
Most introductions to Tesseract tutorials will provide you with instructions to install and configure Tesseract on your machine, provide one or two examples of how to use the tesseract binary, and then perhaps how to integrate Tesseract with Python using a library such as pytesseract — the problem with these intro tutorials is that they fail to capture the importance of page segmentation modes (PSMs). Let’s get a bullseye with our OCR.

Tesseract Page Segmentation Modes (PSMs) Explained: How to Improve Your OCR Accuracy
After going through these guides, a computer vision/deep learning practitioner is given the impression that OCR’ing an image, regardless of how simple or complex it may be, is as simple as opening up a shell, executing the tesseract command, and providing the path to the input image (i.e., no additional options or configurations).
More times than not (and nearly always the case for complex images), Tesseract either:
- Cannot optical character recognition (OCR) any of the text in the image, returning an empty result
- Attempts to OCR the text, but is wildly incorrect, returning nonsensical results
In fact, that was the case for me when I started playing around with OCR tools back in college. I read one or two tutorials online, skimmed through the documentation, and quickly became frustrated when I couldn’t obtain the correct OCR result. I had absolutely no idea how and when to use different options. I didn’t even know what half the options controlled as the documentation was so sparse and did not provide concrete examples!
The mistake I made, and perhaps one of the biggest issues I see with budding OCR practitioners make now, is not fully understanding how Tesseract’s page segmentation modes can dramatically influence the accuracy of your OCR output.
When working with the Tesseract OCR engine, you absolutely have to become comfortable with Tesseract’s PSMs — without them, you’re quickly going to become frustrated and will not be able to obtain high OCR accuracy.
Inside this tutorial, you’ll learn all about Tesseract’s 14 page segmentation modes, including:
- What they do
- How to set them
- When to use each of them (thereby ensuring you’re able to correctly OCR your input images)
Let’s dive in!
Learning Objectives
In this tutorial, you will:
- Learn what page segmentation modes (PSMs) are
- Discover how choosing a PSM can be the difference between a correct and incorrect OCR result
- Review the 14 PSMs built into the Tesseract OCR engine
- See examples of each of the 14 PSMs in action
- Discover my tips, suggestions, and best practices when using these PSMs
To learn how to improve your OCR results with PSM, just keep reading.
Tesseract Page Segmentation Modes
In the first part of this tutorial, we’ll discuss what page segmentation modes (PSMs) are, why they are important, and how they can dramatically impact our OCR accuracy.
From there, we’ll review our project directory structure for this tutorial, followed by exploring each of the 14 PSMs built into the Tesseract OCR engine.
The tutorial will conclude with a discussion of my tips, suggestions, and best practices when applying various PSMs with Tesseract.
What Are Page Segmentation Modes?
The number one reason I see budding OCR practitioners fail to obtain the correct OCR result is that they are using the incorrect page segmentation mode. To quote the Tesseract documentation, by default, Tesseract expects a page of text when it segments an input image (Improving the quality of the output).
That “page of text” assumption is so incredibly important. If you’re OCR’ing a scanned chapter from a book, the default Tesseract PSM may work well for you. But if you’re trying to OCR only a single line, a single word, or maybe even a single character, then this default mode will result in either an empty string or nonsensical results.
Think of Tesseract as your big brother growing up as a child. He genuinely cares for you and wants to see you happy — but at the same time, he has no problem pushing you down in the sandbox, leaving you there with a mouthful of grit, and not offering a helping hand to get back up.
Part of me thinks that this is a user experience (UX) problem that could potentially be improved by the Tesseract development team. Including just a short message saying:
Not getting the correct OCR result? Try using different page segmentation modes. You can see all PSM modes by running
tesseract --help-extra.
Perhaps they could even link to a tutorial that explains each of the PSMs in easy to understand language. From there the end user would be more successful in applying the Tesseract OCR engine to their own projects.
