The Rise of Multimodal LLMs and Efficient Serving with vLLM
In this tutorial, you will learn how multimodal LLMs like LLaVA, GPT-4V, and BakLLaVA combine vision and language understanding, why they represent a major shift in AI capabilities, and how the vLLM framework enables efficient, scalable deployment of these models with OpenAI-compatible APIs.

This lesson is the 1st of a 3-part series on Deploying Multimodal LLMs with vLLM:
- The Rise of Multimodal LLMs and Efficient Serving with vLLM (this tutorial)
- Setting Up LLaVA/BakLLaVA with vLLM: Backend and API Integration
- Building a Streamlit Python UI for LLaVA with OpenAI API Integration
To learn how to build and deploy cutting-edge multimodal LLMs like LLaVA using the high-performance vLLM serving framework, just keep reading.
Introduction to Multimodal LLMs
Large Language Models (LLMs) have revolutionized the way we interact with machines — from writing assistance to reasoning engines. But until recently, they’ve largely been stuck in the world of text.
Humans aren’t wired that way. We make sense of the world using multiple modalities — vision, language, audio, and more — in a seamless, unified way. That’s where Multimodal Large Language Models (MLLMs) come in.
These models don’t just read; they see, interpret, and respond across multiple types of input, especially text and images.
What Are Multimodal LLMs?
Multimodal LLMs are models designed to process and reason across multiple types of inputs — most commonly text and images.
In practice, this means:
- You can feed in a photo or chart and ask the model to describe it.
- You can ask the model questions about an image, like “What brand is this shoe?” or “How many traffic signs are visible?”
- You can combine image + text prompts to guide responses more naturally.
These models work by combining two major components:
- A vision encoder (e.g., CLIP, EVA, or BLIP-2) that extracts features from the image
- A language model (e.g., LLaMA, Vicuna, Mistral) that generates text based on those features and any accompanying prompt
A thin projection layer is typically inserted between the two to map vision features into the language model’s token space.
This structure lets multimodal LLMs “see” and “speak” — enabling powerful tasks like visual question answering (VQA), document comprehension, OCR-free form understanding, medical imaging captioning, and more.
Milestones in Multimodal LLM Evolution
Let’s take a quick tour through the models that have shaped this space.
Flamingo (DeepMind, 2022)
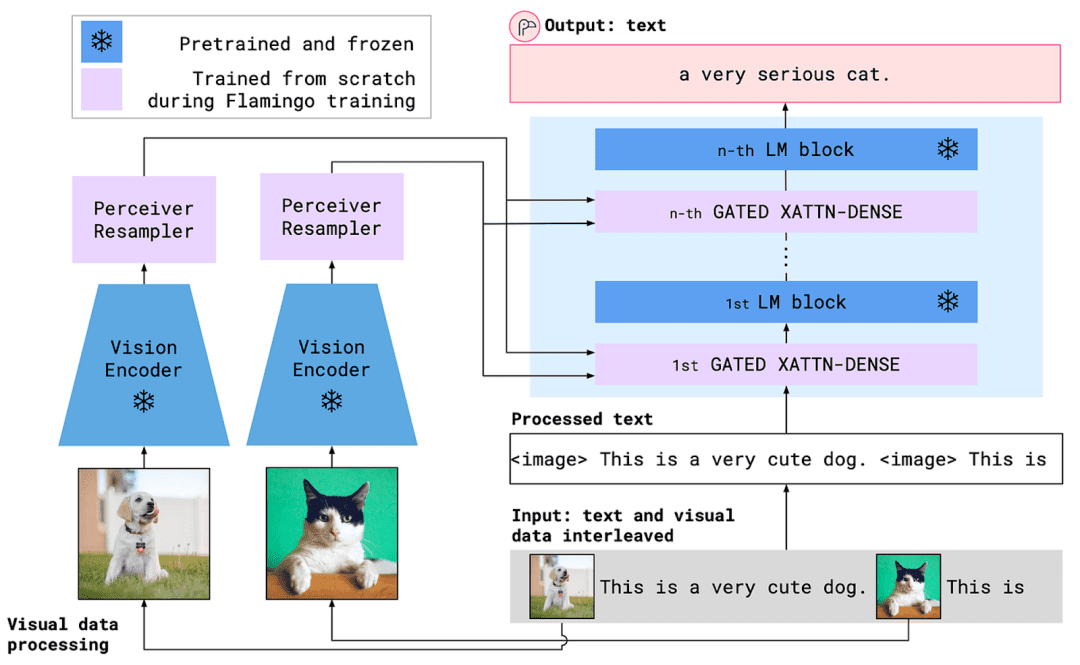
Flamingo (Alayrac et al., 2022, DeepMind) introduced the idea that you can feed image features and text into the same decoder-only language model using clever formatting and adapters.
