
Table of Contents
- Image Translation with Pix2Pix
- Introduction
- Pix2Pix GAN Deconstructed
- Configuring Your Development Environment
- Having Problems Configuring Your Development Environment?
- Project Structure
- Configuring the Prerequisites
- Creating the Data Processing Pipeline
- Creating the Pix2Pix Architecture
- Building the Pix2Pix GAN Training Pipeline
- Training the Pix2Pix GAN
- Building the Inference Script
- Building the Training Monitor
- Analyzing the Training Procedure
- Pix2Pix Visualizations
- Summary
Image Translation with Pix2Pix
Our previous encounters with Generative Adversarial Networks (GANs) took us to the domain of Super Resolution, where we trained a GAN to upscale low-resolution images to a higher resolution. The tutorials effectively showcased how powerful a GAN can be.

That brings us to our domain of study today: Image to image translation. We are essentially converting an image belonging to the input data distribution to that of an image belonging to the output data distribution. In today’s technology world, translation problems pertaining to computer vision are very common, which amplifies the importance of today’s topic.
In this tutorial, you will learn to use Pix2Pix GAN for Image Translation.
This lesson is part of a 4-part series on GANs 201:
- Super-Resolution Generative Adversarial Networks (SRGAN)
- Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN)
- Image Translation with Pix2Pix (this tutorial)
- CycleGAN
To learn how to perform Image Translation with Pix2Pix, just keep reading.
Image Translation with Pix2Pix
Introduction
Image translation applies to various tasks, from simple photo enhancement and editing to more nuanced tasks like grayscale to RGB. For example, suppose your task is image enhancement, and your dataset is a paired set of normal images and their enhanced counterpart. The goal here would be to learn an efficient mapping of the input images to their output counterparts.
The authors of Pix2Pix build on the bedrock approach of figuring out the input-output mapping and train an additional loss function to reinforce this mapping. According to the Pix2Pix paper, their approach is effective in a variety of tasks, including (but not limited to) synthesizing photos from segmentation masks.
Today, we will apply building a Pix2Pix GAN to learn how to build real images from segmentation maps using the cityscapes dataset hosted by UC Berkeley. This dataset contains paired sets of segmentation masks and their corresponding real images of cityscapes.
It is important to note that image translation can be divided into two categories: Paired translation and unpaired translation. Our task today falls under paired translation since specific segmentation masks will correspond to specific real objects.
Pix2Pix GAN Deconstructed
Before we dive into architectural details, let’s understand the difference between a standard GAN and a conditional GANs. A standard GAN generator is described as  \rightarrow y)") , where
, where  is the generator,
is the generator,  is some random noise, and
is some random noise, and  is our output.
is our output.
The problem is that since random noise is being mapped to our output, we won’t have control over what outputs are generated. In conditional GANs, we are inserting the idea of labels (different from real or fake labels, here, labels mean different types of output data) into the GAN equation (Figure 1).
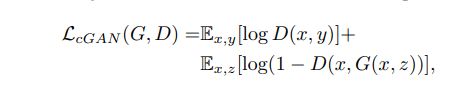
The discriminator now takes into account input data  as well as the output . The generator size of the equation now shows that instead of noise, we feed the input data + noise to the generator. At the same time, the discriminator observes the input data and the generator output.
as well as the output . The generator size of the equation now shows that instead of noise, we feed the input data + noise to the generator. At the same time, the discriminator observes the input data and the generator output.
This helps us create a mapping between inputs and the kind of outputs we would like to have.
With the foundation of conditional GANs, Pix2Pix also mixes the L1 distance (distance between two points) between the real and the generated images.
For the generator, Pix2Pix utilizes a U-Net (Figure 2) due to its skip connections. A U-Net is normally characterized by its first set of downsampling layers, its bottleneck layer, followed by its upsampling layers. The key point to remember here is that the downsampling layers are connected to the corresponding upsampling layers, characterized by the dotted lines in Figure 2.

The discriminator is a Patch GAN discriminator. Let’s take a look at Figure 3.
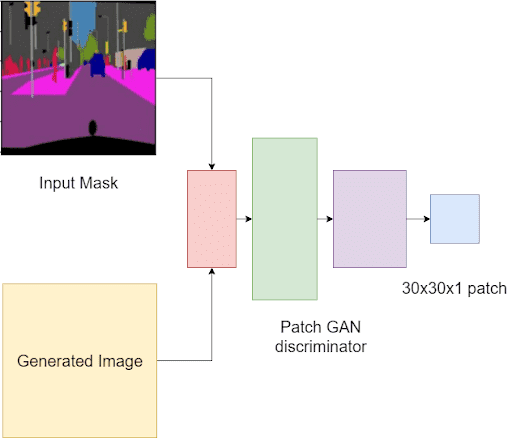
Normal GAN discriminator will take the images as input and output a single value of 0 (fake) or 1 (real). Patch GAN discriminator instead analyzes inputs as local image patches. It will assess if each patch in an image is real or fake.