But until that time comes, Tesseract’s page segmentation modes, despite being a critical aspect of obtaining high OCR accuracy, are somewhat of a mystery to many new OCR practitioners. They don’t know what they are, how to use them, why they are important — many don’t even know where to find the various page segmentation modes!
To list out the 14 PSMs in Tesseract, just supply the --help-psm argument to the tesseract binary:
$ tesseract --help-psm
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
You can then apply a given PSM by supplying the corresponding integer value for the --psm argument.
For example, suppose we have an input image named input.png and we want to use PSM 7, which is used to OCR a single line of text. Our call to tesseract would thus look like this:
$ tesseract input.png stdout --psm 7
In the rest of this tutorial, we’ll review each of the 14 Tesseract PSMs. You’ll gain hands-on experience using each of them and will come out of this tutorial feeling much more confident in your ability to correctly OCR an image using the Tesseract OCR engine.
Project Structure
Unlike most tutorials, which include one or more Python scripts to review, this tutorial is one of the very few that does not utilize Python. Instead, we’ll be using the tesseract binary to explore each of the page segmentation modes.
Keep in mind that this tutorial aims to understand the PSMs and gain first-hand experience working with them. Once you have a strong understanding of them, that knowledge directly transfers over to Python. To set a PSM in Python, it’s as easy as setting an options variable — it couldn’t be easier, quite literally taking only a couple of keystrokes!
Therefore, we’re going to first start with the tesseract binary first.
With that said, let’s take a look at our project directory structure:
|-- psm-0 | |-- han_script.jpg | |-- normal.png | |-- rotated_90.png |-- psm-1 | |-- example.png |-- psm-3 | |-- example.png |-- psm-4 | |-- receipt.png |-- psm-5 | |-- receipt_rotated.png |-- psm-6 | |-- sherlock_holmes.png |-- psm-7 | |-- license_plate.png |-- psm-8 | |-- designer.png |-- psm-9 | |-- circle.png | |-- circular.png |-- psm-10 | |-- number.png |-- psm-11 | |-- website_menu.png |-- psm-13 | |-- the_old_engine.png
As you can see, we have 13 directories, each with an example image inside that will highlight when to use that particular PSM.
But wait … didn’t earlier in the tutorial I say that Tesseract has 14, not 13, page segmentation modes? If so, why are there not 14 directories?
The answer is simple — one of the PSMs is not implemented in Tesseract. It’s essentially just a placeholder for future potential implementation.
Let’s get started exploring page segmentation modes with Tesseract!
PSM 0. Orientation and Script Detection Only
The --psm 0 mode does not perform OCR, at least in terms of how we think of it in the context of this book. When we think of OCR, we think of a piece of software that is able to localize the characters in an input image, recognize them, and then convert them to a machine-encoded string.
Orientation and script detection (OSD) examines the input image, but instead of returning the actual OCR’d text, OSD returns two values:
- How the page is oriented, in degrees, where
angle = {0, 90, 180, 270} - The confidence of the script (i.e., graphics signs/writing system), such as Latin, Han, Cyrillic, etc.
OSD is best seen with an example. Take a look at Figure 1, where we have three example images. The first one is a paragraph of text from my first book, Practical Python and OpenCV. The second is the same paragraph of text, this time rotated 90◦ clockwise, and the final image contains Han script.

Let’s start by applying tesseract to the normal.png image which is shown top-left in Figure 1:
$ tesseract normal.png stdout --psm 0 Page number: 0 Orientation in degrees: 0 Rotate: 0 Orientation confidence: 11.34 Script: Latin Script confidence: 8.10
Here, we can see that Tesseract has determined that this input image is unrotated (i.e., 0◦) and that the script is correctly detected as Latin.
Let’s now take that same image and rotate it 90◦ which is shown in Figure 1 (top-right):
$ tesseract rotated_90.png stdout --psm 0 Page number: 0 Orientation in degrees: 90 Rotate: 270 Orientation confidence: 5.49 Script: Latin Script confidence: 4.76
Tesseract has determined that the input image has been rotated 90◦, and in order to correct the image, we need to rotate it 270◦. Again, the script is correctly detected as Latin.
