
In this tutorial, you will learn about face recognition, including:
- How face recognition works
- How face recognition is different from face detection
- A history of face recognition algorithms
- State-of-the-art algorithms used for face recognition today

Next week we will start implementing these face recognition algorithms.
To learn about face recognition, just keep reading.
What is face recognition?
Face recognition is the process of taking a face in an image and actually identifying who the face belongs to. Face recognition is thus a form of person identification.
Early face recognition systems relied on an early version of facial landmarks extracted from images, such as the relative position and size of the eyes, nose, cheekbone, and jaw. However, these systems were often highly subjective and prone to error since these quantifications of the face were manually extracted by the computer scientists and administrators running the face recognition software.
As machine learning algorithms became more powerful and the computer vision field matured, face recognition systems started to utilize feature extraction and classification models to identify faces in images.
Not only are these systems non-subjective, but they are also automatic — no hand labeling of the face is required. We simply extract features from the faces, train our classifier, and then use it to identify subsequent faces.
Most recently, we’ve started to utilize deep learning algorithms for face recognition. State-of-the-art face recognition models such as FaceNet and OpenFace rely on a specialized deep neural network architecture called siamese networks.
These neural networks are capable of obtaining face recognition accuracy that was once thought impossible (and they can achieve this accuracy with surprisingly little data).
How is face recognition different from face detection?
I’ve often seen new computer vision and deep learning practitioners confuse the difference between face detection and face recognition, sometimes (and incorrectly) using the terms interchangeably.
Face detection and face recognition are distinctly different algorithms — face detection will tell you where in a given image/frame a face is (but not who the face belongs to) while face recognition actually identifies the detected face.
Let’s break this down a bit farther:
Unlike face detection, which is the process of simply detecting the presence of a face in an image or video stream, face recognition takes the faces detected from the localization phase and attempts to identify whom the face belongs to. Face recognition can thus be thought of as a method of person identification, which we use heavily in security and surveillance systems.
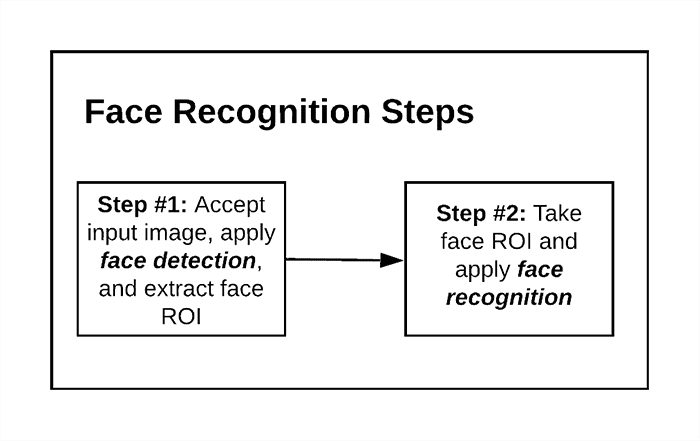
Since face recognition, by definition, requires face detection, we can think of face recognition as a two-phase process.
- Phase #1: Detect the presence of faces in an image or video stream using methods such as Haar cascades, HOG + Linear SVM, deep learning, or any other algorithm that can localize faces.
- Phase #2: Take each of the faces detected during the localization phase and identify each of them — this is where we actually assign a name to a face.
In the remainder of this tutorial, we’ll review a quick history of face recognition, followed by introducing face recognition algorithms and techniques, including Eigenfaces, Local Binary Patterns (LBPs) for face recognition, siamese networks, FaceNet, etc.