- Vision encoder: frozen
- Few-shot learning: strong performance with limited labeled data
- Unlocked capabilities (e.g., VQA, captioning, and image-text reasoning)
Flamingo was a turning point — it showed that with the right tricks, you don’t need to retrain everything from scratch.
GPT-4V (OpenAI, 2023)
GPT-4V (GPT-4 with vision) brought multimodal reasoning into the mainstream.
- Fully closed-source
- Image inputs are accepted as part of chat prompts
- Capable of advanced tasks (e.g., chart reading, meme explanation, and OCR-free form analysis)

It’s currently the gold standard for general-purpose image + text reasoning — but being closed, it’s not usable for most real-world applications that require on-prem, transparent, or low-cost solutions.
LLaVA (Large Language and Vision Assistant, 2023)
LLaVA was the community’s answer to GPT-4V.
- Open-source
- Combines CLIP (ViT-L) as the vision encoder with Vicuna (LLaMA-based) as the language model
- Trained using GPT-4-generated image-text instruction pairs
- Architecture:
- Vision encoder (CLIP ViT-L) → projection → language model (Vicuna)
- Supports image as input and chat-based prompting
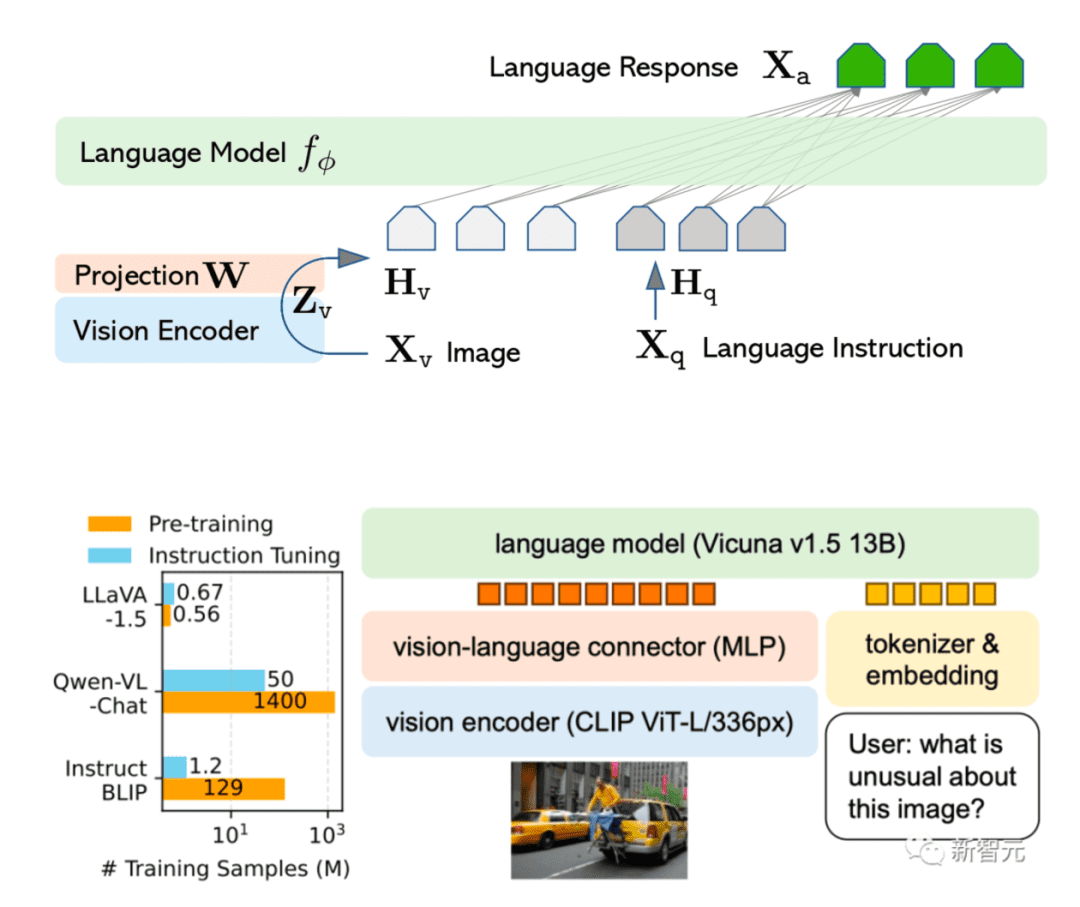
As shown in Figure 4, the vision encoder extracts image features, which are projected via a vision-language connector and aligned with text embeddings before being passed into a large language model (e.g., Vicuna v1.5 13B). The model is instruction-tuned to generate natural language responses from both visual and textual inputs
LLaVA demonstrated that GPT-4V-like results can be achieved using open components — and crucially, it’s fine-tunable, auditable, and deployable.