For a final example, we’ll now apply Tesseract OSD to the Han script image (Figure 1, bottom):
$ tesseract han_script.jpg stdout --psm 0 Page number: 0 Orientation in degrees: 0 Rotate: 0 Orientation confidence: 2.94 Script: Han Script confidence: 1.43
Notice how the script has been labeled correctly as Han.
You can think of the --psm 0 mode as a “meta information” mode where Tesseract provides you with just the script and rotation of the input image — when applying this mode, Tesseract does not OCR the actual text and return it for you.
If you need just the meta information on the text, using --psm 0 is the right mode for you; however, many times we need the OCR’d text itself, in which case you should use the other PSMs covered in this tutorial.
PSM 1. Automatic Page Segmentation with OSD
Tesseract’s documentation and examples on --psm 1 is not complete so it made it hard to provide detailed research and examples on this method. My understanding of --psm 1 is that:
- Automatic page segmentation for OCR should be performed
- And that OSD information should be inferred and utilized in the OCR process
However, if we take the images in Figure 1 and pass them through tesseract using this mode, you can see that there is no OSD information:
$ tesseract example.png stdout --psm 1 Our last argument is how we want to approximate the contour. We use cv2.CHAIN_APPROX_SIMPLE to compress horizontal, vertical, and diagonal segments into their end- points only. This saves both computation and memory. If we wanted all the points along the contour, without com- pression, we can pass in cv2. CHAIN_APPROX_NONE; however, be very sparing when using this function. Retrieving all points along a contour is often unnecessary and is wasteful of resources.
This result makes me think that Tesseract must be performing OSD internally but not returning it to the user. Based on my experimentation and experiences with --psm 1, I think it may be that --psm 2 is not fully working/implemented.
Simply put: in all my experiments, I could not find a situation where --psm 1 obtained a result that the other PSMs could not. If I find such a situation in the future, I will update this section and provide a concrete example. But until then, I don’t think it’s worth applying --psm 1 in your projects.
PSM 2. Automatic Page Segmentation, But No OSD, or OCR
The --psm 2 mode is not implemented in Tesseract. You can verify this by running the tesseract --help-psm command looking at the output for mode two:
$ tesseract --help-psm Page segmentation modes: ... 2 Automatic page segmentation, but no OSD, or OCR. (not implemented) ...
It is unclear if or when Tesseract will implement this mode, but for the time being, you can safely ignore it.
PSM 3. Fully Automatic Page Segmentation, But No OSD
PSM 3 is the default behavior of Tesseract. If you run the tesseract binary without explicitly supplying a --psm, then a --psm 3 will be used.
Inside this mode, Tesseract will:
- Automatically attempt to segment the text, treating it as a proper “page” of text with multiple words, multiple lines, multiple paragraphs, etc.
- After segmentation, Tesseract will OCR the text and return it to you
However, it’s important to note that Tesseract will not perform any orientation/script detection. To gather that information, you will need to run tesseract twice:
- Once with the
--psm 0mode to gather OSD information - And then again with
--psm 3to OCR the actual text
The following example shows how to take a paragraph of text and apply both OSD and OCR in two separate commands:
$ tesseract example.png stdout --psm 0 Page number: 0 Orientation in degrees: 0 Rotate: 0 Orientation confidence: 11.34 Script: Latin Script confidence: 8.10 $ tesseract example.png stdout --psm 3 Our last argument is how we want to approximate the contour. We use cv2.CHAIN_APPROX_SIMPLE to compress horizontal, vertical, and diagonal segments into their end- points only. This saves both computation and memory. If we wanted all the points along the contour, without com- pression, we can pass in cv2. CHAIN_APPROX_NONE; however, be very sparing when using this function. Retrieving all points along a contour is often unnecessary and is wasteful of resources.