In Pix2Pix, the Patch GAN will take in a pair of images: The input mask and generated image and the input mask and target image. This is because the output is conditioned on the input. Hence it is important to keep the input image in the mix (as shown in Figure 1, where the discriminator is taking two inputs).
Let’s go over the generator training procedure (Figure 4).
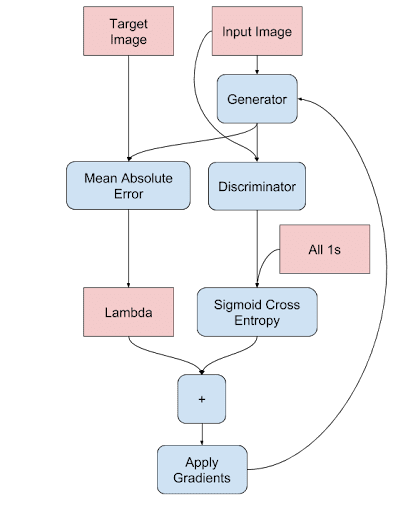
The input mask is fed to the generator giving us the fake output. Then we will feed the (input mask, generated output) pair to the discriminator, but with the label 1. This is the “fooling the discriminator” part which will tell the generator how far it still is from generating real images.
Next, let’s understand the discriminator’s process flow (Figure 5).
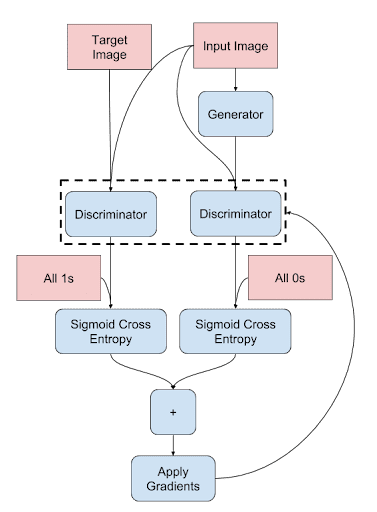
The discriminator training is fairly simple, the only difference being the conditional Patch GAN training. The pair of (input mask, target image) is compared against a label patch of 1s, and the pair of (input mask, generated output) is compared against a label patch of 0s.
Let’s implement this using tensorflow to see it in action.
Configuring Your Development Environment
To follow this guide, you need to have the OpenCV library installed on your system.
Luckily, OpenCV is pip-installable:
$ pip install opencv-contrib-python
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes.
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
!tree . . ├── inference.py ├── outputs │ ├── images │ └── models ├── pyimagesearch │ ├── config.py │ ├── data_preprocess.py │ ├── __init__.py │ ├── Pix2PixGAN.py │ ├── Pix2PixTraining.py │ └── train_monitor.py └── train_pix2pix.py 2 directories, 10 files
In the pyimagesearch directory, we have:
config.py: Contains the complete configuration pipeline of our project.data_preprocess.py: Contains scripts to help us prepare the data for GAN training.__init__.py: Makes thepyimagesearchdirectory act like a python library.Pix2PixGAN.py: Contains the Pix2Pix GAN architecture.Pix2PIxTraining.py: Contains the complete GAN training pipeline packaged into a class.train_monitor.py: Contains callbacks to help monitor model training.
In the core directory, we have:
outputs: Contains the outputs of our project (i.e., the inference images and model weights).inference.py: Contains the script to use our trained model weights for inference.train_pix2pix.py: Contains the script to train the Pix2Pix GAN model.
Configuring the Prerequisites
The config.py script in the pyimagesearch directory houses the entire configuration pipeline for this project.
# import the necessary packages
import os
# name of the dataset we will be using
DATASET = "cityscapes"
# build the dataset URL
DATASET_URL = f"http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{DATASET}.tar.gz"
# define the batch size
TRAIN_BATCH_SIZE = 32
INFER_BATCH_SIZE = 8
# dataset specs
IMAGE_WIDTH = 256
IMAGE_HEIGHT = 256
IMAGE_CHANNELS = 3
# training specs
LEARNING_RATE = 2e-4
EPOCHS = 150
STEPS_PER_EPOCH = 100
# path to our base output directory
BASE_OUTPUT_PATH = "outputs"
# GPU training pix2pix model paths
GENERATOR_MODEL = os.path.join(BASE_OUTPUT_PATH, "models",
"generator")
# define the path to the inferred images and to the grid image
BASE_IMAGES_PATH = os.path.join(BASE_OUTPUT_PATH, "images")
GRID_IMAGE_PATH = os.path.join(BASE_IMAGE_PATH, "grid.png")
On Line 5, we have specified the UC Berkeley dataset we will use for our project. The corresponding URL for the dataset is specified on Line 8.
