Table of Contents
Introduction to KV Cache Optimization Using Grouped Query Attention
Large language models excel at processing extensive contexts, enabling them to generate coherent essays, carry out multi-step reasoning, and maintain conversational threads over thousands of tokens. However, as sequence lengths grow, so do the computational and memory demands during autoregressive decoding. Engineers must balance maximizing context window size and staying within hardware limits.
At the heart of this challenge lies the key-value (KV) cache, which stores every past key and value tensor for each attention head, thereby avoiding redundant computations. While caching accelerates per-token generation, its memory footprint scales linearly with the number of attention heads, sequence length, and model depth. Left unchecked, KV cache requirements can balloon to tens of gigabytes, forcing trade-offs in batch size or context length.
Grouped Query Attention (GQA) offers a middle ground by reassigning multiple query heads to share a smaller set of KV heads. This simple yet powerful adjustment reduces KV cache size without a substantial impact on model accuracy.
In this post, we’ll explore the fundamentals of KV cache, compare attention variants, derive memory-savings math, walk through code implementations, and share best-practice tips for tuning and deploying GQA-optimized models.
This lesson is the 1st of a 3-part series on LLM Inference Optimization — KV Cache:
- Introduction to KV Cache Optimization Using Grouped Query Attention (this tutorial)
- KV Cache Optimization via Multi-Head Latent Attention
- KV Cache Optimization via Tensor Product Attention
To learn how to optimize KV Cache using Grouped Query Attention, just keep reading.
Understanding the KV Cache
Transformers compute, for each token in a sequence, three projections: queries  , keys
, keys  , and values
, and values  . During autoregressive generation, at step
. During autoregressive generation, at step  , the model must attend to all previous tokens
, the model must attend to all previous tokens  .
.
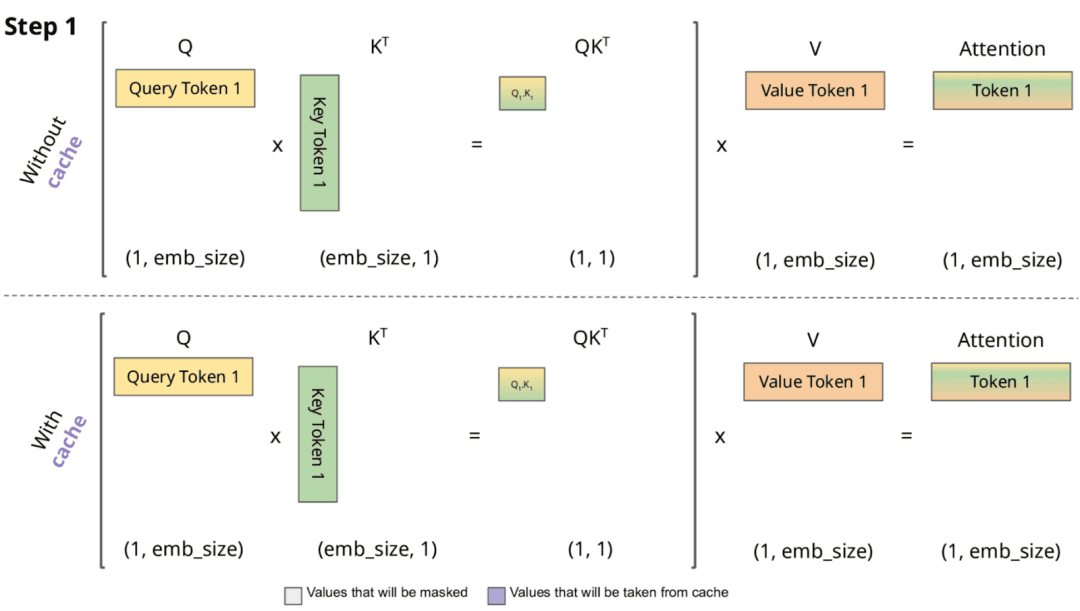
Without caching, one would recompute
} = X^{(\ell)} W_K,\quad V^{(\ell)} = X^{(\ell)} W_V")
for every layer  and every past token — an
and every past token — an ") cost per token that quickly becomes prohibitive.
cost per token that quickly becomes prohibitive.
