In this tutorial you will learn how to use the Movidius NCS to speed up face detection and face recognition on the Raspberry Pi by over 243%!
If you’ve ever tried to perform deep learning-based face recognition on a Raspberry Pi, you may have noticed significant lag.
Is there a problem with the face detection or face recognition models themselves?
No, absolutely not.
The problem is that your Raspberry Pi CPU simply can’t process the frames quickly enough. You need more computational horsepower.
As the title to this tutorial suggests, we’re going to pair our Raspberry Pi with the Intel Movidius Neural Compute Stick coprocessor. The NCS Myriad processor will handle the more demanding face detection while the RPi CPU will handle extracting face embeddings. The RPi CPU processor will also handle the final machine learning classification using the results from the face embeddings.
The process of offloading the most expensive deep learning task to the Movidius NCS frees up the Raspberry Pi CPU to handle the other tasks. Each processor is then handling an appropriate load. We are certainly pushing our Raspberry Pi to the limit, but we don’t have much choice short of using a completely different single board computer such as an NVIDIA Jetson Nano.
By the end of this tutorial, you’ll have a fully functioning face recognition script running at 6.29FPS on the RPi and Movidius NCS, a 243% speedup compared to using just the RPi alone!
Note: This tutorial includes reposted content from my new Raspberry Pi for Computer Vision book (Chapter 14 of the Hacker Bundle). You can learn more and pick up your copy here.
To learn how to perform face recognition using the Raspberry Pi and Movidius Neural Compute Stick, just keep reading!
Raspberry Pi and Movidius NCS Face Recognition
In this tutorial, we will learn how to work with the Movidius NCS for face recognition.
First, you’ll need an understanding of deep learning face recognition using deep metric learning and how to create a face recognition dataset. Without understanding these two concepts, you may feel lost reading this tutorial.
Prior to reading this tutorial, you should read any of the following:
- Face Recognition with OpenCV, Python, and deep learning, my first blog post on deep learning face recognition.
- OpenCV Face Recognition, my second blog post on deep learning face recognition using a model that comes with OpenCV. This article also includes a section entitled “Drawbacks, limitations, and how to obtain higher face recognition accuracy” that I highly recommend reading.
- Raspberry Pi for Computer Vision‘s “Face Recognition on the Raspberry Pi” (Chapter 5 of the Hacker Bundle).
Additionally, you must read either of the following:
- How to build a custom face recognition dataset, a tutorial explaining three methods to build your face recognition dataset.
- Raspberry Pi for Computer Vision‘s “Step #1: Gather your dataset” (Chapter 5, Section 5.4.2 of the Hacker Bundle),
Upon successfully reading and understanding those resources, you will be prepared for Raspberry Pi and Movidius NCS face recognition.
In the remainder of this tutorial, we’ll begin by setting up our Raspberry Pi with OpenVINO, including installing the necessary software.
From there, we’ll review our project structure ensuring we are familiar with the layout of today’s downloadable zip.
We’ll then review the process of extracting embeddings for/with the NCS. We’ll train a machine learning model on top of the embeddings data.
Finally, we’ll develop a quick demo script to ensure that our faces are being recognized properly.
Let’s dive in.
Configuring your Raspberry Pi + OpenVINO environment

This tutorial requires a Raspberry Pi (3B+ or 4B is recommended) and Movidius NCS2 (or higher once faster versions are released in the future). Lower Raspberry Pi and NCS models may struggle to keep up. Another option is to use a capable laptop/desktop without OpenVINO altogether.
Configuring your Raspberry Pi with the Intel Movidius NCS for this project is admittedly challenging.
I suggest you (1) pick up a copy of Raspberry Pi for Computer Vision, and (2) flash the included pre-configured .img to your microSD. The .img that comes included with the book is worth its weight in gold as it will save you countless hours of toiling and frustration.
For the stubborn few who wish to configure their Raspberry Pi + OpenVINO on their own, here is a brief guide:
- Head to my BusterOS install guide and follow all instructions to create an environment named
cv. The Raspberry Pi 4B model (either 1GB, 2GB, or 4GB) is recommended. - Head to my OpenVINO installation guide and create a 2nd environment named
openvino. Be sure to use OpenVINO 4.1.1 as 4.1.2 has issues.
At this point, your RPi will have both a normal OpenCV environment as well as an OpenVINO-OpenCV environment. You will use the openvino environment for this tutorial.
