Last updated on December 30, 2022.

In this tutorial, you will learn how to use OpenCV to perform face recognition. To build our face recognition system, we’ll first perform face detection, extract face embeddings from each face using deep learning, train a face recognition model on the embeddings, and then finally recognize faces in both images and video streams with OpenCV.
Having a dataset with faces of various individuals is crucial for building effective face recognition systems. It allows the model to learn diverse facial features, leading to an improved ability to recognize different individuals.
Roboflow has free tools for each stage of the computer vision pipeline that will streamline your workflows and supercharge your productivity.
Sign up or Log in to your Roboflow account to access state of the art dataset libaries and revolutionize your computer vision pipeline.
You can start by choosing your own datasets or using our PyimageSearch’s assorted library of useful datasets.
Bring data in any of 40+ formats to Roboflow, train using any state-of-the-art model architectures, deploy across multiple platforms (API, NVIDIA, browser, iOS, etc), and connect to applications or 3rd party tools.
This tutorial will use OpenCV to perform face recognition on a dataset of our faces.
You can swap in your own dataset of faces of course! All you need to do is follow my directory structure in insert your own face images.
As a bonus, I’ve also included how to label “unknown” faces that cannot be classified with sufficient confidence.
To learn how to perform OpenCV face recognition, just keep reading!
- Update July 2021: Added section on alternative face recognition methods to consider, including how siamese networks can be used for face recognition.
- Updated December 2022: updated links and content.
OpenCV Face Recognition
In today’s tutorial, you will learn how to perform face recognition using the OpenCV library.
You might be wondering how this tutorial is different from the one I wrote a few months back on face recognition with dlib?
Well, keep in mind that the dlib face recognition post relied on two important external libraries:
- dlib (obviously)
- face_recognition (which is an easy to use set of face recognition utilities that wraps around dlib)
While we used OpenCV to facilitate face recognition, OpenCV itself was not responsible for identifying faces.
In today’s tutorial, we’ll learn how we can apply deep learning and OpenCV together (with no other libraries other than scikit-learn) to:
- Detect faces
- Compute 128-d face embeddings to quantify a face
- Train a Support Vector Machine (SVM) on top of the embeddings
- Recognize faces in images and video streams
All of these tasks will be accomplished with OpenCV, enabling us to obtain a “pure” OpenCV face recognition pipeline.
How OpenCV’s face recognition works
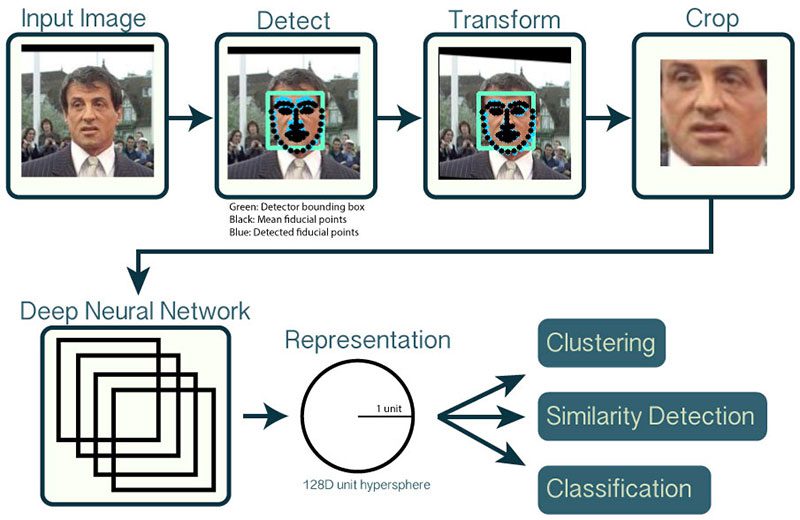
In order to build our OpenCV face recognition pipeline, we’ll be applying deep learning in two key steps:
- To apply face detection, which detects the presence and location of a face in an image, but does not identify it
- To extract the 128-d feature vectors (called “embeddings”) that quantify each face in an image
I’ve discussed how OpenCV’s face detection works previously, so please refer to it if you have not detected faces before.
The model responsible for actually quantifying each face in an image is from the OpenFace project, a Python and Torch implementation of face recognition with deep learning. This implementation comes from Schroff et al.’s 2015 CVPR publication, FaceNet: A Unified Embedding for Face Recognition and Clustering.
Reviewing the entire FaceNet implementation is outside the scope of this tutorial, but the gist of the pipeline can be seen in Figure 1 above.
First, we input an image or video frame to our face recognition pipeline. Given the input image, we apply face detection to detect the location of a face in the image.
Optionally we can compute facial landmarks, enabling us to preprocess and align the face.
Face alignment, as the name suggests, is the process of (1) identifying the geometric structure of the faces and (2) attempting to obtain a canonical alignment of the face based on translation, rotation, and scale.
While optional, face alignment has been demonstrated to increase face recognition accuracy in some pipelines.
