
This past weekend I’ve been really sick with the flu. I haven’t done much besides lay on my couch, sip chicken noodle soup from a coffee mug, and marathon gaming sessions of Call of Duty.

It’s honestly been years since I’ve spent a weekend relentlessly playing Call of Duty. Getting online and playing endless rounds of Team Deathmatch and Domination brought back some great memories of my college roommate and myself gaming all night during my undergraduate years.
Seriously, back in college I was a Call of Duty fanatic — I even had Call of Duty posters hanging on the walls. And I had played all the games: the original Call of Duty games set during World War II; the Modern Warfare series (my favorite); even the Black Ops games. And while I was too sick to get myself off the couch this weekend, I could no-scope my through a game of Domination without a problem.
But by the end of Sunday afternoon I was starting to feel a little burnt out on my gaming session. Apparently, there is a only a finite amount of gaming I can do in a single sitting now that I’m not in college anymore.
Anyway, I reached over to my laptop and started surfing the web. After a few minutes of browsing Facebook, I came across a template matching tutorial I did over at Machine Learning Mastery. In this article, I detailed how to play a game of Where’s Waldo? (or Where’s Wally?, for the international readers) using computer vision.
While this tutorial was pretty fun (albeit, very introductory), I realized there was an easy extension to make template matching more robust that needed to be covered.
You see, there are times when using keypoint detectors, local invariant descriptors (such as SIFT, SURF, FREAK, etc.), and keypoint matching with RANSAC or LMEDs is simply overkill — and you’re better off with a more simplistic approach.
In this blog post I’ll detail how you can extend template matching to be multi-scale and work with images where the template and the input image are not the same size.
OpenCV and Python versions:
This example will run on Python 2.7/Python 3.4+ and OpenCV 2.4.X.
Multi-scale Template Matching using Python and OpenCV
To start this tutorial off, let’s first understand why the standard approach to template matching using cv2.matchTemplate is not very robust.
Take a look at the example image below:

In the example image above, we have the Call of Duty logo on the left. And on the right, we have the image that we want to detect the Call of Duty logo in.
Note: Both the template and input images were matched on the edge map representations. The image on the right is simply the output of the operation after attempting to find the template using the edge map of both images.
However, when we try to apply template matching using the cv2.matchTemplate function, we are left with a false match — this is because the size of the logo image on the left is substantially smaller than the Call of Duty logo on the game cover on the right.
Given that the dimensions of the Call of Duty template does not match the dimensions of the Call of Duty logo on the game cover, we are left with a false detection.
So what do we do now?
Give up? Start detecting keypoints? Extracting local invariant descriptors? And applying keypoint matching?
Not so fast.
While detecting keypoints, extracting local invariant descriptors, and matching keypoints would certainly work, it’s absolutely overkill for this problem.
In fact, we can get away with a much easier solution — and with substantially less code.
The cv2.matchTemplate Trick
So as I hinted at in the beginning of this post, just because the dimensions of your template do not match the dimensions of the region in the image you want to match, does not mean that you cannot apply template matching.
In this case, all you need to do is apply a little trick:
- Loop over the input image at multiple scales (i.e. make the input image progressively smaller and smaller).
- Apply template matching using
cv2.matchTemplateand keep track of the match with the largest correlation coefficient (along with the x, y-coordinates of the region with the largest correlation coefficient). - After looping over all scales, take the region with the largest correlation coefficient and use that as your “matched” region.
As I said, this trick is dead simple — but in certain situations this approach can save you from writing a lot of extra code and dealing with more fancy techniques to matching objects in images.
Note: By definition template matching is translation invariant. The extension we are proposing now can help make it more robust to changes in scaling (i.e. size). But template matching is not ideal if you are trying to match rotated objects or objects that exhibit non-affine transformations. If you are concerned with these types of transformations you are better of jumping right to keypoint matching.
Anyway, enough with the talking. Let’s jump into some code. Open up your favorite editor, create a new file, name it match.py , and let’s get started:
# import the necessary packages
import numpy as np
import argparse
import imutils
import glob
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-t", "--template", required=True, help="Path to template image")
ap.add_argument("-i", "--images", required=True,
help="Path to images where template will be matched")
ap.add_argument("-v", "--visualize",
help="Flag indicating whether or not to visualize each iteration")
args = vars(ap.parse_args())
# load the image image, convert it to grayscale, and detect edges
template = cv2.imread(args["template"])
template = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
template = cv2.Canny(template, 50, 200)
(tH, tW) = template.shape[:2]
cv2.imshow("Template", template)
The first thing we’ll do is import the packages we’ll need. We’ll use NumPy for numerical processing, argparse for parsing command line arguments, imutils for some image processing convenience functions (included with the .zip of the code for this post), glob for grabbing the paths to our input images, and cv2 for our OpenCV bindings.
We then parse our arguments on Lines 8-15. We’ll need three switches: --template , which is the path to the template we want to match in our image (i.e. the Call of Duty logo), --images , the path to the directory including the images that contain the Call of Duty logo that we want to find, and an optional --visualize argument which lets us visualize the template matching search across multiple scales.
Next up, it’s time to load our template off disk on Line 18. We’ll also convert it to grayscale on Line 19 and detect edges on Line 20. As you’ll see later in this post, applying template matching using edges rather than the raw image gives us a substantial boost in accuracy for template matching.
The reason for this is because the Call of Duty logo is rigid and well defined — and as we’ll see later on in this post, it allows us to discard the color and styling of the logo and instead focus solely on the outline. Doing this gives us a slightly more robust approach that we would not have otherwise.
Anyway, after applying edge detection our template should look like this:
Now, let’s work on the multi-scale trick:
# loop over the images to find the template in for imagePath in glob.glob(args["images"] + "/*.jpg"): # load the image, convert it to grayscale, and initialize the # bookkeeping variable to keep track of the matched region image = cv2.imread(imagePath) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) found = None # loop over the scales of the image for scale in np.linspace(0.2, 1.0, 20)[::-1]: # resize the image according to the scale, and keep track # of the ratio of the resizing resized = imutils.resize(gray, width = int(gray.shape[1] * scale)) r = gray.shape[1] / float(resized.shape[1]) # if the resized image is smaller than the template, then break # from the loop if resized.shape[0] < tH or resized.shape[1] < tW: break
We start looping over our input images on Line 25. We then load the image off disk, convert it to grayscale, and initialize a bookkeeping variable found to keep track of the region and scale of the image with the best match.
From there we start looping over the multiple scales of the image on Line 33 using the np.linspace function. This function accepts three arguments, the starting value, the ending value, and the number of equal chunk slices in between. In this example, we’ll start from 100% of the original size of the image and work our way down to 20% of the original size in 20 equally sized percent chunks.
We then resize the image image according to the current scale on Line 36 and compute the ratio of the old width to the new width — as you’ll see later, it’s important that we keep track of this ratio.
On Line 41 we make a check to ensure that the input image is larger than our template matching. If the template is larger, then our cv2.matchTemplate call will throw an error, so we just break from the loop if this is the case.
