Table of Contents
- Unlocking Image Clarity: A Comprehensive Guide to Super-Resolution Techniques
- Introduction
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- What Is Super-Resolution?
- Usual Problems with Low-Resolution Imagery
- Traditional Computer Vision Algorithms for Super-Resolution
- Nearest-Neighbor Interpolation: Efficient and Simple Image Enhancement
- Bilinear Interpolation: Precise Pixel Estimation for Enhanced Imagery
- Bicubic Interpolation: Advanced Grid-Based Interpolation Technique
- Lanczos Interpolation: Capturing Ideal Image Frequencies for Quality Enhancement
- Cubic Spline Interpolation: Curve-Based Edge Smoothing for Improved Images
- EDSR: Cutting-Edge Deep Learning for Super-Resolution
- Implementing Traditional Interpolation Algorithms Using OpenCV
- Applications of Super-Resolution in the Wild
- Enhancing Surveillance Footage: Leveraging Super-Resolution for Clearer Images
- Advancing Geospatial Monitoring: Super-Resolution for Satellite Images
- Revealing Cosmic Details: Super-Resolution in Astronomy Imaging
- Elevating Gaming Visuals: Super-Resolution for Enhanced Gaming Experience
- Revolutionizing Medical Imaging: Super-Resolution for Enhanced Diagnostic Clarity
- How Deep Learning Helps Super-Resolution?
- Summary
Unlocking Image Clarity: A Comprehensive Guide to Super-Resolution Techniques
Introduction
Welcome to the 1st of a 2-part series on super-resolution. In this tutorial, we will learn about the latest trends in Image Super-Resolution as we draw a contrast between the humble beginnings of this field and what the latest state-of-the-art techniques are bringing out as results. Specifically, we’ll go over the following topics:
- Why super-resolution is an important yet underlooked side of computer vision
- Classical algorithms
- Current state-of-the-art techniques
- Applications in the real world
- The way forward

This lesson is the 1st in a 2-part series on Image Super-Resolution:
- Unlocking Image Clarity: A Comprehensive Guide to Super-Resolution Techniques (this tutorial)
- Sharpen Your Vision: Super-Resolution of CCTV Images Using Hugging Face Diffusers
To learn about super-resolution techniques, just keep reading.
Configuring Your Development Environment
To follow this guide, you need to download 2 sample images onto your system and install the SkImage and OpenCV libraries.
Luckily, SkImage and OpenCV are pip-installable:
$ pip install opencv-contrib-python $ pip install skimage # Download a sample image !wget https://people.csail.mit.edu/billf/project%20pages/sresCode/Markov%20Random%20Fields%20for%20Super-Resolution_files/iccv.maddie.small.jpg # Download the EDSR model checkpoint for a 2x upscale !wget -L https://raw.githubusercontent.com/Saafke/EDSR_Tensorflow/master/models/EDSR_x2.pb
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in minutes.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
What Is Super-Resolution?
Have you ever taken photos with your phone and realized that the image you just took at full zoom is way too blurry? Or did you know that an old image in your gallery is not clear enough to identify your loved ones?
Ideally, this would be solved using a mobile phone tool that allows you to sharpen or improve the image. This tool uses the technique that we’re discussing today.
Image Super-Resolution is defined as the task of increasing the resolution of a source image by a constant scale or to a fixed new size. This process normally uses advanced Computer Vision or Machine Learning algorithms to find the best values, which can be used to “fill in” gaps between individual pixels once they are spaced out apart from each other. The values in these gaps increase the inherent frequency of the image and add newer information compared to the original image.
Usual Problems with Low-Resolution Imagery
Low-resolution imagery may cause several problems. For an individual, this could mean heavy pixelation on the image itself, as lower resolution leads to a lower number of pixels in the image. This also leads to the loss of important detail and information from the image.
Consider a photo taken in the wild by an ornithologist as an example. An individual may only be able to identify a given bird species based on its color and rough shape. But if we sharpened the image or obtained a high-resolution version, we may be able to discern it well enough.
 |  |
A lower-resolution image will end up appearing highly blurred and pixelated, affecting how much one can zoom into it without losing quality while also reducing print quality for large-scale production.
It can affect how a professional user may edit the image, since there is not enough information available at hand for editing software to work properly.
For a business, a low-resolution image can affect its SEO (Search Engine Optimization) since search engines usually index high-quality images better. This also highlights the issue of accessibility, wherein individuals with visual impairments may not be able to see the information represented by the image well enough to understand it.
Traditional Computer Vision Algorithms for Super-Resolution
The problem of increasing the resolution of an image is a long-standing one. Several solutions have attempted to do so while using only the available information within the image itself. These methods do not use any form of “learning.” Let’s take a look at some of the most popular ones.
Nearest-Neighbor Interpolation: Efficient and Simple Image Enhancement
This technique is simple and computationally efficient. New rows and columns are added to the image, and the area corresponding to their location is mapped back to the original image. The intensity values in those locations of the original image are directly used to fill the new rows and columns without any change or normalization scheme in place.
This method has the benefit of not creating any form of smoothing artifacts, thus leading to a perfect replication of an image with sharp edges. On the other hand, it can create aberrations that may look like staircases when there are round edges. This is also the reason why it can be susceptible to noise disturbances.