After we’ve (optionally) applied face alignment and cropping, we pass the input face through our deep neural network:
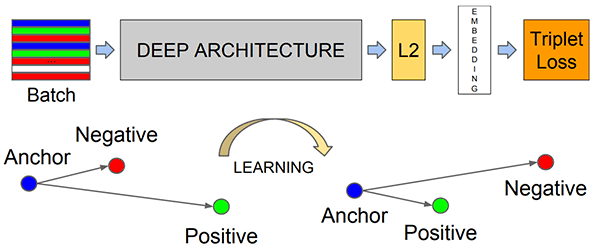
The FaceNet deep learning model computes a 128-d embedding that quantifies the face itself.
But how does the network actually compute the face embedding?
The answer lies in the training process itself, including:
- The input data to the network
- The triplet loss function
To train a face recognition model with deep learning, each input batch of data includes three images:
- The anchor
- The positive image
- The negative image
The anchor is our current face and has identity A.
The second image is our positive image — this image also contains a face of person A.
The negative image, on the other hand, does not have the same identity, and could belong to person B, C, or even Y!
The point is that the anchor and positive image both belong to the same person/face while the negative image does not contain the same face.
The neural network computes the 128-d embeddings for each face and then tweaks the weights of the network (via the triplet loss function) such that:
- The 128-d embeddings of the anchor and positive image lie closer together
- While at the same time, pushing the embeddings for the negative image father away
In this manner, the network is able to learn to quantify faces and return highly robust and discriminating embeddings suitable for face recognition.
And furthermore, we can actually reuse the OpenFace model for our own applications without having to explicitly train it!
Even though the deep learning model we’re using today has (very likely) never seen the faces we’re about to pass through it, the model will still be able to compute embeddings for each face — ideally, these face embeddings will be sufficiently different such that we can train a “standard” machine learning classifier (SVM, SGD classifier, Random Forest, etc.) on top of the face embeddings, and therefore obtain our OpenCV face recognition pipeline.
If you are interested in learning more about the details surrounding triplet loss and how it can be used to train a face embedding model, be sure to refer to my previous blog post as well as the Schroff et al. publication.
Our face recognition dataset

The dataset we are using today contains three people:
- A man
- A woman
- “Unknown”, which is used to represent faces of people we do not know and wish to label as such (here I just sampled faces from the movie Jurassic Park which I used in a previous post — you may want to insert your own “unknown” dataset).
Each class contains a total of six images.
If you are building your own face recognition dataset, ideally, I would suggest having 10-20 images per person you wish to recognize — be sure to refer to the “Drawbacks, limitations, and how to obtain higher face recognition accuracy” section of this blog post for more details.
Project structure
Once you’ve grabbed the zip from the “Downloads” section of this post, go ahead and unzip the archive and navigate into the directory.
From there, you may use the tree command to have the directory structure printed in your terminal:
$ tree --dirsfirst . ├── dataset │ ├── adrian [6 images] │ ├── trisha [6 images] │ └── unknown [6 images] ├── images │ ├── adrian.jpg │ ├── patrick_bateman.jpg │ └── trisha_adrian.jpg ├── face_detection_model │ ├── deploy.prototxt │ └── res10_300x300_ssd_iter_140000.caffemodel ├── output │ ├── embeddings.pickle │ ├── le.pickle │ └── recognizer.pickle ├── extract_embeddings.py ├── openface_nn4.small2.v1.t7 ├── train_model.py ├── recognize.py └── recognize_video.py 7 directories, 31 files
There are quite a few moving parts for this project — take the time now to carefully read this section so you become familiar with all the files in today’s project.
Our project has four directories in the root folder:
dataset/: Contains our face images organized into subfolders by name.images/: Contains three test images that we’ll use to verify the operation of our model.face_detection_model/: Contains a pre-trained Caffe deep learning model provided by OpenCV to detect faces. This model detects and localizes faces in an image.output/: Contains my output pickle files. If you’re working with your own dataset, you can store your output files here as well. The output files include:embeddings.pickle: A serialized facial embeddings file. Embeddings have been computed for every face in the dataset and are stored in this file.le.pickle: Our label encoder. Contains the name labels for the people that our model can recognize.recognizer.pickle: Our Linear Support Vector Machine (SVM) model. This is a machine learning model rather than a deep learning model and it is responsible for actually recognizing faces.
Let’s summarize the five files in the root directory:
extract_embeddings.py: We’ll review this file in Step #1 which is responsible for using a deep learning feature extractor to generate a 128-D vector describing a face. All faces in our dataset will be passed through the neural network to generate embeddings.openface_nn4.small2.v1.t7: A Torch deep learning model which produces the 128-D facial embeddings. We’ll be using this deep learning model in Steps #1, #2, and #3 as well as the Bonus section.train_model.py: Our Linear SVM model will be trained by this script in Step #2. We’ll detect faces, extract embeddings, and fit our SVM model to the embeddings data.recognize.py: In Step #3 and we’ll recognize faces in images. We’ll detect faces, extract embeddings, and query our SVM model to determine who is in an image. We’ll draw boxes around faces and annotate each box with a name.recognize_video.py: Our Bonus section describes how to recognize who is in frames of a video stream just as we did in Step #3 on static images.
Let’s move on to the first step!
Step #1: Extract embeddings from face dataset
Now that we understand how face recognition works and reviewed our project structure, let’s get started building our OpenCV face recognition pipeline.
