
In this tutorial, you will learn how to detect and remove duplicate images from a dataset for deep learning.
Over the past few weeks, I’ve been working on a project with Victor Gevers, the esteemed ethical hacker from the GDI.Foundation, an organization that is famous for responsibly disclosing data leaks and reporting security vulnerabilities.
I can’t go into details of the project (yet), but one of the tasks required me to train a custom deep neural network to detect specific patterns in images.
The dataset I was using was crafted by combining images from multiple sources. I knew there were going to be duplicate images in the dataset — I therefore needed a method to detect and remove these duplicate images from my dataset.
As I was working on the project, I just so happened to receive an email from Dahlia, a university student who also had a question on image duplicates and how to handle them:
Hi Adrian, my name is Dahlia. I’m an undergraduate working on my final year graduation project and have been tasked with building an image dataset by scraping Google Images, Bing, etc. and then training a deep neural network on the dataset.
My professor told me to be careful when building the dataset, stating that I needed to remove duplicate images.
That caused me some doubts:
Why are duplicate images in a dataset a problem? Secondly, how do I detect the image duplicates?
Trying to do so manually sounds like an error-prone process. I don’t want to make any mistakes.
Is there a way that I can automatically detect and remove the duplicates from my image dataset?
Thank you.
Dahlia asks some great questions.
Having duplicate images in your dataset creates a problem for two reasons:
- It introduces bias into your dataset, giving your deep neural network additional opportunities to learn patterns specific to the duplicates
- It hurts the ability of your model to generalize to new images outside of what it was trained on
While we often assume that data points in a dataset are independent and identically distributed, that’s rarely (if ever) the case when working with a real-world dataset. When training a Convolutional Neural Network, we typically want to remove those duplicate images before training the model.
Secondly, trying to manually detect duplicate images in a dataset is extremely time-consuming and error-prone — it also doesn’t scale to large image datasets. We therefore need a method to automatically detect and remove duplicate images from our deep learning dataset.
Is such a method possible?
It certainly is — and I’ll be covering it in the remainder of today’s tutorial.
To learn how to detect and remove duplicate images from your deep learning dataset, just keep reading!
Detect and remove duplicate images from a dataset for deep learning
In the first part of this tutorial, you’ll learn why detecting and removing duplicate images from your dataset is typically a requirement before you attempt to train a deep neural network on top of your data.
From there, we’ll review the example dataset I created so we can practice detecting duplicate images in a dataset.
We’ll then implement our image duplicate detector using a method called image hashing.
Finally, we’ll review the results of our work and:
- Perform a dry run to validate that our image duplicate detector is working properly
- Run our duplicate detector a second time, this time removing the actual duplicates from our dataset
Why bother removing duplicate images from a dataset when training a deep neural network?
If you’ve ever attempted to build your own image dataset by hand, you know it’s a likely possibility (if not an inevitability) that you’ll have duplicate images in your dataset.
Typically, you end up with duplicate images in your dataset by:
- Scraping images from multiple sources (e.g., Google, Bing, etc.)
- Combining existing datasets (ex., combining ImageNet with Sun397 and Indoor Scenes)
When this happens you need a way to:
- Detect that there are duplicate images in your dataset
- Remove the duplicates
But that raises the question — why bother caring about duplicates in the first place?
The usual assumption for supervised machine learning methods is that:
- Data points are independent
- They are identically distributed
- Training and testing data are sampled from the same distribution
The problem is that these assumptions rarely (if ever) hold in practice.
What you really need to be afraid of is your model’s ability to generalize.
If you include multiple identical images in your dataset, your neural network is allowed to see and learn patterns from that image multiple times per epoch.
Your network could become biased toward patterns in those duplicate images, making it less likely to generalize to new images.
Bias and ability to generalize are a big deal in machine learning — they can be hard enough to combat when working with an “ideal” dataset.
Take the time to remove duplicates from your image dataset so you don’t accidentally introduce bias or hurt the ability of your model to generalize.
Our example duplicate-images dataset

To help us learn how to detect and remove duplicate images from a deep learning dataset, I created a “practice” dataset we can use based on the Stanford Dogs Dataset.