Now, simply plug in your NCS2 into a blue USB 3.0 port (the RPi 4B has USB 3.0 for maximum speed) and start your environment using either of the following methods:
Option A: Use the shell script on my Pre-configured Raspbian .img (the same shell script is described in the “Recommended: Create a shell script for starting your OpenVINO environment” section of my OpenVINO installation guide).
From here on, you can activate your OpenVINO environment with one simple command (as opposed to two commands like in the previous step:
$ source ~/start_openvino.sh Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
Option B: One-two punch method.
Open a terminal and perform the following:
$ workon openvino $ source ~/openvino/bin/setupvars.sh
The first command activates our OpenVINO virtual environment. The second command sets up the Movidius NCS with OpenVINO (and is very important). From there we fire up the Python 3 binary in the environment and import OpenCV.
Both Option A and Option B assume that you either are using my Pre-configured Raspbian .img or that you followed my OpenVINO installation guide and installed OpenVINO with your Raspberry Pi on your own.
Caveats:
- Some versions of OpenVINO struggle to read .mp4 videos. This is a known bug that PyImageSearch has reported to the Intel team. Our preconfigured .img includes a fix — Abhishek Thanki edited the source code and compiled OpenVINO from source. This blog post is long enough as is, so I cannot include the compile-from-source instructions. If you encounter this issue please encourage Intel to fix the problem, and either (A) compile from source using our customer portal instructions, or (B) pick up a copy of Raspberry Pi for Computer Vision and use the pre-configured .img.
- We will add to this list if we discover other caveats.
Project Structure
Go ahead and grab today’s .zip from the “Downloads” section of this blog post and extract the files.
Our project is organized in the following manner:
|-- dataset | |-- abhishek | |-- adrian | |-- dave | |-- mcCartney | |-- sayak | |-- unknown |-- face_detection_model | |-- deploy.prototxt | |-- res10_300x300_ssd_iter_140000.caffemodel |-- face_embedding_model | |-- openface_nn4.small2.v1.t7 |-- output | |-- embeddings.pickle | |-- le.pickle | |-- recognizer.pickle |-- setupvars.sh |-- extract_embeddings.py |-- train_model.py |-- recognize_video.py
An example 5-person dataset/ is included. Each subdirectory contains 20 images for the respective person.
Our face detector will detect/localize a face in the image to be recognized. The pre-trained Caffe face detector files (provided by OpenCV) are included inside the face_detection_model/ directory. Be sure to refer to this deep learning face detection blog post to learn more about the detector and how it can be put to use.
We will extract face embeddings with a pre-trained OpenFace PyTorch model included in the face_embedding_model/ directory. The openface_nn4.small2.v1.t7 file was trained by the team at Carnegie Mellon University as part of the OpenFace project.
When we execute extract_embeddings.py, two pickle files will be generated. Both embeddings.pickle and le.pickle will be stored inside of the output/ directory if you so choose. The embeddings consist of a 128-d vector for each face in the dataset.
We’ll then train a Support Vector Machines (SVM) machine learning model on top of the embeddings by executing the train_model.py script. The result of training our SVM will be serialized to recognizer.pickle in the output/ directory.
Note: If you choose to use your own dataset (instead of the one I have supplied with the downloads), you should delete the files included in the output/ directory and generate new files associated with your own face dataset.
The recognize_video.py script simply activates your camera and detects + recognizes faces in each frame.
Our Environment Setup Script
Our Movidius face recognition system will not work properly unless an additional system environment variable, OPENCV_DNN_IE_VPU_TYPE , is set.
Be sure to set this environment variable in addition to starting your virtual environment.
This may change in future revisions of OpenVINO, but for now, a shell script is provided in the project associated with this tutorial.
Open up setup.sh and inspect the script:
#!/bin/sh export OPENCV_DNN_IE_VPU_TYPE=Myriad2
The “shebang” (#!) on Line 1 indicates that this script is executable.
Line 3 sets the environment variable using the export command. You could, of course, manually type the command in your terminal, but this shell script alleviates you from having to memorize the variable name and setting.
Let’s go ahead and execute the shell script:
$ source setup.sh
Provided that you have executed this script, you shouldn’t see any strange OpenVINO-related errors with the rest of the project.