The training and inference batch sizes are subsequently defined on Lines 11 and 12.
Next, the image specifications are defined (Lines 15-17). Finally, the GAN training specs, namely learning rate, epochs, and steps per epoch, are defined (Lines 20-22).
On Line 25, we define the outputs folder, followed by the path to save the generator weights (Lines 28 and 29). Finally, the images folder and the inference image grid path are defined (Lines 32 and 33), concluding the config.py script.
Creating the Data Processing Pipeline
GANs are heavily data-dependent. Hence it is important to have a robust data pipeline. Let’s check out the data pipeline in the data_preprocess.py script.
# import the necessary packages import tensorflow as tf # define the module level autotune AUTO = tf.data.AUTOTUNE def load_image(imageFile): # read and decode an image file from the path image = tf.io.read_file(imageFile) image = tf.io.decode_jpeg(image, channels=3) # calculate the midpoint of the width and split the # combined image into input mask and real image width = tf.shape(image)[1] splitPoint = width // 2 inputMask = image[:, splitPoint:, :] realImage = image[:, :splitPoint, :] # convert both images to float32 tensors and # convert pixels to the range of -1 and 1 inputMask = tf.cast(inputMask, tf.float32)/127.5 - 1 realImage = tf.cast(realImage, tf.float32)/127.5 - 1 # return the input mask and real label image return (inputMask, realImage)
On Line 7, we have the load_image function, which takes the image path as its argument.
First, we read and decode the image from its path (Lines 9 and 10). The images of our dataset are in the format of Figure 7.
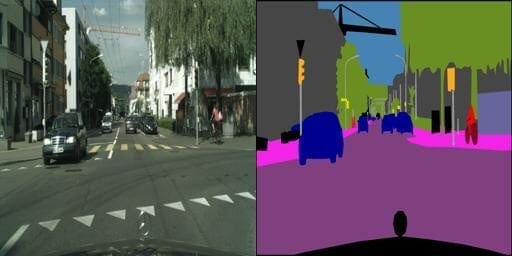
The images are of the shape (256, 512, 3). To create an input mask and real image pair, we calculate the midpoint (Lines 14 and 15) and slice the base image accordingly into an input mask and real image pair (Lines 16 and 17).
With the pair created, we convert the tensors into the float32 format and bring the pixels to the range of -1 to 1 from 0 to 255 (Lines 21 and 22).
def random_jitter(inputMask, realImage, height, width): # upscale the images for cropping purposes inputMask = tf.image.resize(inputMask, [height, width], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR) realImage = tf.image.resize(realImage, [height, width], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR) # return the input mask and real label image return (inputMask, realImage)
The authors of Pix2Pix speak about the importance of random noise in the generator input. Notice how in Figure 1, the generator also takes in random noise z along with input x. That’s because if we don’t provide noise, we make the GAN extremely specific to the dataset.
To ensure generalization, we need some random noise in our input. We achieve that by simply resizing the input images to a higher resolution (Lines 29-32) and later scaling them back down (before we load the data) using the random_jitter function.
class ReadTrainExample(object): def __init__(self, imageHeight, imageWidth): self.imageHeight = imageHeight self.imageWidth = imageWidth def __call__(self, imageFile): # read the file path and unpack the image pair inputMask, realImage = load_image(imageFile) # perform data augmentation (inputMask, realImage) = random_jitter(inputMask, realImage, self.imageHeight+30, self.imageWidth+30) # reshape the input mask and real label image inputMask = tf.image.resize(inputMask, [self.imageHeight, self.imageWidth]) realImage = tf.image.resize(realImage, [self.imageHeight, self.imageWidth]) # return the input mask and real label image return (inputMask, realImage)
Now we will group all the created functions using the read_train_example class. The __init__ function initializes class variables for image height and width (Lines 38-40), while the __call__ function takes the image path as its argument (Line 42).
On Line 44, we get the image pair using the load_image function previously defined. Then we use the random_jitter function to upscale the image and add random artifacts to our image (Line 47).
