Table of Contents
- Harnessing Power at the Edge: An Introduction to Local Large Language Models
- Introduction to Large Language Models (LLMs)
- What Are Large Language Models?
- Historical Context and Technological Evolution
- Key Training Methodologies
- Broad Spectrum of Applications
- Future Prospects and Ethical Considerations
- Introduction to Local LLMs
- The Emergence of Local LLMs
- Advantages of Local LLMs
- Technical Considerations for Local Deployment
- The Future of Local LLMs
- Common Model Formats for LLMs
- PyTorch Models
- SafeTensors
- GGML and GGUF
- Background and Development of GGML
- Transition to GGUF
- Key Features and Benefits of GGUF
- Practical Implications and Framework Support
- Advantages and Challenges
- Conclusion
- Generalized Post-Training Quantization
- Introduction to Generalized Post-Training Quantization
- Quantization Process
- GPTQ’s Impact on LLMs
- Research and Development
- AutoGPTQ Library
- Conclusion
- AWQ
- Frameworks for Local LLMs
- Final Perspectives on Local LLM Ecosystem
- GPTQ Format Model Implementations
- GGUF Model Usage
- User Interfaces for Non-Technical Users
- Personal Recommendations
- Summary
Harnessing Power at the Edge: An Introduction to Local Large Language Models
Why pay a monthly fee when you can run powerful bots equivalent to ChatGPT on your local machine?

In this series, we will embark on an in-depth exploration of Local Large Language Models (LLMs), focusing on the array of frameworks and technologies that empower these models to function efficiently at the network’s edge. Each installment of the series will explore a different framework that enables Local LLMs, detailing how to configure it on our workstations, feed prompts and data to generate actionable insights, perform retrieval-augmented generations, and much more. We will discuss each framework’s architecture, usability, and applications in real-world scenarios in depth.
In today’s post, we’ll start by discussing what Local LLMs are, exploring their advantages and limitations, and explaining why their deployment is becoming increasingly essential for localized, real-time AI processing. After establishing this foundation, we will then delve into a handful of prominent Local LLM frameworks currently available in the market. Join us as we navigate through the transformative landscape of local data processing and decision-making enhanced by LLMs.
This lesson is the 1st in a 4-part series on Local LLMs:
- Harnessing Power at the Edge: An Introduction to Local Large Language Models (this tutorial)
- Lesson 2
- Lesson 3
- Lesson 4
To learn about Local LLMs, their advantages and limitations, and the different frameworks available, just keep reading.
Introduction to Large Language Models (LLMs)
In the rapidly evolving landscape of artificial intelligence (AI), Large Language Models (LLMs) have emerged as one of the most transformative technologies, particularly in the field of natural language processing (NLP). These models, built on sophisticated neural network architectures, are designed to understand, interpret, and generate human-like text, opening new frontiers in AI applications. This section delves into the intricacies of LLMs, exploring their development, functionality, and the profound impact they have on various industries.
What Are Large Language Models?
Large Language Models (LLMs) are advanced AI systems trained on extensive datasets comprising text from a myriad of sources, including books, articles, websites, and other digital content. These models use architectures like Transformer, a deep learning model introduced in 2017. Transformer relies on self-attention mechanisms to process words in relation to all other words in a sentence, thereby capturing nuances of language that were previously elusive. This capability allows LLMs to generate text that is not only coherent but also contextually relevant to the input provided.
Historical Context and Technological Evolution
The journey of LLMs began with foundational models such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). These models laid the groundwork for the development of more sophisticated systems. Today, models like GPT-3, which features over 175 billion parameters, and its even more advanced successors, exemplify the pinnacle of current LLM technology. Training such models requires an enormous amount of computational power and data, making it a resource-intensive endeavor.
This comprehensive timeline presents a visual representation of the key milestones in the evolution of Large Language Models. It begins with the advent of models like GPT-3, which set the stage for the future of automated language processing. Moving through the timeline, we observe a proliferation of models from various tech giants and research institutions, each contributing unique enhancements and specializations.
The image categorizes models by year, showing a clear trajectory of advancement and complexity. Notable mentions include T5 and BERT, which introduced new methodologies for understanding context and semantics. The timeline also includes industry-specific models like Codex and AlphaCode, which are tailored for programming-related tasks.
As we approach the present, the timeline introduces models such as ChatGPT and GPT-4, which incorporate more profound learning capabilities and broader contextual understanding. The diversity of models reflects the specialized needs of different sectors, from web-based applications to more technical, research-oriented tasks. Each model is a stepping stone toward more sophisticated, nuanced, and ethically aware AI communication tools.

The Development of OpenAI’s Generative Pre-Trained Transformers
This timeline chart traces the pivotal developments in OpenAI’s generative pre-trained transformers, commencing with the debut of GPT-1 in June 2018. GPT-1 was notable for its decoder-only architecture and its pioneering approach to generative pre-training. Advancing to GPT-2, which was unveiled in February 2019, we witnessed an upscaling in the model’s size and an enhancement in its multitasking learning capabilities. May 2020 marked the arrival of GPT-3, which further expanded the horizons of in-context learning and tested the limits of scaling with an unprecedented number of parameters.
The progression continued with the inception of Codex in July 2021, an AI tailored for understanding and generating code, paving the way for specialized iterations like code-davinci-002. The davinci series progressed, with text-davinci-002 advancing instruction-following capabilities, text-davinci-003 aiming for human alignment, and later models augmenting chat functionalities and overall comprehension.
March 2023 introduced GPT-3.5 as a bridge to the more sophisticated GPT-4, which boasted enhanced reasoning skills. This was quickly followed by variants like GPT-4 Turbo, offering an extended context window, and GPT-4 Turbo with vision, bringing in multimodal capabilities — both launched in September 2023. These iterations underscore OpenAI’s commitment to refining the complexity and real-world utility of their language models.
Accompanying the timeline is a visual guide illustrating the developmental trajectory of OpenAI’s models. Solid lines denote direct and explicitly stated evolution paths between models, as per official announcements. For example, the solid line connecting GPT-2 to GPT-3 indicates a directly acknowledged progression. Conversely, dashed lines suggest a less definitive evolutionary link, signifying observed technological progress that may not have been formally documented as a direct lineage by OpenAI.