Open up the extract_embeddings.py file and insert the following code:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--embeddings", required=True,
help="path to output serialized db of facial embeddings")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
We import our required packages on Lines 2-8. You’ll need to have OpenCV and imutils installed. To install OpenCV, simply follow one of my guides (I recommend OpenCV 3.4.2, so be sure to download the right version while you follow along). My imutils package can be installed with pip:
$ pip install --upgrade imutils
Next, we process our command line arguments:
--dataset: The path to our input dataset of face images.--embeddings: The path to our output embeddings file. Our script will compute face embeddings which we’ll serialize to disk.--detector: Path to OpenCV’s Caffe-based deep learning face detector used to actually localize the faces in the images.--embedding-model: Path to the OpenCV deep learning Torch embedding model. This model will allow us to extract a 128-D facial embedding vector.--confidence: Optional threshold for filtering week face detections.
Now that we’ve imported our packages and parsed command line arguments, lets load the face detector and embedder from disk:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
Here we load the face detector and embedder:
detector: Loaded via Lines 26-29. We’re using a Caffe based DL face detector to localize faces in an image.embedder: Loaded on Line 33. This model is Torch-based and is responsible for extracting facial embeddings via deep learning feature extraction.
Notice that we’re using the respective cv2.dnn functions to load the two separate models. The dnn module wasn’t made available like this until OpenCV 3.3, but I recommend that you are using OpenCV 3.4.2 or higher for this blog post.
Moving forward, let’s grab our image paths and perform initializations:
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize our lists of extracted facial embeddings and
# corresponding people names
knownEmbeddings = []
knownNames = []
# initialize the total number of faces processed
total = 0
The imagePaths list, built on Line 37, contains the path to each image in the dataset. I’ve made this easy via my imutils function, paths.list_images .
Our embeddings and corresponding names will be held in two lists: knownEmbeddings and knownNames (Lines 41 and 42).
We’ll also be keeping track of how many faces we’ve processed via a variable called total (Line 45).
Let’s begin looping over the image paths — this loop will be responsible for extracting embeddings from faces found in each image:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
We begin looping over imagePaths on Line 48.
First, we extract the name of the person from the path (Line 52). To explain how this works, consider the following example in my Python shell:
$ python
>>> from imutils import paths
>>> import os
>>> imagePaths = list(paths.list_images("dataset"))
>>> imagePath = imagePaths[0]
>>> imagePath
'dataset/adrian/00004.jpg'
>>> imagePath.split(os.path.sep)
['dataset', 'adrian', '00004.jpg']
>>> imagePath.split(os.path.sep)[-2]
'adrian'
>>>
Notice how by using imagePath.split and providing the split character (the OS path separator — “/” on unix and “\” on Windows), the function produces a list of folder/file names (strings) which walk down the directory tree. We grab the second-to-last index, the persons name , which in this case is 'adrian' .
Finally, we wrap up the above code block by loading the image and resize it to a known width (Lines 57 and 58).
Let’s detect and localize faces:
# construct a blob from the image imageBlob = cv2.dnn.blobFromImage( cv2.resize(image, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0), swapRB=False, crop=False) # apply OpenCV's deep learning-based face detector to localize # faces in the input image detector.setInput(imageBlob) detections = detector.forward()
On Lines 62-64, we construct a blob. To learn more about this process, please read Deep learning: How OpenCV’s blobFromImage works.
From there we detect faces in the image by passing the imageBlob through the detector network (Lines 68 and 69).
Let’s process the detections :
# ensure at least one face was found
if len(detections) > 0:
# we're making the assumption that each image has only ONE
# face, so find the bounding box with the largest probability
i = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, i, 2]
# ensure that the detection with the largest probability also
# means our minimum probability test (thus helping filter out
# weak detections)
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI and grab the ROI dimensions
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
The detections list contains probabilities and coordinates to localize faces in an image.
Assuming we have at least one detection, we’ll proceed into the body of the if-statement (Line 72).
We make the assumption that there is only one face in the image, so we extract the detection with the highest confidence and check to make sure that the confidence meets the minimum probability threshold used to filter out weak detections (Lines 75-81).
Assuming we’ve met that threshold, we extract the face ROI and grab/check dimensions to make sure the face ROI is sufficiently large (Lines 84-93).
From there, we’ll take advantage of our embedder CNN and extract the face embeddings:
# construct a blob for the face ROI, then pass the blob # through our face embedding model to obtain the 128-d # quantification of the face faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False) embedder.setInput(faceBlob) vec = embedder.forward() # add the name of the person + corresponding face # embedding to their respective lists knownNames.append(name) knownEmbeddings.append(vec.flatten()) total += 1
We construct another blob, this time from the face ROI (not the whole image as we did before) on Lines 98 and 99.
Subsequently, we pass the faceBlob through the embedder CNN (Lines 100 and 101). This generates a 128-D vector (vec ) which describes the face. We’ll leverage this data to recognize new faces via machine learning.
And then we simply add the name and embedding vec to knownNames and knownEmbeddings , respectively (Lines 105 and 106).
We also can’t forget about the variable we set to track the total number of faces either — we go ahead and increment the value on Line 107.
