
Table of Contents
Netflix Movies and Series Recommendation Systems
In this tutorial, you will learn about Netflix movies and series recommendation systems.

In this blog post, we will dive deeper into the Netflix movies and series recommendation systems (Figure 1). The Internet has revolutionized how we consume television through Over-the-Top (OTT) content streaming platforms like Netflix, Amazon Prime, Disney, HBO, etc.
With over 139M paid subscribers in 300 countries, Netflix has evolved as a successful streaming platform. We all have been in a place where after a long day of work, we turn on Netflix to watch our favorite shows. And, thanks to Netflix recommendations, we don’t have to worry about what to watch.
Netflix recommendations are not just one algorithm but a collection of various state-of-the-art algorithms that serve different purposes to create the complete Netflix experience. This Netflix experience keeps users hooked and away from canceling their subscriptions. Therefore, everything you see on Netflix is a recommendation.
Whenever you watch something on Netflix, the system collects various kinds of data, which is then consumed by these algorithms to update recommendations on your profile home page the very next day. This data includes your location, watch history, ratings, device information, whether you left the show in the middle, etc.
This lesson will cover several aspects of Netflix recommendations and how they work behind the scenes.
This lesson is the 2nd in a 3-part series on Deep Dive into Popular Recommendation Engines 101:
- Fundamentals of Recommendation Systems
- Netflix Movies and Series Recommendation Systems (this tutorial)
- LinkedIn Jobs Recommendation Systems
To learn how Netflix recommendation systems work, just keep reading.
Netflix Movies and Series Recommendation Systems
We will start with the overview of Netflix recommendations and then dig deeper into various aspects (e.g., home page personalization, artwork personalization, search personalization, etc.).
Overview of Netflix Recommendations
Historically, Netflix started as a DVD shipping business and gradually evolved into one of the top OTT streaming platforms. Netflix launched its instant streaming service in 2007, changing how we consume television content and the type of data available for their algorithms.