Understanding these nuances is key to appreciating the deliberate and methodical advancement of each model. While GPT-3’s direct descent from GPT-2 is well-documented, the dashed line from GPT-1 to GPT-2 implies an evolutionary step that is inferred from technological strides rather than explicitly delineated by OpenAI.

Key Training Methodologies
Training LLMs involves two major stages: pre-training and fine-tuning. During pre-training, the model learns a broad understanding of language by predicting words in sentences from the training corpus. Fine-tuning adjusts the model’s parameters to specific tasks, such as question answering or text summarization, using smaller, task-specific datasets. This method of training allows LLMs to adapt to a wide range of applications without losing the general language understanding acquired during pre-training.
Broad Spectrum of Applications
The versatility of LLMs enables their use in a diverse array of applications:
- Content Generation: LLMs assist in composing textual content, from fictional stories to marketing copy, dramatically reducing the time and effort required by human creators.
- Customer Service: They power sophisticated chatbots that offer personalized customer interactions, capable of handling complex queries with ease.
- Programming and Code Generation: Tools like GitHub’s Copilot utilize LLMs to suggest code snippets and entire functions, helping programmers write code more efficiently.
- Translation and Localization: LLMs provide fast and accurate translation services that are crucial for global communication, supporting a multitude of languages and dialects.
- Education and Tutoring: In education, these models can personalize learning by providing tutoring or generating practice tests tailored to the student’s level.
Future Prospects and Ethical Considerations
The potential future developments of LLMs are boundless, with ongoing research aiming to enhance their efficiency, accuracy, and generalizability. However, the deployment of these models also raises significant ethical concerns. Issues such as data privacy, model bias, and the generation of misleading information are critical challenges that researchers and developers continue to address. Additionally, the environmental impact of training large-scale models is a growing concern, prompting a search for more sustainable AI practices.
Introduction to Local LLMs
The landscape of machine learning and, more specifically, the utilization of Large Language Models (LLMs) is experiencing a paradigm shift. Initially, the use of LLMs was largely dominated by cloud-based services, where the computational load of running such expansive models was handled by powerful remote servers. However, there is a growing trend toward the deployment and usage of LLMs on local infrastructures. This movement is driven by various factors, including concerns over data privacy, the need for lower latency, and the desire for greater control over the models. This “Shift to Local LLMs” signifies a substantial turn in how organizations and individuals leverage these powerful AI tools.
The conversation around AI has begun to pivot from cloud reliance to embracing the feasibility and independence of local LLMs. The allure of steering clear of subscription models and having unrestricted usage of AI tools has led to a surge in interest in local deployment. This not only aligns with a cost-saving approach but also champions privacy and immediate access — attributes highly valued in our current technological climate.
The Emergence of Local LLMs
Local LLMs refer to instances where the large language models are deployed directly on-premises or on local machines and servers. This enables direct access to the computational capabilities required to run these models without the need for constant internet connectivity or reliance on external cloud providers.
Advantages of Local LLMs
Data Privacy and Security
Local deployment of LLMs offers enhanced data security and privacy since sensitive information does not need to traverse the internet or be stored on external servers. This is critically important for industries like healthcare and finance, where data confidentiality is paramount.
Low Latency
Organizations can significantly reduce latency by running LLMs locally. The immediate availability of computational resources translates into quicker responses, which is vital for applications that demand real-time processing, such as automated trading systems or emergency response services.
Cost
Shifting to local LLMs eliminates the costs associated with cloud-hosted APIs and the infrastructure typically required for LLM inference. Organizations can directly utilize their existing compute resources, thereby reducing operational expenses and leveraging investments in their own hardware.
Always-on Availability
Local LLMs ensure that the capabilities of these models are always accessible, independent of network connectivity. This is especially advantageous in environments where high-bandwidth connections are unreliable or unavailable, allowing users to maintain productivity with uninterrupted AI assistance.
These advantages collectively forge a path to a more autonomous and resilient AI infrastructure, ensuring that organizations and users can enjoy the power of Large Language Models with the added advantages of cost-efficiency, privacy, control, and uninterrupted access.
Technical Considerations for Local Deployment
Deploying LLMs locally requires addressing several technical considerations.
Hardware
Significant hardware investments are necessary to facilitate the computation-heavy workload of LLMs. This includes high-end GPUs and specialized neural network processors.
Maintenance
Locally deployed LLMs require a dedicated team to manage and update the models, handle data security, and ensure the infrastructure’s integrity.
Scalability
As the demand for AI’s computational power grows, scaling local hardware can be challenging and expensive compared to scalable cloud solutions.
Framework Support and Accessibility
It’s important to note that there are numerous frameworks available that are compatible with various operating systems (e.g., Windows, Linux, and macOS), and they support a wide range of hardware from AMD, NVIDIA, and Apple M series GPUs. Many of these Local LLM frameworks have matured significantly, making LLMs more accessible and easier to run than ever before. We will discuss these frameworks at a high level today, highlighting their ease of use and robustness. This diversity in support ensures that regardless of your specific environment or hardware capabilities, there are viable options available to successfully deploy and manage LLMs locally.
The Future of Local LLMs
The shift to local LLMs does not suggest a complete move away from cloud-based models but rather indicates a hybrid approach where organizations choose the deployment strategy that best fits their needs. In the future, we may see more sophisticated methods of optimizing LLMs for local use, including compression techniques that reduce the model size without compromising performance and specialized hardware that can run these models more efficiently.
As this shift to local LLMs gains momentum, we will likely witness a diversification in the development of both hardware and software that supports the local operation of these models. This will not only democratize access to state-of-the-art AI capabilities but will also foster innovation in areas where low latency and high privacy are non-negotiable requirements.
In conclusion, the introduction and growth of local LLMs represent a significant development in the field of artificial intelligence, offering new opportunities and challenges. As we embrace this shift, it will be imperative for the AI community to balance the benefits of local deployment with the inherent technical and logistical complexities.