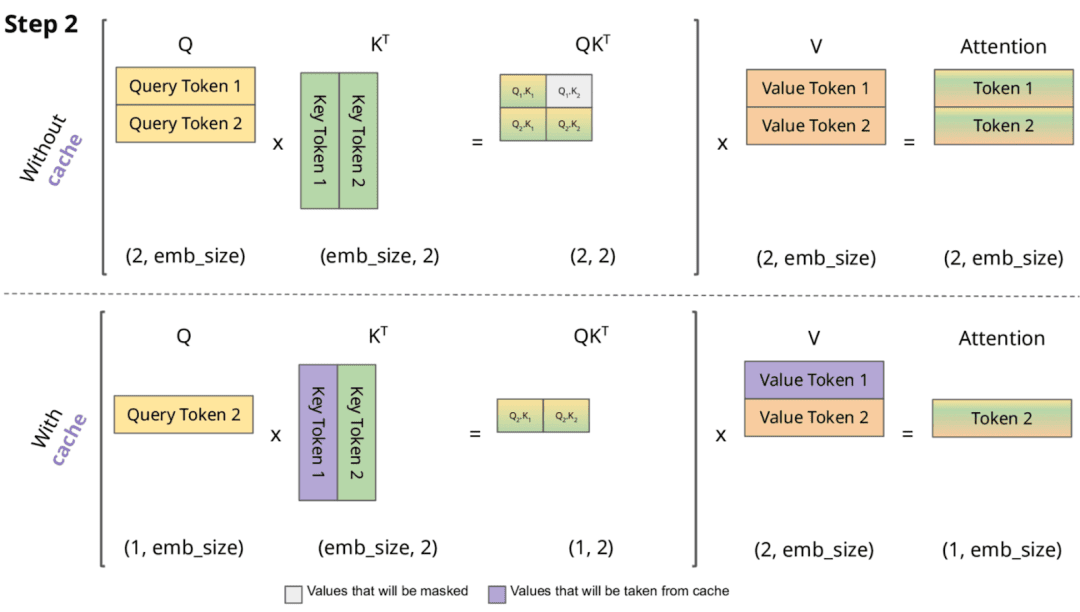
KV caching sidesteps this by storing the past keys and values in memory as they are first computed, so that at step , the model only needs to compute
}_t = x_t W_Q")
and then perform attention against the cached }_{1:t-1},V^{(\ell)}_{1:t-1}}") (Figures 1 and 2).
(Figures 1 and 2).
Because each attention head  at layer maintains its own key and value sequences of dimension
at layer maintains its own key and value sequences of dimension  , the cache for that head and layer grows linearly in the context length
, the cache for that head and layer grows linearly in the context length  .
.
Concretely, if there are  attention heads, and we store both keys and values in 2 bytes (FP16) per element, the per-layer KV cache size is
attention heads, and we store both keys and values in 2 bytes (FP16) per element, the per-layer KV cache size is
.")
Over  layers and a batch of size
layers and a batch of size  , the total KV cache requirement becomes
, the total KV cache requirement becomes

Beyond raw storage, each new token’s attention computation must scan through the entire cached sequence, yielding a compute cost proportional to

Thus, both memory bandwidth (reading , ) and computation (dot-product of against all cached keys) scale linearly with the growing context.
KV caching dramatically reduces the work of recomputing () and (), but it also makes the cache’s size and layout a first-class concern when pushing context windows into the thousands of tokens.
Grouped Query Attention
What Is Grouped Query Attention?