A brief history of face recognition
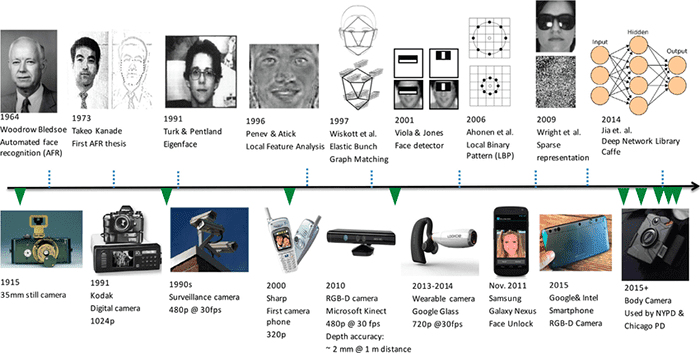
Face recognition may seem ubiquitous now (with it being implemented on most smartphones and major social media platforms), but prior to the 1970s, face recognition was often regarded as science fiction, sequestered to the movies and books set in ultra-future times. In short, face recognition was a fantasy, and whether or not it would become a reality was unclear.
This all changed in 1971 when Goldstein et al. published Identification of human faces. A crude first attempt at face identification, this method proposed 21 subjective facial features, such as hair color and lip thickness, to identify a face in a photograph.
The largest drawback of this approach was that the 21 measurements (besides being highly subjective) were manually computed — an obvious flaw in a computer science community that was rapidly approaching unsupervised computation and classification (at least in terms of human oversight).
Then, over a decade later, in 1987, Sirovich and Kirby published their seminal work, A Low-Dimensional Procedure for the Characterization of Human Faces which was later followed by Turk and Pentland in 1991 with Face Recognition Using Eigenfaces.

Both Sirovich and Kirby, along with Turk and Pentland, demonstrated that a standard linear algebra technique for dimensionality reduction called Principal Component Analysis (PCA) could be used to identify a face using a feature vector smaller than 100-dim.
Furthermore, the “principal components” (i.e., the eigenvectors, or the “eigenfaces”) could be used to reconstruct faces from the original dataset. This implies that a face could be represented (and eventually identified) as a linear combination of the eigenfaces:
Query Face = 36% of Eigenface #1 + -8% of Eigenface #2 … + 21% of Eigenface N
Following the work of Sirovich and Kirby in the late 1980s, further research in face recognition exploded — another popular linear algebra-based face recognition technique utilized Linear Discriminant Analysis. LDA-based face recognition algorithms are commonly known as Fisherfaces.
Feature-based approaches such as Local Binary Patterns for face recognition have also been proposed and are still heavily used in real-world applications:
Deep learning is now responsible for unprecedented accuracy in face recognition. Specialized architectures called siamese networks are trained with a special type of data, called image triplets. We then compute, monitor, and attempt to minimize our triplet loss, thereby maximizing face recognition accuracy.
Popular deep neural network face recognition models include FaceNet and OpenFace.
Eigenfaces

The Eigenfaces algorithm uses Principal Component Analysis to construct a low-dimensional representation of face images.
This process involves collecting a dataset of faces with multiple face images per person we want to identify (like having multiple training examples of an image class we want to identify when performing image classification).
Given this dataset of face images, presumed to be the same width, height, and ideally — with their eyes and facial structures aligned at the same (x, y)-coordinates, we apply an eigenvalue decomposition of the dataset, keeping the eigenvectors with the largest corresponding eigenvalues.
Given these eigenvectors, a face can then be represented as a linear combination of what Sirovich and Kirby call eigenfaces.
Face identification can be performed by computing the Euclidean distance between the eigenface representations and treating the face identification as a k-Nearest Neighbor classification problem — however, we tend to commonly apply more advanced machine learning algorithms to the eigenface representations.
If you’re feeling a bit overwhelmed by the linear algebra terminology or how the Eigenfaces algorithm works, no worries — we’ll be covering the Eigenfaces algorithm in detail later in this series of tutorials on face recognition.
LBPs for face recognition
While the Eigenfaces algorithm relies on PCA to construct a low-dimensional representation of face images, the Local Binary Patterns (LBPs) method relies, as the name suggests, on feature extraction.