Again, you can skip the first command if you only want the OCR’d text.
PSM 4. Assume a Single Column of Text of Variable Sizes
A good example of using --psm 4 is when you need to OCR column data and require text to be concatenated row-wise (e.g., the data you would find in a spreadsheet, table, or receipt).
For example, consider Figure 2, which is a receipt from the grocery store. Let’s try to OCR this image using the default (--psm 3) mode:

$ tesseract receipt.png stdout ee OLE YOSDS: cea eam WHOLE FOODS MARKET - WESTPORT,CT 06880 399 POST RD WEST - (203) 227-6858 365 365 365 365 BACON LS BACON LS BACON LS BACON LS BROTH CHIC FLOUR ALMOND CHKN BRST BNLSS SK HEAVY CREAM BALSMC REDUCT BEEF GRND 85/15 JUICE COF CASHEW C DOCS PINT ORGANIC HNY ALMOND BUTTER wee TAX .00 BAL NP 4.99 NP 4.99 NP 4.99 NP 4.99 NP 2.19 NP 91.99 NP 18.80 NP 3.39 NP. 6.49 NP 5.04 ne £8.99 np £14.49 NP 9.99 101.33 aaa AAAATAT ie
That didn’t work out so well. Using the default --psm 3 mode, Tesseract cannot infer that we are looking at column data and that text along the same row should be associated together.
To remedy that problem, we can use the --psm 4 mode:
$ tesseract receipt.png stdout --psm 4 WHOLE FOODS. cea eam WHOLE FOODS MARKET - WESTPORT,CT 06880 399 POST RD WEST - (203) 227-6858 365 BACONLS NP 4.99 365 BACON LS NP 4.99 365 BACONLS NP 4.99 365 BACONLS NP 4,99 BROTH CHIC NP 2.19 FLOUR ALMOND NP 91.99 CHKN BRST BNLSS SK NP 18.80 HEAVY CREAM NP 3.39 BALSMC REDUCT NP 6.49 BEEF GRND 85/15 NP 6.04 JUICE COF CASHEW C NP £8.99 DOCS PINT ORGANIC NP 14,49 HNY ALMOND BUTTER NP 9,99 wee TAX = 00 BAL 101.33
As you can see, the results here are far better. Tesseract is able to understand that text should be grouped row-wise, thereby allowing us to OCR the items in the receipt.
PSM 5. Assume a Single Uniform Block of Vertically Aligned Text
The documentation surrounding --psm 5 is a bit confusing as it states that we wish to OCR a single block of vertically aligned text. The problem is there is a bit of ambiguity as to what “vertically aligned text” actually means (as there is no Tesseract example showing an example of vertically aligned text).
To me, vertically aligned text is either placed at the top of the page, center of the page, bottom of the page. In Figure 3, an example of text that is top-aligned (left), middle-aligned (center), and bottom-aligned (right).

However, in my own experimentation, I found that --psm 5 works similar to --psm 4, only for rotated images. Consider Figure 4, where we have a receipt rotated 90◦ clockwise to see such an example in action.

Let’s first apply the default --psm 3:
$ tesseract receipt_rotated.png stdout WHOLE FOODS. (mM AR K E T) WHOLE FOODS MARKET - WESTPORT,CT 06880 399 POST RD WEST - (203) 227-6858 365 BACON LS 365 BACON LS 365 BACON LS 365 BACON LS BROTH CHIC FLOUR ALMOND CHKN BRST BNLSS SK HEAVY CREAM BALSMC REDUCT BEEF GRND 85/15 JUICE COF CASHEW C DOCS PINT ORGANIC HNY ALMOND BUTTER eee TAX =.00 BAL ee NP 4.99 NP 4.99 NP 4,99 NP 4.99 NP 2.19 NP 1.99 NP 18.80 NP 3.39 NP 6.49 NP 8.04 NP £8.99 np "14.49 NP 9.99 101.33 aAnMAIATAAT AAA ATAT ie
Again, our results are not good here. While Tesseract can correct for rotation, we don’t have our row-wise elements of the receipt.
