, it is for complexity reduction.)
This is followed by dimensional restoration, as we have another dense function with filters equal to  .
.
With our dimensions restored, the sigmoid function gives us a weight for each channel. So all we need to do is multiply this with our previously stored input, and now we have weighted channel-wise output (Line 96). This is also the scale operation mentioned by the authors of the paper.
def classifier(self, x): # flatten the input x = Flatten()(x) # apply Fully Connected Dense layers with ReLU activation x = Dense(self.denseUnits, activation="relu")(x) x = Dense(self.denseUnits, activation="relu")(x) x = Dense(self.numClasses, activation="softmax")(x) # return the predictions return x def build_model(self): # initialize the input layer inputs = Input(self.inputShape) # pass the input through the stem => learner => classifier x = self.stem(inputs) x = self.learner(x) outputs = self.classifier(x) # build the keras model with the inputs and outputs model = Model(inputs, outputs) # return the model return model
On Line 101, we define the classifier function for the remaining layers of our architecture. We add a flattened layer, followed by 3 dense layers, the last one being our output layer with filters equal to the number of classes in the cifar10 dataset (Lines 106-111).
With our architecture out of the way, our following function is build_model (Line 113). This function will be used just to use the functions we have defined till now and set it up in the correct order. On Lines 118-120, we first use the stem function, followed by the learner function, and top it up with the classifier function.
On Lines 124-126, we initialize and return the model. That finishes our model architecture.
def train_model(self, model, xTrain, yTrain, xVal, yVal, epochs, batchSize): # compile the model model.compile( optimizer=self.optimizer, loss=self.loss, metrics=self.metrics) # initialize a list containing our callback functions callbacks = [ keras.callbacks.EarlyStopping(monitor="val_loss", patience=5, restore_best_weights=True), keras.callbacks.ReduceLROnPlateau(monitor="val_loss", patience=3) ] # train the model model.fit(xTrain, yTrain, validation_data=(xVal, yVal), epochs=epochs, batch_size=batchSize, callbacks=callbacks) # return the trained model return model
On Line 128, we have the function train_model, which takes in the following arguments:
model: The model that will be used for training.xTrain: The training image input dataset.yTrain: The training dataset labels.xVal: The validation image dataset.yVal: The validation labels.epochs: Specifies the number of epochs for running the training.batchSize: Specifies the batch size for grabbing data.
We first compile our model with the optimizer, loss, and metrics (Lines 131-133).
On Lines 136-141, we have set up a few callback functions to help with our training. Finally, we fit the data into our model and start the training (Lines 144 and 145).
Training the Squeeze-and-Excitation Network
Our final task is to train the SE network and note its results. First, however, to understand how it is better than a regular CNN, we will be training a vanilla CNN and a SE block powered CNN side by side to note their results.
For that, let’s move into the train.py script located in the root directory of our project.
# USAGE
# python train.py
# setting the random seed for reproducibility
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.model import VGG
from pyimagesearch.data import get_cifar10_data
# get the dataset
print("[INFO] downloading the dataset...")
((xTrain, yTrain), (xVal, yVal), (xTest, yTest)) = get_cifar10_data()
# build a vanilla VGG model
print("[INFO] building a vanilla VGG model...")
vggObject = VGG(inputShape=config.INPUT_SHAPE, ratio=config.RATIO,
blocks=config.BLOCKS, numClasses=config.NUMBER_CLASSES,
denseUnits=config.DENSE_UNITS, convFilters=config.CONV_FILTER,
isSqueezeExcite=False, optimizer=config.OPTIMIZER, loss=config.LOSS,
metrics=config.METRICS)
vggModel = vggObject.build_model()
# build a VGG model with SE layer
print("[INFO] building VGG model with SE layer...")
vggSEObject = VGG(inputShape=config.INPUT_SHAPE, ratio=config.RATIO,
blocks=config.BLOCKS, numClasses=config.NUMBER_CLASSES,
denseUnits=config.DENSE_UNITS, convFilters=config.CONV_FILTER,
isSqueezeExcite=True, optimizer=config.OPTIMIZER, loss=config.LOSS,
metrics=config.METRICS)
vggSEModel = vggSEObject.build_model()
On Line 6, along with other imports, we have defined a specific random seed to make our project reproducible each time someone runs it.