BakLLaVA (2024)
BakLLaVA builds on the LLaVA blueprint, but takes it one step further:
- Trained entirely on open datasets — no reliance on GPT-4 outputs
- Supports LLaMA 2 and Mistral-based backbones
- Offers more transparency and broader licensing freedom
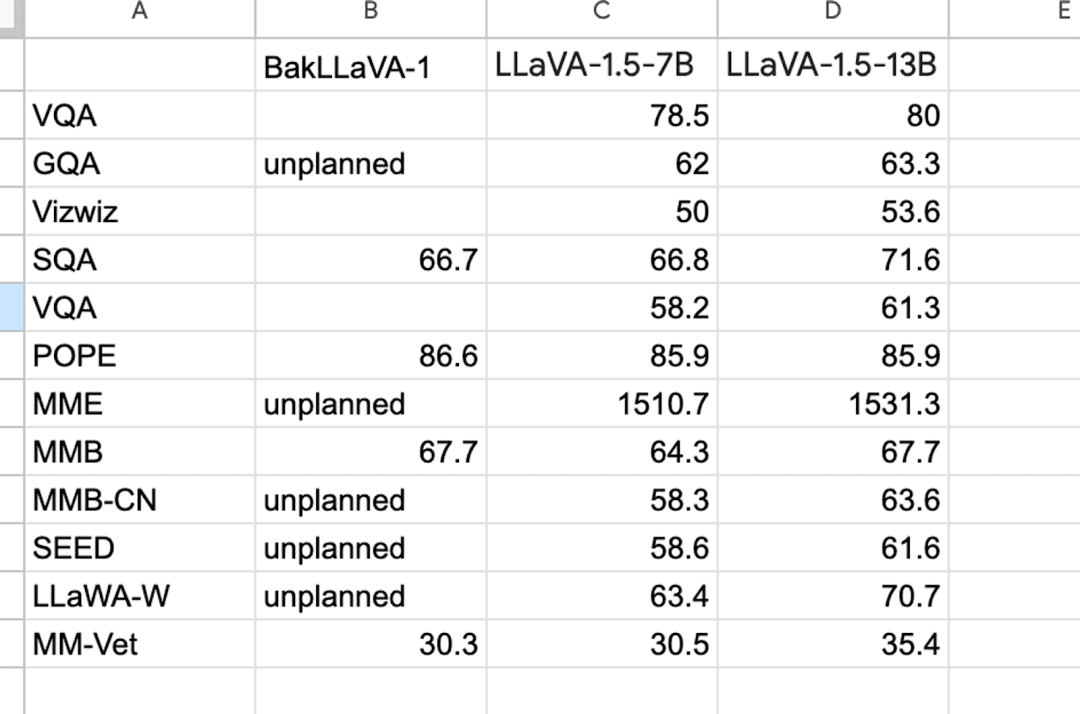
Table 1 presents benchmark results for different multimodal LLM variants — specifically:
- BakLLaVA-1
- LLaVA-1.5–7B
- LLaVA-1.5–13B
These models are compared across various vision-language tasks, such as:
- VQA (Visual Question Answering)
- GQA (Graph-based QA)
- SQA (Structured QA)
- POPE, MME, MMBench, SEED, etc.
Each value in Table 1 represents a score or accuracy metric for the model on that specific benchmark. For instance:
- BakLLaVA-1 scores 86.6 on POPE, slightly higher than both LLaVA variants.
- On VQA, LLaVA-1.5–13B outperforms with a score of 80, showing the benefit of a larger model size.
Some cells are marked “unplanned”, indicating the evaluation for that benchmark wasn’t run (possibly due to resource or dataset availability).
In short, Table 1 shows how well these models reason over vision+language tasks, and BakLLaVA-1 delivers competitive performance — sometimes beating LLaVA variants despite using less compute. The results highlight BakLLaVA-1’s competitive performance in POPE, SQA, and MMB, while LLaVA-1.5 variants cover a wider range of planned benchmarks with stronger overall results.
It’s a community-first initiative that aligns with the open-source ethos and serves as a true alternative to proprietary multimodal models.
