
In this tutorial, you will learn how to train a DCGAN to generate fashion images in color. You will learn the common challenges, techniques to address these challenges, and GAN evaluation metrics through the training process.

This lesson is the third post of a GAN tutorial series:
- Intro to Generative Adversarial Networks (GANs)
- Get Started: DCGAN for Fashion-MNIST
- GAN Training Challenges: DCGAN for Color Images (this post)
To learn how to train a DCGAN to generate fashion images in color and common GAN training challenges and best practices, just keep reading.
In my previous post, Get Started: DCGAN for Fashion-MNIST, you learned how to train a DCGAN to generate grayscale Fashion-MNIST images. In this post, let’s train a DCGAN with color images to demonstrate the common challenges of GAN training. We will also briefly discuss some improvement techniques and GAN evaluation metrics. Please follow the tutorial with the Colab notebook here for a complete code example.
DCGAN for Color Images
We will take the DCGAN code from my previous post as the baseline and then make adjustments to train color images. Since we already walked through the DCGAN training end-to-end in detail in my previous post, now we will focus only on the key changes needed to train DCGAN for color images:
- Data: download the color images from Kaggle and preprocess them to the range of
[-1, 1]. - Generator: adjust how to upsample the model architecture to generate a color image.
- Discriminator: adjust the input image shape from
28×28×1to64×64×3.
With these changes, you can start training the DCGAN on the color image; however, when working with color images or any data other than MNIST or Fashion-MNIST, you will realize how challenging GAN training can be. Even training with Fashion-MNIST grayscale images could be tricky.
1. Prepare the Data
We will train the DCGAN with a dataset called Clothing & Models from Kaggle, which is a collection of clothing pieces scraped from Zalando.com. There are six categories and over 16k color images in the size of 606×875, which will be resized to 64×64 for training.
To download data from Kaggle, you will need to provide your Kaggle credential. You could either upload the Kaggle json file to Colab or put your Kaggle user name and key in the notebook. We chose the latter option.
os.environ['KAGGLE_USERNAME']="enter-your-own-user-name" os.environ['KAGGLE_KEY']="enter-your-own-user-name"
Download and unzip the data to a directory called dataset.
!kaggle datasets download -d dqmonn/zalando-store-crawl -p datasets !unzip datasets/zalando-store-crawl.zip -d datasets/
After downloading and unzipping the data, we set a directory where the data are.
zalando_data_dir = "/content/datasets/zalando/zalando/zalando"
Then we use Keras’ image_dataset_from_directory to create a tf.data.Dataset from the images in the directory, which will be used for training the model later on. Finally, we specify the image size of 64×64 and a batch size of 32.
train_images = tf.keras.utils.image_dataset_from_directory( zalando_data_dir, label_mode=None, image_size=(64, 64), batch_size=32)
Let’s visualize one training image as an example in Figure 1:

64×64 training image (source: Clothing & Models).Same as before, we normalize the images to the range of [-1, 1] because the generator’s final layer activation uses tanh. Finally, we apply the normalization by using the map function of tf.dataset with a lambda function.
train_images = train_images.map(lambda x: (x - 127.5) / 127.5)
2. Generator
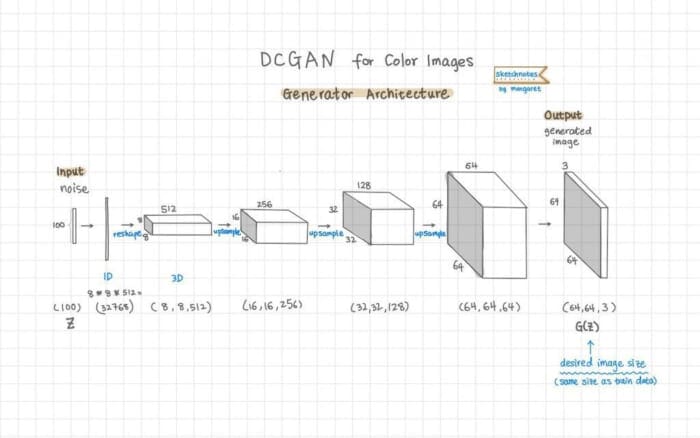
We create the generator architecture with the keras Sequential API in the build_generator function. We already went through the details of how to create the generator architecture in my previous DCGAN post. Here let’s look at how to adjust the upsampling to generate the desired color image size of 64×64×3:
- We update
CHANNELS = 3for color images instead of 1, which is for grayscale images. - A stride of 2 halves the width and height so you can work backward to figure out the initial image size dimension: for Fashion-MNIST, we upsampled as
7 -> 14 -> 28. Now we are working with a training image size of64×64, so we upsample a few times as8 -> 16 -> 32 -> 64. This means we add one more set ofConv2DTranspose -> BatchNormalization -> ReLU.
Another change made to the generator is to update kernel size from 5 to 4 to avoid reducing checkerboard artifacts in the generated images (see Figure 2).