Data Sources
Whenever someone watches a show or movie, Netflix collects vast amounts of data to optimize recommendations. Here is an overview of the data sources that Netflix uses to optimize its recommendations:
- Netflix has billions of item ratings from members, and they receive millions of ratings every day.
- Millions of streams are played daily, resulting in millions of data about the duration, intensity, and time of day.
- Each item has rich metadata (e.g., genre, actors, director, year, popularity).
- Social data is one of the latest sources for Netflix, which processes what connected friends have watched or rated.
- Millions of queries are searched on Netflix every day.
- External data sources like box office performance, critic ratings and reviews, etc.
- Netflix also keeps track of users who have interacted with recommendations by keeping track of time spent in scrolls and clicks on a given page.
With the vast availability of user data, Netflix has evolved its recommendation systems so that now 75-80% of what people watch is from some recommendation.
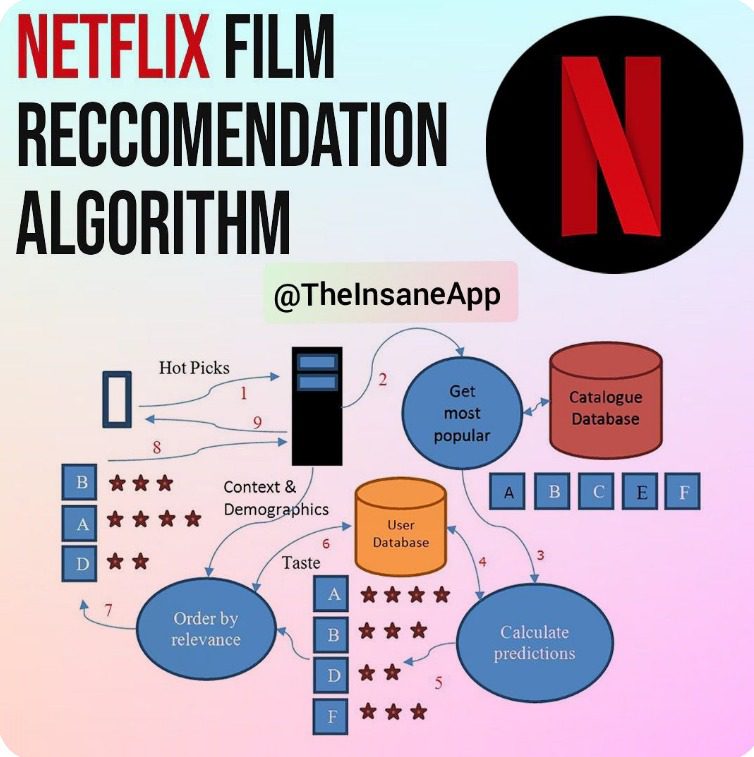
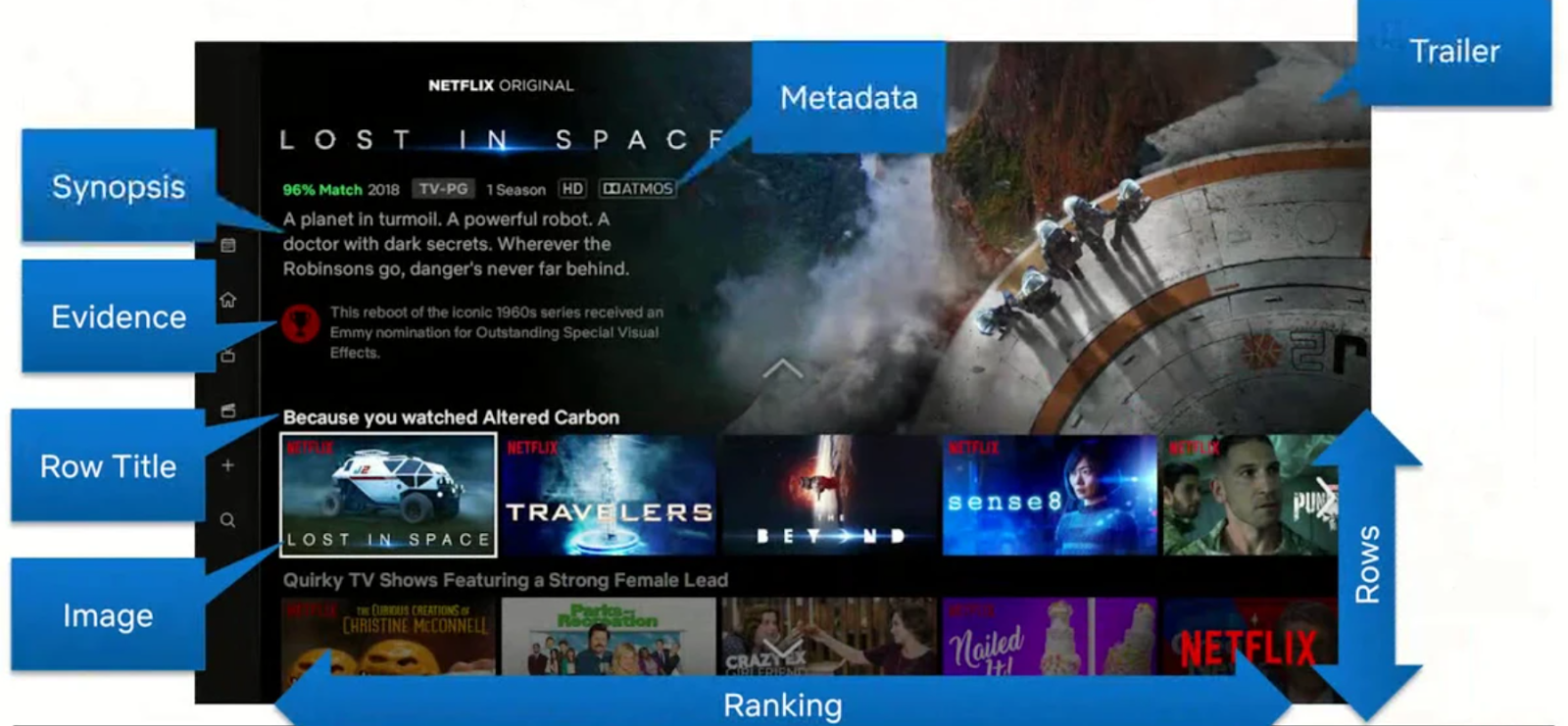
Everything on the Netflix platform is a recommendation. Figure 2 shows the multi-dimensionality of Netflix recommendations. It starts by personalizing the home page, which comprises groups of videos arranged in horizontal rows. Each row has a title (e.g., New releases, Because you watched X, Continue watching, etc.) that conveys the intended meaningful connection between the videos in that group. And it goes on to personalize title images, trailers, metadata, synopsis, etc.
Objectives of Netflix Recommendations
The Netflix recommendation problem is multi-dimensional in that it tries to optimize for several objectives along with accuracy.
Diversity
Individuals have many interests, which can further depend on their mood. Thus, the recommendations should appeal to their range of interests and moods.
Awareness
The recommendations should convey that the system is adapting to their taste. In addition, conveying the reason for a recommendation promotes trust by encouraging members to provide feedback, resulting in better recommendations. To ensure awareness, Netflix provides explanations (as row titles) as to why it recommends a movie or a show.