On Lines 14 and 15, we download the cifar10 dataset using the get_cifar10_data function we have previously created in the data.py script. The data is unpacked into three splits: training, validation, and testing.
We then initialize the vanilla CNN using our model architecture script model.py (Lines 19-24). If you remember correctly, there was an isSqueezeExcite bool variable in our class, which told the functions if the model to be initialized will have a SE block. For a vanilla CNN, we simply need to set that variable to False (Line 22).
Now, we will initialize the CNN with the SE block. We follow the same steps as the previously created vanilla CNN, keeping all the parameters the same, except for the isSqueezeExcite bool variable, which we will set to True for this case.
Note: All the parameters you see being used have been defined in our config.py script.
# train the vanilla VGG model
print("[INFO] training the vanilla VGG model...")
vggModel = vggObject.train_model(model=vggModel, xTrain=xTrain,
yTrain=yTrain, xVal=xVal, yVal=yVal, epochs=config.EPOCHS,
batchSize=config.BATCH_SIZE)
# evaluate the vanilla VGG model on the testing dataset
print("[INFO] evaluating performance of vanilla VGG model...")
(loss, acc) = vggModel.evaluate(xTest, yTest,
batch_size=config.BATCH_SIZE)
# print the testing loss and the testing accuracy of the vanilla VGG
# model
print(f"[INFO] VANILLA VGG TEST Loss: {loss:0.4f}")
print(f"[INFO] VANILLA VGG TEST Accuracy: {acc:0.4f}")
First, the vanilla CNN is trained using the train_model function from the VGG class template (Lines 37-39). Then, the loss and accuracy of the vanilla CNN tested using the test dataset are stored on Lines 43 and 44.
# train the VGG model with the SE layer
print("[INFO] training the VGG model with SE layer...")
vggSEModel = vggSEObject.train_model(model=vggSEModel, xTrain=xTrain,
yTrain=yTrain, xVal=xVal, yVal=yVal, epochs=config.EPOCHS,
batchSize=config.BATCH_SIZE)
# evaluate the VGG model with the SE layer on the testing dataset
print("[INFO] evaluating performance of VGG model with SE layer...")
(loss, acc) = vggSEModel.evaluate(xTest, yTest,
batch_size=config.BATCH_SIZE)
# print the testing loss and the testing accuracy of the SE VGG
# model
print(f"[INFO] SE VGG TEST Loss: {loss:0.4f}")
print(f"[INFO] SE VGG TEST Accuracy: {acc:0.4f}")
Now it is time to train the VGG model with the SE block (Lines 53-55). We similarly store the loss and accuracy of the VGG SE model tested on the test dataset (Lines 59 and 60).
We print these values to compare them with the vanilla CNN results.
Let’s see how well the models fared against each other!
[INFO] building a vanilla VGG model... [INFO] training the vanilla VGG model... Epoch 1/100 1407/1407 [==============================] - 22s 10ms/step - loss: 1.5038 - acc: 0.4396 - val_loss: 1.1800 - val_acc: 0.5690 - lr: 0.0010 Epoch 2/100 1407/1407 [==============================] - 13s 9ms/step - loss: 1.0136 - acc: 0.6387 - val_loss: 0.8751 - val_acc: 0.6922 - lr: 0.0010 Epoch 3/100 1407/1407 [==============================] - 13s 9ms/step - loss: 0.8177 - acc: 0.7109 - val_loss: 0.8017 - val_acc: 0.7200 - lr: 0.0010 ... Epoch 8/100 1407/1407 [==============================] - 13s 9ms/step - loss: 0.3874 - acc: 0.8660 - val_loss: 0.7762 - val_acc: 0.7616 - lr: 0.0010 Epoch 9/100 1407/1407 [==============================] - 13s 9ms/step - loss: 0.1571 - acc: 0.9441 - val_loss: 0.9518 - val_acc: 0.7880 - lr: 1.0000e-04 Epoch 10/100 1407/1407 [==============================] - 13s 9ms/step - loss: 0.0673 - acc: 0.9774 - val_loss: 1.1386 - val_acc: 0.7902 - lr: 1.0000e-04 [INFO] evaluating performance of vanilla VGG model... 313/313 [==============================] - 1s 4ms/step - loss: 0.7785 - acc: 0.7430 [INFO] VANILLA VGG TEST Loss: 0.7785 [INFO] VANILLA VGG TEST Accuracy: 0.7430
First, we have the vanilla VGG, which has trained for 10 epochs and reached a training accuracy of 97%. The validation accuracy peaked at 79%. We can already see that the vanilla VGG hasn’t generalized well.