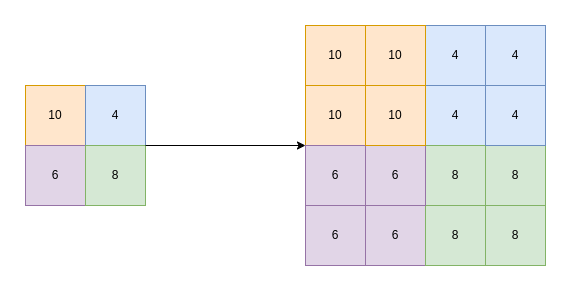
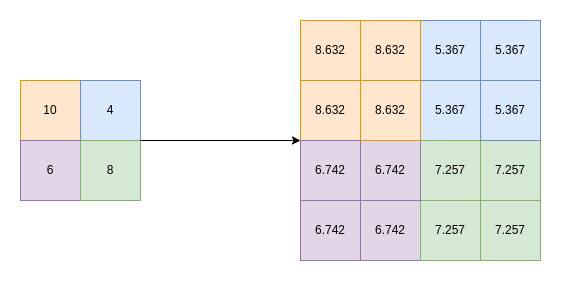
Bilinear Interpolation: Precise Pixel Estimation for Enhanced Imagery
This technique estimates the value of a certain pixel position based on the values of four points that make up a rectangular grid. The intensity values at these positions are used to calculate the final intensity value by taking a weighted average and assigning a higher weight to points closer to the target.
We perform the process of averaging twice to account for changes across both the  and
and  -axes at the same time, which makes it equivalent to applying linear interpolation twice. Normally, the process is done with the -axis first, followed by interpolating with the values obtained previously across the -axis.
-axes at the same time, which makes it equivalent to applying linear interpolation twice. Normally, the process is done with the -axis first, followed by interpolating with the values obtained previously across the -axis.
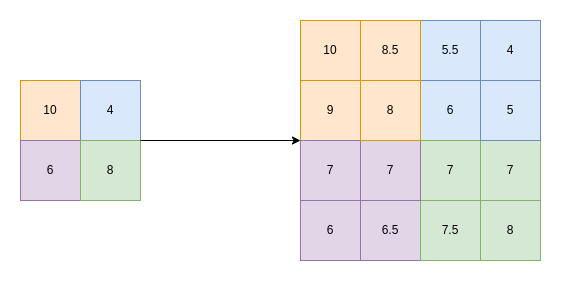
Bicubic Interpolation: Advanced Grid-Based Interpolation Technique
Bicubic interpolation is similar to bilinear interpolation, but instead of considering a 2x2 grid area for performing calculations, it uses a 4x4 grid. It also goes one step further, considering not only the intensity values of the two grid points but also the rate of change of these intensities across the grid’s space.
Mathematically, this process uses a concept called the “Cubic Spline” internally, which tries to fit two data points not with a straight line but with a smooth curve. This technique gives sharper edges and cleaner details with lesser block artifacts that normally come through bilinear interpolation. However, it is important to note that due to this same reason, it is more computationally costly than other techniques.
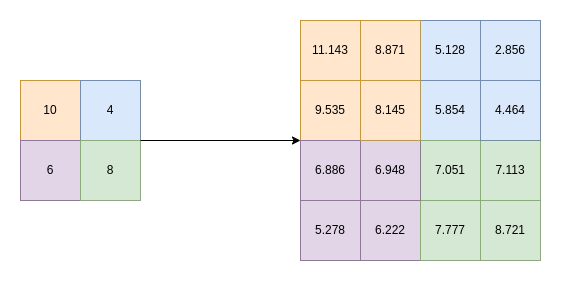
Lanczos Interpolation: Capturing Ideal Image Frequencies for Quality Enhancement
The Lanczos filter, named after Hungarian mathematician Cornelius Lanczos, uses the sinc function /x") to capture the ideal frequency of the intensity values in an image at different locations. This filter can capture all of them separately, greatly minimizing distortion and making a clean, upscaled image.
to capture the ideal frequency of the intensity values in an image at different locations. This filter can capture all of them separately, greatly minimizing distortion and making a clean, upscaled image.
This filter is said to be among the best in terms of qualitative performance, greatly increasing sharpness. However, it can also introduce “halo” or “ringing” artifacts, which come around sharp edges with a strong intensity difference. The “a” parameter of the Lanczos filter can be adjusted, which controls the window size.
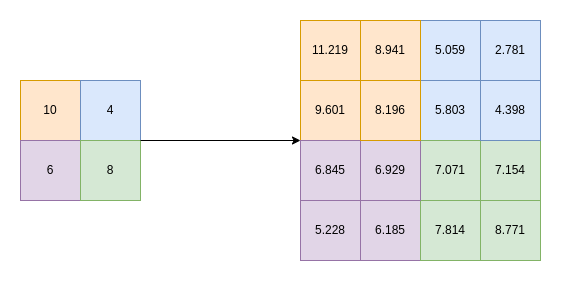
Cubic Spline Interpolation: Curve-Based Edge Smoothing for Improved Images
A predecessor to Bicubic Interpolation, the Cubic Spline technique works by augmenting the process of linear interpolation with curves instead of straight lines. The underlying derivative of such a curve is a straight line, allowing for a smooth transition that translates to a smooth edge from a qualitative perspective.
However, there are cases wherein these splines may overshoot or not perfectly fit due to numerical precision issues. The process is also comparatively costly in terms of computation, restricting accessibility or use in large-scale contexts.
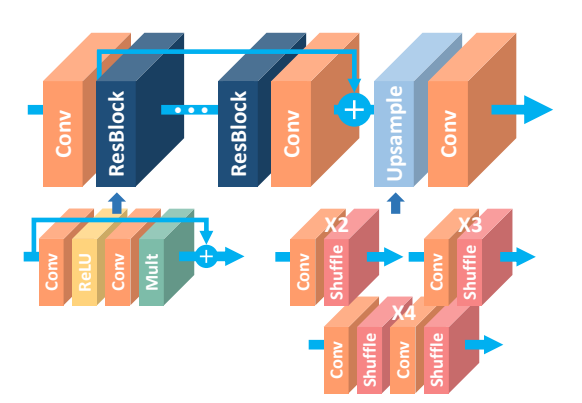
EDSR: Cutting-Edge Deep Learning for Super-Resolution
While this is not a traditional Computer Vision algorithm for interpolation, it is among the first deep learning techniques unveiled for this task. EDSR (Enhanced Deep Residual Networks for Single Image Super-Resolution) make use of ResNets and Convolutional layers to perform super-resolution. It builds on top of an earlier work of SRResNet (Super-Resolution Residual Network) and improves it by removing unnecessary modules while making the network wider and deeper.