To resolve the problem, we can use --psm 5:
$ tesseract receipt_rotated.png stdout --psm 5
Cea a amD
WHOLE FOODS MARKET - WESTPORT, CT 06880
399 POST RD WEST - (203) 227-6858
* 365 BACONLS NP 4.99 F
* 365 BACON LS NP 4.99 F
* 365 BACONLS NP 4,99 F*
* 365 BACONLS NP 4.99 F
* BROTH CHIC NP 2.19 F
* FLOUR ALMOND NP 1.99 F
* CHKN BRST BNLSS SK NP 18.80 F
* HEAVY CREAM NP 3.39 F
* BALSMC REDUCT NP 6.49 F
* BEEF GRND 85/1§ NP {6.04 F
* JUICE COF CASHEW C NP [2.99 F
*, DOCS PINT ORGANIC NP "14.49 F
* HNY ALMOND BUTTER NP 9,99
wee TAX = 00 BAL 101.33
Our OCR results are now far better on the rotated receipt image.
PSM 6. Assume a Single Uniform Block of Text
I like to use --psm 6 for OCR’ing pages of simple books (e.g., a paperback novel). Pages in books tend to use a single, consistent font throughout the entirety of the book. Similarly, these books follow a simplistic page structure, which is easy for Tesseract to parse and understand.
The keyword here is uniform text, meaning that the text is a single font face without any variation.
Below shows the results of applying Tesseract to a single uniform block of text from a Sherlock Holmes novel (Figure 5) with the default --psm 3 mode:
$ tesseract sherlock_holmes.png stdout CHAPTER ONE we Mr. Sherlock Holmes M: Sherlock Holmes, who was usually very late in the morn- ings, save upon those not infrequent occasions when he was up all night, was seated at the breakfast table. I stood upon the hearth-rug and picked up the stick which our visitor had left behind him the night before. It was a fine, thick piece of wood, bulbous-headed, of the sort which is known as a “Penang lawyer.” Just under the head was a broad silver band nearly an inch across. “To James Mortimer, M.R.C.S., from his friends of the C.C.H.,” was engraved upon it, with the date “1884.” It was just such a stick as the old-fashioned family practitioner used to carry--dig- nified, solid, and reassuring. “Well, Watson, what do you make of it2” Holmes w: sitting with his back to me, and I had given him no sign of my occupation. “How did you know what I was doing? I believe you have eyes in the back of your head.” “L have, at least, a well-polished, silver-plated coffee-pot in front of me,” said he. “But, tell me, Watson, what do you make of our visitor's stick? Since we have been so unfortunate as to miss him and have no notion of his errand, this accidental souvenir be- comes of importance, Let me hear you reconstruct the man by an examination of it.”

To save space, I removed many of the newlines from the above output. If you run the above command in your own system you will see that the output is far messier than what it appears in the text.
By using the --psm 6 mode, we are better able to OCR this big block of text:
$ tesseract sherlock_holmes.png stdout --psm 6 CHAPTER ONE SS Mr. Sherlock Holmes M Sherlock Holmes, who was usually very late in the morn ings, save upon those not infrequent occasions when he was up all night, was seated at the breakfast table. I stood upon the hearth-rug and picked up the stick which our visitor had left behind him the night before. It was a fine, thick piece of wood, bulbous-headed, of the sort which is known as a “Penang lawyer.” Just under the head was a broad silver band nearly an inch across. “To James Mortimer, M.R.C.S., from his friends of the C.C.H.,” was engraved upon it, with the date “1884.” It was just such a stick as the old-fashioned family practitioner used to carry--dig- nified, solid, and reassuring. “Well, Watson, what do you make of it2” Holmes was sitting with his back to me, and I had given him no sign of my occupation. “How did you know what I was doing? I believe you have eyes in the back of your head.” “T have, at least, a well-polished, silver-plated coflee-pot in front of me,” said he. “But, tell me, Watson, what do you make of our visitor’s stick? Since we have been so unfortunate as to miss him and have no notion of his errand, this accidental souvenir be- comes of importance. Let me hear you reconstruct the man by an examination of it.” 6
There are far less mistakes in this output, thus demonstrating how --psm 6 can be used for OCR’ing uniform blocks of text.