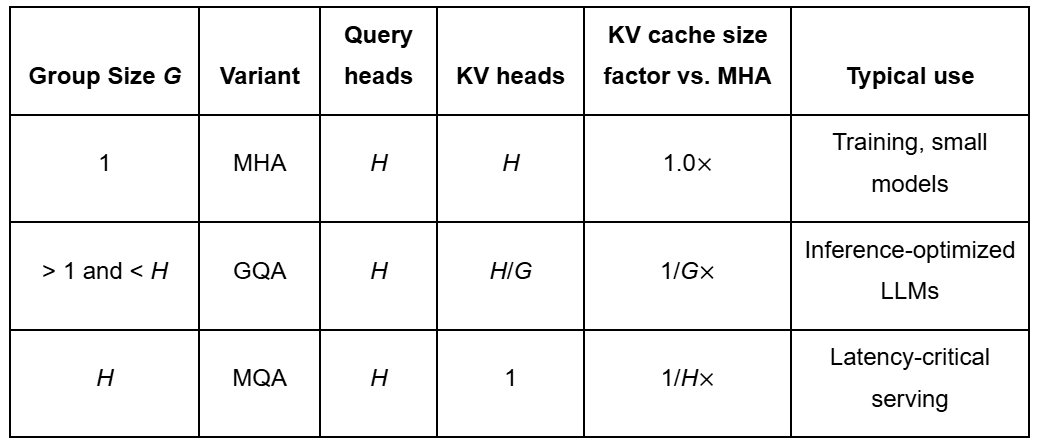
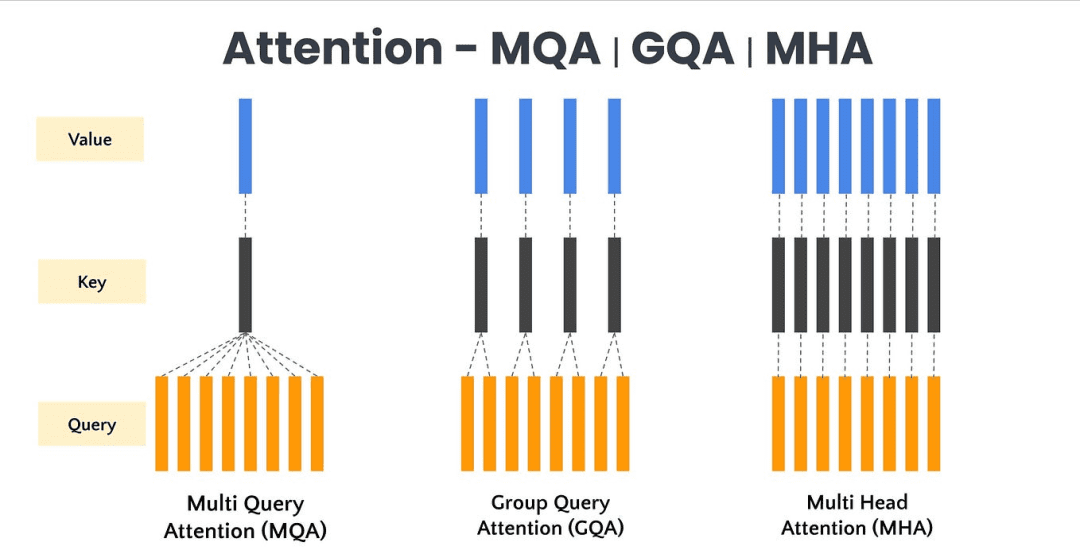
Grouped Query Attention (GQA) modifies the standard multi-head attention (MHA) by having multiple query heads share a reduced set of key and value heads (Figure 3).
In vanilla MHA, the number of key heads  and value heads
and value heads  equals the number of query heads
equals the number of query heads  :
:

GQA introduces a grouping factor  so that
so that

meaning each group of query heads attends to a single shared key and value head.
Despite this sharing, the query projections remain one per head:
},\quad i=1,\dots,H_q.")
Keys and values are computed only per group: for group index /G\bigr\rfloor+1") , we have
, we have
},\quad V_j = X W_V^{(j)}.")
During attention, each query head  uses the shared pair
uses the shared pair ") :
:
 =\text{softmax} \left(\dfrac{Q_i K_j^\top}{\sqrt{d_{\text{head}}}}\right) V_j.")
By cutting the number of key and value projections from  to
to  , GQA reduces both the parameter count in
, GQA reduces both the parameter count in  and
and  and the memory needed to store their outputs, while leaving the overall model dimension and final output projection unchanged.
and the memory needed to store their outputs, while leaving the overall model dimension and final output projection unchanged.
Based on different values of , we can categorize attention into the following types (Table 1):
How Grouped Query Attention Reduces KV Cache?