If you encounter the following error message in the next section, be sure to execute setup.sh:
Traceback (most recent call last):
File "extract_embeddings.py", line 108 in
cv2.error: OpenCV(4.1.1-openvino) /home/jenkins/workspace/OpenCV/
OpenVINO/build/opencv/modules/dnn/src/opinfengine.cpp:477
error: (-215:Assertion failed) Failed to initialize Inference Engine
backend: Can not init Myriad device: NC_ERROR in function 'initPlugin'
Extracting Facial Embeddings with Movidius NCS
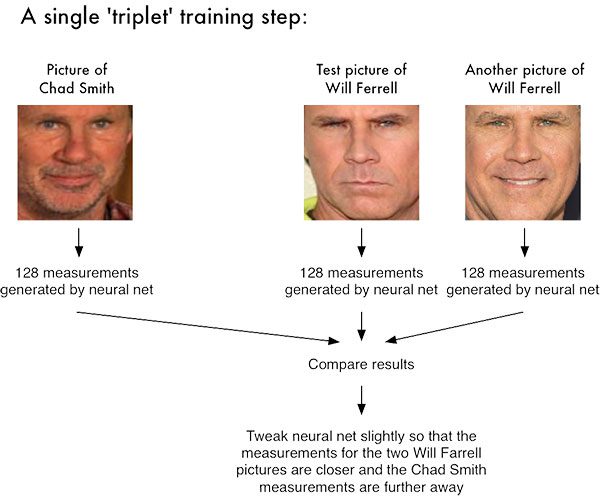
In order to perform deep learning face recognition, we need real-valued feature vectors to train a model upon. The script in this section serves the purpose of extracting 128-d feature vectors for all faces in your dataset.
Again, if you are unfamiliar with facial embeddings/encodings, refer to one of the three aforementioned resources.
Let’s open extract_embeddings.py and review:
# import the necessary packages
from imutils import paths
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--dataset", required=True,
help="path to input directory of faces + images")
ap.add_argument("-e", "--embeddings", required=True,
help="path to output serialized db of facial embeddings")
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
Lines 2-8 import the necessary packages for extracting face embeddings.
Lines 11-22 parse five command line arguments:
--dataset: The path to our input dataset of face images.--embeddings: The path to our output embeddings file. Our script will compute face embeddings which we’ll serialize to disk.--detector: Path to OpenCV’s Caffe-based deep learning face detector used to actually localize the faces in the images.--embedding-model: Path to the OpenCV deep learning Torch embedding model. This model will allow us to extract a 128-D facial embedding vector.--confidence: Optional threshold for filtering week face detections.
We’re now ready to load our face detector and face embedder:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
detector.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
# load our serialized face embedding model from disk and set the
# preferable target to MYRIAD
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
embedder.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
Here we load the face detector and embedder:
detector: Loaded via Lines 26-29. We’re using a Caffe-based DL face detector to localize faces in an image.embedder: Loaded on Line 33. This model is Torch-based and is responsible for extracting facial embeddings via deep learning feature extraction.
Notice that we’re using the respective cv2.dnn functions to load the two separate models. The dnn module is optimized by the Intel OpenVINO developers.
As you can see on Line 30 and Line 36 we call setPreferableTarget and pass the Myriad constant setting. These calls ensure that the Movidius Neural Compute Stick will conduct the deep learning heavy lifting for us.
Moving forward, let’s grab our image paths and perform initializations:
# grab the paths to the input images in our dataset
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(args["dataset"]))
# initialize our lists of extracted facial embeddings and
# corresponding people names
knownEmbeddings = []
knownNames = []
# initialize the total number of faces processed
total = 0
The imagePaths list, built on Line 40, contains the path to each image in the dataset. The imutils function, paths.list_images automatically traverses the directory tree to find all image paths.
Our embeddings and corresponding names will be held in two lists: (1) knownEmbeddings, and (2) knownNames (Lines 44 and 45).
We’ll also be keeping track of how many faces we’ve processed the total variable (Line 48).
Let’s begin looping over the imagePaths — this loop will be responsible for extracting embeddings from faces found in each image:
# loop over the image paths
for (i, imagePath) in enumerate(imagePaths):
# extract the person name from the image path
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# load the image, resize it to have a width of 600 pixels (while
# maintaining the aspect ratio), and then grab the image
# dimensions
image = cv2.imread(imagePath)
image = imutils.resize(image, width=600)
(h, w) = image.shape[:2]
We begin looping over imagePaths on Line 51.