Freshness
The recommendations should be fresh. The system should recommend new items if a user isn’t interested in a particular recommendation for long.
Ranking
The order in which items are recommended is critical in providing a personalized experience. Netflix recommendation systems provide the best possible ordering in real-time and within a specific context. The ranking algorithm is decomposed into scoring, sorting, and filtering.
Personalized Home Page
The Netflix home page (Figure 3) is one of the main ways a member interacts with recommendations. The primary function of the home page is to help each member find something they will love watching. Since the original catalog contains more videos than what can be displayed on a screen, it is important to tailor the home page according to the user’s interests and moods.
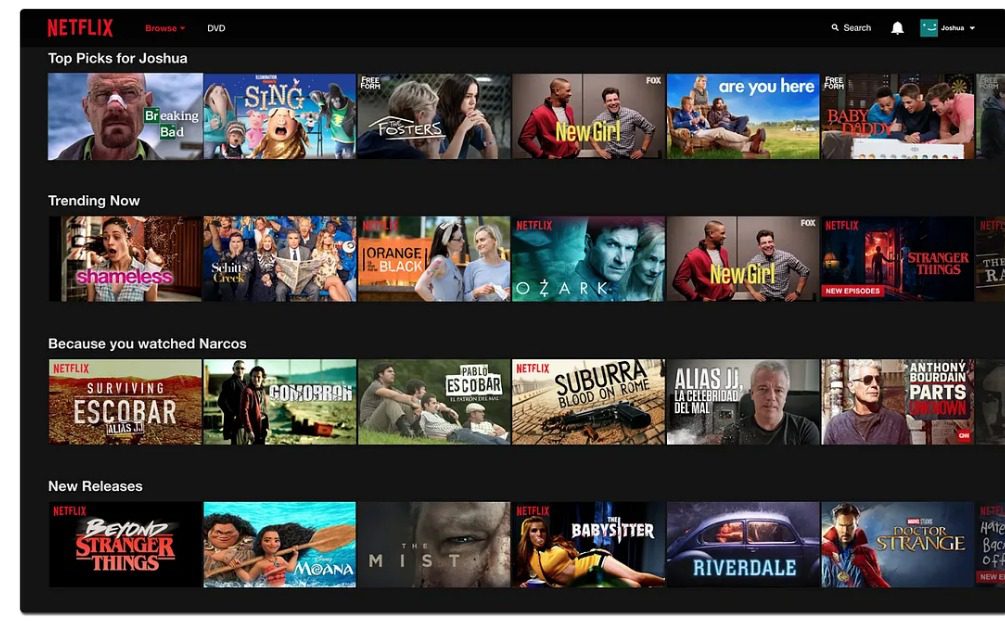
As mentioned earlier, the Netflix home page consists of groups of videos arranged in horizontal rows. Each row has a title (e.g., New releases, Because you watched X, Continue watching, etc.) that conveys the intended meaningful connection between the videos in that group.
Personalizing rows makes the recommendation problem multi-dimensional. It involves figuring out how to select the rows most relevant to each member, populate those rows with videos, and arrange them on the limited page area so that choosing a video to watch is intuitive (Figure 4).

Rule- and Ranking-Based Approaches
For a long time, Netflix used rule-based approaches to populate the member’s home pages. This approach consists of templates that define what types of rows can go in what order on a page. For example, a rule can specify that the first row will be “Continue watching,” then “New Releases,” then “Top 10,” followed by four to five genre-specific rows, and so on.
The only personalization possible in such an approach is to pick relevant videos for each genre row based on the videos already watched or liked by the user (e.g., “Because you watched X”).
Despite being simple and effective, such an approach can lead to suboptimal performance as the rows are not personalized to members’ interests. Furthermore, with time, the template grows and becomes too complex to handle. To mitigate these issues, Netflix proposed using a better approach known as row-ranking.
The row-ranking approach treats each row as an item in the ranking problem. In other words, using existing recommendation approaches (e.g., content-based) to develop a utility function to measure the usefulness of a row for a particular member. All candidates’ rows are then sorted based on their utilities, and the top rows are picked to generate the home page.
However, as discussed in the previous lesson of this series, content-based and scoring-based approaches suffer from overspecialization. The recommendations lack diversity, so a user can get a page full of videos that are just slight variations of each other. To include diversity, Netflix then followed a stage-wise approach where each row is picked in a greedy manner such that it maximizes the utility and, at the same time, is not similar to previously selected rows.
Machine Learning for Page Generation
A good utility function that checks the relevance of a row is the core of building a personalized home page. Machine learning (ML) approaches can be used to learn utility functions by training it on historical data of which home pages have been created for members (i.e., what they see, how they interact, and what they play).