The KV cache stores past key and value tensors of shape ![[T\times d_{\text{head}}]](https://b2633864.smushcdn.com/2633864/wp-content/latex/341/34197615c404759fe8a2a01c44b308ce-ffffff-000000-0.png?size=72x18&lossy=2&strip=1&webp=1 "[T\times d_{\text{head}}]") for each head, where is the current context length, and
for each head, where is the current context length, and  is the bytes per element (e.g., 2 for FP16).
is the bytes per element (e.g., 2 for FP16).
In standard MHA, the per-layer cache memory is

Under GQA, only  key and value heads are stored, giving
key and value heads are stored, giving

Thus, the cache size shrinks by a factor of ():

Importantly, the compute cost of the dot-product attention — proportional to  — stays the same.
— stays the same.
This decouples memory bandwidth from FLOPs, so reducing the cache directly translates to faster long-context inference without altering per-token computational load.
Implementing KV Caching via Grouped Query Attention
In this section, we will see how using Grouped Query Attention improves the inference time and KV Cache size. For simplicity, we will implement a toy transformer model with 1 layer of a Grouped Query Attention layer.
Grouped Query Attention
We will start by implementing the Grouped Query Attention in PyTorch.
import torch
import torch.nn as nn
import time
import matplotlib.pyplot as plt
class GroupedQueryAttention(nn.Module):
def __init__(self, hidden_dim, num_heads, group_size=1):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
self.group_size = group_size
self.kv_heads = num_heads // group_size
self.head_dim = hidden_dim // num_heads
self.q_proj = nn.Linear(hidden_dim, hidden_dim)
self.k_proj = nn.Linear(hidden_dim, self.kv_heads * self.head_dim)
self.v_proj = nn.Linear(hidden_dim, self.kv_heads * self.head_dim)
self.out_proj = nn.Linear(hidden_dim, hidden_dim)
def forward(self, x, kv_cache):
batch_size, seq_len, _ = x.size()
# Project queries, keys, values
q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(batch_size, seq_len, self.kv_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(batch_size, seq_len, self.kv_heads, self.head_dim).transpose(1, 2)
# Append to cache
kv_cache['k'] = torch.cat([kv_cache['k'], k], dim=2)
kv_cache['v'] = torch.cat([kv_cache['v'], v], dim=2)
# Expand KV heads to match query heads
k_exp = kv_cache['k'].repeat_interleave(self.group_size, dim=1)
v_exp = kv_cache['v'].repeat_interleave(self.group_size, dim=1)
# Scaled dot-product attention
scores = torch.matmul(q, k_exp.transpose(-2, -1)) / (self.head_dim ** 0.5)
weights = torch.nn.functional.softmax(scores, dim=-1)
attn_output = torch.matmul(weights, v_exp)
# Merge heads
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.hidden_dim)
return self.out_proj(attn_output), kv_cache
We define a grouped query attention module on Lines 6-13. Here, we inherit from nn.Module and capture the main dimensions: hidden_dim, num_heads, and group_size. We compute kv_heads = num_heads // group_size to determine how many key and value heads we’ll actually project, and head_dim = hidden_dim // num_heads as the dimension per query head.
On Lines 15-18, we instantiate four linear layers: one each for projecting queries (q_proj), keys (k_proj), and values (v_proj), and a final out_proj to recombine the attended outputs back into the model’s hidden space.
On Lines 20-27, the forward method begins by unpacking batch_size and seq_len from the input tensor x. We then project x into queries, keys, and values. Queries are shaped into (batch, num_heads, seq_len, head_dim) on Line 24, while keys and values use (batch, kv_heads, seq_len, head_dim) on Lines 25 and 26.
On Lines 29 and 30, we append these newly computed key and value tensors along the time dimension into kv_cache, preserving all past context for autoregressive decoding.
Next, we align the cached key and value heads to match the number of query heads. On Lines 33 and 34, we use repeat_interleave to expand each group’s cached (, ) from kv_heads to num_heads so every query head can attend.
On Lines 37-39, we implement scaled dot-product attention: we compute raw scores via q @ k_expᵀ divided by √head_dim, apply softmax to obtain attention weights, and then multiply by v_exp to produce the attended outputs.
Finally, on Lines 41-43, we merge the per‐head outputs back to (batch, seq_len, hidden_dim) and pass them through out_proj, returning both the updated attention output and the expanded kv_cache.