We continue this process of looping over images, detecting faces, and extracting face embeddings for each and every image in our dataset.
All that’s left when the loop finishes is to dump the data to disk:
# dump the facial embeddings + names to disk
print("[INFO] serializing {} encodings...".format(total))
data = {"embeddings": knownEmbeddings, "names": knownNames}
f = open(args["embeddings"], "wb")
f.write(pickle.dumps(data))
f.close()
We add the name and embedding data to a dictionary and then serialize the data in a pickle file on Lines 110-114.
At this point we’re ready to extract embeddings by running our script.
To follow along with this face recognition tutorial, use the “Downloads” section of the post to download the source code, OpenCV models, and example face recognition dataset.
From there, open up a terminal and execute the following command to compute the face embeddings with OpenCV:
$ python extract_embeddings.py --dataset dataset \ --embeddings output/embeddings.pickle \ --detector face_detection_model \ --embedding-model openface_nn4.small2.v1.t7 [INFO] loading face detector... [INFO] loading face recognizer... [INFO] quantifying faces... [INFO] processing image 1/18 [INFO] processing image 2/18 [INFO] processing image 3/18 [INFO] processing image 4/18 [INFO] processing image 5/18 [INFO] processing image 6/18 [INFO] processing image 7/18 [INFO] processing image 8/18 [INFO] processing image 9/18 [INFO] processing image 10/18 [INFO] processing image 11/18 [INFO] processing image 12/18 [INFO] processing image 13/18 [INFO] processing image 14/18 [INFO] processing image 15/18 [INFO] processing image 16/18 [INFO] processing image 17/18 [INFO] processing image 18/18 [INFO] serializing 18 encodings...
Here you can see that we have extracted 18 face embeddings, one for each of the images (6 per class) in our input face dataset.
Step #2: Train face recognition model
At this point we have extracted 128-d embeddings for each face — but how do we actually recognize a person based on these embeddings? The answer is that we need to train a “standard” machine learning model (such as an SVM, k-NN classifier, Random Forest, etc.) on top of the embeddings.
In my previous face recognition tutorial we discovered how a modified version of k-NN can be used for face recognition on 128-d embeddings created via the dlib and face_recognition libraries.
Today, I want to share how we can build a more powerful classifier on top of the embeddings — you’ll be able to use this same method in your dlib-based face recognition pipelines as well if you are so inclined.
Open up the train_model.py file and insert the following code:
# import the necessary packages
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--embeddings", required=True,
help="path to serialized db of facial embeddings")
ap.add_argument("-r", "--recognizer", required=True,
help="path to output model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to output label encoder")
args = vars(ap.parse_args())
We’ll need scikit-learn, a machine learning library, installed in our environment prior to running this script. You can install it via pip:
$ pip install scikit-learn
We import our packages and modules on Lines 2-5. We’ll be using scikit-learn’s implementation of Support Vector Machines (SVM), a common machine learning model.
From there we parse our command line arguments:
--embeddings: The path to the serialized embeddings (we exported it by running the previousextract_embeddings.pyscript).--recognizer: This will be our output model that recognizes faces. It is based on SVM. We’ll be saving it so we can use it in the next two recognition scripts.--le: Our label encoder output file path. We’ll serialize our label encoder to disk so that we can use it and the recognizer model in our image/video face recognition scripts.
Each of these arguments is required.
Let’s load our facial embeddings and encode our labels:
# load the face embeddings
print("[INFO] loading face embeddings...")
data = pickle.loads(open(args["embeddings"], "rb").read())
# encode the labels
print("[INFO] encoding labels...")
le = LabelEncoder()
labels = le.fit_transform(data["names"])
Here we load our embeddings from Step #1 on Line 19. We won’t be generating any embeddings in this model training script — we’ll use the embeddings previously generated and serialized.
Then we initialize our scikit-learn LabelEncoder and encode our name labels (Lines 23 and 24).
Now it’s time to train our SVM model for recognizing faces:
# train the model used to accept the 128-d embeddings of the face and
# then produce the actual face recognition
print("[INFO] training model...")
recognizer = SVC(C=1.0, kernel="linear", probability=True)
recognizer.fit(data["embeddings"], labels)
On Line 29 we initialize our SVM model, and on Line 30 we fit the model (also known as “training the model”).
Here we are using a Linear Support Vector Machine (SVM) but you can try experimenting with other machine learning models if you so wish.
After training the model we output the model and label encoder to disk as pickle files.
# write the actual face recognition model to disk f = open(args["recognizer"], "wb") f.write(pickle.dumps(recognizer)) f.close() # write the label encoder to disk f = open(args["le"], "wb") f.write(pickle.dumps(le)) f.close()
We write two pickle files to disk in this block — the face recognizer model and the label encoder.
At this point, be sure you executed the code from Step #1 first. You can grab the zip containing the code and data from the “Downloads” section.
Now that we have finished coding train_model.py as well, let’s apply it to our extracted face embeddings:
$ python train_model.py --embeddings output/embeddings.pickle \ --recognizer output/recognizer.pickle \ --le output/le.pickle [INFO] loading face embeddings... [INFO] encoding labels... [INFO] training model... $ ls output/ embeddings.pickle le.pickle recognizer.pickle
Here you can see that our SVM has been trained on the embeddings and both the (1) SVM itself and (2) the label encoding have been written to disk, enabling us to apply them to input images and video.