First, we extract the name of the person from the path (Line 55). To explain how this works, consider the following example in a Python shell:
$ python >>> from imutils import paths >>> import os >>> datasetPath = "../datasets/face_recognition_dataset" >>> imagePaths = list(paths.list_images(datasetPath)) >>> imagePath = imagePaths[0] >>> imagePath 'dataset/adrian/00004.jpg' >>> imagePath.split(os.path.sep) ['dataset', 'adrian', '00004.jpg'] >>> imagePath.split(os.path.sep)[-2] 'adrian' >>>
Notice how by using imagePath.split and providing the split character (the OS path separator — “/ ” on Unix and “\ ” on non-Unix systems), the function produces a list of folder/file names (strings) which walk down the directory tree. We grab the second-to-last index, the person’s name, which in this case is adrian.
Finally, we wrap up the above code block by loading the image and resizing it to a known width (Lines 60 and 61).
Let’s detect and localize faces:
# construct a blob from the image imageBlob = cv2.dnn.blobFromImage( cv2.resize(image, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0), swapRB=False, crop=False) # apply OpenCV's deep learning-based face detector to localize # faces in the input image detector.setInput(imageBlob) detections = detector.forward()
On Lines 65-67, we construct a blob. A blob packages an image into a data structure compatible with OpenCV’s dnn module. To learn more about this process, read Deep learning: How OpenCV’s blobFromImage works.
From there we detect faces in the image by passing the imageBlob through the detector network (Lines 71 and 72).
And now, let’s process the detections:
# ensure at least one face was found
if len(detections) > 0:
# we're making the assumption that each image has only ONE
# face, so find the bounding box with the largest probability
j = np.argmax(detections[0, 0, :, 2])
confidence = detections[0, 0, j, 2]
# ensure that the detection with the largest probability also
# means our minimum probability test (thus helping filter out
# weak detection)
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, j, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI and grab the ROI dimensions
face = image[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
The detections list contains probabilities and bounding box coordinates to localize faces in an image. Assuming we have at least one detection, we’ll proceed into the body of the if-statement (Line 75).
We make the assumption that there is only one face in the image, so we extract the detection with the highest confidence and check to make sure that the confidence meets the minimum probability threshold used to filter out weak detections (Lines 78-84).
When we’ve met that threshold, we extract the face ROI and grab/check dimensions to make sure the face ROI is sufficiently large (Lines 87-96).
From there, we’ll take advantage of our embedder CNN and extract the face embeddings:
# construct a blob for the face ROI, then pass the blob # through our face embedding model to obtain the 128-d # quantification of the face faceBlob = cv2.dnn.blobFromImage(face, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False) embedder.setInput(faceBlob) vec = embedder.forward() # add the name of the person + corresponding face # embedding to their respective lists knownNames.append(name) knownEmbeddings.append(vec.flatten()) total += 1
We construct another blob, this time from the face ROI (not the whole image as we did before) on Lines 101 and 102.
Subsequently, we pass the faceBlob through the embedder CNN (Lines 103 and 104). This generates a 128-D vector (vec) which quantifies the face. We’ll leverage this data to recognize new faces via machine learning.
And then we simply add the name and embedding vec to knownNames and knownEmbeddings, respectively (Lines 108 and 109).
We also can’t forget about the variable we set to track the total number of faces either — we go ahead and increment the value on Line 110.
We continue this process of looping over images, detecting faces, and extracting face embeddings for each and every image in our dataset.
All that’s left when the loop finishes is to dump the data to disk:
# dump the facial embeddings + names to disk
print("[INFO] serializing {} encodings...".format(total))
data = {"embeddings": knownEmbeddings, "names": knownNames}
f = open(args["embeddings"], "wb")
f.write(pickle.dumps(data))
f.close()
We add the name and embedding data to a dictionary and then serialize it into a pickle file on Lines 113-117.
At this point we’re ready to extract embeddings by executing our script. Prior to running the embeddings script, be sure your openvino environment and additional environment variable is set if you did not do so in the previous section. Here is the quickest way to do it as a reminder:
$ source ~/start_openvino.sh Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings... $ source setup.sh
From there, open up a terminal and execute the following command to compute the face embeddings with OpenCV and Movidius:
$ python extract_embeddings.py \ --dataset dataset \ --embeddings output/embeddings.pickle \ --detector face_detection_model \ --embedding-model face_embedding_model/openface_nn4.small2.v1.t7 [INFO] loading face detector... [INFO] loading face recognizer... [INFO] quantifying faces... [INFO] processing image 1/120 [INFO] processing image 2/120 [INFO] processing image 3/120 [INFO] processing image 4/120 [INFO] processing image 5/120 ... [INFO] processing image 116/120 [INFO] processing image 117/120 [INFO] processing image 118/120 [INFO] processing image 119/120 [INFO] processing image 120/120 [INFO] serializing 116 encodings...