Among all the other techniques in this list, this process has the best qualitative output at the cost of significantly higher computational requirements (although lower than most other Deep Learning techniques). However, using a neural network has the inherent risk of erroneous extrapolation if the input image is not within the distribution of the training data.
Implementing Traditional Interpolation Algorithms Using OpenCV
Now that we have a basic understanding of these algorithms, let’s examine how to implement each one in Python!
First, let’s download some images and the EDSR model checkpoint that we will use later.
# Download a sample image !wget https://people.csail.mit.edu/billf/project%20pages/sresCode/Markov%20Random%20Fields%20for%20Super-Resolution_files/iccv.maddie.small.jpg # Download the EDSR model checkpoint for a 2x upscale !wget -L https://raw.githubusercontent.com/Saafke/EDSR_Tensorflow/master/models/EDSR_x2.pb
Now, we resolve our dependencies by importing them into the environment. For this exercise, we will use OpenCV, Skimage, and Matplotlib.
import cv2 import skimage import matplotlib.pyplot as plt
Let’s read the image we just downloaded and view it once. Note that OpenCV loads images in the BGR format, while the image is originally in the RGB format. So, we need to shift the channels around using OpenCV’s utility. See the corrected image below.
img = cv2.imread("iccv.maddie.small.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print(f"Original Image shape: {img.shape}")
plt.imshow(img)

All but 2 of the algorithms mentioned are available through the cv2.resize() API, which we can control using a Flag. Let’s now write a function that will allow us to modularize this functionality and perform interpolation quickly!
def interpolation(img, mode_type, factor=None):
if mode_type == "Cubic Spline":
# Only function that uses skimage instead of cv2
img = skimage.transform.resize(img, (img.shape[0] * factor, img.shape[1] * factor), order=3, anti_aliasing=False)
return img
elif mode_type == "EDSRx4":
# This functionality uses a Deep Learning model, so it does not make use of the
# cv2.resize() API
print(f"This mode only supports scale factor = 2, so all images will have this factor only")
sr = cv2.dnn_superres.DnnSuperResImpl_create()
path = "EDSR_x2.pb"
sr.readModel(path)
sr.setModel("edsr", 4)
result = sr.upsample(img)
return result
elif mode_type == "Linear":
mode = cv2.INTER_LINEAR
