Table of Contents
- Train a MaskFormer Segmentation Model with Hugging Face 🤗 Transformers
- Summary
Train a MaskFormer Segmentation Model with Hugging Face 🤗 Transformers
In this tutorial, we will learn how to train MaskFormer on a Colab Notebook to perform panoptic segmentation.

We will use the 🤗Transformers and Datasets libraries to load and train a model on the Scene Parsing dataset and the Hub library to publish our model. To measure the performance of our trained model, we will use the 🤗Evaluate library.
You will learn how to:
- Load and preprocess the dataset
- Use the transformers Trainer class to train models
- Evaluate your trained segmentation model
Project Structure
For this tutorial, we will use a Colab Notebook. Feel free to jump over to the notebook or create a new notebook and code along!
Requirements
Before starting, please create an account on the Hugging Face Hub. This will allow us to push our trained models and preprocessing pipeline to the Hub for public or private use.
Bonus
Hugging Face has multiple Python libraries under its umbrella: datasets, transformers, evaluate, and accelerate, just to name a few! To familiarize yourself with these libraries, feel free to jump into their documentation.
An Introduction to Image Segmentation
Image segmentation is a massively popular computer vision task that deals with the pixel-level classification of images. Unlike the object detection task, where the goal is to predict object classes and corresponding bounding boxes, the image segmentation task aims to learn how to segment similar groups of pixels and predict the object classes of these groups.
As we might have guessed, segmentation provides higher granularity information about images compared to object detection and has a wide variety of use cases (e.g., self-driving, quality assurance, medical imaging, fashion, satellite imaging, etc.).
The three subtasks of image segmentation are:
- Semantic segmentation
- Instance segmentation
- Panoptic segmentation
While semantic and instance segmentation are often used interchangeably, these tasks require different model architectures. Let’s see how these subtasks differ from each other with the example shown in Figure 1.
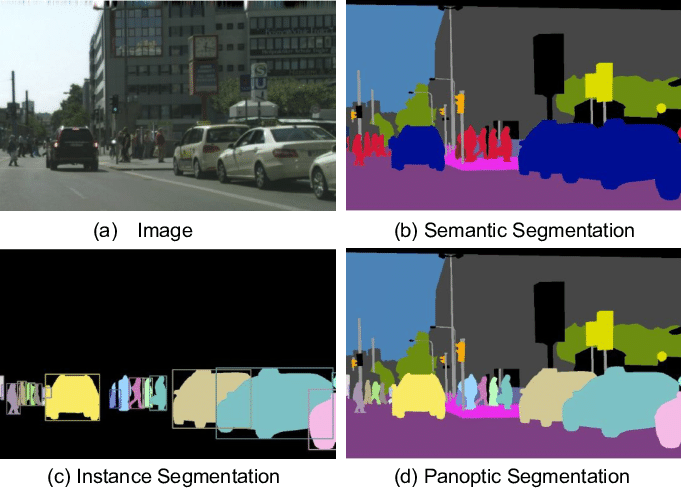
The image includes sky, road, multiple persons, cars, trees, and traffic light instances.
Semantic segmentation: The model tries to map each pixel to a class label (e.g., sky: 0, road: 1, person: 2, car: 3, tree: 4, traffic_light: 5). The pixels of all cars in the image are labeled as 3.
Instance segmentation: The model tries to map each pixel to a class label and differentiate between the instances of the same object class. Pixels of car 1 and car 2 have the same class id but not the same instance id. There can also be two sky instances due to a person standing in the foreground and splitting the sky pixels into two segments. However, background pixels such as sky and road are often disregarded as object categories in instance segmentation tasks.
Panoptic segmentation: The model provides the best semantic and instance segmentation. It allows assigning a single instance id to non-overlapping segments (e.g., the split sky segments). Background classes such as sky and road are always included in the class labels.
The panoptic segmentation models can be considered simple extensions of instance segmentation models. However, note that the panoptic segmentation task is very useful as it provides a more relevant context in many use cases (e.g., self-driving cars).
In short, semantic segmentation is our vanilla task, instance segmentation combines semantic segmentation with object detection, and panoptic segmentation combines semantic and instance segmentation and can handle multiple instances of the same object class when there shouldn’t be (e.g., there is only one sky!).
To learn more about the different segmentation subtasks, check out a previous blog post.
What Is MaskFormer?
