Table of Contents
- Autoregressive Model Limits and Multi-Token Prediction in DeepSeek-V3
- Why Next-Token Prediction Limits DeepSeek-V3
- Multi-Token Prediction in DeepSeek-V3: Predicting Multiple Tokens Ahead
- DeepSeek-V3 Architecture: Multi-Token Prediction Heads Explained
- Gradient Insights for Multi-Token Prediction in DeepSeek-V3
- DeepSeek-V3 Training vs. Inference: How MTP Changes Both
- Multi-Token Prediction Loss Weighting and Decay for DeepSeek-V3
- Step-by-Step Implementation of Multi-Token Prediction Heads in DeepSeek-V3
- Integrating Multi-Token Prediction with DeepSeek-V3’s Core Transformer
- Theoretical Foundations: MTP, Curriculum Learning, and Auxiliary Tasks
- Multi-Token Prediction Benefits: Coherence, Planning, and Faster Convergence
- Summary
Autoregressive Model Limits and Multi-Token Prediction in DeepSeek-V3
In the first three parts of this series, we built the foundation of DeepSeek-V3 by implementing its configuration and Rotary Positional Embeddings (RoPE), exploring the efficiency gains of Multi-Head Latent Attention (MLA), and scaling capacity through the Mixture of Experts (MoE). Each of these components adds a crucial piece to the puzzle, progressively shaping a model that balances performance, scalability, and efficiency. With these building blocks in place, we are now ready to tackle another defining innovation: Multi-Token Prediction (MTP).

Unlike traditional autoregressive models that predict one token at a time, MTP enables DeepSeek-V3 to forecast multiple tokens simultaneously, significantly accelerating training and inference. This approach not only reduces computational overhead but also improves the model’s ability to capture richer contextual patterns across sequences.
In this lesson, we will explore the theory behind MTP, examine why it represents a leap forward in language modeling, and implement it step by step. As with the earlier lessons, this installment continues our broader mission to reconstruct DeepSeek-V3 from scratch, showing how innovations including RoPE, MLA, MoE, and now MTP fit together into a cohesive architecture that will culminate in the assembly and training of the full model.
This lesson is the 4th in a 6-part series on Building DeepSeek-V3 from Scratch:
- DeepSeek-V3 Model: Theory, Config, and Rotary Positional Embeddings
- Build DeepSeek-V3: Multi-Head Latent Attention (MLA) Architecture
- DeepSeek-V3 from Scratch: Mixture of Experts (MoE)
- Autoregressive Model Limits and Multi-Token Prediction in DeepSeek-V3 (this tutorial)
- Lesson 5
- Lesson 6
To learn about DeepSeek-V3 and build it from scratch, just keep reading.
Why Next-Token Prediction Limits DeepSeek-V3
Traditional language models are trained with a simple objective: given tokens  , predict the next token
, predict the next token  . Mathematically, we maximize:
. Mathematically, we maximize:
") .
.
This autoregressive factorization is elegant and has proven remarkably effective. However, it has a fundamental limitation: the model only receives a training signal for immediate next-token prediction. It never explicitly learns to plan multiple steps ahead.
Consider generating the sentence: “The cat sat on the mat because it was comfortable.” When predicting “because,” the model should already be considering how the sentence will complete — including the subordinate clause, the pronoun reference, and the conclusion. But with next-token prediction alone, there’s no explicit gradient signal encouraging this forward planning. The model might learn it implicitly through exposure to many examples, but we’re not directly optimizing for it.
This limitation becomes especially apparent in tasks requiring long-term coherence (e.g., story generation, multi-paragraph reasoning, or code generation), where later statements must be consistent with earlier declarations. The model can easily generate locally fluent text that globally contradicts itself because its training objective only looks one token ahead.
Multi-Token Prediction in DeepSeek-V3: Predicting Multiple Tokens Ahead
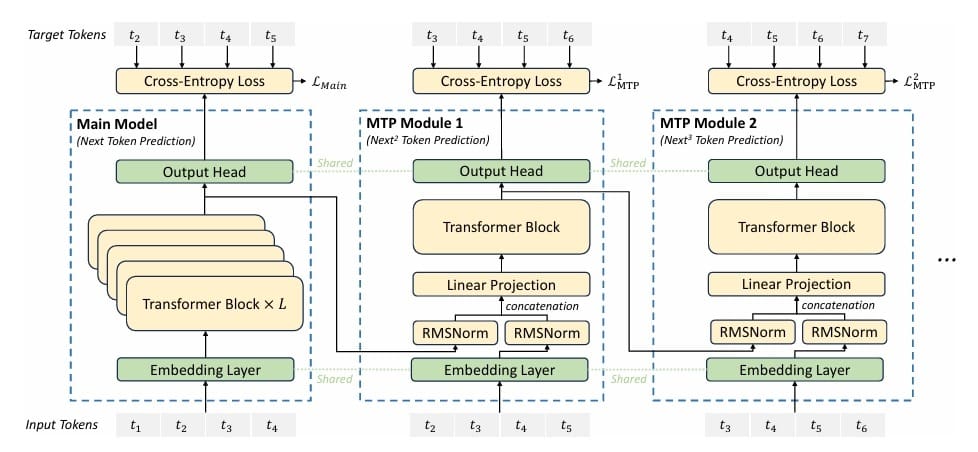
Multi-Token Prediction (Figure 1) addresses this by adding auxiliary prediction heads that forecast multiple tokens into the future. Alongside the standard prediction ") , we also predict:
, we also predict:
")
")
and so on for  tokens ahead. Critically, these predictions are computed in parallel during training (not autoregressively) — we know all ground truth tokens, so we can supervise all predictions simultaneously.