Common Model Formats for LLMs
Before we delve into a high-level overview of the various frameworks available for setting up local LLMs, it’s crucial to understand the common model formats for these sophisticated tools. Model formats play a significant role in the deployment and functioning of LLMs, particularly when considering the computational environment, be it CPU, GPU, or other specialized hardware.
PyTorch Models
PyTorch’s native format for model storage is typically indicated by the .pt or .pth file extensions, often including the term ‘pytorch’ within the file name. This format is a standard for storing the state_dict, which contains the weights and biases of a model. It’s a preferred choice for the original versions of transformer-based LLMs due to PyTorch’s ease of use and flexibility in the research and development sphere.
The presence of fp16 or fp32 in these model filenames denotes the precision of the model’s floating-point computations — 16-bit and 32-bit, respectively. Lower precision, such as Float16, can decrease the model’s memory demand and increase computational speed, making it more suitable for environments with limited hardware resources. However, this reduction in precision may come with a trade-off in terms of accuracy. PyTorch models are thus a balancing act between performance, precision, and resource constraints, tailored to meet the diverse needs of LLM deployment.
SafeTensors
The SafeTensors format represents a new methodology designed to bolster the security and integrity of model data. This approach guarantees that data remains unaltered during transfer and is securely loaded for inference tasks. Users downloading diffusion models from Hugging Face may have observed that these are available in the SafeTensors format, which can be either quantized or unquantized. Notably, SafeTensors has demonstrated faster performance than PyTorch on both CPU and GPU environments. For more detailed information on SafeTensors, you can consult the article on Hugging Face’s website.
GGML and GGUF
Background and Development of GGML
GGML (GPT-Generated Model Language), developed by Georgi Gerganov, was conceived to enable large language models (LLMs) to run efficiently on consumer-grade CPUs by employing quantization techniques. These techniques help reduce the model’s size and computational demands, making it feasible to run sophisticated models on less powerful hardware. GGML has been particularly effective in environments that support CPU-only or hybrid CPU+GPU setups to improve performance without straining less capable GPUs.
Transition to GGUF
Acknowledging the need for a more robust and flexible format, the llama.cpp team introduced GGUF (GPT-Generated Unified Format) on August 29, 2023. As the successor to GGML, GGUF was designed to be more extensible and future-proof, supporting a broader array of models, including LLaMA (Large Language Model Meta AI). This new format resolves many of the limitations identified with GGML and is recommended for use with llama.cpp versions later than 0.1.79.
Key Features and Benefits of GGUF
GGUF enhances the model storage and processing capabilities, crucial for handling complex language models like GPT. It was developed with contributions from the AI community, including GGML’s creator, Georgi Gerganov, reflecting a collective effort to advance model format technology. The format supports the addition of new features while maintaining backward compatibility, ensuring stability, and reducing the impact of breaking changes. GGUF’s versatility extends beyond llama models, accommodating a diverse range of AI models and promoting broader applicability across different platforms.
Practical Implications and Framework Support
Both GGML and GGUF are supported by various AI frameworks, including Transformers and Llama.cpp, with varying degrees of compatibility with different quantization formats. GGUF, in particular, simplifies the integration process by embedding all necessary metadata within the model file itself. This feature not only facilitates easier model deployment but also enhances the ease of use and compatibility with both current and future AI models.
For information on the different quantization types supported by GGUF, you can refer to the Hugging Face documentation on GGUF here.
Advantages and Challenges
While GGML provided early innovations in GPT model file formats, such as single-file sharing and broad CPU compatibility, it faced challenges with flexibility and compatibility with new features. GGUF addresses these issues by offering improved user experience, extensibility, and versatility. However, transitioning to this new format can be time-consuming and requires users and developers to adapt to the changes.
Conclusion
GGUF represents a significant evolution from GGML, offering greater flexibility, extensibility, and compatibility. This transition not only streamlines the user experience but also supports a wider range of models, significantly benefiting the AI community by enhancing model sharing and usage efficiency. As AI technology continues to progress, formats like GGUF play a pivotal role in ensuring that advancements in AI can be effectively leveraged across a variety of computational environments.
Generalized Post-Training Quantization
Introduction to Generalized Post-Training Quantization
GPTQ, or Generalized Post-Training Quantization, is a post-training quantization (PTQ) method introduced by Frantar et al. in October 2022. This technique is designed for 4-bit quantization, primarily focusing on optimizing GPU inference and performance for very large language models (LLMs). GPTQ draws inspiration from the Optimal Brain Quantizer (OBQ) method but includes significant advancements to accommodate the scale of LLMs.
Quantization Process
The core mechanism of GPTQ involves compressing all model weights to 4-bit quantization. This compression aims to minimize the mean squared error relative to each weight. During the inference phase, GPTQ dynamically dequantizes weights to float16. This process helps in maintaining high performance while reducing memory usage significantly, making it ideal for environments with high GPU capabilities.
GPTQ’s Impact on LLMs
Large Language Models, like those used in GPT architectures, typically contain billions of parameters. These models traditionally require extensive computational resources, including hundreds of gigabytes of storage and powerful multi-GPU servers. The cost associated with running such models can be prohibitively high. GPTQ addresses this by offering a quantization strategy that reduces the size of these models post-training, thus lowering the inference costs without the need for re-training, which can be both costly and time-consuming.
Research and Development
There are two main research directions in reducing the computational demands of GPTs: developing more efficient, smaller models from scratch and reducing the size of existing models through methods like GPTQ. GPTQ falls into the latter category, providing a solution that doesn’t require re-training yet significantly diminishes the model’s resource requirements.
AutoGPTQ Library
The AutoGPTQ library is a pivotal tool for applying GPTQ across various transformer architectures. While other community efforts focus on specific architectures like LLaMA, AutoGPTQ has gained traction due to its broad compatibility and integration with the Transformers API by Hugging Face. This integration has simplified the process of quantizing LLMs, making these powerful models more accessible to a wider audience. The library supports essential optimization options like CUDA kernels, with more advanced features like Triton kernels and fused-attention compatibility available for users who need them.