To represent a row, we can use the aggregate feature of videos as the row representation. These features can be simple metadata or model-based features (extracted from a deep learning model), representing how good that video is for a member. Using such row representation, we can look into past interactions to identify whether similar rows have been recommended to the user.
Page-Level Metrics
It is important to have a good metric to evaluate the quality of the generated home page by a specific recommendation algorithm. For page-level metrics, Netflix uses standard ranking metrics (discussed in the previous lesson of the series), such as Recall but in a two-dimensional layout. As we mentioned earlier, for a page to be relevant to a member, both the rows and the videos in those rows should be relevant to the member’s interest.
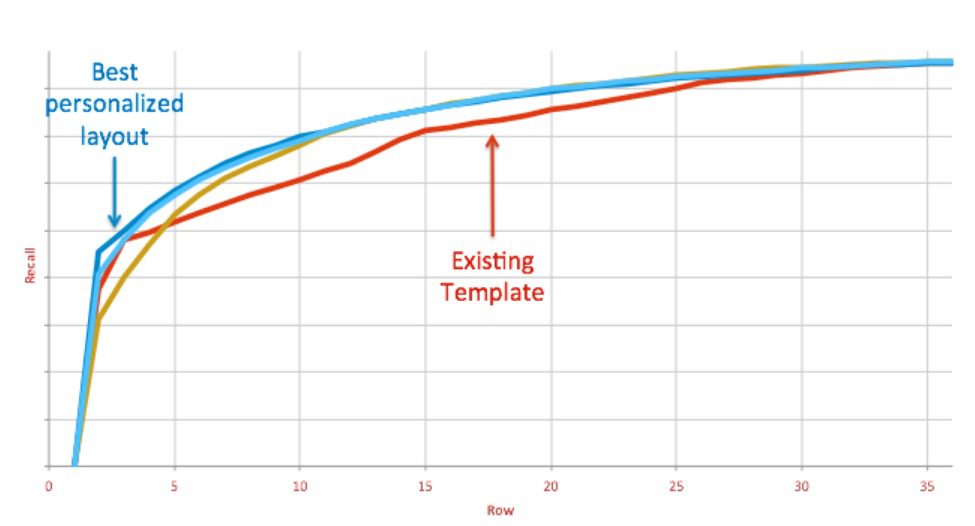
To measure this, Netflix proposes to use a two-dimensional recall known as Recall@M-by-N (Figure 5) that counts the fraction of relevant items in the first M rows and N columns on the page. For example, Recall@4-by-5 will measure the quality of content displayed in the first five videos (columns) of the first four rows. Such a metric can also capture corner cases like duplicate videos or short rows.

As shown in Figure 6, one can also fix the number of N columns and then sweep across M rows to measure how the recall increases as the member scrolls down the page.
Artwork Personalization
Artwork (Figure 7) refers to the imagery Netflix uses to portray movie or show titles. If that artwork captures something compelling (maybe a favorite actor, a car chase scene, or an action scene), it gives a visual idea of why that title is good. An image is worth a thousand words; hence, through its recommendation system, Netflix shows the perfect image for a movie that entices the user to try it.

Let us try personalizing the image we use to depict the movie Good Will Hunting (Figure 8). For example, someone interested in watching romantic movies can get interested in Good Will Hunting if they see the artwork of Matt Damon and Minnie Driver. Likewise, someone who is a fan of comedies can be drawn to the movie if the artwork contains Robin Williams.

Contextual Bandits Approach
A traditional ML approach to personalize the artworks will involve collecting a batch of historical data on how users have previously interacted with various artworks and then training an ML model to estimate the utility of an artwork for a member.
Next, it involves A/B testing this new model with the current production model to see if the new algorithm performs better than the current one in real life.
A/B testing, also known as split testing, is a method used to compare two or more versions of a product, feature, or algorithm. A/B testing involves randomly dividing the user base into Control and Treatment groups.
The Control group is exposed to the current production model or feature, while the Treatment group is exposed to the new algorithm or feature being tested. The two groups are randomly assigned to ensure unbiased results.
The system then analyzes user interactions and behaviors (e.g., click-through rates, engagement metrics, conversion rates, or other relevant key performance indicators (KPIs)).