MaskFormer is a state-of-the-art image segmentation model by Facebook Research that proposes a unified framework for semantic, instance, and panoptic segmentation tasks. See Figure 2 for an overview of the MaskFormer architecture.

The official MaskFormer includes checkpoints for models trained on ADE20K, Cityscapes, COCO, and Mapillary Vistas across all tasks and multiple model sizes.
In this tutorial, we will use the Hugging Face implementation of MaskFormer, which allows us to load, train, and evaluate the model on a custom dataset with a few lines of code. In addition, we will use an instance segmentation dataset to fine-tune a MaskFormer model trained on another dataset.
Do not worry if it is your first time with Hugging Face. We have got your back! This tutorial is the right mix to learn about the ecosystem inside out.
🤗Transformers Ecosystem
The 🤗 transformers library enables users to easily use, experiment with, and fine-tune pre-trained state-of-the-art models. The library also designs custom architectures for new research. Other Hugging Face libraries (e.g., Datasets and Evaluate) are designed to make it easier to load datasets and evaluate model performance. In addition, they can be smoothly integrated with transformers pipelines.
Before training a model using 🤗 transformers, we need to:
- Load a dataset with the 🤗 Datasets library or write a custom dataloader to load our own data.
- Create a custom
XXXModelConfigobject to define the model architecture, hyperparameters and labels (where applicable). - Initialize a
XXXModelmodel with the customXXXModelConfigconfig object. - Preprocess the dataset using the same configuration (e.g., expected image size).
To train a MaskFormer model, all we need to do is replace XXX in the above steps with MaskFormer.
How to Train an Instance Segmentation Model with MaskFormer?
This tutorial focuses on fine-tuning an image segmentation model (MaskFormer) on a custom dataset. This is meant to provide an understanding of how fine-tuning works and an overview of the Hugging Face ecosystem. We structure the tutorial in the following manner:
- Setup
- Loading the Dataset
- Preprocessing the Dataset
- Fine-tuning the MaskFormer Model
- Inference and Performance Evaluation
Setup
Let’s start by installing the dependencies.
In this tutorial, we use the following:
- The 🤗 Datasets library to load the MIT Scene Parsing Benchmark dataset.
- The 🤗 Transformers library to preprocess the data and fine-tune a MaskFormer model.
- The 🤗 Evaluate library to benchmark the trained model’s performance.
- The Hub client library to push our trained model to the 🤗 Hub.
- The Albumentations library, in conjunction with the transformers preprocessor class, to augment our data for training.
# Install the necessary dependencies !pip install datasets -qq !pip install evaluate -qq !pip install albumentations -qq !pip install git+https://github.com/huggingface/transformers.git -qq # We will use this to push our trained model to HF Hub !pip install huggingface_hub -qq
We can now import MaskFormer and other dependencies:
# Import the necessary packages
import random
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import albumentations as A
import numpy as np
import pandas as pd
from datasets import load_dataset
from transformers import (
MaskFormerConfig,
MaskFormerImageProcessor,
MaskFormerModel,
MaskFormerForInstanceSegmentation,
)
import evaluate
from huggingface_hub import notebook_login
Loading the Dataset
About the Dataset
This tutorial will use the Scene Parsing dataset to train an instance segmentation model. This dataset is an extension of the ADE20K dataset, consisting of over 20K images and their segmentation annotations. It is named after Adela Barriuso, who single-handedly annotated the dataset. ADE20K is among the most popular and widely used semantic segmentation datasets. The Scene Parsing dataset has 150 semantic labels for the semantic segmentation task and 100 for the instance segmentation task.
Loading a Dataset with 🤗 Datasets
We can use the 🤗 Datasets library to load this dataset with a single line of code and create train, validation, and test generators.
Note: Downloading the dataset takes 1.2 GB of disk space. If you don’t want to download the whole dataset, you can simply pass in the streaming=True argument to create an iterable dataset where samples are downloaded as you iterate over them.
Now, let’s download the dataset from the 🤗 Hub with the load_dataset() function. Calling this function will download the dataset and return an iterable DatasetDict object. Note that we can also pass in an optional split argument to download train, validation, and test sets separately.
