On Monday, I showed you how to build an awesome Lord of the Rings image search engine, from start to finish. It was a lot of fun and we learned a lot. We made use of OpenCV image descriptors. More importantly, we got to look at some real-world code to see how exactly an image search engine is built.
But let’s back up a step.
During that blog post, I made mention to the four steps of building an image search engine:
- Defining your descriptor: What type of descriptor are you going to use? What aspect of the image are you describing?
- Indexing your dataset: Apply your descriptor to each image in your dataset.
- Defining your similarity metric: How are you going to determine how “similar” two images are?
- Searching: How does the actual search take place? How are queries submitted to your image search engine?
While Monday’s post was a “let’s get our hands dirty and write some code” type of article, the next few blog posts are going to be a little higher level. But if you plan on building an image search engine of your own, these are four steps you need to understand.
Today we are going to focus only on the first step: Defining our Image Descriptor.
We will explore the remaining steps in the next coming weeks.
Defining Your Image Descriptor
In our Lord of the Rings image search engine, we used a 3D color histogram to characterize the color of each image. This OpenCV image descriptor was a global image descriptor and applied to the entier image. The 3D color histogram was a good choice for our dataset. The five scenes we utilized from the movies each had relatively different color distributions, thus making it easier for a color histogram to return relevant results.
Of course, color histograms are not the only image descriptor we can use. We can also utilize methods to describe both the texture and shape of objects in an image.
Let’s take a look:
Color
As we’ve already seen, color is the most basic aspect of an image to describe, and arguably the most computationally simple. We can characterize the color of an image using the mean, standard deviation, and skew of each channel’s pixel intensities. We could also use color histograms as we’ve seen in other blog posts. In color histograms are global image descriptors applied to the entire image.
One benefit of using simple color methods is that we can easily obtain image size (scale) and orientation (how the image is rotated) invariance.
How is this possible?
Well, let’s take a look at this model of Jurassic Park’s T-Rex at varying scales and orientations, and the resulting histograms extracted from each image.
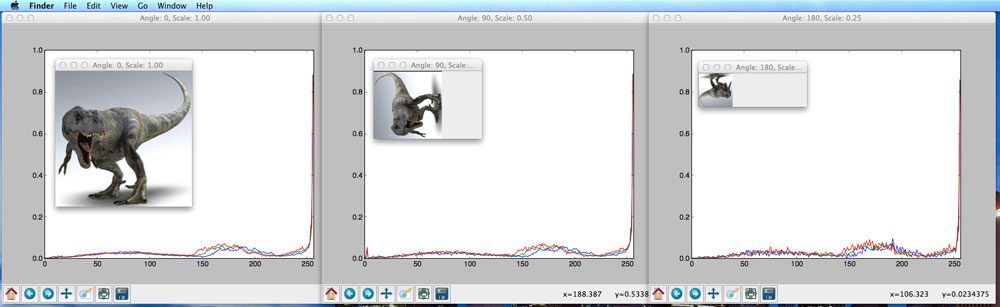
As you can see, we rotate and resize the image with a varying number of angles and scaling factors. The number of bins is plotted along the X-axis and the percentage of pixels placed in each bin on the Y-axis.
In each case, the histogram is identical, thus demonstrating that the color histogram does not change as the image is scaled and rotated.
Rotation and scale invariance of an image descriptor are both desirable properties of an image search engine. If a user submits a query image to our image search engine, the system should find similar images, regardless of how the query image is resized or rotated. When a descriptor is robust to changes such as rotation and scale, we call them invariants due to the fact that the descriptor is invariant (i.e. does not change) even as the image is rotated and scaled.
Texture
Texture tries to model feel, appearance, and the overall tactile quality of an object in an image; however, texture tends to be difficult to represent. For example, how do we construct an image descriptor that can describe the scales of a T-Rex as “rough” or “coarse”?
Most methods trying to model texture examine the grayscale image, rather than the color image. If we use a grayscale image, we simply have a NxN matrix of pixel intensities. We can examine pairs of these pixels and then construct a distribution of how often such pairs occur within X pixels of each other. This type of distribution is called a Gray-Level Co-occurrence Matrix (GLCM).
Once we have the GLCM, we can compute statistics, such as contrast, correlation, and entropy to name a few.
Other texture descriptors exist as well, including taking the Fourier or Wavelet transformation of the grayscale image and examining the coefficients after the transformation.
Finally, one of the more popular texture descriptors of late, Histogram of Oriented Gradients, has been extremely useful in the detection of people in images.
Shape
When discussing shape, I am not talking about the shape (dimensions, in terms of width and height) of the NumPy array that an image is represented as. Instead, I’m talking about the shape of a particular object in an image.
When using a shape descriptor, or first step is normally to apply a segmentation or edge detection technique, allowing us to focus strictly on the contour of the shape we want to describe. Then, once we have the contour, we can again compute statistical moments to represent the shape.
Let’s look at an example using this Pikachu image:

On the left, we have the full color image of Pikachu. Typically, we would not use this type of image to describe shape. Instead, we would convert the image to grayscale and perform edge detection (center) or utilize the mask of Pikachu (i.e. the relevant part of the image we want to describe).
OpenCV provides the Hu Moments method, which is widely used as a simple shape descriptor.
In the coming weeks, I will demonstrate how we can describe the shape of objects in an image using a variety of shape descriptors.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this post we discussed the first step in building an image search engine: choosing an image descriptor. We need to examine our dataset and decide what aspects of the images we are going to describe. Is the color distribution of the image important when performing a search? What about the texture of an object in an image? Or the shape? Or maybe we need to characterize all three?
Choosing a descriptor is just the first step. Next week, we’ll explore how to apply our image descriptor(s) to each image in our dataset.
Downloads:
You can download a .zip of the code and example image here.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