Step #3: Recognize faces with OpenCV
We are now ready to perform face recognition with OpenCV!
We’ll start with recognizing faces in images in this section and then move on to recognizing faces in video streams in the following section.
Open up the recognize.py file in your project and insert the following code:
# import the necessary packages
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
We import our required packages on Lines 2-7. At this point, you should have each of these packages installed.
Our six command line arguments are parsed on Lines 10-23:
--image: The path to the input image. We will attempt to recognize the faces in this image.--detector: The path to OpenCV’s deep learning face detector. We’ll use this model to detect where in the image the face ROIs are.--embedding-model: The path to OpenCV’s deep learning face embedding model. We’ll use this model to extract the 128-D face embedding from the face ROI — we’ll feed the data into the recognizer.--recognizer: The path to our recognizer model. We trained our SVM recognizer in Step #2. This is what will actually determine who a face is.--le: The path to our label encoder. This contains our face labels such as'adrian'or'trisha'.--confidence: The optional threshold to filter weak face detections.
Be sure to study these command line arguments — it is important to know the difference between the two deep learning models and the SVM model. If you find yourself confused later in this script, you should refer back to here.
Now that we’ve handled our imports and command line arguments, let’s load the three models from disk into memory:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
We load three models in this block. At the risk of being redundant, I want to explicitly remind you of the differences among the models:
detector: A pre-trained Caffe DL model to detect where in the image the faces are (Lines 27-30).embedder: A pre-trained Torch DL model to calculate our 128-D face embeddings (Line 34).recognizer: Our Linear SVM face recognition model (Line 37). We trained this model in Step 2.
Both 1 & 2 are pre-trained meaning that they are provided to you as-is by OpenCV. They are buried in the OpenCV project on GitHub, but I’ve included them for your convenience in the “Downloads” section of today’s post. I’ve also numbered the models in the order that we’ll apply them to recognize faces with OpenCV.
We also load our label encoder which holds the names of the people our model can recognize (Line 38).
Now let’s load our image and detect faces:
# load the image, resize it to have a width of 600 pixels (while # maintaining the aspect ratio), and then grab the image dimensions image = cv2.imread(args["image"]) image = imutils.resize(image, width=600) (h, w) = image.shape[:2] # construct a blob from the image imageBlob = cv2.dnn.blobFromImage( cv2.resize(image, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0), swapRB=False, crop=False) # apply OpenCV's deep learning-based face detector to localize # faces in the input image detector.setInput(imageBlob) detections = detector.forward()
Here we:
- Load the image into memory and construct a blob (Lines 42-49). Learn about
cv2.dnn.blobFromImagehere. - Localize faces in the image via our
detector(Lines 53 and 54).
Given our new detections , let’s recognize faces in the image. But first we need to filter weak detections and extract the face ROI:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the
# prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for the
# face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
You’ll recognize this block from Step #1. I’ll explain it here once more:
- We loop over the
detectionson Line 57 and extract theconfidenceof each on Line 60. - Then we compare the
confidenceto the minimum probability detection threshold contained in our command lineargsdictionary, ensuring that the computed probability is larger than the minimum probability (Line 63). - From there, we extract the
faceROI (Lines 66-70) as well as ensure it’s spatial dimensions are sufficiently large (Lines 74 and 75).
Recognizing the name of the face ROI requires just a few steps:
# construct a blob for the face ROI, then pass the blob # through our face embedding model to obtain the 128-d # quantification of the face faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False) embedder.setInput(faceBlob) vec = embedder.forward() # perform classification to recognize the face preds = recognizer.predict_proba(vec)[0] j = np.argmax(preds) proba = preds[j] name = le.classes_[j]
First, we construct a faceBlob (from the face ROI) and pass it through the embedder to generate a 128-D vector which describes the face (Lines 80-83)
Then, we pass the vec through our SVM recognizer model (Line 86), the result of which is our predictions for who is in the face ROI.
We take the highest probability index (Line 87) and query our label encoder to find the name (Line 89). In between, I extract the probability on Line 88.
Note: You cam further filter out weak face recognitions by applying an additional threshold test on the probability. For example, inserting if proba < T (where T is a variable you define) can provide an additional layer of filtering to ensure there are less false-positive face recognitions.
Now, let’s display OpenCV face recognition results:
# draw the bounding box of the face along with the associated
# probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(image, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(image, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
For every face we recognize in the loop (including the “unknown”) people:
- We construct a
textstring containing thenameand probability on Line 93. - And then we draw a rectangle around the face and place the text above the box (Lines 94-98).
And then finally we visualize the results on the screen until a key is pressed (Lines 101 and 102).
It is time to recognize faces in images with OpenCV!
To apply our OpenCV face recognition pipeline to my provided images (or your own dataset + test images), make sure you use the “Downloads” section of the blog post to download the code, trained models, and example images.