>>> DatasetDict({
>>> train: Dataset({
>>> features: ['image', 'annotation'],
>>> num_rows: 20210
>>> })
>>> test: Dataset({
>>> features: ['image', 'annotation'],
>>> num_rows: 3352
>>> })
>>> validation: Dataset({
>>> features: ['image', 'annotation'],
>>> num_rows: 2000
>>> })
>>> })
Now let’s load the Scene Parsing dataset’s instance segmentation subset:
train = load_dataset("scene_parse_150", "instance_segmentation", split="train")
validation = load_dataset("scene_parse_150", "instance_segmentation", split="validation")
test = load_dataset("scene_parse_150", "instance_segmentation", split="test")
Each instance in the train, validation, and test set dictionaries of Scene Parsing to have two keys: image and annotation.
Note: Different datasets on the hub have different keys based on their target task, and we can refer to the dataset page to see what they contain (see the Scene Parsing dataset page).
print(train[0])
>>> {'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=256x256 at 0x7F48DF5D6310>,
'annotation': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=256x256 at 0x7F48DF5D6250>}
Dataset Visualization
Let’s print out an image randomly selected from our train set.
# Grab a random index of the training dataset
print("[INFO] Displaying a random image and its annotation...")
index = random.randint(0, len(train))
# Using the random index grab the corresponding datapoint
# from the training dataset
image = train[index]["image"]
image = np.array(image.convert("RGB"))
annotation = train[index]["annotation"]
annotation = np.array(annotation)
# Plot the original image and the annotations
plt.figure(figsize=(15, 5))
for plot_index in range(3):
if plot_index == 0:
# If plot index is 0 display the original image
plot_image = image
title = "Original"
else:
# Else plot the annotation maps
plot_image = annotation[..., plot_index - 1]
title = ["Class Map (R)", "Instance Map (G)"][plot_index - 1]
# Plot the image
plt.subplot(1, 3, plot_index + 1)
plt.imshow(plot_image)
plt.title(title)
plt.axis("off")
Instance Segmentation Annotations
In this section, we will look at instance segmentation annotations. As described in the Scene Parsing dataset page, the instance annotation masks are stored in RGB image format and structured as follows:
- The R(ed) channel encodes category ID.
- The G(reen) channel encodes instance ID.
- Instance IDs are assigned per image such that each object in an annotation image has a different instance ID (regardless of its class ID). In contrast, different annotation images can have objects with the same instance ID. Each image in the dataset has
< 256object instances.
We can refer to this file (train split) for the 100 class labels included in the instance segmentation subset of Scene Parsing.
Important Notes
Semantic and instance segmentation subsets of Scene Parsing don’t have the same id2label mapping. To find the mapping between the semantic categories for instance_segmentation and semantic_segmentation and the ADE20K dataset, we need to refer to Mapping.txt.
Preprocessing the Dataset
For any 🤗 Transformers vision model, we can simply use the corresponding FeatureExtractor or ImageProcessor class to preprocess raw images (and segmentation maps) and convert them to the format expected by the model.
As Scene Parsing is a large image dataset, we will call the preprocessor as we iterate over the training and validation loops instead of preprocessing all data at once.
FeatureExtractor and ImageProcessor Classes
Each model on the 🤗 Hub has a corresponding FeatureExtractor or ImageProcessor or Processor (for multi-modal models) class that is used to preprocess the raw image (or text, speech, etc.) such that it has the expected input shape and format used by the model. Some classes also include convenient post-processing methods to convert raw model outputs to final predictions.
Same as the Model and Config class, we can use the from_pretrained() method to retrieve the processor of any pre-trained model.
from transformers import XXXModelImageProcessor
# Use default configuration
preprocessor = XXXModelImageProcessor.from_pretrained(<MODEL_NAME>)
train = load_dataset(<DATASET>)["train"]
for data in train:
model = XXXModelImageProcessor(data[<target_key>])
Defining a Preprocessor Configuration
An important point to note here is that the preprocessor configuration needs to be consistent with the model configuration chosen for the input data to be preprocessed correctly (e.g., expected image size, normalization, augmentation, …).
As there are no model checkpoints available on the hub that were trained on the Scene Parsing dataset, we will create our custom preprocessor configuration.