elif mode_type == "Nearest":
mode = cv2.INTER_NEAREST
elif mode_type == "Cubic":
mode = cv2.INTER_CUBIC
elif mode_type == "Lanczos4":
mode = cv2.INTER_LANCZOS4
img = cv2.resize(img, (0, 0), fx=factor, fy=factor, interpolation=mode)
return img
There we go! Our function can now handle images of any size and resize them by a factor of our own choice with all the algorithms we just read about.
Now, let’s quickly define a minimal runner that would utilize this function and generate some results.
modes = [
"Linear",
"Nearest",
"Cubic",
"Lanczos4",
"Cubic Spline",
"EDSRx4",
]
factors = [
2
]
image_dict = {}
for mode in modes:
for factor in factors:
image_dict[f"Original Image for {mode}"] = img # Log original image per mode
image_dict[f"{mode} with {factor}x"] = interpolation(img, mode, factor)
That will now help us to prepare all our images and save them in memory. Let’s quickly plot it, too, and visualize our results in the image below.
titles = list(image_dict.keys())
data = list(image_dict.values())
fig, axes = plt.subplots(6, 2, figsize=(12, 30))
for i in range(6):
for j in range(2):
index = i * 2 + j
axes[i, j].imshow(data[index]) # Wrap around for cyclical data
axes[i, j].set_title(titles[index])
axes[i, j].set_xlabel("Width")