From there, open up a terminal and execute the following command:
$ python recognize.py --detector face_detection_model \ --embedding-model openface_nn4.small2.v1.t7 \ --recognizer output/recognizer.pickle \ --le output/le.pickle \ --image images/adrian.jpg [INFO] loading face detector... [INFO] loading face recognizer...

Here you can see me sipping on a beer and sporting one of my favorite Jurassic Park shirts, along with a special Jurassic World pint glass and commemorative book. My face prediction only has 47.15% confidence; however, that confidence is higher than the “Unknown” class.
Let’s try another OpenCV face recognition example:
$ python recognize.py --detector face_detection_model \ --embedding-model openface_nn4.small2.v1.t7 \ --recognizer output/recognizer.pickle \ --le output/le.pickle \ --image images/trisha_adrian.jpg [INFO] loading face detector... [INFO] loading face recognizer...
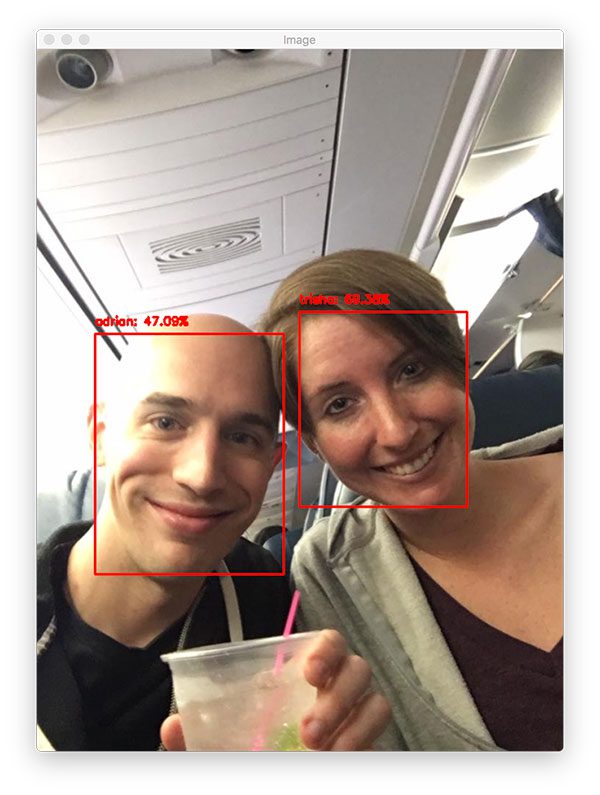
In a final example, let’s look at what happens when our model is unable to recognize the actual face:
$ python recognize.py --detector face_detection_model \ --embedding-model openface_nn4.small2.v1.t7 \ --recognizer output/recognizer.pickle \ --le output/le.pickle \ --image images/patrick_bateman.jpg [INFO] loading face detector... [INFO] loading face recognizer...

The third image is an example of an “unknown” person who is actually Patrick Bateman from American Psycho — believe me, this is not a person you would want to see show up in your images or video streams!
BONUS: Recognize faces in video streams
As a bonus, I decided to include a section dedicated to OpenCV face recognition in video streams!
The actual pipeline itself is near identical to recognizing faces in images, with only a few updates which we’ll review along the way.
Open up the recognize_video.py file and let’s get started:
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import pickle
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
Our imports are the same as the Step #3 section above, except for Lines 2 and 3 where we use the imutils.video module. We’ll use VideoStream to capture frames from our camera and FPS to calculate frames per second statistics.
The command line arguments are also the same except we aren’t passing a path to a static image via the command line. Rather, we’ll grab a reference to our webcam and then process the video. Refer to Step #3 if you need to review the arguments.
Our three models and label encoder are loaded here:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load our serialized face embedding model from disk
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
Here we load face detector , face embedder model, face recognizer model (Linear SVM), and label encoder.
Again, be sure to refer to Step #3 if you are confused about the three models or label encoder.
Let’s initialize our video stream and begin processing frames:
# initialize the video stream, then allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
# start the FPS throughput estimator
fps = FPS().start()
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
frame = vs.read()
# resize the frame to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
frame = imutils.resize(frame, width=600)
(h, w) = frame.shape[:2]
# construct a blob from the image
imageBlob = cv2.dnn.blobFromImage(
cv2.resize(frame, (300, 300)), 1.0, (300, 300),
(104.0, 177.0, 123.0), swapRB=False, crop=False)
# apply OpenCV's deep learning-based face detector to localize
# faces in the input image
detector.setInput(imageBlob)
detections = detector.forward()
Our VideoStream object is initialized and started on Line 43. We wait for the camera sensor to warm up on Line 44.
We also initialize our frames per second counter (Line 47) and begin looping over frames on Line 50. We grab a frame from the webcam on Line 52.
From here everything is the same as Step 3. We resize the frame (Line 57) and then we construct a blob from the frame + detect where the faces are (Lines 61-68).
Now let’s process the detections:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
Just as in the previous section, we begin looping over detections and filter out weak ones (Lines 71-77). Then we extract the face ROI as well as ensure the spatial dimensions are sufficiently large enough for the next steps (Lines 84-89).