This process completed in 57s on a RPi 4B with an NCS2 plugged into the USB 3.0 port. You may notice a delay at the beginning as the model is being loaded. From there, each image will process very quickly.
Note: Typically I don’t recommend using the Raspberry Pi for extracting embeddings as the process can require significant time (a full-size, more-powerful computer is recommended for large datasets). Due to our relatively small dataset (120 images) and the extra “oomph” of the Movidius NCS, this process completed in a reasonable amount of time.
As you can see we’ve extracted 120 embeddings for each of the 120 face photos in our dataset. The embeddings.pickle file is now available in the output/ folder as well:
ls -lh output/*.pickle -rw-r--r-- 1 pi pi 66K Nov 20 14:35 output/embeddings.pickle
The serialized embeddings filesize is 66KB — embeddings files grow linearly according to the size of your dataset. Be sure to review the “How to obtain higher face recognition accuracy” section later in this tutorial about the importance of an adequately large dataset for achieving high accuracy.
Training an SVM model on Top of Facial Embeddings
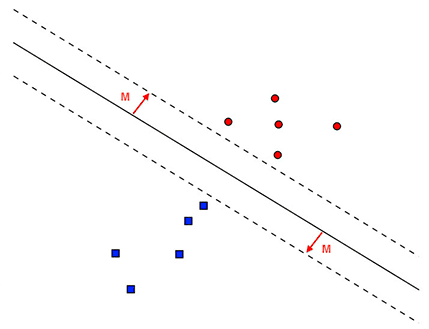
At this point we have extracted 128-d embeddings for each face — but how do we actually recognize a person based on these embeddings?
The answer is that we need to train a “standard” machine learning model (such as an SVM, k-NN classifier, Random Forest, etc.) on top of the embeddings.
For small datasets a k-Nearest Neighbor (k-NN) approach can be used for face recognition on 128-d embeddings created via the dlib (Davis King) and face_recognition (Adam Geitgey) libraries.
However, in this tutorial, we will build a more powerful classifier (Support Vector Machines) on top of the embeddings — you’ll be able to use this same method in your dlib-based face recognition pipelines as well if you are so inclined.
Open up the train_model.py file and insert the following code:
# import the necessary packages
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--embeddings", required=True,
help="path to serialized db of facial embeddings")
ap.add_argument("-r", "--recognizer", required=True,
help="path to output model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to output label encoder")
args = vars(ap.parse_args())
We import our packages and modules on Lines 2-6. We’ll be using scikit-learn’s implementation of Support Vector Machines (SVM), a common machine learning model.
Lines 9-16 parse three required command line arguments:
--embeddings: The path to the serialized embeddings (we saved them to disk by running the previousextract_embeddings.pyscript).--recognizer: This will be our output model that recognizes faces. We’ll be saving it to disk so we can use it in the next two recognition scripts.--le: Our label encoder output file path. We’ll serialize our label encoder to disk so that we can use it and the recognizer model in our image/video face recognition scripts.
Let’s load our facial embeddings and encode our labels:
# load the face embeddings
print("[INFO] loading face embeddings...")
data = pickle.loads(open(args["embeddings"], "rb").read())
# encode the labels
print("[INFO] encoding labels...")
le = LabelEncoder()
labels = le.fit_transform(data["names"])
Here we load our embeddings from our previous section on Line 20. We won’t be generating any embeddings in this model training script — we’ll use the embeddings previously generated and serialized.
Then we initialize our scikit-learn LabelEncoder and encode our name labels (Lines 24 and 25).
Now it’s time to train our SVM model for recognizing faces:
# train the model used to accept the 128-d embeddings of the face and
# then produce the actual face recognition
print("[INFO] training model...")
params = {"C": [0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0],
"gamma": [1e-1, 1e-2, 1e-3, 1e-4, 1e-5]}
model = GridSearchCV(SVC(kernel="rbf", gamma="auto",
probability=True), params, cv=3, n_jobs=-1)
model.fit(data["embeddings"], labels)
print("[INFO] best hyperparameters: {}".format(model.best_params_))
We are using a machine learning Support Vector Machine (SVM) with a Radial Basis Function (RBF) kernel, which is typically harder to tune than a linear kernel. Therefore, we will undergo a process known as “gridsearching”, a method to find the optimal machine learning hyperparameters for a model.