At this point we can apply template matching to our resized image:
# detect edges in the resized, grayscale image and apply template
# matching to find the template in the image
edged = cv2.Canny(resized, 50, 200)
result = cv2.matchTemplate(edged, template, cv2.TM_CCOEFF)
(_, maxVal, _, maxLoc) = cv2.minMaxLoc(result)
# check to see if the iteration should be visualized
if args.get("visualize", False):
# draw a bounding box around the detected region
clone = np.dstack([edged, edged, edged])
cv2.rectangle(clone, (maxLoc[0], maxLoc[1]),
(maxLoc[0] + tW, maxLoc[1] + tH), (0, 0, 255), 2)
cv2.imshow("Visualize", clone)
cv2.waitKey(0)
# if we have found a new maximum correlation value, then update
# the bookkeeping variable
if found is None or maxVal > found[0]:
found = (maxVal, maxLoc, r)
# unpack the bookkeeping variable and compute the (x, y) coordinates
# of the bounding box based on the resized ratio
(_, maxLoc, r) = found
(startX, startY) = (int(maxLoc[0] * r), int(maxLoc[1] * r))
(endX, endY) = (int((maxLoc[0] + tW) * r), int((maxLoc[1] + tH) * r))
# draw a bounding box around the detected result and display the image
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
On Line 46 we compute the Canny edge representation of the image, using the exact same parameters as in the template image.
We then apply template matching using cv2.matchTemplate on Line 47. The cv2.matchTemplate function takes three arguments: the input image, the template we want to find in the input image, and the template matching method. In this case, we supply the cv2.TM_CCOEFF flag, indicating we are using the correlation coefficient to match templates.
The cv2.minMaxLoc function on Line 48 takes our correlation result and returns a 4-tuple which includes the minimum correlation value, the maximum correlation value, the (x, y)-coordinate of the minimum value, and the (x, y)-coordinate of the maximum value, respectively. We are only interested in the maximum value and (x, y)-coordinate so we keep the maximums and discard the minimums.
Line 51-57 handle visualizing the multi-scale template match. This allows us to inspect the regions of the image that are getting matched at each iteration of the scale.
From there, we update our bookkeeping variable found on Lines 61 and 62 to keep track of the maximum correlation value found thus far, the (x, y)-coordinate of the maximum value, along with the ratio of the original image width to the current, resized image width.
At this point all the hard work is done.
After we have looped over all scales of the image, we unpack our bookkeeping variable on Line 66, and then compute our starting and ending (x, y)-coordinates of our bounding box on Line 67 and 68. Special care is taken to multiply the coordinates of the bounding box by the ratio on Line 37 to ensure that the coordinates match the original dimensions of the input image.
Finally, we draw our bounding box and display it to our screen on Lines 71-73.
Multi-scale Template Matching Results
Don’t take my word for it that this method works! Let’s look at some examples.
Open up your terminal and execute the following command:
$ python match.py --template cod_logo.png --images images
Your results should look like this:

As you can see, our method successfully found the Call of Duty logo, unlike the the basic template matching in Figure 1 which failed to find the logo.

We then apply multi-scale template matching to another Call of Duty game cover — and again we have found the Call of Duty logo, despite the template being substantially smaller than the input image.
Also, take a second a examine how different the style and color of the Call of Duty logos are in Figure 3 and Figure 4. Had we used the RGB or grayscale template we would have not been able to find these logos in the input images. But by applying template matching to the edge map representation rather than the original RGB or grayscale representation, we were able to obtain slightly more robust results.