Other Open-Source Models
The space is evolving rapidly. Some key players include:
- CogVLM: High-performing multimodal model with open weights and strong benchmarks
- MiniGPT-4: Lightweight alternative using BLIP-2 + Vicuna
- VisualGLM, BLIVA, PandaGPT: Each with different encoder-decoder combos and training strategies
However, a common limitation across many of these is that they’re hard to deploy efficiently, especially for production use cases.
The Deployment Gap
Open-source models like LLaVA and BakLLaVA are incredible — but most come with:
- Slow inference on large images
- Lack of batching, streaming, or GPU memory efficiency
- No OpenAI-style API for easy app integration
This is where vLLM comes in — a high-performance inference engine originally built for text-only LLMs, now being extended for vision-language models via projects like llava_vllm.
Would you like immediate access to 3,457 images curated and labeled with hand gestures to train, explore, and experiment with … for free? Head over to Roboflow and get a free account to grab these hand gesture images.
Configuring Your Development Environment
To follow this guide, make sure you have the Transformers and Pillow libraries installed on your system.
Luckily, all libraries are pip-installable:
$ pip install transformers==4.53.2 pillow==11.3.0
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Try It Yourself: Inference with LLaVA and BakLLaVA
Let’s see how easy it is to run inference with open-source multimodal models using Hugging Face and Transformers. We’ll start with LLaVA-1.5-7B, then move to BakLLaVA-v1.
Example 1: LLaVA-1.5-7B (via pipeline)
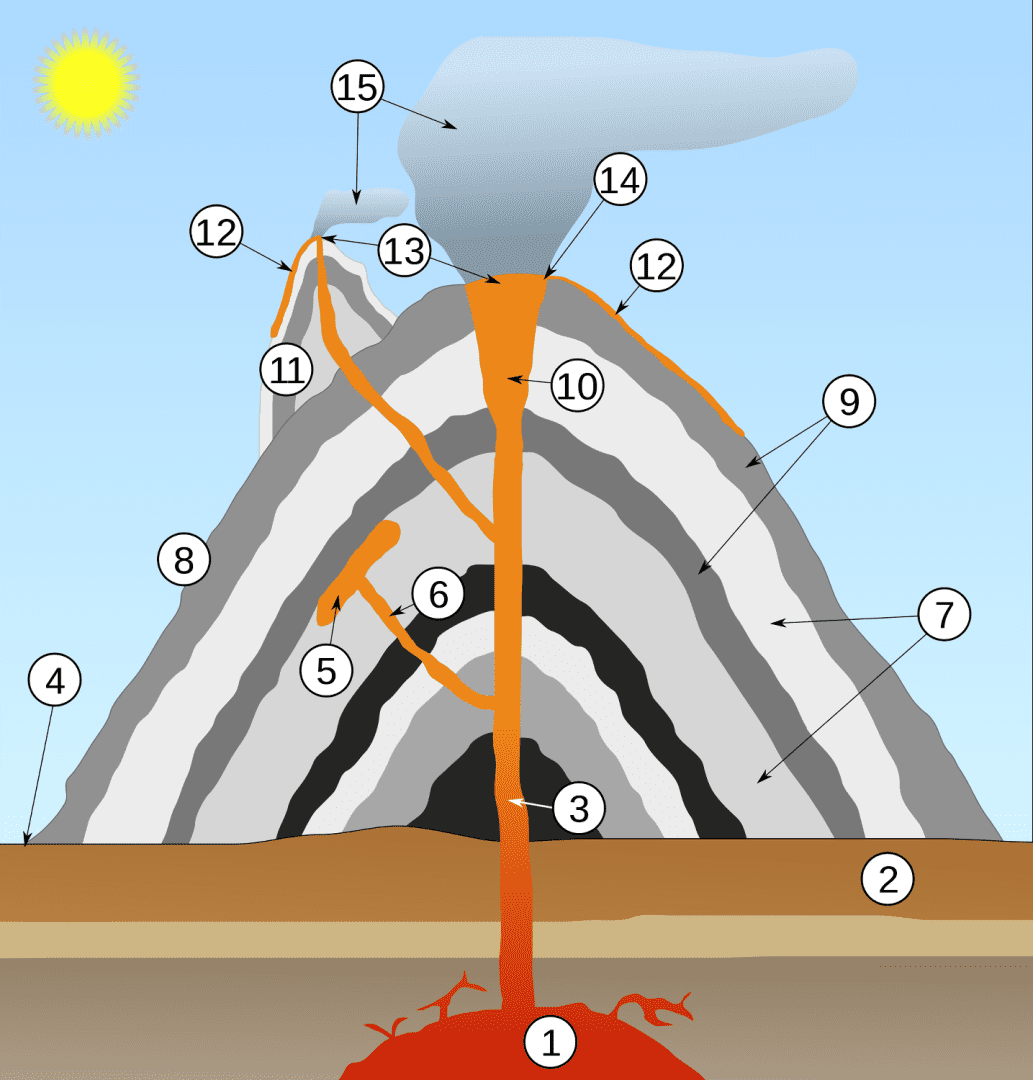
In this example, we’ll use LLaVA-1.5-7B to answer a question about a volcano diagram from the AI2D dataset.