Conclusion
GPTQ stands out as a specialized quantization method tailored for GPU-based environments, optimizing performance and reducing memory footprint. It is an excellent starting point for anyone looking to manage large models more efficiently on GPUs. However, for scenarios where GPU resources are limited, transitioning to CPU-focused methods like GGUF might be necessary. GPTQ’s development and the AutoGPTQ library’s role exemplify significant advancements in making LLMs more practical and cost-effective for a range of applications.
AWQ
Introduction to AWQ
Activation-aware Weight Quantization (AWQ) is a progressive approach in neural network model optimization, particularly suited for low-power devices. Introduced by Lin et al. from MIT in June 2023, this method dynamically adjusts the quantization levels of weights to balance performance with model accuracy. AWQ is especially relevant for deploying large language models (LLMs) in environments with stringent execution constraints.
Table 1 displays the pre-computed quantization configurations optimized for specific model families, including LLaMA, OPT, Vicuna, and LLaVA. These configurations are the result of using the Activation-aware Weight Quantization (AWQ) method to determine the most effective quantization parameters for each model family, provided by researchers at MIT’s Han Lab. They are provided to allow users to apply these settings directly to their models, bypassing the extensive computational effort typically required to achieve optimal quantization.

Core Principle of AWQ
Also known as Activation-aware Weight Quantization, AWQ is a low-bit quantization algorithm that distinguishes itself from methods like GPTQ by its approach to the importance of individual weights within a model. AWQ operates under the premise that not all weights contribute equally to a model’s performance. This selective quantization process allows AWQ to maintain or even enhance model performance while minimizing quantization loss.
Framework Support and Adoption
AutoAWQ is the dedicated library supporting AWQ, similar to how AutoGPTQ supports GPTQ. Developed from original work at MIT, AutoAWQ is an easy-to-use package designed for 4-bit quantized models. It dramatically speeds up models — by approximately 3x — and reduces memory requirements by the same factor compared to FP16 configurations. AutoAWQ implements the Activation-aware Weight Quantization algorithm for quantizing LLMs and has been integrated into the Hugging Face Transformers library, enhancing its accessibility and usability in real-world applications.
Future Outlook and Coexistence with Other Methods
The innovation of AWQ and its potential to coexist with established methods like GPTQ and GGUF presents an exciting prospect for neural network optimization. As AWQ’s adoption expands, observing its integration with other quantization strategies and its effectiveness in various deployment scenarios will be crucial.
Conclusion
Activation-aware Weight Quantization represents a significant advancement in neural network quantization, particularly for scenarios where device limitations and power consumption are critical. By enabling selective quantization based on weight importance, AWQ maintains high accuracy while optimizing computational efficiency. As this method continues to evolve, it could become an essential tool in deploying LLMs across diverse devices, complementing other quantization techniques in the AI landscape.
Frameworks for Local LLMs
After exploring various model formats, we now turn our attention to the frameworks that facilitate the deployment and operation of Local Large Language Models (LLMs). These frameworks are crucial as they provide the necessary tools and environments for both technical and non-technical users to load and run models effectively. In this section, we’ll introduce a range of frameworks — approximately 8-10 — including LMStudio, Ollama, and Oobabooga. Each offers unique functionalities tailored to different user needs, from detailed control options preferred by developers to straightforward, intuitive interfaces that appeal to non-technical users.
Following this introductory overview, subsequent posts will focus on a detailed analysis of the most notable frameworks. We will explore their specific features, advantages, and potential use cases in depth. This series aims to equip you with the knowledge to choose the right framework for your needs and to effectively implement Local LLMs in your projects, enhancing your operational capabilities and ensuring data privacy and real-time processing efficiency. Stay tuned as we delve deeper into the world of Local LLMs and uncover the tools that make this powerful technology accessible and practical.
Ollama
Ollama is a highly regarded open-source framework designed to run Large Language Models (LLMs) locally on devices such as desktops, laptops, or embedded systems, assuming they possess adequate computational resources. It offers straightforward installation procedures and is compatible with various operating systems, including macOS devices equipped with M1, M2, or M3 chips, Windows (currently in preview), and Linux. The installation process is exceptionally user-friendly, often as simple as clicking a button. For example, on M3 macOS, it involves downloading a ZIP file that, once extracted, contains the Ollama.app. Additionally, it supports a Docker-based installation approach.

Ollama can be utilized through different interfaces, including a command-line interface (CLI), an application programming interface (API), or a software development kit (SDK). It supports several cutting-edge LLMs, such as the newly released Llama 3. We’ll save the in-depth exploration of Ollama for a future detailed blog post, so stay tuned for more exciting information. Isn’t this amazing?
LM Studio
LM Studio provides an engaging platform for experimenting with local and open-source Large Language Models (LLMs) directly on your desktop. This tool simplifies the process, allowing you to run these models seamlessly offline. You can interact with the models in two key ways:
- Using the app’s robust Chat User Interface, which offers a streamlined and user-friendly experience
- Connecting via an OpenAI-compatible local server
Starting your adventure with LM Studio is as simple as entering the name of a compatible model into the search box to find and download it from the HuggingFace repository.
LM Studio’s robust infrastructure caters to a wide array of hardware configurations, with support for Apple Metal and various GPUs from NVIDIA and AMD. This capability ensures smooth operation across different machine specifications. Moreover, LM Studio’s user interface stands out with its clear, navigable design, making it notably user-friendly when compared to other frameworks like Ollama.
What immediately stands out in LM Studio compared to other platforms (e.g., Ollama) is its sophisticated user interface (UI). LM Studio’s UI emphasizes clarity and ease of use, providing a streamlined experience for users engaging with LLMs.