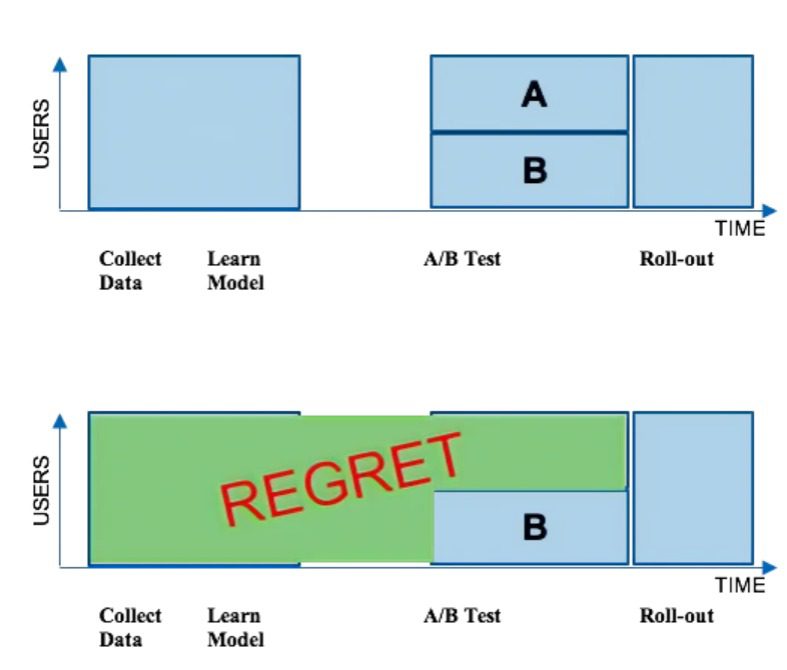
By comparing the performance metrics between the Control and Treatment groups, one can conclude whether the new algorithm or feature improves interaction. If yes, the new algorithm or feature is available to the whole population. On the other hand, if the results are inconclusive, then the new feature is retained from moving into production.
Even though these batch-based ML algorithms are widely used, they still suffer from regret as many members over a long period did not benefit from the better experience (Figure 9). Thus, it is important to use algorithms that can work online and update themselves with changing user behavior and interests.
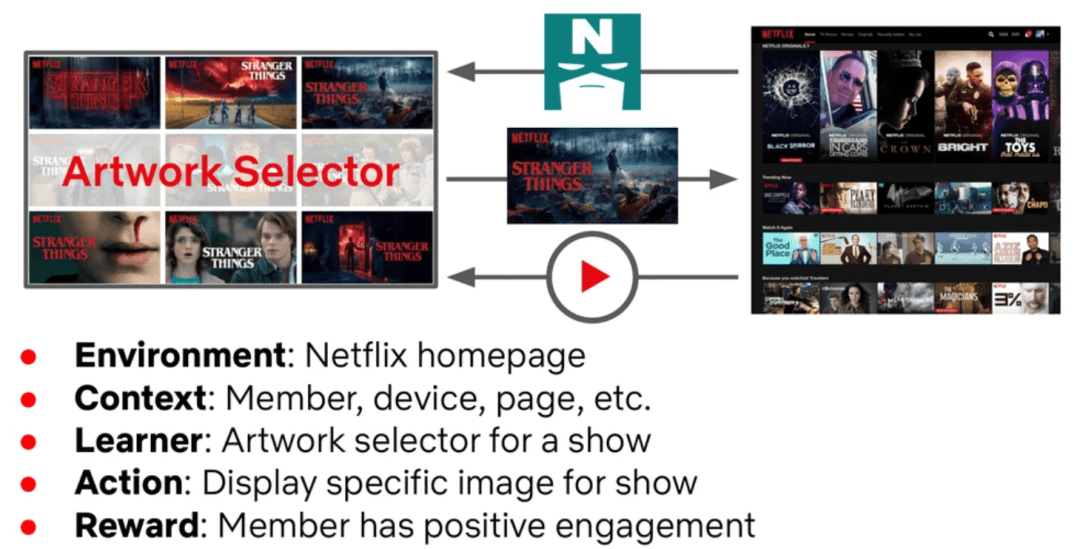
Contextual bandits (Figure 10) solve this regret problem by rapidly figuring out the optimal personalized artwork for each member and a given context.

These algorithms are a class of online algorithms that use a context (e.g., member profile, interests, and mood), choose an action (e.g., personalized artwork), and observe a cost or reward for the selected action only (whether the member interacted with the personalized artwork). Based on the cost or reward, contextual bandits align themselves with changing user behavior (Figure 11).
One key property of contextual bandits is that they don’t suffer from overspecialization. Using data exploration techniques (e.g., epsilon greedy approach), we can add randomness in the recommendations (i.e., instead of suggesting personalized artwork, suggest a random one) to explore more about the user behavior.
Usually, this is controlled so that the regret incurred by exploration is typically very small, and the cost of exploration per member is negligible.