from transformers import pipeline
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load model via pipeline
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id)
# Download a demo image (volcano cross-section from AI2D)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display the image so we know what the model sees
plt.imshow(image)
plt.axis("off")
plt.title("AI2D Demo Image")
plt.show()
# Construct a multimodal prompt (diagram QA style)
prompt = (
"USER: <image>\n"
"What does the label 15 represent? "
"(1) lava (2) core (3) tunnel (4) ash cloud\n"
"ASSISTANT:"
)
# Run inference
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs[0]["generated_text"])
- We first load the LLaVA model into a Hugging Face pipeline.
- The image is fetched and displayed, allowing readers to see the volcano diagram.
- The prompt mixes text with an
<image>placeholder to ask a multiple-choice question. - The model then generates an answer — often pointing to the correct option, “ash cloud.”
Output:
USER: What does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud ASSISTANT: The label 15 represents the ash cloud, which is a cloud of ash and debris that is produced when a volcano erupts. This ash cloud can be seen in the image, along with the other labels representing the mountain, lava, and core.
Example 2: BakLLaVA-v1 (with AutoProcessor)
Next, let’s try BakLLaVA-v1, a newer open-source multimodal LLM. Instead of the pipeline API, here we use AutoProcessor and the model’s generate() method directly.
import requests
from PIL import Image
import torch
import matplotlib.pyplot as plt
from transformers import AutoProcessor, LlavaForConditionalGeneration
# Model and test image
model_id = "llava-hf/bakLlava-v1-hf"
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
prompt = "USER: <image>\nWhat are these?\nASSISTANT:"
# Load model and processor
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to("cuda" if torch.cuda.is_available() else "cpu")
processor = AutoProcessor.from_pretrained(model_id)
# Fetch and display image
raw_image = Image.open(requests.get(image_url, stream=True).raw)
plt.imshow(raw_image)
plt.axis("off")
plt.title("COCO Sample Image")
plt.show()
# Prepare inputs (note: use keyword args for safety)
inputs = processor(
images=raw_image,
text=prompt,
return_tensors="pt"
).to(model.device, torch.float16)
# Generate text output
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)
print(processor.decode(output[0], skip_special_tokens=True))
- BakLLaVA is loaded directly via
from_pretrained(). - We fetch a sample COCO image (two dogs on a couch) and display it.
- The processor encodes both the image and prompt into tensors.
- The model’s
generate()method produces a natural language response (e.g., “two dogs sitting on a couch”).

Now that we’ve explored the evolution of multimodal LLMs — from early models like Flamingo to open-source frameworks like LLaVA and BakLLaVA — it’s time to take a step back and understand why this shift toward multimodal intelligence actually matters.
In the next section, we’ll explore the real-world impact of these models, the kinds of tasks they unlock, and why the open-source ecosystem is rallying around them.
Why Multimodal Matters
Multimodal LLMs aren’t just an academic curiosity — they represent a major shift in how we build and interact with AI systems.
By combining language understanding with visual perception, these models unlock an entirely new class of applications that text-only models can’t handle.
Real-World Use Cases
Here are just a few domains where multimodal LLMs are already making an impact:
Image Captioning
Automatically describing what’s in an image — not just listing objects, but generating fluent, contextual descriptions.
- “A golden retriever jumping over a log in the forest.”
- “An elderly man reading a newspaper on a bench.”

Used in: accessibility tools, photo libraries, ecommerce platforms, and image search engines.
Visual Question Answering (VQA)
These models can answer natural-language questions about an image, often reasoning over layout, object relationships, and spatial positioning.
- Q: “How many people are wearing helmets?”
- Q: “Is the traffic light red or green?”

Used in: autonomous vehicles, industrial inspection, safety monitoring, and education tools.