axes[i, j].set_ylabel("Height")
fig.suptitle("Interpolation across different frames", fontsize=20)
plt.tight_layout()
plt.show()
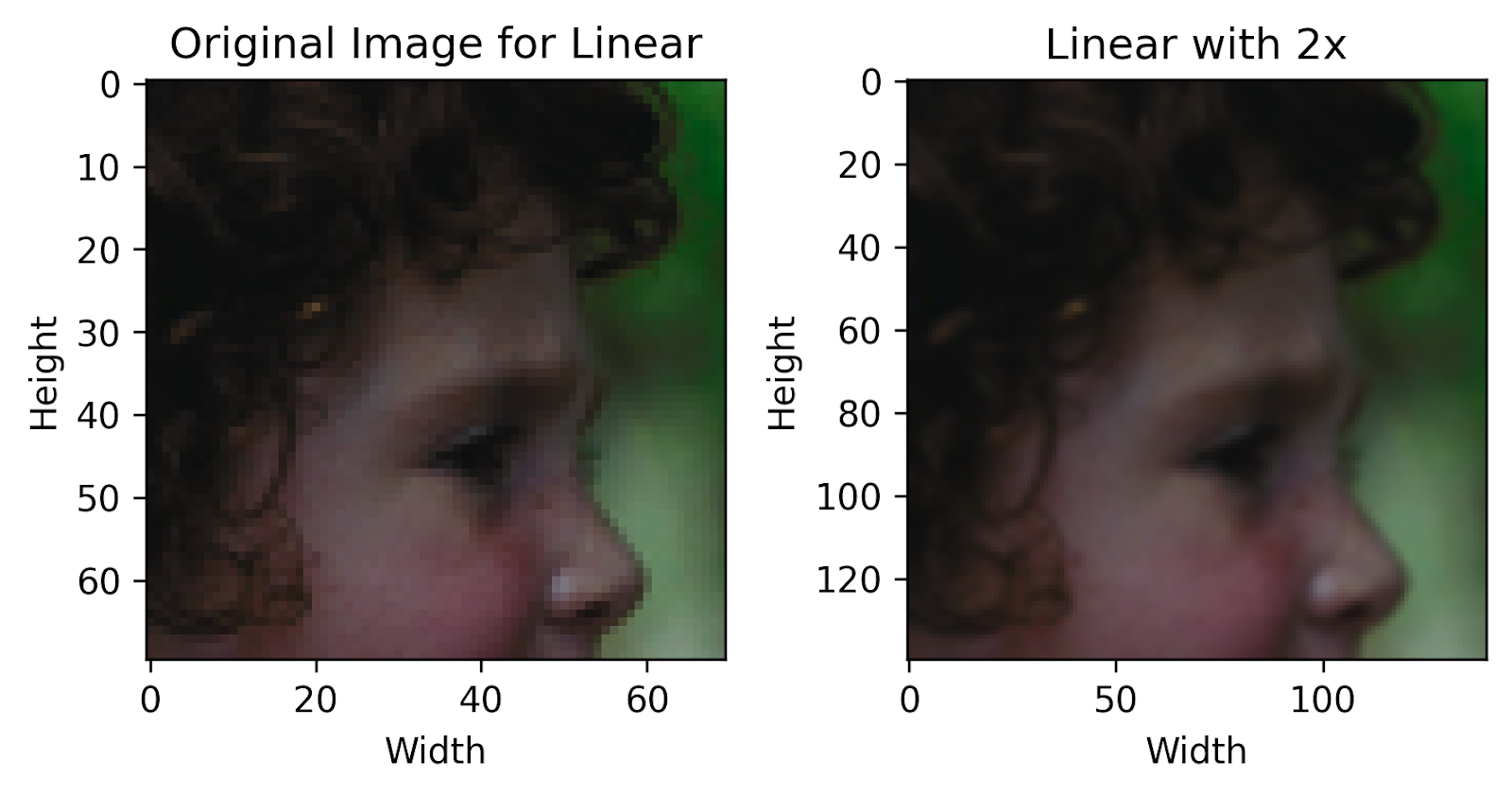
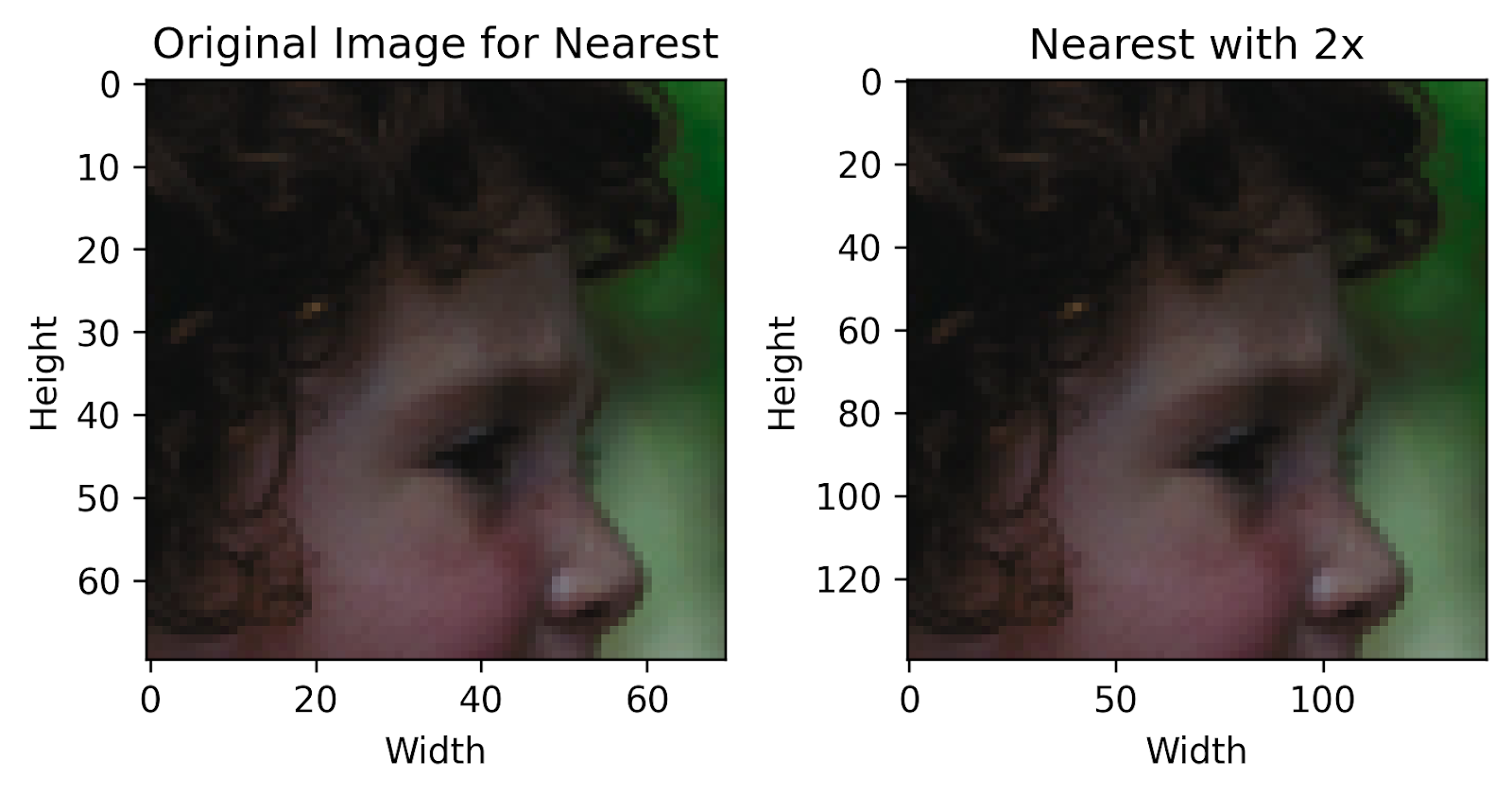
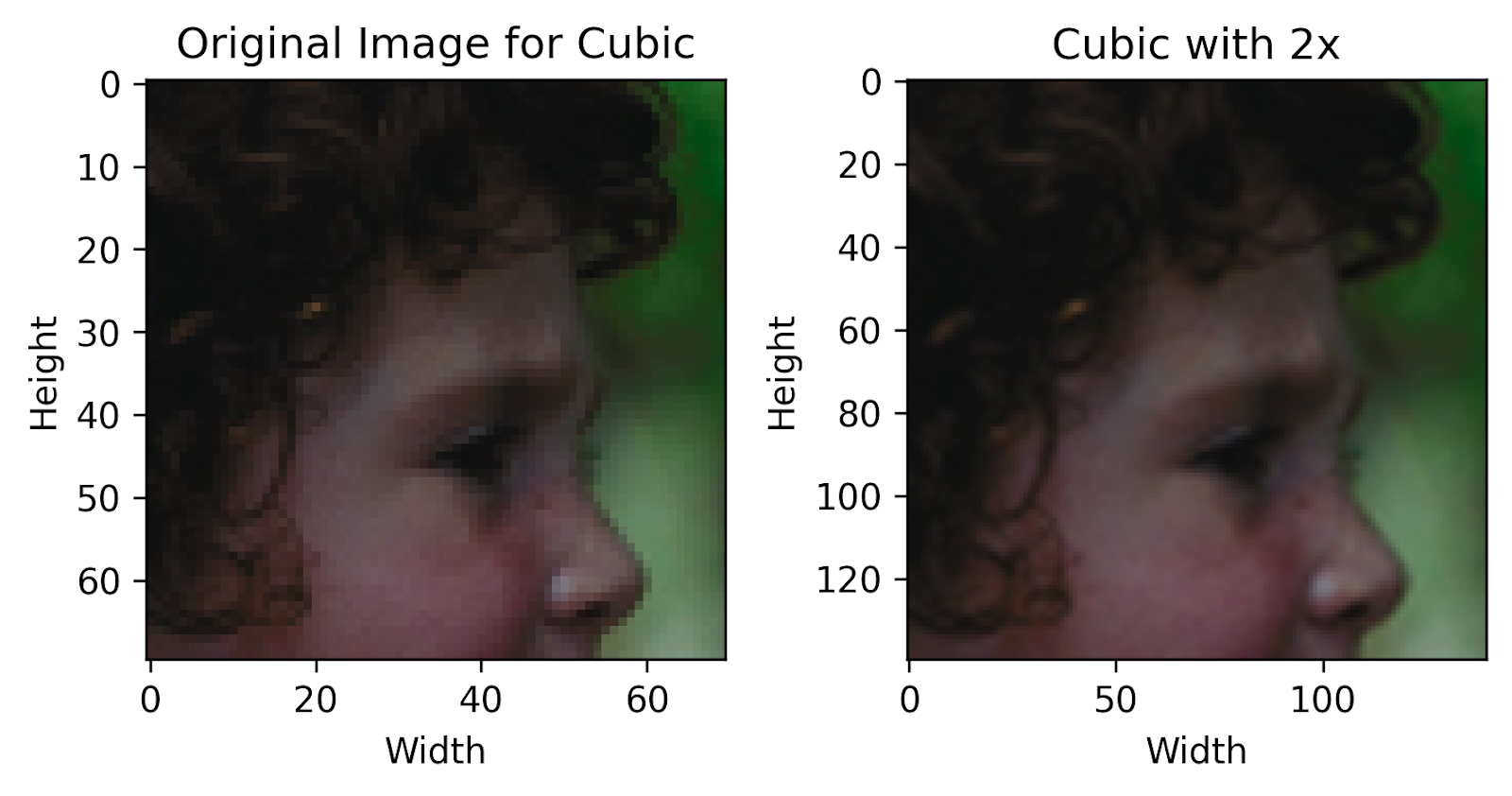
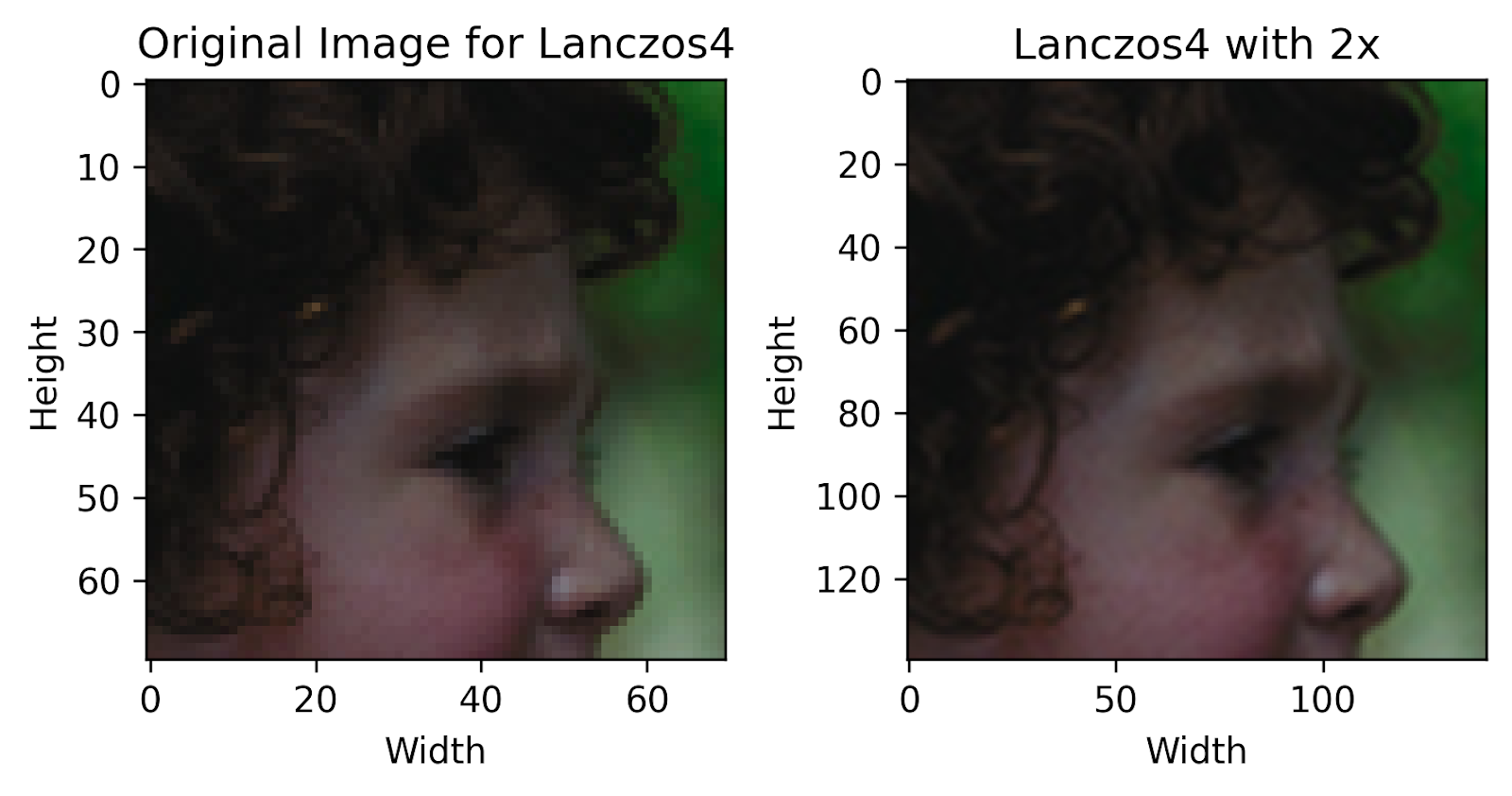
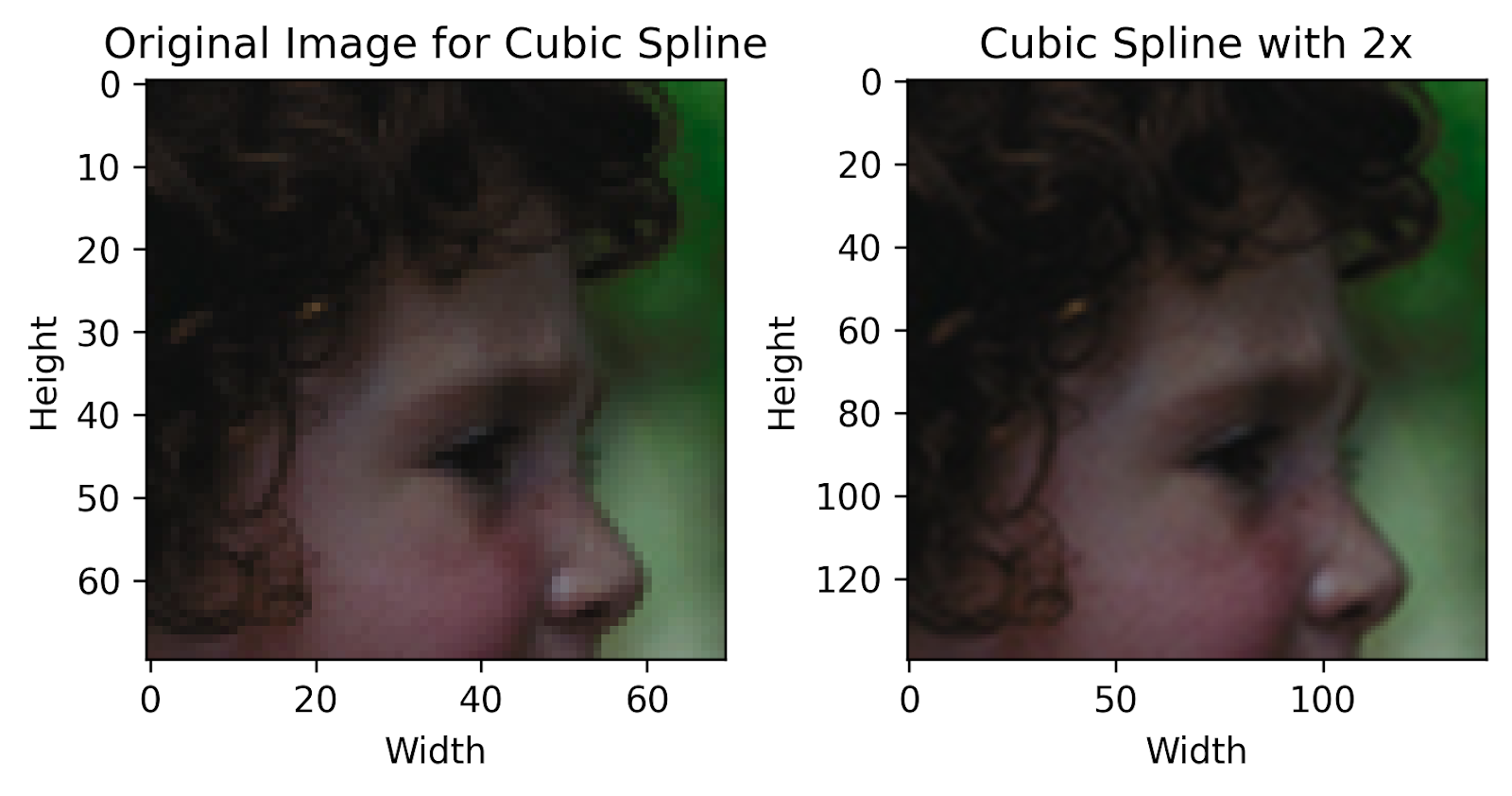
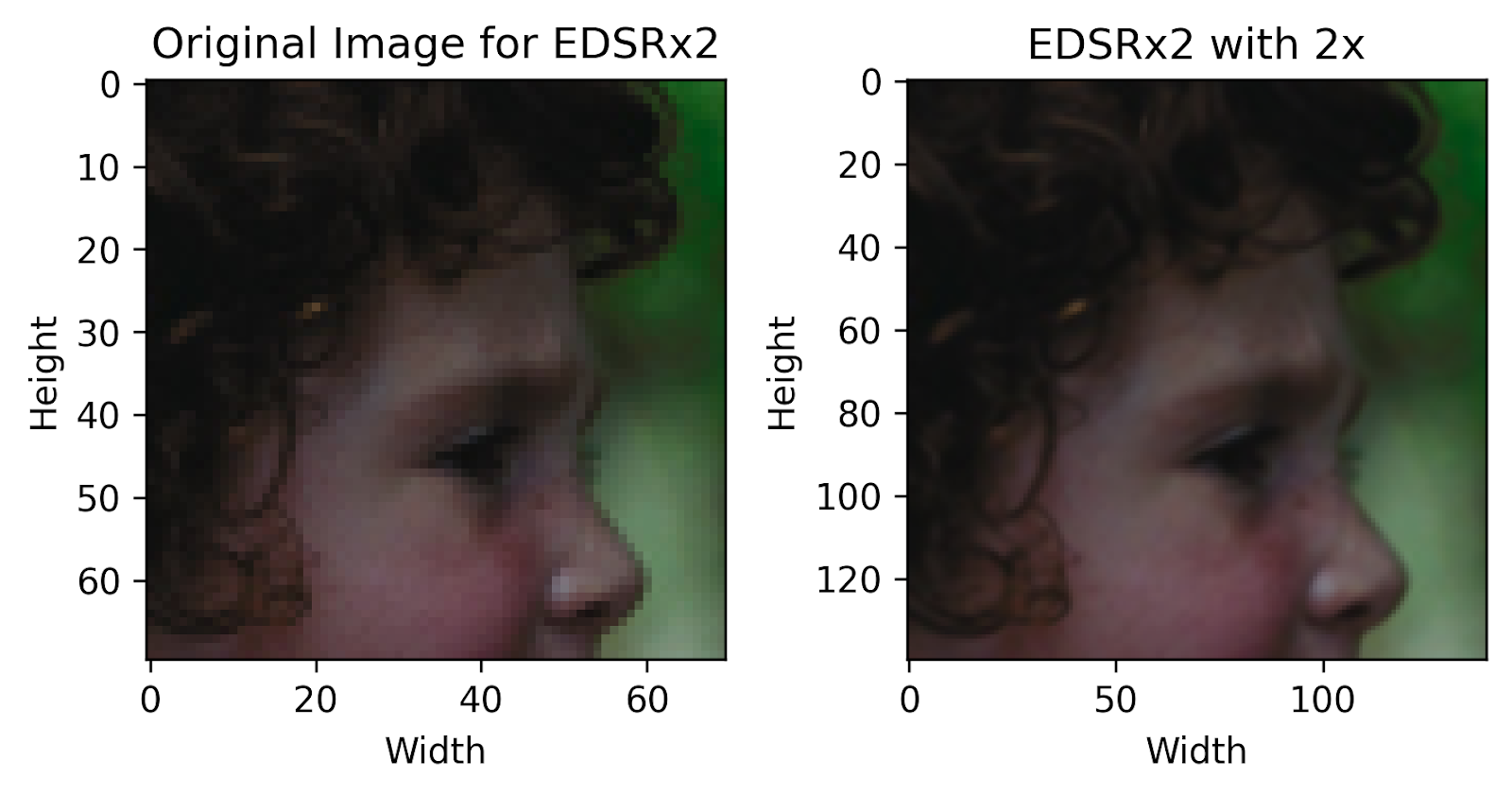
Finally! We can now see how each technique performs compared to the original image. We can outright visually notice that the pixelation present in the original image has now been reduced by a large degree, with a higher overall quality.
Applications of Super-Resolution in the Wild
Unsurprisingly, bad images are very common in the real world. This can hinder many applications, which often makes image super-resolution an important step in preprocessing the original image. Let’s take a look at a few popular use cases.
Enhancing Surveillance Footage: Leveraging Super-Resolution for Clearer Images
It’s common to see movies in which the boss in a police control room asks the officers to zoom into an image and sharpen it to identify important clues and pieces of information that may be relevant to the case.