This dataset consists of 20,580 images of dog breeds, including Beagles, Newfoundlands, and Pomeranians, just to name a few.
To create our duplicate image dataset, I:
- Downloaded the Stanford Dogs Dataset
- Sampled three images that I would duplicate
- Duplicated each of these three images a total of N times
- Then randomly sampled the Stanford Dogs Dataset further until I obtained 1,000 total images
The following figure shows the number of duplicates per image:

Our goal is to create a Python script that can detect and remove these duplicates prior to training a deep learning model.
Project structure
I’ve included the duplicate image dataset along with the code in the “Downloads” section of this tutorial.
Once you extract the .zip, you’ll be presented with the following directory structure:
$ tree --dirsfirst --filelimit 10 . ├── dataset [1000 entries] └── detect_and_remove.py 1 directory, 1 file
As you can see, our project structure is quite simple. We have a dataset/ of 1,000 images (duplicates included). Additionally, we have our detect_and_remove.py Python script, which is the basis of today’s tutorial.
Implementing our image duplicate detector
We are now ready to implement our image duplicate detector.
Open up the detect_and_remove.py script in your project directory, and let’s get to work:
# import the necessary packages from imutils import paths import numpy as np import argparse import cv2 import os
Imports for our script include my paths implementation from imutils so we can grab the filepaths to all images in our dataset, NumPy for image stacking, and OpenCV for image I/O, manipulation, and display. Both os and argparse are built-in to Python.
If you do not have OpenCV or imutils installed on your machine, I recommend following my pip install opencv guide which will show you how to install both.
The primary component of this tutorial is the dhash function:
def dhash(image, hashSize=8): # convert the image to grayscale and resize the grayscale image, # adding a single column (width) so we can compute the horizontal # gradient gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) resized = cv2.resize(gray, (hashSize + 1, hashSize)) # compute the (relative) horizontal gradient between adjacent # column pixels diff = resized[:, 1:] > resized[:, :-1] # convert the difference image to a hash and return it return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
As described earlier, we will apply our hashing function to every image in our dataset. The dhash function handles this calculation to create a numerical representation of the image.
When two images have the same hash, they are considered duplicates. With additional logic, we’ll be able to delete duplicates and achieve the objective of this project.
The function accepts an image and hashSize and proceeds to:
- Convert the image to a single-channel grayscale image (Line 12)
- Resize the image according to the
hashSize(Line 13). The algorithm requires that the width of the image have exactly1more column than the height as is evident by the dimension tuple. - Compute the relative horizontal gradient between adjacent column pixels (Line 17). This is now known as the “difference image.”
- Apply our hashing calculation and return the result (Line 20).
I’ve covered image hashing in these previous articles. In particular, you should read my Image hashing with OpenCV and Python guide to understand the concept of image hashing using my dhash function.
With our hashing function defined, we’re now ready to define and parse command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-r", "--remove", type=int, default=-1,
help="whether or not duplicates should be removed (i.e., dry run)")
args = vars(ap.parse_args())
Our script handles two command line arguments, which you can pass via your terminal or command prompt:
--dataset: The path to your input dataset, which contains duplicates that you’d like to prune out of the dataset--remove
We’re now ready to begin computing hashes:
# grab the paths to all images in our input dataset directory and
# then initialize our hashes dictionary
print("[INFO] computing image hashes...")
imagePaths = list(paths.list_images(args["dataset"]))
hashes = {}
# loop over our image paths
for imagePath in imagePaths:
# load the input image and compute the hash
image = cv2.imread(imagePath)
h = dhash(image)
# grab all image paths with that hash, add the current image
# path to it, and store the list back in the hashes dictionary
p = hashes.get(h, [])
p.append(imagePath)
hashes[h] = p
First, we grab all imagePaths in our dataset and initialize an empty Python dictionary to hold our hashes (Lines 33 and 34).
Then, looping over imagePaths, we:
- Load an image (Line 39)
- Compute the hash,
h, using thedhashconvenience function (Line 40) - Grab all image paths,
p, with the same hash,h(Line 44). - Append the latest
imagePathtop(Line 45). At this point,prepresents our set of duplicate images (i.e., images with the same hash value) - Add all of these duplicates to our
hashesdictionary (Line 46)
At the end of this process, our hashes dictionary maps a given hash to a list of all image paths that have that hash.