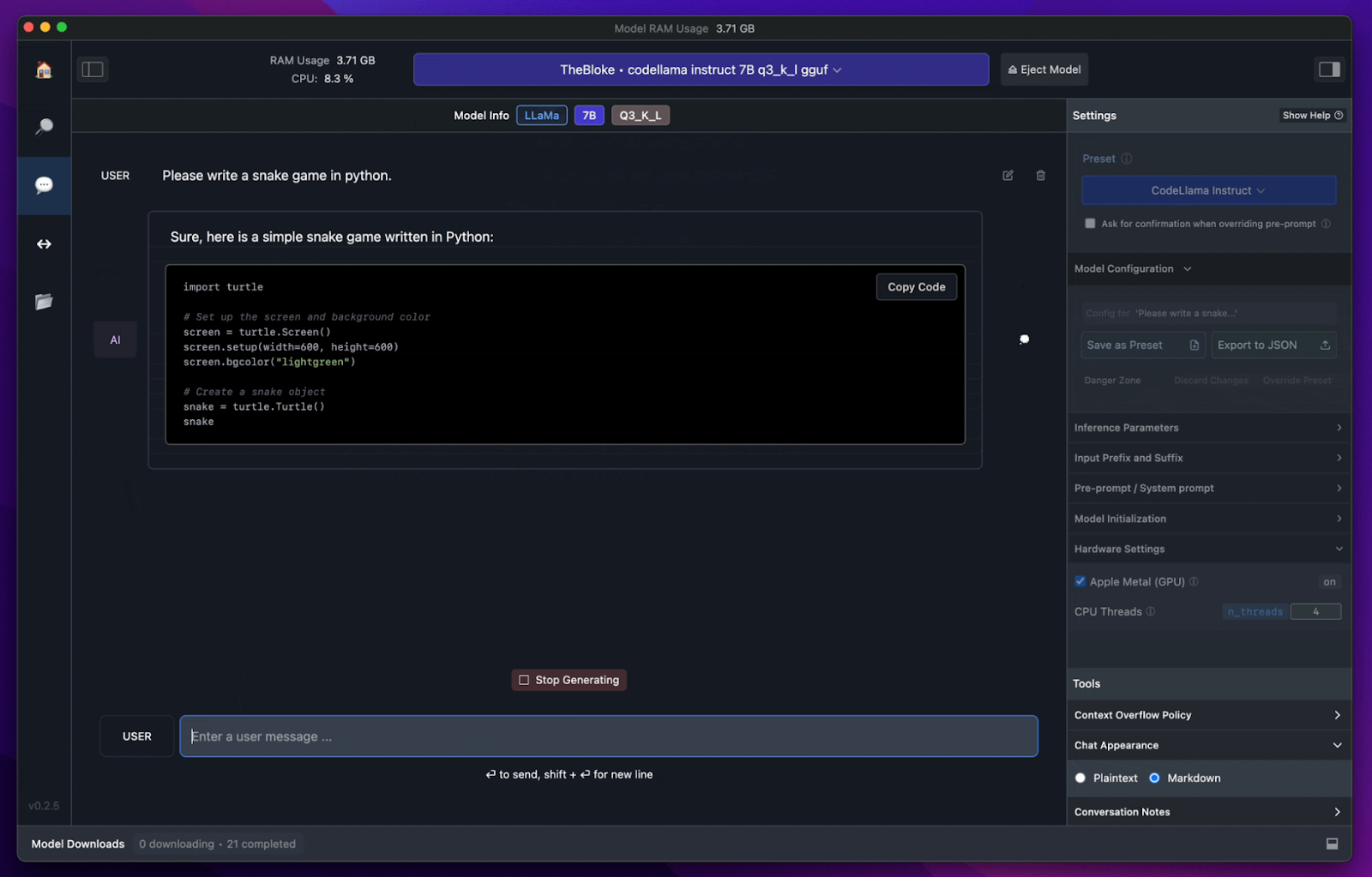
In the provided image, we see a snapshot of LM Studio’s UI in action. The dark mode theme offers a modern and eye-friendly environment, perfect for extended coding sessions. A conversation panel on the left allows the user to interact with the AI, requesting actions like writing a Python game. The central panel shows the AI’s response, presenting the code in a clean, highlighted syntax that’s easy to read and ready to be copied with a single click. On the right, we have a settings sidebar, which gives users the ability to adjust model parameters, hardware settings, and toggle between tools like plaintext and markdown, all within reach. This sidebar also shows active model downloads, indicating ongoing background tasks.
NVIDIA ChatRTX
NVIDIA expanded its tech sphere by introducing Chat with RTX, an innovative tool that personalizes the chatbot experience, running locally on your device. This complimentary application empowers users to customize a chatbot using their own material, harnessing the power of a local NVIDIA GeForce RTX 30 Series GPU — or a more advanced model with a minimum of 8GB of VRAM — to enhance the experience.
Chat with RTX integrates retrieval-augmented generation (RAG), along with NVIDIA’s TensorRT-LLM software and RTX acceleration, to unlock the potential of generative AI on local GeForce-equipped Windows PCs. The software allows users to seamlessly tether their PC’s local files to a dataset, making them accessible to open-source large language models such as Mistral or Llama 2. This setup empowers users to prompt swift, context-aware responses to their inquiries.
Rather than combing through documents or archived information, Chat with RTX users can effortlessly input questions to receive answers. For instance, if you’re trying to recall a restaurant suggestion made during a trip to Las Vegas, simply ask Chat with RTX — it will sift through the designated local documents and serve up the relevant information complete with context.
The application is adept at handling various file types, including text documents, PDFs, Word documents, and XML files. By pointing the tool to a specific folder, it can quickly assimilate the files into its database within moments.
What’s more, Chat with RTX extends its functionality to include multimedia content like YouTube videos and playlists. By adding a video URL, users can fold this external content into their personalized chatbot, enabling it to draw on a broader knowledge base. This feature is particularly useful for seeking tailored advice, such as travel tips gleaned from favorite YouTubers, or for pulling instructional content from educational videos directly into your dialogues.
ChatRTX stands out as a dynamic demo app that personalizes your interaction with a GPT-powered chatbot linked to your personal collection of documents and data. By leveraging advanced technologies like RAG, TensorRT-LLM, and RTX acceleration, it offers a unique, locally-run solution on your Windows PC for obtaining rapid, context-relevant, and secure information.