# Create the MaskFormer Image Preprocessor
processor = MaskFormerImageProcessor(
reduce_labels=True,
size=(512, 512),
ignore_index=255,
do_resize=False,
do_rescale=False,
do_normalize=False,
)
>>> preprocessor
>>> >>>
>>> MaskFormerImageProcessor {
>>> "_max_size": 1333,
>>> "do_normalize": false,
>>> "do_reduce_labels": true,
>>> "do_rescale": false,
>>> "do_resize": false,
>>> "ignore_index": 255,
>>> "image_mean": [
>>> 0.485,
>>> 0.456,
>>> 0.406
>>> ],
>>> "image_processor_type": "MaskFormerImageProcessor",
>>> "image_std": [
>>> 0.229,
>>> 0.224,
>>> 0.225
>>> ],
>>> "resample": 2,
>>> "rescale_factor": 0.00392156862745098,
>>> "size": {
>>> "height": 512,
>>> "width": 512
>>> },
>>> "size_divisor": 32
>>> }
The preprocessor configuration is compact with mostly easy-to-understand fields. As specified in the MaskFormerImageProcessor docs, the reduce_label argument handles class labels that start from 1.
When set to True, the reduce_label argument replaces the background / null class pixels (denoted with 0) with the ignore_index specified and decrements all other labels by 1. This comes in handy as Python indexing starts from 0, and we will need the labels to start from 0 to calculate the loss terms correctly.
Note: Instance segmentation dataset labels start from 1 while 0 is reserved for the null / background class to be ignored.
How to Use MaskFormerImageProcessor
Remember, MaskFormer is a unified framework supporting multiple segmentation tasks: semantic, instance, and panoptic segmentation. Hence, its preprocessor is designed to handle both semantic and instance segmentation annotations.
Let’s jump into MaskFormerImageProcessorʼs documentation once again. After initializing our image processor, we need to pass in the following arguments to process our data:
imagessegmentation_maps(optional)instance_id_to_semantic_id(optional)
Let’s break it down. images are the images we’d like to segment. segmentation_maps can either be pixel-wise class annotations (default) or pixel-wise instance id annotations. If we pass in instance-level annotations, we also need to pass in an instance_id_to_semantic_id dictionary (List[Dict[int, int]] or Dict[int, int]) that maps instance ids to class ids. During inference, we only need to pass in images as input.
Remember that our dataset’s annotation field stores annotations as images, where the Red channel and Green channel values correspond to pixel-wise class and instance labels, respectively. Since we would like to train instance segmentation models, we need to pass in pixel-wise instance segmentation maps as the segmentation_maps argument and create either a global instance_id_to_semantic_id dictionary or a list of dictionary for per-image instance id to class id mapping. Hence, we will need to do additional light preprocessing before feeding the data into our preprocessor.
Fine-Tuning the MaskFormer Model
We are now ready to fine-tune the MaskFormer model on the Scene Parsing dataset for the instance segmentation task.
Defining a Configuration
Each pre-trained model on 🤗 Hub has its own repository and a config.json file (see an example over here. The configuration file defines the model architecture (e.g., number of layers, hidden dimension), hyperparameters (e.g., dropout ratio) and other relevant metadata (e.g., labels in the dataset).
We can load the specific configuration of any available pre-trained model simply using the from_pretrained() method.
from transformers import MaskFormerConfig
config = MaskFormerConfig.from_pretrained("facebook/maskformer-swin-base-coco")
config
We can also initialize a XXXModelConfig object, which defaults to values specified in the configuration_XXXModel.py (like MaskFormerʼs configuration script) file of the respective model.
To create a custom XXXModelConfig object, we can either create a custom config.json file and pass it to the from_pretrained() method or initialize XXXModelConfig with default values and edit it as we would edit a *dictionary*.
from transformers import MaskFormerConfig # Option 1 - Use custom configuration file config = MaskFormerConfig.from_pretrained(<PATH TO YOUR LOCAL CUSTOM CONFIG JSON>) # Option 2 - Edit default configuration config = MaskFormerConfig() config.embed_dim = 256 # Editing the configuration
We need to start by defining a model configuration in order to initialize a MaskFormerForInstanceSegmentation model, as discussed above.
For this tutorial, we will use the configuration of the pre-trained facebook/maskformer-swin-base-ade model with a few modifications and fine-tune MaskFormer on the Scene Parsing instance segmentation subset. Note that this model is trained on the ADE20K semantic segmentation dataset and can only perform the semantic segmentation task.
If we wanted to train MaskFormer from scratch, we could also define a custom configuration by initializing a MaskFormerConfig object and changing the default values or loading a custom config.json file.
# Define the name of the model
model_name = "facebook/maskformer-swin-base-ade"
# Get the MaskFormer config and print it
config = MaskFormerConfig.from_pretrained(model_name)
print("[INFO] displaying the MaskFormer configuration...")
print(config)
The config.json file shows that the label2id and id2label fields are specific to the ADE20K dataset. Therefore we’ll need to customize it.