tokens ahead. Critically, these predictions are computed in parallel during training (not autoregressively) — we know all ground truth tokens, so we can supervise all predictions simultaneously.
The complete training objective becomes:
 + \sum\limits_{d=1}^{n} \lambda_d \sum\limits_{t=1}^{T-d-1} \log P(x_{t+d+1} \mid x_{1:t}, x_{t+1:t+d})") ,
,
where is the number of future tokens we predict,  are weighting coefficients (typically decreasing with distance:
are weighting coefficients (typically decreasing with distance:  ), and we’ve explicitly shown that predictions at depth
), and we’ve explicitly shown that predictions at depth  condition on both the context up to position
condition on both the context up to position  and the intermediate tokens up to
and the intermediate tokens up to  .
.
DeepSeek-V3 Architecture: Multi-Token Prediction Heads Explained
Implementing MTP requires architectural additions. We can’t just reuse the main language modeling head for future predictions — we need to condition on the intermediate tokens. DeepSeek-V3 implements this through a hierarchy of prediction heads, each specialized for a particular future depth.
Head Architecture: For predicting tokens ahead, we have a head  that combines:
that combines:
- The hidden representation from the Transformer at position
 :
: 
- The embedding of the token at position
 :
: 
 :
: 
The combination follows:
} = \text{Combine}(h_t, e_{t+d})")
This combined representation is then processed through a mini-Transformer (lightweight attention and feedforward layers) before projecting to the vocabulary:
} = h_t^{(d)} + \text{Attention}(h_t^{(d)})")
} = h_t^{(d)} + \text{MoE}(h_t^{(d)})")
} W_\text{vocab}")
The intuition is powerful: to predict token  , we start with the representation at position (encoding all context), incorporate the embedding of token (telling us what word we’ve just generated), process through a small Transformer (allowing the model to refine this combination), and project to vocabulary (producing logits over the vocabulary). This architecture naturally encourages forward planning — the model must learn representations at position that are useful for predictions multiple steps ahead.
, we start with the representation at position (encoding all context), incorporate the embedding of token (telling us what word we’ve just generated), process through a small Transformer (allowing the model to refine this combination), and project to vocabulary (producing logits over the vocabulary). This architecture naturally encourages forward planning — the model must learn representations at position that are useful for predictions multiple steps ahead.
Gradient Insights for Multi-Token Prediction in DeepSeek-V3
From an optimization perspective, MTP provides richer gradient signals. In standard training, only the hidden representation  receives gradients from predicting . With MTP, also receives gradients from predicting
receives gradients from predicting . With MTP, also receives gradients from predicting  . These additional gradients encourage to encode information relevant not just for the immediate next token, but for multiple future tokens.
. These additional gradients encourage to encode information relevant not just for the immediate next token, but for multiple future tokens.
Moreover, the gradients from future predictions flow through different pathways — through the MTP heads’ mini-Transformers. This creates a form of multi-task learning in which different prediction depths impose distinct consistency constraints on the learned representations. A representation that works well for predicting 1 token ahead might not be good for predicting 5 tokens ahead; MTP encourages learning representations that support both.
We can think of this as adding an implicit regularizer. The additional prediction objectives constrain the learned representations to be more structured, more forward-looking, and more globally coherent. It’s similar in spirit to multi-task learning, where auxiliary tasks improve representation quality even if we care primarily about one main task.
DeepSeek-V3 Training vs. Inference: How MTP Changes Both
During Training: We compute all predictions in parallel. For a sequence of length  , we predict:
, we predict:
- Main head: positions 1 through
 predict positions 2 through
predict positions 2 through 
- Depth-1 head: positions 1 through
 predict positions 3 through
predict positions 3 through - Depth-2 head: positions 1 through predict positions 4 through
 predict positions 2 through
predict positions 2 through  predict positions 3 through
predict positions 3 through  predict positions 4 through
predict positions 4 through Each prediction uses the ground truth intermediate tokens (available during training), so there’s no error accumulation. The losses are computed independently and summed with appropriate weights.