Let’s try another image:

Once again, our method was able to find the logo in the input image!
The same is true for Figure 6 below:

And now for my favorite Call of Duty, Modern Warfare 3:
Once again, our multi-scale approach was able to successfully find the template in the input image!
And what’s even more impressive is that there is a very large amount of noise in the MW3 game cover above — the artists of the cover used white space to form the upper-right corner of the “Y” and the lower-left corner of the “C”, hence no edge will be detected there. Still, our method is able to find the logo in the image.
Visualizing the Match
In the above section we looked at the output of the match. But let’s take a second to dive into a visualization of how this algorithm actually works.
Open up your terminal and execute the following command:
$ python match.py --template cod_logo.png --images images --visualize 1
You’ll see an animation similar to the following:
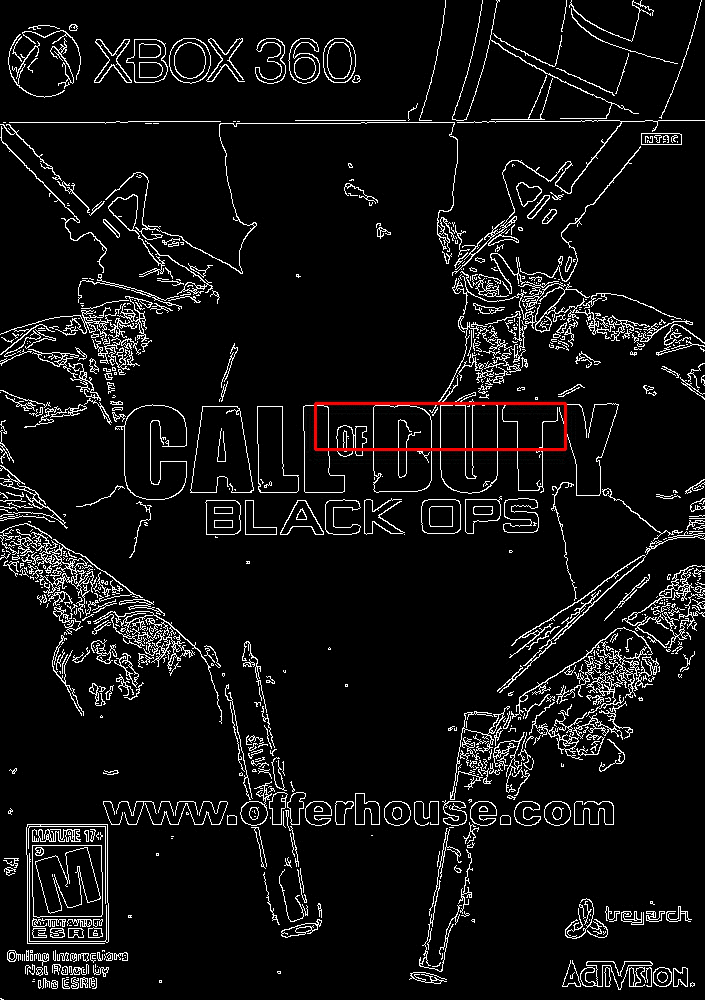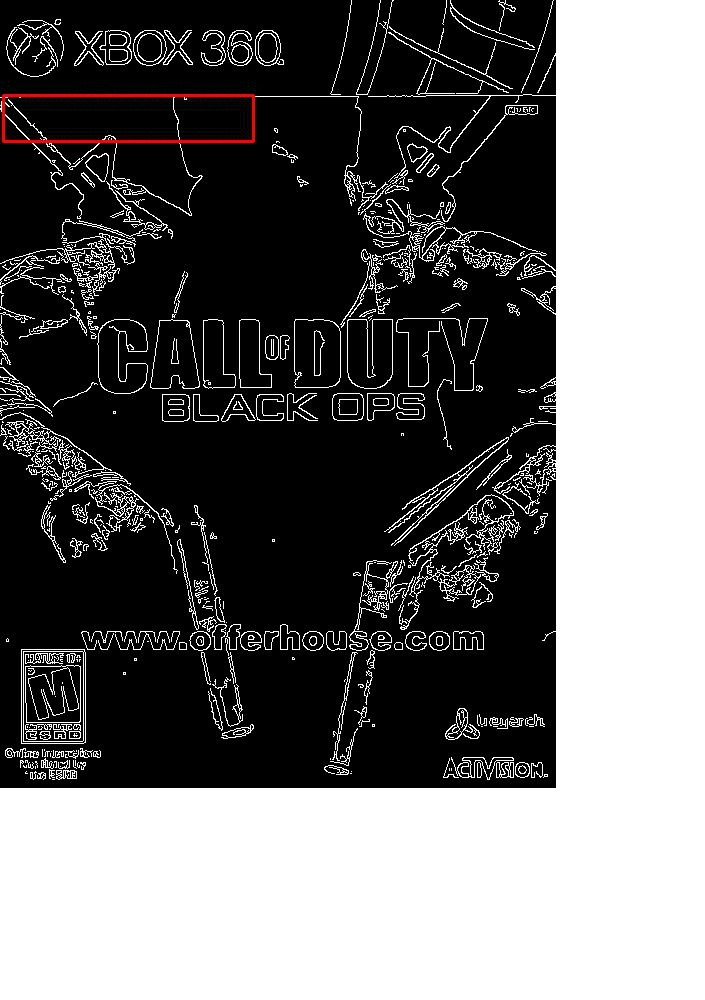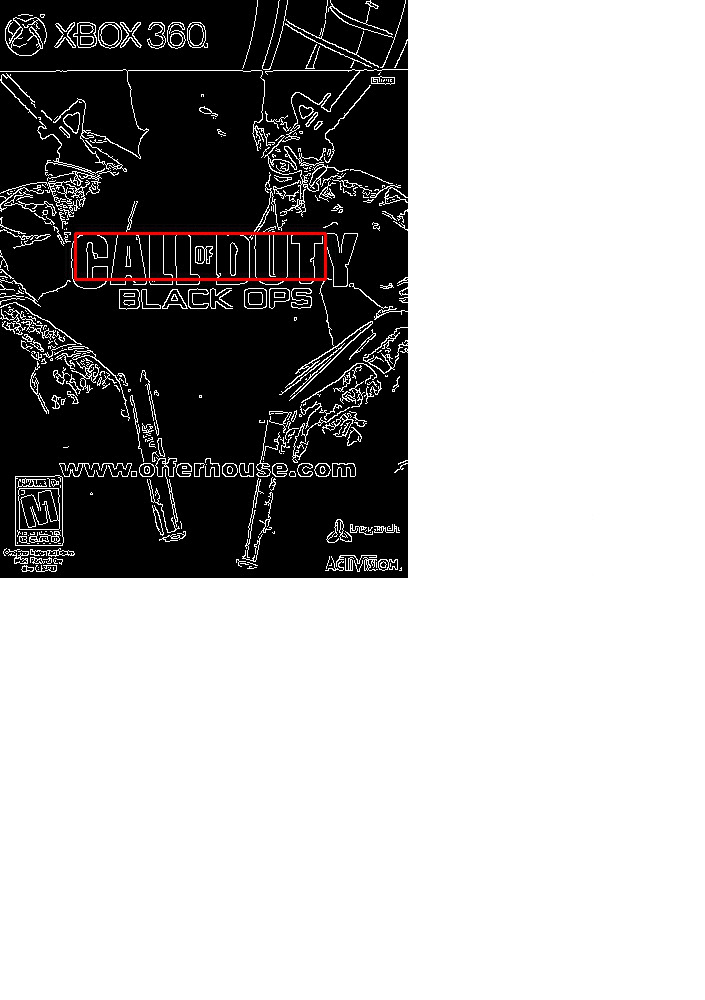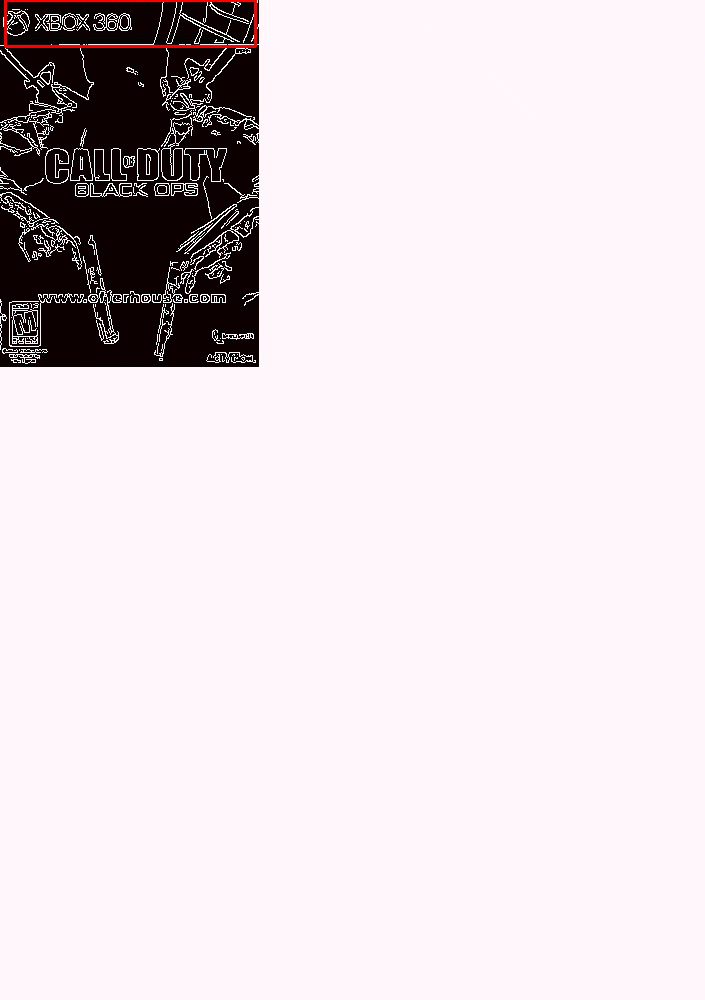
At each iteration, our image is resized and the Canny edge map computed.
We then apply template matching and find the (x, y)-coordinates of the image with the largest correlation coefficient.
Lastly, we store these values in a bookkeeping variable.
At the end of the algorithm we find the (x, y)-coordinates of the region with the largest correlation coefficient response across all scales and then draw our bounding box, as seen below:
For completeness, here is another example of visualizing our multi-scale template matching using OpenCV and Python:

Limitations and Drawbacks
Of course, applying simple template matching, even multi-scale template matching has some significant limitations and drawbacks.
While we can handle variations in translation and scaling, our approach will not be robust to changes in rotation or non-affine transformations.
If we are concerned about rotation on non-affine transformations we are better off taking the time to detect keypoints, extract local invariant descriptors, and apply keypoint matching.
But in the case where our templates are (1) fairly rigid and well-defined via an edge map and (2) we are only concerned with translation and scaling, then multi-scale template matching can provide us with very good results with little effort.
Lastly, it’s important to keep in mind that template matching does not do a good job of telling us if an object does not appear in an image. Sure, we could set thresholds on the correlation coefficient, but in practice this is not reliable and robust. If you are looking for a more robust approach, you’ll have to explore keypoint matching.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post we discovered how to make standard template matching more robust by extending it to work with multiple scales.
We also discovered that in cases where our template image is rigid and well-formed, that utilizing an edge map rather than the RGB or grayscale representation can yield better results when applying template matching.
Our method to multi-scale template matching works well if we are only concerned with translation and scaling; however, this method will not be as robust in the presence of rotation and non-affine transformations. If our template or input image exhibits these types of transformations we are better off applying keypoint detection, local invariant descriptors, and keypoint matching.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

I understand this is very simple and straightforward method. My only concern for doing a multi-scale search like this would be the time taken to find a match. I mean what would be the worst case time taken i.e if the image was say 1200×1920, and the match was found at the last scale?