We then reshape the images to (256, 256, 3) to fit our project pipeline (Lines 51-54).
class ReadTestExample(object): def __init__(self, imageHeight, imageWidth): self.imageHeight = imageHeight self.imageWidth = imageWidth def __call__(self, imageFile): # read the file path and unpack the image pair (inputMask, realImage) = load_image(imageFile) # reshape the input mask and real label image inputMask = tf.image.resize(inputMask, [self.imageHeight, self.imageWidth]) realImage = tf.image.resize(realImage, [self.imageHeight, self.imageWidth]) # return the input mask and real label image return (inputMask, realImage)
Like the read_train_example, we create the ReadTestExample class exclusively for the test dataset (Line 59). The class contents stay the same, except that we do not apply any augmentation and resize the image to fit the project pipeline (Lines 59-75).
def load_dataset(path, batchSize, height, width, train=False): # check if this is the training dataset if train: # read the training examples dataset = tf.data.Dataset.list_files(str(path/"train/*.jpg")) dataset = dataset.map(ReadTrainExample(height, width), num_parallel_calls=AUTO) # otherwise, we are working with the test dataset else: # read the test examples dataset = tf.data.Dataset.list_files(str(path/"val/*.jpg")) dataset = dataset.map(ReadTestExample(height, width), num_parallel_calls=AUTO) # shuffle, batch, repeat and prefetch the dataset dataset = (dataset .shuffle(batchSize * 2) .batch(batchSize) .repeat() .prefetch(AUTO) ) # return the dataset return dataset
On Line 77, we create the load_dataset function, which takes in the dataset path, batch size, and a bool variable train, which will determine if the function returns the training dataset or the test dataset.
On Lines 79-83, we define the condition of the train bool being set to True. The dataset is initialized, and the ReadTrainExample function is mapped to all entries. For the train bool being set to False, we initialize the dataset and map the read_test_example function to all the entries.
This is followed by batching and prefetching the data (Lines 92-97). This concludes the load_dataset function.
Creating the Pix2Pix Architecture
For the Pix2Pix architecture, we need to define a U-Net generator and a Patch GAN discriminator. Let’s move into the Pix2PixGAN.py script.
# import the necessary packages from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2DTranspose from tensorflow.keras.layers import LeakyReLU from tensorflow.keras.layers import concatenate from tensorflow.keras.layers import MaxPool2D from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import Dropout from tensorflow.keras import Model from tensorflow.keras import Input class Pix2Pix(object): def __init__(self, imageHeight, imageWidth): # initialize the image height and width self.imageHeight = imageHeight self.imageWidth = imageWidth def generator(self): # initialize the input layer inputs = Input([self.imageHeight, self.imageWidth, 3]) # down Layer 1 (d1) => final layer 1 (f1) d1 = Conv2D(32, (3, 3), activation="relu", padding="same")( inputs) d1 = Dropout(0.1)(d1) f1 = MaxPool2D((2, 2))(d1) # down Layer 2 (l2) => final layer 2 (f2) d2 = Conv2D(64, (3, 3), activation="relu", padding="same")(f1) f2 = MaxPool2D((2, 2))(d2) # down Layer 3 (l3) => final layer 3 (f3) d3 = Conv2D(96, (3, 3), activation="relu", padding="same")(f2) f3 = MaxPool2D((2, 2))(d3) # down Layer 4 (l3) => final layer 4 (f4) d4 = Conv2D(96, (3, 3), activation="relu", padding="same")(f3) f4 = MaxPool2D((2, 2))(d4) # u-bend of the u-bet b5 = Conv2D(96, (3, 3), activation="relu", padding="same")(f4) b5 = Dropout(0.3)(b5) b5 = Conv2D(256, (3, 3), activation="relu", padding="same")(b5) # upsample Layer 6 (u6) u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2), padding="same")(b5) u6 = concatenate([u6, d4]) u6 = Conv2D(128, (3, 3), activation="relu", padding="same")( u6) # upsample Layer 7 (u7) u7 = Conv2DTranspose(96, (2, 2), strides=(2, 2), padding="same")(u6) u7 = concatenate([u7, d3]) u7 = Conv2D(128, (3, 3), activation="relu", padding="same")( u7) # upsample Layer 8 (u8) u8 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding="same")(u7) u8 = concatenate([u8, d2]) u8 = Conv2D(128, (3, 3), activation="relu", padding="same")(u8) # upsample Layer 9 (u9) u9 = Conv2DTranspose(32, (2, 2), strides=(2, 2), padding="same")(u8) u9 = concatenate([u9, d1]) u9 = Dropout(0.1)(u9) u9 = Conv2D(128, (3, 3), activation="relu", padding="same")(u9) # final conv2D layer outputLayer = Conv2D(3, (1, 1), activation="tanh")(u9) # create the generator model generator = Model(inputs, outputLayer) # return the generator return generator
We have packaged the generator and discriminator into a single class for easy access (Line 12).
In Figure 2, we have illustrated how a U-Net should look. On Line 20, we start by defining the inputs of the generator model. This is followed by a Conv2D, Dropout, and a MaxPool2D layer. This layer will later be concatenated with one of the upsampling layers, so we store the Conv2D layer output (Lines 23-26).