During Inference: Interestingly, MTP heads are typically not used during autoregressive generation. Once training is complete, we generate text using only the main prediction head in the standard autoregressive manner. The MTP heads have served their purpose by improving the learned representations; we don’t need their multi-step predictions at inference time.
This is computationally appealing: we get the benefits of MTP (better representations, improved coherence) during training, but inference remains as efficient as a standard language model. There’s no additional computational cost at deployment.
Multi-Token Prediction Loss Weighting and Decay for DeepSeek-V3
The weighting coefficients are important hyperparameters. Intuitively, predictions further in the future are harder and less reliable, so we should weight them less heavily. A common scheme is exponential decay:

where  . For example, with
. For example, with  :
:
- Depth 1 (predicting
 from ): weight 1.0
from ): weight 1.0 - Depth 2 (predicting from ): weight 0.5
- Depth 3 (predicting from ): weight 0.25
 from
from  from
from  from
from In our implementation, we use a simpler approach: uniform weighting of 0.3 for all MTP losses relative to the main loss. This is less sophisticated but easier to tune and still provides the core benefits.
Step-by-Step Implementation of Multi-Token Prediction Heads in DeepSeek-V3
Let’s implement the complete MTP system:
class MultiTokenPredictionHead(nn.Module):
"""
Multi-Token Prediction Head
Each head predicts a token at a specific future position.
Combines previous hidden state with future token embedding.
"""
def __init__(self, config: DeepSeekConfig, depth: int):
super().__init__()
self.depth = depth
self.n_embd = config.n_embd
# Combine previous hidden state with future token embedding
self.combine_proj = nn.Linear(2 * config.n_embd, config.n_embd, bias=config.bias)
# Normalization
self.norm1 = RMSNorm(config.n_embd)
self.norm2 = RMSNorm(config.n_embd)
# Transformer components (mini-transformer for each head)
self.attn = MultiheadLatentAttention(config)
self.mlp = MixtureOfExperts(config)
self.attn_norm = RMSNorm(config.n_embd)
self.mlp_norm = RMSNorm(config.n_embd)
Lines 1-24: Prediction Head Structure. Each MultiTokenPredictionHead is specialized for a particular depth — head 1 predicts 1 token ahead, head 2 predicts 2 tokens ahead, etc. We store the depth for potential depth-conditional processing (though we don’t use it in this simple implementation).
The architecture has 3 main components: a combination projection that merges the hidden state and future token embeddings, normalization layers for stabilization, and a mini-Transformer consisting of an attention module and an MoE. This mini-Transformer is complete but lightweight — it has the same architecture as our main model blocks but serves a specialized purpose.
def forward(self, prev_hidden, future_token_embed):
"""
Args:
prev_hidden: [B, T, D] - Hidden states from previous layer
future_token_embed: [B, T, D] - Embeddings of future tokens
Returns:
hidden: [B, T, D] - Processed hidden states
"""
# Normalize inputs
prev_norm = self.norm1(prev_hidden)
future_norm = self.norm2(future_token_embed)
# Combine representations
combined = torch.cat([prev_norm, future_norm], dim=-1)
hidden = self.combine_proj(combined)
# Process through mini-transformer
hidden = hidden + self.attn(self.attn_norm(hidden))
moe_out, _ = self.mlp(self.mlp_norm(hidden))
hidden = hidden + moe_out
return hidden
Lines 26-41: The Combination Strategy. The forward method takes two inputs: prev_hidden (the hidden representation at position , encoding all context up to that point) and future_token_embed (the embedding of the token at position , providing information about what’s been generated). We normalize both inputs independently — this prevents scale mismatches between the hidden representations (which may have grown or shrunk through many Transformer layers) and the embeddings (which come fresh from the embedding layer). We concatenate along the feature dimension, doubling the dimensionality, then project back to n_embd dimensions. This projection learns how to merge content from these two different sources.
Lines 44-46: Mini-Transformer Processing. The combined representation flows through a lightweight Transformer. First, attention with a residual connection: the model can attend across the sequence, allowing position to gather information from other positions when predicting . This is crucial because the prediction might depend on context earlier in the sequence. Then, MoE with a residual connection: the expert networks can apply non-linear transformations, refining the combined representation. The use of the same MLA attention and MoE that we’ve already implemented is elegant — we’re reusing well-tested components. The pre-norm architecture (normalizing before attention and MoE rather than after) has become standard in modern Transformers for training stability.
Line 48: Returning Refined Hidden State. The output hidden state has the same dimensionality as the input ( ), so it can be projected through the vocabulary matrix to get logits for predicting
), so it can be projected through the vocabulary matrix to get logits for predicting  . This hidden state has been enriched with information from both the context (via
. This hidden state has been enriched with information from both the context (via prev_hidden) and the intermediate token (via future_token_embed), and has been refined through attention and expert processing. It represents the model’s best understanding of what should come next-next, not just next.