You normally wouldn’t run a full-scale match on an image as large of 1200×1920 — most images are resized to be substantially smaller prior to applying template matching, object detection, etc. Luckily, template matching is a very fast operation (in comparison to other techniques).
thanks adrian!
but it is possible to make templates in the directory too and we can put many image templates for better result
Sure, you can use multiple templates. You would just need to loop over the templates individually and call
cv2.matchTemplatefor each of the, and keep track of the template that gave you the best result.I noticed that you used a PNG file as the template and JPG files as the images you are searching. Is there any advantage to using PNG, JPG, or any other image format? Will certain formats process faster than others? Will some perform better or worse when template matching? Thanks!
No, there is no difference between image formats when performing template matching. Once the image is loaded from disk, the image is always represented as a NumPy array internally by OpenCV. The only decision when using various image file formats should be (1) image size and (2) lossy or lossless image compression.
I’m using Python 2.7.9 and OpenCV 3.0.0 on my Raspberry Pi.
I ran your code right out of the (zip) box and it works! However, when I choose to enable the “visualize” function it doesn’t automatically animate. Bummer. Oddly, if I press CTRL on my keyboard it seems to step through the animations with each key press.
I was wondering if you had a quick code update to make this example compatible with both OpenCV 2.4x as well as 3.0.0?
Thanks!
I generated the animations for this blog post as a .gif so the animations would run automatically. Notice the
cv2.waitKey(0)call on Line 57 — this means you need a press any key on your keyboard to advance the progression of frames, otherwise the frames would process, display, and automatically close so fast that you wouldn’t be able to visualize them. Thecv2.waitKeyfunction is important to use when visualizing your results.Finally, it sounds like you’re just getting started learning OpenCV so. I would suggest going through the free crash courses on the blog and also grabbing a copy of Practical Python and OpenCV. This book will really help clear up any doubts or questions you have regarding the basics.
Also, I just tested the code out on my system using Python 2.7 and both OpenCV 2.4 and OpenCV 3.0. In both cases the code ran without error.
Thank you for the clarification! I saw the waitKey function and incorrectly assumed it was a delay. Which… gave me an idea.
A really cool update to your code is to change both of the waitKey functions into a 1 second delay, like this:
cv2.waitKey(1000)
That way, when the code runs using the “–visualize” argument it looks almost exactly like your animated gif. =)
Thank you so much for this example!
When I try to use an image captured by a camera (I’m using the Raspberry Pi camera module attached to RPI 2) to compare to a template (PNG file) I get an error which contains the following:
depth == CV-8U || depth == CV_32F
It appears there is a mismatch of sorts between the template and the image. I asked the image format question above and assumed that an image from the camera would be no different than an image loaded from the disk (JPG, PNG, or something else). It looks like there is a difference for images grabbed from the camera frames and I’m not sure how to attack this one. Appreciate any help you can offer!
Adrian,
I figured out why it wasn’t working when using the raspberry pi camera.
I was trying to create a shortcut by using a “template” that was already canny edge detected. After some digging I realized that a .jpg file imported into python script isn’t going to look the same after it’s converted to black and white and then edge detected (even if the template image already was black and white and edged detected!)
So, my shortcut actually turned out to be a long, wandering path through the woods and back. Like I always say: learn by doing! Just wanted to let you know that the problem is solved. You don’t have to post this on your blog unless you think that my hard lessons might benefit someone else.
Cheers,
-Brian
Thanks for sharing Brian — and congrats on resolving the issue! (I consolidated both your comments into a single one, that way if other readers have a similar problem, they can see the answer as well).
I noticed using this method that the program will always draw a box around something in the image, even if the “target” isn’t present and even when it’s clearly not a match. Is there any way to create a “threshold” parameter so that the template match must be above a certain confidence level before the box is permitted to be drawn to help prevent false positives?
Technically, yes, you can define a threshold parameter — but it will have to be manually defined. If you take a look at the
maxValvalue returned fromcv2.minMaxLoc, you can manually ensure that the correlation is above a given threshold, like this:The problem becomes setting
myThresholdaccurately. This is why more advanced methods such as keypoint detection, local invariant descriptors, and keypoint matching are more robust. They allow us to not only detect the presence of an object, but also the absence of one as well.To accurately implement a hard-coded threshold value, I ran a test to print maxVal to the terminal window so I could see what I was working with. I got values for maxVal in the range from 2000000.0 (object not present) up to 5000000.0 (object present and a solid match found.)
However, when I try to implement a threshold if-statement it doesn’t work:
if maxVal > 4000000:
…then draw the bounding box
It’s as if maxVal is a completely different value than what is printed to the terminal window, and thus, my hard-coded threshold. Any ideas on why that is happening?
Are you running your code on the same set of images? If so, then the
maxValuewould certainly not change when you re-run your script after printing them out to your terminal. There is likely a logic error elsewhere in your code. I would suggest adding some more print statements to your code and try to debug where the error is.Posting my solution for benefit of others.
I was using the wrong maxVal variable! I should have been using the one that was packed in the “found” bookkeeping variable.
To keep things simple, I created a new variable called maxVal2 and used that to trigger an IF statement, like this:
(maxVal2, maxLoc, r) = found #unpack the bookkeeping variable
if maxVal2 > 5000000:
(draw the bounding box using Loc and r)
Working great now!
Hi Adrian, this is a awesome technique and can be used in various use cases.i have a small problem. I tried installing “imutils” but it seems that the download path is broken. Can you suggest an alternative to the image resizing thing done using imuitls? Can opencv methods be used instead of using imutils?
Hey Saurav — you should be able to install the
imutilspackage viapip:$ pip install imutilsI just tested on a few of my machines and it does indeed work.
In this line of code:
if found is None or maxVal > found[0]:
…what is the purpose of “is None” ?
Thanks!
Since we initialized
found = NoneonLine 30, we need to make sure it is notNonebefore we access an array in the list (which would cause an error to be thrown).Okay…. how we can create threshold or detect that out template doesn’t match with input picture?
You will need to manually specify that threshold. You determine it via trial and error by examining the correlation values for matches vs. non-matches.
Hi Adrian,
The project is quite interesting ! Thanks for sharing 🙂
I have a idea of scanning of 2 templates to search in a single hit is that possible ??
Thanks,
SAI
Can you elaborate on what you mean by “scanning 2 templates to search in a single hit”? I’m not sure what you mean.
Hi Adrian,
Thanks a lot for sharing!
I was searching for a solution to verify a video in which a single icon is displayed in random sizes at random positions (like a screensaver).
Your logic worked like a charm 🙂
Fantastic! I’m glad it worked for you Rateesh! 🙂
Hi Rateesh ,
how you did it ?
can you help me or Adrian to find the solution for this Problem ?
or can you send your code ?
Thank you in advance 🙂
Hi Adrian,
Thanks for a great post.
You mentioned that this method is not the most effective for detecting if an object does *not* appear in the image, and refer to keypoint matching. I looked into this, specifically using SIFT/SURF features and it looks promising. I was just wondering how you would use the results of such a matching to more robustly determine wether the queried object actually exists within the image or not?
Determining if an object does/does not exist in an image using keypoints and local invariant descriptors (such as SIFT and SURF), can be broken down into three steps:
The goal here is to determine the “inlier” keypoints (true matches) versus the “outliers” (keypoints that could not be matched between the two images). Based on the number of matched inliers, we can determine if an object contains a specific object (or not).
If you’re interested in learning more about this topic, take a look at Practical Python and OpenCV where I detail how to use keypoint detection, local invariant descriptors, and keypoint matching to identify the covers of books. The same approach can be used for other object matching as well.
Hi Adrian, huge thanks for this great article!