This is an interesting example of how super-resolution is abstracted away, while being an important step to make the image clearer. In security cameras, super-resolution can be used to improve the quality of already-captured or live footage, allowing for better identification of objects and people. This can be crucial in forensic analysis and monitoring public areas for signs of distress.

Advancing Geospatial Monitoring: Super-Resolution for Satellite Images
Researchers are looking to leverage super-resolution capabilities with images captured from satellites stationed in Earth’s orbit to monitor geographical changes over time. This could also be useful for governments, as it could enable them to observe certain areas of interest.

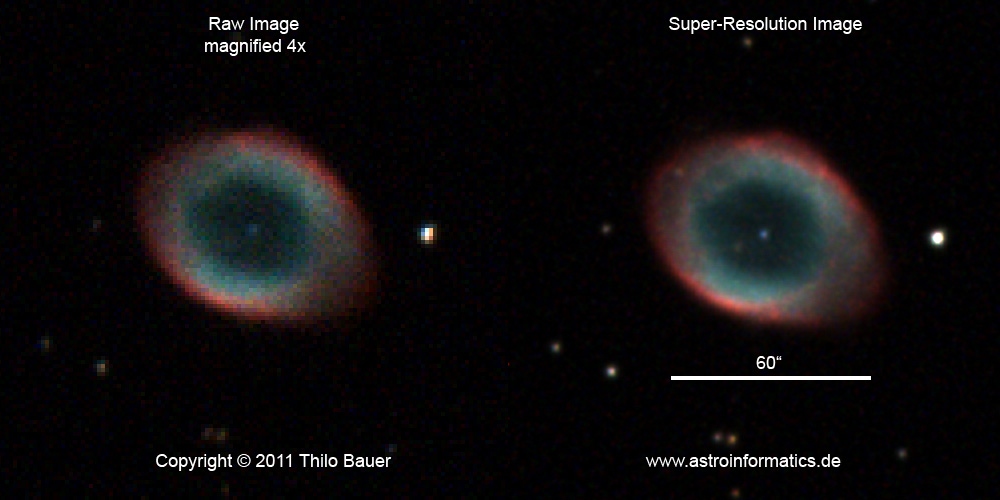
Revealing Cosmic Details: Super-Resolution in Astronomy Imaging
Super-resolution can also be made to work beyond Earth. Images captured from probes and satellites orbiting other planets or celestial bodies sometimes undergo super-resolution to help researchers identify important objects. These kinds of images often require capturing faint objects with long exposure times, leading to unwanted artifacts or blurs. Super-resolution can reduce this effect to a large extent.