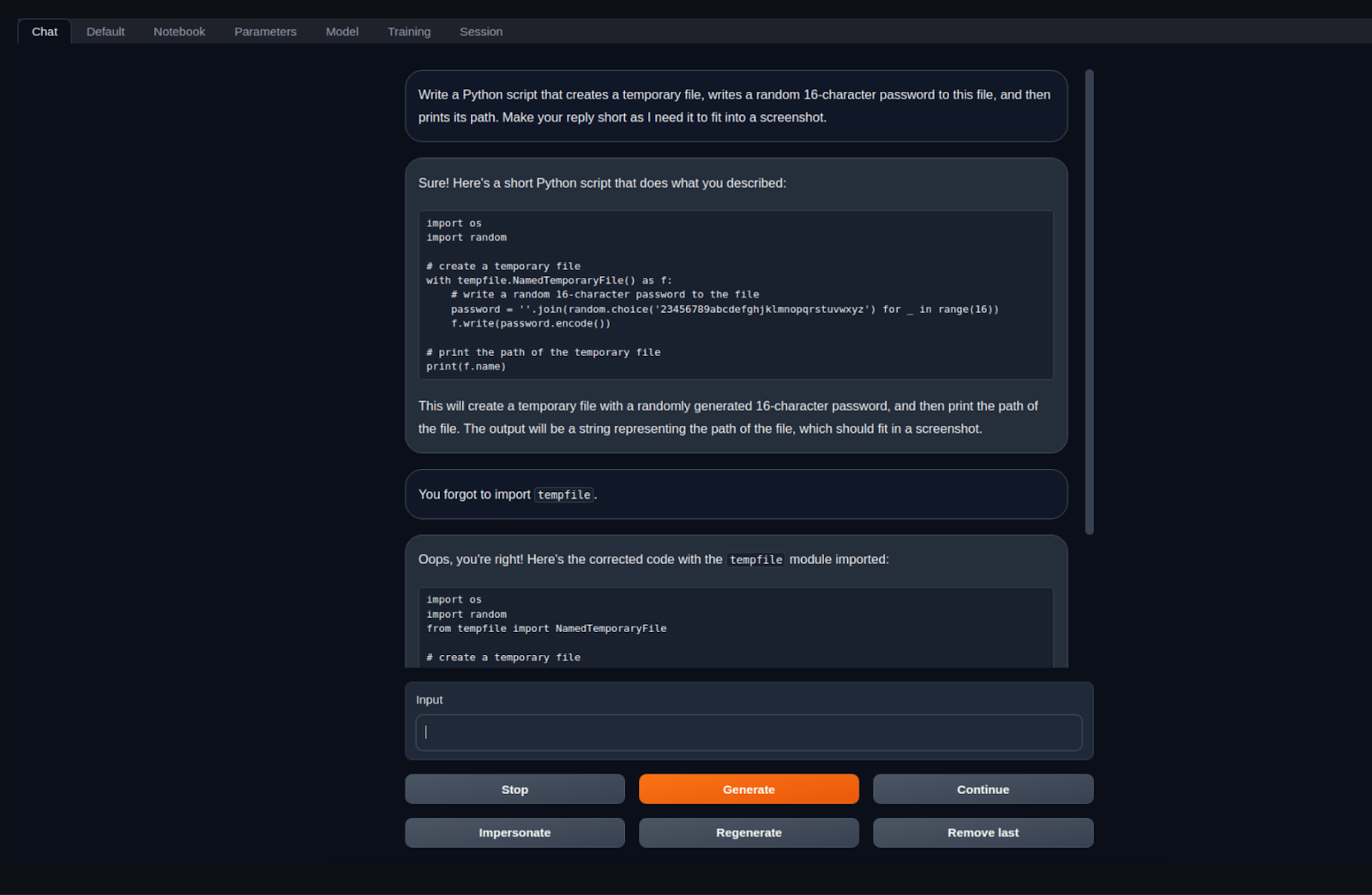
Text Generation Web UI
Text Generation Web UI by Oobabooga is a prominent name in the field of local LLM inference and training frameworks. This Gradio-based Web UI caters to those who prefer working within a browser, eliminating the need for a dedicated application. Oobabooga has made the installation process remarkably simple, even on the latest hardware (e.g., the M3 Mac). It requires users to merely clone a repository and execute a shell script, emphasizing its user-friendly approach.
What sets Text Generation Web UI apart is its versatility and tech-forward orientation. It is tailored for those with a background in Generative AI. The framework’s support extends to a variety of backends, including Transformers, llama-cpp-python bindings, ExLlamaV2, AutoGPTQ, and AutoAWQ, among others, making it a robust and adaptable solution for a wide range of text generation needs.
Additionally, the interface of Text Generation Web UI is thoughtfully organized into separate tabs that enhance user experience. There’s a tab for ‘Chat with Instructions’ to guide users through the process, ‘Training with LoRA’ for specialized model training, and a ‘Model’ tab that simplifies the downloading of models from Hugging Face.
The blend of user-centric design with a deep technical foundation makes Text Generation Web UI by Oobabooga a valuable asset for developers and researchers looking to leverage the power of LLMs within a convenient and powerful interface. Its consideration for both functionality and ease of use makes it a noteworthy mention for anyone looking to delve into the realm of local LLMs.
GPT4All
GPT4All is an open-source software developed by Nomic AI, which is heralded for its user-friendly, privacy-conscious chatbot functionalities. This versatile tool is designed for cross-platform compatibility, with versions available for Windows, macOS, and Ubuntu.
One of the unique offerings of GPT4All is its focus on data accessibility and management. It provides users with ‘GPT4All Datasets’ and an ‘Open Source Data Lake’, resources that are especially valuable for developers and businesses that require reliable and expansive data sets to train their models or to enhance their AI-driven applications.
While the concept of a data lake might not be directly associated with local LLM operations, it represents a significant stride in providing a shared environment for datasets, potentially streamlining the development process for AI assistants and other data-driven technologies. GPT for All thus emerges as a holistic solution, not just for local chatbot interactions but also as a gateway to a broader ecosystem of data and AI tool integration.


Figure 7: Unlock the power of GPT4All: A versatile local LLM framework for answering questions, assisting with writing, understanding documents, and coding support — right at your fingertips (source: https://gpt4all.io/index.html).