I got two questions:
1. What is the reason for looping over multiple scales of the input image, instead of trying multiple scales of the template?
And do you agree that scaling the template could be faster, processing-wise, since the template is generally much smaller than the input image?
2. For what reasons do you discourage using template matching when there’s changes in rotation?
Is it simply because of the processing time it would take to loop over multiple rotation angles, especially if combined with looping over multiple scales?
In general, the template is substantially smaller than the source image. Thus, in order to detect the template at various scales of the image, we apply an image pyramid. While it may be faster to resize the actual template, it won’t help us much if the region we want to detect in the image is larger than the template.
And yes, you could apply template matching with rotation as well. You would simply need to loop over all possible rotations of your template image. However, consider applying template matching in 5-degree increments. That means you would need to evaluate 360 / 5 = 72 templates per layer of the pyramid. This quickly becomes quite slow and computationally expensive.
For objects that can appear under various rotations, I suggest using keypoint detectors and local invariant descriptors such as SIFT, SURF< etc.
Thanks for your reply!
I thought about it a bit more, and realized that I was wrong suggesting that scaling of the template could make the process faster.
What I meant was looping over multiple scaled-up versions of the template, as opposed to looping over multiple scaled-down versions of the input image.
My thinking was that this would be faster, when it comes to resizing that we’re doing inside the loop – because we’d be dealing with a smaller amount of input pixels to resize.
However, I completely forgot about the computational cost of matching the template.
And now I realized that when keeping the input image untouched, the cost of matchTemplate() would stay the same, or actually grow as we’re going through the loop and the template gets larger and larger.
With your approach in this example, I’m assuming that matchTemplate() becomes faster and faster, as the input image gets smaller and smaller. Which probably makes the entire process more efficent than what I was trying to suggest.
Cheers!
Correct, as the input image becomes smaller, there is less data to process, thus
cv2.matchTemplatewill run faster.I know that this is old post, but if you change the scale, you then change the values of coeficient calculations, so you could not compare results from different scales.
Hi , i am matching a image of some text and , it matches even if it is not the same text . how to set threshold in this ??
Take a look at Line 47 — the
resultvariable contains the correlations with largest values. You can threshold this variable to prune false-positive regions. Alternatively, you might want to find multiple local maxima using something like scikit-image.Hi, in mutiscale template matching , how can i get the co-ordinates of the image that matched with the template and also i need to click on that co-ordinates. please hepl me out in this . Thanks in advance
The coordinates of the matched template are returned by
cv2.minMaxLoc— see Line 48. As for clicking the coordinates, take a look at this blog post on mouse events, it should help point you in the right direction.Hi, scikit-image url is not working ? Thanks
The scikit-image website is working just fine. Perhaps check our internet connection? Otherwise, I’m not sure what your question is.
Dear Adrian!
Id like to make a small raspberry project to detect star signs in the sky at night.
The average star diameter in the image is 3-4 pixels.
Its hard for me to decide which way to go.
Template matching or feature detection?
What would you suggest?
Bests!
Gaspar
Detecting constellations in the sky is actually a pretty challenging computer vision problem. I would recommend using either (1) template matching or (2) detecting each star, trying to identify important ones as landmarks, and then using the geometry (i.e., angles between important stars) determine your constellations.
Dear Adrian!
Thank you for the reply.
I guessed i could make templates in a “starsign database” folder and using a wide angle lens take one photo of the sky and match it with database.
The photo is 5mp so it will really need a fast solution.
Template matching may work i think:)
I will start to test as soon as i can get opencv working on my pi.
Hi Adrian
How to put text or labelling on that red retangle matched text
simillar text like:
https://pyimagesearch.com/2016/02/15/determining-object-color-with-opencv/
*sorry ugly english
You can draw a rectangle using
cv2.rectangle. And drawing text can be done usingcv2.putText. The blog post you linked to in your comment demonstrates how to use thecv2.putTextfunction to draw text on your output image.Hi Adrian
what if we have bigger template than the object actually is in the frame we are scanning? For example if our template is something the size of 9x9x9, but in the frame it is ‘far away’ and it looks like it is 3x3x3? What would be the best course of action? Downsizing the template and scanning the picture with that or something else? Assuming we don’t know anything about the incoming frame, how to decide what to downsize?
Hey Antonio — if you’re worried about having a larger object that what appears in the frame, then you should upsample (i.e., increase the size of) the frame prior to processing. You could double the size of the input frame and then apply the same method detailed in this post.
why don’t you scale the template image instead of original image. It’ll save time.
How exactly? Also, you need to scale the template down, otherwise you would infer information, which is generally bad (unless complex AI is involved)
Hi guys,
I had rewritten the python code in C++ for some work that I was doing and I thought to share it so that everyone could benefit.
Code is mostly the same except that my code has the image names hard-coded in the source code. If anyone needs it, the C++ code can be downloaded from here: http://hassannadeem.com/assets/code/multi_scale_template_matching_cpp.zip
Thanks for sharing Hassan!
Hi Adrian,
First I would to thank you some much for this tutorial, you’ve made a great job. It helps me a lot while I was doing some research for matching template code !
I used your code to find a microchip in a image taken by a camera, and then corrects the position of a robot which manipulates the chips. The program of the robot must run several hours, and unfortunately, around 45 minutes of running, the program crashes and an error raises: OpenCV error Out of memory !
It crashes always at the line 47 ” result = cv2.matchTemplate(edged, template, cv2.TM_CCOEFF)”.
Have you ever had this kind of problem before ? If yes, did you find a solution ? Or did you have any idea of what creates this memory leak ?
For information, I run this program on a Raspberry Pi 3 model B.
Thanks !
How big (in terms of width and height) are your images? Normally, we don’t compare images that are larger than 600-800 pixels along their largest dimension. It could be the case that you are comparing two gigantic images and then running out of memory.
My Template does not exceed 400 pixels for the largest dimension, but I try to find this template in an image of dimensions 1280 x 720 pixels. So yes I try to find it in a gigantic images, but it’s really strange that it runs out of memory after 45 minutes (The function is called maybe around 50 times).
Do you suggest that I have to reduce the size of the image in which I search the template ? In that case it worries me a little bit, because I don’t know where is the template in the image, so I can’t crop the image in a blind way, and also I have to know exactly the number of pixels between the center of the image and the template found in the image, to correct after that the position of the robot I command.
Is any way to change the scale of the image, find the template and then do the inverse to have the exact number of pixels like I found it in the native image ?
This sounds like it might indeed be a memory leak issue. If possible, try to profile your code and see where the memory leak is coming from. If you’re reading the frames from a video stream, then it might be possible that is where your memory leak is coming from.
Good morning, Adrian! First of all, thanks for your work.
I’m a turtle (@balbino_live) trying to select my future winner lotto ticket.
The thing works well if I detect something like a white dot painted/attached on my shell. Numbers are selected and tweeted correctly. Take a look at this tweet:
https://twitter.com/balbino_live/status/704621280037900288
But now I want to track my moves using a template of my body (or shell), but of course, I’m in a irregular shape, and I can be at the sun, or underwater, or going upwards or downwards.
Some suggestion to a better approximation? May I try with many rotated templates of my body? May I try finding a shape like an oval (I was using circles for the white dot)?
Thanks again, Adrian!
I took a look at your Twitter link and I do indeed see the lotto functionality. However, I’m not sure what you are referring to in the second half of your question? Can you elaborate more and perhaps explain what I’m looking at?
Thanks for your answer, Adrian.