A few entries in the dictionary may look like this:
{
...
7054210665732718398: ['dataset/00000005.jpg', 'dataset/00000071.jpg', 'dataset/00000869.jpg'],
8687501631902372966: ['dataset/00000011.jpg'],
1321903443018050217: ['dataset/00000777.jpg'],
...
}
Notice how the first hash key example has three associated image paths (indicating duplicates) and the next two hash keys have only one path entry (indicating no duplicates).
At this point, with all of our hashes computed, we need to loop over the hashes and handle the duplicates:
# loop over the image hashes
for (h, hashedPaths) in hashes.items():
# check to see if there is more than one image with the same hash
if len(hashedPaths) > 1:
# check to see if this is a dry run
if args["remove"] <= 0:
# initialize a montage to store all images with the same
# hash
montage = None
# loop over all image paths with the same hash
for p in hashedPaths:
# load the input image and resize it to a fixed width
# and heightG
image = cv2.imread(p)
image = cv2.resize(image, (150, 150))
# if our montage is None, initialize it
if montage is None:
montage = image
# otherwise, horizontally stack the images
else:
montage = np.hstack([montage, image])
# show the montage for the hash
print("[INFO] hash: {}".format(h))
cv2.imshow("Montage", montage)
cv2.waitKey(0)
Line 49 begins a loop over the hashes dictionary.
Inside, first we check to see if there is more than one hashedPaths (image paths) with that computed hash (Line 51), thereby implying there is a duplicate.
If not, we ignore the hash and continue to check the next hash.
On the other hand, if there are, in fact, two or more hashedPaths, they are duplicates!
Therefore, we start an if/ else block to check whether this is a “dry run” or not; if the --remove flag is not a positive value, we are conducting a dry run (Line 53).
A dry run means that we aren’t ready to delete duplicates yet. Rather, we just want to check to see if any duplicates are present.
In the case of a dry run, we loop over all of the duplicate images and generate a montage so we can visualize the duplicate images (Lines 56-76). Each time a set of duplicates is displayed on screen, you can press any key to see the next set of duplicates. If you’re new to montages, check out my Montages with OpenCV tutorial.
Now let’s handle the non-dry run case — when --remove is a positive value:
# otherwise, we'll be removing the duplicate images else: # loop over all image paths with the same hash *except* # for the first image in the list (since we want to keep # one, and only one, of the duplicate images) for p in hashedPaths[1:]: os.remove(p)
In this case, we are actually deleting the duplicate images from our system.
In this scenario, we simply loop over all image paths with the same hash except for the first image in the list — we want to keep one, and only one, of the example images and delete all other identical images.
Great job implementing your very own duplicate image detection and removal system.
Running our image duplicate detector for our deep learning dataset
Let’s put our image duplicate detector to work.
Start by making sure you have used the “Downloads” section of this tutorial to download the source code and example dataset.
From there, open up a terminal, and execute the following command just to verify there are 1,000 images in our dataset/ directory:
$ ls -l dataset/*.jpg | wc -l
1000
Let’s now perform a dry run, which will allow us to visualize the duplicates in our dataset:
$ python detect_and_remove.py --dataset dataset [INFO] computing image hashes... [INFO] hash: 7054210665732718398 [INFO] hash: 15443501585133582635 [INFO] hash: 13344784005636363614
The following figure shows the output of our script, demonstrating that we have been able to successfully find the duplicates as detailed in “Our example duplicate image dataset” section above.