Toy Transformer and Inference
Now that we have implemented the grouped query attention module, we will implement a 1-layer toy Transformer block that takes a sequence of input tokens, along with KV Cache, and performs one feedforward pass.
class TransformerBlock(nn.Module):
def __init__(self, hidden_dim, num_heads, group_size=1):
super().__init__()
self.attn = GroupedQueryAttention(hidden_dim, num_heads, group_size)
self.norm1 = nn.LayerNorm(hidden_dim)
self.ff = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim * 4),
nn.ReLU(),
nn.Linear(hidden_dim * 4, hidden_dim)
)
self.norm2 = nn.LayerNorm(hidden_dim)
def forward(self, x, kv_cache):
attn_out, kv_cache = self.attn(x, kv_cache)
x = self.norm1(x + attn_out)
ff_out = self.ff(x)
x = self.norm2(x + ff_out)
return x, kv_cache
We define a TransformerBlock class on Lines 1-11, where the constructor wires together a grouped MultiHeadAttention layer (self.attn), two LayerNorms (self.norm1 and self.norm2), and a two-layer feed-forward network (self.ff) that expands the hidden dimension by 4× and then projects it back.
On Lines 13-18, the forward method takes input x and the kv_cache, runs x through the attention module to get attn_out and an updated cache, then applies a residual connection plus layer norm (x = norm1(x + attn_out)).
Next, we feed this through the FFN, add another residual connection, normalize again (x = norm2(x + ff_out)), and finally return the transformed hidden states alongside the refreshed kv_cache.
The code below runs an inference to generate a sequence of tokens in an autoregressive manner.
def run_inference(block, group_size=1):
hidden_dim = block.attn.hidden_dim
num_heads = block.attn.num_heads
seq_lengths = list(range(1, 101, 10))
kv_cache_sizes = []
inference_times = []
kv_cache = {
'k': torch.empty(1, num_heads // group_size, 0, hidden_dim // num_heads),
'v': torch.empty(1, num_heads // group_size, 0, hidden_dim // num_heads)
}
for seq_len in seq_lengths:
x = torch.randn(1, 1, hidden_dim) # One token at a time
start = time.time()
_, kv_cache = block(x, kv_cache)
end = time.time()
size = kv_cache['k'].numel() + kv_cache['v'].numel()
kv_cache_sizes.append(size)
inference_times.append(end - start)
return seq_lengths, kv_cache_sizes, inference_times
On Lines 1-6, we define run_inference, pull out hidden_dim and num_heads, and build a list of target seq_lengths (1 to 101 in steps of 10), along with empty lists for kv_cache_sizes and inference_times.
On Lines 8-11, we initialize kv_cache with empty tensors for 'k' and 'v' of shape [1, num_heads//group_size, 0, head_dim] so it can grow as we generate tokens.
Then, in the loop over each seq_len on Lines 13-17, we simulate feeding one random token x at a time into the transformer block, timing the forward pass, and updating kv_cache.
Finally, on Lines 19-23, we measure the total number of elements in the cached keys and values, append that to kv_cache_sizes, record the elapsed time to inference_times, and then return all three lists for plotting or analysis.
Experiments and Analysis
Finally, we will test our implementation of grouped query attention with different group sizes .
For each group size, we will plot the size of the KV Cache and inference time as a function of sequence length.
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
for group_size in [1, 2, 4, 8, 16, 32]:
gqa_block = TransformerBlock(hidden_dim=4096, num_heads=32, group_size=group_size)
seq_lengths, sizes, times = run_inference(gqa_block, group_size=group_size)
plt.plot(seq_lengths, sizes, label="GQA : {}".format(group_size))
plt.xlabel("Generated Tokens")
plt.ylabel("KV Cache Size")
plt.title("KV Cache Growth")
plt.legend()
plt.subplot(1, 2, 2)
for group_size in [1, 2, 4, 8, 16, 32]:
gqa_block = TransformerBlock(hidden_dim=4096, num_heads=32, group_size=group_size)
seq_lengths, sizes, times = run_inference(gqa_block, group_size=group_size)
plt.plot(seq_lengths, times, label="GQA : {}".format(group_size))
plt.xlabel("Generated Tokens")
plt.ylabel("Inference Time (s)")
plt.title("Inference Speed")
plt.legend()
plt.tight_layout()
plt.show()
On Lines 1 and 2, we set up a 12×5-inch figure and declare the first subplot for KV cache growth.