To do this, we will download the Scene Parsing instance segmentation labels and reduce the labels such that the labels start from 0 instead of 1.
# Download SceneParsing instance segmentation labels
!wget https://raw.githubusercontent.com/CSAILVision/placeschallenge/master/instancesegmentation/instanceInfo100_train.txt
# Get a modified version of the id2label and label2id
data = pd.read_csv(
"/content/instanceInfo100_train.txt",
sep="\t",
header=0,
on_bad_lines="skip",
)
id2label = {id: label.strip() for id, label in enumerate(data["Object Names"])}
label2id = {v: k for k, v in id2label.items()}
# Edit MaskFormer config labels
config.id2label = id2label
config.label2id = label2id
Notes on Fine-Tuning HF Models
To fine-tune pre-trained models on custom datasets with different labels, we will need to make a few modifications. The classification or final prediction heads of each model are specific to the dataset it was trained on. However, we can still use the learned parameters of the base model to accelerate our training progress. This ensures that we start the training from a close-to-ideal point in terms of model parameters.
In practice, we will simply:
- Initialize a
MaskFormerForInstanceSegmentationmodel with random weights - Load a pre-trained
MaskFormerModelwith a compatible configuration - Replace the random base model (
MaskFormerModel) weights of ourMaskFormerForInstanceSegmentationmodel with that of the pre-trainedMaskFormerModelmodel
We already know that the XXXModelConfig object defines the model architecture, hyperparameters, and the relevant metadata to create and initialize a model. This is why the first and foremost step would be to create a XXXModelConfig object.
Note: We use XXXModelConfig to make the code more generic. If you want to use your favorite model, just replace XXX with the model’s name. 🤗 Hub has a list of models from which you can choose. Head on to the 🤗 Hub to know more.
from transformers import XXXModelConfig, XXXModel # Use default configuration config = XXXModelConfig() # Initialize model with config model = XXXModel(config)
Initializing a MaskFormer Model
Now we can define our custom configuration and initialize MaskFormer for training!
# Use the config object to initialize a MaskFormer model with randomized weights model = MaskFormerForInstanceSegmentation(config) # Replace the randomly initialized model with the pre-trained model weights base_model = MaskFormerModel.from_pretrained(model_name) model.model = base_model
MaskFormer Model Inputs
The MaskFormerForInstanceSegmentation model expects the following inputs during training:
pixel_values: Tensor of shape(batch_size, num_channels, height, width). Preprocessed image to be passed into the model as input.pixel_mask(optional): Mask to avoid performing attention on padding pixel values.mask_labels(optional): List of mask label tensors of shape(num_labels, height, width)to be fed to a model.class_labels(optional): List of target class label tensors of shape(num_labels, height, width)to be fed to the model. They identify the labels ofmask_labels, e.g., the label ofmask_labels[i][j]ifclass_labels[i][j].
Note: While segmentation datasets more or less have the same structure and data fields, different models such as MaskFormer and Segformer have different approaches to frame the segmentation problem. For example, MaskFormer creates binary instance segmentation maps (mask_labels) for each object instance across the training set, which requires additional preprocessing. Luckily, our preprocessor (an instance of the MaskFormerImageProcessor class) takes care of all these custom preprocessing steps.
However, the ImageProcessor classes don’t support data augmentation (e.g., image flipping, random crops, hue changes, etc.). To illustrate how you can combine custom data augmentation steps with the existing image processor classes of transformers, we will create a DataLoader class that uses both the MaskFormerImageProcessor and the Albumentations library. So, let’s go ahead and define our data loader class.