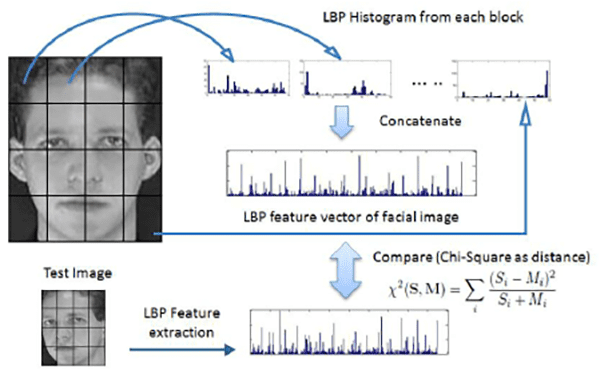
First introduced by Ahonen et al. in their 2004 paper, Face Recognition with Local Binary Patterns, their method suggests dividing a face image into a 7×7 grid of equally sized cells:

By dividing the image into cells we can introduce locality into our final feature vector. Furthermore, some cells are weighted such that they contribute more to the overall representation. Cells in the corners carry less identifying facial information compared to the cells in the center of the grid (which contain eyes, nose, and lip structures).
Finally, we concatenate the weighted LBP histograms from the 49 cells to form our final feature vector.
The actual face identification is performed by k-NN classification using the  distance between the query image and the dataset of labeled faces — since we are comparing histograms, the distance is a better choice than the Euclidean distance.
distance between the query image and the dataset of labeled faces — since we are comparing histograms, the distance is a better choice than the Euclidean distance.
While both Eigenfaces and LBPs for face recognition are fairly straightforward algorithms for face identification, the feature-based LBP method tends to be more resilient against noise (since it does not operate on the raw pixel intensities themselves) and will usually yield better results.
We’ll be implementing LBPs for face recognition in detail later in this series of tutorials.
Deep learning-based face recognition
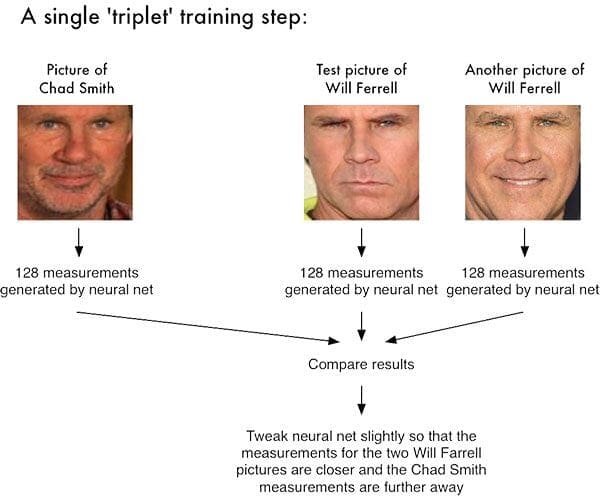
Deep learning has impacted nearly every aspect and subfield of computer science. Face recognition is no different.
For many years, LBPs and Eigenfaces/Fisherfaces were considered the state-of-the-art in face recognition. These techniques were easily fooled, and accuracy was poor outside the research lab/controlled environments.
Deep learning changed all that. Specialized neural network architectures and training techniques, including siamese networks, image triplets, and triplet loss, enabled researchers to obtain face recognition accuracy that was once thought impossible.
These methods are far more accurate and robust than previous techniques. And despite the stigma of neural networks being data hungry beasts, siamese networks allow us to train these state-of-the-art models with very little data.
If you’re interested in learning more about deep learning-based face recognition, I suggest you read the following guides on PyImageSearch:
- Face recognition with OpenCV, Python, and deep learning
- OpenCV Face Recognition
- Raspberry Pi Face Recognition
- Raspberry Pi and Movidius NCS Face Recognition
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we learned that face recognition is a two-phase process that consists of:
- Face detection and extraction of the face ROI (region of interest)
- Identification, where we identify who the face belongs to
From there, we reviewed the history of face recognition algorithms, including:
- Crude (and often subjective) facial landmarks that were manually labeled by researchers
- Linear algebra-based techniques such as Eigenfaces and Fisherfaces
- LBPs for face recognition
- Deep learning-based models, including FaceNet and OpenFace
The next tutorial in this series will cover how to implement Eigenfaces with OpenCV.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.