Document and Form Understanding
Instead of relying on brittle OCR + heuristic pipelines, multimodal LLMs can directly parse forms, tables, scanned documents, and receipts — with visual and linguistic grounding.
- “What is the total amount on this invoice?”
- “Who signed this contract?”
- “Which fields are missing?”

Used in: fintech, insurance, compliance, intelligent document processing (IDP).
Grounded Reasoning
Multimodal LLMs can understand why something in an image matters based on textual cues — from interpreting charts and memes to reasoning over diagrams.
- “What’s funny about this meme?”
- “Which process comes after oxidation in this flowchart?”

Used in: education, technical support, and content moderation.
Why Developers and Companies Care
So why is there so much momentum behind multimodal LLMs in the open-source community?
- Natural UX: Upload an image + type a prompt → get an answer. It mirrors human communication.
- Flexible Inputs: Apps are no longer constrained by text-only input boxes.
- Model Consolidation: Instead of stitching together multiple models (OCR + captioning + reasoning), multimodal LLMs unify everything in one.
- Competitive Advantage: These models bring GPT-4V-like capabilities to self-hosted stacks — no need to send sensitive data to a third-party API.
- Open-Source Velocity: Tools like LLaVA and BakLLaVA are improving rapidly, and the community is eager to build tooling around them.
In short: multimodal LLMs are not just “nicer” models — they’re enablers for entirely new classes of intelligent applications.
What Are We Going to Build?
Before we dive into the infrastructure details and server setup, let’s step back and look at the end-to-end user flow we’re going to implement in this mini-series.
By the end of Lesson 3, you’ll have a fully working pipeline where a user can upload an image and prompt through a simple UI — and get back a caption or visual response from a powerful multimodal LLM served efficiently using vLLM.
The Goal
We’re deploying a multimodal model like LLaVA or BakLLaVA using the vLLM serving framework. This setup will expose an OpenAI-compatible API, allowing us to connect a simple frontend like Streamlit, as well as test with scripts such as test_openai.py.
As shown in Figure 9, a user uploads an image and prompt through a Streamlit UI, which sends a JSON request to the vLLM server. The request is forwarded in OpenAI-compatible format to the model, where the vision encoder and language model generate a response. The response is then returned in OpenAI style and displayed in the frontend. This workflow, implemented in Lessons 2 and 3, demonstrates the complete architecture and interaction pipeline
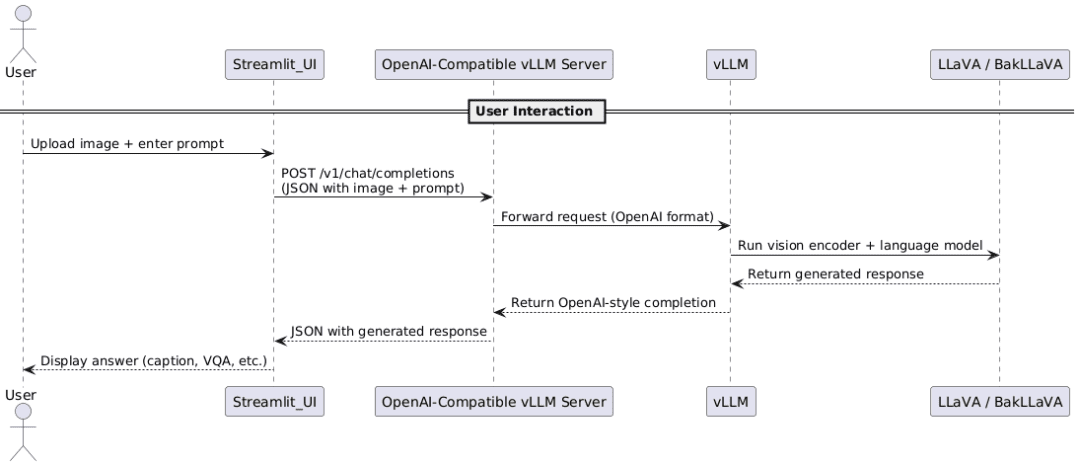
Inference Flow: Step-by-Step
Here’s how the full pipeline works:
- A user uploads an image and types a prompt in a Streamlit UI.
- The Streamlit app formats the request as JSON (including the image encoded in base64).
- It sends the request to the OpenAI-compatible LLaVA server, exposed via vllm.entrypoints.openai.llava_server.
- This server uses vLLM to load and serve the LLaVA/BakLLaVA model efficiently.
- The model processes the vision + language inputs and returns the output.
- Streamlit displays the generated response to the user.