Now it’s time to perform OpenCV face recognition:
# construct a blob for the face ROI, then pass the blob
# through our face embedding model to obtain the 128-d
# quantification of the face
faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255,
(96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# perform classification to recognize the face
preds = recognizer.predict_proba(vec)[0]
j = np.argmax(preds)
proba = preds[j]
name = le.classes_[j]
# draw the bounding box of the face along with the
# associated probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# update the FPS counter
fps.update()
Here we:
- Construct the
faceBlob(Lines 94 and 95) and calculate the facial embeddings via deep learning (Lines 96 and 97). - Recognize the most-likely
nameof the face while calculating the probability (Line 100-103). - Draw a bounding box around the face and the person’s
name+ probability (Lines 107 -112).
Our fps counter is updated on Line 115.
Let’s display the results and clean up:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
To close out the script, we:
- Display the annotated
frame(Line 118) and wait for the “q” key to be pressed at which point we break out of the loop (Lines 119-123). - Stop our
fpscounter and print statistics in the terminal (Lines 126-128). - Cleanup by closing windows and releasing pointers (Lines 131 and 132).
To execute our OpenCV face recognition pipeline on a video stream, open up a terminal and execute the following command:
$ python recognize_video.py --detector face_detection_model \ --embedding-model openface_nn4.small2.v1.t7 \ --recognizer output/recognizer.pickle \ --le output/le.pickle [INFO] loading face detector... [INFO] loading face recognizer... [INFO] starting video stream... [INFO] elasped time: 12.52 [INFO] approx. FPS: 16.13
Figure 7: Face recognition in video with OpenCV.
As you can see, our face detector is working! Our OpenCV face recognition pipeline is also obtaining ~16 FPS on my iMac. On my MacBook Pro I was getting ~14 FPS throughput rate.
Drawbacks, limitations, and how to obtain higher face recognition accuracy

Inevitably, you’ll run into a situation where OpenCV does not recognize a face correctly.
What do you do in those situations?
And how do you improve your OpenCV face recognition accuracy? In this section, I’ll detail a few of the suggested methods to increase the accuracy of your face recognition pipeline
You may need more data

My first suggestion is likely the most obvious one, but it’s worth sharing.
In my previous tutorial on face recognition, a handful of PyImageSearch readers asked why their face recognition accuracy was low and faces were being misclassified — the conversation went something like this (paraphrased):
Them: Hey Adrian, I am trying to perform face recognition on a dataset of my classmate’s faces, but the accuracy is really low. What can I do to increase face recognition accuracy?
Me: How many face images do you have per person?
Them: Only one or two.
Me: Gather more data.
I get the impression that most readers already know they need more face images when they only have one or two example faces per person, but I suspect they are hoping for me to pull a computer vision technique out of my bag of tips and tricks to solve the problem.
It doesn’t work like that.
If you find yourself with low face recognition accuracy and only have a few example faces per person, gather more data — there are no “computer vision tricks” that will save you from the data gathering process.
Invest in your data and you’ll have a better OpenCV face recognition pipeline. In general, I would recommend a minimum of 10-20 faces per person.
Note: You may be thinking, “But Adrian, you only gathered 6 images per person in today’s post!” Yes, you are right — and I did that to prove a point. The OpenCV face recognition system we discussed here today worked but can always be improved. There are times when smaller datasets will give you your desired results, and there’s nothing wrong with trying a small dataset — but when you don’t achieve your desired accuracy you’ll want to gather more data.
Perform face alignment

The face recognition model OpenCV uses to compute the 128-d face embeddings comes from the OpenFace project.
The OpenFace model will perform better on faces that have been aligned.
Face alignment is the process of:
- Identifying the geometric structure of faces in images.
- Attempting to obtain a canonical alignment of the face based on translation, rotation, and scale.
As you can see from Figure 9 at the top of this section, I have:
- Detected a faces in the image and extracted the ROIs (based on the bounding box coordinates).
- Applied facial landmark detection to extract the coordinates of the eyes.
- Computed the centroid for each respective eye along with the midpoint between the eyes.
- And based on these points, applied an affine transform to resize the face to a fixed size and dimension.
If we apply face alignment to every face in our dataset, then in the output coordinate space, all faces should:
- Be centered in the image.
- Be rotated such the eyes lie on a horizontal line (i.e., the face is rotated such that the eyes lie along the same y-coordinates).
- Be scaled such that the size of the faces is approximately identical.
Applying face alignment to our OpenCV face recognition pipeline was outside the scope of today’s tutorial, but if you would like to further increase your face recognition accuracy using OpenCV and OpenFace, I would recommend you apply face alignment.
Check out my blog post, Face Alignment with OpenCV and Python.
Tune your hyperparameters
My second suggestion is for you to attempt to tune your hyperparameters on whatever machine learning model you are using (i.e., the model trained on top of the extracted face embeddings).
For this tutorial, we used a Linear SVM; however, we did not tune the C value, which is typically the most important value of an SVM to tune.
The C value is a “strictness” parameter and controls how much you want to avoid misclassifying each data point in the training set.
Larger values of C will be more strict and try harder to classify every input data point correctly, even at the risk of overfitting.
Smaller values of C will be more “soft”, allowing some misclassifications in the training data, but ideally generalizing better to testing data.