PSM 7. Treat the Image as a Single Text Line
The --psm 7 mode should be utilized when you are working with a single line of uniform text. For example, let’s suppose we are building an automatic license/number plate recognition (ANPR) system and need to OCR the license plate in Figure 6.

Let’s start by using the default --psm 3 mode:
$ tesseract license_plate.png stdout Estimating resolution as 288 Empty page!! Estimating resolution as 288 Empty page!!
The default Tesseract mode balks, totally unable to OCR the license plate.
However, if we use --psm 7 and tell Tesseract to treat the input as a single line of uniform text, we are able to obtain the correct result:
$ tesseract license_plate.png stdout --psm 7 MHOZDW8351
PSM 8. Treat the Image as a Single Word
If you have a single word of uniform text, you should consider using --psm 8. A typical use case would be:
- Applying text detection to an image
- Looping over all text ROIs
- Extracting them
- Passing each individual text ROI through Tesseract for OCR
For example, let’s consider Figure 7, which is a photo of a storefront. We can try to OCR this image using the default --psm 3 mode:

$ tesseract designer.png stdout MS atts
But unfortunately, all we get is gibberish out.
To resolve the issue, we can use --psm 8, telling Tesseract to bypass any page segmentation methods and instead just treat this image as a single word:
$ tesseract designer.png stdout --psm 8 Designer
Sure enough, --psm 8 is able to resolve the issue!
Furthermore, you may find situations where --psm 7 and --psm 8 can be used interchangeably — both will function similarly as we are either looking at a single line or a single word, respectively.
PSM 9. Treat the Image as a Single Word in a Circle
I’ve played around with the --psm 9 mode for hours, and truly, I cannot figure out what it does. I’ve searched Google and read the Tesseract documentation, but come up empty handed — I cannot find a single concrete example on what the circular PSM is intended to do.
To me, there are two ways to interpret this parameter (Figure 8):
- The text is actually inside the circle (left)
- The text is wrapped around an invisible circular/arc region (right)

The second option seems much more likely to me, but I could not make this parameter work no matter how much I tried. I think it’s safe to assume that this parameter is rarely, if ever, used — and furthermore, the implementation may be a bit buggy. I suggest avoiding this PSM if you can.
PSM 10. Treat the Image as a Single Character
Treating an image as a single character should be done when you have already extracted each individual character from the image.
Going back to our ANPR example, let’s say you’ve located the license plate in an input image and then extracted each individual character on the license plate — you can then pass each of these characters through Tesseract with --psm 10 to OCR them.
Figure 9 shows an example of the digit 2. Let’s try to OCR it with the default --psm 3:
$ tesseract number.png stdout Estimating resolution as 1388 Empty page!! Estimating resolution as 1388 Empty page!!
Tesseract attempts to apply automatic page segmentation methods, but due to the fact that there is no actual “page” of text, the default --psm 3 fails and returns an empty string.
We can resolve the matter by treating the input image as a single character via --psm 10:
$ tesseract number.png stdout --psm 10 2
Sure enough, --psm 10 resolves the matter!
PSM 11. Sparse Text: Find as Much Text as Possible in No Particular Order
Detecting sparse text can be useful when there is lots of text in an image you need to extract. When using this mode, you typically don’t care about the order/grouping of text, but rather the text itself.
This information is useful if you’re performing Information Retrieval (i.e., text search engine) by OCR’ing all the text you can find in a dataset of images, and then building a text-based search engine via Information Retrieval algorithms (tf-idf, inverted indexes, etc.).