First try:
The Pi camera, at random time intervals, detects if the turtle moved from the previous one, takes a snapshot, and translate its actual position to a lotto digit using a numbered net, until the whole draw is completed.
Problem for me:
I want to detect position of the turtle in the image (without having to paint a fixed shape as a white dot for reference).
The turtle has not a fixed shape (example: legs in or out), COLOUR (may be taking the sun or being underwwater), and POSITION (may be walking up or down); it’s becoming difficult for me to recognize it. This is why I used a fixed white dot in my first tries.
So:
I don’t know which could the best approach. May be training OpenCV to recognize the turtle? May be comparing against a shell-template in various positions? Etc.
Hope I could explaint it well. Thanks again.
Balbino.
This sounds like a neat project, thanks for the added information. My first thought would be to recommend thresholding, both normal thresholding and adaptive thresholding, to help you segment the foreground (the turtle) from the background (the rest of the image). Thresholding will work regardless of positioning.
The problem then is that color could vary dramatically. This isn’t an issue as long as their is enough contrast between the background and the foreground, but if there isn’t thresholding will not work.
I would also suggest applying template matching where you have a “template” image of each turtle position and then try to match the template to the input image.
Again, I don’t think I know enough about this project to give super great advice off the top of my head, but this is where I would start.
Hey Adrian, I was wondering. Can I multi-scale the template, instead of the image ? I asked this because I have more than 1 objects in my image that [supposed to] match the template.
You certainly can.
Hey Adrian,
Thank you so much for your post and your work!
Curious what your guidance would be on rotated rectangular templates matching. A brief tale of my struggle is as follow:
1) CCOEFF method is great b/c of intensity scaling. However, only SQDIFF and CCORR takes in a mask to effectively produce the rotated rectangle template: unfortunately, results of these two methods (w/ masks) are riddled with false positives. Often, these false positives get higher match scores than the actual part of the image that the template was extracted from, especially when the template lacks sharp features.
2) Naive as I am, I went ahead and built a custom function to do CCOEFF with masking. Results work. However, even after leaning down the loops, adding all reasonable early exits, and implementing multiprocessing, this function was still ~2 lightyears slower than the opencv implementation.
3) As one last hail mary, I tried to “trick” cv2.matchTemplate(…CCOEFF…) into ignoring the masked pixels of the rotated rectangle by setting the BGR values of those pixels to the average BGR value of the template, thinking that theoretically, the contribution of those pixels to the CCOEFF calculation would be then be zero (due to the intensity scaling part of the calculation). Result: no bueno. False positives galore..
Any advice on how best to proceed?
Best,
Joe
Ouch, matching rotated rectangular templates is a real pain. Instead of using template matching I would instead use keypoints, local invariant descriptors, and keypoint matching. These methods are by their very definition invariant to rotation. I demonstrate how to build a system to recognize the covers of books inside Practical Python and OpenCV that would help you accomplish this. If you want to share more details about your project and the types of ROIs you are trying to match I can also give you a better idea if the book will help.
Hi adrian,
I am very thankful for posting this kind of solution. It helped me a lot. I am having query regarding different dpi images. i have single image with different dpi like 100dpi, 200dpi,…500dpi. So what dpi of template i should take for matching?Actually, i dont have idea about relation of dpi with image. So i am not able to detect Region of interest. My goal is to find text “PNR” which will be taken as a template for matching to destination image and after getting it as reference point, i have to detect outer rectangle where text is written inside rectangle. Please guide me to resolve this issue or provide me some reference to understand how dpi affect in template matching.
Thanks,
Ruhi
I wouldn’t worry about the DPI as long as its consistent between your template and source image. If you have a template image with 100 DPI then use a source image that also has 100 DPI (assuming this is possible).
Hello,
How would I extend the tutorial to be able to find multiple occurrences of the template in the target image. For example: If “CALL of DUTY” was present x times in the image, how would I draw x boxes around each instance.
Thank you for your time.
Mukesh.
To detect multiple objects via template matching you would:
1. Take the
resultvariable outputted fromcv2.matchTemplate2. Threshold it to find (x, y)-coordinates that have a confidence greater than N (you would have to define N manually).
3. Treat each of these (x, y)-coordinates that have a high correlation score as a detected object.
Again, the trick is setting the correlation threshold right.
Hello,
Wanted to ask what was your reason for using CCOEFF method for this example instead of the other 5 methods?
Thanks
For most template matching applications the correlation coefficient tends to give the best results. I would recommend testing the other methods as well, but again, for out-of-the-box template matching I would recommend the correlation coefficient by default.
Hello,
I am new at this field so, sorry in advanced for my question.
I’ve downloaded the script from the zip file, and it can’t run..btw, I;m using the standard script Python 3.6 and the latest opencv. so does this mean i have to change the directory of the template and the image??
It’s hard to say what the issue is without seeing your exact error message, but yes, make sure you are in the source code directory after unzipping the package before you execute the Python script.
Hello Adrian,
I am so thrilled by your blog.
Nevertheless, running your code I get the following:
” (_, maxLoc, r) = found
TypeError: ‘NoneType’ object is not iterable.”
I checked on stackoverflow and so on, but I do not get how that happened and how to solve it. Do you have any clue or advice?
Thanks in advance.
If you are getting this error it’s because no match was found (Lines 61 and 62).
Hi,
I have to find three templates into a live stream (webcam) how can I do that??
Thanks in advance.
1. Grab the frame from your webcam.
2. Loop over each of the three templates.
2.1 Apply template matching to the frame for all three templates
If you need help learning the basics of OpenCV and accessing a webcam stream, I highly recommend that you work through Practical Python and OpenCV to learn the fundamentals.
how to detect this using real time, i would like to detect using web camera. what are the changes that i can go??
You would need to update the code so that it accesses a video stream and applies template matching to each frame. I discuss how to access your webcam in this blog post as well as in Practical Python and OpenCV.
Hello Adrian! Stumbled upon this post and this has helped me immensely to integrate opencv with pyautogui in a project I am working on!! Thx!
Thanks Sohit — I’m happy to hear the PyImageSearch blog helped you! Have a great day 🙂
Hi Adrian,
I am using your example to identify objects on application screens to guide end-users. The templates are first recorded and stored as a functional instruction (Guide).
The matching is OK when the original template is smaller than the image to match. But what when the template is bigger? I get negative results.
What would be the best approach to match when the template is bigger? I tried to resize the original template after recording to a smaller size but that does not improve the matching.
Thanks fro sharing your knowledge.
If your template is larger than the image you are trying to find the template it, you can either (1) resize the template or (2) increase the size of your input image. Depending on the complexity of the objects you are trying to recognize, it might also be worth to train a custom HOG + Linear SVM detector.
What is the maximum value that maxval can take?
Hey Adrian, whats the reason for using ‘resize’ from ‘imutils’ rather than from ‘cv2’, if any ?
The
imutils.resizefunction automatically takes care of ensuring the aspect ratio is the same whilecv2.resizedoes not.Super basic question – where do I save the source code to be able to run it from the terminal? Thanks.
First, you should use the “Downloads” section of this guide to download a .zip of the source code. Save it anywhere on your machine that you would like (your “Desktop” or “Downloads” directory would be a good start). Unarchive the code. Open up a terminal. Change directory to where your newly downloaded source code lives. Then execute the script.
If you need help learning the fundamentals of computer vision and image processing (along with some experience using the command line), be sure to work through Practical Python and OpenCV. This book is designed to help you master the basics quickly and pain free.
I keep getting the following error:
usage: match.py [-h] -t TEMPLATE -i IMAGES [-v VISUALIZE]
match.py: error: argument -i/–images: expected one argument
Does anyone know what would cause this?