This is followed by 3 sets of Conv2D and MaxPool2D layers (Lines 29-38). These layers represent the downsampling layers. Lines 41-43 represent the bottleneck layers of the U-Net.
The subsequent layers are upsampling layers. The first set of upsampling layers is concatenated with the last downsampling layer. The 2nd set of upsampling layers is concatenated with the second-last downsampling layer. The final set of upsampling layers is concatenated with the first downsampling layer Conv2D output (Lines 46-70).
The final output layer is a Conv2D layer to bring the output to 256, 256, 3 (Line 73).
def discriminator(self): # initialize input layer according to PatchGAN inputMask = Input(shape=[self.imageHeight, self.imageWidth, 3], name="input_image" ) targetImage = Input( shape=[self.imageHeight, self.imageWidth, 3], name="target_image" ) # concatenate the inputs x = concatenate([inputMask, targetImage]) # add four conv2D convolution layers x = Conv2D(64, 4, strides=2, padding="same")(x) x = LeakyReLU()(x) x = Conv2D(128, 4, strides=2, padding="same")(x) x = LeakyReLU()(x) x = Conv2D(256, 4, strides=2, padding="same")(x) x = LeakyReLU()(x) x = Conv2D(512, 4, strides=1, padding="same")(x) # add a batch-normalization layer => LeakyReLU => zeropad x = BatchNormalization()(x) x = LeakyReLU()(x) # final conv layer last = Conv2D(1, 3, strides=1)(x) # create the discriminator model discriminator = Model(inputs=[inputMask, targetImage], outputs=last) # return the discriminator return discriminator
On Line 81, we define the discriminator. As explained earlier, the conditional discriminator will take in two images as its inputs (Lines 83-89). We concatenate the two images on Line 92, followed by standard Conv2D and LeakyReLU layers (Lines 95-101).
A batch normalization layer is added on Line 104, followed by another LeakyReLU layer. The final Conv2D layer is added to have a 30x30x1 patch output (Line 108). The discriminator is created on Line 111, concluding the discriminator and the Pix2Pix GAN architecture.
Building the Pix2Pix GAN Training Pipeline
The Pix2Pix GAN training process is slightly different from a normal GAN. So let’s hop into the Pix2PixTraining.py script.
# import the necessary packages from tensorflow.keras import Model import tensorflow as tf class Pix2PixTraining(Model): def __init__(self, generator, discriminator): super().__init__() # initialize the generator, discriminator self.generator = generator self.discriminator = discriminator def compile(self, gOptimizer, dOptimizer, bceLoss, maeLoss): super().compile() # initialize the optimizers for the generator # and discriminator self.gOptimizer = gOptimizer self.dOptimizer = dOptimizer # initialize the loss functions self.bceLoss = bceLoss self.maeLoss = maeLoss
For ease of understanding, we have packaged the entire process into a class (Line 5).
On Line 6, we define the __init__ function, which takes the generator and discriminator as arguments and creates class-specific variable copies of these arguments (Lines 9 and 10).
The next function is compile, which takes in the generator optimizer, the discriminator optimizer, and the loss functions (Line 12). The function creates class variable counterparts of the arguments (Lines 16-21).
def train_step(self, inputs): # grab the input mask and corresponding real images (inputMask, realImages) = inputs # initialize gradient tapes for both generator and discriminator with tf.GradientTape() as genTape, tf.GradientTape() as discTape: # generate fake images fakeImages = self.generator(inputMask, training=True) # discriminator output for real images and fake images discRealOutput = self.discriminator( [inputMask, realImages], training=True) discFakeOutput = self.discriminator( [inputMask, fakeImages], training=True)
The train_step function on Line 23 takes the image pairs as its argument. First, we unpack the image pair (Line 25). Then we initialize two gradient tapes, one for the discriminator and one for the generator (Line 28).
We start by passing the input mask images through the generator and getting fake outputs (Line 30).
Next, we pass the input masks and the real target images through the Patch GAN discriminator and store it as the discRealOutput (Lines 33 and 34). We similarly pass the input masks along with the fake images through the Patch GAN and store the outputs as the discFakeOutput (Lines 35 and 36).