You’ll also be able to:
- Test this using a Python script that mimics OpenAI’s Chat Completion interface
- Swap out the OpenAI API for the native LLaVA server (
vllm.entrypoints.llava.llava_server) if needed
Challenges of Serving Multimodal Models
Multimodal LLMs (e.g., LLaVA and BakLLaVA) have opened the door to powerful vision-language capabilities — all in the open-source ecosystem. But if you’ve ever tried deploying one, you’ll know the truth:
🔥 These models are incredibly hard to serve efficiently.
Despite their breakthrough performance, most multimodal LLMs are not designed with production deployment in mind. They work in notebooks, sure — but try scaling them, integrating them with apps, or serving them on limited GPU infrastructure… and you’ll hit a wall fast.
Let’s break down why.
1. Compute Overhead from Vision + Language
Multimodal models are doubly demanding — because they process both images and text. You’re no longer just loading an LLM like LLaMA or Vicuna.
Now, you also need:
- A vision encoder (e.g., CLIP or BLIP-2) — usually a large ViT model
- A projection layer to align image features with the language model’s token space
- The decoder (Vicuna, Mistral, etc.) to generate responses
This means:
- More GPU memory
- Longer inference time
- Slower cold starts
Even a small image, once encoded, adds hundreds of dense tokens to the prompt — pushing models closer to the context window limits.
2. No Batching, No Streaming, Poor Throughput
Most of the LLaVA-based repositories use simple Python inference loops — not optimized serving engines.
This leads to:
- No request batching: every user call is handled sequentially
- No token streaming: output is returned all at once, causing latency
- Poor GPU utilization: even on high-end hardware, you can end up waiting on idle compute
For real-world apps like chatbots or visual assistants, this performance drag is unacceptable.
3. Lack of OpenAI-Compatible APIs
Most open-source multimodal models expose basic HTTP endpoints or inference scripts.
But they don’t speak the OpenAI API language, which means:
- You can’t plug them into LangChain, LlamaIndex, or Gradio components without major changes
- You can’t reuse frontend code written for GPT-4 or other OpenAI models
- You lose out on ecosystem compatibility and tooling
4. No Unified Serving Framework
Unlike text-only LLMs (which have Hugging Face Text Generation Inference, vLLM, TGI, etc.), the multimodal world is fragmented.
Each repo reinvents:
- Its own server
- Its own API spec
- Its own format for image inputs
There’s no standard, and little focus on high-performance serving.
5. Developer Pain, End-User Friction
The result? A lot of unnecessary friction.
- Developers spend days debugging slow servers, memory issues, and JSON formats
- Users get laggy experiences and unresponsive apps
- Everyone asks: “Why can’t this be as easy as calling OpenAI?”
The Takeaway
Multimodal LLMs are revolutionary — but they need a proper serving engine to make them usable in the real world.
We need:
- High-throughput inference
- Token streaming
- OpenAI-compatible APIs
- Easy-to-integrate UI workflows
That’s where vLLM comes in — and in the next section, we’ll show you exactly how it addresses these problems.
What Is vLLM?
vLLM is an open-source, high-throughput inference engine for large language models, designed to offer blazing-fast generation, efficient GPU memory usage, and native OpenAI-compatible endpoints. Developed by researchers at UC Berkeley, it replaces slower, memory-heavy solutions like Hugging Face pipelines or naive FastAPI backends with a serving stack purpose-built for production-scale LLM deployments — including multimodal models like LLaVA.
Unlike traditional approaches, which often suffer from inefficient memory usage and high latency under real-time workloads, vLLM is optimized for scale from the ground up. It incorporates several advanced techniques used in modern model-serving platforms like OpenAI and Anthropic — giving developers a way to replicate that experience locally or in cloud environments.
Core Features That Power vLLM
Let’s take a closer look at the innovations under the hood:
PagedAttention (Efficient KV Caching)
Autoregressive LLMs generate a growing set of key/value (KV) attention caches as they generate more tokens — leading to fragmented and bloated memory footprints, especially when handling multi-user workloads.
vLLM introduces PagedAttention, a new memory management scheme that chunks KV caches into fixed-size blocks and stores them in a paged, virtualized GPU memory structure.
This enables:
- Better memory reuse across parallel prompts
- Lower memory fragmentation
- Higher batch sizes without running out of VRAM
In practice, PagedAttention can reduce memory overhead by up to 80% while supporting tens to hundreds of concurrent sessions.
Continuous Batching
Unlike traditional batching (where requests must arrive together), vLLM supports continuous, asynchronous batching. Incoming prompts are dynamically grouped on-the-fly into optimal execution batches — ensuring near 100% GPU utilization even when prompt lengths and arrival times vary.