Figure 10 shows an example of sparse text. Here, we have a screenshot from my “Get Started” page on PyImageSearch. This page provides tutorials grouped by popular computer vision, deep learning, and OpenCV topics.
Let’s try to OCR this list of topics using the default --psm 3:
$ tesseract website_menu.png stdout How Do | Get Started? Deep Learning Face Applications Optical Character Recognition (OCR) Object Detection Object Tracking Instance Segmentation and Semantic Segmentation Embedded and lol Computer Vision Computer Vision on the Raspberry Pi Medical Computer Vision Working with Video Image Search Engines Interviews, Case Studies, and Success Stories My Books and Courses
While Tesseract can OCR the text, there are several incorrect line groupings and additional whitespace. The additional whitespace and newlines are a result of how Tesseract’s automatic page segmentation algorithm works — here it’s trying to infer document structure when in fact there is no document structure.
To get around this issue, we can treat the input image as sparse text with --psm 11:
$ tesseract website_menu.png stdout --psm 11 How Do | Get Started? Deep Learning Face Applications Optical Character Recognition (OCR) Object Detection Object Tracking Instance Segmentation and Semantic Segmentation Embedded and lol Computer Vision Computer Vision on the Raspberry Pi Medical Computer Vision Working with Video Image Search Engines Interviews, Case Studies, and Success Stories My Books and Courses
This time the results from Tesseract are far better.
PSM 12. Sparse Text with OSD
The --psm 12 mode is essentially identical to --psm 11, but now adds in OSD (similar to --psm 0).
That said, I had a lot of problems getting this mode to work properly and could not find a practical example where the results meaningfully differed from --psm 11.
I feel it’s necessary to say that --psm 12 exists; however, in practice, you should use a combination of --psm 0 (for OSD) followed by --psm 11 (for OCR’ing sparse text) if you want to replicate the intended behavior of --psm 12.
PSM 13. Raw Line: Treat the Image as a Single Text Line, Bypassing Hacks That Are Tesseract-Specific
There are times that OSD, segmentation, and other internal Tesseract-specific preprocessing techniques will hurt OCR performance, either by:
- Reducing accuracy
- No text being detected at all
Typically this will happen if a piece of text is closely cropped, the text is computer generated/stylized in some manner, or it’s a font face Tesseract may not automatically recognize. When this happens, consider applying --psm 13 as a “last resort.”
To see this method in action, consider Figure 11 which has the text “The Old Engine” typed in a stylized font face, similar to that of an old-time newspaper.
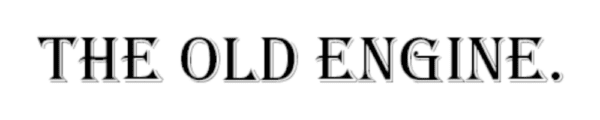
Let’s try to OCR this image using the default --psm 3:
$ tesseract the_old_engine.png stdout Warning. Invalid resolution 0 dpi. Using 70 instead. Estimating resolution as 491 Estimating resolution as 491
Tesseract fails to OCR the image, returning an empty string.
Let’s now use --psm 13, bypassing all page segmentation algorithms and Tesseract preprocessing functions, thereby treating the image as a single raw line of text:
$ tesseract the_old_engine.png stdout --psm 13 Warning. Invalid resolution 0 dpi. Using 70 instead. THE OLD ENGINE.
This time we are able to correctly OCR the text with --psm 13!
Using --psm 13 can be a bit of a hack at times so try exhausting other page segmentation modes first.
Tips, Suggestions, and Best Practices for PSMs
Getting used to page segmentation modes in Tesseract takes practice — there is no other way around that. I strongly suggest that you:
- Read this tutorial multiple times
- Run the examples included in the text for this tutorial
- And then start practicing with your own images
Tesseract, unfortunately, doesn’t include much documentation on their PSMs, nor are there specific concrete examples that are easily referred to. This tutorial serves as my best attempt to provide you with as much information on PSMs as I can, including practical, real-world examples of when you would want to use each PSM.