# Define the configurations of the transforms specific
# to the dataset used
ADE_MEAN = np.array([123.675, 116.280, 103.530]) / 255
ADE_STD = np.array([58.395, 57.120, 57.375]) / 255
# Build the augmentation transforms
train_val_transform = A.Compose([
A.Resize(width=512, height=512),
A.HorizontalFlip(p=0.3),
A.Normalize(mean=ADE_MEAN, std=ADE_STD),
])
class ImageSegmentationDataset(Dataset):
def __init__(self, dataset, processor, transform=None):
# Initialize the dataset, processor, and transform variables
self.dataset = dataset
self.processor = processor
self.transform = transform
def __len__(self):
# Return the number of datapoints
return len(self.dataset)
def __getitem__(self, idx):
# Convert the PIL Image to a NumPy array
image = np.array(self.dataset[idx]["image"].convert("RGB"))
# Get the pixel wise instance id and category id maps
# of shape (height, width)
instance_seg = np.array(self.dataset[idx]["annotation"])[..., 1]
class_id_map = np.array(self.dataset[idx]["annotation"])[..., 0]
class_labels = np.unique(class_id_map)
# Build the instance to class dictionary
inst2class = {}
for label in class_labels:
instance_ids = np.unique(instance_seg[class_id_map == label])
inst2class.update({i: label for i in instance_ids})
# Apply transforms
if self.transform is not None:
transformed = self.transform(image=image, mask=instance_seg)
(image, instance_seg) = (transformed["image"], transformed["mask"])
# Convert from channels last to channels first
image = image.transpose(2,0,1)
if class_labels.shape[0] == 1 and class_labels[0] == 0:
# If the image has no objects then it is skipped
inputs = self.processor([image], return_tensors="pt")
inputs = {k:v.squeeze() for k,v in inputs.items()}
inputs["class_labels"] = torch.tensor([0])
inputs["mask_labels"] = torch.zeros(
(0, inputs["pixel_values"].shape[-2], inputs["pixel_values"].shape[-1])
)
else:
# Else use process the image with the segmentation maps
inputs = self.processor(
[image],
[instance_seg],
instance_id_to_semantic_id=inst2class,
return_tensors="pt"
)
inputs = {
k:v.squeeze() if isinstance(v, torch.Tensor) else v[0] for k,v in inputs.items()
}
# Return the inputs
return inputs
# Build the train and validation instance segmentation dataset
train_dataset = ImageSegmentationDataset(
train,
processor=processor,
transform=train_val_transform
)
val_dataset = ImageSegmentationDataset(
validation,
processor=processor,
transform=train_val_transform
)
Before moving on, let’s check if the preprocessed data is in the expected format:
# Check if everything is preprocessed correctly inputs = val_dataset[0] for k,v in inputs.items(): print(k, v.shape)
Everything seems to be in the correct order! We can now create a collate function to load the data in batches and move on to model training.
def collate_fn(examples):
# Get the pixel values, pixel mask, mask labels, and class labels
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_mask = torch.stack([example["pixel_mask"] for example in examples])
mask_labels = [example["mask_labels"] for example in examples]
class_labels = [example["class_labels"] for example in examples]
# Return a dictionary of all the collated features
return {
"pixel_values": pixel_values,
"pixel_mask": pixel_mask,
"mask_labels": mask_labels,
"class_labels": class_labels
}
# Building the training and validation dataloader
train_dataloader = DataLoader(
train_dataset,
batch_size=4,
shuffle=True,
collate_fn=collate_fn
)
val_dataloader = DataLoader(
val_dataset,
batch_size=4,
shuffle=False,
collate_fn=collate_fn
)
Training Step
We will now fine-tune our model for 2 epochs for demonstration purposes. If we need the fine-tuned model, we will download it later for inference and evaluation, which is trained for 25 epochs. Ideally, we would fine-tune our model for >100 epochs for optimal performance.
# Use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Initialize Adam optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
# Set number of epochs and batch size
num_epochs = 2
for epoch in range(num_epochs):
print(f"Epoch {epoch} | Training")
# Set model in training mode
model.train()
train_loss, val_loss = [], []
# Training loop
for idx, batch in enumerate(tqdm(train_dataloader)):
# Reset the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(
pixel_values=batch["pixel_values"].to(device),
mask_labels=[labels.to(device) for labels in batch["mask_labels"]],
class_labels=[labels.to(device) for labels in batch["class_labels"]],
)
# Backward propagation
loss = outputs.loss
train_loss.append(loss.item())
loss.backward()
if idx % 50 == 0:
print(" Training loss: ", round(sum(train_loss)/len(train_loss), 6))
# Optimization
optimizer.step()
# Average train epoch loss
train_loss = sum(train_loss)/len(train_loss)
# Set model in evaluation mode
model.eval()
start_idx = 0
print(f"Epoch {epoch} | Validation")
for idx, batch in enumerate(tqdm(val_dataloader)):
with torch.no_grad():
# Forward pass
outputs = model(
pixel_values=batch["pixel_values"].to(device),
mask_labels=[labels.to(device) for labels in batch["mask_labels"]],
class_labels=[labels.to(device) for labels in batch["class_labels"]],
)
# Get validation loss
loss = outputs.loss
val_loss.append(loss.item())
if idx % 50 == 0:
print(" Validation loss: ", round(sum(val_loss)/len(val_loss), 6))
# Average validation epoch loss
val_loss = sum(val_loss)/len(val_loss)
# Print epoch losses
print(f"Epoch {epoch} | train_loss: {train_loss} | validation_loss: {val_loss}")
Saving the Trained Model
Luckily for us, 🤗 Transformers make it really easy to save trained models and custom preprocessing pipelines. We can simply call the save_pretrained() method as follows:
model.save_pretrained(<Path to target save folder>) preprocessor.save_pretrained(<Path to target save folder>)
Alternatively, we can push our trained model to the hub for private use or share it publicly. To do this, you will need to create an account on the Hub and get an authentication token. For more information, check out the tutorial on sharing your models.