This is because the kernel size of 5 is not divisible by the stride of 2, according to the post Deconvolution and Checkerboard Artifacts. So the solution is to use a kernel size of 4 instead of 5.
We can visualize the DCGAN generator architecture in Figure 3:
Visualize the generator architecture in code by calling generator.summary() in Figure 4:

3. Discriminator
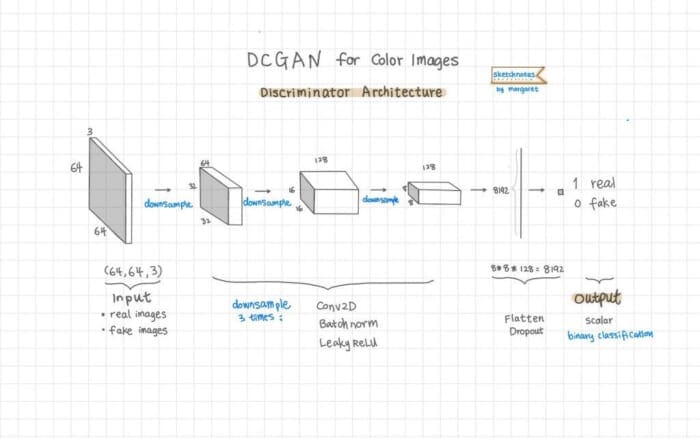
The main change in the discriminator architecture is the image input shape: we are using the shape of [64, 64, 3] instead of [28, 28, 1]. We also added one more set of Conv2D -> BatchNormalization -> LeakyReLU to balance out the increased architecture complexity in the generator as mentioned above. Everything else remains the same.
We can visualize the DCGAN discriminator architecture in Figure 5:
Visualize the discriminator architecture in code by calling discriminator.summary() in Figure 6:

The DCGAN Model
Again we define the DCGAN model architecture by subclass keras.Model and override train_step to define the custom training loops. The only slight change in code is to apply one-sided label smoothing to the real labels.
real_labels = tf.ones((batch_size, 1))
real_labels += 0.05 * tf.random.uniform(tf.shape(real_labels))
This technique reduces the overconfidence of the discriminator and therefore helps stabilize the GAN training. Refer to Adrian Rosebrock’s post Label smoothing with Keras, TensorFlow, and Deep Learning for details on label smoothing in general. The “one-sided label smoothing” technique for regularizing GAN training is proposed in the paper Improved Techniques for Training GANs, where you may find other improvement techniques as well.
Define Kera Callback for Training Monitoring
Same code with no change — override Keras Callback to monitor and visualize the generated images during training.
class GANMonitor(keras.callbacks.Callback):
def __init__():
...
def on_epoch_end():
...
def on_train_end():
...
Train the DCGAN Model
Here we put together the dcgan model with the DCGAN class:
dcgan = DCGAN(discriminator=discriminator, generator=generator, latent_dim=LATENT_DIM)
Compile the dcgan model, and the main change is the learning rate. Here I have set the discriminator learning rate as 0.0001 and generator learning rate as 0.0003. This is to make sure that the discriminator doesn’t overpower the generator.
D_LR = 0.0001 # discriminator learning rate G_LR = 0.0003 # generator learning rate dcgan.compile( d_optimizer=keras.optimizers.Adam(learning_rate=D_LR, beta_1 = 0.5), g_optimizer=keras.optimizers.Adam(learning_rate=G_LR, beta_1 = 0.5), loss_fn=keras.losses.BinaryCrossentropy(), )
Now we simply call model.fit() to train the dcgan model!
NUM_EPOCHS = 50 # number of epochs dcgan.fit(train_images, epochs=NUM_EPOCHS, callbacks=[GANMonitor(num_img=16, latent_dim=LATENT_DIM)])
Here are the screenshots with images created by the generator throughout the DCGAN training process (Figure 7):