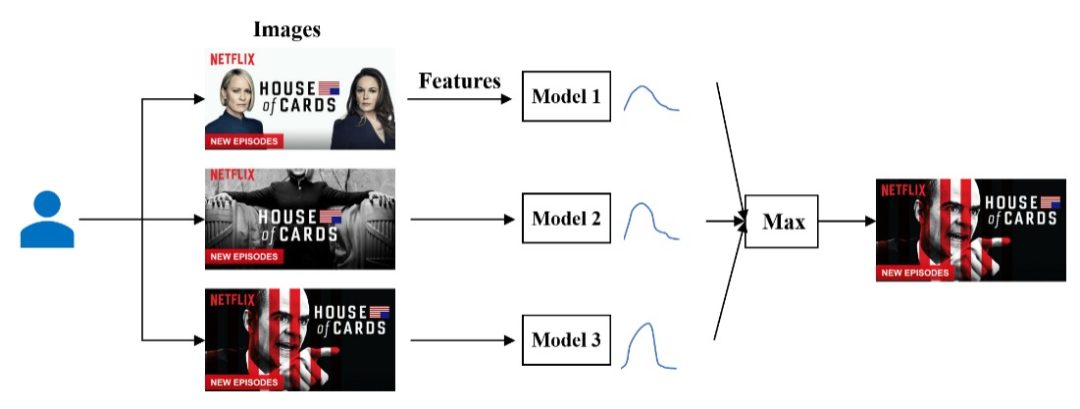
For a given title, Netflix stores a few dozen candidate artwork images. Furthermore, it records how different members have interacted with these candidate artworks (e.g., if a member presented with an artwork did not engage, while other members presented with the same artwork did).
This data is then fed to contextual bandits to model the probability or utility that a member will enjoy a given artwork. Then, based on the predicted probabilities of each candidate artwork, we can pick the one with the highest probability (Figure 12).
Performance Evaluation
To evaluate the contextual bandits offline, Netflix uses an offline technique called “replay.” This replay allows us to measure how users would have engaged with the titles if they were hypothetically presented with the images selected by the new algorithm.
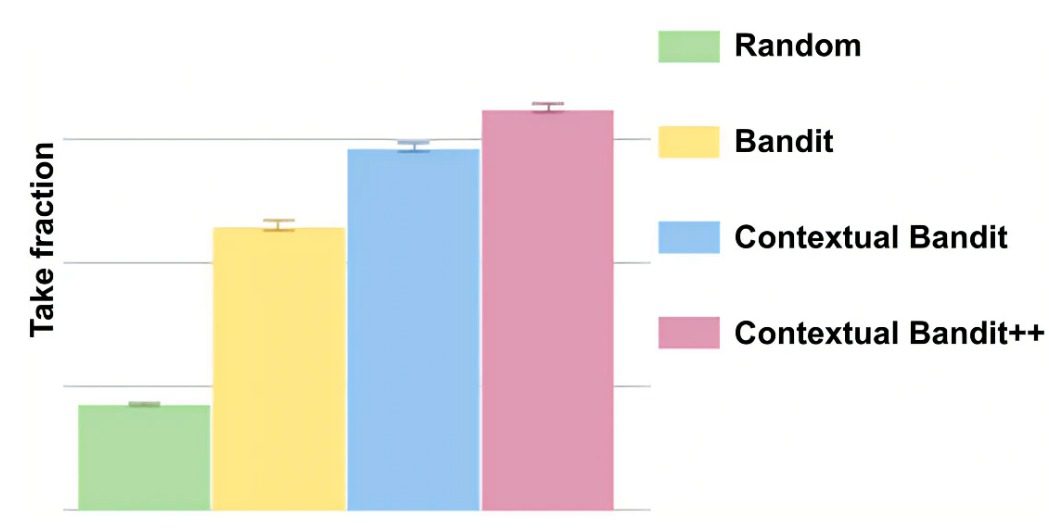
One way to quantify replay is through take fraction. As shown in Figure 13, take fraction measures the fraction of members that played the title in profiles where the production model and the new model assignment are the same.
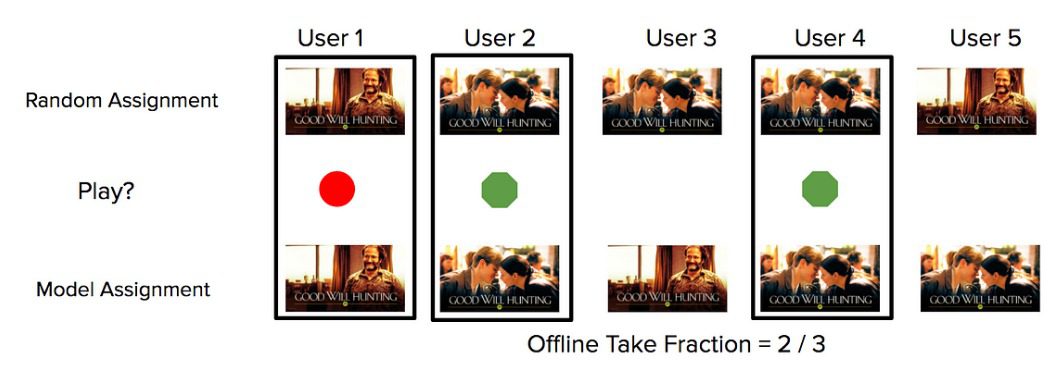
Figure 14 compares the performance of contextual bandits to a random assignment algorithm using the take fraction metric.