from huggingface_hub import notebook_login # Login to your account notebook_login()
# Push your model and preprocessor to the Hub
model.push_to_hub("my-awesome-model")
processor.push_to_hub("my-awesome-model")
Using the push_to_hub() method will create a repository named <YOUR_USERNAME>/my-awesome-model on the Hub. Whether you save your model locally or push it to the hub, saving the model will create a folder identical to any MaskFormer repo on the hub, see an example over here.
Let’s go ahead and push our fine-tuned model to the hub:
# Login to your account
notebook_login()
# We won't be using albumentations to preprocess images for inference
processor.do_normalize = True
processor.do_resize = True
processor.do_rescale = True
# Push your model and preprocessor to the Hub
model.push_to_hub("maskformer-swin-base-sceneparse-instance")
processor.push_to_hub("maskformer-swin-base-sceneparse-instance")
Inference and Evaluation
We can now load our trained model with a single line of code and perform inference. Remember, we can load a pre-trained model using the from_pretrained(<MODEL NAME OR PATH>) method. Since we pushed our trained model to the hub, we can load it using the repository name we defined earlier. Then, to perform inference, we just need to pass in the pixel_values (preprocessed input image) to the model.
# Use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Grab the trained model and processor from the hub
model = MaskFormerForInstanceSegmentation.from_pretrained(
"adirik/maskformer-swin-base-sceneparse-instance"
).to(device)
processor = MaskFormerImageProcessor.from_pretrained(
"adirik/maskformer-swin-base-sceneparse-instance"
)
Let’s test our model on a test image:
# Use random test image
index = random.randint(0, len(test))
image = test[index]["image"].convert("RGB")
target_size = image.size[::-1]
# Preprocess image
inputs = processor(images=image, return_tensors="pt").to(device)
# Inference
model.eval()
with torch.no_grad():
outputs = model(**inputs)
Next, let’s see what information is returned by our model:
# Let's print the items returned by our model and their shapes
print("Outputs...")
for key, value in outputs.items():
print(f" {key}: {value.shape}")
Post-Processing Outputs
As we can see, MaskFormer returns class query logits of shape (batch_size, num_queries, num_labels + 1) and mask query logits of shape (batch_size, num_queries, height, width). Therefore, to retrieve the most probable instance segmentation masks and their classes and to rescale them back to the original image/s shape, we can use the convenient post_process_instance_segmentation() method of the MaskFormerImageProcessor class.
Note that this class also has post_process_semantic_segmentation() and post_process_panoptic_segmentation() methods to post-process the outputs of MaskFormer models trained on semantic segmentation and panoptic segmentation datasets. If in doubt, refer to the model card of the checkpoint you would like to use to find out which dataset your selected model was trained on.
Let’s post-process our segmentation predictions and see what this method outputs:
# Post-process results to retrieve instance segmentation maps
result = processor.post_process_instance_segmentation(
outputs,
threshold=0.5,
target_sizes=[target_size]
)[0] # we pass a single output therefore we take the first result (single)
instance_seg_mask = result["segmentation"].cpu().detach().numpy()
print(f"Final mask shape: {instance_seg_mask.shape}")
print("Segments Information...")
for info in result["segments_info"]:
print(f" {info}")
The MaskFormerImageProcessor.post_process_instance_segmentation() returns a list of length batch_size where each entry is a dictionary and contains two keys:
segmentation: A tensor of shape(height, width)where each pixel represents an instance id orList[List]run-length encoding (RLE) of the segmentation map ifreturn_coco_annotationis set toTrueor a concatenated tensor of binary segmentation maps (one per detected instance) of shape(num_instances, height, width)ifreturn_binary_mapsis set toTrue.segments_info: A dictionary that contains additional information on each segment.id: An integer representing the instance id.label_id: An integer representing the semantic class id corresponding toid.score: Prediction score of a segment withid.