GAN Training Challenges
Now that we have finished training DCGAN with color images. Let’s discuss some of the common challenges of GAN training.
GANs are very difficult to train, and here are some of the well-known challenges:
- Non-convergence: instability, vanishing gradients, or slow training
- Mode collapse
- Difficult to evaluate
Failure to Converge
Unlike training other models such as an image classifier, the losses or accuracy of D and G during training only measure D and G individually and doesn’t measure the GAN overall performance and how good the generator is at creating images. The GAN model is “good” when an equilibrium is reached between the generator and discriminator, typically when the discriminator’s loss is around 0.5.
GAN training instability: it’s difficult to keep D and G balanced to reach an equilibrium. Looking at the losses during training, you will notice they may oscillate wildly. And both D and G could get stuck and never improve. Training for a long time doesn’t always make the generator better. The image quality by the generator may deteriorate over time.
Vanishing gradient: in the custom training loop, we went over how to calculate the discriminator and generator losses, compute gradients and then use the gradients to make updates. The generator relies on the discriminator’s feedback to make improvements. If the discriminator is so strong that it overpowers the generator: it can tell each time there is a fake image, then the generator stops making progress in its training.
You may notice that sometimes the generated images stay as poor quality even after training for a while. This means the model fails to find an equilibrium between the discriminator and generator.
Experiment: Make D architecture much stronger (more parameters in model architecture) or train faster than G (e.g., increase D’s learning rate to be much higher than G’s).
Mode Collapse
Mode collapse occurs when the generator produces the same images or a small subset of the training images repeatedly. A good generator should make a wide variety of images that resemble the training images in all its categories. Mode collapse happens when the discriminator can’t tell the generated images are fake, so the generator keeps producing those same images to fool the discriminator.
Experiment: to simulate the mode collapse issue in the code, try reducing the noise vector dimension from 100 to 10; or increase the noise vector dimension from 100 to 128 to increase image diversity.
Difficult to Evaluate
It’s challenging to evaluate the GAN models because there is no easy way to determine whether a generated image is “good.” Unlike an image classifier, the prediction is either correct or incorrect according to the ground truth label. This leads to the discussion below on how we evaluate GAN models.
GAN Evaluation Metrics
There are two criteria for a successful generator — it should generate images with:
- good quality: high fidelity and realistic,
- diversity (or variety): a good representation of the training images’ different types (or categories).
We can evaluate the model either qualitatively (visually inspect images) or quantitatively with some metrics.
Qualitative evaluation via visual inspection. As we did in the DCGAN training, we look at a set of images generated on the same seed and visually inspect whether the images look better as training goes on. This works for a toy example, but it’s too labor-intensive for large-scale training.
Inception Score (IS) and Fréchet Inception Distance (FID) are two popular metrics to compare GAN models quantitatively.
The Inception Score was introduced in this paper: Improved Techniques for Training GANs. It measures both the quality and diversity of the generated images. The idea is to use the inception model to classify the generated images and use the predictions to evaluate the generator. A higher score indicates the model is better.
The Fréchet Inception Distance (FID) also uses the inception network for feature extraction and calculates the data distribution. FID improves upon IS by looking at both the generated images and training images instead of only the generated images in isolation. A lower FID means the generated images are more similar to the real images, therefore a better GAN model.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this post, you have learned how to train a DCGAN to generate fashion images in color. You have also learned about the common challenges of GAN training, some improvement techniques, and the GAN evaluation metrics. In my next post, we will learn how to further improve training stability with Wasserstein GAN (WGAN) and Wasserstein GAN with Gradient Penalty (WGAN-GP).
Citation Information
Maynard-Reid, M. “GAN Training Challenges: DCGAN for Color Images,” PyImageSearch, 2021, https://pyimagesearch.com/2021/12/13/gan-training-challenges-dcgan-for-color-images/
@article{Maynard-Reid_2021_GAN_Training,
author = {Margaret Maynard-Reid},
title = {{GAN} Training Challenges: {DCGAN} for Color Images},
journal = {PyImageSearch},
year = {2021},
note = {https://pyimagesearch.com/2021/12/13/gan-training-challenges-dcgan-for-color-images/},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.