Integrating Multi-Token Prediction with DeepSeek-V3’s Core Transformer
The MTP heads integrate into the main model during training. After computing the final hidden states  from the main Transformer, we apply the following operations:
from the main Transformer, we apply the following operations:
- Main prediction: Project to vocabulary to predict , compute cross-entropy loss
- Depth-1 prediction: For each position , get embedding of (ground truth), combine with through head 1, project to vocabulary to predict
 , compute cross-entropy loss
, compute cross-entropy loss - Depth-2 prediction: For each position , get embedding of (ground truth), combine with head-1 output, project to vocabulary to predict , compute cross-entropy loss
 , compute cross-entropy loss
, compute cross-entropy loss , compute cross-entropy loss
, compute cross-entropy lossThe key insight is that we chain the heads: head 2’s input includes head 1’s output. This creates a hierarchical structure in which each head builds on the previous one, progressively looking further into the future.
Theoretical Foundations: MTP, Curriculum Learning, and Auxiliary Tasks
MTP has interesting theoretical connections to other areas of machine learning:
Temporal Difference Learning: In reinforcement learning, temporal difference learning propagates value information backward from future states. MTP does something analogous — it propagates gradient information backward from future predictions, encouraging current representations to encode future-relevant information.
Auxiliary Tasks: MTP can be viewed as an auxiliary task framework in which the auxiliary tasks are future token predictions. Research in multi-task learning shows that auxiliary tasks improve representation quality when they are related but distinct from the main task. Future token prediction is perfectly related (it is the same task at different time steps) but distinct (it requires different information).
Curriculum Learning: The depth-weighted loss structure implements a form of curriculum — we emphasize near-future predictions (easier, more reliable) more than far-future predictions (harder, noisier). This gradually increasing difficulty may help training by first learning short-term dependencies before tackling long-term structure.
Multi-Token Prediction Benefits: Coherence, Planning, and Faster Convergence
Research on Multi-Token Prediction shows several empirical benefits:
- Improved Coherence: Models trained with MTP generate more globally coherent text, with fewer contradictions or topic drift over long generations
- Better Planning: For tasks like story writing or code generation, where early decisions constrain later possibilities, MTP helps the model make forward-compatible choices
- Faster Convergence: The additional training signals can accelerate learning, reaching target performance with fewer training steps
- Regularization: MTP acts as a regularizer, preventing overfitting by encouraging representations that support multiple related objectives
However, MTP also has costs. Training becomes more complex — we must manage multiple prediction heads and carefully weight their losses. Training is slower — computing multiple predictions per position increases computation by a factor of roughly  for future tokens (the factor is not linear because not all positions can predict tokens ahead). Memory usage increases due to the additional heads’ parameters.
for future tokens (the factor is not linear because not all positions can predict tokens ahead). Memory usage increases due to the additional heads’ parameters.
The tradeoff is typically favorable for larger models and longer-form generation tasks. For small models or short-sequence tasks, the overhead may outweigh the benefits. In our children’s story generation task, MTP should help with maintaining narrative consistency across a story.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In the first three lessons of this series, we progressively assembled the foundations of DeepSeek-V3: starting with its configuration and Rotary Positional Embeddings (RoPE), then advancing to the efficiency of Multi-Head Latent Attention (MLA), and scaling capacity through the Mixture of Experts (MoE). Each of these innovations has added a crucial piece to the architecture, balancing efficiency, scalability, and representational power. With those components in place, we turn to another breakthrough that redefines how language models learn and generate text: Multi-Token Prediction (MTP).
Traditional autoregressive models rely on next-token prediction, a strategy that, while effective, can be shortsighted — focusing only on immediate context rather than broader sequence-level patterns. MTP addresses this limitation by enabling the model to predict multiple tokens ahead, accelerating training and inference while enriching contextual understanding. In this lesson, we explore the shortcomings of next-token prediction, introduce the architecture of specialized prediction heads, and examine why MTP works from a gradient perspective.
We then dive into practical considerations (e.g., weighted loss, decay strategies, and implementation details), before integrating MTP into the main model. By the end, we see how this innovation not only improves efficiency but also strengthens the theoretical and empirical foundations of DeepSeek-V3, bringing us closer to assembling the complete architecture.
Citation Information
Mangla, P. “Autoregressive Model Limits and Multi-Token Prediction in DeepSeek-V3,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/alrep
@incollection{Mangla_2026_autoregressive-model-limits-and-mTP-in-deepseek-v3,
author = {Puneet Mangla},
title = {{Autoregressive Model Limits and Multi-Token Prediction in DeepSeek-V3}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
year = {2026},
url = {https://pyimg.co/alrep},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.