Let’s go ahead and visualize the post-processed per-pixel instance segmentation map.
def visualize_instance_seg_mask(mask):
# Initialize image with zeros with the image resolution
# of the segmentation mask and 3 channels
image = np.zeros((mask.shape[0], mask.shape[1], 3))
# Create labels
labels = np.unique(mask)
label2color = {
label: (
random.randint(0, 255),
random.randint(0, 255),
random.randint(0, 255),
)
for label in labels
}
for height in range(image.shape[0]):
for width in range(image.shape[1]):
image[height, width, :] = label2color[mask[height, width]]
image = image / 255
return image
instance_seg_mask_disp = visualize_instance_seg_mask(instance_seg_mask)
plt.figure(figsize=(10, 10))
for plot_index in range(2):
if plot_index == 0:
plot_image = image
title = "Original"
else:
plot_image = instance_seg_mask_disp
title = "Segmentation"
plt.subplot(1, 2, plot_index+1)
plt.imshow(plot_image)
plt.title(title)
plt.axis("off")
Performance Evaluation
The result looks pretty good, but we still need to quantitatively benchmark our model to see how well it performs. Since our test set does not have any segmentation maps we can use, we will use our validation set, and the Evaluate library to benchmark predicted segmentation maps against ground truth maps.
The panoptic and instance segmentation models are typically evaluated using the Panoptic Quality (PQ) and Average Precision (AP) metrics, respectively. To simplify our workflow, we can post-process our predictions to get the predicted semantic segmentation maps instead of the instance segmentation maps and use the simpler Mean Intersection over Union (IoU) metric to benchmark our fine-tuned model. Load the mean_iou metric from the evaluate library to compute the mean intersection over the union between the prediction and ground truth sets.
# Load Mean IoU metric
metrics = evaluate.load("mean_iou")
# Set model in evaluation mode
model.eval()
# Test set doesn't have annotations so we will use the validation set
ground_truths, preds = [], []
for idx in tqdm(range(200)):
image = validation[idx]["image"].convert("RGB")
target_size = image.size[::-1]
# Get ground truth semantic segmentation map
annotation = np.array(validation[idx]["annotation"])[:,:,0]
# Replace null class (0) with the ignore_index (255) and reduce labels
annotation -= 1
annotation[annotation==-1] = 255
ground_truths.append(annotation)
# Preprocess image
inputs = processor(images=image, return_tensors="pt").to(device)
# Inference
model.eval()
with torch.no_grad():
outputs = model(**inputs)
# Post-process results to retrieve semantic segmentation maps
result = processor.post_process_semantic_segmentation(outputs, target_sizes=[target_size])[0]
semantic_seg_mask = result.cpu().detach().numpy()
preds.append(semantic_seg_mask)
results = metrics.compute(
predictions=preds,
references=ground_truths,
num_labels=100,
ignore_index=255
)
print(f"Mean IoU: {results['mean_iou']} | Mean Accuracy: {results['mean_accuracy']} | Overall Accuracy: {results['overall_accuracy']}")
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Hohoo, that’s it. We fine-tuned a pre-trained MaskFormer model on the Scene Parsing dataset for instance segmentation, and got pretty good results after training for only a few epochs. We uploaded our model to the Hugging Face hub so that we could download and use it with a few lines of code. We shared our model publicly, but we could also set it as private for personal use or commercialization purposes.
On top of this, we learned how to load datasets with the Datasets library, preprocess datasets with transformers ImageProcessor classes, and combine them with other image processing libraries such as Albumentations for data augmentation during training. We also learned the transformers library’s different components and how they are organized to make it easier to create custom configurations and preprocessing pipelines to fine-tune pre-trained models. Finally, we used the Evaluate library to benchmark the performance of our fine-tuned model.
Tweet @pyimagesearch OR email ask.me@pyimagesearch.com
Citation Information
Dirik, A. “Train a MaskFormer Segmentation Model with Hugging Face Transformers,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2023, https://pyimg.co/6b7z8
@incollection{Dirik_2023_HFTMF,
author = {Alara Dirik},
title = {Train a MaskFormer Segmentation Model with Hugging Face Transformers},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2023},
url = {https://pyimg.co/6b7z8},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.