It’s interesting to note that according to one of the classification examples in the OpenFace GitHub, they actually recommend to not tune the hyperparameters, as, from their experience, they found that setting C=1 obtains satisfactory face recognition results in most settings.
Still, if your face recognition accuracy is not sufficient, it may be worth the extra effort and computational cost of tuning your hyperparameters via either a grid search or random search.
Use dlib’s embedding model (but not it’s k-NN for face recognition)
In my experience using both OpenCV’s face recognition model along with dlib’s face recognition model, I’ve found that dlib’s face embeddings are more discriminative, especially for smaller datasets.
Furthermore, I’ve found that dlib’s model is less dependent on:
- Preprocessing such as face alignment
- Using a more powerful machine learning model on top of extracted face embeddings
If you take a look at my original face recognition tutorial, you’ll notice that we utilized a simple k-NN algorithm for face recognition (with a small modification to throw out nearest neighbor votes whose distance was above a threshold).
The k-NN model worked extremely well, but as we know, more powerful machine learning models exist.
To improve accuracy further, you may want to use dlib’s embedding model, and then instead of applying k-NN, follow Step #2 from today’s post and train a more powerful classifier on the face embeddings.
Did you encounter a “USAGE” error running today’s Python face recognition scripts?
Each week I receive emails that (paraphrased) go something like this:
Hi Adrian, I can’t run the code from the blog post.
My error looks like this:
usage: extract_embeddings.py [-h] -i DATASET -e EMBEDDINGS
-d DETECTOR -m EMBEDDING_MODEL [-c CONFIDENCE]
extract_embeddings.py: error: the following arguments are required:
-i/--dataset, -e/--embeddings, -d/--detector, -m/--embedding-model
Or this:
I’m using Spyder IDE to run the code. It isn’t running as I encounter a “usage” message in the command box.
There are three separate Python scripts in this tutorial, and furthermore, each of them requires that you (correctly) supply the respective command line arguments.
If you’re new to command line arguments, that’s fine, but you need to read up on how Python, argparse, and command line arguments work before you try to run these scripts!
I’ll be honest with you — face recognition is an advanced technique. Command line arguments are a very beginner/novice concept. Make sure you walk before you run, otherwise you will trip up. Take the time now to educate yourself on how command line arguments.
Secondly, I always include the exact command you can copy and paste into your terminal or command line and run the script. You might want to modify the command line arguments to accommodate your own image or video data, but essentially I’ve done the work for you. With a knowledge of command line arguments you can update the arguments to point to your own data, without having to modify a single line of code.
For the readers that want to use an IDE like Spyder or PyCharm my recommendation is that you learn how to use command line arguments in the command line/terminal first. Program in the IDE, but use the command line to execute your scripts.
I also recommend that you don’t bother trying to configure your IDE for command line arguments until you understand how they work by typing them in first. In fact, you’ll probably learn to love the command line as it is faster than clicking through a GUI menu to input the arguments each time you want to change them. Once you have a good handle on how command line arguments work, you can then configure them separately in your IDE.
From a quick search through my inbox, I see that I’ve answered over 500-1,000 of command line argument-related questions. I’d estimate that I’d answered another 1,000+ such questions replying to comments on the blog.
Don’t let me discourage you from commenting on a post or emailing me for assistance — please do. But if you are new to programming, I urge you to read and try the concepts discussed in my command line arguments blog post as that will be the tutorial I’ll link you to if you need help.
Alternative OpenCV face recognition methods
In this tutorial, you learned how to perform face recognition using OpenCV and a pre-trained FaceNet model.
Unlike our previous tutorial on deep learning-based face recognition, which utilized two other libraries/packages (dlib and face_recognition), the method covered here today utilizes just OpenCV, therefore removing other dependencies.
However, it’s worth noting that there are other methods that you can utilize when creating your own face recognition systems.
I suggest starting with siamese networks. Siamese networks are specialized deep learning models that:
- Can be successfully trained with very little data
- Learn a similarity score between two images (i.e., how similar two faces are)
- Are the cornerstone of modern face recognition systems
I have an entire series of tutorials on siamese networks that I suggest you read to become familiar with them:
- Building image pairs for siamese networks with Python
- Siamese networks with Keras, TensorFlow, and Deep Learning
- Comparing images for similarity using siamese networks, Keras, and TensorFlow
- Contrastive Loss for Siamese Networks with Keras and TensorFlow
Additionally, there are non-deep learning-based face recognition methods you may want to consider:
These methods are less accurate than their deep learning-based face recognition counterparts, but tend to be much more computationally efficient and will run faster on embedded systems.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we used OpenCV to perform face recognition.
Our OpenCV face recognition pipeline was created using a four-stage process:
- Create your dataset of face images
- Extract face embeddings for each face in the image (again, using OpenCV)
- Train a model on top of the face embeddings
- Use OpenCV to recognize faces in images and video streams
You can, of course, swap in your own face dataset provided you follow the directory structure of the project detailed above.
If you need help gathering your own face dataset, be sure to refer to this post on building a face recognition dataset.
I hope you enjoyed today’s tutorial on OpenCV face recognition!
To download the source code, models, and example dataset for this post join PyImageSearch University, our OpenCV and Face Detection Course