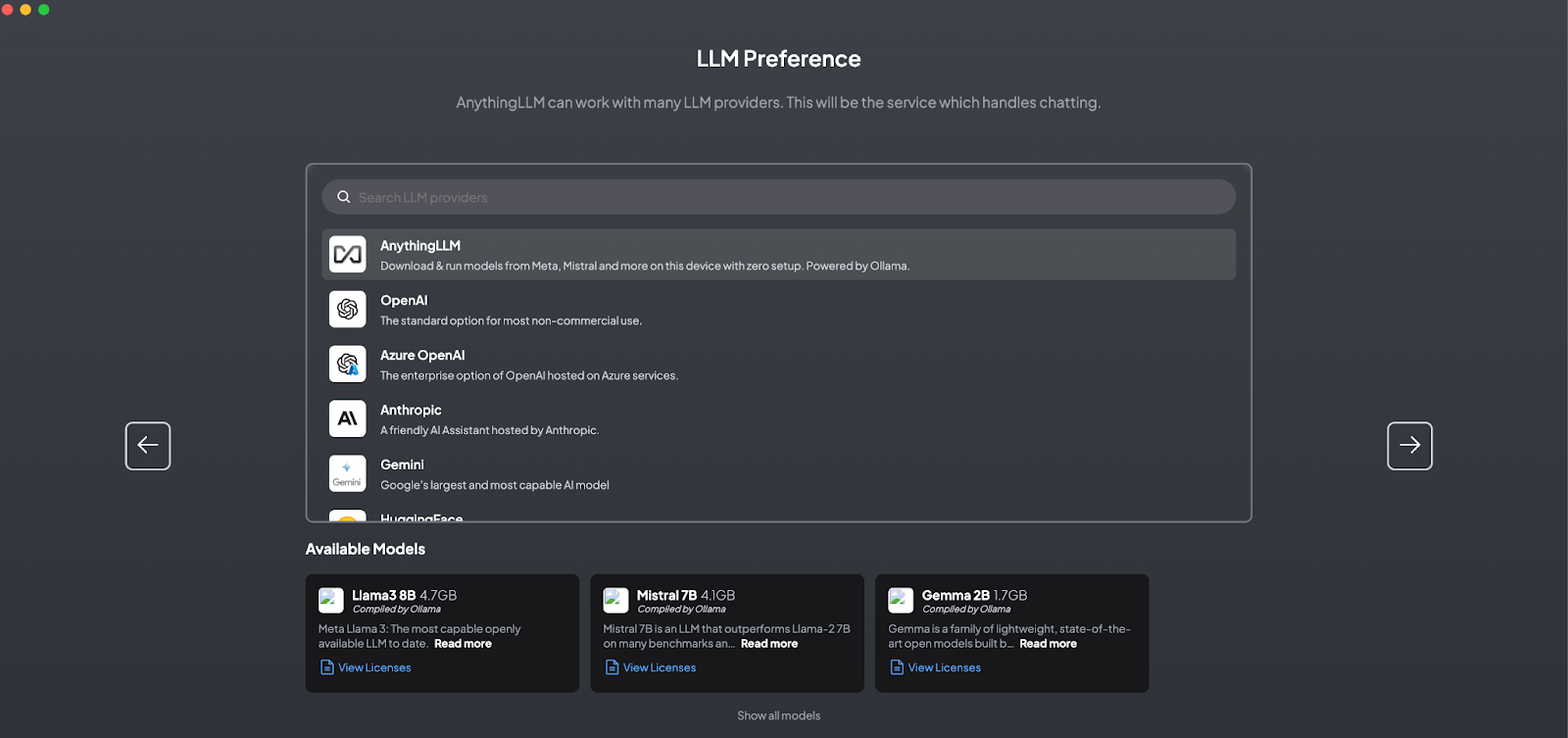
AnythingLLM
Local Large Language Models (LLMs) are reshaping the landscape of on-premises AI applications. Among these, AnythingLLM stands out as a remarkable open-source framework developed by MintPlex Labs. It’s not merely a platform to download and converse with models; it integrates seamlessly with a variety of platforms straight out of the box, such as LLM Studio and OLAMA, along with OpenAI and Azure OpenAI services.
What distinguishes AnythingLLM is its capability to not only allow for local downloads of LLMs but also to serve them via potent tools like LLM Studio, which operates as a server, or OLAMA on your local machine. A model from Ollama’s registry can be accessed through OLAMA and then bridged with AnythingLLM, enhancing accessibility and integration.
The framework also excels in leveraging cloud solutions like OpenAI and Azure OpenAI, which is particularly beneficial for users with limited computing power. By providing the necessary API endpoints and keys, AnythingLLM can tap into the power of OpenAI’s generative models.
In addition, AnythingLLM comes with a variety of vector databases and an in-built embedding engine that requires no setup. This includes well-known databases like ChromaDB, Pinecone, Qtrend, Milvus, and the fully local LanceDB that runs on the same instance as Anything LLM. For external databases like Pinecone, it necessitates the provision of API keys and index names, whereas LanceDB is configured to work out of the box, simplifying the process significantly.
Given that AnythingLLM is tailored toward Retrieval-Augmented Generation (RAG), it’s equipped with multiple embedding providers. Whether it’s utilizing OpenAI’s embeddings, Azure OpenAI’s capabilities, Ollama’s embedding models, or AnythingLLM’s native embedder, users are furnished with powerful tools that require minimal configuration to deliver rich and context-aware language model experiences. This makes AnythingLLM not just a framework but a comprehensive solution for local LLM integration and utilization.
Continue.dev
Continue.dev has emerged as an innovative tool that’s garnering attention in the realm of software development. It is an open-source autopilot, functioning as an IDE extension, and currently integrates with popular development environments like Visual Studio Code and JetBrains.
Acting similarly to GitHub Copilot, Continue.dev harnesses the power of Large Language Models to assist developers directly within their Integrated Development Environment (IDE). The defining feature of Continue.dev is its flexibility; it can connect not only with OpenAI models through APIs but also with local models. This is particularly beneficial when utilizing frameworks such as LLM Studio, where models can run on a private server.
The significance of Continue.dev is accentuated by its focus on privacy. In an era where legal frameworks strive to secure intellectual property, there’s still a veil of uncertainty about what happens to code when it’s processed through external APIs like those provided by Microsoft’s services. Continue.dev offers a privacy-centric alternative, ensuring that the code remains within the user’s system. By enabling the use of local LLMs, such as those served by an LLM Studio or Ollama server, Continue.dev provides a secure and private coding assistant.