Search Personalization
Netflix provides two search use cases: fetch and explore.
In the fetch use case, the user has a clear intent of what specific title they need to watch.
Personalization can help them get results faster if the title they are searching for is available and has a high affinity with their taste profile. When the title is unavailable, the search should recommend titles that match the user profile but are also related to the user query.
The explore option consists of broad queries (e.g., genre, actor, director, etc.), where the search should recommend items relevant to the user’s taste and having the same actor, genre, director, etc. Therefore, the search needs to have a balance of both relevance and personalization.
The search results need to be more relevant (than personalized) for fetch use cases as the user has a specific intent. On the other hand, the search results can be more personalized for exploring use cases since the intent is very broad.
Ranking- and Modeling-Based Approaches
The Netflix search ranking model is a deep learning feed-forward network (Figure 15) that takes the following three classes of features as inputs.
- Context features refer to the user and his query (e.g., user profile, location, query, language, etc.). Users are grouped into small clusters based on their viewing history to obtain context-only features. The cluster assignments, along with the query, are then used as personalized context features.
- Title features describe the target title to rank (e.g., genre, cast, director, popularity, reviews, etc.).
- Context-title features include attributes describing the match between some contextual information and the target title (e.g., query-title lexical similarity or user-item affinity). To obtain these features, Netflix uses a separate model to compute personalized user-item (query-item) affinity scores, which can be interpreted as the probability the user would engage with the item or an item that matches a query.
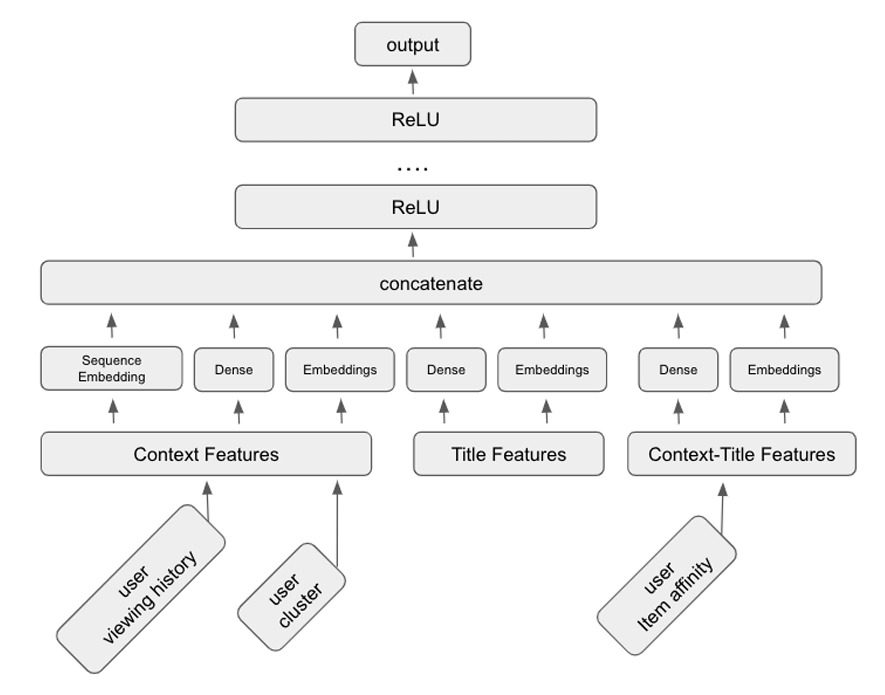
As shown in Figure 15, all these features are fed to a deep learning model, which outputs a utility score representing a title’s usefulness for a user and a query.