Elevating Gaming Visuals: Super-Resolution for Enhanced Gaming Experience
Super-resolution is actively used in games to improve rendered textures and images and provide a better experience. It also helps in upscaling the game screen to the user’s display resolutions to give the best experience available.
A lot of computer-generated imagery is often rendered in real-time in games and the animation industry. Offsetting this with pre-generated images upscaled to a particular resolution saves time and compute for the end-user.

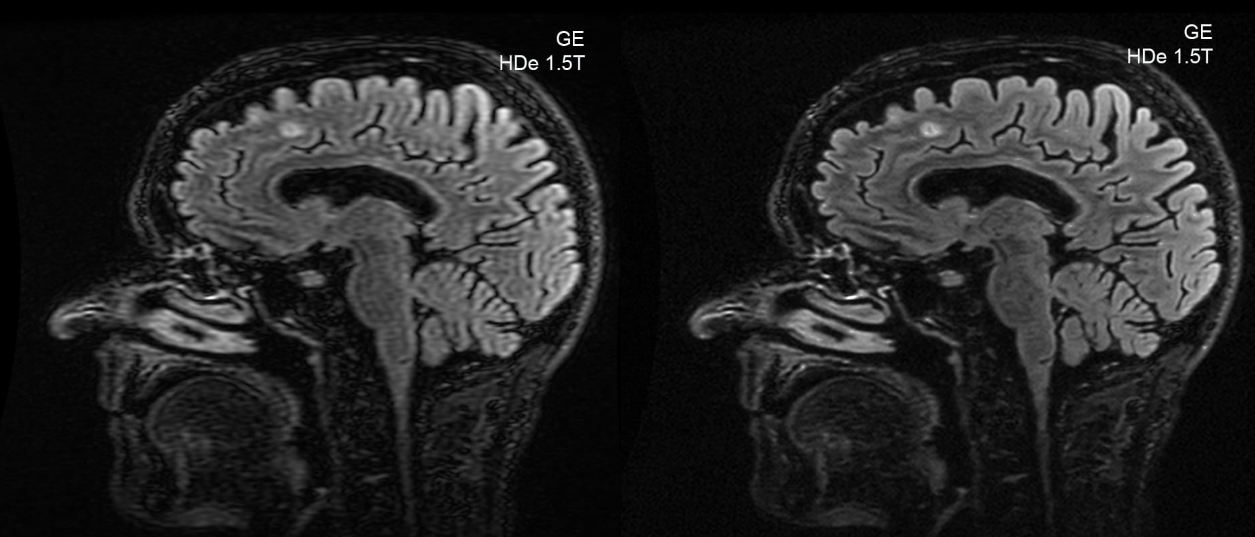
Revolutionizing Medical Imaging: Super-Resolution for Enhanced Diagnostic Clarity
Several medical image types require massive scan times that can get exponentially larger with higher resolution requirements. This trade-off is short-circuited with super-resolution to get a better look, allowing doctors to maintain enough resolution to identify details while reducing the amount of time the patient must spend in the process. It also helps in identifying objects at a microscopic level, allowing us to go further than what most optical microscopes allow and enhance details in biological samples.
How Deep Learning Helps Super-Resolution?
As we noticed in our explorations with traditional techniques, interpolation can introduce artifacts and lead to blurring in several different common cases. Hence, this task became ripe for disruption using Deep Learning techniques, wherein solutions involving Convolutional Neural Networks (CNNs) and Residual Networks (ResNets) were introduced to achieve a better output from a qualitative perspective.
These models were able to capture complex patterns and highly non-linear relationships between the pixels and give a higher-resolution image that was made on the addition and extrapolation of information already available within the image. This is a stark contrast compared to interpolation, wherein only replication took place with no new net information added.
Today, Deep Learning techniques have advanced since their first application to this task. We now have strong baseline results that point to them being significantly better than traditional Computer Vision techniques of interpolation. Hence, we will now take a look at some state-of-the-art techniques for performing image super-resolution in an upcoming blog post.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
That’s it! In this tutorial, we took a brief and quick look at the following concepts and ideas:
- The problem which gave rise to the need for super-resolution
- Current classical Computer Vision algorithms for interpolation super-resolution
- Implementing some of these algorithms using OpenCV
- Some real-life applications of super-resolution
- Why Deep Learning techniques can be better?
Super-resolution is a touchy subject, and only a few industries can confidently apply it to images. This is primarily because of the nature of artifacts that occur in the process and also because of the compute required for the upscaling.
In an upcoming tutorial, we’ll use PyTorch and Hugging Face Diffusers to use a new image super-resolution technique for upscaling images from security cameras!
Citation Information
Mukherjee, S. “Unlocking Image Clarity: A Comprehensive Guide to Super-Resolution Techniques,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/w4kr8
@incollection{Mukherjee_2024_Unlocking-Image-ClaritySuper-Resolution-Techniques,
author = {Suvaditya Mukherjee},
title = {Unlocking Image Clarity: A Comprehensive Guide to Super-Resolution Techniques},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/w4kr8},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.