Upon evaluation of the test dataset, the accuracy comes to 74%.
[INFO] building VGG model with SE layer... [INFO] training the VGG model with SE layer... Epoch 1/100 1407/1407 [==============================] - 18s 12ms/step - loss: 1.5177 - acc: 0.4352 - val_loss: 1.1684 - val_acc: 0.5710 - lr: 0.0010 Epoch 2/100 1407/1407 [==============================] - 17s 12ms/step - loss: 1.0092 - acc: 0.6423 - val_loss: 0.8803 - val_acc: 0.6892 - lr: 0.0010 Epoch 3/100 1407/1407 [==============================] - 17s 12ms/step - loss: 0.7834 - acc: 0.7222 - val_loss: 0.7986 - val_acc: 0.7272 - lr: 0.0010 ... Epoch 8/100 1407/1407 [==============================] - 17s 12ms/step - loss: 0.2723 - acc: 0.9029 - val_loss: 0.8258 - val_acc: 0.7754 - lr: 0.0010 Epoch 9/100 1407/1407 [==============================] - 17s 12ms/step - loss: 0.0939 - acc: 0.9695 - val_loss: 0.8940 - val_acc: 0.8058 - lr: 1.0000e-04 Epoch 10/100 1407/1407 [==============================] - 17s 12ms/step - loss: 0.0332 - acc: 0.9901 - val_loss: 1.1226 - val_acc: 0.8116 - lr: 1.0000e-04 [INFO] evaluating performance of VGG model with SE layer... 313/313 [==============================] - 2s 5ms/step - loss: 0.7395 - acc: 0.7572 [INFO] SE VGG TEST Loss: 0.7395 [INFO] SE VGG TEST Accuracy: 0.7572
The SE VGG reached a training accuracy of 99%. The validation accuracy peaked at 81%. The generalization is still not good but can be termed better than the vanilla VGG.
After training the same number of epochs, the test accuracy came to 75%, more than the vanilla VGG.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This post brings our consecutive blogs on modified Convolutional Neural Networks (CNNs) to a close. In our last post, we saw how we could teach a CNN to correct the orientation of an image by itself. This week, we know what happens when the channel-wise features are also included in the feature pool.
The results were as clear as day; we can push the CNNs to take extra measures and get even better results with the right approach.
Today, we worked with channels often overlooked in favor of spatial information. While it is true that spatial information will make more sense to the naked eye, an algorithm’s way of drawing out information shouldn’t be undermined.
We compared a vanilla architecture with the squeeze-and-excitation (SE) block attached. The results showed a boost in the ability of the network to assess patterns when the SE block was attached to it. The SE block simply adds to the global feature pool, allowing the model to choose from more features.
Citation Information
Chakraborty, D. “Attending to Channels Using Keras and TensorFlow,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2022, https://pyimg.co/jq94n
@incollection{Chakraborty_2022_Attending_Channels,
author = {Devjyoti Chakraborty},
title = {Attending to Channels Using {Keras} and {TensorFlow}},
booktitle = {PyImageSearch}, editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/jq94n},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.