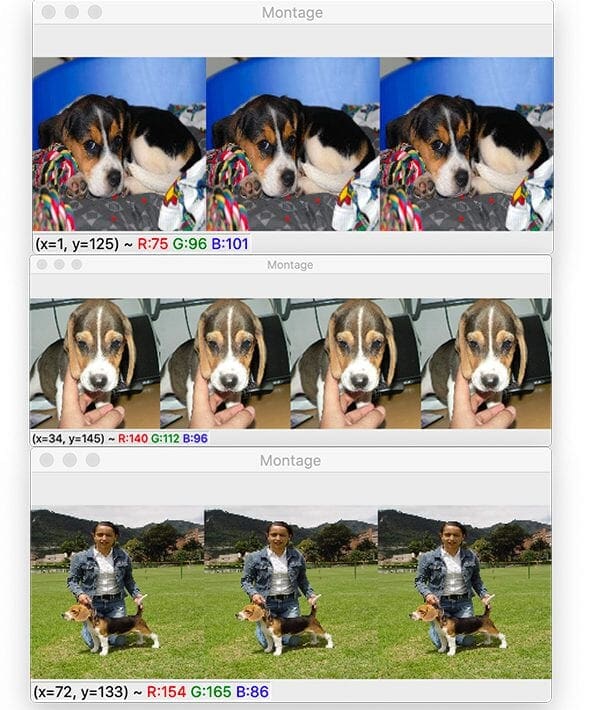
To actually remove the duplicates from our system, we need to execute detect_and_remove.py again, this time supplying the --remove 1 command line argument:
$ python detect_and_remove.py --dataset dataset --remove 1 [INFO] computing image hashes...
We can verify that the duplicates have been removed by counting the number of JPEG Images in the dataset directory:
$ ls -l dataset/*.jpg | wc -l
993
Originally, there were 1,000 images in dataset, but now there are 993, implying that we removed the 7 duplicate images.
At this point, you could proceed to train a deep neural network on this dataset.
How do I create my own image dataset?
I’ve created a sample dataset for today’s tutorial — it is included with the “Downloads” so that you can begin learning the concept of deduplication immediately.
However, you may be wondering:
“How do I create a dataset in the first place?”
There isn’t a “one size fits all” approach for creating a dataset. Rather, you need to consider the problem and design your data collection around it.
You may determine that you need automation and a camera to collect data. Or you may determine that you need to combine existing datasets to save a lot of time.
Let’s first consider datasets for the purpose of face applications. If you’d like to create a custom face dataset, you can use any of three methods:
- Enrolling faces via OpenCV and a webcam
- Downloading face images programmatically
- Manually collecting face images
From there, you can apply face applications, including facial recognition, facial landmarks, etc.
But what if you want to harness the power of the internet and an existing search engine or scraping tool? Is there hope?
In fact there is. I have written three tutorials to help you get started.
- How to create a deep learning dataset using Google Images
- How to (quickly) build a deep learning image dataset (using Bing)
- Scraping images with Python and Scrapy
Use these blog posts to help create your datasets, keeping in mind the copyrights of the image owners. As a general rule, you should only use copyrighted images for educational purposes. For commercial purposes, you need to contact the owner of each image for permission.
Collecting images online nearly always results in duplicates — be sure to do a quick inspection. After you have created your dataset, follow today’s deduplication tutorial to compute hashes and prune the duplicates automatically.
Recall the two important reasons for pruning duplicates from your machine learning and deep learning datasets:
- Duplicate images in your dataset introduce bias into your dataset, giving your deep neural network additional opportunities to learn patterns specific to the duplicates.
- Additionally, duplicates impact the ability of your model to generalize to new images outside of what it was trained on.
From there, you can train your very own deep learning model on your newly formed dataset and deploy it!
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to detect and remove duplicate images from a deep learning dataset.
Typically, you’ll want to remove duplicate images from your dataset to ensure each data point (i.e., image) is represented only a single time — if there are multiple identical images in your dataset, your convolutional neural network may learn to be biased toward the images, making it less likely for your model to generalize to new images.
To help prevent this type of bias, we implemented our duplicate detector using a method called image hashing.
Image hashing works by:
- Examining the contents of an image
- Constructing a hash value (i.e., an integer) that uniquely quantifies an input image based on the contents of the image alone
Using our hashing function we then:
- Looped over all images in our image dataset
- Computed an image hash for each image
- Checked for “hash collisions,” implying that if two images had the same hash, they must be duplicates
- Removed duplicate images from our dataset
Using the technique covered in this tutorial, you can detect and remove duplicate images from your own datasets — from there, you’ll be able to train a deep neural network on top of your newly deduplicated dataset!
I hope you enjoyed this tutorial.
To download the source code and example dataset for this post (and be notified when future tutorials are published here on PyImageSearch), just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.