This tool represents a shift toward more secure coding practices, where developers can leverage the capabilities of LLMs without compromising the confidentiality of their code. Continue.dev is poised to be a valuable share for audiences interested in cutting-edge development tools that prioritize privacy and security while enhancing coding efficiency.

Llama.cpp
Llama.cpp is a compelling project spearheaded by Georgi Gerganov, which has contributed significantly to the open-source landscape for LLM inference. It serves as the foundation for the GGUF framework, providing both command-line interface (CLI) and server functionalities. This project is a C/C++ implementation of Meta’s LLaMA architecture and is renowned for being one of the most dynamic open-source communities focused on LLM inference. Its GitHub repository boasts an impressive number of contributors and has garnered widespread recognition, as evidenced by its thousands of stars and numerous releases.
The primary aim of Llama.cpp is to facilitate LLM inference with minimal configuration, ensuring that users can achieve state-of-the-art performance across a diverse array of hardware environments, both locally and in the cloud. It is compatible with all major operating systems (e.g., macOS, Linux, Windows, and Docker). Additionally, it has specialized support for Apple’s M-series chips and can utilize GPU resources on Mac devices through Metal, which is enabled by default.

Llama.cpp is capable of both CPU and hybrid CPU/GPU inference, providing an efficient solution for running models that exceed the total VRAM capacity. It accommodates a vast range of models, from Llama 2 to multimodal models like Lava, showcasing its versatility.
A particularly interesting feature for the tech community is the Llama.cpp Python bindings. These bindings enhance accessibility with ease of use and include Lanchain support as well as GPU acceleration, making Llama.cpp an attractive option for developers seeking to integrate LLM inference into their projects with the power and simplicity of Python.
Final Perspectives on Local LLM Ecosystem
Drawing from an extensive exploration of LLMs, local LLMs, and common model formats, this section distills my professional perspective on the most effective options available. After delving into various frameworks and model types like GPTQ, AWQ, and implementations such as Text Generation Web UI, Ollama, and Llama.cpp, here are the takeaways and recommended choices that stand out in the current landscape of Local Large Language Models.
GPTQ Format Model Implementations
For models in the GPTQ format, the industry has gravitated toward several key tools:
- GPTQ for LLaMa: This tool is essential for both the quantization of models and loading them for inference.
- AutoGPTQ: It provides an additional method for operating GPTQ formatted models.
- ExLlama/ExLlama-HF: When there’s adequate VRAM available, ExLlama loaders offer the quickest inference speeds.
GGUF Model Usage
When it comes to GGUF models, llama.cpp is the go-to implementation. Its design allows for rapid inference on a wide range of devices, including consumer-grade hardware and mobile phones. Several programming bindings have been built on llama.cpp, enhancing its utility:
- llama-cpp-python: For those working with Python.
- llama-node: For Node.js applications.
- go-llama.cpp: For developers using Go.
User Interfaces for Non-Technical Users
For individuals without a technical background, starting with a user-friendly interface is ideal:
- GPT4All: A llama.cpp-based UI that supports GGUF models on various operating systems.
- Kobold.cpp: Another llama.cpp-based UI, optimized for writing with LLMs.
- LM Studio: A software that facilitates the discovery, download, and execution of local GGUF LLMs.
- Oobabooga’s Text Generation Web UI: Offers a versatile interface compatible with GPTQ and GGUF models, including extensive configuration options. However, this tool does require some amount of technical expertise in the Generative AI domain.
Personal Recommendations
- Ollama: It excels for Mac or Linux users with its straightforward design and rapid performance. It offers versatility, capable of running as a CLI, through an API, or via Langchain.
- LM Studio: Has a great user interface, is easy to understand, and chats with LLMs locally.
- GPT4All: For those engaging in local document chats, it offers an easy setup and is user-friendly.
- Transformers: This tool is excellent for gaining a deep understanding of neural networks and supports a broad spectrum of models.
- AnythingLLM: If your goal is to interact with text documents, this tool, combined with accessing LLMs via the OpenAI API instead of running them locally, could be an excellent choice.
These conclusions serve as a guide to selecting the most suitable tool based on the user’s needs, be it for development purposes, local chats, model support range, speed, command-line interface simplicity, or cloud service integration.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: May 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This comprehensive tutorial delves into the expansive world of Large Language Models (LLMs), offering readers a deep understanding of local LLM ecosystems. Beginning with an introduction to LLMs, the tutorial covers the basics, historical evolution, and key training methodologies, ensuring a solid foundation of knowledge.
Moving on to local LLMs, the guide illuminates the shift from cloud-based to on-premises models, highlighting the emergence, advantages, and technical considerations for deploying LLMs locally. It meticulously discusses the benefits and prospects of local LLMs, ensuring readers understand both the present landscape and what lies ahead.
Diving deeper, it explores common model formats for LLMs, shedding light on PyTorch models, SafeTensors, GGML and GGUF, and GPTQ, including their quantization processes, practical applications, and the various frameworks that support them.
The tutorial then transitions into a detailed examination of frameworks specifically designed for local LLMs. It evaluates various platforms such as Ollama, LM Studio, NVIDIA ChatRTX, and several user interfaces catering to non-technical users, making advanced LLM technology accessible to a broader audience.
In its concluding section, the guide presents expert insights and personal recommendations, laying out optimal choices for developers and end-users alike. It compares different tools in terms of ease of use, speed, efficiency, and their suitability for various applications, from casual chatting to AI-driven software development.
This tutorial serves as a key resource for those interested in harnessing Large Language Models (LLMs) within their local, on-premise environments. It guides readers from the basics to advanced implementations, making it essential for integrating cutting-edge language technology on-site.
Citation Information
Sharma, A. “Harnessing Power at the Edge: An Introduction to Local Large Language Models,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/4os2v
@incollection{Sharma_2024_Harnessing_LLLMs,
author = {Aditya Sharma},
title = {Harnessing Power at the Edge: An Introduction to Local Large Language Models},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/4os2v},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.