Between Lines 4-7, we loop over various group_size values, instantiate a TransformerBlock for each, call run_inference to gather sequence lengths and cache sizes, and plot the KV cache size versus the number of generated tokens.
On Lines 14-18, we switch to the second subplot, repeat the loop to collect and plot inference times against token counts, and finally, on Lines 21-28, we set axis labels, add a title and legend, tighten the layout, and call plt.show() to render both charts (Figure 4).
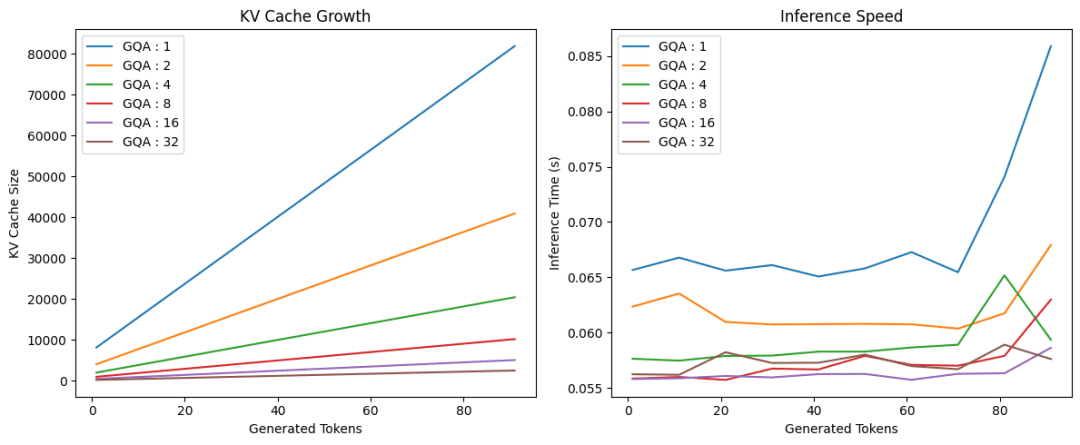
As shown in Figure 4, using grouped query attention significantly reduces the KV cache size and inference time compared to vanilla multihead self-attention (group size 1).
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
We begin by framing the challenge of long‐context inference in transformer models. As sequence lengths grow, storing past key and value tensors in the KV cache becomes a major memory and bandwidth bottleneck. To address this, we introduce Grouped Query Attention (GQA), an architectural modification that enables multiple query heads to share a smaller set of key-value heads, thereby reducing the cache footprint with minimal impact on accuracy.
Next, we unpack the mechanics of KV caching — why transformers store per‐head key and value sequences, how cache size scales with head count , context length , and model depth , and the resulting latency pressure from reading large caches each token. We then formally define GQA, showing how the grouping factor reduces the number of KV projections from to  and yields a
and yields a  reduction in cache memory. We illustrate this with equations and intuitive diagrams, contrasting vanilla multi‐head attention, multi‐query attention, and the GQA middle ground.
reduction in cache memory. We illustrate this with equations and intuitive diagrams, contrasting vanilla multi‐head attention, multi‐query attention, and the GQA middle ground.
Finally, we walk through a hands-on implementation: building a toy TransformerBlock in PyTorch that supports arbitrary GQA groupings, wiring up KV cache growth, and running inference experiments across group sizes. We plot how cache size and per-token inference time evolve for  , analyze the memory-latency trade-off, and distill practical guidelines for choosing and integrating GQA into real-world LLM deployments.
, analyze the memory-latency trade-off, and distill practical guidelines for choosing and integrating GQA into real-world LLM deployments.
Citation Information
Mangla, P. “Introduction to KV Cache Optimization Using Grouped Query Attention,” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/b241m
@incollection{Mangla_2025_intro-to-kv-cache-optimization-using-grouped-query-attention,
author = {Puneet Mangla},
title = {{Introduction to KV Cache Optimization Using Grouped Query Attention}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
year = {2025},
url = {https://pyimg.co/b241m},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.