# compute the adversarial loss for the generator
misleadingImageLabels = tf.ones_like(discFakeOutput)
ganLoss = self.bceLoss(misleadingImageLabels, discFakeOutput)
# compute the mean absolute error between the fake and the
# real images
l1Loss = self.maeLoss(realImages, fakeImages)
# compute the total generator loss
totalGenLoss = ganLoss + (10 * l1Loss)
# discriminator loss for real and fake images
realImageLabels = tf.ones_like(discRealOutput)
realDiscLoss = self.bceLoss(realImageLabels, discRealOutput)
fakeImageLabels = tf.zeros_like(discFakeOutput)
generatedLoss = self.bceLoss(fakeImageLabels, discFakeOutput)
# compute the total discriminator loss
totalDiscLoss = realDiscLoss + generatedLoss
# calculate the generator and discriminator gradients
generatorGradients = genTape.gradient(totalGenLoss,
self.generator.trainable_variables
)
discriminatorGradients = discTape.gradient(totalDiscLoss,
self.discriminator.trainable_variables
)
# apply the gradients to optimize the generator and discriminator
self.gOptimizer.apply_gradients(zip(generatorGradients,
self.generator.trainable_variables)
)
self.dOptimizer.apply_gradients(zip(discriminatorGradients,
self.discriminator.trainable_variables)
)
# return the generator and discriminator losses
return {"dLoss": totalDiscLoss, "gLoss": totalGenLoss}
First, we will calculate the generator loss. For that, we simply associate fake labels (1s) (Line 39) to the fake discriminator output patch and calculate the l1 distance between the target real images and the predicted fake images (Lines 40-44). The l1 distance will help capture the finer details by directly translating information from the real images to the generator.
We add the two losses, concluding with the generator loss (Line 47). The lambda coefficient for the L1 loss is set to 10 for our project. However, the paper asks to put it as 1000.
Next, we move into discriminator training. The input mask-real image Patch GAN output is compared to a patch of 1s, while the input mask-fake images Patch GAN output is compared to a patch of 0s. This is normal GAN training but with added requirements for Patch GAN and conditional GANs (Lines 50-53).
The gradients are then calculated and applied to the trainable weights (Lines 59-75).
Training the Pix2Pix GAN
With our architecture and training pipeline ready, we just need to execute the two scripts correctly. Let’s move into the train_pix2pix.py script.
# USAGE
# python train_pix2pix.py
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.Pix2PixTraining import Pix2PixTraining
from pyimagesearch.Pix2PixGAN import Pix2Pix
from pyimagesearch.data_preprocess import load_dataset
from pyimagesearch.train_monitor import get_train_monitor
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.losses import MeanAbsoluteError
from tensorflow.keras.utils import get_file
import pathlib
import os
# download the cityscape training dataset
print("[INFO] downloading the dataset...")
pathToZip = get_file(
fname=f"{config.DATASET}.tar.gz",
origin=config.DATASET_URL,
extract=True
)
pathToZip = pathlib.Path(pathToZip)
path = pathToZip.parent/config.DATASET
# build the training dataset
print("[INFO] building the train dataset...")
trainDs = load_dataset(path=path, train=True,
batchSize=config.TRAIN_BATCH_SIZE, height=config.IMAGE_HEIGHT,
width=config.IMAGE_WIDTH)
# build the test dataset
print("[INFO] building the test dataset...")
testDs = load_dataset(path=path, train=False,
batchSize=config.INFER_BATCH_SIZE, height=config.IMAGE_HEIGHT,
width=config.IMAGE_WIDTH)
Using tensorflow’s get_file function to download the cityscapes dataset (Lines 23-27), we use pathlib to efficiently store pointers to the file paths (Lines 28 and 29).
On Lines 33-35, we build the training dataset using the load_dataset function previously created in the data_processing.py script.
On Lines 39-41, we build the test dataset using the load_dataset function previously created in the data_processing.py script.
# initialize the generator and discriminator network
print("[INFO] initializing the generator and discriminator...")
pix2pixObject = Pix2Pix(imageHeight=config.IMAGE_HEIGHT,
imageWidth=config.IMAGE_WIDTH)
generator = pix2pixObject.generator()
discriminator = pix2pixObject.discriminator()
# build the pix2pix training model and compile it
pix2pixModel = Pix2PixTraining(
generator=generator,
discriminator=discriminator)
pix2pixModel.compile(
dOptimizer=Adam(learning_rate=config.LEARNING_RATE),
gOptimizer=Adam(learning_rate=config.LEARNING_RATE),
bceLoss=BinaryCrossentropy(from_logits=True),
maeLoss=MeanAbsoluteError(),
)
# check whether output model directory exists
# if it doesn't, then create it
if not os.path.exists(config.BASE_OUTPUT_PATH):
os.makedirs(config.BASE_OUTPUT_PATH)
# check whether output image directory exists, if it doesn't, then
# create it
if not os.path.exists(config.BASE_IMAGES_PATH):
os.makedirs(config.BASE_IMAGES_PATH)
# train the pix2pix model
print("[INFO] training the pix2pix model...")
callbacks = [get_train_monitor(testDs, epochInterval=10,
imagePath=config.BASE_IMAGES_PATH,
batchSize=config.INFER_BATCH_SIZE)]
pix2pixModel.fit(trainDs, epochs=config.EPOCHS, callbacks=callbacks,
steps_per_epoch=config.STEPS_PER_EPOCH)
# set the path for the generator
genPath = config.GENERATOR_MODEL
# save the pix2pix generator
print(f"[INFO] saving pix2pix generator to {genPath}...")
pix2pixModel.generator.save(genPath)
On Line 45, we build the Pix2Pix network object, followed by the generator and the discriminator (Lines 47 and 48). A Pix2PixTraining pipeline object is then built, passing the previously created generator and discriminator as arguments. The pipeline is then compiled using the Adam optimizer and binary cross-entropy and mean absolute error losses (Lines 51-59).