Please take the time to read up on command line arguments before continuing.
Great as always, Adrian!
Do you know what the best to match template of binary dots field with image?
Hi Pavel — I would need to see example images of what you are trying to detect.
Good example of this task is constellation detection: for example to find on the star night photo https://goo.gl/images/4gp99F the constellation of the great bear https://goo.gl/images/JHHi8Y.
And the other big problem that very intersted for me is how tracking every point after capturing and setting corresponding after template matching?
Applying computer vision to astronomy is an entirely specialized field, one that I don’t have much working knowledge over (as I’ve never studied it before). There are even dedicated libraries to astronomy and computer vision. I would suggest taking a look at AstroCV and the associated slides if your goal is to apply computer vision to the images you linked to.
I just have a huge doubt regarding correlation coefficient and I hope i’ll get better answer.
I have a list of template images and only one target image. Now I’ll loop through the template images and match it with the target image and will get the max Val (Correlation coefficient value ). So now I have the max Val (Correlation coefficient value) of one image which has the highest correlation coefficient value, so I’ll show the image which is highly correlated, to the user. But the problem with this approach is, consider a scenario where the target image is no way related to the template images but still, i’ll get a correlation coefficient value (r). So now what is happening is my code is showing me the image with the highest coeff value but the image is no way related to the template images. So I’m planning to set a threshold value or is there any other way to detect false positives?
I have no idea on how to set the threshold value. Please guide me.
You are correct, in this instance you would set a threshold to detect false positives. You would need to manually determine the threshold yourself by testing against a bunch of example images.
If you’re concerned about false-positives a better approach would be to use keypoint detection + local invariant descriptors + keypoint matching. I demonstrate how to use this method (and filter out false-positives) inside Practical Python and OpenCV where we build a system to recognize the covers of books. Be sure to take a look, I think it will help you out a lot in this project.
What if the size of of call of duty on my test image is smaller than size of the template. How can we handle that scenario. Shall we then reduce the size of templates too over various scale?
You could reduce the size of the template or you could adjust the image pyramid step to increase the size of the original image instead of just downsampling it.
Hello Adrian,
My test image is having template matching image in multiple places.
How to detect those many matching place.
Right now, only one matching place i am able to see in result.
Take the resulting output from
cv2.matchTemplateand then threshold it to determine all (x, y)-coordinates that have a confidence greater than T — these will be your detections. Please note that you will have to set “T” yourself. I would suggest experimentally tuning the value and seeing what works best for you.I am new to using OpenCV and Python. Can you add this above specified line of program to match multiple occurences in a single image?
can i use this code for real time object detection. I want to detect the object from live streaming. Please tell me how can i do this? Thank you.
For simple objects, yes, absolutely. An example of accessing a video stream can be found here and inside my book, Practical Python and OpenCV.
Hello Adrian,
This is a great post. Can this method be adapted to identify multiple occurrences of the template in an image? if so, can you kindly advise how?
Hello Adrian, please ignore my question, just realized that its been asked earlier in the comments section.
hey Govind, have you figured out how to apply Adrian’s advice of identifying multiple occurences into practice? If so, please do provide those lines of code here as I am new to OpenCV and want to learn about it or else explain the concept in depth for me understand. Thanks in advance.
Thanks for all the help! Is there any way to return the pixel coordinates of the center of the image being matched? I’m using a circle for my template image.
The bounding box coordinates are returned on Lines 67 and 68. Add the x coordinates and divide by two. Do the same for the y coordinates. This will give you the center coordinate of the bounding box.
Thanks Adrain,
It works fine. However, this algorithm doesn’t lend itself to the problem of detection of multiple instances of an object with varying colors. Say you want to detect the stars on a US map colored differently from that of in the template image. How would you tweak your code to suit the problem at hand?
Appreciate you time.
Since this method computes the edge map before applying template matching you could use this for varying colors. For more advanced object detection that can discard color information, take a look at HOG + Linear SVM. I demonstrate how to implement this framework inside the PyImageSearch Gurus course.
How can I display only the most accurate result of the image matching? Thanks.
Hey CJ — what does “display the most accurate result” mean in this context? What exactly are you trying to display?
how can i run this example on python27 IDLE
I mostly see OpenCV articles as it relates to comparing images. Can you use Template Matching to categorize scanned forms/documents? I have to enter data by sifting through tons of government forms. There can be 9 different versions of the same form (e.g., so the handwritten info could be 9 different places) and everything is named DOCUMENT(1xxx).TIF. It’s government, what do you expect?
I saw you had a tutorial on recognizing handwriting so i was thinking of put 2 & 2 together 🙂
Step 1: recognize the kind of document (Form RW-2107.rev53, badnames-2018-01.blah)
Step 2: if it’s a document we want, search the area on the document for handwriting there
Step 3: If there’s handwriting, read it!
Step 4: Go get coffee while the machine does my job
Hi Jaan — you can absolutely use template matching or some form of feature extraction + matching method to categorize scanned forms or documents. Exactly which method you would use depends on the images themselves. Do you have any example images of what you’re working with?
Thank’s a lot Adrian.
its very helpfully. But i want to ask something, how can i put other templates in the same project for the perfect result ?
If you want to use multiple templates you would need to loop over each of them individually, perform the matching process, and then keep the one with the largest correlation score.
Hi Adrian,
Thanks a lot for such a Nice blog. Could you please let me know how should we match a template of size greater than Input image(Input image consists of a white space and template of reduced size).
Perhaps I’m misunderstanding the question but is there a reason you cannot resize your template so that it’s smaller than your input image and then apply template matching?
I cannot find the code, do we have to copy paste and use it, what abt the required packages? Can someone please help…I really loved this work!
Scroll down to the “Downloads” section of this blog post and then you can download the code. You do not have to copy and paste.
hi Adrian, I used your code and it worked fine when the template images are extracted from the same big image…
Say I have to check for a logo of a company and I have the logo image with me but it is in a bigger DPI and larger scale. Now I have to verify if the same logo appeared in a PDF report which I have converted into PNG Image each page. Since the logo image in the PDF page is smaller in size as it is in the header, the scaling doesn’t work…Do you have any suggestions as to what can be done…
I tried to increase the scaling from edged = cv2.Canny(resized, 50, 200) to edged = cv2.Canny(resized, 50, 500)… but this too doesn’t seem to work…it identifies some other area on the page…
I also wanted to try with some other color scheme of the logo image…did not work…it really works flawlessly when the image is extracted from the same larger image…any ideas plss?
Thank you for this wonderful work!!! 🙂 Kudos to you!
There are a few ways to approach this problem but if you want a more robust approach I would actually recommend either:
1. Applying keypoint matching via keypoints local invariant descriptors
2. Training your own custom object detector for each logo
How many example images do you have per logo? Or do you only have one (i.e., the template)?
First of all, a big thanks for your help!
Yes I have one logo, say for example the logo of “Google”, and I want to search this Google logo in all the documents we have, so the size may vary with each document, but since it is a logo, the design wont change, however there maybe changes in number of pixels, scale, DPI, and color variations, since the documents will embed these logos in their own way…
1) I have seen the Keypoint descriptors but they draw lines or just mark the points on the image…What if I wish to create a box around it like u did and also would it work for varying scaled images…
2) I am unaware of how to do custom object dectector training for each logo…can u point me to some URL where I can learn this pls?
Thank you for ur time!
1. If you wanted to continue to use simple template matching you can try. You would just resize your input logo image to be either larger or smaller depending on your use case. You would need to experiment with this approach.