That said, here are some tips and recommendations to help you get up and running with PSMs quickly:
- Always start with the default
--psm 3to see what Tesseract spits out. In the best-case scenario, the OCR results are accurate, and you’re done. In the worst case, you now have a baseline to beat. - While I’ve mentioned that
--psm 13is a “last resort” type of mode, I would recommend applying it second as well. This mode works surprisingly well, especially if you’ve already preprocessed your image and binarized your text. If--psm 13works you can either stop or instead focus your efforts on modes 4-8 as it’s likely one of them will work in place of 13. - Next, applying
--psm 0to verify that the rotation and script are being properly detected. If they aren’t, it’s unreasonable to expect Tesseract to perform well on an image where it cannot properly detect the rotation angle and script/writing system. - Provided the script and angle are being detected properly, you need to follow the guidelines in this tutorial. Specifically, you should focus on PSMs 4-8, 10, and 11. Avoid PSMs 1, 2, 9, and 12 unless you think there is a specific use case for them.
- Finally, you may want to consider brute-forcing it. Try each of the modes sequentially 1-13. This is a “throw spaghetti at the wall and see what sticks” type of hack, but you get lucky every now and then.
If you find that Tesseract isn’t giving you the accuracy you want regardless of what page segmentation mode you’re using, don’t panic or get frustrated — it’s all part of the process. OCR is part art, part science. Leonardo da Vinci wasn’t painting the Mona Lisa right out of the gate. It was an acquired skill that took practice.
We’re just scratching the surface of what’s possible with OCR. Future tutorials will take a deeper dive and help you to better hone this art. With practice, like Figure 12 shows, you too will be hitting bullseyes with your OCR project.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned about Tesseract’s 14 page segmentation modes (PSMs). Applying the correct PSM is absolutely critical for correctly OCR’ing an input image.
Simply put, your choice in PSM can mean the difference between an image accurately OCR’d versus getting either no result or a nonsensical result back from Tesseract.
Each of the 14 PSMs inside of Tesseract makes an assumption on your input image, such as a block of text (e.g., a scanned chapter), a single line of text (perhaps a single sentence from a chapter), or even a single word (e.g., a license/number plate).
The key to obtaining accurate OCR results is to:
- Use OpenCV (or your image processing library of your choice) to clean up your input image, remove noise, and potentially segment text from the background
- Apply Tesseract, taking care to use the correct PSM that corresponds to your output from any preprocessing
For example, if you are building an automatic license plate recognizer (which we’ll do in a future tutorial), then we would utilize OpenCV to first detect the license plate in the image. This can be accomplished using either image processing techniques or a dedicated object detector such as HOG + Linear SVM, Faster R-CNN, SSD, YOLO, etc.
Once we have the license plate detected, we would segment the characters from the plate, such that the characters appear as white (foreground) against a black background.
The final step would be to take the binarized license plate characters and pass them through Tesseract for OCR. Our choice in PSM will be the difference between correct and incorrect results.
Since a license plate can be seen as either a “single line of text” or a “single word,” we would want to try --psm 7 or --psm 8. A --psm 13 may also work as well, but using the default (--psm 3) is unlikely to work here since we’ve already processed our image quality heavily.
I would highly suggest that you spend a fair amount of time exploring all the examples in this tutorial, and even going back and reading it again — there’s so much knowledge to be gained from Tesseract’s page segmentation modes.
From there, start applying the various PSMs to your own images. Note your results along the way:
- Are they what you expected?
- Did you obtain the correct result?
- Did Tesseract fail to OCR the image, returning an empty string?
- Did Tesseract return completely nonsensical results?
The more practice you have with PSMs, the more experience you gain, which will make it that much easier for you to correctly apply OCR to your own projects.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.