The output directories are created if not already (Lines 63-69). We define callbacks and use our custom callback function to track training (Lines 73-75).
The penultimate step is to fit the data into our Pix2Pix model with parameters like epochs and steps per epoch (Lines 76 and 77).
Finally, we save the training generator in the path set in the configuration pipeline (Lines 80 and 84).
Building the Inference Script
To assess the predictions of our generator, we will build an inference script. Let’s move into the inference.py script.
# USAGE
# python inference.py
# import tensorflow and fix the random seed for better reproducibility
import tensorflow as tf
tf.random.set_seed(42)
# import the necessary packages
from pyimagesearch import config
from pyimagesearch.data_preprocess import load_dataset
from tensorflow.keras.preprocessing.image import array_to_img
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import get_file
from matplotlib.pyplot import subplots
import pathlib
import os
# download the cityscape training dataset
print("[INFO] downloading the dataset...")
pathToZip = get_file(
fname=f"{config.DATASET}.tar.gz",
origin=config.DATASET_URL,
extract=True
)
pathToZip = pathlib.Path(pathToZip)
path = pathToZip.parent/config.DATASET
# build the test dataset
print("[INFO] building the test dataset...")
testDs = load_dataset(path=path, train=False,
batchSize=config.INFER_BATCH_SIZE, height=config.IMAGE_HEIGHT,
width=config.IMAGE_WIDTH)
Echoing the training script, we build the test dataset the same way we build the training dataset, using the get_file function from tensorflow and pathlib (Lines 20-32).
# get the first batch of testing images
(inputMask, realImage) = next(iter(testDs))
# set the path for the generator
genPath = config.GENERATOR_MODEL
# load the trained pix2pix generator
print("[INFO] loading the trained pix2pix generator...")
pix2pixGen = load_model(genPath, compile=False)
# predict using pix2pix generator
print("[INFO] making predictions with the generator...")
pix2pixGenPred = pix2pixGen.predict(inputMask)
# plot the respective predictions
print("[INFO] saving the predictions...")
(fig, axes) = subplots(nrows=config.INFER_BATCH_SIZE, ncols=3,
figsize=(50, 50))
On Line 35, we grab the first batch of testing images. The trained generator weights are then loaded on Line 42 using the generator path.
The input test images are then used to make predictions (Line 46). To plot these images, we define a subplot (Lines 50 and 51).
# plot the predicted images
for (ax, inp, pred, tar) in zip(axes, inputMask,
p2pGenPred, realImage):
# plot the input mask image
ax[0].imshow(array_to_img(inp))
ax[0].set_title("Input Image")
# plot the predicted Pix2Pix image
ax[1].imshow(array_to_img(pred))
ax[1].set_title("pix2pix prediction")
# plot the ground truth
ax[2].imshow(array_to_img(tar))
ax[2].set_title("Target label")
# check whether output image directory exists, if it doesn't, then
# create it
if not os.path.exists(config.BASE_IMAGEs_PATH):
os.makedirs(config.BASE_IMAGES_PATH)
# serialize the results to disk
print("[INFO] saving the pix2pix predictions to disk...")
fig.savefig(config.GRID_IMAGE_PATH)
We loop over the input images, predictions, and the real images, plotting each of them for our final grid image (Lines 54-66). The visualizations are then saved in the output images path set in the configuration file (Lines 70-75).
Building the Training Monitor
Before we see the training results, let’s quickly go over the train_monitor.py script.
# import the necessary packages from tensorflow.keras.preprocessing.image import array_to_img from tensorflow.keras.callbacks import Callback from matplotlib.pyplot import subplots import matplotlib.pyplot as plt import tensorflow as tf def get_train_monitor(testDs, imagePath, batchSize, epochInterval): # grab the input mask and the real image from the testing dataset (tInputMask, tRealImage) = next(iter(testDs)) class TrainMonitor(Callback): def __init__(self, epochInterval=None): self.epochInterval = epochInterval def on_epoch_end(self, epoch, logs=None): if self.epochInterval and epoch % self.epochInterval == 0: # get the pix2pix prediction tPix2pixGenPred = self.model.generator.predict(tInputMask) (fig, axes) = subplots(nrows=batchSize, ncols=3, figsize=(50, 50))
The get_train_monitor function is defined on Line 8, which takes the test dataset, image path, batch size, and epoch intervals as its arguments. We use iter to grab a batch of data to predict (Line 10).