Recent Trends in Personalization at Netflix
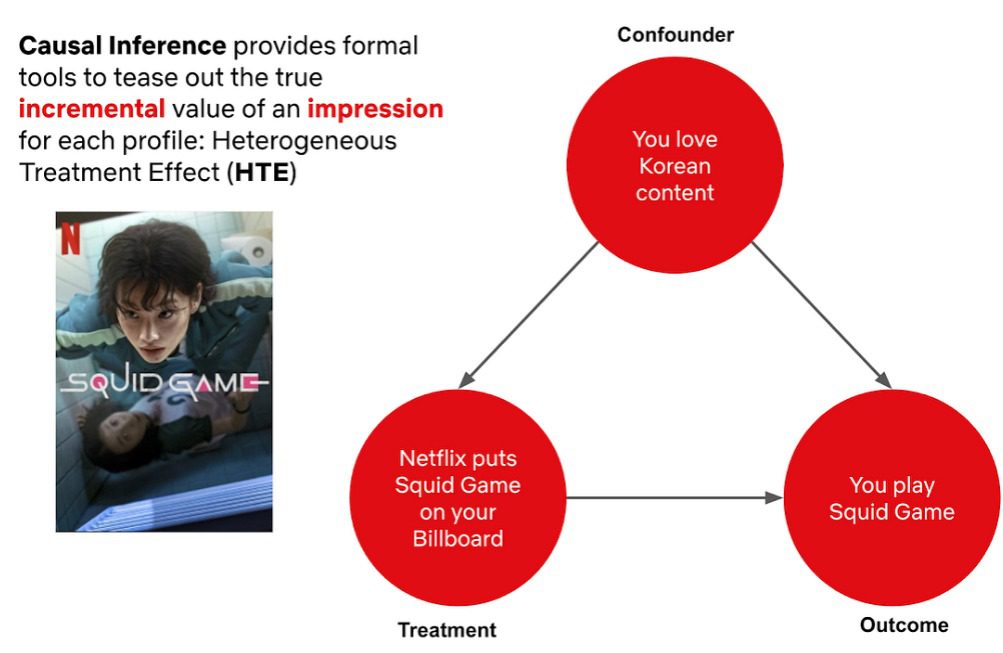
Besides using advanced ML algorithms like contextual bandits to provide personalization, Netflix has been exploring the field of causal inference to improve the quality of their recommendations.
Causality is the phenomenon when one thing causes another thing to happen. Causal inference is the process where we determine if one thing did cause another thing to happen by looking at all the evidence available. For example, causal inference can help Netflix understand whether a user watched a title because it was recommended or simply because he wanted to (Figure 16).
Correlation and Causation are two distinct concepts. Correlation is when two things happen together. Causation refers to the phenomenon where one event causes another event to happen.
For example, ice cream demand and crime rates might seem correlated because they rise and fall together. However, ice cream sales do not cause crime rates to rise or fall. Instead, both of these might be influenced by a third variable: temperature.
Machine learning algorithms used in recommendations learn from the correlations between features and targets. Hence, they don’t understand the causal relationship between the feature and the target.
However, using causal inference techniques on top of ML recommendations can refine them by identifying the exact titles users want to watch instead of just identifying which titles they are likely to engage with.
To this end, Netflix created a framework that applies a light, causal adaptive layer on top of the base recommendation system called the Causal Ranker Framework. This framework consists of several components: an impression (treatment) to play (outcome) attribution, true negative label collection, causal estimation, offline evaluation, and model serving.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This blog post covered various kinds of Netflix recommendations and how they work behind the scenes.
The Netflix home page is one of the main ways a member interacts with recommendations. Netflix started with a rule-based approach where a set of rules decides the home page’s template, and the only personalization happens when populating a template with relevant videos. Later, Netflix shifted to row-ranking-based approaches that consider each row an item in a ranking problem.
The next use case is artwork personalization, where Netflix shows you the perfect image for a movie that entices you to try it. Netflix uses contextual bandits to rapidly figure out the optimal personalized artwork for each member and a given context in online fashion. Furthermore, based on cost or reward, contextual bandits align themselves with changing user behavior.
Search personalization is another area where Netflix uses recommendation systems. The Netflix search-ranking model is a deep learning feed-forward network that takes three classes of features as inputs (i.e., context features, title features, and context-title features). Context features include user profile, location, query, language, etc. Title features describe the target title to rank; these include genre, cast, director, popularity, reviews, etc.
Besides contextual bandits, Netflix has been working to integrate advanced algorithms like causal inference to improve their recommendations. For example, using causal inference techniques on top of ML recommendations can refine them by identifying the exact titles users want to watch instead of just identifying with which titles they are likely to engage.
Stay tuned for an upcoming lesson on Linkedin Jobs recommendation systems!
Citation Information
Mangla, P. “Netflix Movies and Series Recommendation Systems,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/sqd7x
@incollection{Mangla_2023_Netflix,
author = {Puneet Mangla},
title = {Netflix Movies and Series Recommendation Systems},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/sqd7x},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.