2. You can turn the matched keypoints into a bounding box. Have you seen my chapter on recognizing the covers of books inside Practical Python and OpenCV? Inside the book I demonstrate how to use keypoint matching to accept (1) and input query image and (2) match it in a separate image. This would help you with the project.
3. You could start with a HOG + Linear SVM detector which I discuss how to implement and train inside the PyImageSearch Gurus course. The problem is that you will need to gather many example images of each logo that you want to detect and recognize. If you do not already have this data you would need to gather it.
Thank you very much Adrian, I would look into your suggestions…Awesome help!
Hi Adrian,
Thanks for this wonderful article… I copied your code and ran it for fun. It has so much potential.
Also read through the comments and it amazing that you answered almost every question asked. There must have been repeated questions to the point where I got annoyed reading through it… I don’t know how you do it man… kudos for having the right attitude and sharing not only your knowledge, but also your wisdom.
Thank you Todd, I really appreciate that 🙂 It can be tedious at times but I do my best to remind myself that we are all here to learn.
Can you suggest an approach of rotation & scale invariant approach that does not have license limitation ?
ORB would be a great start. I actually cover ORB detection and matching inside Practical Python and OpenCV and the PyImageSearch Gurus course.
This is good work, nice job.
Thanks Toby!
Hi Adrian,
Thanks for the wonderful article!
Just why scaling the main image and not the template? The template is smaller than the main image and scaling that instead could potentially save some time!
Try it and see! I recommend learning by doing, it’s the best way to learn.
Hi Adrian,
Greetings!
Loved this post, gives truly deep insight in rescaling the images and finding matches. I went through the various questions posted above, and I too had one of the same question – “Can u pls provide an excerpt of code for your suggestion:
1. Take the result variable outputted from cv2.matchTemplate
2. Threshold it to find (x, y)-coordinates that have a confidence greater than N (you would have to define N manually).
3. Treat each of these (x, y)-coordinates that have a high correlation score as a detected object.
How do i normalize it? I get thick huge bounding boxes around the entire image everytime. I guess I have to reduce the number of bounding boxes created. Could you pls help…
Hey Percy, thanks for the kind words. I don’t have code snippets on hand for what you requested. I’m so happy to provide these free tutorials for you to learn from but I also have a large number of readers to help and support. There are times when I simply cannot write code for everyone, otherwise I would never get anything else done! I may revisit this topic in a future tutorial though!
If you are truly interested in learning more about template matching and object detection I would recommend you join the PyImageSearch Gurus course where I cover the topics in detail. There are also dedicated forums where I can provide more detailed answers to your questions.
Hi Adrian,
I’m trying to match template image in a given image. But my problem is that the template image has some regions which are to be ignored. I have a binary image same as the size of the template image stating regions to ignore while trying to match the images.
In short i have 3 images namely the main image, template image and the binary image containing regions to ignore. How can I solve this use case. Need your help with this.
Thanks
I would need to see example images of what you’re working with to provide suggestions.
Lines 54 and 55 show you how to get the bounding box coordinates.
Hi Adrian, thanks for this very nice tutorial. I’ve been struggling to code a robust circle detection routine using several techniques. When apply template matching to my data I was surprise to find it works pretty well.
The main drawback is the sensitivity to the number of different scales you try.
Are there any tricks to achieve sub-“scaleStep” accuracy without trying a lot of possible steps?
I’m not sure what you mean by sub-scale steps. If you think a particular scale works well then you could manually define the set of scales you want to test and include more fine-grained scales for the “most likely” scale the object could be at.
Wonderful article and just what I was looking for. Cheers!
Thanks Brenden, I’m glad you enjoyed it!
what is the best way to implement same in real-time.
This method can run in real-time on a CPU. You just need to access your camera first.
Hi, Adrian.
On source image i have 2 identical templates, but detected only 1 template. How to make a definition 2 templates?
You would need to threshold the returned confidence map. Find all locations that have a confidence greater than T (but you will need to tune and set T manually).
Hello Adrian
How difficult to apply the same technique to solve jigsaw puzzle? And would be nice if can be done in real time by just put each piece in front of the camera, then it tell us where that piece goes. Of course the complete picture already uploaded to the computer.
Thank you very much
As far as I understand, It’s essentially impossible to solve a jigsaw problem. Even if you could reliably segment the puzzle pieces there are too many possible rotations for each piece. If each piece is square it would be possible though.
Hi, is this better than feature matching?
“Better” can only be defined in context of the problem. Feature matching is typically more robust but also computationally more expensive. Multi-scale template matching could be less accurate but could also work better for objects with very little texture.
Hi, Adrian, this is a good tutorial. I like it! just a very simple question: why do you use edge map for template matching instead of grayscale image? I saw one reason is that using edge is faster. Is there any other advantage for it?
The edge map was more accurate in this case.
The link provided by you at starting of tutorial is not working .
https://machinelearningmastery.com/using-opencv-python-and-template-matching-to-play-wheres-waldo/
Strange, I guess Jason decided to take down the tutorial. I would reach out to him directly and ask why.
There is a copy on archive.org at https://web.archive.org/web/20170918035306/https://machinelearningmastery.com/using-opencv-python-and-template-matching-to-play-wheres-waldo/
Thanks for sharing David!
Adrian, first of all keep up the good work, IMHO all of your posts are of very valuable information.
Regarding on how to detect when the logo is not present insteadd of using a threshold I thought on using “keypoint detection + local invariant descriptors + keypoint matching” but only on the selected area from template matching.
That makes sense for you?
Thanks in advance
That is exactly how you approach the problem. Check the output of the homography and ensure enough inliers are matched. Practical Python and OpenCV will teach you how to do exactly that.
Adrian, I was thinking on using SIFT/SURF/ORB on the selected zone choosed by the template matching but I don’t see clearly why to use homography taking into account that our images never change its perspective, can we use homography when the image and the template will always share the same perspective?.
As you can infere I’m just a beginner so, please, be patient with my questions.
Thanks in advance
Hi Adrian, is there a way to find the matching score of the image when it matches the template?
Yes, you can grab the correlation score via:
score = result[maxLoc[0], maxLoc[1]]It may also be:
score = result[maxLoc[1], maxLoc[0]]You should refer to OpenCV’s documentation to determine the proper indexing into the
resultarray.Hi Adrian,
What will happen if the image is rotated….will this work? If not what to do?
Or can we not use template matching for rotated images at all??
Template matching will not work for rotated images. For rotation I suggest using keypoint detection, feature extraction, and keypoint matching — all of that is covered inside Practical Python and OpenCV.
Could you do the same thing but also loop through skewing to allow for object detecting in 3 dimensional images?
Hello, what is the intuition or what is happening on line 53? So I understand that you want to draw a red border and cv2.rectangle() takes an image for its first parameter, what is the reason for passing np.dstack([edged, egded, egded]) as the image?
I used an image (opened with cv2.imread()) as the first parameter and it works the same. If passing an image does the same thing, what are the benefits and differences between using an np.dstack vs the actual image?
The “edged” image is a single channel image. We call “np.stack([edged, edged, edged])” to turn it into a 3 channel RGB image which in turn allows us to draw on the image.
I would like to know if i can detect more than one object using the template and multi-scaling, for example if a have a template with a bird and an image where there are 10 equal bird. I would like to put a squared around each individual bird. thanks a lot.
I wonder if you provide with a code.
thank a lot
Luigi Salemi
Take a look at the other comments on this post as I have already addressed that question.
That said, instead of template matching I would recommend you use a dedicated object detector.