Lines 30-33 set our gridsearch parameters and perform the process. Notice that n_jobs=1. If you were utilizing a more powerful system, you could run more than one job to perform gridsearching in parallel. We are on a Raspberry Pi, so we will use a single worker.
Line 34 handles training our face recognition model on the face embeddings vectors.
Note: You can and should experiment with alternative machine learning classifiers. The PyImageSearch Gurus course covers popular machine learning algorithms in depth.
From here we’ll serialize our face recognizer model and label encoder to disk:
# write the actual face recognition model to disk f = open(args["recognizer"], "wb") f.write(pickle.dumps(model.best_estimator_)) f.close() # write the label encoder to disk f = open(args["le"], "wb") f.write(pickle.dumps(le)) f.close()
To execute our training script, enter the following command in your terminal:
$ python train_model.py --embeddings output/embeddings.pickle \
--recognizer output/recognizer.pickle --le output/le.pickle
[INFO] loading face embeddings...
[INFO] encoding labels...
[INFO] training model...
[INFO] best hyperparameters: {'C': 100.0, 'gamma': 0.1}
Let’s check the output/ folder now:
ls -lh output/*.pickle -rw-r--r-- 1 pi pi 66K Nov 20 14:35 output/embeddings.pickle -rw-r--r-- 1 pi pi 470 Nov 20 14:55 le.pickle -rw-r--r-- 1 pi pi 97K Nov 20 14:55 recognizer.pickle
With our serialized face recognition model and label encoder, we’re ready to recognize faces in images or video streams.
Real-Time Face Recognition in Video Streams with Movidius NCS
In this section we will code a quick demo script to recognize faces using your PiCamera or USB webcamera. Go ahead and open recognize_video.py and insert the following code:
# import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import pickle
import time
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--detector", required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-m", "--embedding-model", required=True,
help="path to OpenCV's deep learning face embedding model")
ap.add_argument("-r", "--recognizer", required=True,
help="path to model trained to recognize faces")
ap.add_argument("-l", "--le", required=True,
help="path to label encoder")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
Our imports should be familiar at this point.
Our five command line arguments are parsed on Lines 12-24:
--detector: The path to OpenCV’s deep learning face detector. We’ll use this model to detect where in the image the face ROIs are.--embedding-model: The path to OpenCV’s deep learning face embedding model. We’ll use this model to extract the 128-D face embedding from the face ROI — we’ll feed the data into the recognizer.--recognizer: The path to our recognizer model. We trained our SVM recognizer in the previous section. This model will actually determine who a face is.--le: The path to our label encoder. This contains our face labels such asadrianorunknown.--confidence: The optional threshold to filter weak face detections.
Be sure to study these command line arguments — it is critical that you know the difference between the two deep learning models and the SVM model. If you find yourself confused later in this script, you should refer back to here.
Now that we’ve handled our imports and command line arguments, let’s load the three models from disk into memory:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
detector = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
detector.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
# load our serialized face embedding model from disk and set the
# preferable target to MYRIAD
print("[INFO] loading face recognizer...")
embedder = cv2.dnn.readNetFromTorch(args["embedding_model"])
embedder.setPreferableTarget(cv2.dnn.DNN_BACKEND_OPENCV)
# load the actual face recognition model along with the label encoder
recognizer = pickle.loads(open(args["recognizer"], "rb").read())
le = pickle.loads(open(args["le"], "rb").read())
We load three models in this block. At the risk of being redundant, here is a brief summary of the differences among the models:
detector: A pre-trained Caffe DL model to detect where in the image the faces are (Lines 28-32).embedder: A pre-trained Torch DL model to calculate our 128-D face embeddings (Line 37 and 38).recognizer: Our SVM face recognition model (Line 41).
One and two are pre-trained deep learning models, meaning that they are provided to you as-is by OpenCV. The Movidius NCS will perform inference using only the detector (Line 32). The embedder is better if it run’s on the Pi CPU (Line 38).
The third recognizer model is not a form of deep learning. Rather, it is our SVM machine learning face recognition model. The RPi CPU will have to handle making face recognition predictions using it.
We also load our label encoder which holds the names of the people our model can recognize (Line 42).
Let’s initialize our video stream:
# initialize the video stream, then allow the camera sensor to warm up
print("[INFO] starting video stream...")
#vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# start the FPS throughput estimator
fps = FPS().start()
Line 47 initializes and starts our VideoStream object. We wait for the camera sensor to warm up on Line 48.
Line 51 initializes our FPS counter for benchmarking purposes.
Frame processing begins with our while loop:
# loop over frames from the video file stream while True: # grab the frame from the threaded video stream frame = vs.read() # resize the frame to have a width of 600 pixels (while # maintaining the aspect ratio), and then grab the image # dimensions frame = imutils.resize(frame, width=600) (h, w) = frame.shape[:2] # construct a blob from the image imageBlob = cv2.dnn.blobFromImage( cv2.resize(frame, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0), swapRB=False, crop=False) # apply OpenCV's deep learning-based face detector to localize # faces in the input image detector.setInput(imageBlob) detections = detector.forward()
We grab a frame from the webcam on Line 56. We resize the frame (Line 61) and then construct a blob prior to detecting where the faces are (Lines 65-72).
Given our new detections , let’s recognize faces in the frame. But, first we need to filter weak detections and extract the face ROI:
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with
# the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections
if confidence > args["confidence"]:
# compute the (x, y)-coordinates of the bounding box for
# the face
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# extract the face ROI
face = frame[startY:endY, startX:endX]
(fH, fW) = face.shape[:2]
# ensure the face width and height are sufficiently large
if fW < 20 or fH < 20:
continue
Here we loop over the detections on Line 75 and extract the confidence of each on Line 78.
Then we compare the confidence to the minimum probability detection threshold contained in our command line args dictionary, ensuring that the computed probability is larger than the minimum probability (Line 81).
From there, we extract the face ROI (Lines 84-89) as well as ensure it’s spatial dimensions are sufficiently large (Lines 92 and 93).
Recognizing the name of the face ROI requires just a few steps:
# construct a blob for the face ROI, then pass the blob # through our face embedding model to obtain the 128-d # quantification of the face faceBlob = cv2.dnn.blobFromImage(cv2.resize(face, (96, 96)), 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False) embedder.setInput(faceBlob) vec = embedder.forward() # perform classification to recognize the face preds = recognizer.predict_proba(vec)[0] j = np.argmax(preds) proba = preds[j] name = le.classes_[j]
First, we construct a faceBlob (from the face ROI) and pass it through the embedder to generate a 128-D vector which quantifies the face (Lines 98-102)
Then, we pass the vec through our SVM recognizer model (Line 105), the result of which is our predictions for who is in the face ROI.
We take the highest probability index and query our label encoder to find the name (Lines 106-108).
Note: You can further filter out weak face recognitions by applying an additional threshold test on the probability. For example, inserting if proba < T (where T is a variable you define) can provide an additional layer of filtering to ensure there are fewer false-positive face recognitions.
Now, let’s display face recognition results for this particular frame:
# draw the bounding box of the face along with the
# associated probability
text = "{}: {:.2f}%".format(name, proba * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(frame, text, (startX, y),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
# update the FPS counter
fps.update()
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# stop the timer and display FPS information
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
To close out the script, we:
- Draw a bounding box around the face and the person’s name and corresponding predicted probability (Lines 112-117).
- Update our
fpscounter (Line 120). - Display the annotated frame (Line 123) and wait for the
qkey to be pressed at which point we break out of the loop (Lines 124-128). - Stop our
fpscounter and print statistics in the terminal (Lines 131-133). - Cleanup by closing windows and releasing pointers (Lines 136 and 137).
Face Recognition with Movidius NCS Results
Now that we have (1) extracted face embeddings, (2) trained a machine learning model on the embeddings, and (3) written our face recognition in video streams driver script, let’s see the final result.
Ensure that you have followed the following steps:
- Step #1: Gather your face recognition dataset.
- Step #2: Extract facial embeddings (via the
extract_embeddings.pyscript). - Step #3: Train a machine learning model on the set of embeddings (such as Support Vector Machines per today’s example) using
train_model.py.
From there, set up your Raspberry Pi and Movidius NCS for face recognition:
- Connect your PiCamera or USB camera and configure either Line 46 or Line 47 of the realtime face recognition script (but not both) to start your video stream.
- Plug in your Intel Movidius NCS2 (the NCS1 is also compatible).
- Start your
openvinovirtual environment and set the key environment variable as shown below:
$ source ~/start_openvino.sh Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings... $ source setup.sh
Using OpenVINO 4.1.1 is critical. The newer 4.1.2 has a number of issues causing it to not work well.