We create a class called TrainMonitior, inheriting from the keras Callback class (Line 12). The main function to note here is on_epoch_end, which takes in the epochs as an argument (Line 16).
When the epoch reaches certain points where it is divisible by the epochInterval value, we will display the predictions from the generator (Line 19). To plot those results, we will create a subplot on Lines 21 and 22.
# plot the predicted images
for (ax, inp, pred, tgt) in zip(axes, tInputMask,
tPix2pixGenPred, tRealImage):
# plot the input mask image
ax[0].imshow(array_to_img(inp))
ax[0].set_title("Input Image")
# plot the predicted Pix2Pix image
ax[1].imshow(array_to_img(pred))
ax[1].set_title("Pix2Pix Prediction")
# plot the ground truth
ax[2].imshow(array_to_img(tgt))
ax[2].set_title("Target Label")
plt.savefig(f"{imagePath}/{epoch:03d}.png")
plt.close()
# instantiate a train monitor callback
trainMonitor = TrainMonitor(epochInterval=epochInterval)
# return the train monitor
return trainMonitor
The next part of the function is plotting the input mask, predictions, and the ground truth (Lines 25-40). Finally, we instantiate a trainMonitor object and conclude the function.
Analyzing the Training Procedure
Let’s analyze the training loss.
[INFO] training pix2pix... Epoch 1/150 100/100 [==============================] - 62s 493ms/step - dLoss: 0.7812 - gLoss: 4.8063 Epoch 2/150 100/100 [==============================] - 46s 460ms/step - dLoss: 1.2357 - gLoss: 3.3020 Epoch 3/150 100/100 [==============================] - 46s 460ms/step - dLoss: 0.9255 - gLoss: 4.4217 ... Epoch 147/150 100/100 [==============================] - 46s 457ms/step - dLoss: 1.3285 - gLoss: 2.8975 Epoch 148/150 100/100 [==============================] - 46s 458ms/step - dLoss: 1.3033 - gLoss: 2.8646 Epoch 149/150 100/100 [==============================] - 46s 457ms/step - dLoss: 1.3058 - gLoss: 2.8853 Epoch 150/150 100/100 [==============================] - 46s 458ms/step - dLoss: 1.2994 - gLoss: 2.8826
We see some fluctuations in the loss values, but eventually, the generator loss goes down. The fluctuations can be attributed to the L1 loss, where we compare the pixel-wise values.
Since many images for which we are individually comparing the pixel-wise distance to replicate the image’s finer details, the loss will try to resist before eventually dipping to a respectable value.
Pix2Pix Visualizations
Let’s analyze the visualizations of our Pix2Pix model (Figures 8 and 9).
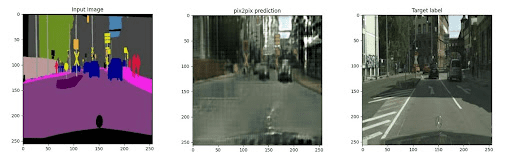
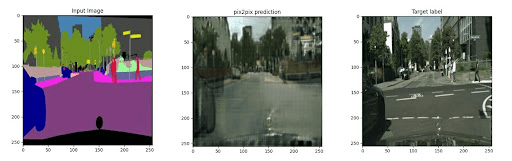
As we can see from the input segmentation mask, the Pix2Pix predictions have nearly captured the overall essence of the information represented by the input image mask.
Notice that the input masks do not have finer details like white road paint, sign writings, etc. Accordingly, these have not been reflected in the predictions. However, general observations, like the gray road, green trees, and black cars, have successfully popped up in the predictions.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Today, we went over Pix2Pix, a type of generative adversarial network which can create input to output mappings. It utilizes the concept of adversarial loss and the pixel-wise distance between generated and output images. The adversarial loss shapes our generator to work as expected. The pixel-wise loss helps develop the finer details.
The visualizations show that our model has learned the input-output mapping very robustly. The outputs are very near the actual real images, showing that our loss functions have also worked correctly.
The stagnation of loss at times can be attributed to the difficulty in getting the pixel-wise loss to a lower value.
Citation Information
Chakraborty, D. “Image Translation with Pix2Pix,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2022, https://pyimg.co/ma1qi
@incollection{Chakraborty_2022_ImageTransPix2Pix,
author = {Devjyoti Chakraborty},
title = {Image Translation with Pix2Pix},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/ma1qi},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.