This batching strategy supports real-time inference at scale, and is particularly important in latency-sensitive scenarios like chat applications or RAG pipelines.
Speculative Decoding
To further accelerate inference, vLLM supports speculative decoding, a technique where a lightweight draft model generates candidate tokens, which the main model then verifies.
This reduces response time by pipelining generation steps and improves responsiveness without sacrificing accuracy — especially during long-form generation.
Streaming Responses
vLLM supports token streaming, allowing the model to send outputs incrementally as they’re generated — just like OpenAI’s ChatGPT.
This is essential for applications like:
- Chatbots
- Agent loops
- Any UI that benefits from progressive rendering (e.g., Streamlit, LangChain)
Streaming is enabled via flags in vllm-serve and supported natively in its OpenAI-style endpoints.
Built-in OpenAI-Compatible API
You can query vLLM using the same /v1/chat/completions and /v1/completions APIs used by OpenAI’s GPT models — which means tools like:
- LangChain
- OpenAI SDKs
- Custom UIs (e.g., Streamlit): work out of the box with minimal code changes.
Why This Matters for Multimodal Workloads
While vLLM was originally developed for language-only models, it now includes first-class support for vision-language models like LLaVA via the –mm-vision-tower flag. This means:
- You can run image + text prompts
- Output grounded, multimodal responses
- Without needing any model-specific patches or wrappers
Both offline Python APIs (from vllm import LLM) and OpenAI-compatible server mode (vllm serve) work seamlessly with models like:
- llava-hf/llava-1.5-7b-hf
- bakllava/llava-1.6
- And future extensions (e.g., CogVLM, LLaVA-Next)
This makes vLLM the go-to serving solution for developers building production-ready multimodal interfaces.
vLLM GitHub Repository
You can find the official vLLM source code on GitHub here: github.com/vllm-project/vllm
This repository contains everything you need to get started with vLLM:
- The vLLM inference engine and vllm-serve entrypoint
- Example scripts for serving models via both Python and OpenAI-compatible endpoints
- Docker setup and deployment instructions
- Guides for working with different model types (text-only, vision-language, MoE, etc.)
- Active issues, discussions, and contributions from the open-source community
The repo is actively maintained and regularly updated with new features like LLaVA integration, continuous batching improvements, and speculative decoding enhancements. If you’re planning to extend vLLM, contribute features, or stay up to date with roadmap discussions, the GitHub repo is the place to watch.
You’ll also find quick links to documentation, issue reporting, and model support in the README. Whether you’re deploying on a single GPU or designing inference-as-a-service pipelines, this repo is your one-stop resource.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this lesson, we took a deep dive into the evolving landscape of multimodal large language models — models that don’t just understand text. However, we can also process and reason over images. From early breakthroughs like Flamingo to closed-source systems like GPT-4V and open-source challengers like LLaVA and BakLLaVA, we’ve seen how the frontier of AI is rapidly expanding beyond language.
We explored why multimodal matters — not just in theory, but in practice. These models are already being used to build smarter assistants, improve accessibility, analyze documents, and power next-generation applications across domains. And the demand for open, self-hosted, and adaptable alternatives to commercial APIs is only growing.
But with that opportunity comes complexity. Most open-source multimodal models aren’t designed with efficient deployment in mind. High memory usage, lack of batching, and incompatible APIs make serving them at scale a real challenge.
That’s where vLLM enters the picture. Created to serve LLMs with high throughput and low latency, vLLM now supports vision-language inference thanks to a recent PR that adds LLaVA model support. While it doesn’t handle multimodal models entirely out of the box, it provides a robust, OpenAI-compatible foundation — and with a few targeted extensions, it can be adapted to serve LLaVA or BakLLaVA in real-world applications.
In the next lesson, we’ll take everything we’ve learned here and turn it into something concrete. We’ll clone the repository, set up the vLLM backend, and deploy a fully working multimodal server that accepts images and text prompts. Whether you’re planning to build a custom visual chatbot, a document Q&A tool, or want to experiment with multimodal reasoning, this setup will give you everything you need to get started.
Let’s get building.
Citation Information
Singh, V. “The Rise of Multimodal LLMs and Efficient Serving with vLLM,” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/b7phz
@incollection{Singh_2025_rise-of-multimodal-llms-and-efficient-serving-with-vllm,
author = {Vikram Singh},
title = {{The Rise of Multimodal LLMs and Efficient Serving with vLLM}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
year = {2025},
url = {https://pyimg.co/b7phz},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.