From there, open up a terminal and execute the following command:
$ python recognize_video.py --detector face_detection_model \ --embedding-model face_embedding_model/openface_nn4.small2.v1.t7 \ --recognizer output/recognizer.pickle \ --le output/le.pickle [INFO] loading face detector... [INFO] loading face recognizer... [INFO] starting video stream... [INFO] elasped time: 60.30 [INFO] approx. FPS: 6.29
Note: Ensure that the version of scikit-learn you use for deployment matches the version you use for training. If the versions do not match, then you may encounter a problem when you try to load the model from disk. In particular, you may encounter AttributeError: 'SVC' object has no attribute '_n_support'. This is especially important if you are training on your laptop/desktop/cloud environment and deploying to a Raspberry Pi. It is very easy for the versions to be out of sync, so always be sure to check them in both places via pip freeze | grep scikit. To install a specific version in your environment, simply use this command: pip install scikit-learn==0.22.1, replacing the version as appropriate.
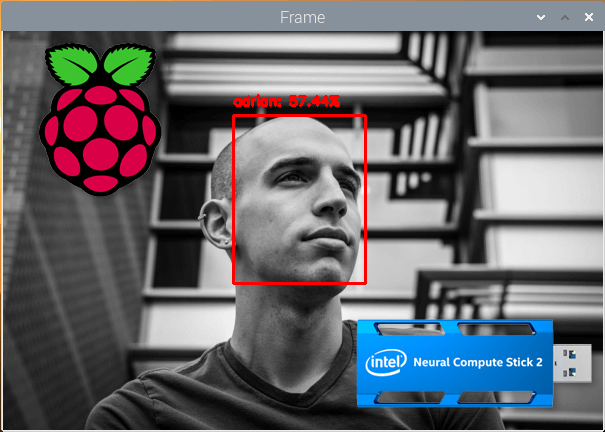
As you can see, faces have correctly been identified. What’s more, we are achieving 6.29 FPS using the Movidius NCS in comparison to 2.59 FPS using strictly the CPU. This comes out to a speedup of 243% using the RPi 4B and Movidius NCS2.
I asked PyImageSearch team member, Abhishek Thanki, to record a demo of our Movidius NCS face recognition in action. Below you can find the demo:
As you can see the combination of the Raspberry Pi and Movidius NCS is able to recognize Abhishek’s face in near real-time — using just the Raspberry Pi CPU alone would not be enough to obtain such speed.
My face recognition system isn’t recognizing faces correctly

As a reminder, be sure to refer to the following two resources:
- OpenCV Face Recognition includes a section entitled “Drawbacks, limitations, and how to obtain higher face recognition accuracy”.
- “How to obtain higher face recognition accuracy”, a section of Chapter 14, Face Recognition on the Raspberry Pi (Raspberry Pi for Computer Vision).
Both resources help you in situations where OpenCV does not recognize a face correctly.
In short, you may need:
- More data. This is the number one reason face recognition systems fail. I recommend 20-50 face images per person in your dataset as a general rule.
- To perform face alignment as each face ROI undergoes the embeddings process.
- To tune your machine learning classifier hyperparameters.
Again, if your face recognition system is mismatching faces or marking faces as “Unknown” be sure to spend time improving your face recognition system.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we used OpenVINO and our Movidius NCS to perform face recognition.
Our face recognition pipeline was created using a four-stage process:
- Step #1: Create your dataset of face images. You can, of course, swap in your own face dataset provided you follow the same dataset directory structure of today’s project.
- Step #2: Extract face embeddings for each face in the dataset.
- Step #3: Train a machine learning model (Support Vector Machines) on top of the face embeddings.
- Step #4: Utilize OpenCV and our Movidius NCS to recognize faces in video streams.
We put our Movidius NCS to work for only one of following deep learning tasks:
- Face detection: Localizing faces in an image (Movidius)
- Extracting face embeddings: Generating 128-D vectors which quantify a face numerically (CPU)
We then used the Raspberry Pi CPU to also handle the non-DL machine learning classifier used to make predictions on the 128-D embeddings.
It may seem like the CPU is doing more with two of the tasks, just keep in mind that deep learning face detection is a very computationally “expensive” operation.
This process of separating responsibilities allowed the CPU to call the shots, while employing the NCS for the heavy lifting. We achieved a speedup of 243% using the Movidius NCS for face recognition in video streams.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), just drop your email in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

